海關大數據分析教學研究
2023-05-30 10:48:04鄭鵬飛李菁菁
計算機應用文摘 2023年1期
鄭鵬飛 李菁菁
關鍵詞:海關大數據;GTA;R語言教學
1引言
對貿易數據進行統計和分析,是我國海關的傳統重要職能之一。2021年,我國貨物進出口總額突破39萬億元,比上年增長21 .4%。其中,出口21.7萬億元,增長21.2%;進口17.4萬億元,增長21. 5%。進出口貿易規模飛速增長,對海關統計分析人員的數據處理能力提出了更高的要求。然而,依據我國的海關統計制度,海關貿易數據的采集依賴各海關日常業務中產生的海量報關單,匯總以后具有來源廣、字段多、跨度大、體量大等特征,原始數據經常會到達數百萬行甚至上億行,面對如此規模的數據,傳統的Excel,Tableau等辦公軟件基本很難使用或者無法使用,需要使用新的工具才能實現“快、廣、深”的目標[1]。
作為一種綜合分析、科學預測的技術手段,大數據技術為構建統籌全局、系統集成、協同高效的海關數據分析體系提供了可能[2]。歐美發達國家海關的實踐已經表明,大數據技術可以成為海關數據分析的“效率倍增器”。例如,美國海關開發的“全球自動布控系統”能夠迅速將旅客、艙單等信息與其他數據庫進行綜合比對,大幅提升了對“高風險旅客”的篩查效率。
鑒于此,《“十四五”海關發展規劃》將“科技興關動力強勁,創新應用能力大幅提升”作為主要目標之一,強調要“以大數據驅動風險防控、通關監管、稅收征管、檢驗檢疫等海關主要業務運行,形成大數據智能應用生態,提升大數據輔助治理能力。”
2統計軟件R語言特征
為使人才培養符合大數據處理的需求,目前很多高校都開設了諸多統計軟件課程[3],如Python,R,Stata,SAS,SPSS,MATLAB等。其中,R語言是一種功能強大、被諸多高校所青睞的課程,它具有以下幾個基本特征。
(1)R是開源軟件[4]。可以在它的網站及其鏡像中下載任何有關的安裝程序、源代碼、程序包及其源代碼、文檔資料。標準的安裝文件自身就帶有許多模塊和內嵌統計函數,安裝好后可以直接實現許多常用的統計功能。
(2)R是一種可編程的語言。作為一個開放的統計編程環境,語法通俗易懂,很容易學會和掌握語言的語法。而且學會之后,我們可以編制自己的函數來擴展現有的語言。這也就是為什么它的更新速度比一般統計軟件(如SPSS,SAS等)快得多。大多數最新的統計方法和技術都可以在R中直接得到。
(3)所有R的函數和數據集是保存在程序包里面的[5]。只有當一個包被載人時,它的內容才可以被訪問。一些常用、基本的程序包已經被收入標準安裝文件中,隨著新的統計分析方法的出現,標準安裝文件中所包含的程序包也隨著版本的更新而不斷變化。在另外版安裝文件中,已經包含的程序包有:base-R的基礎模塊、mle-極大似然估計模塊、ts-時間序列分析模塊、mva-多元統計分析模塊、survival-生存分析模塊等。
(4)R具有很強的互動性[6]。如圖1所示,除了圖形輸出是在另外的窗口處,它的輸入輸出窗口都是在同一個窗口進行的,輸入語法中如果出現錯誤會馬上在窗口中得到提示,對以前輸入過的命令有記憶功能,可以隨時再現、編輯修改,以滿足用戶的需要。輸出的圖形可以直接保存為JPG,BMP,PNG等圖片格式,還可以直接保存為PDF文件。另外,和其他編程語言與數據庫之間有很好的接口。
綜上所述.R語言是一門適合大數據分析的強大工具。然而,凡事都有其兩面性,與圖形界面豐富的傳統統計軟件相比,R語言具有一定的學習門檻,初學者往往需要輸入至少一萬行代碼才能入門[7],而且很多程序包的學習甚至比R語言本身還要復雜(如ggplot2軟件包)。
3教學難點
在當前的R語言類課程教學中,主要存在兩個難點。
(1)教學時長偏短。在大多數高校的人才培養方案中,R語言類課程的教學時長都是16周、32學時,教學內容多聚焦于數據結構、基本語法,難以使學生快速掌握大數據分析能力[8]。
(2)難以獲取數據來源。海關高度重視數據保密工作,海關采集并保有的很多數據都涉及國家機密。雖然海關統計部門也通過其數據公布平臺定期發布海關數據(如圖2所示),但其體量與“大數據”的特征存在較大的差距[9]。
除海關數據外,很多其他來源的大數據都涉及商業機密,既難以供學生在課堂上操作實踐,也可能與海關數據分析的主題相去甚遠。
4基于GTA數據的教學案例
GTA是全球關貿數據庫(Global Trade Atlas)的簡稱,它將全球200多個國家和地區海關所提供的進出口統計信息整合成一個全面的、雙邊的商品貿易數據庫,使全球貿易分析人員按需搜索并下載所需數據成為可能。該數據庫同時提供逐筆的貿易信息,數據來源廣、體量大、跨度久,是用來進行海關大數據分析教學的絕佳數據。
4.1分析目標
驗證“十三五”期間我國優勢出口產業是否發生了明顯地向其他國家轉移。
4.2解決思路
第一階段:基于GTA數據庫,將我國2015年的全部出口報關單按6位數HS編碼進行分組并匯總金額,按倒序排列,取出前200位HS編碼(TOP 200商品)作為我國2015年優勢產業代碼。
第二階段:計算2015年,全世界各個國家和地區的TOP 200商品出口金額,計算包括我國在內的各個國家和地區這200種商品的出口份額(Share2015)。
第三階段:基于GTA數據庫,查找2019年全世界各個國家和地區TOP 200商品的出口金額,計算包括我國在內的各個國家和地區這200種商品的出口份額(Share2019)。
也可以繪制成圖形,更清晰直觀地展示5年內我國在TOP 200商品出口份額的變化情況,如圖3所示。
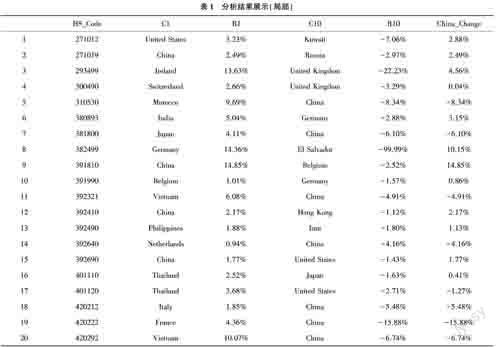
計算結果如表1所列(局部),不僅能得到在目標5年內TOP 200商品中國的市場份額變化情況,還能得到該商品市場份額增加的前5名國家和減少的后5名國家(因篇幅限制,此處僅顯示前1和后1),即回答了“我們的份額是從誰那搶來的”或者“我們的份額被誰搶走了”的現實問題。
總體來看,在TOP 200商品中,我國出口份額增加的商品有95種,減少的有105種,基本保持穩定,即2015~2019年間,我國并未發生明顯的產業鏈流失。
5結束語
在大數據人才培養過程中,統計軟件R語言等可編程開源軟件是較為普遍的選擇。然而,由于海關數據的特殊性和難以獲取性,貼近海關數據分析實際的實踐教學相對困難。本文以GTA數據為例,利用難度不高的代碼對海關統計分析領域的一個常見問題進行了較為清晰的解答,為海關大數據分析教學提供了新的思路。
