車載智能語音助手綜合評估模型建立及應用
2023-04-11 01:01:54道發(fā)發(fā)丁敏袁粲璨陳曉軍黎小平趙嵩
汽車文摘 2023年4期
道發(fā)發(fā) 丁敏 袁粲璨 陳曉軍 黎小平 趙嵩
(一汽-大眾汽車有限公司,長春 130011)
縮略語
NLP Nature Language Processing
BLEU Bilingual Evaluation Understudy
ROUGE Recall-Oriented Understudy for Gisting Evaluation
TTS Text To Speech
VPA Virtual Personal Assistant
AI Artificial Intelligence
0 引言
隨著物聯(lián)網(wǎng)、車聯(lián)網(wǎng)、自動駕駛技術的發(fā)展,汽車行業(yè)的競爭力正在從傳統(tǒng)的以性能為核心轉(zhuǎn)變?yōu)橐詳?shù)字化和智能化為核心,包括眾多的智能座艙服務和輔助駕駛服務。車載語音助手是汽車數(shù)字化的一部分[1],也是人機交互的一級入口,常見的車載語音助手包含任務型對話功能和閑聊功能,其中任務型對話應用于車內(nèi)支持的功能操作,如車控、導航、天氣等,閑聊則是通用的聊天型對話,不完成具體的任務。
車載語音助手的出現(xiàn)解放了駕駛員的雙手和雙眼,用戶無需注視屏幕或操作按鈕即可完成對應的需求。但同時,為了“可見即可說”,車載語音助手需要支持數(shù)百個常用的指令及無窮的說法變換,其性能的優(yōu)劣直接影響用戶的體驗[2]。故針對車載語音助手的綜合性評價非常重要。
語音助手的實現(xiàn)邏輯是基于人工智能的自然語言處理(Nature Language Processing,NLP)模型。常用的模型評估方法通常是針對單個模型的點對點評估,如對于實體識別[3]、序列標注[4]的模型,采用精確率、召回率、精確率和召回率的加權平均(F1 Score)數(shù)值等評估指標;對于文本生成[5]任務使用雙語評估研究(Bi?lingual Evaluation Understudy,BLEU)、自動摘要評價(Recall-Oriented Understudy for Gisting Evaluation,ROUGE)方法進行評估。車載語音助手通常由至少十幾個不同的模型組成,每個模型在開發(fā)過程中的訓練數(shù)據(jù)不一定相同,評估指標也不相同,故不能用各部分的單獨技術性指標來描述整個系統(tǒng)的性能。在開發(fā)過程中,開發(fā)人員完成所有組件的開發(fā)并整合成語音助手之后,測試人員會根據(jù)其設計所支持的功能進行通過性測試。這種測試方式會忽略實際應用場景的復雜性、用戶表達的多樣性,無法深度探查語音助手的能力及其背后算法的有效性[6]。
