上市公司財務舞弊預測因子定量評估算法
2023-05-06 23:26:24張熠劉天祥黃遠健
會計之友 2023年10期
張熠 劉天祥 黃遠健
【摘 要】 隨著股票發行注冊制的全面實施,如何對上市公司財務舞弊行為進行有效的定性或定量預測及判斷,成為監管機構、金融機構及相關領域學者關注的重點和研究難點。文章通過構建舞弊影響因子向量,引入關系矩陣,創造性地將上市公司財務舞弊預測因子定量評估問題轉化為關聯矩陣迭代計算問題,實現財務舞弊預測因子定量評估。首次實現財務舞弊行為預測與財務報告分離,并基于關聯矩陣實現可追溯且確定性的預測,為前置監管和精準監管提供理論和應用支撐。基于經驗對該算法有效性進行實證,為其在相關領域的應用提供直接支撐。
【關鍵詞】 關系矩陣; 財務舞弊; 定量評估; 上市公司
【中圖分類號】 F275;F239.1? 【文獻標識碼】 A? 【文章編號】 1004-5937(2023)10-0117-07
一、引言
財務舞弊是指企業主體在開展對外財務披露過程中,存在因主客觀因素導致重大誤導性財務報告,并對第三方決策判斷產生實質性影響的行為。宏觀層面看,財務舞弊的影響不限于干擾金融市場正常活動秩序,更會深層次通過影響社會資源非理性流動影響整體金融市場的健康發展。財務舞弊,特別是涉及一、二級市場主體(即上市公司)的財務舞弊,能夠通過金融市場迅速蔓延到整個資本市場,其影響范圍和影響深度要遠大于一般性的企業經營失利或決策失誤。
黨的二十大報告指出,加強和完善現代金融監管,強化金融穩定保障體系,依法將各類金融活動全部納入監管,守住不發生系統性風險底線。財政部在《關于加大審計重點領域關注力度控制審計風險進一步有效識別財務舞弊的通知》中明確,要嚴格執行審計準則,提高應對財務舞弊的執業能力。隨著股票發行注冊制的全面實施,如何對上市公司財務舞弊行為進行有效的定性或定量預測及判斷成為業界關注的重點。
隨著人工智能和大數據等相關領域的發展與成熟,基于大數據挖掘技術和人工智能的財務舞弊識別成為學術界研究的重點和具有發展潛力的方向。大數據挖掘技術方面,Lin等[ 1 ]利用數據挖掘技術對財務狀態信息和公共信息進行評估,并形成一系列涉及垂直領域的財務舞弊判定方法。Goel等[ 2 ]提出了一種新的年度報告定性分析方法,其使用自然語言處理技術確定報告中所表達的情感,并以此為基礎進行欺詐檢測與預測,研究結果表明報告所表達出的積極和消極情緒與欺詐存在明顯的關聯性。Kogan等[ 3 ]認為對完整數據的持續審計是有意義的,并提出一種連續數據級審計系統的框架。Alles等[ 4 ]指出財務報表審計使用大數據存在的問題,并提出一系列改進措施。張英明和徐晨[ 5 ]以2010—2019年滬深A股上市公司為樣本,從社會責任視角分析了高管團隊特征對財務舞弊風險的影響,研究結果表明,在社會責任的調節下,高管團隊特征對財務舞弊風險的影響呈現門檻效應。目前該類研究最大的難題在于高質量的數據分級分類和具備普適性的專家模型的獲取。同時此類方法本質上屬于狀態審計,無法對關聯財務舞弊進行有效識別。