基于物聯網視角農業環境大數據系統設計要點研究
2023-03-22 09:29:16張向豐
物聯網技術 2023年3期
張向豐
(黃河水利職業技術學院,河南 開封 475000)
0 引 言
在傳統的農業生產模式中,從業者依靠經驗判斷作物長勢、制定管理策略,但由于缺乏精確的數據支撐,容易出現偏差。基于物聯網的農業環境大數據系統能夠解決該問題。此類系統的設計重點在于數據的獲取途徑、存儲方式以及分析處理方法,本文從這三個方面對系統的設計要點進行深入探索,旨在提出科學的設計方案。
1 農業物聯網
1.1 農業物聯網技術
農作物生長對環境條件有一定的要求,如土壤水勢、土壤酸堿性、環境溫度、空氣濕度、光照強度等方面。現代農業生產的精細化、智慧化程度在不斷提高,這就要求在農業管理中加強對各類環境數據的監控,并在其基礎上制定科學、高效的策略。在這一過程中涉及到各類農業環境數據的檢測、存儲和展示。
農業物聯網以互聯網技術為基礎,融合了各種類型的農業數據傳感器,加強了農業生產者的信息感知能力。另外,將農業物聯網技術與數據分析算法、人工智能等相結合,可實現較高水平的自動化種養。
1.2 農業物聯網的體系架構
按照數據生成到應用的先后順序,可將農業物聯網的體系架構劃分為五層,如圖1所示。
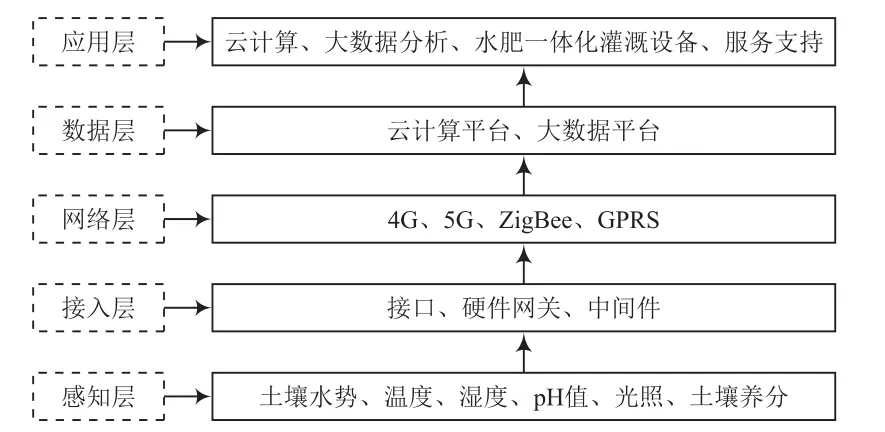
圖1 農業物聯網體系架構
(1)感知層
感知層是農業物聯網采集環境大數據的主要渠道,其核心設備是各種傳感器,如小型智能氣象站、土壤墑情檢測儀、溫濕度測量儀器等。當前,傳感器的智能化水平不斷提高,其采集的數據可自動上傳至系統管理后臺。
(2)接入層
農業物聯網中存在多種類型的傳感器,其生產廠家、通信方式可能存在差異。接入層用于實現不同傳感器的訪問,提升系統兼容性。接入層由中間件、網關以及接口組成。以硬件網關為例,可兼容以太網、RS 485、RS 232等多種輸入方式,可滿足不同傳感器的通信需求[1-2]。
(3)網絡層
通信網絡是農業物聯網的重要組成部分,傳感器的數據上傳、管理后臺對設備的遠程操控均依賴于通信網絡。常用的通信方式為GPRS、4G、5G等。在大數據系統中,數據傳輸規模較大,對網絡層的傳輸速率提出了較高的要求。
(4)數據層
數據層的功能包括兩個方面,分別為數據存儲和數據預處理。傳感器長期運行,會產生大量的農業環境數據,由數據層提供存儲功能,實現資源集中與共享。數據預處理的目的是清洗粗大誤差、補充部分缺失值,必要時進行數據轉換,如歸一化處理,為后期的數據分析、計算和應用創造有利的條件。
(5)應用層
數據層實現了原始數據的集中存儲,應用層的功能則是進一步分析、開發、挖掘原始數據,從而發現農業生產的規律、建立相應模型,指導農業生產決策[3-4]。云計算、大數據技術在應用層發揮著重要作用,是數據分析的主要技術手段。
