商用4G&5G小基站基帶芯片的設計與分析
2023-06-02 23:52:01王俊
計算機應用文摘 2023年10期
王俊
關鍵詞:系統級芯片;5G NR;4G LTE;BB;DSP
1引言
近10年來,4G&5G通信技術的飛速發速極大地提升了通信效率,改變了日常的通信生活方式。5G相比于4G,其空口帶寬更大、天線數更多、調制階數更高,空口速率更是提升到10倍以上,帶寬與多天線等通信技術對基站的物理層信號處理能力提出了更高的要求。目前,市場上的5G網側基帶芯片基本被國外芯片廠商壟斷,如NXP,Qualcomm,Intel,Xilinx等,國內設備商華為和中興也有自研的5G基帶SoC芯片,但不對其他設備商銷售。因此,國內的小站設備商獲得4G&5G基帶商用SoC芯片的選擇范圍很小,若要選擇純國產的基帶SoC芯片更是不可能。因此,研制一款能部分替代國外小站基帶芯片的國產商用SoC芯片便提上了日程。
2項目概況
該基帶SoC芯片OC8010是可用于4G&5G小基站或自定義軟件無線電(SDR)方案中的基帶處理芯片。芯片遵循3GPP[1]Rel-15和Rel-16,并有足夠軟化資源以支持后續版本的演進,同時兼顧功耗、性能、面積的平衡性。基帶處理主要集成了4個高效能的協議與控制處理器ARM A72 CPU、4G和SG雙模通信基帶處理硬件加速器、4個高性能的專為SG優化過的CEVA XC-12矢量DSP等。另外,芯片上還集成了豐富的前傳與中傳高速接口、低速外設接口等。在這些加速器和矢量處理器的輔助下,用戶可以實現高吞吐率的多種無線通信系統。
芯片設計專門考慮了一些低功耗設計,這些設計有助于其在各種通信場景下獲取高性能和低功耗特性。另外,芯片的研發、生產、封裝和測試都在國內,是國產自主可控的SDR基帶處理芯片。
OC8010是一個異構多核基帶SoC,軟硬件架構更加復雜,在芯片設計中需應對這幾個方面的挑戰:更加復雜的數據通信和任務調度:龐大的抽象的系統架構,以實現清晰、高效的硬件與軟件設計;協調好SoC上的硬件加速、DSP和CPU等各種異構并行處理資源;提供豐富有效的片上調試功能;在性能、靈活性、功耗、面積等方面折中。
3SoC芯片系統結構設計
OC8010SoC上的基帶處理資源主要包括物理層信號處理、物理層控制、前傳后中傳接口等子系統,BB SoC芯片架構圖如圖1所示。其中,物理層信號處理子系統主要由芯片上的L1硬件加速器(L1 Accelerator)與矢量DSP(L1 Processor)構成;物理層控制子系統主要由ARMCPU構成;接口子系統包含前傳(分布式單元DU與遠端單元RU) CPRI或eCPRI接口,與中傳(中央單元CU與分布式單元DU)PCIe或ETH接口。
OC8010基帶SoC芯片上有豐富的計算資源,有符合3GPP的比特級編譯碼加速器,以及OFDM波形前端LowPHY處理加速器,片上有多達近萬億MAC運算能力的矢量4個DSP核,可以滿足用戶差異化的信道估計與均衡算法設計,或者用戶自定義的專用通信系統基帶信號處理。其可以應用于4G&5G小基站的基帶處理,如圖2所示,OC8010可以分別完成全部的L1 High-PHY與LowPHY處理,或是只完成High-PHY的處理,需要外接NPU進行L2/L3協議棧處理,外接DFE芯片完成中射頻處理等。
該芯片基帶處理器中的運算資源靈活可配,可以根據波形基帶處理的復雜度,采用1套或2套運算資源完成單模或雙模并發波形處理。以單模5GNR為例,可以支持的典型規格為FRl-TDD,BW= 100 MHz.SCS=30 kHz.2小區4T4R,并可以實現DL 4 Gbps,上行2 Gbps的峰值吞吐量。若4G&5G雙模并發配置下,則可以同時支持SGNR FRl-TDD,BW=100 MHz.SCS= 30 kHz@ 4T4R 1小區.4G LTE BW= 20 MHz,SCS=15 kHz@ 4T4R 3小區的規格。
4SoC芯片主要功能模塊設計
4.1CPU子系統模塊設計