針對人工智能方面的研究更注重人工智能算法的應用,整體思路是通過對特定財務狀態或狀態集分析和模型訓練,獲取有限特征指標,并以此為基礎進行財務舞弊判斷。余玉苗和呂凡[ 6 ]從發生財務舞弊公司前一年與舞弊當年的財務指標動態增量信息視角入手,建立邏輯回歸模型,研究發現固定資產增長率、經營現金流量和流動負債比率等五個財務指標的變動對財務舞弊產生重要影響。金花妍和劉永澤[ 7 ]基于舞弊三角理論構建了舞弊識別模型,研究結果表明,財務穩定性越差、監督部門的監督積極性越低、曾經獲得非標準審計意見次數越多,公司發生財務舞弊的可能性越高。姚宏和佟飛[ 8 ]基于層次分析法建立上市公司盈余質量評價四維模型,研究結果表明,該模型將戰略管理與價值管理相結合,能夠揭示上市公司在價值增長過程中的真實性、穩定性、可持續性、風險性等內在特征。Ravisankar等[ 9 ]基于多層前饋神經網絡、支持向量機等人工智能技術進行財務報表欺詐識別,并對各算法的精度和特征進行分析。Maria等[ 10 ]研究提出基于機器學習算法的會計欺詐檢測優化機制,并通過評估相關財務指標進一步協助風險較高的企業進行內審。趙納暉和張天洋[ 11 ]通過實證研究對比了深度學習模型和以往常用的淺層模型在檢測財務報告舞弊時的性能,結果表明,在規模對等的舞弊和非舞弊類財務報告組成的文本數據集上,深度學習模型表現出明顯優于基準模型的分類性能。高燕等[ 12 ]以A股制造企業為樣本,構建BP神經網絡模型用于財務風險預警。該類研究最大的困境在于結果的可解釋性有待提高,對宏觀財務舞弊和關聯財務舞弊的識別效能較為有限以及研究成果難以沉淀共享。
基于關聯矩陣的研究思路是將目標場景中個體之間的關聯關系視為一種“投票”并將其轉化為矩陣,然后通過與個體狀態向量的迭代計算來實現重要節點識別。不難理解,通過關聯矩陣及其迭代計算,基于關聯矩陣的算法框架能夠將狀態問題轉變為過程問題,能夠對過程問題、路徑問題及宏觀態勢等進行更好的描述。結合財務舞弊識別研究碰到的困難,可以看到基于關聯矩陣的財務舞弊研究將是一個非常有前景的方向。Chakrabarti等[ 13 ]首次提出可以將關聯矩陣應用于金融舞弊識別,但并未就相關細節進行研究和描述。Romero等[ 14 ]進一步拓展了關聯矩陣應用領域,重點針對壓力情況下的社會網絡行為進行深入探討,為基于關聯矩陣的財務舞弊識別研究提供了理論雛形。目前基于關聯矩陣的財務舞弊識別研究還沒有形成較為系統的理論框架和技術體系,究其原因包括:(1)環境因子的選擇沒有普適標準,通常認為參與迭代的記錄數需達到8 000萬條及以上,小規模數據體量無法保障迭代效果;(2)場景迭代算法有效性無法保證。
基于上述問題,本文首先構建財務舞弊影響因子向量,從財務舞弊事件維度出發,對各影響因子實際發生情況進行分類和歸并處理。其次基于同一財務舞弊事件中影響因子之間的關聯關系構建財務舞弊預測因子關系矩陣,建立財務舞弊預測因子(如經營虧損、問詢、關注和監管措施等)時序影響關系,再借助關系矩陣迭代計算,實現財務舞弊過程快速預測,進而創造性地將上市公司財務舞弊預測因子定量評估問題轉化為關聯矩陣迭代計算問題,實現財務舞弊預測因子定量評估。在此基礎上,本文針對迭代過程涉及的因子向量初始化、算法收斂性、中止條件選擇等進行深入分析。最后以2018—2020年已公開披露的財務舞弊事件為對象,對算法有效性進行驗證。