2 物聯網視角下的農業環境大數據系統設計要點
2.1 設計思路分析
2.1.1 農業環境大數據采集
數據是大數據系統的基礎,在設計過程中應該根據農業生產的特點,完成傳感器選型、網絡通信方式選擇,并考慮數據存儲方式、存儲能力等因素。
2.1.2 農業環境大數據存儲
搭建農業環境大數據系統需要解決大規模存儲以及訪問快速響應的問題。在本文的系統設計中將HDFS作為農業環境大數據的存儲方式。HDFS是Hadoop體系中的分布式存儲組件,其本質是一個文件系統,通過流式數據訪問模式存儲超大文件,能夠將數據分塊存儲到硬件集群內的不同機器上。
2.1.3 數據計算和挖掘
初始采集的農業大數據缺乏規律,難以指導農業生產決策,因而需借助算法挖掘數據中的潛在規律。大數據技術中的聚類算法、神經網絡算法、決策樹算法等均能處理農業生產數據,既能分析歷史數據,又能預測作物生長情況。例如,在智慧灌溉中可采用隨機森林算法構建水肥一體化模型。ID3算法、C4.5算法以及CART算法屬于較為成熟的隨機森林算法。在實際應用中先收集農業灌溉及作物生長的大數據,在其基礎上提取數據特征,開展模型訓練,最后形成具有水肥預測能力的灌溉模型,進而指導灌溉活動。
2.2 系統架構及主要子模塊
2.2.1 系統整體架構
(1)數據層
數據層分為數據源存儲模塊和大數據存儲模塊兩部分,前者建立在關系型數據庫(如MySQL、SQL Server)的基礎上,從農業傳感器以及國家農業信息化資源網站獲取原始數據。后者采用HDFS分布式存儲模式,用于匯總經過預處理的合格數據,在匯總的過程中還須根據業務特點實施數據分類。
(2)業務層
業務層采用Apache Spark大數據處理引擎,以聚類算法構建數據分析和計算的模型。Spark中的MLlib機器學習庫可用于迭代計算,利用該擴展庫提高農業大數據的處理效率。
(3)交互層
交互層設計有三大功能,分別為算法管理、數據管理、數據上傳及下載。顯然,交互層服務于人機交互。數據管理模塊以可視化的方式展示數據挖掘的結果,提高管理人員的數據理解效率。
2.2.2 系統主要子模塊
子模塊是對數據層、業務層、交互層的功能細分,在軟件設計中需逐層分解功能需求,以便開展詳細的業務流程設計與程序代碼開發。系統平臺子模塊包括HDFS分布式存儲模塊、源數據存儲模塊、機器學習模塊、算法實現模塊、源數據獲取模塊、數據預處理模塊、SQL查詢模塊、上傳下載模塊。
2.3 系統硬件設計
2.3.1 軟硬件配置
軟硬件資源是農業環境大數據系統的重要組成部分,涵蓋部署在農田環境內的終端傳感器、計算機、操作系統等。計算機為系統提供了計算資源,大數據系統中集成了算法,可批量處理規模較大的數據,對計算機的CPU、緩存、硬盤資源等提出了較高的要求。表1為計算機軟硬件設計方案。
