基于細粒度特征與注意力機制的機載圖像匹配
2023-05-12 05:13:44俞心蕊姚竹賢連思銘丁祝順
航天控制 2023年2期
俞心蕊 姚竹賢,2 連思銘 丁祝順
1. 北京航天控制儀器研究所,北京 100039 2. 中國航天電子技術(shù)研究院,北京 100094
0 引言
機載圖像匹配技術(shù)是定位導航、目標跟蹤等應用的基礎,對匹配精度與效率都有著極高的要求。隨著計算機技術(shù)的發(fā)展,基于深度學習的策略成為機載圖像匹配任務的主流研究方向。目前絕大多數(shù)策略都是基于卷積神經(jīng)網(wǎng)絡,如文獻[1-3]分別基于VGG[4]網(wǎng)絡、ResNet[5]網(wǎng)絡、NCN[6]網(wǎng)絡來解決正射視角的航空圖像匹配問題。但在實際飛行中,拍攝視角具有不確定性,圖像會有空間上的轉(zhuǎn)換,需要充分理解全局關(guān)系。而基于卷積神經(jīng)網(wǎng)絡的方法感受野較小,無法在不破壞細粒度特征的同時獲取全局特征關(guān)聯(lián)。為此,學者們將具有全局感受野的注意力機制[7]引入機載圖像匹配任務,如文獻[8-9]分別基于空間轉(zhuǎn)換器[10](Spatial Transformer, ST)和視覺轉(zhuǎn)換器[11](Vision Transformer, ViT)來處理多視角機載圖像匹配問題。但上述方法在特征提取階段忽略了匹配圖像間的關(guān)聯(lián)關(guān)系。而文獻[12]已證明,進一步學習圖像間的相似性特征能有效提高后續(xù)匹配的精度。
因此,本文提出了一種基于細粒度特征和互注意力機制的機載圖像匹配方法(Image Matching based onFine-Grained Features andMutualAttention Mechanism, FGMA)。該方法以ViT為主干網(wǎng)絡提取局部細粒度特征和全局語義信息,引入互注意力機制來聯(lián)合學習匹配圖像間的相似性特征,將細粒度特征按注意力得分進行分割對齊,并使用改進的三重損失約束FGMA模型,實現(xiàn)多視圖多視角機載圖像匹配。
1 基于細粒度特征與互注意力的機載圖像匹配框架
1.1 FGMA模型結(jié)構(gòu)
FGMA由特征提取模塊和匹配模塊組成,具體如圖1所示。特征提取模塊利用ViT提取圖像局部細粒度特征和全局語義特征并融合,通過互注意力機制來增強圖像間相似度高的細粒度特征;匹配模塊通過計算每個細粒度特征的均值得到對應的注意力得分,按分值將細粒度特征分割對齊,用改進的三重損失約束模型進行訓練。

圖1 FGMA模型結(jié)構(gòu)示意圖
1.2 FGMA特征提取模塊
1.2.1 視覺轉(zhuǎn)換器ViT模塊

(1)
(2)
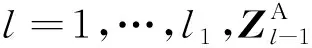
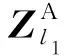
(3)
(4)
1.2.2 互注意力模塊

圖3 互注意力模塊結(jié)構(gòu)示意圖
(5)
(6)
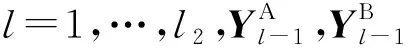
1.3 FGMA匹配模塊
在多視圖多視角圖像匹配中直接引入衡量全局特征差異會導致圖像匹配的精確度不高。基于此,本文引入了基于細粒度特征的分割對齊方式。根據(jù)每個細粒度特征的注意力得分,將特征劃分為m個區(qū)域?qū)R。特征分割示意圖如圖4所示,其中(a)為原輸入圖像,(b)為注意力得分的可視化熱力圖,(c)為特征分割示意圖。

圖4 特征分割示意圖
(7)
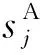
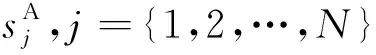
(8)

