基于組合神經網絡的軟件命名實體識別仿真
2023-03-11 05:02:40盧青華袁麗娜
計算機仿真 2023年1期
盧青華,袁麗娜
(廣州大學華軟軟件學院,廣東 廣州 510990)
1 引言
命名實體識別為自然語言技術中的一種[1],通過文本中的特殊意義將文字和詞匯加以分類,并根據劃分的區域準確識別人名、時間、地名等信息[2],為智能人工等高級NLP任務提供準確且有效的信息,目前的命名實體識別需要消耗大量的人力和物力,為改變這一現狀,現對命名實體識別展開研究[3]。
嚴紅[4]等人提出基于深度神經網絡的軟件命名實體識別方法,該方法通過卷積神經網絡獲取軟件字符特征前需要抽取出軟件的詞嵌入、字符嵌入和語句特征向量,并在雙向門控循環神經網絡和條件隨機場識別器的基礎上根據詞嵌入、字符特征和語句特征向量實現軟件命名實體識別,該方法直接提取文本中的語句特征向量,沒有將命名實體中的文字和詞匯映射到低維度空間獲取低維度空間向量,因此在識別命名實體過程中無法全面提取命名實體特征標簽,導致其中存在大量冗余信息。馮艷紅[5]等人提出基于BLSTM的軟件命名實體識別方法,該方法利用文章詞向量描述命名實體的上下文信息,采用詞向量構成命名實體的前綴、后綴和領域信息,同時基于標注序列標簽的相關性約束BLSTM代價函數將領域知識嵌入模型代價函數中以此增強模型的識別能力,最終實現軟件命名實體識別,該方法在識別命名實體過程中沒有在字特征向量的基礎上加入詞特征和詞性特征向量再獲取標注序列的標簽,導致該方法的標簽不完整,以此降低了識別性能,不能完全識別命名實體,導致F1值較低。李健龍[6]等人提出基于雙向LSTM的軟件命名實體識別方法,該方法利用無監督訓練得出軟件中語料的分布式向量,基于雙向LSTM遞歸神經網絡模型加入字詞結合的輸入向量和注意力機制對雙向LSTM遞歸神經網絡模型進行擴展和改進,從而實現軟件命名實體識別,該方法在識別命名實體前沒有采用組合神經網絡預測命名實體標簽再進行命名實體識別,無法完善命名實體識別結果,KS值較低。
為解決上述方法中存在的問題,提出基于組合神經網絡的軟件命名實體識別仿真。
2 基于組合神經網絡的命名實體標簽預測
在識別命名實體過程中可將識別問題轉化成對文本中的各個字進行一次“SBEIO”的標簽預測問題[7],目前標注字體的方法大多通過人工選取相對應的特征模板后進行標注,由此會消耗大量的人力和物力,為避免浪費,可通過組合神經網絡模型對NLP任務進行標注,組合神經網絡模型通過訓練獲取可代表文本詞匯特征的低維度詞向量[8],此方法即可以提高效率也可節省人力、物力和財力等資源消耗,且通過訓練得到的詞匯向量之間存在一種語義聯系,此聯系可直接提高命名實體的識別召回率,除此之外,組合神經網絡模型還可輕松添加額外的命名實體特征信息[9]。
組合神經網絡模型由輸入層、組合神經網絡層和輸出層三大部分組成,其中輸入層的主要功能為映射輸入層中文字的詞向量,且每個字的向量都為固定的低維度向量,同時將所有詞向量保存到Lookup內,每當輸入層出現新的詞匯,輸入層都會對新詞匯進行映射,同時重新排列組合輸入層內的所有向量,將排列組合后的向量當作下一層的輸入向量再進行下一步操作。組合神經網絡層由一個非線性層和兩個線性層構成,此層的主要作用為連接上下層。輸出層主要利用Viterbi算法總結出上層語句和詞匯中的最優標簽序列。
