廣義最大覆蓋模型的新型人類學習優化算法
2023-03-11 05:02:02張楓雪
計算機仿真 2023年1期
張楓雪,劉 勇
(上海理工大學管理學院,上海 200093)
1 引言
廣義最大覆蓋模型是在傳統覆蓋模型基礎上發展而來,當需求點在設施點的最小覆蓋距離(或時間)內時,服務質量最優;當超過最小覆蓋距離(或時間)時,服務質量單調遞減;當超過最大覆蓋距離(或時間)時,服務質量變為零。廣義最大覆蓋模型將服務質量引入到覆蓋選址問題中,更加符合實際問題的需要。Jia等為了應對大規模突發事件,考慮距離對于服務質量的影響,建立廣義最大覆蓋模型來解決需求不確定性和醫療供應不足的問題[1]。Ozbaygin等考慮覆蓋率,研究了時間受約束的最大覆蓋銷售員問題,其目的是找到一個訪問某個客戶子集的旅行團,從而使有限時間內覆蓋的需求量最大化[2]。馬云峰等基于時間滿意度函數提出廣義最大覆蓋選址模型,考慮時間因素對企業選址的影響[3]。王文峰等基于傳統的最大覆蓋模型提出應急服務設施的廣義覆蓋選址模型,為醫療救援物資的選址提供解決方案[4]。于冬梅等建立共享不確定需求和中斷情景下服務能力有限的應急設施廣義覆蓋選址魯棒優化模型,有效解決需求不確定和中斷風險下選址布局網絡的構建問題,確定最優的選址分配方案[5]。韓珣等通過信號強度函數和概率函數,刻畫聯合覆蓋對顧客選擇的影響,建立競爭環境下的廣義自提點選址模型,有利于企業通過自提點的布局獲取競爭優勢[6]。
廣義最大覆蓋模型為設施點布局規劃提供了可行有效的模型,如何求解該模型一直是研究熱點。該模型與傳統覆蓋模型一樣是NP-hard問題[7]。目前,常用的算法有分支切割算法[2]、拉格朗日松弛算法[1,3],遺傳算法[1,6],分布估計算法[4]和灰狼優化算法[5]等。這些算法為求解廣義最大覆蓋模型提供了思路,但是存在易早熟收斂和計算精度低等問題。為有效求解廣義最大覆蓋模型,本文提出一種新型人類學習優化算法(Novel Human Learning Optimization,NHLO),數值實驗驗證新算法可以顯著提高模型的計算精度,為該問題的求解提供新途徑。
2 廣義最大覆蓋模型
2.1 問題描述及假設
已知候選設施點和需求點,以及候選設施點與每個需求點之間的距離,規定了設施點和需求點的距離限制。在給定的限制條件下,使設施點盡可能多的覆蓋需求點,提供更好的服務。服務的質量通過覆蓋率體現,覆蓋率越大表明應急資源分布越合理。該模型提出的基本假設如下:
1)設施點和需求點是離散的,有n個需求點,有m個候選設施點。
2)每個設施點提供服務的能力是足夠的。
3)每個需求點只被一個設施點覆蓋。
4)設施點向需求點提供的服務質量隨著與需求點的距離增加而降低。
2.2 符號定義
1)I={1,2,…n}:需求點的集合。
2)J={1,2,…m}:設施候選點的集合。
3)s:待建設施點的數量,其中1≤s≤m。
4)wi:需求點i處的人口數量。
5)dij:需求點i和設施點j之間的距離。
6)L,U:分別表示最小距離值和最大距離值。
7)α:表示需求點i對距離的敏感性。
8)λij:表示模型中的需求點i被設施點j覆蓋的程度,0≤λij≤1。
9)xj:0-1變量,當設施點j被選中時為1,否則為0。
10)yij:0-1變量,當需求點i被設施點j覆蓋時為1,否則為0。
2.3 覆蓋水平函數
引入最小距離L和最大距離U兩個值,當設施點和需求點之間的距離在設定的最小距離之內,屬于完全覆蓋;當設施點和需求點的距離大于最小距離小于最大距離時,屬于部分覆蓋;當設施點和需求點的距離大于最大距離時,屬于沒有任何覆蓋[8]。
覆蓋水平函數λij[9]如下
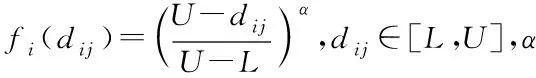
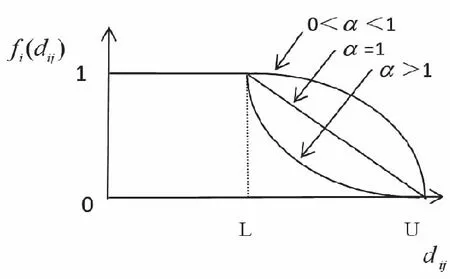
圖1 覆蓋水平函數曲線
2.4 數學模型

(1)
s.t.