Cortex-A72處理器是ARM公司于2015推出,并為高性能,低功耗的處理器實現了ARMv8-A體系結構。其廣泛應用于高端智能手機、大屏移動設備、企業網絡設備、服務器、無線基臺、數字電視等領域。OC8010芯片集成了4個ARM Cortex-A72核,L1和L2緩存子系統等。具體如表1所列。
ARM 72 11存儲器系統由獨立的指令緩存(I-Cache)與數據緩存(D-Cache)構成[2]。
A72 11指令緩存系統具有以下特點:(1)固定的Cache line為64字節;(2)每16位采用奇偶校驗保護;(3)指令緩存按物理索引和物理標記(PIPT)方式工作;(4)采用LRU(Least Recently Used)緩存替換策略;(5)支持內存自檢測試MBIST(Memory Built-InSelf Test)。
A72 11數據緩存系統具有以下特點:(1)固定的Cache line為64字節;(2)每32位采用ECC保護;(3)數據緩存按物理索引和物理標記(PIPT)方式工作;(4)支持對正常內存的亂序、推測性、非阻塞性加載請求和對設備內存的非推測性、非屏蔽性加載請求;(5)采用LRU緩存替換策略;(6)硬件預取器,生成針對L1數據緩存和L2數據緩存的預取;(7)支持內存自檢測試MBIST(Memory Built-In Self Test)。
在4個Cortex-A72核的共同作用下,CPU子系統可以確保在每個時隙(slot)內完成小基站多小區多用戶的處理要求。CPU子系統主要負責物理層處理的控制功能,完成L2與L1之間的FAPI(SCF222:PHYAPI Specification)請求消息參數的解析、FAPI響應消息的準備發送、配置物理信道(如PDSCH,PDCCH,PBCH,PUSCH,PUCCH,PRACH等)的參數、調度L1硬件加速器與L1 DSP矢量處理器完成物理層發送和接收處理等。
4.2DSP子系統模塊設計
片上集成了4個高性能矢量CEVA XC12 DSP核。XC12是CEVA的第4代矢量處理器IP,它能夠進行客戶配置和擴展,應用范圍較廣,可用于蜂窩網絡的5G-NR和4G-LTE,智能手機或其他終端,如Wi-Fi UE和CPE等,提供極低功耗、Gbps級的無線調制解調器功能,以便于客戶實現高吞吐率的寬帶無線通信系統。
CEVA-XC12 DSP架構突破了以下關鍵技術。
(1)全新微架構滿足超高頻率和超低功耗要求——能夠在10nm內以1.8 GHz頻率運作,與前代產品CEVA-XC4500相比,功耗降低50%。
(2)具有大規模計算能力,以維持高數據速率——配備4矢量處理器引擎,每秒運算次數接近1萬億次(TOP)。
(3)全新獨特的高精度算法——支持高達256×256維矩陣高效運算。
(4)用于加速基帶信號處理組件的全新專用指令和算法庫——為先進的256和1024 QAM解調提供創新支持。
(5)新型核間數據流接口——允許在內核或加速器之間達到超低傳輸延遲。
為了提升DSP的性能,OC8010對一些關鍵電路采取了優化方案,如縮短了分頻電路的路徑延時,并將片上DSP的最高時鐘頻率提至800 MHz~1GHz。
4.3加速器模塊設計
OC8010芯片集成了寬帶通信系統常用的硬件加速器。在這些硬件加速器的輔助下,可以實現高吞吐率的4G,SG及用戶自定義無線通信信號處理加速,如圖3所示為OC8010芯片基帶處理軟硬件劃分,片上的硬件加速器主要包括編譯碼、均衡、Low-PHY等加速器子系統。
4.3.1編譯碼加速器子系統
該加速器子系統由LDPC和Polar、卷積、Turbo等加速器構成,LDPC和Polar編碼和譯碼器遵循3GPP38.212 Rel-16規范,主要用于SGNR的編譯碼處理以及Turbo和卷積編碼。譯碼加速器遵循3GPP 36.212Rel-10規范,主要用于4G LTE的編譯碼加速處理。
業務信道編碼器主要完成TB CRC、CB分割、CBCRC、LDPC/Turbo編碼、速率匹配、CB級聯等處理;業務信道譯碼器主要完成CB分割、解速率匹配、HARQ合并、LDPC/Turbo譯碼、CB CRC、CB級聯、TB CRC等處理。表2為典型配置下(LDPC與Turbo譯碼均為8次迭代)的業務信道編譯碼器最大吞吐量性能(@ 600 MHz時鐘頻率)。
