適用于強(qiáng)化學(xué)習(xí)慣性環(huán)境的分?jǐn)?shù)階改進(jìn)OU噪聲
2023-04-29 13:47:01王濤張衛(wèi)華蒲亦非
四川大學(xué)學(xué)報(bào)(自然科學(xué)版)
2023年2期
王濤 張衛(wèi)華 蒲亦非


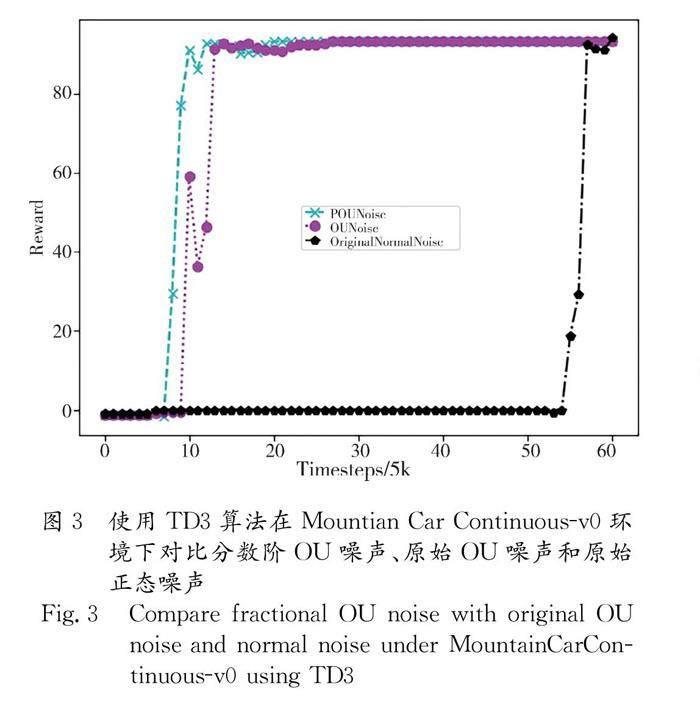
本文將DDPG算法中使用的Ornstein-Uhlenbeck (OU) 噪聲整數(shù)階微分模型推廣為分?jǐn)?shù)階OU噪聲模型,使得噪聲的產(chǎn)生不僅和前一步的噪聲有關(guān)而且和前K步產(chǎn)生的噪聲都有關(guān)聯(lián).通過(guò)在gym慣性環(huán)境下對(duì)比基于分?jǐn)?shù)階OU噪聲的DDPG和TD3算法和原始的DDPG和TD3算法,我們發(fā)現(xiàn)基于分?jǐn)?shù)階微積分的OU噪聲相比于原始的OU噪聲能在更大范圍內(nèi)震蕩,使用分?jǐn)?shù)階OU噪聲的算法在慣性環(huán)境下具有更好的探索能力,收斂得更快.
DDPG算法; TD3算法; 分?jǐn)?shù)階微積分; OU噪聲; 強(qiáng)化學(xué)習(xí)
TP39A2023.022001
收稿日期: 2022-03-26
基金項(xiàng)目: 四川省科技計(jì)劃(2022YFQ0047)
作者簡(jiǎn)介: 王濤(1997-), 男,? 碩士研究生, 四川資陽(yáng)人, 研究方向?yàn)榉謹(jǐn)?shù)階微積分與強(qiáng)化學(xué)習(xí). E-mail: 2647877536@qq.com
通訊作者: 張衛(wèi)華. E-mail: zhangweihua@scu.edu.cn
An improved Ornstein-Uhlenbeck exploration noise based on fractional order calculus for reinforcement learning environments with momentum
WANG Tao, ZHANG Wei-Hua, PU Yi-Fei
(College of Computer Science, Sichuan University, Chengdu 610065, China)
In this paper, the integer-order Ornstein-Uhlenbeck (OU) noise model used in the deep deterministic policy gradient (DDPG) algorithm is extended to the fractional-order OU noise model, and the generated noise is not only related to the noise of the previous step but also related to the noise generated in the previous K steps in the proposed model.The DDPG algorithm and twin delayed deep deterministic(TD3) algorithm using the fractional-order OU noise model were compared with the original DDPG algorithm and TD3 algorithm in the gym inertial environment. We found that, compared with the original OU noise, the fractional-order OU noise can oscillate in a wider range, and the algorithm using the fractional-order OU noise had better exploration ability and faster convergence in inertial environment.
Deep deterministic policy gradient; Twin delayed deep deterministic; Fractional calculus; Ornstein-Uhlenbeck process; Reinforcement learning
1 引 言
深度Q網(wǎng)絡(luò)(DQN)[1]的提出開(kāi)創(chuàng)了深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)結(jié)合的先例,DQN算法直接使用了深度神經(jīng)網(wǎng)絡(luò)來(lái)擬合強(qiáng)化學(xué)習(xí)中的Q(s,a) 函數(shù),并根據(jù)貪心策略選擇下一步需要執(zhí)行的動(dòng)作,這一工作使得算法在Atari游戲上達(dá)到了近似人類玩家的水平.
基于DQN的工作,后續(xù)還有人還提出了DDQN[2],Dueling DQN[3],Rainbow DQN[4]等工作,這些工作極大地改進(jìn)了基于值函數(shù)估計(jì)類算法的效果.不過(guò),這些工作的動(dòng)作空間都是離散的,智能體每次只能選擇有限的幾個(gè)動(dòng)作.然而,在實(shí)際的應(yīng)用場(chǎng)景下,更多的是需要強(qiáng)化學(xué)習(xí)算法處理連續(xù)控制任務(wù).比如無(wú)人機(jī)追逃控制[5],飛行器高度控制[6],機(jī)械臂軌跡規(guī)劃[7,8],無(wú)人機(jī)航跡規(guī)劃[9]等.
對(duì)于連續(xù)控制任務(wù)則無(wú)法直接使用DQN系列的算法,研究人員參考DQN系列算法值函數(shù)估計(jì)的思想,提出了DDPG算法[10],在……
登錄APP查看全文
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國(guó)傳媒大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
中國(guó)生殖健康(2020年6期)2020-02-01 06:28:50
小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10
中國(guó)生殖健康(2019年11期)2019-01-07 01:28:02
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 20:56:37