RCache: A Read-Intensive Workload-Aware Page Cache for NVM Filesystem
2023-05-08 06:13:24TUYaofengZHUBohongYANGHongzhangHANYinjunSHUJiwu
ZTE Communications 2023年1期
TU Yaofeng ,ZHU Bohong ,YANG Hongzhang ,HAN Yinjun ,SHU Jiwu
(1.State Key Laboratory of Mobile Network and Mobile Multimedia Technology,Shenzhen 518055,China;2.ZTE Corporation,Shenzhen 518057,China;3.Tsinghua University,Beijing 100084,China)
Abstract: Byte-addressable non-volatile memory (NVM),as a new participant in the storage hierarchy,gives extremely high performance in storage,which forces changes to be made on current filesystem designs.Page cache,once a significant mechanism filling the perfor‐mance gap between Dynamic Random Access Memory (DRAM) and block devices,is now a liability that heavily hinders the writing perfor‐mance of NVM filesystems.Therefore state-of-the-art NVM filesystems leverage the direct access (DAX) technology to bypass the page cache entirely.However,the DRAM still provides higher bandwidth than NVM,which prevents skewed read workloads from benefiting from a higher bandwidth of the DRAM and leads to sub-optimal performance for the system.In this paper,we propose RCache,a readintensive workload-aware page cache for NVM filesystems.Different from traditional caching mechanisms where all reads go through DRAM,RCache uses a tiered page cache design,including assigning DRAM and NVM to hot and cold data separately,and reading data from both sides.To avoid copying data to DRAM in a critical path,RCache migrates data from NVM to DRAM in a background thread.Ad‐ditionally,RCache manages data in DRAM in a lock-free manner for better latency and scalability.Evaluations on Intel Optane Data Cen‐ter (DC) Persistent Memory Modules show that,compared with NOVA,RCache achieves 3 times higher bandwidth for read-intensive work‐loads and introduces little performance loss for write operations.
Keywords: storage system;file system;persistent memory
1 Introduction
In 2019,Intel released the first commercially available non-volatile memory (NVM) device called Intel DC Op‐tane Persistent Memory[1].Compared with Dynamic Ran‐dom Access Memory (DRAM),byte-addressable nonvolatile memory provides comparable performance and similar interfaces (e.g.,Load∕Store) along with data persistence at the same time.Because of a unique combination of features,NVM has a great advantage of performance on storage systems and posts the urgent necessity of reforming the old architecture of storage systems.Refs.[2–11] re-architected the old storage systems to better accommodate NVM and significant perfor‐mance boost that endorsed these design choices.
Among these novel designs,bypassing the page cache in kernel space is a popular choice.The page cache in Linux is used to be an effective mechanism to shorten the performance gap between DRAM and block devices.Since NVM has a close performance to the DRAM,the page cache itself posts severe performance loss to the NVM filesystem,because the page cache introduces extra data copy at every file operation and leads to write amplification on NVM.Therefore,the legacy page cache in the Linux kernel has become a liability for the NVM system.For the above reasons,recent work sim‐ply deployed the DAX[12]technology to bypass the page cache entirely[12–17].With the DAX technology,NVM filesystems ac‐cess the address space of NVM directly,without the necessity of filling the page cache first,which reduces the latency of file‐system operations significantly.
However,although NVM achieves bandwidth and latency at the same order of magnitude as DRAM,DRAM still provides bandwidth several times higher than NVM and fairly lower la‐tency than NVM.Therefore,the DAX approach reduces extra data copy and achieves fast write performance at the cost of cached read,especially for read-intensive workloads[18–20].The page cache provides benefits for reading but has severe performance impacts on writing because of the extra data copy and write amplification.And the DAX approach is efficient for writing due to direct access to NVM but fails to utilize DRAM bandwidth for reading.Therefore,in order to utilize DRAM bandwidth and avoid extra data copy and write amplifications,the page cache should be redesigned to allow both direct ac‐cess and cached read.