4.3.2均衡加速器子系統
均衡加速器子系統支持最小均方誤差干擾抑制(MMSE-IRC)算法,因該算法良好的性能與復雜性而被業界廣泛應用。MMSE-IRC算法對于基站檢測位于相鄰小區間環境中的用戶來說是必不可少的,與MMSE-MRC算法相比,它能夠減少區間干擾和降低高斯噪聲的影響,進而提升了接收機的均衡性能。
OC8010的均衡加速器可支持自適應MMSE-IRC和MMSE-MRC算法,可使接收機在不同信道環境下均能獲得最好的均衡性能。圖4為該加速器的功能示意圖。
該均衡加速器可以支持PUSCH均衡處理,在典型配置下的處理能力為:完成每個上行slot全部均衡處理時間小于1個3GPP定義的時隙(slot)。這里的典型配置為2個SGNR FRl-TDD小區,每小區273PRB(BW100MHz,SCS=30 kHz),4接收天線,2Layer等。
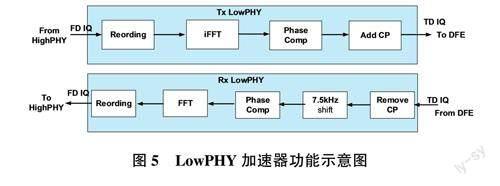
4.3.3時頻域轉換LowPHY加速器子系統
該加速器主要完成OFDM波形變換:Tx Low-PHY主要完成數據重排、IFFT、加CP、相位補償(5G)等處理;Rx Low-PHY主要完成去CP、相位補償(5G)、7.SkShift( LTE)、FFT、數據重排等處理。LowPHY加速器功能示意圖如圖5所示。
該LowPHY加速器的典型處理能力為2個SGNRFRl-TDD小區,每小區4T4R,BW=100 MHz,SCS=30 kHz。
4.4存儲器模塊設計
在異構多核系統芯片中,數據的存儲、傳輸與交換需要更加高效的存儲架構,從而導致存儲與計算之間的矛盾更加突出。基帶信號在處理高密集計算類應用時,如何設計高效的片上共享存儲器對發揮SoC整體性能有重要作用。
OC8010基帶芯片上的處理單元之間需要大量的數據交互,通過仔細分析基帶接收與發送信號處理的數據流,得到幾種典型場景下的數據流模型(Trafficmode),包括但不限于模塊間的數據吞吐量、數據緩存大小、處理單元數據的并發。
OC8010上的共享緩存具有如下系統特性:(1)緩存大小為10 MB字節;(2)分成8個Bank,每個Bank1.25 MB字節;(3)每個Bank均為2端器存儲器,支持對同一個Bank不同地址地同時讀與寫;(4)支持任務隊列以及每個端口優先級可配;(5)多個端口訪問權重可配,支持帶權重的輪詢(WRR)訪問機制;(6)每個port支持基于“緊急”的防餓死機制等。
4.5總線模塊設計
總線結構及互連設計直接影響芯片總體性能的發揮,OC8010片上總線選用ARM的CoreLink NIC系列主流商用總線,將系統中的ARM CPU處理器、CEVA DSP、加速器、PCIe等高速外設、12C等低速外設、存儲器(SRAM,ROM,DDR)等所有系統組件連接起來,允許這些組件之間進行互聯互通,并且易于軟件編程使用。系統分析與評估了片上的通信帶寬、吞吐率、QOS、功耗使用、安全性以及成本等因素后,最終通過片上切分為多個總線區域進行互聯,參見圖1。
4.6高速接口模塊設計
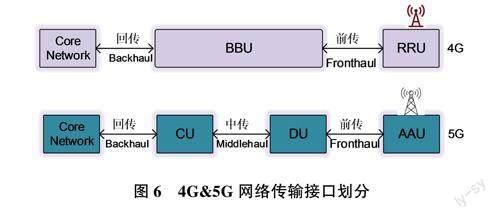
4G只有前傳和回傳2個部分,在SG網絡中則演變為三個部分,AAU連接DU部分稱為SG前傳(Fronthaul),中傳(Middlehaul)指DU(處理L1物理層)連接CU(處理L2/L3協議棧)部分,而回傳(Backhaul)是CU和核心網之間的通信承載,如圖6所示。基帶SoC處于BBU中的DU部分,相關的接口只涉及前傳與中/后傳。
前傳接口:OC8010上的eCPRI用于O-DU High-PHY和O-RU Low-PHY之間通過以太網傳輸頻域IQ數據,接口遵循O-RAN聯盟的前傳接口規范,同時支持OTIC的相關標準。支持5G物理層功能按Option8(CPRI)和Option7-x(eCPRI)接口切分方式與RU對接,芯片可編程配置處理前傳接口的CPRI/eCPRI協議數據和用戶自定義數據,CPRI/eCPRI接口均支持發送與接收數據的壓縮與解壓縮,支持的壓縮算法如塊浮點(Block Float-Point)、塊縮放(Block-scaling)、律(I -law)等,能夠滿足4G&5G多應用場景下的定制化需求。