綜上所述,本文提出了一套綜合性的語音助手評估模型,旨在以貼近用戶的方式量化描述語音助手的綜合表現(xiàn),并可以反推出各個子系統(tǒng)的性能,用于問題定位和優(yōu)化。
1 評估模型建立
本模型包含評價數(shù)據(jù)庫、指標生成模型、可視化組件、自動化組件4個主要部分。其中評價數(shù)據(jù)庫包含10 026 條由人工構造的高階用例,以矩陣形式組織,橫向按語義點區(qū)分,如意圖聯(lián)想、語義容錯、多意圖識別共31 個評價項,縱向按車載常用功能分為64個功能,主要涉及車控、導航、天氣、多媒體、電話主要車載技能以及維保、藍牙、計算器、油價等長尾技能[7]。指標生成模型包含完成率、意圖識別率生成模型以及意圖聯(lián)想、語義容錯、多意圖識別子項指標生成模型。可視化組件包含數(shù)據(jù)載入、低代碼分析、柱狀圖、條形圖、餅圖、時間序列分析功能。自動化組件主要包括自動化分析、多輪對話模擬、報告生成輔助性組件。
標準的指標生成模型可生成主要的技術性描述指標,大量的評估用例保證評估結果無偏差,本模型可應用于需求調(diào)研階段的競品分析,也可應用于生產(chǎn)階段的需求對接,保證產(chǎn)品交付質(zhì)量。
1.1 評估用例
本模型的核心設計目標是一款普適的車載語音助手評估模型,可應用于市場上常見的搭載智能語音助手的綜合評估。一般的評估過程需要遵循可量化、層次性、普遍性、客觀性原則。針對以上原則和實際需求,構建了一批用于評估的用例庫,所有用例均由經(jīng)驗豐富的測試人員和產(chǎn)品人員編寫,并通過一個審核小組逐條審核,最終形成了一個萬余條的評估用例庫。
評估用例庫中,用例的組織方式遵從分層原則,分別從智能等級、功能點、困難程度、語義維度4個方面進行分級。為了能夠得到精確的量化指標,在構造用例時確保每條用例只對應于一種語義指標。
表1 示意每個維度上的詳細層次結構,其中技能共有27個一級項和64個二級項,語義維度分3個一級項和31個二級項。表1中只列出一級項,省略了二級項。

表1 用例維度分級表
根據(jù)評估模型的特點,設計了一套用例構建標準,從語義維度對用例的構建原則、評估目標以及其智能程度進行分級,表2描述了用例構建過程中語義維度各指標的定義以及對應的評價項,由于篇幅所限,本文僅列出部分內(nèi)容,全量的評價項共有31項,基本覆蓋所有語義類型。本文中的所有用例都根據(jù)此表進行構建。其中,L1、L2、L3、L4 分別代表4 個不同的智能程度。
1.2 主要指標評估模型
評估模型分為主要指標和次要指標,其中主要指標為任務完成率、意圖識別率,用于評估語音助手在任務型對話上的端到端能力;次要指標是語音維度的31 個細分維度,用于對車載語音智能程度、語義理解能力、語義理解模型效果的分析。
評估過程中,為了降低評估人員主觀的誤差,使3名評估人員同時進行打分,當所有評估人員都認為該用例通過時,則該用例通過。
對于任務完成率和意圖識別率,指標的量化計算公式如式(1)。
式中,pa為評估用例結果的得分;αi為第i條用例的得分;X為用例集合。當所有評估人員的打分都為1時,ai=1,否則ai=0。