In this paper,we propose RCache,a read-intensive workload-aware page cache for the NVM filesystem.RCache aims to provide fast read performance for read-intensive work‐loads and avoid introducing significant performance loss for write operations at the same time.To achieve this,RCache as‐signs DRAM and NVM to hot and cold data separately,and reads data from both sides.Our major contributions are sum‐marized as follows.
? We propose a read-intensive workload-aware page cache design for the NVM filesystem.RCache uses a tired page cache design,including reading hot data from DRAM and ac‐cessing cold data directly from NVM to utilize DRAM band‐width for reading and preserving fast write performance.In ad‐dition,RCache offloads data copy from NVM to DRAM and to a background thread,in order to remove a major setback of caching mechanism from the critical path.
? RCache introduces a hash-based page cache design to manage the page cache in a lock-free manner using atomic in‐structions for better scalability.
? We implement RCache and evaluate it on servers with In‐tel DC Persistent Memory Modules.Experimental results show that RCache effectively utilizes the bandwidth of DRAM with few performance cost to manage the page cache and outper‐forms the state-of-the-art DAX filesystem under readintensive workloads.
2 Background and Motivation
2.1 Non-Volatile Memory
Byte-addressable NVM technologies,including Phasechange Memory (PCM)[22–24],ReRAM,and Memristor[21],have been intensively studied in recent years.These NVMs provide comparable performance and a similar interface as the DRAM,while persisting data after power is off like block devices.Therefore,NVMs are promising candidates for pro‐viding persistent storage ability at the main memory level.Recently,Intel has released Optane DC Persistent Memory Modules (DCPMM)[1],which is the first commercially avail‐able persistent memory product.Currently,new products come in three capacities: 128 GB,256 GB,and 512 GB.Pre‐vious studies show that a single DCPMM provides band‐widths at 6.6 GB∕s and 2.3 GB∕s at most for read∕write.Note that these bandwidth have the same order of magnitudes com‐parable to the DRAM but is a lot lower than the DRAM[25].
2.2 Page Cache and DAX Filesystem
Page cache is an important component in a Linux kernel filesystem.In brief,the page cache consists of a bunch of pages in DRAM and the corresponding metadata structures.The page cache is only accessed by the operating system in the context of a filesystem call and acts as a transparent layer to user applications.For a write system call,the operating sys‐tem writes data on pages in the page cache,which cannot guar‐antee the persistence of the data.To guarantee the persistence of the data,the operating system needs to flush all data pages in the page cache to the storage devices,probably within an fsync system call.For a read system call,the operating system first reads data from the page cache;if not present,the operat‐ing system further reads data from the storage devices.Note that this may involve loading data into the page cache depend‐ing on the implementation.In the current implementation,the operating system maintains an individual radix tree for each opened file.
As for the DAX filesystem,note that the page cache is ex‐tremely useful for block devices with much higher access la‐tency than DRAM,but not suitable for the NVM devices with comparable access latency to DRAM.As mentioned before,to ensure data persistence,the user must issue an fsync system call after a write system call.This brings substantial access la‐tency to persisting data in an NVM filesystem.Therefore,the state-of-the-art NVM filesystems leverage the DAX technology to bypass the page cache entirely and achieve instant persis‐tence immediately when the write system call returns.In a DAX filesystem,read∕write system call does not access the page cache at all,instead,data are loaded∕stored from∕to the NVM respectively using a memory interface.The DAX tech‐nology reduces extra data copy and accomplishes lower-cost data persistence.
2.3 Issue of DAX and Page Cache
The performance of NVM is close to that of DRAM but not equal to it.We measure the read and write latency of two differ‐ent filesystems (NOVA[17]and EXT4[26]) representing two differ‐ent mechanisms (DAX and Page Cache).Fig.1(a) shows that the read latency of the DAX is much higher than the page cache (4 kB sequential read).Fig.1(b) shows that the write la‐tency of the DAX is much lower than the page cache (4 kB se‐quential write).
