基于ERNIE的新聞標題文本分類
2023-05-30 10:48:04徐云鵬曹暉
計算機應用文摘 2023年7期
徐云鵬 曹暉
關鍵詞:文本分類;EWLTC; ERNIE;注意力機制
中圖法分類號:TP391 文獻標識碼:A
隨著時代的發展,文本數據從傳統的實體化向數字化、虛擬化方向發展。新聞文本是我們生活中接觸最為廣泛的一種文本數據,但由于新聞來源渠道復雜多樣,需要對其進行準確的分類。
一方面,準確的新聞類別標簽可以幫助用戶快速地檢索感興趣的新聞;另一方面,根據用戶的使用需求進行標簽化、類別化推薦,需要將新聞文本存儲至不同類別庫中。隨著信息的爆炸式增長,人工標注數據完成分類任務極為耗時,且易受到標注人主觀意識的影響。對于快速實現文本分類的需求日漸增加,自動文本分類技術應運而生。深度學習方法作為該領域的主流研究方向,突破以往機器學習的瓶頸,給文本分類領域帶來重大機遇。
ERNIE (Enhanced
Representation
throughKnowledge Integration)是百度發布的預訓練模型。它將Google發布的BERT( Bidirectional EncoderRepresentation from Transformers)中單詞級別的MASK拓展成3種級別的Knowledge Masking,從而讓模型學習到更多語言知識,在多項任務實踐效果上超越了BERT。
Jawahar等在2019年分別通過短語語法(Phrasal Syntax)、探測任務(Probing Task)、主謂一致(Subject-Verb Agreement)、組成結構(Compositional Structure)4個實驗發現,以BERT為代表的預訓練模型編碼了豐富的語言學層次信息:表層信息特征在底層網絡,句法信息特征在中間層網絡,語義信息特征在高層網絡。Encoder層越淺,句子向量越能代表低級別語義信息,Encoder層越深,句子向量越能代表更高級別的語義信息。因此,本文EWLTC模型為了獲取不同級別的語義信息,提升模型分類效果,將預訓練模型ERNIE Encoder層輸出的第1個token向量[CLS]通過注意力機制進行加權求和,并作為后續全連接層的輸入,增加了語義信息的融入,使得新聞標題文本結果優于ERNIE以及傳統的文本分類模型。
1相關工作
文本分類(Text Classification,TC)作為自然語言處理領域的重要研究領域,主要分為淺層學習和深度學習兩個發展階段。淺層學習在1960~2010年占據文本分類模型的主導地位。淺層學習模型主要是基于統計學習的模型,如樸素貝葉斯(Naive Bayes,NB),K近鄰(k-Nearest Neighbor,KNN)和支持向量機(Support Vector Machine,SVM)等。盡管與早期基于規則的分類方法相比,淺層學習模型(Shallow Learning)在準確性和穩定性方面具有顯著優勢,但淺層模型的堆疊層數僅有1~2層,導致模型的表達能力極為有限,并且樣本的特征提取極其依賴先驗知識進行手動抽取,反復的實驗摸索耗費大量的人力物力,極大地限制了淺層模型的效果。
2006年,Hinton提出深度學習(Deep Learning)的概念,使用多隱藏層的人工神經網絡來進行樣本的特征抽取與學習,克服了淺層學習依賴人工的缺點,由此成為目前自然語言處理的主流研究方法。卷積神經網絡(Convolutional Neural Networks,CNN)與遞歸神經網絡(Recurrent Neural Network,RNN)是用于文本分類任務的2種主流深度學習方法,TCNN與RNN模型相較于淺層學習模型,CNN的并行計算效率高,RNN則更注重文本的序列特征,二者都可以顯著提高文本分類性能。隨后,研究人員將人類視覺注意力機制的原理引入自然語言處理任務中,其基本原理為在眾多的輸入信息中聚焦于對當前任務更為關鍵的信息,而降低對其他信息的關注度,甚至過濾掉無關信息,將其與深度學習模型相結合,有效提升了文本分類的計算效率與準確率。
2018年,BERT的出現在自然語言處理領域具有里程碑式的意義,其在多個自然語言處理(Natural Language Processing,NLP)任務中獲得了新的SOTA(state-of-the-art)的結果,其強大的模型特征抽取能力使大量研究工作圍繞其展開,自然語言處理研究進入大數據時代,ERNIE模型是BERT的眾多改進模型之一。
2模型描述
