融合ELECTRA 和文本局部信息的中文語法錯誤檢測方法
2023-03-16 10:21:38陳柏霖王天極任麗娜黃瑞章
計算機工程 2023年3期
陳柏霖,王天極,任麗娜,3,黃瑞章
(1.貴州大學 公共大數據國家重點實驗室,貴陽 550025;2.貴州大學 計算機科學與技術學院,貴陽 550025;3.貴州輕工職業技術學院,貴陽 550025)
0 概述
隨著互聯網的普及,中文電子文本的數量呈爆炸式增長趨勢。文本質量參差不齊,語法錯誤會嚴重影響人們的閱讀效率。在中文輔助寫作中,一個完善的中文語法錯誤檢測工具可以幫助學習者快速定位錯誤點和錯誤類型并對文章進行修改,從而提高寫作效率。此外,借助中文語法錯誤檢測工具可以讓審校人員節省大量時間,提高出版業校對過程中的工作效率。然而,面對海量的中文文本,如何快速高效地自動檢測中文語法錯誤成為一個亟需解決的問題。
中文語法錯誤檢測(Chinese Grammar Error Detection,CGED)的目標是自動檢測文本中存在的錯別字、語法和語序錯誤等。對于給定的文本,CGED 的檢測對象包括是否有語法錯誤、錯誤的類型以及錯誤的發生位置。傳統的語法錯誤檢測研究主要集中于英文,大多從全局語義出發,采用機器翻譯等生成式方法對語法錯誤進行檢測和糾正。與英文相比,中文不存在顯著詞邊界,也沒有時態、單數、復數等識別元素,語法復雜度高且蘊含的語義信息豐富,因此,中文語法錯誤檢測更加依賴于文本局部信息,如短語在句子中的語義和位置等。目前,許多研究人員參考了英文語法糾錯方法,使用生成式方法直接進行改錯,跳過了錯誤檢測環節,只有少量研究采用序列標注方法進行中文語法錯誤檢測。然而,生成式方法往往從全局語義出發,忽略了中文文本局部信息對語法檢錯的作用,并存在所需數據量大、難以訓練、可靠性差等問題,使其不能很好地適用于中文語法錯誤檢測任務。因此,如何在數據有限的情況下充分利用文本局部信息提高中文語法錯誤檢測的效果,是該領域的一個重點研究方向。
本文提出應用于中文語法錯誤檢測任務的ELECTRA-GCNN-CRF 模型。不同于生成式方法,本文將語法檢錯任務視為序列標注問題,使得所需數據量和訓練難度降低。在ELECTRA 預訓練語言模型的基礎上,通過門控卷積網絡捕捉文本局部信息,緩解錯誤語義傳播問題,并加入殘差機制避免梯度消失現象,最后通過條件隨機場(Conditional Random Field,CRF)層解碼獲取每個字符的語法錯誤標簽。
1 相關工作