To sum up,the DAX technology prevents the read opera‐tions from benefiting a much higher bandwidth of DRAM in the NVM filesystem,and the presence of the page cache sig‐nificantly increases the latency of write operations with imme‐diate data persistence.To overcome this,the page cache mechanism needs to be redesigned.
3 Rcache Design
3.1 Overview
We build RCache for servers with non-volatile memory to accelerate read-intensive workloads.In order to benefit from the DRAM bandwidth for read operations but not to induce no‐table latency for data persistence,we build RCache,a readintensive workload-aware page cache for the NVM filesystem.
1) RCache assigns DRAM and NVM to hot and cold data separately,and allows cached read and direct read from NVM to coexist.Furthermore,RCache offloads data copy to a back‐ground thread to alleviate the pressure of the critical path.
2) In addition,RCache deploys a lock-free page cache us‐ing hash-table to further reduce the performance cost of cache coherence management.
The architecture of RCache is described in Fig.2.RCache keeps an individual cache structure for each opened file.The page cache consists of a bunch of DRAM pages and a cache entry table containing a certain number of cache entries in the DRAM.A cache entry represents a DRAM page.It carries necessary information for RCache to manage the cache and navigate data given a logical block number.As shown in Fig.3,a cache entry carries a validation flag to indicate the status of this cache entry,a timestamp for the least recently used (LRU) algorithm,a Blocknr to indicate the logical block num‐ber that the entry represents,a DRAM page that is a pointer points to the actual cache page in DRAM,and an NVM page that is a pointer points to the actual data page in NVM.
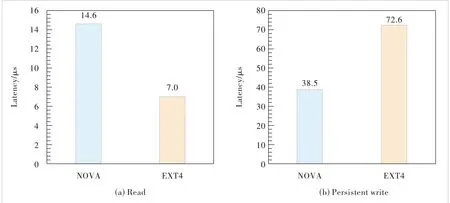
▲Figure 1.Performance comparison between different hardware and different filesystem settings
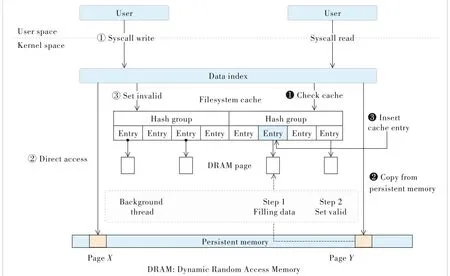
▲Figure 2.RCache architecture
3.2 Tiered Page Cache Design
As shown in Fig.2,the page cache is accessed in two con‐texts: a read∕write system call and a background thread.
For a read operation,the operating system accesses the page cache first.If the data required by the user are present and valid in the page cache,the operating system copies data directly from the cached page in the DRAM to the user’s buf‐fer;if a cache miss happens,the operating system falls back to the legacy procedure where the operating system reads data di‐rectly from the NVM and inserts the newly read data to the page cache.For cache insertion,since reading all the data blocks into the page cache introduces extra data copy and then leads to higher latency,RCache only inserts a small cache entry carrying a pointer to the physical block to the page cache instead of the actual data blocks.
For a write operation,the operat‐ing system needs to invalidate all cached pages affected by this write operation before returned to users.We further explain why the invali‐dation procedure is light weight in Section 3.3.
RCache depends on a back‐ground kernel thread to finish the management of the cache.As de‐scribed above,in the read operation,RCache only inserts cache entries to the page cache.In the context back‐ground thread,once a pending cache entry is discovered,RCache first allocates a DRAM page to cache data,and then copies data from the NVM block to the DRAM page according to the cache entry.At last,RCache declares the validity of the cache entry by switching the validation flag atomically.Note that only when RCache updates the vali‐dation flag in the cache entry to vali‐dation,the cache entry is available for read∕write context.
