基于區塊鏈的審計數據查詢框架構建研究
2023-03-02 16:11:06徐超趙必然陳勇
會計之友 2023年5期
徐超 趙必然 陳勇
【摘 要】 區塊鏈技術具有去中心化、防篡改、可追溯等技術特點,可以為審計數據安全提供幫助。然而在實際審計場景應用中,區塊鏈系統由于其本身查詢效率低下和查詢功能有限等不足,難以滿足審計的及時性和功能性需求。文章提出一種基于區塊鏈的審計數據查詢系統框架。首先擴展了區塊鏈上存儲的數據結構,滿足對被審計數據做數據處理的需求;其次,把區塊鏈中的數據同步到其他數據庫中,實現數據的快速查詢和多類型查詢;最后,通過設計同步規則和構建索引,保證數據從區塊鏈到數據庫的一致性和快速更新。從仿真實驗結果來看,該框架方案在查詢效率、查詢功能、數據同步等方面具有良好的表現。
【關鍵詞】 區塊鏈; 查詢優化; 審計數據
【中圖分類號】 F234.3? 【文獻標識碼】 A? 【文章編號】 1004-5937(2023)05-0136-07
一、引言
隨著物聯網(IoT)[1]、供應鏈管理[2]、遠程信息處理(Telematics)[3]等的快速發展,數據逐漸成為事件驅動的載體,但在數據交互過程中其完整性和安全性無法得到保證,迫切需要新技術來有效地管理數據。區塊鏈作為不可信環境中的可信機器,在數據完整性、去中心化和分布式賬本技術方面已被證明是有效的[4]。審計對數據的真實性和完整性的要求是十分嚴格的,所以在這點上,區塊鏈很好地滿足了審計的需求。
在區塊鏈技術和審計的結合方面,一些學者從不同角度開展了研究。畢秀玲等[5]認為區塊鏈技術是審計數據的安全保障,可以構建起“審計智能+”的免疫系統。鄭石橋[6]分析了區塊鏈對審計取證路徑的影響,并提出了一個區塊鏈對審計取證影響的理論框架。王琳等[7]基于區塊鏈技術構建了一套適用于現代審計業務發展趨勢的實時審計框架,并對框架內各個模塊的組成、功能及工作機理進行詳細說明。房巧玲等[8]提出并構建了一種區塊鏈技術驅動下的審計模式——基于雙鏈架構的混合審計模式。王涵等[9]提出了一種基于區塊鏈和默克爾哈希樹的公共審計數據共享方案,以達到對管理員權限的控制和數據的動態修改,并在實現隱私保護、批量審計和降低系統資源消耗的同時,保證了方案的安全性。綜上,目前區塊鏈與審計結合的研究主要還是停留在理論框架上,應用方面的側重點也沒有考慮到數據的查詢問題。
二、研究現狀
在審計過程中,被審計數據的數量和屬性繁雜,審計問題多種多樣,而每一個審計問題往往只涉及到部分信息。所以除了要保證數據的完整性以外,如何根據特定的審計問題從區塊鏈上快速地找出所有目標信息也變得越來越重要。
然而,區塊鏈缺少傳統數據管理系統中的許多便利,例如強大的查詢引擎,在查詢語言和查詢處理方面使用起來不方便[10],導致區塊鏈只支持基于哈希的關鍵字查詢,查詢方式單一,且需要遵循特定的格式(例如128位十六進制元素)。同時,很多區塊鏈系統為了追求卓越的寫性能,都采用鍵值數據庫作為底層數據庫,例如Level DB[11]。然而,這類數據庫通常基于LSM-tree[12]存儲結構,其讀取性能勉強令人滿意,尤其是隨機讀取。
