融合注意力機(jī)制的網(wǎng)絡(luò)監(jiān)督細(xì)粒度識(shí)別
2023-04-29 09:53:10范九丹
信息系統(tǒng)工程 2023年7期
關(guān)鍵詞:深度學(xué)習(xí)
范九丹


摘要:在細(xì)粒度識(shí)別任務(wù)中,良好標(biāo)注的訓(xùn)練數(shù)據(jù)難于獲取,現(xiàn)有強(qiáng)注釋的數(shù)據(jù)集數(shù)量少,由于細(xì)粒度圖像背景復(fù)雜、子類別圖像差異細(xì)微等問(wèn)題,導(dǎo)致現(xiàn)有細(xì)粒度識(shí)別模型精度不高。為此,使用具有圖像級(jí)標(biāo)簽的免費(fèi)網(wǎng)絡(luò)圖像作為訓(xùn)練數(shù)據(jù),設(shè)計(jì)了一種融合注意力機(jī)制的網(wǎng)絡(luò)監(jiān)督細(xì)粒度識(shí)別模型。首先引入瓶頸注意力機(jī)制有效提高網(wǎng)絡(luò)的表征能力,準(zhǔn)確聚焦前景識(shí)別主體,減少了背景特征的影響。實(shí)驗(yàn)結(jié)果表明,提出的模型在Web-Bird(鳥(niǎo)類數(shù)據(jù)集)、Web-Cars(汽車數(shù)據(jù)集)、Web-Aircraft(飛機(jī)數(shù)據(jù)集)三個(gè)數(shù)據(jù)集上的ACA指標(biāo)分別達(dá)到82.8%、88.1%和83.1%,在同類型算法中處于領(lǐng)先水平。
關(guān)鍵詞:細(xì)粒度識(shí)別;注意力機(jī)制;深度學(xué)習(xí);殘差網(wǎng)絡(luò)
一、前言
細(xì)粒度圖像分類(Fine-grained image categorization)屬于圖像分類范疇[1],旨在對(duì)粗粒度大的圖像進(jìn)行更細(xì)致的子類別的細(xì)分。因其在智慧城市、商品識(shí)別、公共安全、生態(tài)保護(hù)等領(lǐng)域具有重要的科學(xué)意義和應(yīng)用價(jià)值。不同于普通的圖像分類任務(wù),細(xì)粒度子類別受到微小的類間差異[2]和較大的類內(nèi)差異以及雜亂背景特征的影響。深度學(xué)習(xí)在圖像中得到的特征具有更強(qiáng)的表達(dá)能力,因此在細(xì)粒度圖像分類上被廣泛應(yīng)用。當(dāng)前基于深度學(xué)習(xí)的細(xì)粒度分類方法可以大致分為三類:強(qiáng)監(jiān)督方法、弱監(jiān)督方法和半監(jiān)督方法。強(qiáng)監(jiān)督方法首先檢測(cè)關(guān)鍵零件,然后集成零件特征作為細(xì)粒度分類的最終視覺(jué)表示。不僅需要圖像級(jí)標(biāo)簽,還需要手動(dòng)注釋的邊界框或零件注釋。由于細(xì)粒度類別的手動(dòng)注釋耗時(shí)且需要專家性意見(jiàn),實(shí)用性和擴(kuò)展性受到限制。弱監(jiān)督方法不再使用邊界框和零件標(biāo)注,只需要在訓(xùn)練期間使用圖像級(jí)別的標(biāo)簽。例如,朱陽(yáng)光等[3]提出一種聯(lián)合殘差網(wǎng)絡(luò)(Residual network,Resnet)和Inception網(wǎng)絡(luò)通過(guò)優(yōu)化卷積神經(jīng)網(wǎng)絡(luò)提高捕捉細(xì)粒度特征的能力。藍(lán)潔等[4]根據(jù)Tensor Sketch算法計(jì)算出多組來(lái)自不同通道卷積層的雙線性特征向量進(jìn)行融合學(xué)習(xí)細(xì)粒度鳥(niǎo)類的特征信息。盡管如此,弱監(jiān)督組方法仍然需要大量正確的圖像級(jí)別標(biāo)簽。半監(jiān)督方法涉及利用網(wǎng)絡(luò)圖像訓(xùn)練細(xì)粒度分類模型。例如,Xu等人[5]提出利用詳細(xì)的注釋,并將盡可能多的知識(shí)從現(xiàn)有的強(qiáng)監(jiān)督數(shù)據(jù)集轉(zhuǎn)移到弱監(jiān)督網(wǎng)絡(luò)圖像,以實(shí)現(xiàn)細(xì)粒度識(shí)別。Niu等人[6]提出了一種新的學(xué)習(xí)場(chǎng)景,該場(chǎng)景只需要專家標(biāo)記一些細(xì)粒度的子類別,然后借助網(wǎng)絡(luò)圖像預(yù)測(cè)所有剩余的子類別。半監(jiān)督方法涉及各種形式的人工干預(yù),可擴(kuò)展性相對(duì)有限。