3.3 Lock-Free Cache Management
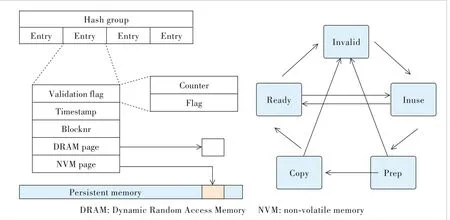
▲Figure 3.Cache structure and status shifting paradigm
The decoupled cache mechanism splits the cache management into two separating and concurrent con‐texts,which makes coordinating across all units more expensive since it leads to more cross-core communications.Therefore,RCache deploys a lock-free cache management procedure to minimize the impact.First,RCache operates cache entries by manipu‐lating the validation flag atomicity using Compare-and-Swap (CAS) instructions.In the current implementation,a cache en‐try switches among five states using the Compare-and-Swap in‐struction.Fig.3 depicts the transition diagram among these five states.At the initial point,all cache entries are invalid.To insert a cache entry,RCache first acquires control of a can‐didate entry by setting the validation flag of this entry to “In use” atomically using CAS,which prevents other threads from operating on this entry.Then,RCache fills necessary informa‐tion (e.g.the block number and the NVM page pointer) and changes the status to “Prep”,which tells the background thread that this entry has all information needed and is ready for data copy.From the background thread view,before copy‐ing data from persistent memory to DRAM,the background thread first sets the status of a cache entry to “Copy”,then the background thread initiates a data copy procedure.When the data copy completes,the background thread sets the status of a cache entry to “Ready” by using CAS instruction operating on the validation flag,and,only at this point,the cache is available for read operations.To write data into a certain page,if cache hits,RCache needs to invalidate the cache entry rep‐resenting this page by switching the status to“Invalid” by CAS,and the validation flag of the entry to “Invalid”.Note that RCache never invalidates an “In use” cache entry,be‐cause the “In use” status only exists in the context of a read syscall.Since the file is locked up in write operations,this situation never happens.To read data from a cache entry,RCache first switches the status from “Ready” to “In use” us‐ing CAS,then copies data from the DRAM page to user buffer,and at last,changes the status back to “Ready”.However,this leads to an inconsistent status where users might be given wrong data,since there might be several threads reading data from the cache entry concurrently.Therefore,RCache incar‐nates an additional counter in the validation flag,when a reader wants to read this cache,it must increase this counter;and when a reader finishes reading,it must decrease the counter.Therefore,only the last reader can switch the status back to “Ready”.
3.4 Implementation
We implement RCache on NOVA,a state-of-the-art NVM filesystem devel‐oped with the DAX technology.We keep the metadata and data layout in NOVA in‐tact,and add extra logic for managing the cache in the context of read∕write proce‐dure.We launch the background thread in kernel at the mount phase,and reclaim this thread during the unmount phase.To tackle the hotness of a block,we extend the block index in NOVA,and add an extra counter to each leaf node of the radix tree.We insert a block into the cache only when it is accessed more times than a threshold in a time window.The threshold and the time window are predefined.
4 Evaluation
In this section,we first evaluate RCache’s read∕write la‐tency,then we evaluate the read performance under readintensive workload,and at last,we evaluate the read perfor‐mance under a skewed read-intensive workload.
4.1 Experimental Setup
We implement RCache and evaluate the performance of RCache on the server with Intel Optane DCPMM.The server has 192 GB DRAM and two Intel Xeon Gold 6 240 M proces‐sors (2.6 GHz,36 cores per processor) and 1 536 GB Intel Op‐tane DC Persistent Memory Modules (6×256 GB).Because cross-non-uniform memory access (NUMA) traffic has a huge impact on performance[27],throughout the entire evaluation,we only utilize NVMs on one NUMA node to deploy RCache and other file systems (e.g.,only 768 GB NVMs on this server).The server is running Ubuntu18.04 with Linux Kernel 4.15.