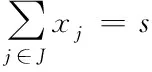
(2)
yij≤xj?j=J?i∈I
(3)
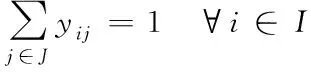
(4)
xj={0,1} ?j∈J
(5)
yij={0,1} ?i∈I?j=J
(6)
其中,式(1)表示考慮覆蓋水平的需求量最大;式(2)表示需要建設的應急設施點為s個;式(3)只有當候選設施點j被選中時,需求點i才能被候選設施點j覆蓋;式(4)每個需求點i都被一個且只被一個設施點j覆蓋;式(5)和(6)分別表示xj和yij是屬于0或者1的決策變量。
3 廣義最大覆蓋模型的新型人類學習優化算法
人類學習優化算法是Wang等人在2014年提出,通過模仿人類的學習行為來進行優化搜索。人類學習優化算法包括以下幾個部分[10]:
1)初始化
人類學習優化算法個體采用二進制編碼,具體方法如式(7)所示
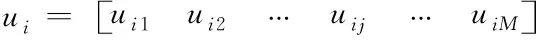
(7)
1≤i≤N,1≤j≤M
其中,ui表示第i個個體,且uij∈{0,1};N表示群體規模;M表示解的維數。
2)隨機學習算子
初始階段,由于人沒有知識和經驗,會隨機獲取各種知識。基于此,算法設計了隨機學習算子,如式(8) 所示
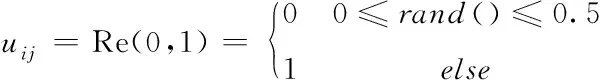
(8)
其中,rand()是介于0到1之間的隨機數。
3)個體學習算子
當人們有了一定的知識和經驗后,個體會將隨機學習過程中獲得的知識和經驗運用到自身實踐中。根據自己的經驗學習解決問題,不斷的總結和更新自身的個體學習知識庫IKD,建立個人知識數據庫來儲存個人最好的學習經驗。在算法中,設計個體學習算子,如式(9)和(10)所示
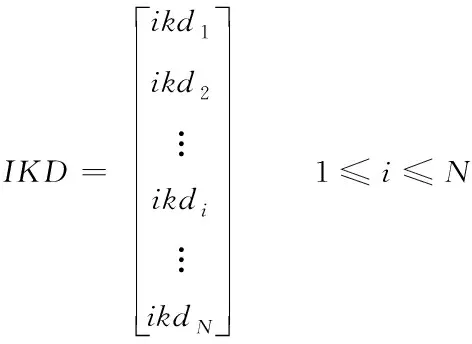
(9)
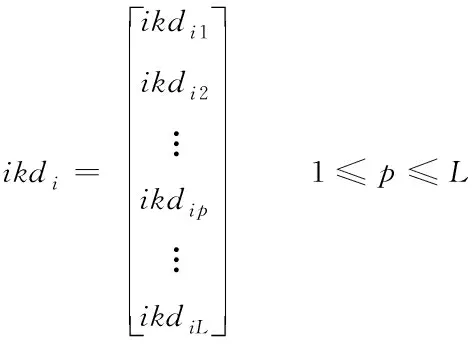
(10)