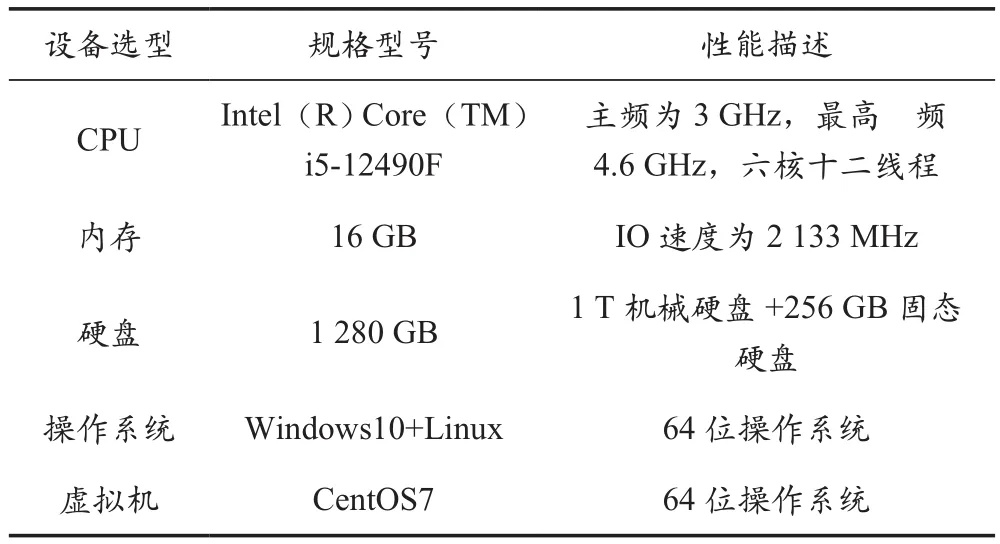
表1 農業環境大數據系統軟硬件資源配置
2.3.2 集群設計
HDFS采用分布式存儲方式,將較大的數據文件分塊存儲在不同的機器上。因此,在系統硬件設計階段應配置集群。具體實現流程為創建CentOS虛擬機、網絡調試、虛擬機克隆、安裝系統基本環境、安裝Hadoop、安裝Apache Spark、配置ssh訪問秘鑰等[5-6]。以上安裝過程推薦采用Linux環境。集群中設置多個Hadoop節點,可根據實際需求進行拓展。
2.4 數據處理功能
2.4.1 數據存儲
(1)數據源存儲
數據源存儲于MySQL數據庫,傳感器采集的數據通過通信網絡上傳至接口,再經過后臺代碼的處理,最終寫入數據庫,網絡中采集的數據也可采用相同的方式進行存儲。設計人員應根據數據特點設計表結構、字段名稱、字段類型以及字段長度等。農業環境中的溫度、濕度、pH值、光照強度等均為數值型數據,因而可采用關系型數據庫。表2為字段設計的實例。
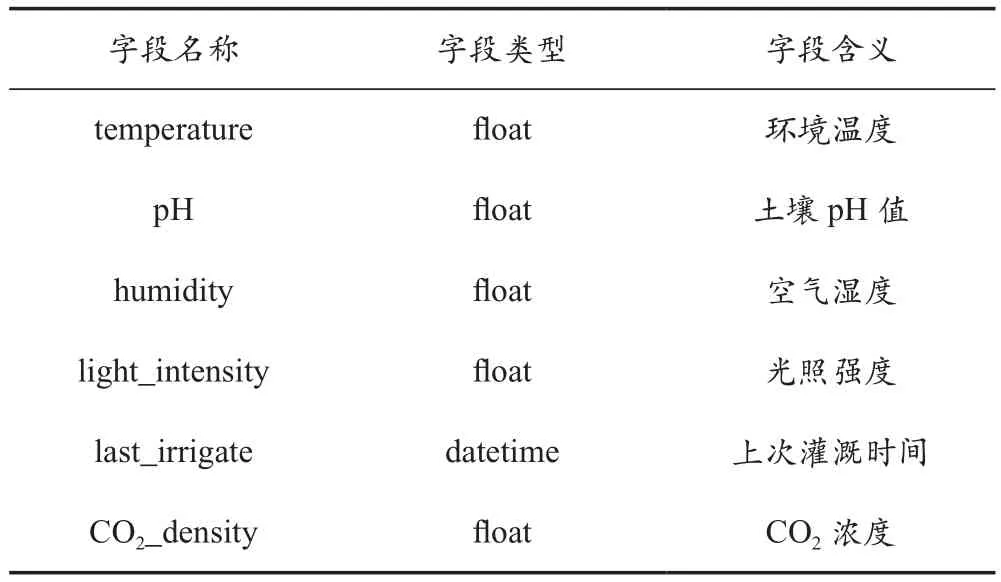
表2 農業環境大數據系統數據源字段存儲實例
(2)HDFS數據存儲
HDFS主要存儲經過預處理的農業環境大數據,Hadoop技術框架中存在Stributed File System(分布式文件系統),由多個機器組成,每臺機器上運行一個DataNode進程,負責管理一部分數據。在所有機器中,由一臺機器獨立運行NameNode進程,客戶端通過該進程實現數據讀寫[7-8]。HDFS通過以上方式實現大數據的分布式存儲。
2.4.2 數據分析
Spark的MLlib機器學習庫集成了數據清洗、SQL查詢、建模等一系列功能,模型建立依賴于算法。在MLlib中內置了通用性的學習算法,包括分類、協同過濾、回歸、聚類等。農業環境大數據系統利用MLlib中集成的GMM算法、K-means算法完成數據分析和建模。軟件工具中提供了統一的算法調用編碼方式。例如,K-means算法的調用代碼為import org.apache.spark.ml.clustering.BisectingKMeans。將預處理后的農業環境大數據導入算法中,再進入數據訓練階段。
2.5 系統應用測試
2.5.1 測試方法
(1)數據源
以某地的高等級西瓜種植區為數據采集的主要對象,棚內設置有多種傳感器,數據采集指標為CO2濃度、植株間距、根系溫度、環境溫度、土壤pH值等[11-12],共計10項內容。實地采集的數據樣本不足以支撐算法模型訓練,因而引入部分網絡開源數據,以提高各項指標的數據量。為檢驗數據量對處理結構的影響,將其設置為三種級別,其對應的數據量分別為1萬組、10萬組、100萬組。數據存儲在HDFS中,文件格式為csv。