語法錯誤檢測研究可以追溯到20 世紀80 年代,早期大都基于經驗和規則來檢查和糾正語法錯誤。為了識別和處理更復雜的語法錯誤,基于機器翻譯的方法被用于語法錯誤檢測中[1-3],該類方法將文本糾錯視為從錯誤句子到正確句子的“翻譯”問題。在英文文本糾錯中,FU 等[4]將簡單的拼寫錯誤通過規則進行改正,對于改正后的文本,利用Transformer 模型對較復雜的語法錯誤進行修改。ZHAO 等[5]將復制機制集成到機器翻譯模型中,利用輸入句和生成句之間存在大量重疊單詞的特點,將簡單的詞復制任務交給復制機制,使用注意力機制學習難度較大的新詞生成任務。在中文領域,機器翻譯方法大多只研究針對錯別字的糾錯,也被稱為中文拼寫檢查(Chinese Spelling Check)。現有方法主要從以下3 個方面進行研究:
1)使用不同方法對漢字音形混淆集進行建模[6-7],學習錯誤字和正確字之間的映射關系。
2)將漢字的音形特征通過特征嵌入的方式注入模型底層[8-10],使得模型能夠動態學習每個字的特征。
3)使用不同策略對模型產生的候選字進行后處理[11-13],從而提升輸出精度。
由于中文語法錯誤檢測起步較晚,缺乏高質量的大規模訓練語料,使得機器翻譯方法在包含多種語法錯誤的文本中檢測效果不佳。部分研究使用數據增強方法[14-15],通過人工構造中文語法錯誤數據來對現有數據集進行擴充。然而,現有方法模擬出的偽數據的語法錯誤分布往往與真實分布并不十分一致,不能對模型起到很好的訓練作用。因此,有研究人員將中文文本糾錯分解為先檢錯后糾錯的二階段任務,并將中文語法錯誤檢測視為序列標注任務。目前,中文語法錯誤檢測相關研究大都集中在NLPTEA 的CGED 評測任務中。FU 等[16]在BiLSTM+CRF 序列標注模型上添加分詞、高斯ePMI、PMI 得分等先驗知識,并通過不同的初始化策略訓練多個BiLSTM 模型,對其加權融合后通過CRF 層輸出最終結果。2020 年,在NLPTEA 的CGED 評測任務[17]中,WANG 等[18]在Transformer 語言模型的基礎上融入殘差網絡,增強輸出層中每個輸入字的信息,使得模型可以更好地檢測語法錯誤位置。CAO 等[19]在BERT 模型的基礎上加入一種集成基于分數的特征的門控機制,融合了語義特征、輸入序列的位置特征和基于評分的特征。LUO 等[20]使用基于BERT 模型和圖卷積網絡的方法提高基線模型對句法依賴的理解,并在多任務學習框架下結合序列標注和端到端模型來提高原始序列標注任務的效果。
綜上,現有的中文語法錯誤檢測方法通常從全局語義出發,使用生成式方法直接生成正確語句或是在模型中添加人工句法特征,均未有效利用文本局部信息。針對這一問題,本文使用ELECTRA 預訓練模型表征文本信息,在此基礎上,使用門控卷積神經網絡(Gated Convolution Neural Network,GCNN)網絡捕捉文本的局部語義和位置信息,最后使用CRF 進行解碼,不需要額外添加句法特征,從而緩解梯度消失和錯誤語義傳播問題。