其中,ikdi表示第i個人的個體學習知識庫IKD;ikdip代表第i個人的第p個為最佳解;L表示ikdi的規模。
當進行個體學習時,它會根據ikdi中的知識生成新的解決方案,其操作方式如式(11)所示
uij=ikdipj
(11)
其中,ikdipj代表第i個人的第p個為最佳解第j個分量。
4)社會學習算子
人類除了通過自身學習獲得直接經驗外,還可以向其他人學習獲得間接經驗,從而對知識庫進行補充更新,為了模擬這種學習策略,建立社會學習知識庫SKD。在算法中,設計社會學習算子,如式(12)所示
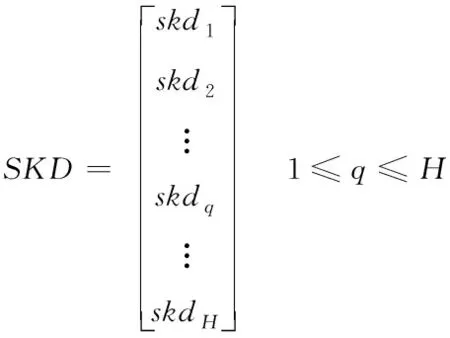
(12)
其中,skdq表示SKD中的第q個解。
基于SKD中的知識,可以按照式(13)進行社會學習,從而在搜索過程中產生更好的解決方案。
uij=skdqj
(13)
其中skdqj表示SKD中的第q個解第j個分量。
綜上所述,人類學習優化算法使用隨機學習算子、個體學習算子和社會學習算子,在IKD和SKD中存儲的知識基礎上產生新的解決方案并尋找最優解。這三種學習算子的選擇策略如式(14)所示
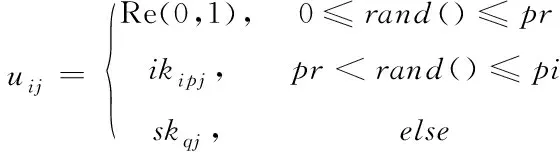
(14)
其中,pr是選擇隨機學習的概率,(pi-pr)和(1-pi)的值分別表示選擇個體學習和社會學習的概率。
5)更新
當所有個體求出解后,需要根據適應度函數計算每個個體的適應度,從而更新IKD和SKD。對于IKD的更新,當新生成的解的適應度優于IKD中的最差解的適應度或者IKD中的解個數沒有達到預先定義的值時,新生成的解儲存在IKD中。SKD的更新也如IKD一樣,如果當前一代的最優解優于SKD中最差的解,或者SKD中當前解的個數小于預先定義的個數,則將當前代的最優解保存在SKD中。
有三種不同方式的學習策略,分別是隨機學習、個體學習和社會學習,經過這三種方式的學習會不斷的更新個體學習知識庫和社會學習知識庫。學習系統結構圖如圖2所示。