此外,為了能夠捕捉評估一致的隨機性,除了上述pa指標外,引入指標pc,對于多個評估人員ej,用例集合X的評估分數(shù)是集合S,那么pc的計算公式為:
式中,p(s|ei)是每個評估人員給出分數(shù)s的頻率估計;s是用例;最后能夠得到和評估一致性相關的結果σ:
式中,當σ越靠近1,則表示多名評價者評價的一致性越強,評估結果越可靠。在本模型中,當σ>0.8 時,認為當輪評價有效,采用該輪評價結果。
同時,對于完成率和意圖識別率,將整個語音助手視為一個統(tǒng)一的機器學習模型,采用查準率、查全率和F1值描述語音助手的整體表現(xiàn):
式中,Pr為查準率;TP為語音助手成功完成的任務數(shù);FP為語音助手未識別的拒識用例數(shù);Recall為查全率;FN為語音助手成功識別到的拒識用例數(shù);F1代表語音助手的實際表現(xiàn),其數(shù)值越靠近1,表示語音助手的性能越佳。
綜上,在評價任務完成和意圖識別2 個主要維度時,使用了2套指標,第1套綜合指標使用一致性評估方式保證評估人員的一致性,第2套指標將語音助手看做一個整體的AI模型,使用查準率、查全率和F1值來評估其整體表現(xiàn)。
在實際研發(fā)過程中,研發(fā)人員或項目管理人員不僅關注語音助手的整體指標,更需要注意各部分子功能的具體指標,以此保證子模塊算法的性能。
1.3 語義指標評估模型
在本評估模型中,語義方面共分3 個一級語義和31個二級語義,從算法角度進行分類,可以歸結為文本分類任務、匹配任務、序列標注任務和文本生成任務。
對于文本分類任務和序列標注任務,由于評估樣本有限,且樣本分布不完全均衡,為避免忽略小樣本數(shù)據(jù),故使用MicroAveraged方法評估:
其中,Pmicro為微平均查準率,Rmicro為微平均查全率,TPi為第i類任務里識別正確的數(shù)量,F(xiàn)Pi為第i類任務里識別錯誤的數(shù)量,F(xiàn)Ni為第i類里把錯誤類別識別成正確類別的數(shù)量,----TP,----FP,分別為TPi和FPi的算數(shù)平均值。
對于文本匹配任務,使用Top@N覆蓋率來描述其性能,計算方式為前N項候選指標中包含正確結果的準確率。
對于文本生成任務,使用BLEU作為其評估指標:
式中,BP為最佳匹配長度;wn為賦予Pn權重;Pn為多元精度得分;lc為結果的長度;lr為標準答案句子的長度。
綜上,描述了本模型中2 個主要指標(任務完成和意圖識別)以及31個二級語義指標的評估方法,主要指標將語音助手視為一個單獨對象,使用查準率、查全率、F1值來描述其性能,并采用σ約束來規(guī)避評估人員主觀上導致的評分不一致問題[8]。二級語義指標將語音助手視為多個子模型的集合,針對每個二級語義項,都給出單獨的評價指標,開發(fā)人員可以借助這些指標進行深度的問題定位,需求分析人員可以借助這些指標完成對目標產(chǎn)品的多維度分析。