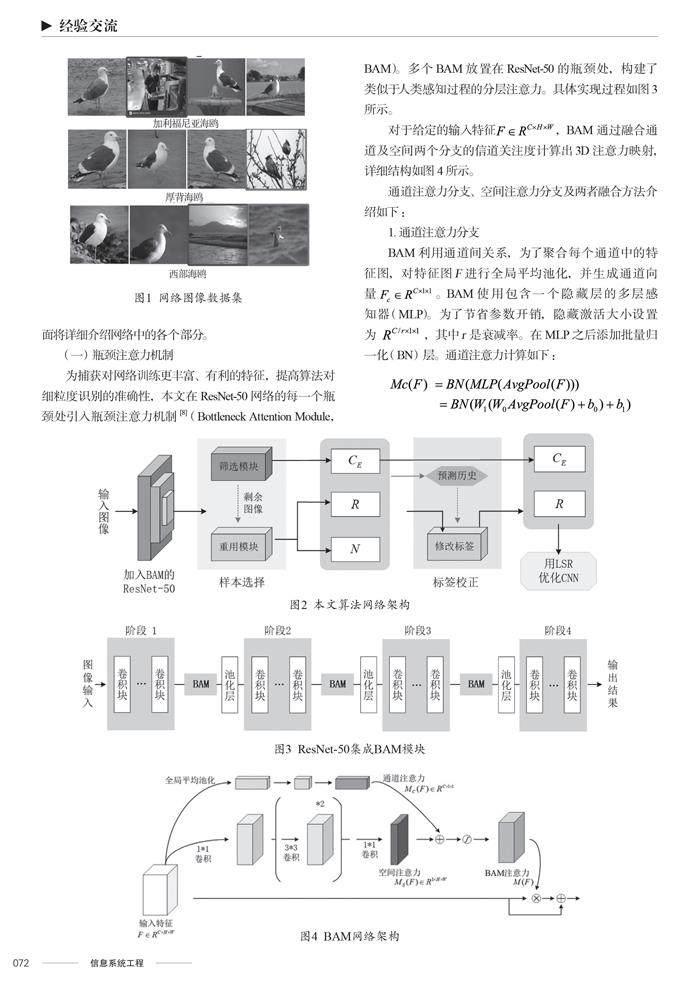
本文使用網(wǎng)絡(luò)監(jiān)督方法解決細(xì)粒度問(wèn)題,利用網(wǎng)絡(luò)上的免費(fèi)數(shù)據(jù)訓(xùn)練細(xì)粒度的分類模型。網(wǎng)絡(luò)圖像標(biāo)簽通常源于自動(dòng)標(biāo)記系統(tǒng)或非專家注釋,存在大量標(biāo)簽噪聲。標(biāo)簽噪聲分為“類內(nèi)噪聲”和“類外噪聲”兩種。類內(nèi)噪聲圖片的真實(shí)標(biāo)簽包含在訓(xùn)練數(shù)據(jù)集的已知子類別中(參見(jiàn)圖1中帶有邊界框的圖像)。類外噪聲圖片與訓(xùn)練數(shù)據(jù)集完全無(wú)關(guān),它們的真實(shí)標(biāo)簽不屬于所在數(shù)據(jù)集中任一子類標(biāo)簽(參見(jiàn)圖1中帶有紫色邊界框的圖像)。為解決樣本圖像中大量標(biāo)簽噪聲、背景特征干擾導(dǎo)致的識(shí)別效果不理想等問(wèn)題,主要進(jìn)行了如下工作:①在特征提取階段引入瓶頸注意力模塊,解決由背景特征干擾造成的識(shí)別能力弱的問(wèn)題。②采用基于確定性的可重用樣本選擇和校正方法,利用額外的可重復(fù)使用樣本。③在三個(gè)流行的基準(zhǔn)細(xì)粒度數(shù)據(jù)集Web-Bird(鳥(niǎo)類數(shù)據(jù)集)、Web-Cars(汽車數(shù)據(jù)集)、Web-Aircraft(飛機(jī)數(shù)據(jù)集)上進(jìn)行測(cè)試和評(píng)估,結(jié)果在同類型算法中處于領(lǐng)先水平。
二、模型框架
本文使用的基于瓶頸注意力機(jī)制的網(wǎng)絡(luò)監(jiān)督細(xì)粒度識(shí)別模型如圖2所示。本文選取ResNet-50[7]作為特征提取網(wǎng)絡(luò),引入瓶頸注意力機(jī)制,提高網(wǎng)絡(luò)的表征能力。首先,特征提取網(wǎng)絡(luò)預(yù)測(cè)每個(gè)圖像的標(biāo)簽,生成標(biāo)簽預(yù)測(cè)歷史并計(jì)算每個(gè)圖像的損失。然后,篩選模塊對(duì)圖像損失值排序,選出一部分低損失的圖像。接著,重用模塊對(duì)剩下的高損失圖像計(jì)算預(yù)測(cè)確定性并排序,選擇預(yù)測(cè)確定性大的樣本作為可重用樣本,并且利用預(yù)測(cè)歷史修改它們的標(biāo)簽。最后,利用以上步驟得到的兩部分訓(xùn)練樣本來(lái)優(yōu)化模型。下面將詳細(xì)介紹網(wǎng)絡(luò)中的各個(gè)部分。
(一)瓶頸注意力機(jī)制
1.通道注意力分支
2.空間注意力分支
3.注意力分支合并
(二)樣本選擇及校正
1.基于確定性的可用樣本選擇
2.基于預(yù)測(cè)歷史的標(biāo)簽修正
三、實(shí)驗(yàn)結(jié)果及分析
(一)數(shù)據(jù)集
Web-Aircraft(飛機(jī)數(shù)據(jù)集)包含100個(gè)飛機(jī)類型的16,836張圖像:13,503張圖像用于訓(xùn)練,3,333張圖像用于測(cè)試。
Web-Bird(鳥(niǎo)類數(shù)據(jù)集)涵蓋了200種不同的鳥(niǎo)類子類別,總共包含24,182張圖像:18,388張用于訓(xùn)練,5794張用于測(cè)試。