不同于模擬簡單生物行為的蟻群優化算法、微粒群優化算法和蜂群優化算法等,人類學習優化算法是模擬人類學習行為,為復雜問題的求解提供了新方法。人類學習算法在求解經典組合優化問題——背包問題時,表現出良好的優化性能。但是近期的研究[11-13]表明,和其它智能優化算法一樣,基本人類學習優化算法存在的計算精度低和早熟收斂等問題。
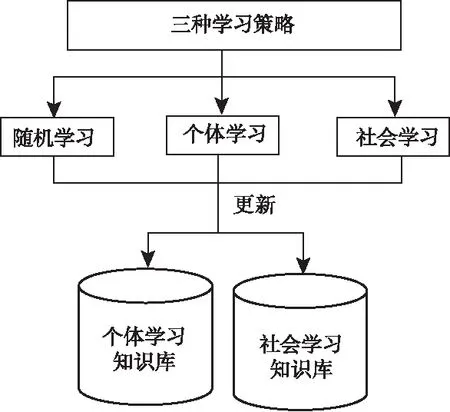
圖2 學習系統結構圖
為有效求解廣義最大覆蓋問題,基于人類學習行為特點,本文設計一種新型人類學習優化算法。在學習的早期階段,由于自身知識和經驗不足,隨機性學習的可能性比較大。但是隨著學習的深入,向自我和他人學習的能力越來越強。而根據式(14),隨機學習算子、個體學習算子和社會學習算子的選擇策略根據概率進行設置,不符合人們學習過程的特點。因此,對式(14)進行調整,重新設計這三種學習算子的選擇策略。隨著學習過程的不斷深入,隨機學習的概率逐漸下降[13],個體學習和社會學習的概率增加。隨機學習的概率不再是常數,而是隨迭代次數遞減,具體公式如式(15)
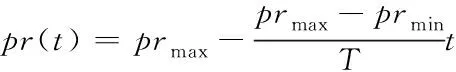
(15)
當個體選擇向自我學習還是他人學習時,也不再根據概率確定,而是根據個體能力確定。當個體對應的函數值大于平均值時,說明個體學習效果較好,繼續保持個體學習;當個體對應函數值小于等于平均值時,說明個體學習效果不佳,需要向其他人學習。
本文提出的自適應學習策略如式(16)所示
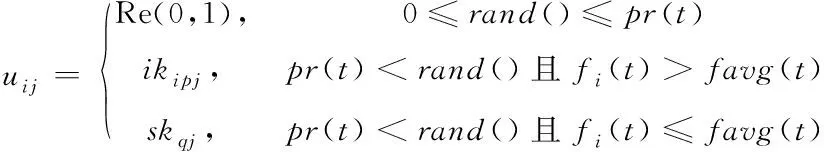
(16)
其中fi(t)表示第t次迭代時第i個個體的函數值,favg(t)表示第t次迭代時所有個體函數值的平均值。
在求解時,等式約束(2)采用罰函數進行處理。此外,選址決策變量xj和算法中的尋優個體ui相對應。例如,備選設施點有5個,尋優個體ui維數設為5。如果第一個分量取0,表示不選第一個候選點;如果第二個分量等于1,表示選第二個候選點,以此類推。在確定好選址決策變量xj后,根據覆蓋水平函數將最近的候選設施點分配給需求點,從而確定分配變量yij。