2 模型結構
本文提出的ELECTRA-GCNN-CRF 模型整體架構如圖1 所示,該模型自底向上由輸入層、GCNN 層、CRF 層和輸出層組成,其中,GCNN 層的作用是提取文本的局部信息。ELECTRA-GCNN-CRF 模型將中文語法糾錯視為序列標注任務,為文本中的每個字預測對應的語法錯誤標簽,并對文本采用BIO 的標注方式,即字符位于語法錯誤部分開頭時標注為B,位于語法錯誤部分內部時標注為I,非語法錯誤部分的字符標注為O。
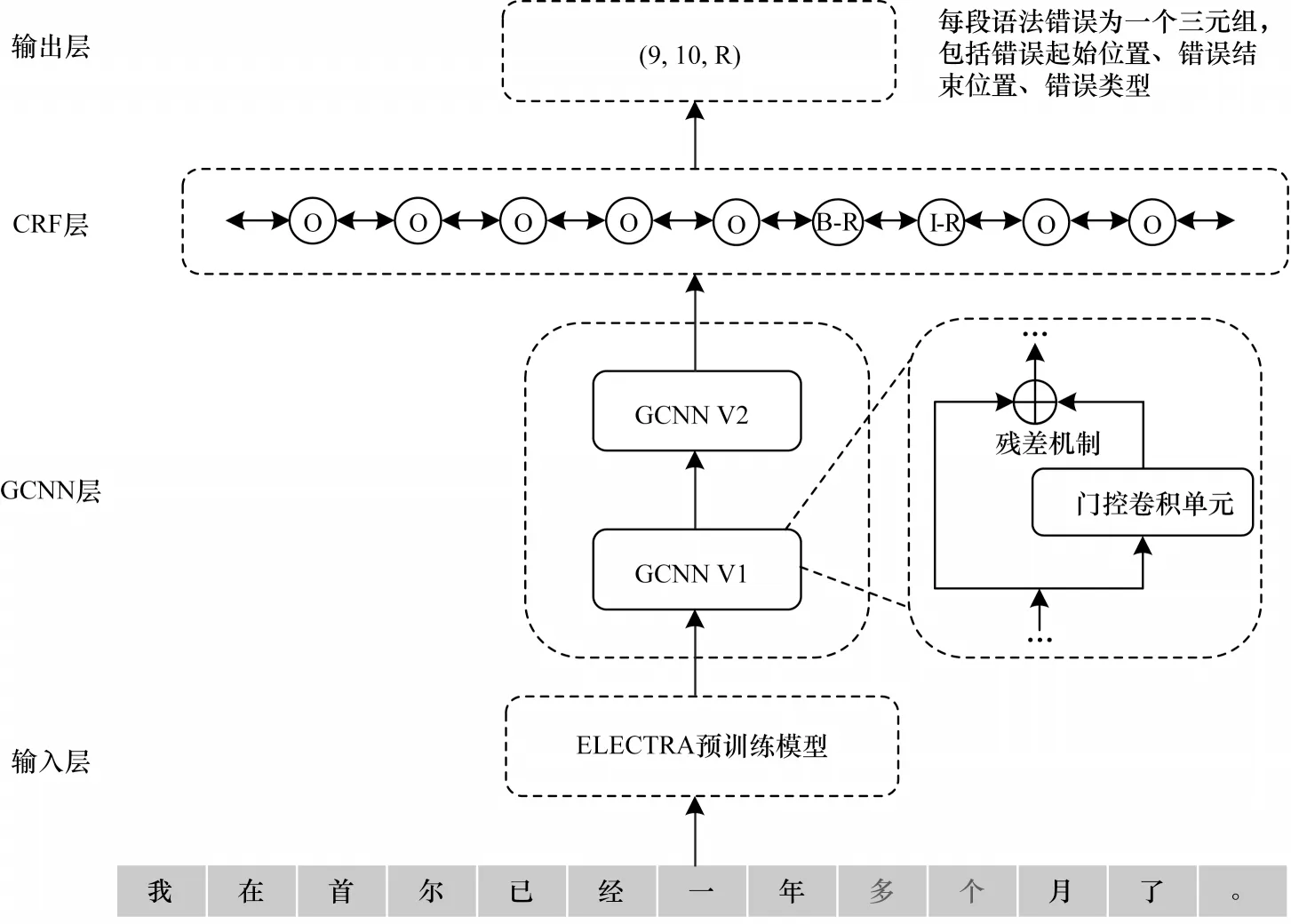
圖1 ELECTRA-GCNN-CRF 模型架構Fig.1 ELECTRA-GCNN-CRF model architecture
2.1 輸入層
文本輸入模型前需要對其進行向量化處理,傳統文本表示模型存在表征能力不足、無法處理一詞多義等問題。預訓練語言模型在大規模無監督語料中進行訓練,通過Transformer 架構對輸入序列進行建模,獲取每個字的上下文語義知識,因此,其可以根據上下文語義動態生成字向量,有效解決一詞多義問題,而且還能根據不同任務對預訓練模型進行微調,從而獲得針對性更強的字向量,適應特定任務的需求。
由于ELECTRA 預訓練語言模型具有訓練效率高、訓練方式能夠避免數據不匹配問題等優點,因此本文選用ELECTRA 預訓練語言模型進行文本向量化。ELECTRA 模型是CLARK 等[21]借 鑒GAN 網絡[22]的思想而設計的,該模型由生成器和判別器兩部分組成,并使用RTD(Replace Token Detection)預訓練方式。生成器是個小型掩碼語言模型,負責對輸入的Token 進行隨機替換,然后讓判別器判別生成器的輸出是否發生了替換,取判別器作為最終的ELECTRA 預訓練語言模型,其具體流程如圖2 所示。這種預訓練方式避免了因“[MASK]”標記導致的預訓練階段與微調階段數據不匹配問題,并且大幅提高了訓練效率,也使ELECTRA 預訓練語言模型對文本中的語義變化特別敏感,適用于語法錯誤檢測任務,其性能優于BERT 預訓練語言模型。
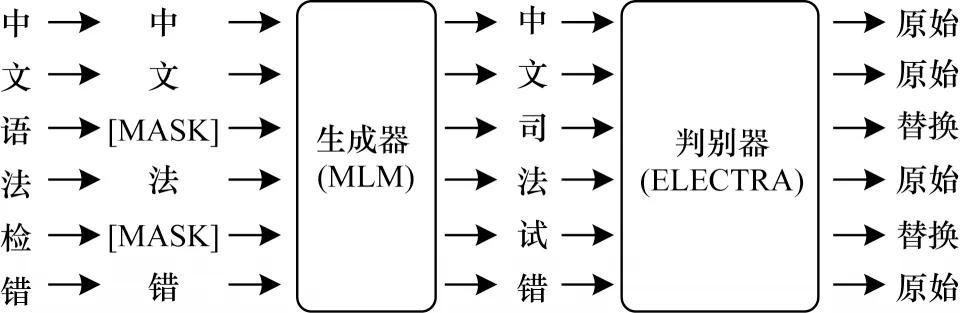
圖2 ELECTRA 預訓練語言模型訓練流程Fig.2 Training procedure of ELECTRA pre-training language model
設輸入序列為X={x1,x2,…,xn},則生成的隱藏層向量Hc為:
2.2 殘差門控卷積神經網絡
為了充分利用文本局部信息進行語法錯誤檢測,降低語法錯誤對上下文語義的影響,本文使用殘差門控卷積神經網絡提取文本的局部特征,此部分由兩層卷積核長度分別為5 和3 的殘差門控卷積層組成,整體模型和殘差門控卷積神經網絡結構如圖3所示。