取m=3,即將按注意力得分重新排序后的細粒度特征按分值劃分為3個等級,使用數(shù)字1、2、3來定義。令得分最高的細粒度特征區(qū)域為f1,其次為f2,f3,對fi,i={1,2,3}進行平均池化操作,得到描述每個區(qū)域的特征向量Ei表達式如下:
(9)
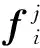
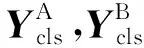
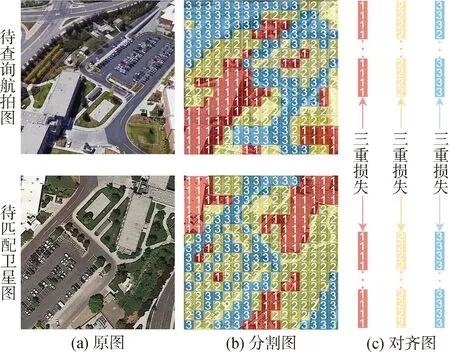
圖5 特征塊對齊示意圖
1.4 損失函數(shù)
FGMA模型的損失函數(shù)由交叉熵損失和三重損失組成。其中,交叉熵損失用來預測圖像的類別,三重損失用來約束圖像中不同區(qū)域間的距離,具體過程如下。
通過交叉熵損失L1對圖像分類結(jié)果進行約束,公式如下:
(10)
式中:pi表示樣本i的標簽,正類為1,負類為0;qi表示樣本i的預測正確的概率。
為了使模型建立更準確的匹配關(guān)系,應用改進的三重損失L2對分類后的細粒度特征進行自監(jiān)督訓練,最小化兩張圖像中相似區(qū)域之間的距離,表達式如下:
L2=ln(1+exp(d(a,p)-d(a,n)))
(11)
(12)
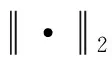
2 實驗
2.1 數(shù)據(jù)集
由于本文研究內(nèi)容側(cè)重于機載圖像匹配,因此所用數(shù)據(jù)集是基于開源的University-1652數(shù)據(jù)集[15]重新劃分所得。其中,訓練集包含1012對無人機圖像和待匹配衛(wèi)星圖像;測試集包含128*10=1280張待查詢無人機多圖像和896張待匹配衛(wèi)星圖像。
2.2 實施細節(jié)
在參數(shù)初始化方面,分類器模塊采用kaiming[16]初始化。訓練時,本文輸入圖像先經(jīng)過圖像增強(如隨機填充、隨機裁剪和隨機翻轉(zhuǎn)等),并將大小調(diào)整為256×256。優(yōu)化器方面,采用隨機梯度下降法,設置動量為0.9,權(quán)重衰減為0.0005,小批量為32。對于初始學習率,主干網(wǎng)絡參數(shù)設置為0.0015,其余可學習參數(shù)設置為0.05。模型總共訓練了100個周期。網(wǎng)絡使用交叉熵損失和三重損失分別約束分類結(jié)果和匹配效果。在測試過程中,使用歐氏距離計算查詢圖像和待匹配圖像間相似度。FGMA模型基于Pytorch框架實現(xiàn),所有實驗都在Nvidia GTX 1080Ti GPU上進行。
2.3 實驗評估
為了驗證所提出方法的有效性,設計如下實驗: 1)驗證基于注意機制的多視圖多視角機載圖像匹配效果。該實驗分為2個部分,首先在其他模塊不變的情況下用ResNet網(wǎng)絡替代ViT網(wǎng)絡,來驗證獲取全局信息的必要性。其次,在以Vit為主干網(wǎng)絡的基礎上,通過改變互注意力模塊的深度驗證互注意力模塊的有效性。2)對比劃分區(qū)域數(shù)量對圖像匹配效果的影響,驗證按注意力得分重新劃分后的細粒度特征類別的可靠性。
2.3.1 基于注意力機制的機載圖像匹配實驗
表1對比了基于注意力的ViT網(wǎng)絡和基于卷積的ResNet網(wǎng)絡處理本文任務的效果。從表中數(shù)據(jù)可以看出層深為8的小尺寸Vit-S網(wǎng)絡比ResNet-50的F1分數(shù)高10.12%,比ResNet-101的F1分數(shù)高6.17%,推理時間僅為ResNet-50的1.26倍,相比于ResNet-101推理速度更快。這是因為注意機制允許網(wǎng)絡關(guān)注全局信息,而基于純卷積神經(jīng)網(wǎng)絡的方法只關(guān)注顯著信息,忽略了全局信息。因此,上述實驗證明了全局信息有助于提升多視圖多視角機載圖像匹配性能。此外,還比較了層深為12的標準尺寸視覺轉(zhuǎn)換器Vit-B網(wǎng)絡,發(fā)現(xiàn)加深ViT網(wǎng)絡在犧牲推理速度的同時匹配效果并沒有帶來明顯的改善。因此選用ViT-S作為模型的主干。

