基于LSTM結合注意力機制的長文本分類優化研究
2023-03-11 21:07:12于慶洋
互聯網周刊 2023年3期

摘要:文本分類是指用計算機對文本(或其他實體)按照一定的分類體系或標準進行自動分類標記。伴隨著信息的爆炸式增長,人工標注數據已經變得耗時、質量低下,且受到標注人主觀意識的影響。因此,利用機器自動化對文本進行標注具有一定的現實意義,將重復且枯燥的文本標注任務交由計算機進行處理能夠有效克服以上問題,同時所標注的數據具有一致性、高質量等特點。其應用場景眾多,包括:情感分析、主題分類、意圖識別等;其分類標簽可以是:情感分析(積極、消極、中性)、主題分類(歷史、體育、旅游、情感)等。傳統的文本分類早期是通過模式詞、關鍵詞等,同時結合一些規則策略進行。此方法的缺點很明顯,人工成本高,且召回率比較低。此后,使用經典傳統的機器學習方法做文本分類任務初顯成效,即“特征工程+淺層分類模型”,被稱為傳統機器學習方法。近些年,伴隨深度學習的異軍突起,基于深度學習的文本分類方法興起,本文基于LSTM文本分類,針對LSTM網絡結構的缺陷,引入注意力機制Attention,優化文本分類模型,在文本長度較長的情況下,效果尤為顯著。
關鍵詞:文本分類;LSTM;注意力機制;長文本
1. 背景
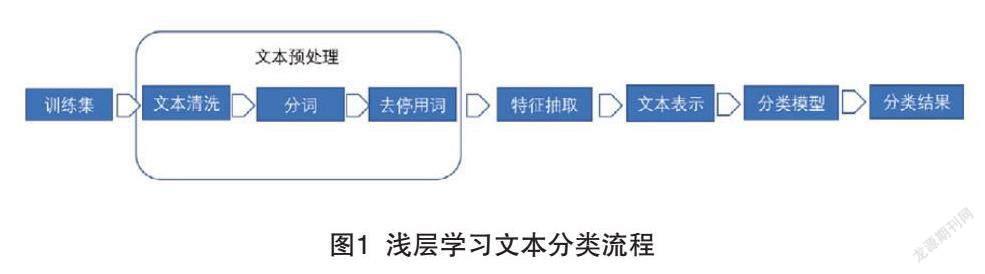
本文主要闡述的是基于機器學習、深度學習的文本分類算法,專家規則類不在討論范圍。傳統的機器學習算法(淺層學習)做文本分類一般流程如圖1所示。
文本預處理是通用的,可以看到除去文本預處理部分,最主要的兩部分是“文本特征表示”和“分類模型”。而在基于淺層模型的文本分類任務中,由于模型往往是線性類的簡單模型,表征與泛化能力較弱,并且由于模型的簡單性,若想達到較好的效果,需要做很復雜的特征工程與精細化的文本處理,且強依賴算法工程師的工程經驗,人工成本高。深度學習興起后,大批量的文本分類任務開始使用深度學習。相較于傳統的淺層學習,深度學習不需要過于繁重的手動特征工程。目前在深度學習中,主要用來做文本分類的網絡有兩種:遞歸神經網絡(RNN)網絡、LSTM網絡。本文基于LSTM網絡的針對長文本分類的結構性缺陷,提出引入注意力機制網絡來進行重要信息的編碼提取,顯著提升了模型效果與性能。
2. 遞歸神經網絡
由于文本類型的數據往往前后是有著很強的聯系,故使用機器來對文本數據進行分析時,模型需要具備一定的記憶能力,由于傳統神經網絡結構的天然局限性,無法做到這點。遞歸神經網絡(以下簡稱RNN)的出現解決了這個問題,通過在網絡中添加循環,它能讓信息被“記憶”得更長久。RNN是有循環的,簡單來說就是允許信息從當前步驟傳遞到下一個步驟。其實RNN是由一個個與全連接網絡相同的普通神經單元構成的,只不過這些神經單元在輸出信息的同時,會將這些信息進行向后傳遞,這種網絡結構天然滿足序列類型數據的前后關聯邏輯,可以說是為此類數據量身定做的特定模型結構。
3. LSTM網絡
LSTM是RNN網絡的一個升級版,它的提出是為了緩解RNN網絡中存在的長期依賴導致的梯度消失問題。
3.1 長期依賴問題
RNN最具吸引力的一點,是它能把之前的信息連接到當前的任務上。比如我們可以用之前的詞來理解現在這一步的詞,如果能建立起這種潛在關聯,RNN的前途將不可限量。那么,是否能真的做到?根據過往經驗,不一定做得到,而且即便是做得到,效果大多數也會大打折扣。尤其是在較長的文本中,有時,相距較遠的詞語之間的關聯性仍然是比較強的,例如,假設一段長文本有N個詞(N為較大的數),在這段話中,很可能第N個詞和第一個詞也有比較強的相關性,此時,當我們要預測第N個詞的時候,需要用到第一個詞的信息,但由于文本很長,雖然RNN的特殊結構使其具備一定的記憶性,但第一個詞與第N個詞之間距離較長,此時已經超出了RNN的記憶能力范圍,心有余而力不足,即RNN無法學習到這種長期的依賴性。此時,LSTM出現了。長期短期記憶網絡,通常被稱為“LSTM”也是一種RNN變體,只不過比較特殊,通過其特殊的網絡結構,能緩解梯度消失問題,從而學習到長期依賴性。