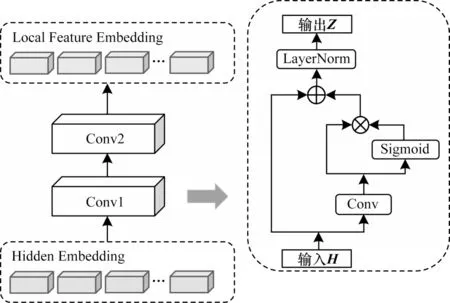
圖3 殘差門控卷積神經網絡結構Fig.3 Structure of residual gated convolution neural network
GCNN 主要由卷積層和線性門控單元(Gate Linear Unit,GLU)組成。卷積層可以提取一定寬度內相鄰詞的局部語義和位置特征,并使由語法錯誤造成的錯誤語義控制在給定寬度內,能夠有效緩解錯誤語義傳播問題。GLU 是一種門控機制,使用Sigmoid 激活函數控制信息流通,能夠保留有效信息,抑制無效信息帶來的影響[23]。
GCNN 單元內的操作可用公式表示為:
其中:Hc表示由輸入層得到的隱藏層向量;Conv 表示卷積操作;σ表示Sigmoid 激活函數;?表示向量的哈達瑪積;C表示經過門控卷積單元的局部特征向量。
為了保留全局語義信息并改善梯度消失問題,本文在GCNN 單元的基礎上引入殘差機制,用公式表示為:
其中:LayerNorm 表示層歸一化;⊕表示向量相加;Z表示經過GCNN 的特征向量。
2.3 CRF 層
CRF 可以解決輸出序列與標注規則不符的問題,如“B-S”標簽后不能接“B-W”標簽等,只能接“I-S”或者“O”標簽。CRF 模型通過特征轉移函數計算概率分數,以判斷當前位置與相鄰位置標簽的依賴關系。
設CRF的輸入序列為Z,則輸出序列的分數函數為:
其中:Tyi,yi+1表示標簽yi到標簽yi+1的 轉移分數;Pi,yi表示第i個字到第yi個標簽的分數。
然后通過條件概率公式計算預測序列Y,以此生成所有可能的標注序列YZ,最后使用維特比算法計算YZ中得分最高的Y:
其中:為真實的標注序列;Y為全局最優標注序列。
2.4 輸出層
ELECTRA-GCNN-CRF 模型在輸出層進行BIO解碼,將語法錯誤標簽轉化為(起始位置,結束位置,語法錯誤類型)格式的三元組,輸出語法錯誤檢測結果。如圖1 中輸出(9,10,R),表明例句中起始位置為“9”、結束位置為“10”的“個月”這一段文本存在語法錯誤,錯誤類型為“成分冗余”。
3 實驗結果與分析
3.1 數據集
為了驗證本文方法的有效性,使用NLPTEA 中文語法錯誤檢測數據集進行實驗,其為一份人工標注過的語法錯誤檢測數據集,語料來源是母語不為漢語的學習者在中文寫作中產生的錯誤樣例。數據集將語法錯誤分為4 種類型:Selection error(記為“S”,即用詞不當);Redundant error(記為“R”,即成分冗余);Missing error(記為“M”,即成分缺失);Word ordering error(記為“W”,即詞序不當)。對于每段語法錯誤,生成“起始位置,結束位置,語法錯誤類型”格式的三元組,如果語句中不存在語法錯誤,則輸出“correct”。數據集中的語句可能沒有語法錯誤,也可能包含一種或多種語法錯誤,數據樣例如表1 所示。