表1 不同主干網(wǎng)絡對比
表2展現(xiàn)了互注意力機制在多視圖多視角機載圖像匹配中的效果。從表2可以看出僅加入1層互注意力機制,整個模型的F1分數(shù)提高了2.97%,而推理速度僅僅增加了0.0028s,證實了所加互注意力機制的有效性;如果加入5層,在略微增加耗時的情況下,模型F1分數(shù)提高了8.02%;但繼續(xù)加深互注意力機制,模型性能不升反降,分析原因應是隨著層深增加,參數(shù)過多,造成過擬合現(xiàn)象。因此,本文FGMA模型中設置5層互注意力層。
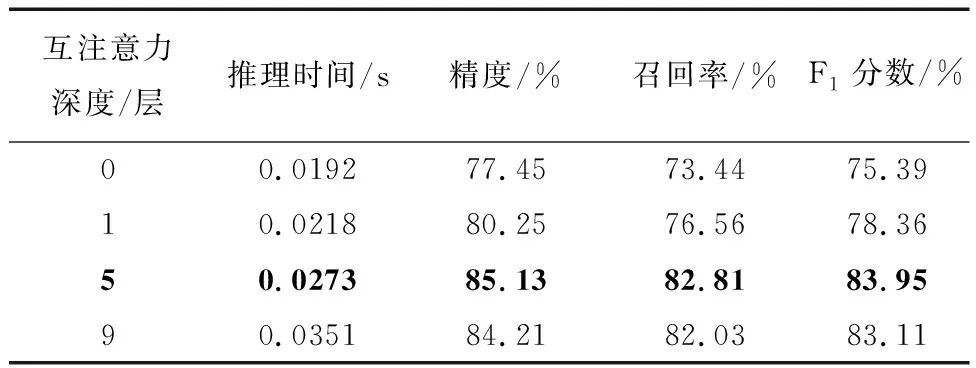
表2 互注意力機制的影響
2.3.2 區(qū)域數(shù)量對匹配效果的影響實驗
表3展現(xiàn)了分割區(qū)域m的選擇對匹配性能的影響。從表中可以發(fā)現(xiàn),選取不同的m,模型匹配性能會略有不同,但m>1時的匹配性能明顯優(yōu)于m=1,即將圖像分割后按區(qū)域?qū)R,要優(yōu)于直接按整張圖像對齊的匹配策略,證實了本文FGMA模型匹配模塊的有效性。此外,從表中可以發(fā)現(xiàn),分割區(qū)域并不是越多越好,分割區(qū)域的數(shù)量與模型提取的細粒度特征大小息息相關(guān),而細粒度特征的大小決定了它學習信息的能力。
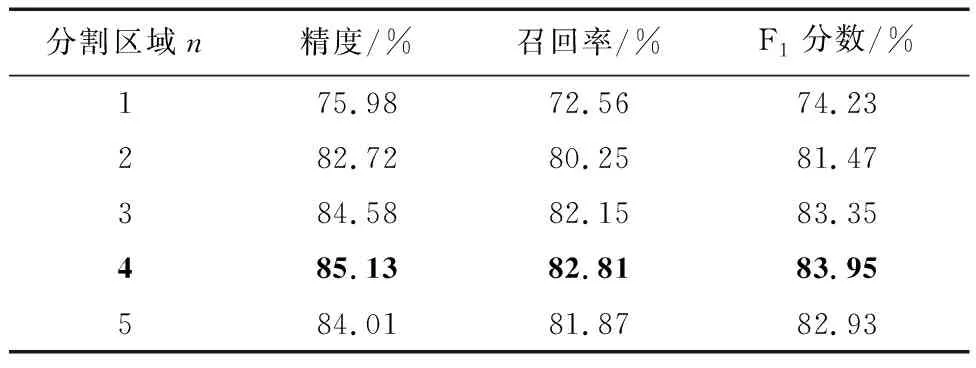
表3 分割區(qū)域數(shù)量的影響
圖6展示了FGMA模型在University-1652數(shù)據(jù)集上測試的部分結(jié)果。圖中返回的匹配圖像上方數(shù)值為1表示為正確匹配,為0則為錯誤匹配。圖6(a)展示了不同場景圖像的匹配結(jié)果,均為正確匹配,證實了所提模型具有一定的泛化性。圖6(b)和(c)展示了不同視角拍攝的同一場景圖像的匹配
結(jié)果,其中(b)是分割區(qū)域m=4時的匹配結(jié)果,(c)是m=1時的匹配結(jié)果。從圖中可以發(fā)現(xiàn),當m=1,即不分割區(qū)域時,不是所有視角的圖像都能返回正確匹配,而當m=4時,不論從什么視角拍攝的機載圖像,都能返回正確的衛(wèi)星圖像。因此,證實了本文提出的FGMA模型對多視圖多視角的機載匹配圖像具有魯棒性。
3 結(jié)論
將注意力機制應用于多視圖多視角機載圖像匹配任務,來融合細粒度特征和全局語義信息。此外,還引入互注意力模塊和細粒度特征分割與對齊模塊來提高模型的匹配性能。其中,互注意力機制著重學習具有匹配性的細粒度特征,而細粒度特征分割與對齊模塊,用來處理圖像空間上的變化。同時,改進三重損失函數(shù)使模型訓練更加平滑,加快模型收斂。最后實驗結(jié)果表明,FGMA方法的匹配精度高于目前先進算法,后續(xù)將進一步修改ViT的結(jié)構(gòu),以降低時間復雜度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