二、關聯矩陣舞弊預測因子構建
作為金融市場中最活躍的參與者,上市公司經營活動與經營狀態一直是監管部門和投資者關注的焦點,并已經實現高度市場化運作。金融市場中,各上市公司最主要的目標是獲得比間接融資更低的融資成本來支撐企業發展,在全市場分享其發展收益的同時,也讓全市場分擔其發展過程中的各種風險。上市公司應根據《上市公司信息披露管理辦法》真實、準確、完整、及時地披露信息,不得有虛假記載、誤導性陳述或者重大遺漏,并應當同時向所有投資者公開披露信息。在良性市場發展過程中,企業應與投資者保持真實、準確、完整、及時的溝通。但在實際執行過程中,上市公司因各種內外部因素,會有目的性地進行虛假報送、偏向披露、延時披露等不合規操作,以期從金融市場中獲取與其市場表現不一致的市場價值預估。換言之,某一個財務舞弊事件,本質上是公司實際經營狀態與市場預期不一致的體現,是企業為獲得不當市場收益而采取的一種不合規、被動操作。鑒于上市公司的關注度普遍較高,這種不合規操作會前置性地通過各種監管渠道、新聞媒體、官方通告等有所體現,如高管離職、行政處罰、宏觀政策變化等,這通常也是“做空”機構尋求收益的立足點。
綜上不難理解,上市公司價值是金融市場持續迭代評估過程中的一個特定時間和群體的鏡像,在任一時點獲得的市場評價都是整個金融市場對其歷史表現并與同期其他上市公司綜合表現的一個相對值。因此,可以有如下假設:(1)某一個財務舞弊事件,本質上是公司某一段時間內經營活動與經營狀態的集中和被動體現;(2)部分經營活動與經營狀態的發生會以更高概率預示上市公司進行財務舞弊,如經營虧損;(3)部分經營活動與經營狀態之間存在關聯關系,且同時出現時會以更高概率預示上市公司進行財務舞弊,如監管措施和重大人事變動。基于此,為了更直觀地對本文算法進行描述,提出如下定義:
定義1 財務舞弊影響因子關聯關系可以用二元組表示為D(S,R)。其中S={s1,s2,…,sn}是財務舞弊影響因子向量,n為影響因子數量;R表示各影響因子之間的關聯關系,R=(Rij) ,1≤i,j≤n,且有:
Rij=∑si?圮sj si和sj同時出現次數的累加? 0? ? ? ?否則 (1)
值得注意的是,此處關聯關系是一種由源節點指向目標節點的“認可”關系,且矩陣元素值是針對當前財務舞弊影響因子集合S而言,并非所有財務舞弊影響因子集。
定義2 財務舞弊影響因子權重出入度函數是指所有“認可”某影響因子的關聯關系和,記為DegR,且有:
DegR(si)=∑jRij? ? (2)
在上市公司經營過程中,DegR可以進一步分為DegIR和DegOR兩個函數,前者用于描述潛在影響當前因子的函數和(即入度函數),后者用于描述潛在受當前因子影響的因子函數和(即出度函數)。
定義3 財務舞弊影響因子關聯矩陣是指用于描述所有財務舞弊影響因子關聯關系的矩陣,記為T,且有:
Tij=? DegR(si)>0,1≤i,j≤n? ?0? ? ? ?否則 (3)
考慮到影響因子本身的相對獨立性,本文綜合算法復雜度和算法有效性選擇線性函數作為分布函數,即 ,表明該影響因子在進行影響權重向下傳導時,每個潛在受影響因子所獲取權重比例的分布。Rij越大,si能夠傳導到sj的影響力比例也越大,反之亦然。
定義4 財務舞弊影響因子權重向量是指以每個影響因子的影響權重作為元素值的向量,記為w(S)=[w(s1),w(s2),…,w(sn)]T,w(si)≥0,1≤i≤n,n為影響因子數量。與影響因子關聯矩陣和出入度函數不同,因子權重向量表征某一時點該影響因子的實際影響力,值越大,表明其影響力越大,反之亦然。
(一)關聯矩陣算法
與現有研究不同,本文強調各影響因子之間以關聯關系為基礎建立的相互“認可”關系,并以此作為權重計算的基礎。在每次迭代過程中,每個影響因子會基于“認可”關系將自身權重以歸一化方式公平地傳導到下游影響因子,并以同樣方式從“認可”它的上游影響因子獲取權重。
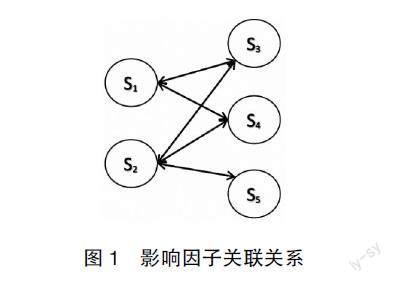
如圖1所示,s3、s4是s1的“認可”影響因子,s3、s4、s5是s2的“認可”影響因子,s1、s2是s3和s4的“認可”影響因子,s2是s5的“認可”影響因子,故各影響因子的權重計算如下:
w(s1)= w(s3)+ w(s4)
w(s2)= w(s3)+ w(s4)+w(s5)
w(s3)= w(s1)+ w(s2)
w(s4)= w(s1)+ w(s2)
w(s5)= w(s2)
進一步,在普適意義上,對于任一個w(S),第k步迭代權重向量為w(S) ,則有:
w(sj) = =∑iTij*w(si)
(4)
故進一步推導,有:
w(s) =TT*w(s)? ? (5)
根據公式(5)可知,對于任一次迭代操作,所有節點會基于關聯矩陣T轉置實現其他節點對自身“認可”的權重匯總,并將自身的“認可”投票傳遞給其認可的節點。在理想情況下,基于公式(3)的歸一化處理和關聯矩陣轉置,公式(5)會在全局層面保持所有節點之間的權重順利流動。
關于初始向量w(s) ,在理論層面上可以選擇權重向量值不同時為0且非負的任意向量作為初始值,如w(s) =( )T 1*n。值得注意的是,不同選擇結果僅影響迭代次數,并不影響最終權重向量計算結果,且當初始向量的權重分布與最終權重向量分布越靠近時,所需要迭代次數越少,反之亦然。每次迭代本質是權重在全局范圍內的一次優化并確保優化后的結果更符合其實際權重,因此當迭代進行到一定階段后,任意連續兩次迭代權重向量之間的一次范數會趨于收斂,即算法會趨于收斂。在實際操作過程中,可結合業務訴求設定目標精度作為算法中止條件,即有:
w'(s) -w'(s) <?啄? ? (6)