2.1 詞向量特征
假設軟件中存在一個字典DC和詞典DW,并將字向量和詞向量分別存儲在字向量矩陣Mc∈Rdc×|DC|和詞向量矩陣Mw∈Rdw×|DW|內,且|DC|和|DW|為字和詞的向量大小,dc和dw為字和詞的向量維度。
2.1.1 字特征
令軟件中某句中文為c[1:n],此句由n個字向量ci構成,其中ci屬于字典DC,且i大于等于1小于等于n。
提取c[1:n]中各個字的特征向量當作組合神經網絡中的輸入層,為簡化輸入特征,利用映射函數Ψc(·)∈Rdc表達其特征,映射后的特征表達式為
Ψc(ci)=Mc
(1)
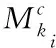
將字向量簡化后,結合上下文收集盡可能多的關于字ci的信息,通過滑動窗口在語句字數有差異時提取字ci的特征,可保證特征的完整性。令字窗口的面積為ωc,將文本中的每個字從左到右依次輸入到滑動窗口,可獲取其輸入特征為
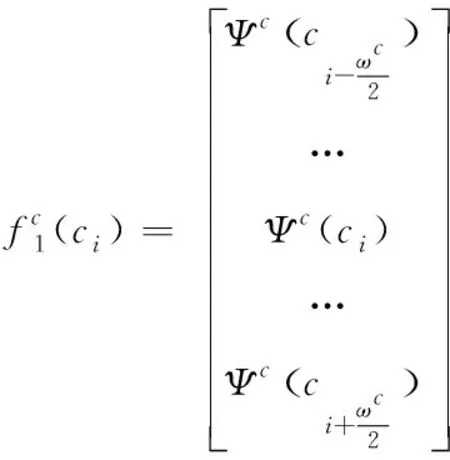
(2)
當存在字不屬于詞典的情況時,需將此字通過映射設置成固定的向量,并將每個維度空間中的向量進行歸一化[10]。根據組合神經網絡模型可知,在輸入層得到歸一化向量后,將字特征向量輸入組合神經網絡中,字向量會按照線性轉換、非線性轉換和線性轉換的順序提取出字特征,其中非線性轉換向量可根據sigmoid函數進行計算,則非線性轉換提取字特征的表達式為
g(x)=1/(e-x+1)
(3)
令Tc為命名實體識別的標簽類別,由此可知|Tc|維向量為組合神經中的輸出,即當組合神經網絡中含有5個節點時,ci中含有每個標簽概率的大小就為|Tc|輸出向量,則ci中具有標簽的概率表達式為
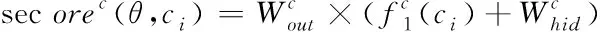
(4)
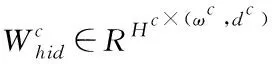
2.1.2 詞特征
提取詞特征與提取字特征的方法大致相同,首先設置詞特征窗口為ωw,并通過映射函數Ψw(·)∈Rdw進行提取,映射函數方程式為
Ψw(wj)=Mw
(5)
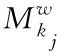
則根據上述方程可將詞wj的輸入特征設置成
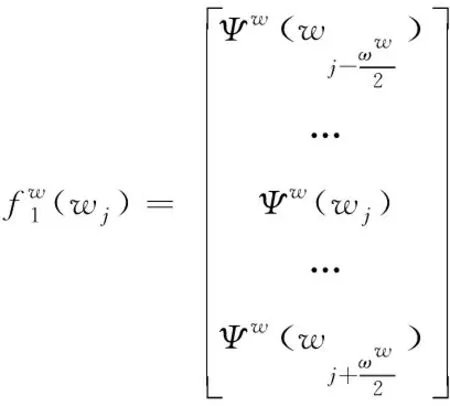
(6)
詞向量與字向量的不同點為詞向量可以隨時加入新特征,以此方便特征提取,因為命名實體為根據外界語言環境進行命名,因此可輕易抽取詞性屬性,從而得出軟件語句之間的結構關系,所以為優化命名實體識別的性能,需要在詞特征內添加詞性屬性。
假設POS為詞性標注集,令單位方陣為MP,且MP屬于R|POS|×|POS|,則詞wj的標記映射函數表達式為
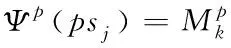
(7)