綜上所述,求解廣義最大覆蓋模型的新型人類學習優化算法的偽代碼如下:
輸入:種群的規模N,維數M,隨機學習的概率pr。
輸出:種群最優解。
1)根據N和M初始化種群
2)計算每個個體適應度
3)個體學習知識庫IKD和社會學習知識庫SKD初始化
4)計算隨機學習的概率pr(t)
5)通過執行式(16)的學習算子生成新的解
6)if 0≤rand()≤pr(t)
7)通過隨機學習算子生成新的解
8)elseif rand()>pr(t) and fi(t)>favg(t)
9)通過個體學習算子生成新的解
10)elseif rand()>pr(t) and fi(t)≤favg(t)
11)通過社會學習算子生成新的解
12)end if
13)計算新的個體的適應度,更新IKD和SKD
14)end for
學習過程流程圖如圖3所示。
在圖3中,用算法是否達到最大迭代次數來表示學習目標是否完成。
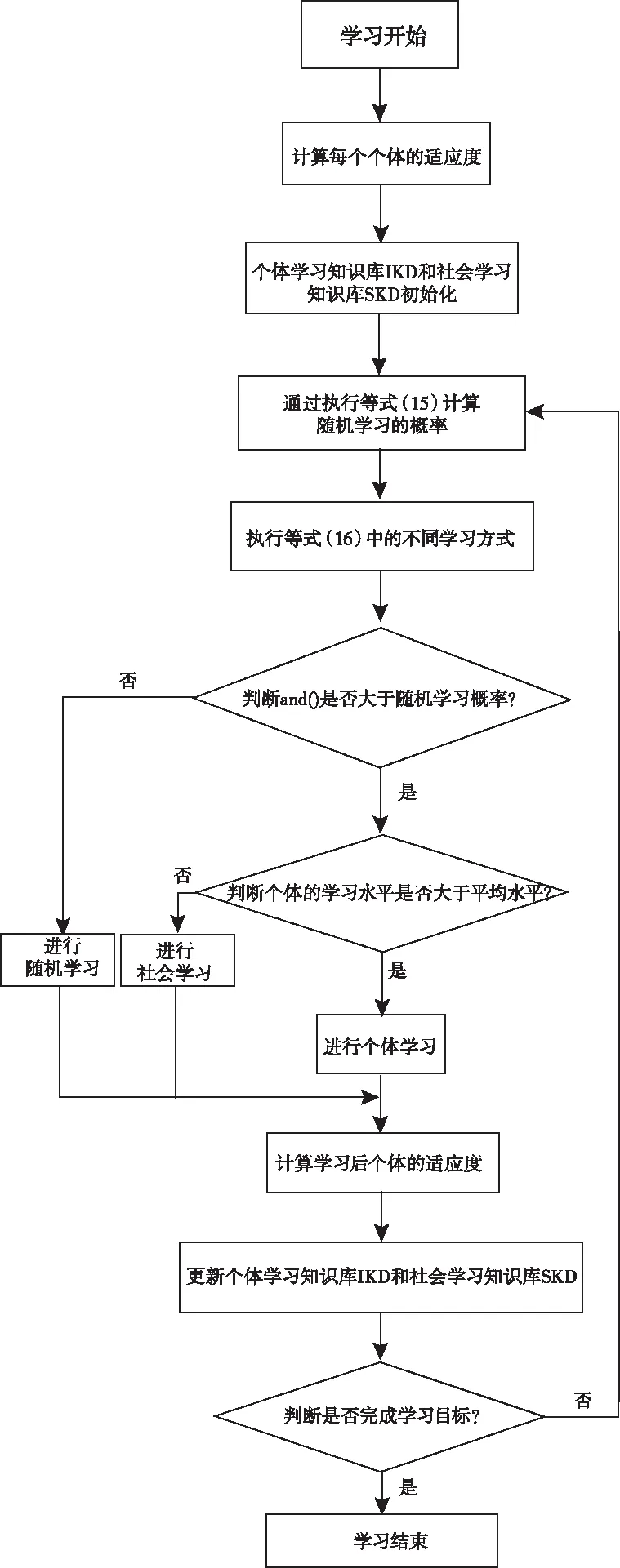
圖3 學習過程流程圖
4 數值實驗
采用三組實驗,測試新型人類學習優化算法的性能,并將其和遺傳算法(Genetic Algorithm,GA)[14]、微粒群優化算法(Particle Swarm Optimization,PSO)[15]、最有價值球員算法(Most Valuable Player Algorithm,MVPA)[16]和人類學習優化算法(Human Learning Optimization,HLO)[11]的計算結果進行比較。
在第一組實驗中,需求點規模為50個,備選設施點規模為30,考慮新建設施點數量分別為2個和3個兩種情況;在第二組實驗中,需求點規模為100個,備選設施點規模為50,考慮新建設施點數量分別為3個和4個兩種情況。