其中,?啄為某一大于0的常數,其具體選擇與目標場景對識別精度和效率的訴求相關。通常,?啄越小,精度越高,且所需迭代次數越多,反之亦然。針對金融市場而言,常規研究對象均在10 000個以內,常規服務器均可以實現準實時計算,即無需關注初始向量的分布選擇。但針對一級市場投融資研究而言,考慮到潛在涉及主體數量較大,如極端情況下應覆蓋約6 000萬的國內工商注冊企業,可選擇如下三個方案來減少迭代次數以獲取更高的性能:(1)在均分權重基礎上,提升顯性高權重節點的權重占比。(2)在均分權重基礎上,進行非關聯關系發生次數統計分析,并基于統計結果構建各節點初始權重向量。(3)提前進行粗收斂精度預計算,并基于預計算結果構建各節點的初始權重向量。
(二)預測因子構建
如前文所述,關聯矩陣T的主要作用是構建各影響因子之間的關聯關系,并基于公式(5)實現所有影響因子之間的權重順利流轉。因此,為了確保權限的充分、公平分配,需確保所有影響因子之間的“認可”關系是直接的或有限步可達的。但實際應用過程中,特別是“孤立”影響因子和影響因子群的存在,會造成影響因子權重無法全局順利流動,進而導致計算失敗。據不完全統計,以2018年1月1日至2020年12月31日時間段內公開披露的數據為例,由監管機構發布的財務舞弊事件共1 918次,影響因子類別共100類,其中安全生產異常和擔保變更風險兩個影響因子實際發生次數僅為1次,實際發生次數低于100的影響因子數量有43個。
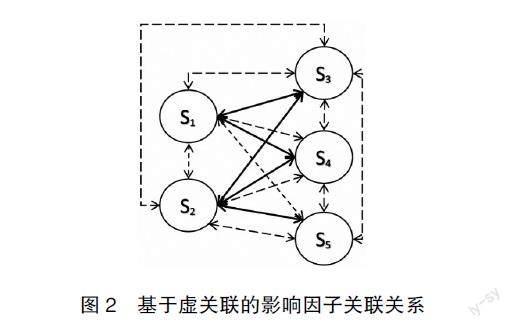
出現“孤立”影響因子和影響因子群的根本原因在于個別或部分影響因子與其他影響因子關聯太少或沒有,形成若干個只能“獨立認可”的影響因子和“內部認可”的影響因子群,造成權重向量無法通過關聯矩陣實現全局范圍內的順利流動。為了解決該問題,本文引入了“虛關聯關系”。相對于圖1所示的實關聯關系,虛關聯關系(如圖2所示)本身并不存在,僅是確保影響因子權重順利流轉的輔助手段。通過對2018年1月1日至2020年12月31日時間段內公開披露數據的分析,按發生次數自高到低,影響因子發生次數的四分之三分位數是39,有10%的影響因子實際發生次數低于10。基于此,在不影響整體權重分布的情況下,將虛關聯矩陣r構造為:
r=( )n*n,1≤i,j≤n? (7)
設d為權重調節因子并用于分配實關聯和虛關聯在實際迭代過程中的權重占比,即公式(3)和公式(5)調整如下:
T'=d*T+(1-d)*r? ? (8)
w(s) =(T')T*w(s)? ? ?(9)
不難看出,通過r構建了所有影響因子之間的虛關聯,同時考慮到其權重分配值遠小于實關聯分配值,且可以通過調整d來實現權重再分配,其對最終權重結果分布的影響可控。針對d值選擇,暫無可執行的標準或規范,在執行層面更多依據算法設計者的經驗,但通常在0.85及以上。在實際應用過程中,d值選擇通常考慮如下因素:(1)目標場景對各節點之間的權重區分度要求。通常區分度要求越高,d值應越大,如一級市場投資機會挖掘;反之亦然,如宏觀面分析研究。(2)初始化r時,虛關聯和實關聯之間的相對大小。通常相對大小越小,d值需越大,反之亦然。
(三)結果分析
為了進一步對算法有效性進行驗證,本文以國內上市公司在2018年1月1日至2020年12月31日時間段內公開披露的數據為分析對象,對算法的收斂性、穩定性及精度選擇影響等進行分析。在數據預處理方面,預先進行了剔除財務舞弊撤銷和非財務舞弊事件記錄、同篇報道影響因子分離以及基于事件的影響因子歸集等操作,同時參考財報季度發布機制,選擇以財務舞弊事件為基線向前倒推90個自然日作為影響因子統計范圍。