Table 1 lists file systems for comparison.We build all file‐systems on the same NVM device with a PMem driver.For EXT4,we build it following the traditional procedure with a page cache involved.For both NOVA and RCache,since RCache shares most of the filesystem routines with NOVA,we deploy both of them on an NVM device with a PMem driver and DAX enabled.
For a latency test,we use custom micro benchmarks and Fx‐mark[28]for bandwidth evaluation.Fxmark is a benchmark de‐signed to evaluate the scalabil‐ity of file systems.In this evaluation,we use three subbenchmarks,namely DRBL,DRBM and DWAL,in Fxmark.

▼Table 1.Evaluated file systems
4.2 Overall Performance
To evaluate the read∕write performance,we use a custom micro-benchmark.All evalua‐tion on each filesystem spawns only one thread.We first create a file with 64 MB,then issue 4 kB read∕write data with 100 000 requests,and finally calcu‐late the average latency.Since EXT4 does not ensure data per‐sistency in the write system call,we issue another fsync af‐ter each write system call to preserve data persistency.Fig.4 shows the read∕write latency for three evaluated filesystems.
For read operations,EXT4 shows the lowest latency,and the latency of RCache is close to that of EXT4 and much lower than that of NOVA.This is because RCache utilizes the DRAM bandwidth to acceler‐ate read.
To evaluate the read band‐width under a read-intensive workload,we use sub-benchmark DRBL from Fxmark.DRBL first creates a 64 MB file for each thread and then issues se‐quence read operation to the filesystem.We conduct the evalua‐tion for 20 s.If a read operation reaches the tail of the file,the next read operation is set at the beginning of the file.From Fig.5(a) we can see that the RCache shows much better read perfor‐mance than NOVA and close to that of EXT4.
4.3 Read Performance Under Skewness