中后傳接口:DU與CU之間的中傳接口采用PCIe Gen4(向下兼容Gen3)或ETH (10GE),該接口主要實現L1與L2的通信。
5SoC芯片的可靠性設計
5.1高可靠的冗余電路設計
對于內存軟錯誤(soft errors),錯誤修正碼(ECC)技術在SRAM電路中得到了廣泛的應用,通過對輸人數據進行編碼并在內存中添加額外的冗余存儲位來提高內存的容錯性。對于硬錯誤(hard errors),內置自檢(built-in self-test,BIST)技術是內存測試技術的主流,內置自修復(built-in self-repair,BISR)技術應運而生,用于處理硬錯誤的修復。通過BISR的修復,可極大地提高芯片的優良率以及降低芯片的成本。ECC電路和BISR電路分別用于軟誤差和硬誤差的修復。以上兩種冗余電路技術在OC8010芯片上都已被采用,用來提升芯片的可靠性以適應不同的工作環境。
5.2高可靠復位電路設計
為確保芯片系統中電路穩定可靠工作,復位電路是必不可少的一部分。例如,電路在工作中受到干擾后,容易出現CPU程序“跑飛”而盲目運行,甚至出現死機現象,芯片上的復位電路則能夠糾正系統錯誤,以確保系統正常工作。
高可靠復位電路主要應用場景包括如下幾個部分。
系統啟動:從芯片上電復位開始至CPU加載完Uboot這一階段,復位電路進行的PLL配置、時鐘切換等應用。
子系統初始化:片上子系統由復位釋放到正常工作這一階段,復位電路對應的初始化操作。
子系統重啟:子系統在正常工作日寸,可根據需求重新啟動。包括CPU、DSP以及各類硬件加速器等子系統重啟等。
異常情況處理:應對異常觸發的場景,復位電路對應的操作。
5.3多工作模式設計實現低功耗
OC8010芯片從一開始的系統設計階段就引入了低功耗設計,在系統和架構設計層從性能和功耗方面進行軟硬件劃分,通過軟硬件協同仿真,將最佳性能/功耗比作為確定片上軟硬劃分的依據,以及將不同的子系統功能單獨分割開,方便后續芯片的實現等。
在RTL設計階段采用的主要方法如下。
(1)門控時鐘技術(Clock gating),根據設計將暫時不用的模塊的時鐘信號通過一個控制信號關斷( gating)住,降低該模塊的時鐘信號翻轉率,從而降低芯片功耗。
(2)電源門控(power gating),可通過靜態配置的方式,將芯片中某個區域的供電電源關掉。
(3)支持動態頻率(Dynamic Frequency Scaling)調節等,如支持每個DSP核可單獨配置持降頻至1/2和1/4。
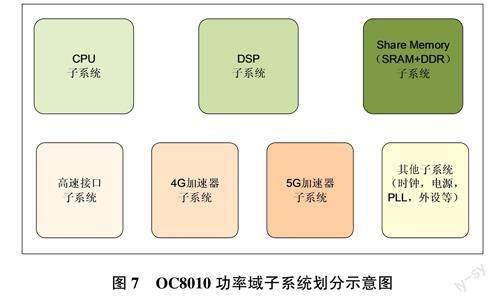
另外,根據系統中各個模塊的用途,以及IP自身支持的低功耗方案,將SoC劃分為不同的功率域,系統級的功率域如圖7所示。
針對不同的功率域子系統,以及每個子系統內部模塊都可以進行精細的低功耗設置,如可以對部分CPU/DSP核或者某個加速器進行關斷,從而有助于在各種通信場景下獲取高性能和低功耗特性。
6結束語
寬帶無線通信基帶芯片的設計是一個復雜的系統工程,只有少數幾家國外芯片巨頭可提供成熟的解決方案。本文介紹了國產OC8010商用小基站基帶芯片的設計與實現方案,提出了支持4G&5G雙模并發的基帶芯片解決方案,設計中解決了基帶芯片處理數據量大、算法復雜度高、可靠性要求高、低功耗等問題,滿足了商用4G&5G的大容量要求。該芯片方案有助于相關人員了解目前小基站基帶芯片的現狀,并為類似基帶芯片設計提供指導。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
藝術啟蒙(2018年7期)2018-08-23 09:14:18
家庭影院技術(2017年9期)2017-09-26 03:41:45
海峽姐妹(2017年7期)2017-07-31 19:08:17