測試數據和場景數據如下:(1)發布主體覆蓋中國證監會、上海證券交易所、深圳證券交易所及各地方證監局等124家監管及從屬機構,財務舞弊事件共發布1 918條,涉及主體952家;(2)以財務舞弊事件發生時間為基線向前倒推90個自然日,針對各上市公司公開發布的負面新聞共有583 163次,影響因子涉及監管措施、經營虧損、證券價格異動等100類;(3)考慮到財務舞弊偏于宏觀預測,且虛關系為實關系的1/n(搜索引擎類應用通常為倒數平方或更小)相對較大,設置權重調節因子d為0.85。
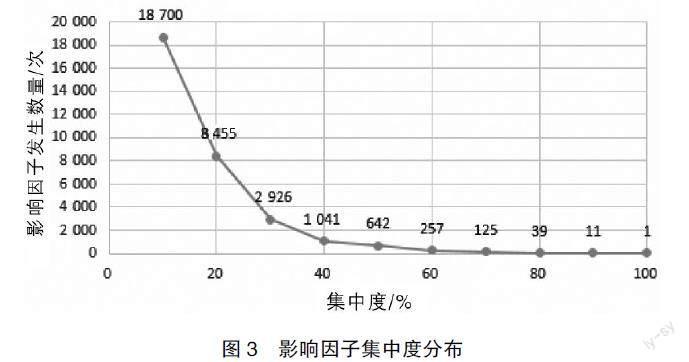
1.影響因子集中度分布
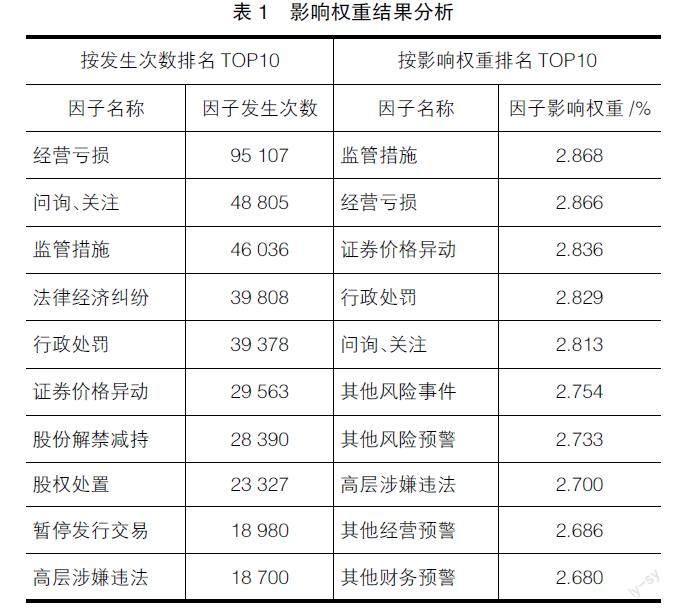
影響因子集中度分布如圖3所示,披露數據集中度10%的值為18 700次(前10名影響因子發生次數總占比為66.55%),集中度20%的值為8 455次(前20名影響因子發生次數總占比為86.78%),同時可以看出不同影響因子之間存在明顯的簇群效應。如表1所示,針對所有發生財務舞弊事件的上市公司,在所有公開披露的負面新聞中,披露次數最多的是“經營虧損”且共計發生95 107次。影響因子的權重按發生次數的統計結果與算法執行結果并不一致。以“經營虧損”為例,實際發生次數約為“問詢、關注”的兩倍,且就發生次數來看兩者分別排名第一和第二,但從權重來看“監管措施”排名第一,從領域常識而言算法執行結果更合理。
2.算法穩定性和收斂性分析
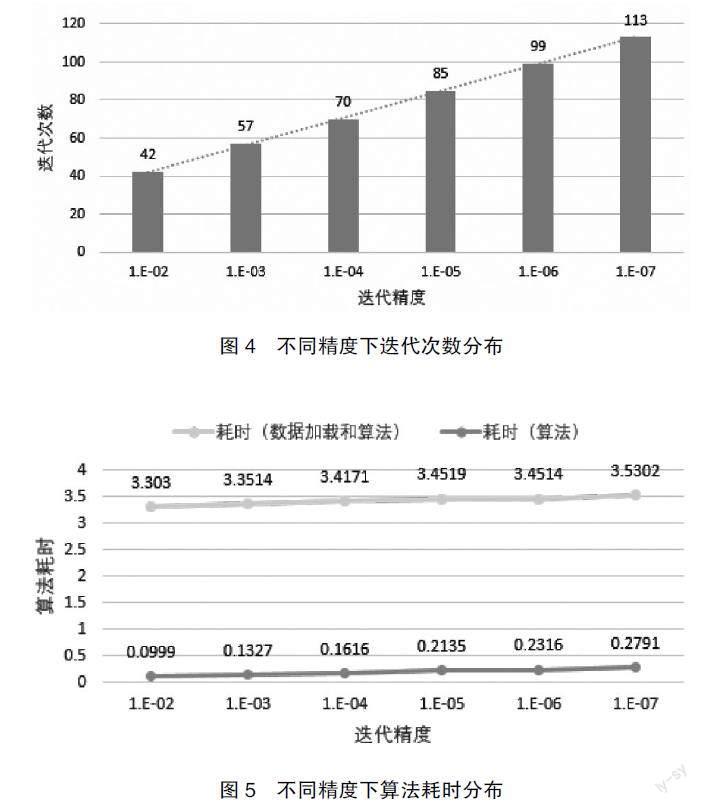
如圖4所示,在各迭代精度下,算法均可以實現快速收斂,且迭代精度位數與到達穩定所需求的迭代次數之間整體維持準線性穩定狀態,如在1.E-02時需迭代42次,1.E-04時需迭代70次,在1.E-07時則需迭代113次,這也進一步證明了本文算法的穩定性。同時考慮到迭代過程并未對關聯矩陣進行諸如稀疏轉換等處理,且虛關聯關系屬于全連接關系,因此在關聯關系類別確定情況下,算法收斂特征和穩定性與目標場景中的關聯關系數量無關。換言之,算法穩定性和收斂性對目標場景特征是透明的。
3.算法耗時分布
如圖5所示,在各迭代精度下,算法均能夠快速且穩定的完成迭代計算。在考慮數據加載耗時情況下,算法執行時長整體分布在4秒以內,且變化幅度控制在2.5%以內,因此,針對上市公司財務舞弊預測,算法可用于不同調節因子的多場景準實時分析;若采取數據預加載,雖然耗時變化幅度在8%~33%之間,但整體分布在0.3秒以內,即算法可用于量化交易、動態監管等實時應用場景。
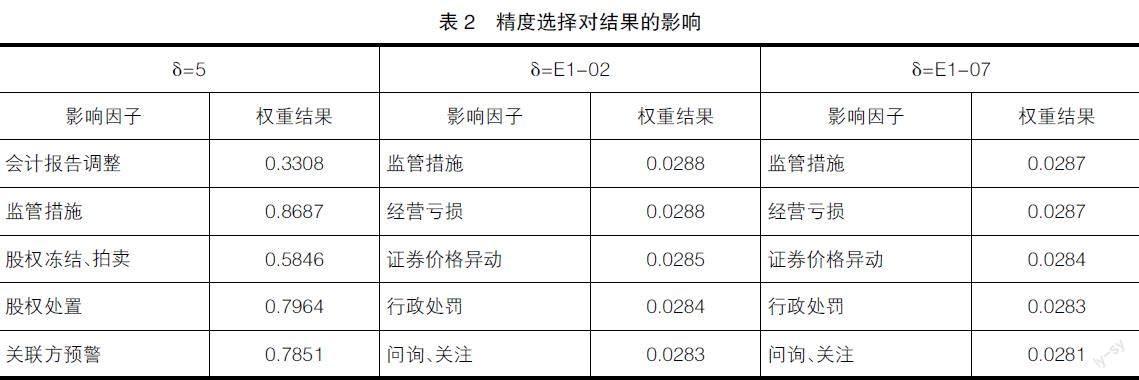
4.精度選擇分析