表1 NLPTEA 中文語法錯誤檢測數據集數據樣例Table 1 Data sample of NLPTEA Chinese grammar error detection dataset
本文收集了NLPTEA 歷年的CGED 任務評測數據集,去重之后對數據進行BIO 標注,將數據集給出的標簽映射到每一個字符上,并按照8∶2 的比例劃分訓練集和驗證集,最終在2020 年的NLPTEA CGED 任務的測試集上進行測試,數據集規模如表2所示。
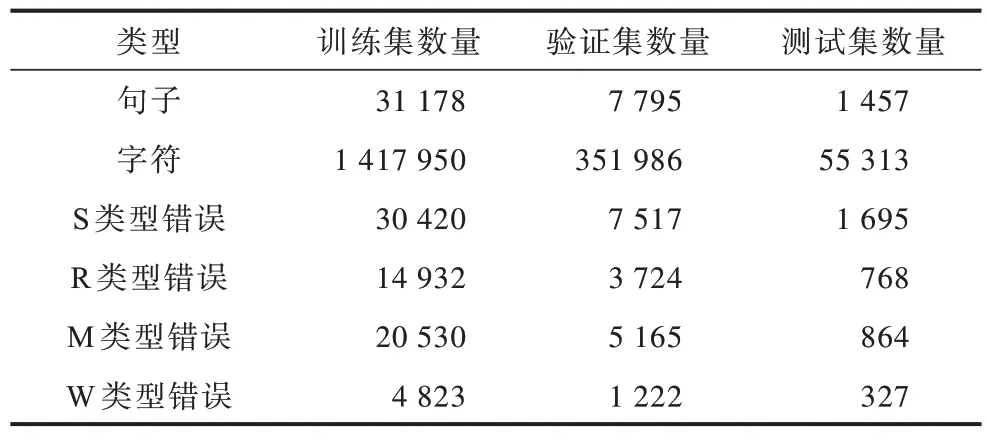
表2 數據集規模Table 2 Dataset size 單位:個
3.2 評價指標
本文采用NLPTEA 的CGED 任務評價指標作為本次實驗的評價標準。語法錯誤檢測模型需要從以下3 個方面對語句進行檢測:
1)Detection-level,即檢測層,對于輸入的語句,判斷其是否包含語法錯誤。
2)Identification-level,即識別層,對于輸入的語句,判斷其包含哪幾種語法錯誤。
3)Position-level,即定位層,對于輸入的語句,判斷每段語法錯誤的起始位置和類型。Position-level是語法錯誤檢測最關鍵的部分。
對于上述3 個方面,模型使用以下指標進行評價:
3.3 參數設置
實驗中模型參數設置如下:隱藏層維度為768;ELECTRA 預訓練模型[24]的Transformer結構為12層;多頭注意力機制的頭數為12;每批次大小為240;優化器采用Adam;丟棄率為0.15;最大迭代次數為20;使用早停法緩解過擬合;CRF 層的學習率為10-3,其他層的學習率為10-5;GCNN 層卷積核寬度分別為5 和3。
3.4 對比實驗結果分析
為了驗證本文模型的有效性,將其與NLPTEA 2020的CGED 任務中表現優異的檢測模型進行橫向比較與分析,對比模型包括ResELECTRA_ensemble[18]、BSGED_ensemble[19]、StructBERT-GCN[20]和StructBERTGCN_ensemble[20]。4 種對比模型具體描述如下:
1)ResELECTRA_ensemble,該模型將殘差網絡與Transformer 結構進行融合,使用ELECTRA-large預訓練語言模型參數進行初始化,最后使用80 個單一模型進行集成。