式中,psj表示詞性wj被標記,k表示psj的相應詞性序列,Ψp(psj)表示詞性向量,且Ψp(psj)屬于R|POS|。
假設軟件中的某個語句為利用m個詞w[1:m]構成,則此句話中詞特征的表達式為

(8)
式中,ps[1:m]表示詞性標注的序列。
上述中的詞性向量為One-hot向量,因此可以首尾拼接詞向量和其詞性向量,使其成為詞特征。
2.1.3 字詞結合特征
由于只利用字向量進行命名實體識別無法全面理解其含義,又由于組合神經網絡中的窗口對文字有字數要求,且無法將其擴展后識別,因此不能精確地識別命名實體。而詞向量太過依靠外界環境,導致外界環境的好壞直接影響命名實體識別的準確性,并且詞向量自身具有一個可將毫無相關的詞匯通過映射形成特殊詞向量的特性,因此在識別過程中,極有可能將特殊向量當作正常向量進行提取,導致識別結果中出現大量錯誤特征,所以結合兩者的優點構成字詞向量結合的形式進行命名實體識別,進而提高命名實體識別的性能。
假設字詞向量結合的識別方法中含有一種字詞映射關系ci?wj,且wj=ci-t…ci…ci+k(k≥0,t≥0)。獲取字ci的相鄰信息及上下文信息,設置字窗口的大小為ωc,詞窗口的大小為ωw,則根據從左到右的順序滑動窗口,得出字詞結合的輸入特征表達式為
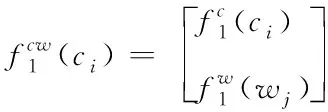
(9)
由于在字詞結合中添加詞性特征,因此在提取字特征的過程中可自動擴展字詞,并以擴展后的詞匯進行字和詞的特征連接,將其輸入到組合神經網絡中,則特征表達式為
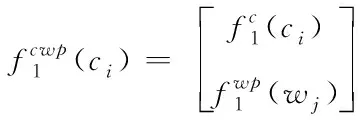
(10)
若T為字詞標簽集合,經過組合神經網絡模型,輸出的向量為|T|維,將其加入到字向量預測標注概率中,則其軟件命名實體函數表達式為
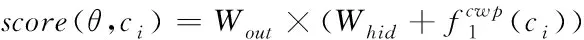
(11)
式中,Whid∈RH×(ωcdc+ωwdw)表示預測標簽過程中的訓練參數,Wout∈RH×|T|表示除預測標簽外的訓練參數,H表示隱藏節點數量。
3 基于支持向量機分類器的軟件命名實體識別
目前的文本分類器中只有支持向量機適用于命名實體識別,此分類方法根據將風險降到最小的原則,將決策平面由超平面構成。支持向量機在命名實體識別中表現突出,它可以將字詞向量利用相應的非線性映射函數映射到高維度特征空間中,在高維度特征空間中獲取最優決策平面,實現命名實體樣本準確識別,同時保證類別間隙較大方便查看類別[11]。
假設軟件命名實體的訓練集合為S,此訓練集可利用超平面進行線性分割,則S的表達式為
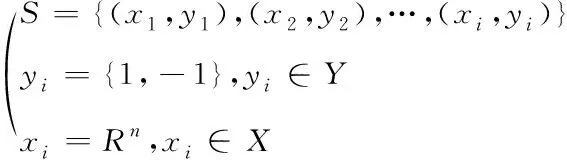
(12)
利用最小二乘法支持向量機計算最優決策平面就為計算二次規劃,則其表達式為
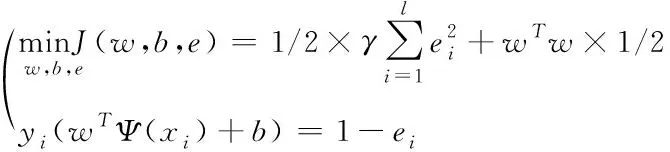
(13)
式中,γ表示訓練過程中的懲罰參數。
并通過拉格朗日函數計算出一次規劃,其表達式為
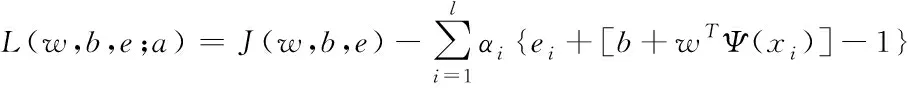
(14)