Web-Cars(汽車數(shù)據(jù)集)包含196個(gè)汽車子類別,包括29,489張圖像:21,448張用于訓(xùn)練,8,041張用于測(cè)試。
(二)實(shí)驗(yàn)條件
本文所有實(shí)驗(yàn)均是在64位的Ubuntu16.04系統(tǒng)中進(jìn)行,采用的深度學(xué)習(xí)框架為Pytorch,在訓(xùn)練過(guò)程中利用NVIDIA TESLA V100S顯卡進(jìn)行加速,并且采用Python3.7編程語(yǔ)言完成代碼的編寫(xiě)。網(wǎng)絡(luò)優(yōu)化過(guò)程采用SGD優(yōu)化器,動(dòng)量為0.9。學(xué)習(xí)率、批量大小和權(quán)重衰減分別設(shè)置為0.01、64和0.0003。迭代訓(xùn)練110次,其中預(yù)熱時(shí)期迭代5次。瓶頸注意力中膨脹值d設(shè)為4,衰減率r設(shè)為16。
(三)評(píng)價(jià)指標(biāo)
本文采用平均分類準(zhǔn)確率(Average Classification Accuracy,ACA)作為評(píng)價(jià)指標(biāo),分類準(zhǔn)確率表示正確分類的樣本數(shù)量占數(shù)據(jù)集所有樣本數(shù)量的比例,計(jì)算得出五次實(shí)驗(yàn)的平均分類準(zhǔn)確率。
(四)模型有效性驗(yàn)證
為驗(yàn)證瓶頸注意力模塊在特征提取過(guò)程中發(fā)揮的作用,本文在數(shù)據(jù)集上進(jìn)行了有無(wú)瓶頸注意力模塊的實(shí)驗(yàn)對(duì)比,如表1所示。由表1可以看出,BAM在Web-Bird、Web-Cars、Web-Aircraft上的平均分類準(zhǔn)確率分別實(shí)現(xiàn)了1.3%、0.9%和0.4%的提升,證明BAM模塊可以進(jìn)一步提高特征提取網(wǎng)絡(luò)的表征能力。
(五)模型先進(jìn)性驗(yàn)證
為驗(yàn)證本文改進(jìn)算法的先進(jìn)性,與目前最新的3種算法對(duì)比結(jié)果如表2所示。表2為不同方法在Web-Bird、Web-Cars和Web-Aircraft數(shù)據(jù)集上的結(jié)果比較,本文算法的平均分類準(zhǔn)確率ACA指標(biāo)均高于目前先進(jìn)的對(duì)比算法。
綜上所述,通過(guò)兩個(gè)方面的實(shí)驗(yàn)分析證明,本文改進(jìn)算法在三個(gè)數(shù)據(jù)集取得優(yōu)異的檢測(cè)性能,進(jìn)而證明了本文算法的有效性和先進(jìn)性。
四、結(jié)語(yǔ)
為應(yīng)對(duì)細(xì)粒度識(shí)別任務(wù)中難以獲取良好標(biāo)記的數(shù)據(jù)集問(wèn)題,本文使用網(wǎng)絡(luò)監(jiān)督方法解決細(xì)粒度識(shí)別問(wèn)題,通過(guò)網(wǎng)絡(luò)免費(fèi)圖像訓(xùn)練細(xì)粒度網(wǎng)絡(luò)。為解決網(wǎng)絡(luò)監(jiān)督細(xì)粒度識(shí)別效果差的問(wèn)題,本文設(shè)計(jì)了一種基于瓶頸注意力機(jī)制的網(wǎng)絡(luò)監(jiān)督細(xì)粒度模型。針對(duì)復(fù)雜背景導(dǎo)致圖像前景特征提取不準(zhǔn)確的問(wèn)題,引入了瓶頸注意力機(jī)制,有效增加特征提取過(guò)程中重要特征的權(quán)重,強(qiáng)化網(wǎng)絡(luò)對(duì)于有用特征信息的利用。本文提出的改進(jìn)算法在各個(gè)指標(biāo)上的結(jié)果均較為理想,為后續(xù)網(wǎng)絡(luò)監(jiān)督細(xì)粒度識(shí)別工作奠定了較好的基礎(chǔ)。今后將進(jìn)一步針對(duì)解決數(shù)據(jù)集標(biāo)簽噪聲相關(guān)工作進(jìn)行研究,提高標(biāo)簽糾錯(cuò)能力,使算法的識(shí)別效果得到進(jìn)一步提升。