在實際的開發(fā)過程中,由于項目采用敏捷的工作方式,項目版本迭代次數(shù)最高可以達到每天一次,導致開發(fā)人員對于問題定位的需求頻率非常高。使用人工分析來定位問題會帶來大量的人力需求,為了降低對于人工的消耗,使用一個簡單的算法模型來進行快速的自動化問題定位。
2 分析方法
2.1 問題描述
評估模型的輸出結果是2 個主要指標和31 個語義指標的評分,這些指標的集合代表了語音助手各部分及整體的表現(xiàn)。為了適應語音助手復雜的任務型對話邏輯,如前文所述,評估模型也遵從分層的構建邏輯,并從功能點和語義的維度進行了兩級劃分。整體的指標體系可以分為4層,上一層級的評估指標值為下一層級指標的算數(shù)平均值(圖1)。
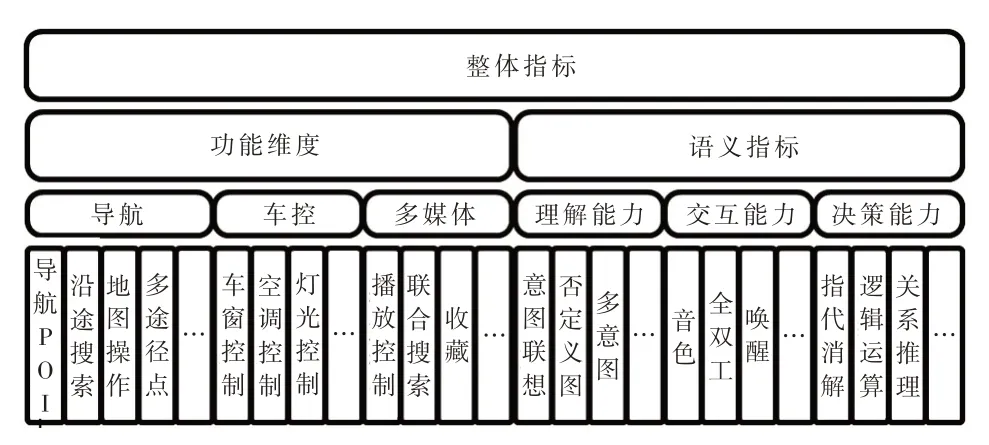
圖1 評估指標層級劃分
表3為使用評估模型對上述組織方式的用例集合進行打分后的結果,其中3項打分S1、S2、S3分別為語義識別、意圖識別、任務完成情況。由于篇幅限制,此處省略了一些其它輔助字段的信息。
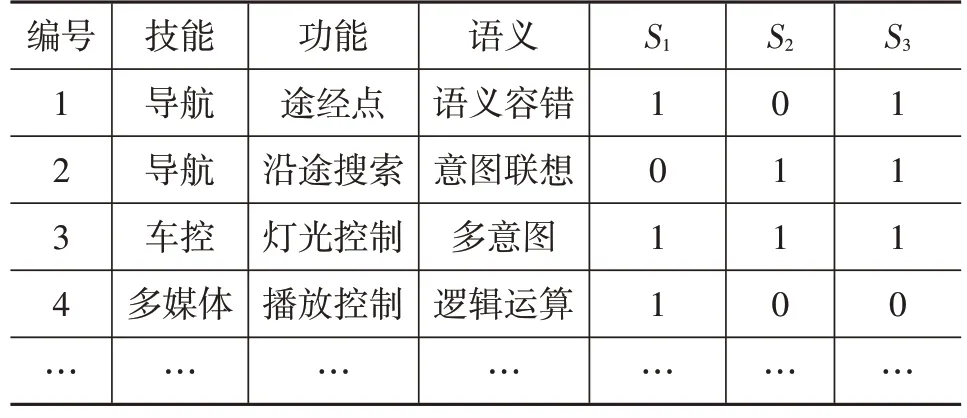
表3 模型評估結果
通常,一次評估后會得到30 000條以上的評估結果數(shù)據(jù)。在研發(fā)生產(chǎn)過程中,伴隨著敏捷迭代,需要進行高頻的模型評估和問題定位分析,使用人工的方式進行分析會帶來極大的人力需求。為了提高問題分析和定位的能力,設計了一套自動化的分析算法,用于研發(fā)過程中快速分析。
2.2 分析算法
模型的評估結果是一個多維分層指標體系,先構建數(shù)據(jù)模型,如圖2所示。S為整體評估分數(shù),由其下層指標合并而成(如整體的任務完成率由功能維度和語義維度得分合并而成)。因此,對于一個二級指標體系來說,分析算法的任務是從S得分的波動中找出造成這種波動的下級節(jié)點,且結果必須具有原子特性,即節(jié)點組合的最簡約形式,如(A1B1、A1C1)的最簡約形式為(A1B1C1)[9]。
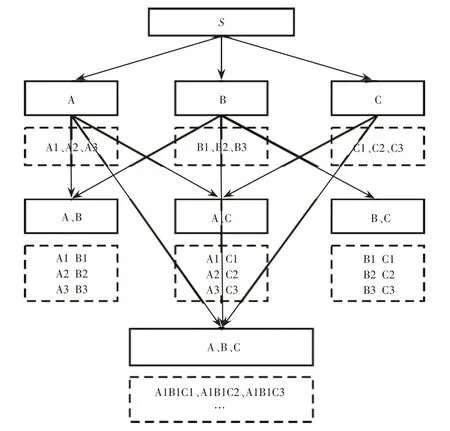
圖2 數(shù)據(jù)模型
在問題定位過程中,需要結果能夠準確反應波動出現(xiàn)的原因,即異常點[10]。異常點的查找需要滿足3個主要條件,也是算法設計過程中的難點[11]。
(1)對于每一個維度,結果需要盡可能解釋主要指標波動原因;
(2)對于每一個維度,結果需要符合最簡原則,即不可再分;
(3)在所有維度中,需要找出和預期結果相差最大的元素。
針對以上問題,參考Adtributor 方法[12],設計分析算法。S值為當前指標的驚喜度,代表該指標偏離預期的距離,距離越遠,驚喜度越高[13],算法如下。
問題定位算法(根因分析)
2.3 試驗結果