其中,αi表示拉格朗日函數中乘子的支持值,ei表示訓練樣本中的錯誤分類。
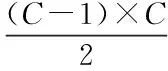
為進一步確定命名實體的類別[14-15],得出其識別決策函數表達式為
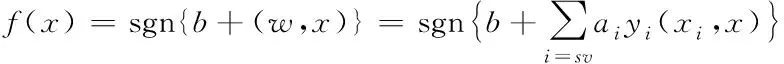
(15)
根據式(16)的結果可確定出命名實體的最終類別,根據以上步驟實現軟件命名實體的識別。
4 實驗與結果
為了驗證所提方法的整體有效性,對基于組合神經網絡的軟件命名實體識別方法、文獻[4]方法和文獻[5]方法進行精度等級(P@N)、F1值和KS曲線進行測試。
4.1 精度等級(P@N)
利用精度等級P@N在訓練集合中任意選取一定數量的樣本進行命名實體識別,正確識別的樣本個數與總個數的比值即為P@N,根據圖1可知,在多次迭代中,選取10個命名實體進行識別,文獻[4]方法的P@N最高值為0.6,且該方法在識別過程中結果不穩定,文獻[5]方法雖穩定,但此方法的P@N僅為0.5,只有所提方法不僅穩定而且P@N達到0.9,因為所提方法在實現命名實體識別前將命名實體中的所有文字和詞匯通過映射獲取其低維空間向量,全面提取命名實體特征標簽,因此可以更加省時省力的識別命名實體,同時排除冗余信息,進而提高精度等級。
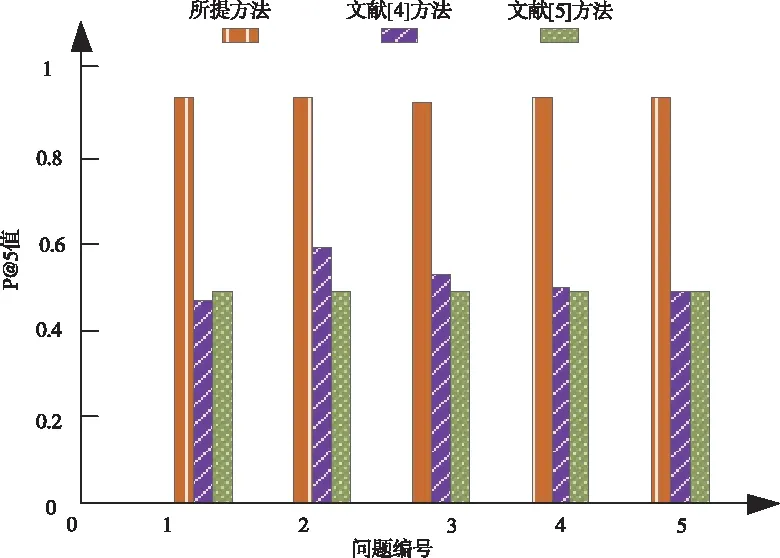
圖1 不同方法的精度等級(P@N)
4.2 F1值
在不同向量維度空間下對比三種方法識別命名實體的F1值,經實驗后發現特征向量的維度大小直接決定最終的識別結果,因此提高向量維度可以提高識別性能,進而提高F1值。
由于傳統方法只利用字特征向量提高F1值,忽略了詞特征和詞性特征向量,因此F1值還有待升高。所提方法在字特征向量的基礎上加入詞特征和詞性特征向量再進行命名實體識別,將識別性能發揮到極致,進而大大升高F1值。
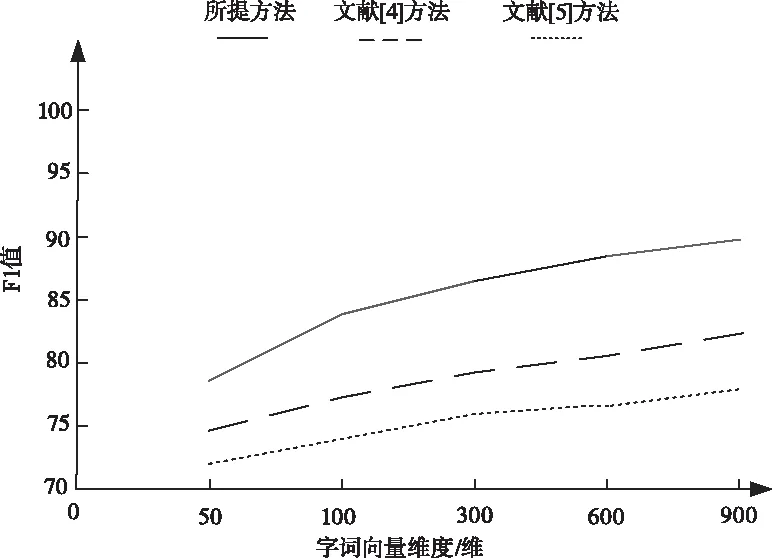
圖2 不同方法的F1值
4.3 KS曲線
KS值為真正類率(FPR)和假正類率(TPR)的比值,將KS值設為縱坐標,橫坐標為識別閾值,即類別的概率分布,通常情況下KS值在[0,1]范圍內越大越好。
實驗結果顯示,所提方法的KS值最大為0.5,接近最優KS值,由此可證明利用所提方法進行命名實體識別可區分出最精確的類別并實現命名實體識別。這是因為該方法在識別命名實體前采用組合神經網絡方法預測命名實體標簽后再進行命名實體識別,不僅方便后續識別,也可完善命名實體標簽類別,進而提高了KS值。
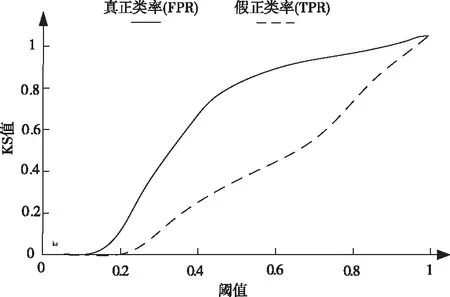
圖3 KS曲線
5 結束語
為解決目前軟件命名實體識別所存在的問題,提出基于組合神經網絡的軟件命名實體識別方法,該方法首先預測軟件中的識別標簽,并通過支持向量機進行標簽識別,從而實現軟件命名實體識別,解決精度等級(P@N)低、F1值低和KS曲線低的問題,為智能人工等高級NLP任務節約了大量資源成本。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