2)BSGED_ensemble,該模型在BERT 的輸出中加入文本位置和PMI特征,并使用門控機制進行控制,通過BiLSTM 網絡獲取上下文信息,然后使用CRF 層進行解碼,最后利用16 個單一模型進行集成。
3)StructBERT-GCN,該模型的訓練方式比原版BERT 增加字序預測和句序預測2 個新的訓練目標,同時將句法依存關系使用GCN 網絡進行建模并融入訓練過程。
4)StructBERT-GCN_ensemble,該模型是38 個StrcutBERT-GCN-CRF 模型和65 個多任務訓練的StructBERT-CRF 模型的集成。
在NLPTEA 2020 的中文語法錯誤檢測數據集上,本文模型與基線模型的對比結果如表3 所示,其中,ELECTRA-GCNN-CRF 和 ELECTRA-GCNNCRF_ensemble 為本文模型,后者是10 個單一模型的集成,最優結果加粗標注。從表3 可以看出,在單一模型中,本文模型較StructBERT-GCN 在3 個方面的F1 值均取得明顯進步,在所有模型中,ELECTRAGCNN-CRF_ensemble 在Detection-level 中的F1 值接近最優性能,在Identification-level 和Position-level方面取得了最優的F1 值。
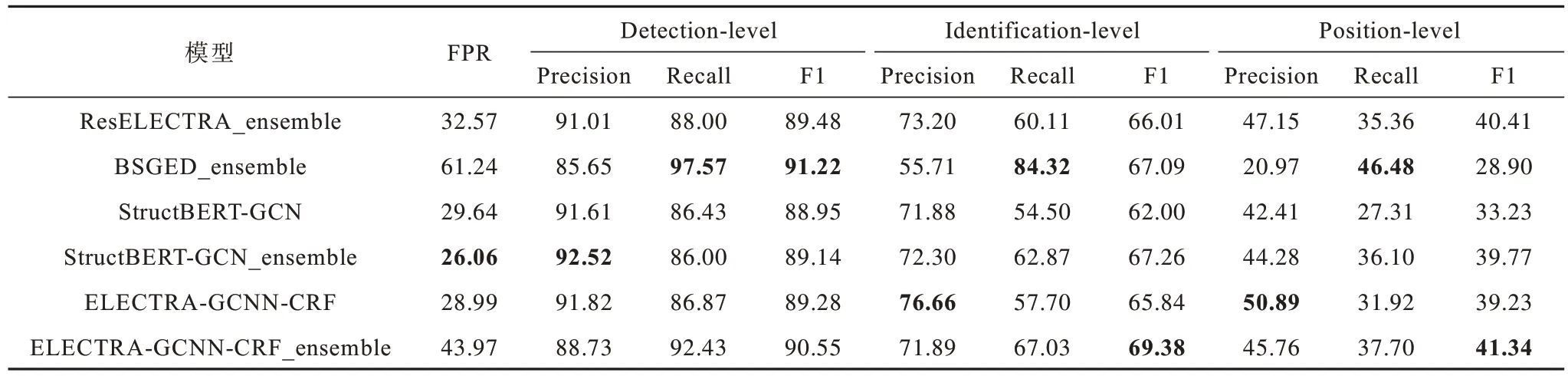
表3 本文模型與NLPTEA 2020 的CGED 任務評測模型性能對比Table 3 Performance comparison between this model and CGED task evaluation models of NLPTEA 2020 %
3.5 消融實驗結果分析
為了驗證本文模型各部分結構的有效性,采用以下模型進行消融實驗:
1)ELECTRA-softmax,僅使用ELECTRA 預訓練語言模型。
2)ELECTRA-CRF,使用ELECTRA 預訓練模型和CRF 層。
3)BERT-GCNN-CRF,將本文的預訓練語言模型替換為BERT-base 預訓練模型[25],其余部分不變。
4)ELECTRA-BiLSTM-CRF,將本文模型的GCNN層替換為2 層BiLSTM 神經網絡,其余部分不變。
5)ELECTRA-GCNN-CRF-RES,在本文模型的基礎上去掉GCNN 層的殘差機制,其余結構和參數不變。
6)ELECTRA-GCNN-CRF,本文提出的中文語法錯誤檢測模型。