近年來的研究主要分為三大方向來解決這些問題。一是通過智能合約驅動數據查詢。Abuhashim et al.[13]旨在通過編寫不同的智能合約函數將數據放入區塊鏈上的智能合約中,以支持區塊鏈索引和檢索。 et al.[14]采用了在以太坊上使用FastQeury智能合約在區塊鏈上存儲和查詢藥物基因組學數據的方案,該方案利用屬性值的唯一性進行存儲映射,類似于哈希表,以實現高效的鍵值查詢。然而,智能合約存在太多限制,包括智能合約本身的潛在漏洞、Gas限制、Solidity語言轉換為字節碼時功能邊界模糊等。并且,從這些文獻的實驗部分可以看出,智能合約只能在特定的數據量較小的場景下使用,不具備泛化性。二是把區塊鏈數據存儲在其他數據庫中。Ether QL系統中包含一個同步管理器模塊,用于從區塊鏈系統中獲取新的區塊數據,解析出區塊鏈字段,存儲在Mongo DB中,然后提供查詢接口,借助外部數據庫實現查詢功能[15]。Bragagnolo
et al.[16]提出使用大數據技術來提取和分析區塊鏈中的信息。他們使用Map/Reduce模型的并行索引算法將區塊鏈數據同步到關系數據庫中。這些方法是高效的,但將數據從區塊鏈更新到其他數據庫時存在延遲,不能很好地滿足用戶實時查詢數據的需求。其次,外部數據庫不是防篡改的,無法保證查詢數據與區塊鏈數據的一致性。三是在區塊鏈內部構建索引結構。Blockchain DB選擇使用紅黑樹和Merkle樹的組合RBTree作為索引結構[17]。Huang et al.[18]設計了一種基于雙向鏈表的區塊鏈,結合了線索二叉搜索樹(TBST)和AVL樹,提出了一種新的塊內搜索結構。由于鏈上的數據與索引的更新是同步的,所以這些方法支持實時查詢,但問題在于在區塊鏈內構建索引結構實施難度較大,并且每種預定義的查詢類型都要對應一個數據結構,擴展性弱。
針對以上問題,為滿足審計場景的數據查詢需求,本文基于數據庫和區塊鏈技術提出了一種面向審計的查詢系統框架。考慮到鏈上空間的局限性以及對數據保密性的要求,本文采取“鏈下審計”+“鏈上驗證”的審計與區塊鏈結合模式,即先對被審數據哈希加密后生成驗證碼,然后把所有的驗證碼存放在區塊鏈中,鏈下進行審計時再從鏈上返回對應數據的驗證碼做計算比對,驗證被審數據是否被篡改。
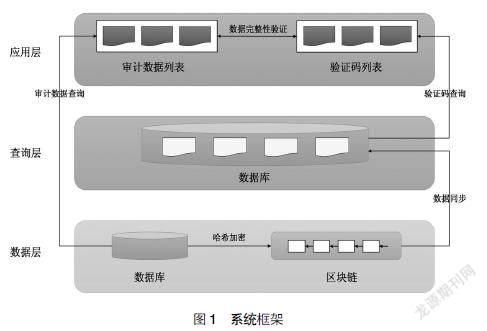
三、系統框架
本文提出的系統框架如圖1所示,包括數據層、查詢層和應用層:數據層包含一個數據庫模塊和一個區塊鏈模塊,分別存儲被審數據和驗證碼;查詢層包含一個數據庫模塊,負責同步區塊鏈上的數據值,并提供快速、多樣的查詢服務;應用層根據審計問題獲取所需的被審數據和驗證碼,并作計算比對,保證被審數據的完整性。
(一)數據層
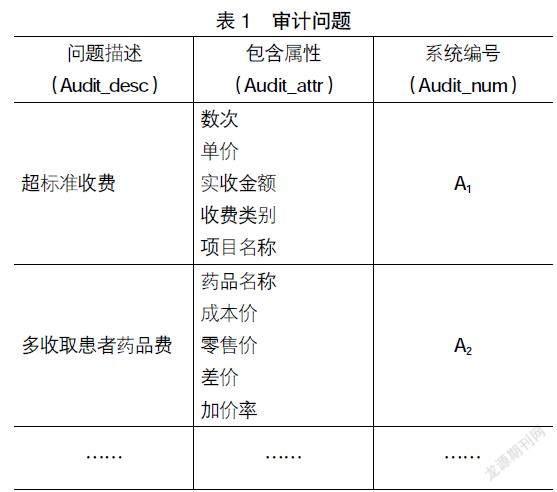
在本文的系統中,會根據常見的審計問題維護一張表,該表包含三個屬性字段:Audit_desc表示某審計問題的描述;Audit_attr表示該審計問題所涉及到的屬性(每條被審數據會有很多屬性,而一個審計問題往往只涉及到其中的幾個);Audit_num表示系統為該審計問題生成的唯一編號Ai,其中Ai表示第i個添加到該表中的審計問題。該表存儲在數據庫模塊中。表1表示在醫療收費審計場景下審計問題表的一個具體示例:系統中編號A1對應的審計問題為“超標準收費”,其涉及到的屬性有“數次”“單價”“實收金額”“收費類別”“項目名稱”等;系統中編號A2對應的審計問題為“多收取患者藥品費”,其涉及到的屬性有“藥品名稱”“成本價”“零售價”“差價”“加價率”等。
在驗證碼上鏈的過程中,系統會根據該表中存在的審計問題,自動在被審數據中找出所有與該審計問題相關的信息,逐條按照預先設定好的哈希函數做哈希運算,生成的驗證碼按照審計問題的編號進行分類。