如表2所示,在精度比較弱時,算法執行結果呈現較大的波動性,且僅在到達一定精度后,算法執行結果的排序才會呈現穩定狀態。因此,在實際應用過程中,通常需要預設多個精度區間,并通過逐步提升精度的策略進行精度區間測試直至執行結果排序達到穩定狀態。針對最終迭代精度,可在選定精度區間后才結合場景訴求進行合理選擇。
綜上可知:(1)在實施應用層面,上市公司財務舞弊預測主要因子應為監管措施、經營虧損、證券價格異動、行政處罰、問詢關注。在開展上市公司財務舞弊預測時,應重點關注涉及此類因子的負面新聞。(2)在進行具體公司財務舞弊監控時,可通過同業公司、產業鏈上下游公司、歸屬行業等維度形成場景數據,進而實現更具針對性的預測,并在決策過程中引入算法實現投資機會高效捕捉。
三、結論和展望
本文在分析現有上市公司財務舞弊預測研究內容的基礎上,創造性地引入關系矩陣,并將上市公司財務舞弊預測因子定量評估問題轉化為關聯矩陣迭代計算問題,實現財務舞弊預測因子定量評估。同時本文對算法應用過程中涉及的權重向量初始化、算法收斂性、中止條件選擇等進行探索,并以2018年到2020年實際公開披露數據為分析對象,對算法有效性、穩定性進行驗證。
與現有研究相比,本文創新點包括:(1)實現財務舞弊行為預測與財務報告分離,將市場面金融活動全部納入監控,并支持動態擴展和準實時計算;(2)基于關聯矩陣實現可追溯、確定性、量化預測,并結合應用需求持續提升計算精度,在保證算法公正、公平的同時,兼顧算法的穩定性和執行效率,為前置監管和精準監管提供理論及應用支撐;(3)借助關系矩陣的透明擴展性,可快速進行新預測因子的判別和影響分析,進而為財務舞弊預測體系的豐富和完善提供有力工具。值得強調的是,影響舞弊的主要自變量應為企業經營狀態和企業自身對市場估值的期望,但在既有文獻中,針對自變量的研究集中于事后反向推演,即通過預測因子來獲取自變量狀態和趨勢。換言之,本文中的預測因子向量亦可用于舞弊自變量的描述。
后續工作中,筆者將重點研究中止條件智能選擇和大規模影響因子場景下的關聯矩陣分割等問題,以進一步降低算法空間復雜度,提高權重計算精度及算法執行效率,進而提升算法普適性。
【參考文獻】
[1] LIN C C,CHIU A A,HUANG S Y,et al. Detecting the financial statement fraud:the analysis of the differences between data mining techniques and experts' judgments[J]. Knowledge-Based Systems,2015,89:459-470.
[2] GOEL S,UZUNER O.Do sentiments matter in fraud detection? Estimating semantic orientation of annual reports[J].Intelligent Systems in Accounting,Finance and Management,2016,23(3):215-239.