(2)實施過程
以JAVA語言編寫算法調用程序以及各類功能性程序,實現數據導入功能;再啟動Hadoop集群,開展數據分析和模型訓練。
2.5.2 結果分析
本系統以K-means算法和GMM算法處理西瓜種植的各類環境大數據,結果見表3所列。K-means算法的關鍵在于K的取值,其決定了數據分簇的數量,表3為K=3時的處理結果。在Spark的MLlib庫中設置有專門的算法性能評估工具,使用該工具評價K在不同取值時的聚類準確率[9-10]。當K=2時,該算法的數據處理準確率達到了86.8%。當K=3時,該算法的數據處理準確率達到了89.5%。另外,系統平臺的數據分析處理能力與其運行時長存在密切關聯,如果數據完全一致,處理時長越短,表明其性能越強。針對三種級別的數據規模,該系統的數據處理時長分別為8 593 ms(數據量為 104)、25 989 ms(數據量為 105)、215 098 ms(數據量為106),可見系統的運行時長與數據量呈正相關。數據分簇意味著產生了三種聚類結果,觀察表3中各項指標的數值,發現其一致性較高,只有個別指標存在小幅差異,如植株間距、根系溫度、土壤濕度,可能原因是各簇的數據樣本有所不同。總體而言,基于物聯網的農業環境大數據系統能夠高效分析和處理農業生產中的各類數據源。
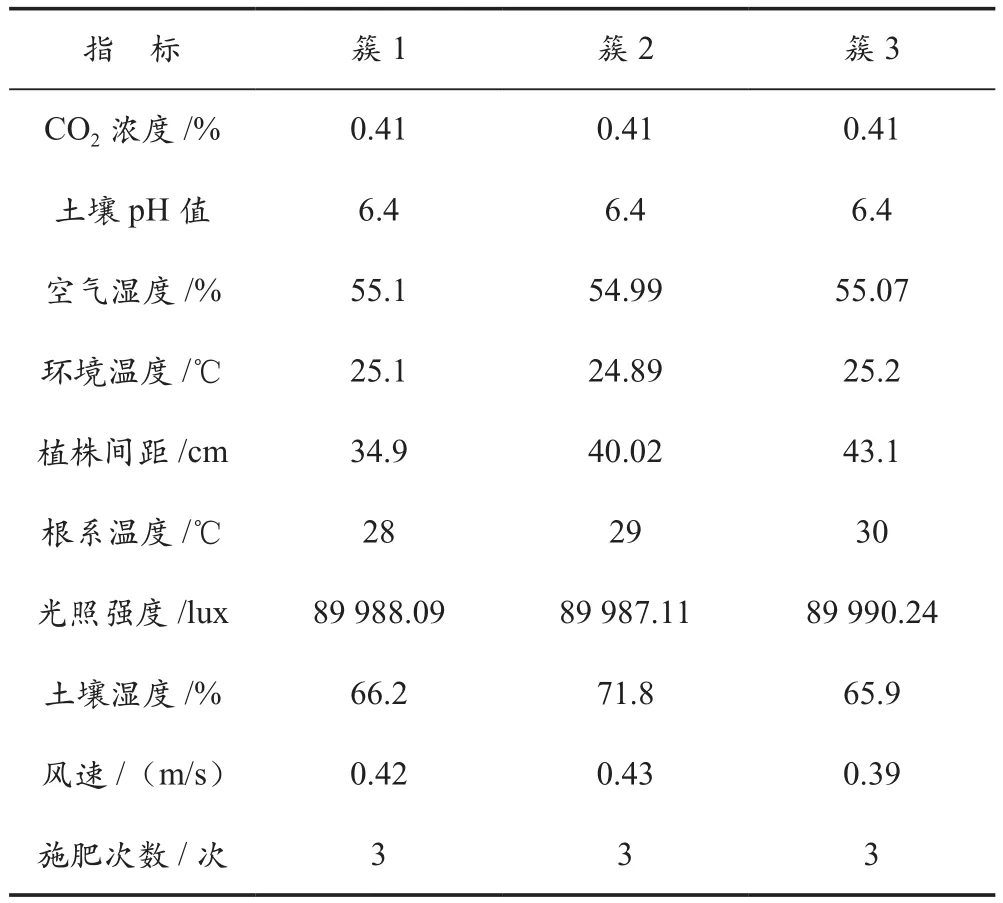
表3 農業環境大數據系統的K-means算法聚類處理結果示例
3 結 語
將物聯網技術、大數據技術和現代化的智能傳感器整合在一起,可建立科學的農業數據服務及管理平臺,為制定農業生產措施提供強大的技術支撐。基于物聯網的農業環境大數據系統由傳感器、計算機、通信網絡、算法程序等軟硬件模塊組成,設計要點為軟硬件交互方式、算法模型、數據存儲方式,具體的解決方案是依托Spark的MLlib庫引入K-means、GMM算法,利用HDFS構建分布式存儲。
猜你喜歡
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
中老年保健(2021年12期)2021-08-24 03:30:40
今日農業(2021年13期)2021-08-14 01:38:18
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
今日農業(2020年15期)2020-12-15 10:16:11
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