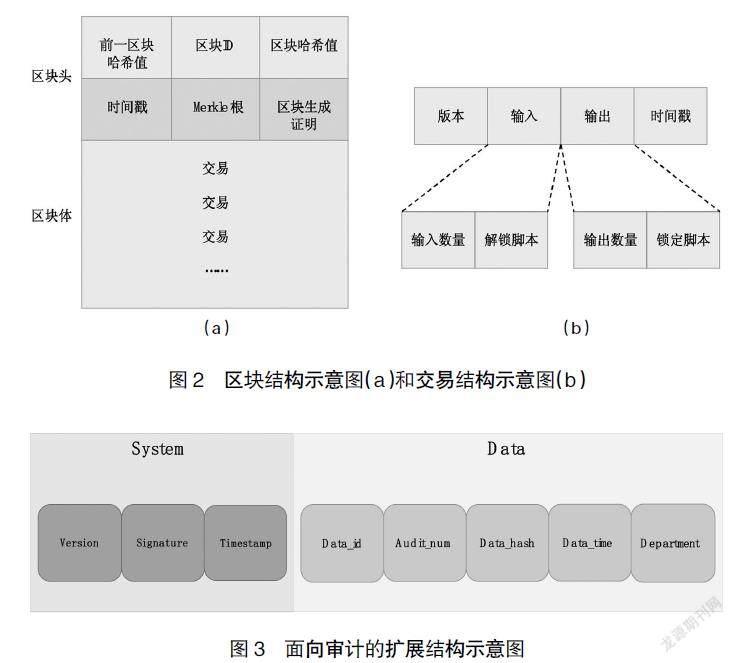
在比特幣[19]系統中,區塊結構如圖2(a)所示:每個區塊都由一個區塊頭和一個區塊體組成,區塊頭含有多個字段,包括指向前一區塊的哈希值、表明區塊身份的區塊ID和本區塊的哈希值、區塊形成的時間戳、區塊體中所有交易自下而上哈希得到的Merkle根以及該區塊被合理生成的證明;區塊體包含多條交易,每條交易的結構如圖2(b)所示:包括交易的版本號、交易輸入、交易輸出以及交易生成的時間戳,其中交易輸入包含輸入數量和附帶用戶私鑰簽名的解鎖腳本,交易輸出包含輸出數量和使用對方公鑰鎖定的鎖定腳本。
由于比特幣系統是面向交易的,并且數據結構是固定的,因此系統只能處理固定結構的交易數據,其每個交易結構里包含的交易數據的信息字段也都是與交易本身有關,而對于被審數據這種更具一般性的數據而言,比特幣系統的交易結構就無法完美地兼容。
為了讓比特幣系統可以在審計場景中更好地對被審數據進行數據處理,本文的解決方法是,對原本的交易結構進行擴展,如圖3所示:擴展后的結構包含系統(System)屬性和數據(Data)屬性兩部分。系統屬性部分用來存放區塊鏈系統為交易生成的信息,包含版本號(Version)、簽名(Signature)和時間戳(Timestamp)等;數據屬性部分用來存放與被審數據本身相關的信息,包括被審數據的鏈下標識號(Data_id)、審計問題的編號(Audit_num)、驗證碼(Data_hash)、被審數據本身發生的時間(Data_time)以及部門編號(Department)等。其中Data_id字段用來匹配鏈上與鏈下的數據,Audit_num字段用來對鏈上數據進行分類,Data_hash字段用來存放鏈下數據經過哈希加密后的結果,Data_time字段用來輔助查詢,Department字段表示被審數據原本歸屬的部門(考慮到審計場景中,被審數據往往是由多個部門的子數據集組成)。
這樣區塊鏈系統就與交易脫鉤,變成了服務于審計的特定數據庫(為了表示這種變化,在下文中,原本區塊鏈系統中的交易改稱為記錄,即每個區塊的區塊體中包含多條記錄)。
(二)查詢層
在提升區塊鏈系統查詢效率和查詢功能的三個方向中,本文的系統選擇的方法是構造查詢層,把區塊鏈上的數據同步到傳統數據庫中。在保證同步數據一致性的方法上,Wu et al.[20]采取的對策是使用哈希函數為每次同步的所有內容和屬性生成一個指紋,這樣只需要驗證指紋的正確性就可以防止數據的偽造。該方法的具體流程為:在每個周期內(可以固定的時間或固定的區塊數量為一個周期),系統先把區塊鏈上更新的所有記錄提取出來,按照目標屬性重組后構建一個微型數據庫,并為小數據庫生成一個指紋;然后系統按照相同的數據庫生成程序,在區塊鏈中構建另一個微型數據庫,并用相同的哈希函數為小數據庫生成一個指紋;最后系統通過比較兩個指紋值來驗證同步數據的一致性。若驗證失敗,則系統中會產生錯誤報告,當錯誤報告達到一定數量時,系統會執行一個診斷程序來檢查數據庫的正確性,直到沒有錯誤報告到達。
該方法的不足之處有:整個同步流程十分耗時,不能很好地滿足實時查詢的需求;系統對于每個周期內構建的微型數據庫只是簡單地按時間順序更新到了大數據庫中,沒有做合并操作,并且該系統中的區塊鏈是面向交易的,鏈上數據的屬性不能全面地體現被審數據的信息,微型數據庫可以提供的查詢類別也就比較局限,無法滿足審計場景中多個審計問題的需求。