消融實驗結果如表4 所示。從表4 可以看出:ELECTRA-softmax、ELECTRA-CRF 和ELECTRAGCNN-CRF 在3 個方面的F1 值均依次上升,證明了GCNN 層和CRF 層的有效性;ELECTRA-BiLSTMCRF 在Detection-level 中取得最高的F1 值,表明在判斷語句是否有語法錯誤的任務中,使用BiLSTM網絡捕捉上下文信息可以獲得更好的效果;對比ELECTRA-GCNN-CRF 和BERT-GCNN-CRF 可以看出,在參數規模相同的情況下,使用ELECTRA 預訓練模型性能遠優于BERT 預訓練模型,證明ELECTRA 生成的上下文語義特征向量更能反映語義變化情況,對錯誤語義更加敏感,能夠獲取基礎的語法錯誤特征,結合后續的局部信息提取層能夠獲得語法錯誤的相對位置和局部語義信息,從而提升語法錯誤檢測效果;ELECTRA-GCNN-CRF 對比ELECTRA-BiLSTM-CRF,在Position-level 的F1 值提升了1.37 個百分點,即使用GCNN 網絡相較于BiLSTM 網絡能夠更好地提取文本特征,緩解語法錯誤對于上下文語義的影響;ELECTRA-GCNNCRF-RES 對 比ELECTRA-GCNN-CRF,在Positionlevel 的F1 值下降了3.97 個百分點,表明加入殘差機制可以使模型更好地識別語法錯誤邊界。
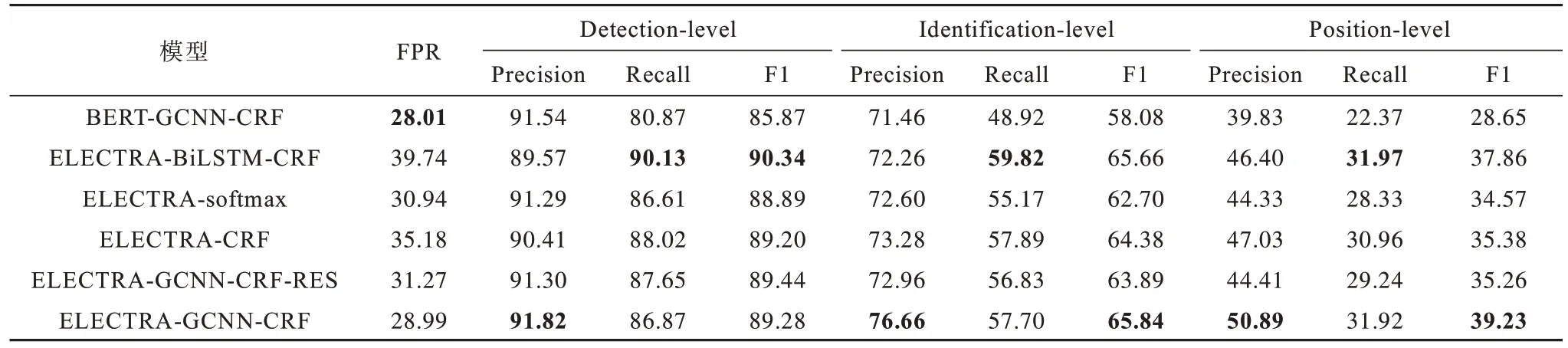
表4 消融實驗結果Table 4 Ablation experimental results %
3.6 語法錯誤對比實驗結果分析
為了進一步比較不同模型在不同類型語法錯誤中的識別效果,本文分別計算BERT-GCNN-CRF、ELECTRA-BiLSTM-CRF、ELECTRA-softmax、ELECTRACRF 和ELECTRA-GCNN-CRF 模型在4 種語法錯誤中Position-level 的精確率、召回率和F1 值,其中精確率如圖4 所示。從圖4 可以看出,本文模型在4 種語法錯誤中均能取得最高的精確率,這是由于語法錯誤通常出現在文本局部,本文模型通過GCNN 網絡能夠學習到每種語法錯誤的相對位置、局部語義信息等重要特征,因此,相比于其他模型,本文模型能夠更加精準地識別語法錯誤的起止邊界和類型,從而提升中文語法錯誤識別精度。在W 型錯誤中,ELECTRA-softmax 和ELECTRA-CRF 模型的對比結果表明CRF 層對于識別語序錯誤具有重要作用。
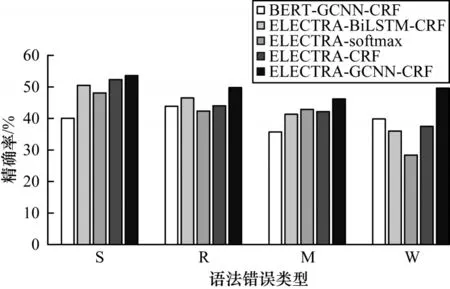
圖4 5 種模型檢測不同類型語法錯誤時的精確率對比Fig.4 Comparison of precision of five models in detecting different types of grammar errors