We evaluate the read performance under the skewed work‐load.We modify the DRBL benchmark instead of reading files sequentially,where each thread post-read request at an offset is controlled by a random variable that follows the normal dis‐tribution.Fig.5(b) shows that,both EXT4 and RCache achieve even better performance than that in Fig.5(a).This is because under the skewed workload,the hot pages are more likely to be stored in the L3 cache and therefore end up with better performance.On the other hand,since NOVA does not utilize DRAM for better read performance,the read bandwidth achieved is much lower than that of EXT4 or RCache.
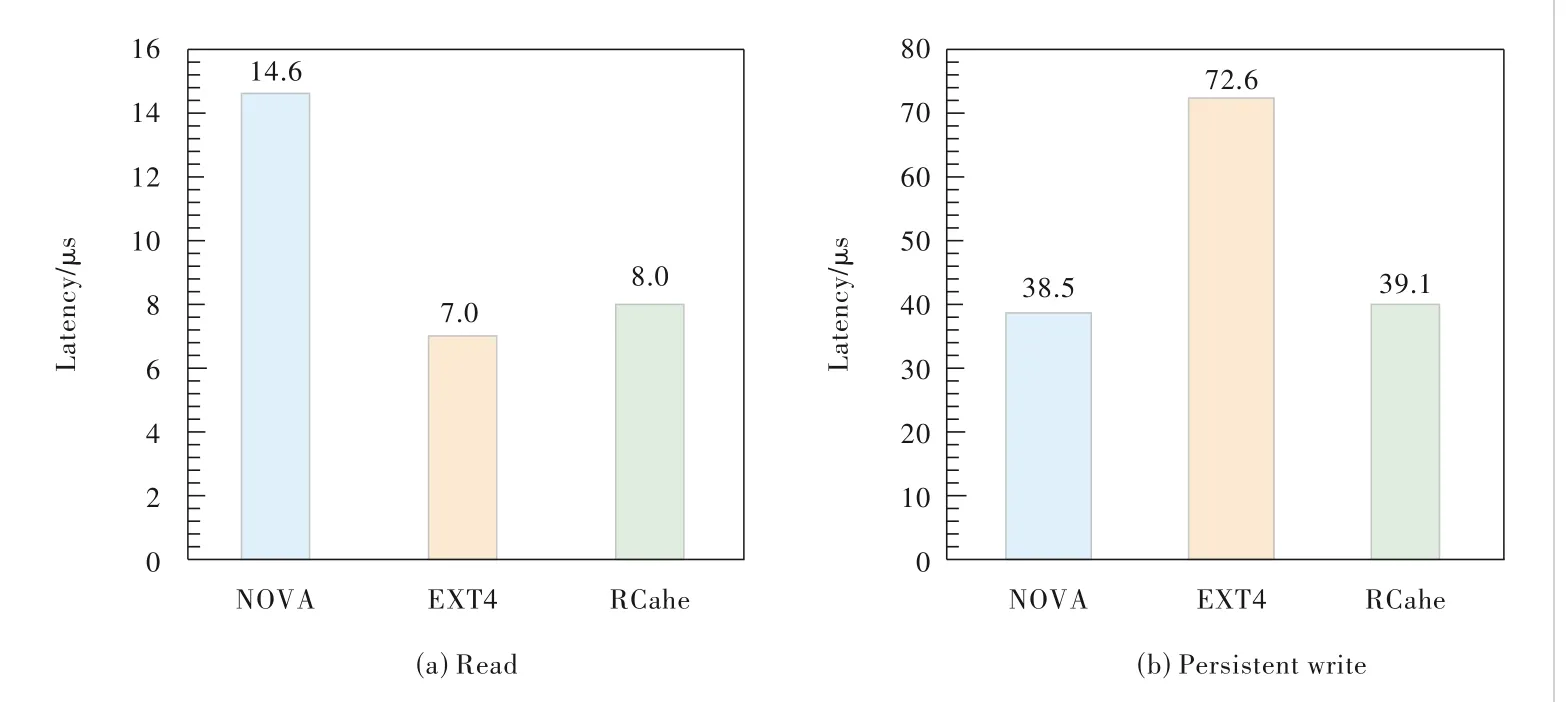
▲Figure 4.Read and write latency of different filesystems
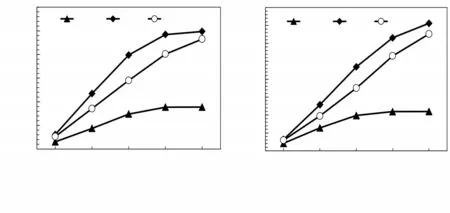
▲Figure 5.Read bandwidth under the read-intensive workload of different filesystems
5 Conclusions
Traditional page cache in the Linux kernel can benefit read workload but cannot fit into an NVM filesystem because it causes extra data copy and write amplification.By bypassing the page cache,the DAX filesystem achieves better write per‐formance but gives up the opportunity of cached read.There‐fore,in this paper,we propose a read-intensive workloadaware page cache for NVM filesystems.RCache uses a tiered page cache design,including assigning DRAM and NVM to hot and cold data separately,and reading data from both sides.Therefore,cached read and direct access can coexist.In addition,to avoid copying data to DRAM in a critical path,RCache migrates data from NVM to DRAM in a background thread.Furthermore,RCache manages data in DRAM in a lock-free manner for better latency and scalability.Evalua‐tions on Intel Optane DC Persistent Memory Modules show that compared with NOVA,RCache has 3 times higher band‐width for read-intensive workloads and introduces little perfor‐mance loss to write operations.

- ZTE Communications的其它文章
- Special Topic on Federated Learning over Wireless Networks
- Scene Visual Perception and AR Navigation Applications
- Adaptive Load Balancing for Parameter Servers in Distributed Machine Learning over Heterogeneous Networks
- Ultra-Lightweight Face Animation Method for Ultra-Low Bitrate Video Conferencing
- Efficient Bandwidth Allocation and Computation Configuration in Industrial IoT
- Secure Federated Learning over Wireless Communication Networks with Model Compression