本文基于為同步數據生成指紋的策略,設計了一個新的同步規則,優化了同步流程;在查詢層中按照審計問題構建多張預查詢表,并把每次同步的數據合并到已有的同類別數據表中,為審計場景提供快速且多類型的查詢,優化了同步結果。
新的數據同步規則為:在每個周期內,系統首先按照審計問題的類別(即審計問題的編號)在區塊鏈上更新的記錄中找出對應的所有數據,用設定好的哈希函數為其生成一個指紋;然后系統把這些數據提取出來,保存到查詢層,并用相同的哈希函數為其生成一個指紋;最后系統比較兩個指紋值來判斷同步數據是否一致。
為了提高數據同步流程中在區塊鏈上查找數據的效率,本文添加了一個索引機制來加速鏈上數據的訪問。系統會維護一個索引表,表中每個類別的數據都對應一個索引結構。索引結構定義如下:{Ai[b1,b2,…,bn]},Ai即審計問題在系統中的編號,n表示每個周期內系統中生成的新區塊總數,bn對應更新區塊在本次周期內的相對位置,bn的取值為“0”或“1”。其本質上是一種位圖結構,位圖中從左數第j位表示該類別的數據是否存在于第j個區塊中(置“0”表示不存在,置“1”表示存在)。當一個類別的記錄首次出現時,系統會在表中添加該類別的名稱以及對應的空白位圖。當有一個新的區塊產生時,通過設置相應位置的編碼(“0”或“1”)來更新索引表。表2展示的是一次更新周期內索引表的具體示例:在該周期內,系統一共生成了10個區塊,其中A1類型的數據存在于第3、4、6、10個區塊中,A2類型的數據存在于第1、6、7、8個區塊中。
這種索引機制的好處有:由于一個類別的記錄可能會存在于不同的區塊中,而位圖可以精準地顯示出記錄存在的目標位置,這樣系統在區塊鏈上查找數據時就可以避免掃描所有區塊;這種索引的構造難度較小,擴展性較高,十分便于系統對索引表的創建與更新。
由于數據層的區塊鏈模塊中的記錄結構是經過擴展的,每條記錄隨著審計問題編號的不同而被分成了不同的類別,因此系統會在查詢層的數據庫模塊中為每個審計問題分別構建各自的表,并以其對應的編號命名。除此之外,系統在查詢層中會維護一張特定的名稱表,用來存放查詢層中已經存在的表名(即審計問題的編號),在每次同步數據的一致性驗證成功后,系統會先判斷查詢層中是否存在同類別的表,若存在就添加到該表中,若不存在就創建一張新表,并把表名添加到名稱表中。
一個類別的所有記錄在系統中的一次更新周期內的同步流程大致如圖4所示:首先系統會根據該數據的類別“Ai”,從索引表中獲取對應的位圖信息Index_table.Ai.Block_distribution;由于位圖是由一串“0”“1”數據組成的,每位只是表示對應位置的存在情況,并沒有直接指明具體的位置,所以系統會根據位圖生成一個具體的位置信息列表Block_loc,里面直接存放具體的區塊編號;系統根據位置信息列表在目標區塊中獲取本次更新周期內的所有類別為Ai的記錄,并添加到一個緩存列表Ai.templist中;系統先對緩存列表生成一個指紋Fingerprint(Ai.templist),再把緩存列表同步到查詢層的一個臨時數據表Ai.temptable中,并對該臨時數據表生成一個指紋Fingerprint(Ai.temptable),只有當緩存列表的指紋Fingerprint(Ai.templist)等于臨時數據表的指紋Fingerprint(Ai.temptable)時,才能保證數據同步的一致性;當系統判定成功后,會在名稱表中查找是否有“Ai”字段的存在,若找不到,說明查詢層中還未構建該類別的數據表,則系統先構建一張對應的數據表Ai.table,并把臨時數據表中的所有數據存放在該表中,最后在名稱表中添加“Ai”字段,若找到,則系統把臨時數據表中的所有數據合并到已有的同類別數據表中。到此,整個流程才算結束。