參考文獻(xiàn)
[1]羅建豪,吳建鑫.基于深度卷積特征的細(xì)粒度圖像分類研究綜述[J].自動(dòng)化學(xué)報(bào),2017,43(8):1306-1318.
[2]魏秀參.深度學(xué)習(xí)下細(xì)粒度級(jí)別圖像的視覺(jué)分析研究[D].南京:南京大學(xué),2018.
[3]朱陽(yáng)光,劉瑞敏,黃瓊桃.基于深度神經(jīng)網(wǎng)絡(luò)的弱監(jiān)督信息細(xì)粒度圖像識(shí)別[J].電子測(cè)量與儀器學(xué)報(bào),2020,34(2):115-122.
[4]藍(lán)潔,周欣,何小海,等.基于跨層精簡(jiǎn)雙線性網(wǎng)絡(luò)的細(xì)粒度鳥(niǎo)類識(shí)別[J].科學(xué)技術(shù)與工程,2019,19(36):240-246.
[5]Zhe X,Huang S,Zhang Y,et al.Augmenting Strong Supervision Using Web Data for Fine-Grained Categorization[C]//IEEE International Conference on Computer Vision.IEEE,2015.
[6]Niu L,Veeraraghavan A,Sabharwal A.Fine-grained Classification using Heterogeneous Web Data and Auxiliary Categories:10.48550/arXiv.1811.07567[P].2018.
[7]He K,Zhang XY,Ren SQ,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE,2016.
[8]Park J,Woo S, Lee JY,et al.BAM: Bottleneck Attention Module:10.48550/arXiv.1807.06514[P].2018.
[9]Sun Z,Yao Y,Wei XS,et al.Webly Supervised Fine-Grained Recognition: Benchmark Datasets and An Approach:10.48550/arXiv.2108.02399[P].2021.
[10]Liu H,Zhang C,Yao Y,et al.Exploiting Web Images for Fine-Grained Visual Recognition by Eliminating Open-Set Noise and Utilizing Hard Examples[J].IEEE transactions on multimedia,2022(24):546-557.
[11]Sun Z,Hua XS,Yao Y,et al.Salvage Reusable Samples from Noisy Data for Robust Learning[J].2020.
作者單位:哈爾濱工程大學(xué)信息與通信工程學(xué)院
猜你喜歡
中國(guó)教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國(guó)遠(yuǎn)程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(bào)(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時(shí)代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(huì)(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