第一組實驗中候選設施點和需求點的位置在[1,50]內均勻分布,第二組實驗中候選設施點和需求點的位置在[1,100]內均勻分布,兩組實驗的人口數量均在[1,100]內隨機生成。廣義最大覆蓋模型中的參數α=0.5。新型人類學習優化算法的參數設置如下: 群體規模為20;隨機學習概率的最大值為0.9,最小值為0.1。遺傳算法、微粒群優化算法、最有價值的運動員算法和人類學習優化算法的參數根據對應文獻進行設置。為了公平起見,這些算法設置相同的函數評價次數,分別為1200次和1500次。實驗環境為intel(R)core(TM)i5-8265U cpu@ 3.4Ghz處理器,內存為8G,采用matlabR2016編程實現算法。實驗結果如表1和2所示。
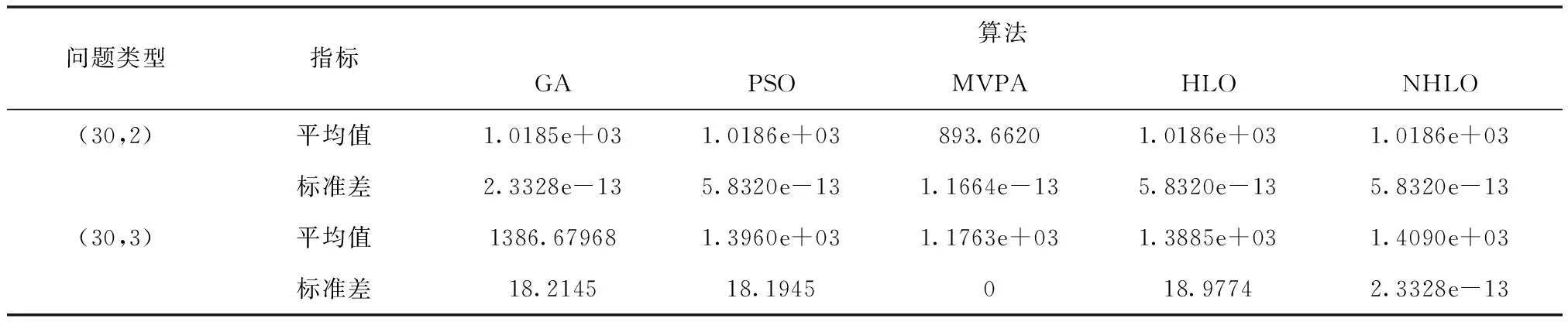
表1 50個需求點和30個備選設施點的算法結果比較
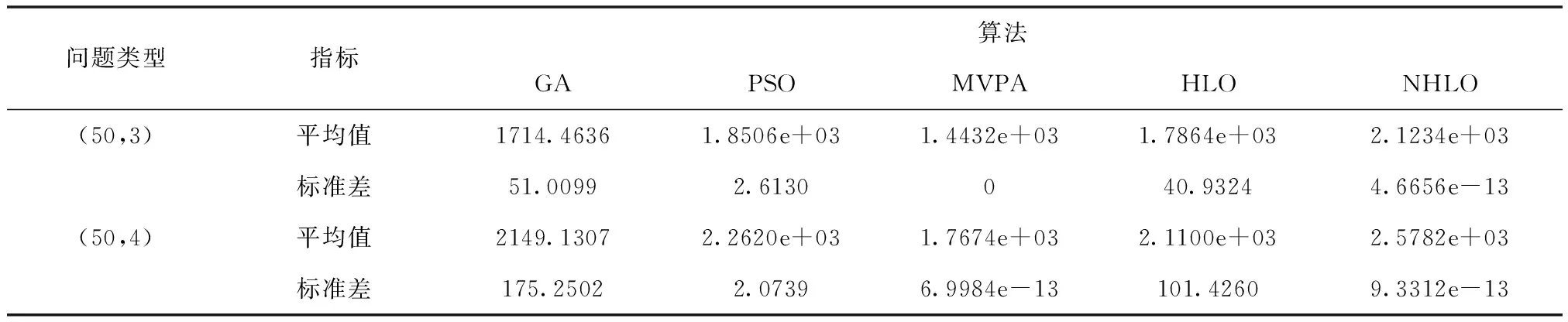
表2 100個需求點和50個備選設施點的算法結果比較
從表1和2中可以看出,相比于其它四種算法,新型人類學習優化算法平均值較高,具有較高的計算精度。此外,本文算法的標準差較小,表明該算法更穩定。在新算法中,隨機學習概率逐步降低,算法由全局勘探向局部搜索轉變。與此同時,算法根據個體自身尋優能力,選擇個體學習算子或者社會學習算子對含有高質量解的區域進行精細化搜索。隨著優化過程的進行,算法不斷向最優解不斷逼近。
第三組實驗采用文獻[17]中算例:某地有12個社區,7個候選設施點,規定最小距離為5km,最大距離為10km,7個候選設施點到12個社區的距離(km)和12個社區的人口數量(千人)如表3所示。利用新型人類學習優化算法給出具體的廣義最大覆蓋模型分配方案。
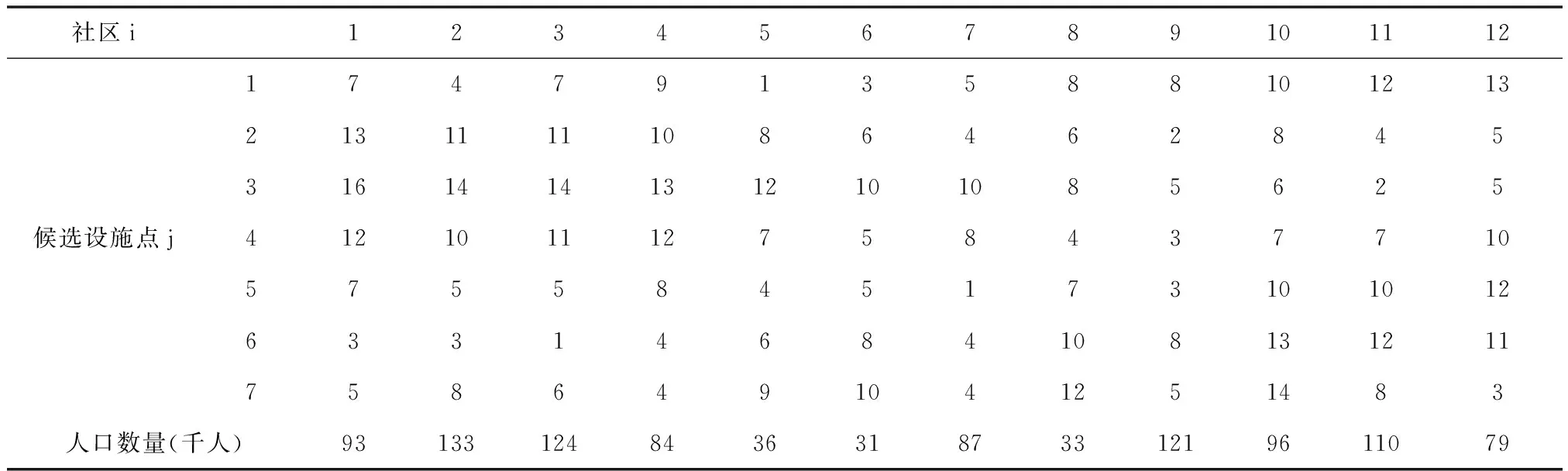
表3 候選設施點到社區的距離(km)和各社區的人口數量
在實驗中,分別考慮從7個候選設施點建3個和4個設施點兩種情況。除最大函數評價次數變為500,新型人類學習優化算法其它參數設置保持不變。此外,還采用傳統覆蓋選址模型求解上述問題。實驗結果如表4和表5所示。