召回率對比情況如圖5 所示,從圖5 可以看出,和精確率情況類似,本文模型在S 型、R 型和W 型的語法錯誤中均能取得最高性能,然而,在M 型語法錯誤中,ELECTRA-BiLSTM-CRF 模型的召回率比本文模型高出3.02%,原因可能是成分缺失錯誤往往出現在句子的主語或謂語部分,識別此種類型的錯誤需要更大范圍的上下文乃至全局語義信息,在全局語義特征提取方面GCNN 網絡不如BiLSTM。
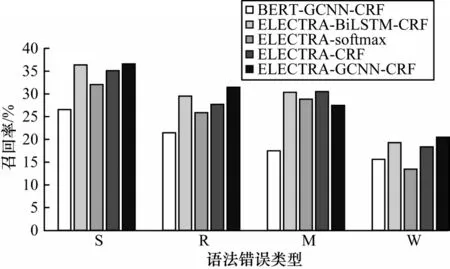
圖5 5 種模型檢測不同類型語法錯誤時的召回率對比Fig.5 Comparison of recall of five models in detecting different types of grammar errors
為了綜合衡量模型性能,平衡精確率和召回率,本文對比不同模型的F1 值,結果如圖6 所示。從圖6可以看出:基于BERT 的中文語法錯誤檢測模型的F1 值在3 種語法錯誤中遜于其他模型,僅在W 型錯誤中優于ELECTRA-softmax 模型,說明ELECTRA模型的預訓練方式對中文語法錯誤檢測任務有顯著效果;在基于ELECTRA 的模型中,對于M 型語法錯誤的識別F1 值均相差無幾,說明基于ELECTRA 的模型均對M 型語法錯誤較為敏感;在其他3 種類型的錯誤中,本文模型的F1 值相較對比模型均有不同程度的提升。以上結果表明本文模型在中文語法錯誤檢測任務中具有有效性。
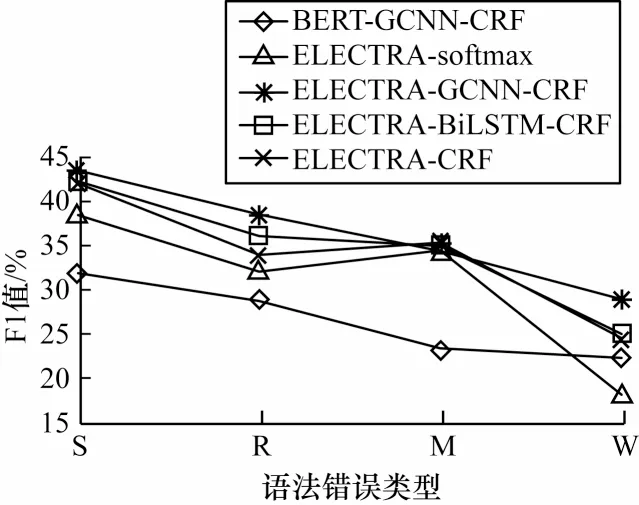
圖6 5 種模型檢測不同類型語法錯誤時的F1 值對比Fig.6 Comparison of F1 values of five models in detecting different types of grammar errors
4 結束語
針對現有中文語法錯誤檢測模型無法充分利用文本局部信息導致語法錯誤檢測效果較差的問題,本文提出一種中文語法錯誤檢測模型ELECTRAGCNN-CRF。將中文語法錯誤檢測視為序列標注問題,通過ELECTRA 語言模型獲取文本的語義表征,結合殘差門控卷積神經網絡和CRF 識別語法錯誤。在NLPTEA CGED 2020 公開數據集上的實驗結果表明,該模型對中文語法錯誤檢測效果具有提升作用,消融實驗結果也驗證了模型各部分結構的有效性。
中文語法具有較高的復雜性,本文所提模型仍然存在很多不足,在錯誤類型和位置的識別檢測方面有很大的提升空間。下一步將針對目前缺乏大規模中文語法錯誤數據集的問題,研究新的數據增強方法,使得構造的偽數據能夠很好地模擬真實的語法錯誤,從而獲得更優的語法錯誤檢測效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