其結構設計的初衷完全是針對上述RNN的不足,具備序列長期依賴性的學習能力。其根本原因是由于其特殊的設計結構,緩解了梯度消失問題,將該記住的記住,該遺忘的遺忘。例如人類的大腦,如果將這個世界所有的信息均強行記住,那么一定會導致關鍵信息的遺忘丟失。LSTM相比于RNN的差異性是:標準RNN中只包含單個tanh層的重復模塊。雖然LSTM也有與之相似的鏈式結構,但不同的是它的重復模塊結構與RNN大不相同,是4個以特殊方式進行交互的神經網絡,如圖2所示。
如圖3所示,從某個節點的輸出到其他節點的輸入,每條線都傳遞一個完整的向量。粉色圓圈表示pointwise操作,如節點求和,而黃色框則表示用于學習的神經網絡層。合并的兩條線表示連接,分開的兩條線表示信息被復制成兩個副本,并將傳遞到不同的位置。
3.2 LSTM背后的核心原理
LSTM的關鍵是神經單元cell的狀態,即貫穿圖2頂部的水平線。cell狀態有點像傳送帶,它只用一些次要的線性交互就能貫穿整個鏈式結構,這其實也就是信息記憶的地方,因此信息能很容易地以不變的形式從中流過,為了增加/刪除cell中的信息,LSTM中有一些控制門(gate)[1]。它們決定了信息通過的方式,包含一個sigmoid神經網絡層和一個pointwise點乘操作。sigmoid層輸出0到1之間的數字,點乘操作決定多少信息可以傳送過去,當為0時,不傳送;當為1時,全部傳送[2]。像這樣的控制門,LSTM共有3個,以此保護和控制cell狀態,如此,便保證了LSTM可以學習到長期信息。
4. 注意力(Attention)機制
在深度學習領域,模型往往需要接收和處理大量的數據,然而在特定的某個時刻,往往只有少部分的某些數據是重要的,這種情況就非常適合Attention機制發光發熱。舉一個簡單的小例子,在機器翻譯中,例如要對“who are you”進行中文翻譯,顯然正確的答案是“你是誰”。那么仔細想一下,這個“你是誰”一定是一個詞、一個詞翻譯出來的。繼續思考,機器在翻譯“誰”的時候,前面的“who are you”這三個詞里面哪個詞對此刻的翻譯比較重要一些,還是說應該是同等重要,答案顯然是“who”這個詞此時比較重要,這就是注意力機制:對于不同的輸入部分,經過注意力網絡算子的計算,賦予不同部分(隱藏層或者輸出層)動態權重,從而實現動態加權的效果。一般情況下,在深度學習中,注意力機制主要有兩個主要部分構成:注意力打分函數與加權平均,后者理解起來不困難,前者比較難理解,通俗地講,打分函數就是為后面的加權平均提供權的計算,不同的注意力機制主要區別就在于注意力打分函數的不同。假設現在我們要對一組輸入H=[h1,h2,h3,...,hn],使用Attention機制計算重要的內容,這里往往需要一個查詢向量query(這個向量往往和你做的任務有關) ,然后通過一個打分函數計算查詢向量query和每個輸入hi之間的相關性,得出一個分數。接下來使用softmax函數對這些分數進行歸一化,歸一化后的結果便是查詢向量query在各個輸入hi上的注意力分布 a=[a1,a2,a3,...,an],其中每一項數值和原始的輸入 H=[h1,h2,h3,...,hn]一一對應。以ai為例,相關計算公式如下:
這里計算出的α即為注意力權值,為后面的加權平均提供了依據。
5. 基于LSTM網絡結合注意力機制優化的長文本分類
上述提到,基于LSTM提取文本的語義,相較于基礎RNN,在學習長距離依賴方面,具有明顯的優勢。但如果文本長度較長,LSTM網絡也還是會出現將離當前詞距離較遠的詞信息遺忘掉的情況,如果每一步驟或者大部分步驟都出現類似的問題,會造成對全文的理解出現較大的偏差,導致文本分類的準確性大大下降[3]。
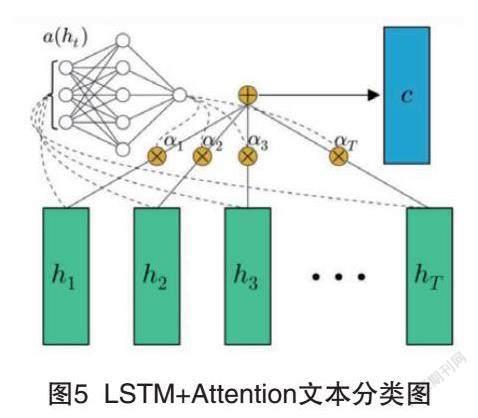