ERNIE總體模型結構和BERT -致,使用的是Transformer Encoder,輸入與輸出的個數保持一致。相較于BERT,ERNIE的改進主要分為兩方面。
(1)采用新的Mask方法。BERT初次提出了MLM方法,以15%的概率用mask token([MASK])隨機對每一個訓練序列中的token進行替換,然后預測出[MASK]位置原有的單詞。BERT是基于字的MASK,ERNIE是基于詞語的MASK。假設訓練句子為“哈爾濱是黑龍江省的省會城市”,BERT會將哈爾濱隨機遮蓋為哈“mask”濱,無法學習到哈爾濱是一個重要的地點實體。ERNIE則隨機遮擋掉地名實體黑龍江,此模型能夠在一定程度上學習到“哈爾濱”與“黑龍江省”的關系,即模型能夠學習到更多語義知識。相較于BERT,ERNIE成了一個具有更多知識的預訓練模型。
(2)增加預訓練任務:通過增加對話預料的訓練,判斷兩句話是否屬于同一句話取代BERT原有的NSP(Next Sentence Prediction)任務。
ERNIE由12層編碼網絡組成,每層的隱藏狀態hidden_size為768,并且有12個z注意力頭(Attention-Head),總計110 M參數。ERNIE在每一層網絡都使用第一個輸入符號([CIJS])輸出進行表征計算,通過自注意力機制匯聚了所有真實符號的信息表征。
ERNIE的每層輸出分別為last_hidden_state,pooler_output, hidden_states, attentions,其中,hidden_states是每層輸出的模型隱藏狀態加上可選的初始嵌入輸出。選取其中12層Encoder層的輸出,總計12個元組:12*(batch_size,sequence_length,hidden_size)。但12層cls每層的特征信息對于預測的貢獻不同,無法簡單相加,為此通過引入注意力機制實現對12個向量的加權求和,在模型訓練中自動分配權重給對象的cls向量。最終將求和后的向量輸入至全連接層進行預測訓練。
3實驗結果與分析
3.1實驗數據集與評價指標
實驗中,采用新聞文本分類中常使用的THUCNews,根據新浪新聞RSS訂閱頻道2005~2011年的歷史數據篩選過濾生成。本次實驗選取其中的5萬條數據集。本文使用目前通用評價指標來評估模型的優劣,即精確率(Precision)和召回率(Recall)。精確率指正確的正樣本個數占分類器判定為正樣本的樣本個數的比例,召回率是指分類正確的正樣本個數占真正的正樣本個數的比例。
3.2實驗對比
本文使用五折交叉驗證(5-fold cross-validation)來測試EWTLC型的效果,該方法的基本思路是:將所有的數據集平均分為5個部分,依次抽取4個部分當作訓練集,剩下1個部分當作測試集進行測試,然后將5輪訓練與預測后的結果進行平均,將平均值作為模型最后的估計結果。
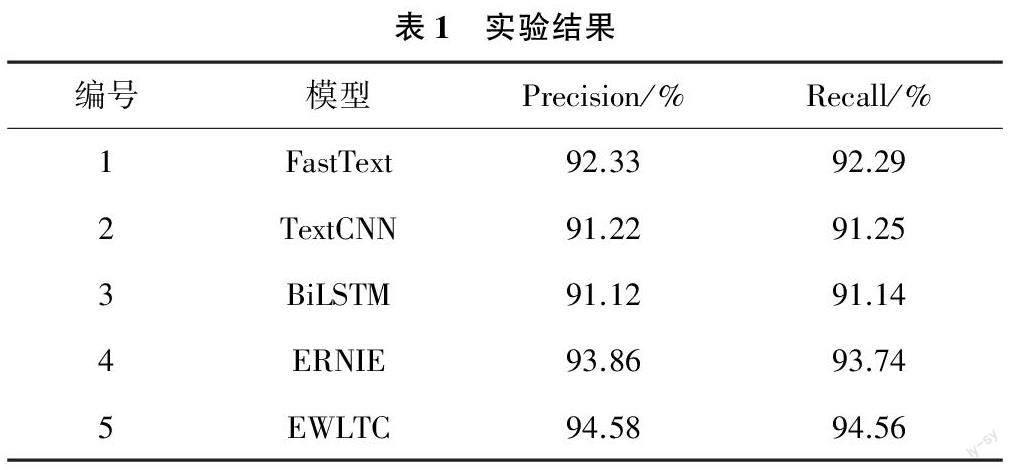
參與對比的網絡模型主要包括:(1)FastText模型,采用Facebook AI Research開源的機器學習訓練工具FastText對新聞標題進行標簽分類;(2)TextCNN模型,采用文本卷積神經網絡TextCNN模型對新聞標題進行標簽分類;(3)BiLSTM模型,采用雙向長短時記憶網絡BiLSTM模型對新聞標題進行標簽分類:(4)BERT+FP模型,基于BERT預訓練模型和全連接層Fully Connected Layers對新聞標題進行標簽分類;(5)EWLTC模型,采用EWLTC模型對新聞標題進行標簽分類。實驗結果如表1所列。
(1)通過對比實驗1和實驗3結果發現,利用FastText模型相較于BiLSTM模型、TextCNN更為優秀,主要原因是FastText克服word2vec中單詞內部形態信息丟失的問題;(2)對比實驗4與實驗1結果發現,采用預訓練模型ERNIE的實驗結果是在FastText的基礎上大幅度的提升,原因在于預訓練模型有助于更好地抽取文本特征,生成文本向量;(3)通過對比實驗5結果與實驗4結果發現,相較于原本的預訓練語言模型只提取最后一層的輸出,EWLTC可以學習更多特征、獲取更好的分類效果。
4結束語
本文EWLTC模型進一步增強了文本的特征提取與表示能力,實現了更好的文本分類效果。
作者簡介:
徐云鵬(1997—),碩士,研究方向:人工智能。
曹暉(1971—),博士,研究方向:人工智能(通信作者)。