表4 建3個設施點時兩種模型的覆蓋情況

表5 建4個設施點時兩種模型的覆蓋情況
從表4和5中可以看出,當建3個設施點時,傳統覆蓋選址模型的平均覆蓋率為0.7651,完全覆蓋的社區有第7個,部分覆蓋的社區有第3個,沒有任何覆蓋的社區有2個。而廣義最大覆蓋選址模型的平均覆蓋率為0.9824,完全覆蓋的社區有10個,部分覆蓋的社區有2個,不存在沒有任何覆蓋的社區。當建4個設施點時,傳統覆蓋選址模型的平均覆蓋率為0.6969,完全覆蓋的社區有第4個,部分覆蓋的社區有第6個,沒有任何覆蓋的社區有2個。而廣義最大覆蓋選址模型的平均覆蓋率為0.9912,完全覆蓋的社區有11個,部分覆蓋的社區有1個,不存在沒有任何覆蓋的社區。
通過上述結果可以發現,廣義最大覆蓋模型不僅可以給出選址方案,而且可以考慮所有需求點的覆蓋水平,通過覆蓋水平提高整體服務質量,為設施選址提供了一種有效模型。
5 結論
為有效求解廣義最大覆蓋模型,在基本人類學習優化算法的基礎上,設計自適應學習策略,提出一種新型人類學習優化算法。將所提出算法和遺傳算法、微粒群優化算法、最有價值球員算法以及人類學習優化算法進行比較。實驗結果表明新算法的優化搜索能力更強,能顯著提高問題的計算精度,為求解廣義最大覆蓋模型提供了一種有效方法。將新算法用于多目標覆蓋選址問題是下一步的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
大科技·百科新說(2021年6期)2021-09-12 02:37:27
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
好孩子畫報(2020年5期)2020-06-27 14:08:05
數學物理學報(2020年2期)2020-06-02 11:29:24
意林·全彩Color(2019年6期)2019-07-24 08:13:50