如圖4所示,假設文本長度為T,則在經過T個時間步驟后,LSTM會輸出T個能表征對應文本信息的隱向量h,根據前述闡釋,由于LSTM輸出的每個隱向量都會送入下一個LSTM的神經單元,故最后一個時刻的輸出hT是包含了全文信息的,可使用此hT來做分類,送入softmax函數,從而輸出分類概率分布。如果我們在對長文本做分類時,完全按照此做的話,會出現前面提到的問題。經過深入分析,原因如下:
(1)雖然LSTM有更強的記憶能力,能較好地保留距離自己較遠的詞信息,但如果文本長度較長,效果也是有限的,隨著文本長度的增加,蘊含的信息量也越發增大,會導致信息覆蓋,導致LSTM可能因為一些不重要的信息,遺忘掉了對于文本理解更重要的某些重要的詞信息。
(2)只使用最后一個時刻的輸出向量來表征全文信息,致使LSTM丟掉了前面很多對理解全文有重要提示作用的信息。綜上兩點,不難想出對應的解決思路:將LSTM每個時刻的輸出向量hi均用作分類任務,形成一個對全文的綜合信息理解的向量h,那么這個h如何形成呢?最直接能想到的就是將所有時刻的hi做一個平均計算AVG。但有沒有更好的方式呢?深度思考一下,每個時刻的隱向量對于全文的理解貢獻度都是一樣的嗎?答案多半是否定的。那么如何做更好呢?結論呼之欲出,對于不同的文本,其每個位置的詞語所含信息對于理解該文本的貢獻度是不同的,針對此現象,如果我們能對這些詞語對應的LSTM輸出隱向量做一個加權平均,做到對于不同文本,每個位置的詞對其權重不同,不僅能有效提取信息,并且解決了上述LSTM的一個大問題:能夠將LSTM遺忘掉的信息重新輸入回來,那么根據上面的闡述,很容易聯想到注意力機制Attention。在LSTM基礎上引入注意力機制作為長文本分類模型的優化原理如圖5所示。
在LSTM網絡的輸出端加入Attention網絡α(ht), 用于計算每個時刻輸出隱向量的注意力權值αi, 注意力打分函數有以下幾種選取:
1)加性模型:s (h,q)=vTtanh(Wh+Uq)
2)點積模型:s(h,q)=hTq
3)縮放點積模型:s(h,q)=hTqD
4)雙線性模型:s(h,q)=hTWq
以上公式中的參數W、U和v均是可學習的參數矩陣或向量,D為輸入向量的維度。下邊我們來分析一下這些分數計算方式的差別。本文采用第一種加性模型的方式作為注意力打分函數,計算出注意力分值后,將加權平均后的h送入softmax函數,輸出分類概率結果。
6. 實驗結論
分別單獨使用LSTM與引入注意力機制Attention后的LSTM做長文本分類的準確度評估實驗結論如表1所示。
可見,引入注意力機制Attention的LSTM做長文本分類無論在召回率、精確率、F1方面,相比于與原始的LSTM,均有顯著的效果提升。
結語
本文通過探究從原始的遞歸神經網絡RNN到LSTM的核心原理,透過原理研究其本質特性,首先,通過分析得出RNN對于文本的長距離學習依賴問題;再次,通過對LSTM核心單元結構的剖析了解到,對于長文本而言,LSTM有時在長距離依賴方面的學習能力仍然是不足的,且很容易在全文理解上找不到重點而導致信息偏差。由此引出本文重點,即注意力機制Attention。由于Attention的結構特性,將其引入LSTM后完美地解決了上述問題。利用注意力機制的權值自動學習及加權平均,不但加強了LSTM對某些重點序列詞語信息的記憶,更有針對性地看到了全文重點,使模型對長文本的理解更具備全局性及重點性,實驗證明,引入注意力機制的LSTM在長文本分類方向的各項指標均顯著高于單純的LSTM,對長文本分類研究發展做出了重要貢獻。
參考文獻:
[1]張文靜,張惠蒙,楊麟兒,等. 基于Lattice-LSTM的多粒度中文分詞[J].中文信息學報,2019,33(1):18-24.
[2]關鵬飛,李寶安,呂學強,等.注意力增強的雙向LSTM情感分析[J].中文信息學報.2019,33(2):105-111.
[3]胡朝舉,梁寧.基于深層注意力的LSTM的特定主題情感分析[J].計算機應用研究,2019,36(4):1075-1079.
作者簡介:于慶洋,碩士,數據算法專業經理,研究方向:推薦系統、自然語言處理、深度學習、機器學習。