在單次更新周期內,不管某類型的數據存在于多少個區塊中,VQL系統都需要進行n次對單個區塊的查找步驟(n為每個周期內更新的區塊數量),所以其同步流程的時間復雜度永遠是O(n)。而在本文的系統中,由于索引的存在,系統對單個區塊的查找次數隨著該類型數據所分布區塊數量的變小而減少,雖然最壞情況下仍然需要執行n次對單個區塊的查找操作,但當數據只存在于一個區塊中時,系統只需要執行一次對單個區塊的查找操作即可,此時同步流程的時間復雜度為O(1)。
(三)應用層
系統中維護的審計問題表可以在應用層中查看,審計人員可以根據表中的信息,直接輸入審計問題所對應的編號即可。系統會根據所輸入的審計問題編號,自動完成數據的完整性驗證,并將被審數據列表、其對應的驗證碼列表以及驗證的結果在應用層中展示。
系統在做完整性驗證時,可以直接從查詢層中的預查詢表中快速地獲取驗證碼列表。因為鏈上數據的每條記錄中也包含數據發生時間和部門編號字段,而這些信息也在數據同步過程中一起同步到了查詢層中,所以如果審計人員想對被審數據做進一步的篩選時,比如獲取特定時間內或特定部門的信息,由于以上字段的存在,系統也可以在查詢層中快速地篩選出對應的驗證碼列表。而記錄中的鏈下標識號字段可以幫助系統在逐條比對的過程中完美地匹配每一條被審數據與其對應的驗證碼。而對于某條具體的數據,系統也可以在查詢層中快速地定位到對應的驗證碼。
四、實驗與分析
由于本文的主要研究點在于區塊鏈數據的查詢方法和同步流程,不涉及網絡以及共識協議,所以進行了仿真實驗。
(一)數據查詢方法
系統對查詢效率的需求主要體現在根據審計問題從區塊鏈系統中快速找到被審數據列表中所有數據對應的驗證碼,最終表現為快速地完成對被審數據的完整性驗證。
本文比較在查詢過程中通過掃描區塊(Scan_block)和使用查詢層(Query_
layer)兩種方法所需的響應時間,并針對三種查詢模式分別做了查詢效率對比實驗,包括:單值查詢,表現為從區塊鏈系統中獲取某一條具體的被審數據對應的驗證碼(比如來自xx部門,產生時間為xxxx-xx-xx,標識號為xx,涉及到的審計問題編號為xx);范圍查詢,表現為從區塊鏈系統中獲取特定條件下的被審數據對應的驗證碼(比如某個時間段或某幾個部門,涉及到的審計問題編號為xx);表查詢,表現為從區塊鏈系統中獲取某一審計問題中的被審數據對應的驗證碼(比如涉及到的審計問題編號為xx)。
在不同數據總量的條件下,分別測試了Scan_block方法與Query_layer方法的表現。具體的實驗結果如表3所示。可以看到,Scan_block方法在任意數據量和任意查詢模式下的耗時都遠高于Query_layer方法,并且在同一種模式中,隨著數據總量的增大,Scan_block方法與Query_layer方法的耗時差在快速擴大。通過分析可知,由于Scan_block方法采用遍歷方法,其查詢過程需要讀取整條鏈上的所有區塊。特別的,由于本文的系統在查詢層中已經按照審計問題的編號對所有數據做了分類存儲,所以在表查詢模式下,Query_layer方法只需要定位到對應的預查詢表即可,這就解釋了為什么在不同的數據總量下,Query_layer方法在表查詢模式中的耗時幾乎保持不變的原因。