根據(jù)上述分析算法,使用真實的打分數(shù)據(jù)進行了相關試驗,以驗證該算法在數(shù)據(jù)集上的有效性。試驗之前,使用前述用例集合對一款自研語音助手進行了全量的打分,生成原始打分數(shù)據(jù)并計算各個維度的打分以及整體的任務完成指標打分。此外,對原始數(shù)據(jù)集隨機添加不同數(shù)量的異常點,通過統(tǒng)計該算法的識別效果驗證上述算法的有效性。
結果如表4 所示,可以發(fā)現(xiàn)在精確度方面和人工分析的差距約為10%,且當異常和數(shù)據(jù)量增加時,算法性能有所下降。這樣的性能在生產(chǎn)過程中是可接受的,同時,結合一些規(guī)則工具,實際的問題定位精確度可以進一步提升。本文只介紹純算法的性能。
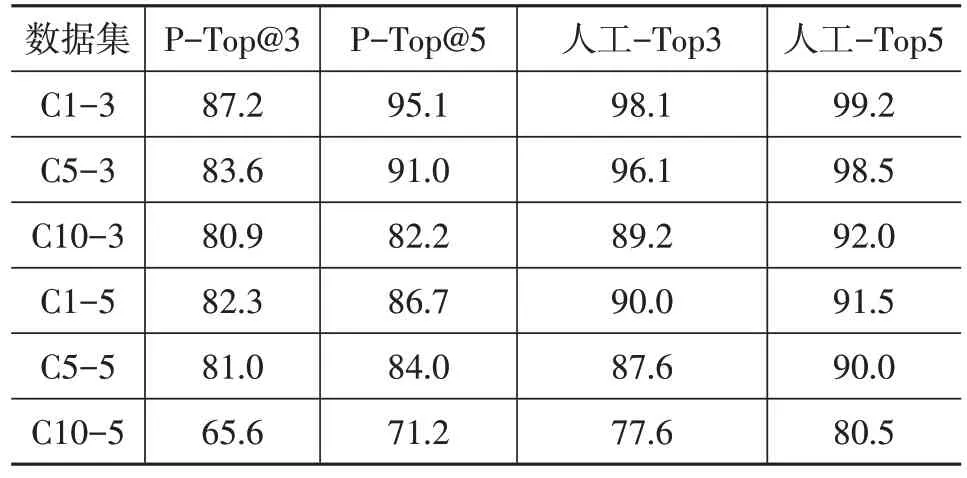
表4 Adtributor算法試驗結果 %
表4 中,C1-3 代表在1 000 條數(shù)據(jù)中注入3 條異常,C10-5代表在10 000條數(shù)據(jù)中注入5條異常,以此類推。其中,P-Top為使用本模型進行評估的得分,人工-Top為使用人工評估后的得分。
3 相關工作
本模型已應用于正常的研發(fā)過程,使用本模型對市場上的車型進行了多次全量競品分析,下面列出部分分析數(shù)據(jù)。表5 所示為整體評估指標,表6 所列為語義部分評估指標。可以看出,本模型可以對語音助手整體做出量化的評估,也可以按語義功能進行評估,維度更多更深,能夠充分分析市場上車載語音產(chǎn)品的表現(xiàn)。
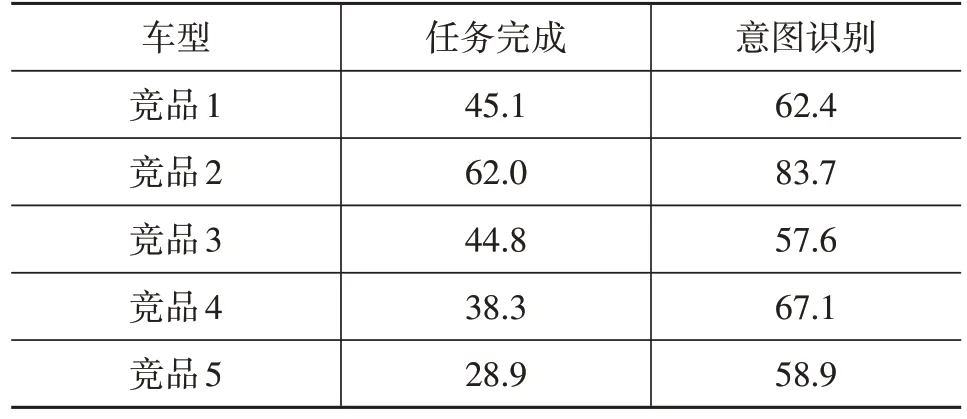
表5 整體指標評估結果 %
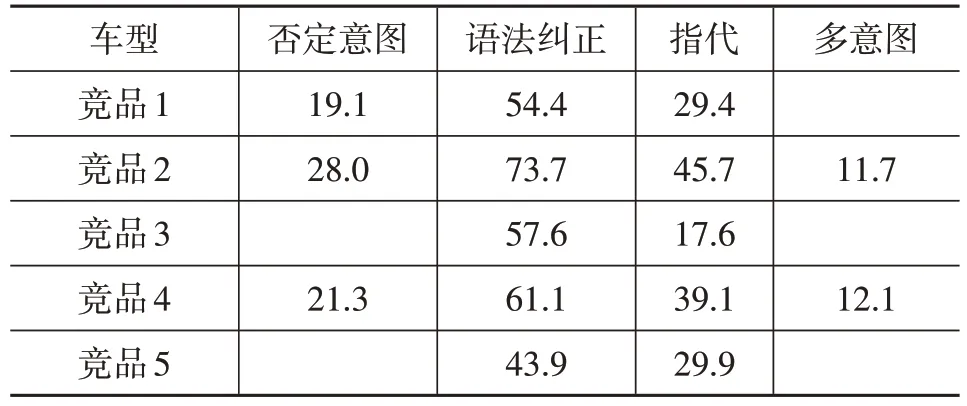
表6 部分語義指標評估結果 %
4 結束語
本文介紹了一個車載語音助手評估模型,該模型的設計背景來源于實際的生產(chǎn)項目。解決了車載語音助手研發(fā)過程中,設計開發(fā)人員在產(chǎn)品分析和問題定位過程中的問題。在構建大量模擬真實交互環(huán)境的數(shù)據(jù)集合的基礎上,設計了分層指標評估模型和問題定位算法,并應用于實際研發(fā)過程,有效提高了產(chǎn)品質(zhì)量以及研發(fā)效率。此外,本文僅闡述評估模型的核心思路及算法,實際生產(chǎn)過程中會用到一些自動化的輔助工具以提升系統(tǒng)工作效率和規(guī)范化輸出。
隨著需求的不斷變化,本模型也在不斷迭代更新,如計劃在功能維度和語義維度之外新增環(huán)境維度,通過還原車輛和用戶所處的環(huán)境,如設計高速行駛、城區(qū)道路行駛、車窗狀態(tài)、車內(nèi)噪聲環(huán)境等,使評估過程更貼切擬合實際場景。
基于單獨Adtributor 算法的模型問題定位能力比人工定位能力弱,計劃額外引入HotSpot方法,通過投票決策的方式進行問題定位,以提升成功率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