[3] KOGAN A,ALLES M G,VASARHELYI M A,et al.Design and evaluation of a continuous data level auditing system[J].Auditing:A Journal of Practice & Theory,2014,33(4):221-245.
[4] ALLES M,GRAY G L.Incorporating big data in audits:identifying inhibitors and a research agenda to address those inhibitors[J].International Journal of Accounting Information Systems,2016,22:44-59.
[5] 張英明,徐晨.高管團隊特征、社會責任意識與財務舞弊風險:基于A股上市公司的門檻效應檢驗[J].會計之友,2021(22):58-65.
[6] 余玉苗,呂凡.財務舞弊風險的識別:基于財務指標增量信息的研究視角[J].經濟評論,2010(4):124-130.
[7] 金花妍,劉永澤.基于舞弊三角理論的財務舞弊識別模型研究:支持向量機與Logistic回歸的耦合實證分析[J].大連理工大學學報(社會科學版),2014,35(1):92-97.
[8] 姚宏,佟飛.會計信息失真背景下的上市公司價值質量評價模型[J].大連理工大學學報(社會科學版),2011,32(2):32-37.
[9] RAVISANKAR P,RAVI V,RAO G R,et al. Detection of financial statement fraud and feature selection using data mining techniques[J].Decision Support Systems,2011,50(2):491-500.
[10] MARIA J,RICHARD G.Fighting accounting fraud through forensic data analytics[J].SSRN Electronic Journal,2018:1-39.
[11] 趙納暉,張天洋.基于MD&A文本和深度學習模型的財務報告舞弊識別[J].會計之友,2022(8):140-149.
[12] 高燕,杜玥,曾森.基于BP神經網絡的制造企業財務風險預警研究[J].會計之友,2023(1):62-70.
[13] CHAKRABARTI D,FALOUTSOS C.Graph mining:laws, tools, and case studies[J].Synthesis Lectures on Data Mining and Knowledge Discovery,2012,7(1):1-207.
[14] ROMERO D M,UZZI B,KLEINBERG J.Social networks under stress[C]//Proceedings of the 25th International Conference on World Wide Web,2016:9-20.