(二)數據同步流程
因為本文系統和VQL系統在本質上都是把鏈上數據同步到鏈外數據庫中做查詢優化,所以兩者單從查詢效率上沒有實質性的區別(不考慮不同數據庫之間的差異)。而本文相較于VQL系統的優勢點在于數據同步流程的優化。一方面是對同步結果的優化:由于本文對鏈上交易結構的擴展,使得本文的系統可以在查詢層中按照審計問題的種類來對數據進行分類存儲,每次更新的數據也都按照種類合并在了一張表中,這樣對于一些常見的審計問題,系統可以直接從這些預查詢表中獲取數據,并且由于標識號、時間、部門編號等屬性的存在,對于在特定范圍內的審計問題,系統也能從查詢層中做進一步的篩選。
另一方面是對同步效率做了優化:由于索引機制的引入,系統從區塊鏈上查找目標數據的速度有了明顯的提升,從而降低了整個同步流程的耗時。這樣在一定程度上可以降低將數據從區塊鏈同步到其他數據庫時的延遲,以滿足用戶實時查詢數據的需求。
本文針對每個更新周期內的同步流程,在兩種場景下對兩個系統的同步效率做了對比實驗。一個是在區塊數量不變的情況下(單次周期內的同步區塊數量保持為25個),觀察系統在不同區塊容量下的表現,結果如圖5所示(Improve表示本文提出的同步方法)。另一個是在區塊容量不變的情況下(單次周期內的區塊最大容量保持為2 500條),觀察系統在不同區塊數量下的表現,結果如圖6所示。可以看到,在兩種情況中的每個條件下,Improve方法的同步流程耗時總是低于VQL系統。并且隨著實驗變量的增加,VQL系統同步流程耗時的增長幅度大于Improve方法。
同時,本文還在以上兩種情況下分別對Improve方法中索引的空間大小做了測量。表4展示的是單次的更新周期內,在單個類別數據上構建的索引結構與更新區塊在不同條件下的空間開銷。可以看到,在任意條件下,索引結構的空間開銷都遠小于單次更新數據的總空間開銷,代價可以說是忽略不計。即使存在多種數據類型,并且在每個數據類別上都構建各自的索引結構,所有索引結構加起來的空間代價仍然是可以接受的。這表明Improve方法中的索引結構在空間上具有很好的擴展性。
五、結語
雖然區塊鏈技術本身的特性十分契合審計場景中對數據的完整性需求,但目前區塊鏈與審計結合的研究并沒有考慮到數據的查詢問題,并且現有的區塊鏈系統因其自身的查詢功能缺陷也無法滿足審計場景的查詢要求。針對這一問題,本文構造了一種基于區塊鏈的面向審計的查詢系統框架。本文考慮到鏈上空間的局限性以及對數據保密性的現實情況,采取了“鏈下審計”+“鏈上驗證”的審計與區塊鏈結合模式;首先為了能讓區塊鏈系統可以很好地兼容被審數據本身的屬性,本文對比特幣系統中的交易數據結構做了面向審計的擴展;其次本文選擇把鏈上數據存儲在其他數據庫的方法來提升區塊鏈系統的查詢功能,并且基于VQL系統的驗證思路,實現了數據同步的一致性;最后本文通過設計新的同步規則和構建索引對VQL的同步流程和同步結果做出優化。實驗結果表明,本文方案在查詢效率和數據同步等方面具有良好的表現。
不足之處在于,對于審計問題表的構造和更新需要人員主動去維護,未來可利用機器學習算法,通過訓練讓系統根據以往的審計經驗自動維護審計問題表。
【參考文獻】
[1] MADAKAM S,LAKE V,LAKE V,et al.Internet of things(iot):a literature review[J].Journal of Computer and Communications,2015,3(5):164-173.
[2] MALIK S,DEDEOGLU V,KANHERE S S,et al.Trustchain:trust management in blockchain and iot supported supply chains[C].2019 IEEE International Conference on Blockchain.2019:184-193.
[3] SANG-OUN L E E,HYUNSEOK J,HAN B.Security assured vehicle data collection platform by blockchain:service providers perspective[C].2019 21st International Conference on Advanced Communication Technology.IEEE,2019:265-268.
[4] KUMAR R,SHARMA R.Leveraging blockchain for ensuring trust in iot:a survey[J].Journal of King Saud University-Computer and Information Sciences,2021.
[5] 畢秀玲,陳帥.科技新時代下的“審計智能”建設[J].審計研究,2019(6):13-21.
[6] 鄭石橋.區塊鏈對審計取證的影響:一個理論框架[J].財會通訊,2021(9):1-5.
[7] 王琳,向際鋼.基于區塊鏈技術的實時審計框架構建[J].財會通訊,2020(9):139-142,147.
[8] 房巧玲,高思凡,曹麗霞.區塊鏈驅動下基于雙鏈架構的混合審計模式探索[J].審計研究,2020(3):12-19.
[9] 王涵,王緒安,周能,等.基于區塊鏈的可審計數據分享方案[J].廣西師范大學學報(自然科學版),2020,38(2):1-7.
[10] ZHU Y,ZHANG Z,JIN C,et al.Towards rich qery blockchain database[C].Proceedings of the 29th ACM International Conference on Information & Knowledge Management,2020:3497-3500.
[11] TULKINBEKOV K,PIRAHANDEH M,KIM D H.Cleveldb:coalesced leveldb for small data[EB/OL].https://github.com/google/leveldb.
[12] ONEIL P,CHENG E,GAWLICK D,et al.The log-
structured merge-tree(LSM-tree)[J].Acta Informatica,1996,33:351-385.
[13] ABUHASHIM A,TAN C C.Smart contract designs on blockchain applications[C].2020 IEEE? Symposium on Computers and Communications,2020:1-4.
[14] GüRSOY G,BRANNON C M,GERSTEIN M.Using ethereum blockchain to store and query pharma-cogenomics data via smart contracts[J].BMC medical genomics,2020,13(1):1-11.
[15] LI Y,ZHENG K,YAN Y,et al.Etherql:a query layer for blockchain system[C].Internat-ional Conference on Database Systems for Advanced Applications,2017:556-567.
[16] BRAGAGNOLO S,MARRA M,POLITO G,et al.Towards scalable blockchain analysis[C].2019? IEEE/ACM 2nd International Workshop on Emerging Trends in Software Engineering for Bloc-kchain,
2019:1-7.
[17] 焦通,申德榮,聶鐵錚,等.區塊鏈數據庫:一種可查詢且防篡改的數據庫[J].軟件學報,2019,30(9):2671-2685.
[18] HUANG T L,HUANG J.An efficient data structure for distributed ledger in blockchain systems[C].2020 International Computer Symposium,2020:175-178.
[19] NAKAMOTO S.Bitcoin:A Peer-to-Peer electronic Cash System[EB/OL].https://bitcoin.org/bitcoin.pdf,2008.
[20] WU H,PENG Z,GUO S,et al.Vql:efficient and verifiable cloud query services for blockchain systems[J].IEEE Transactions on Parallel and Distributed Systems,2021,33(6):1393-1406.
