基于控制流和數據流分析的內存拷貝類函數識別技術
2023-03-02 10:09:14尹小康蘆斌蔡瑞杰朱肖雅楊啟超劉勝利
計算機研究與發展 2023年2期
尹小康 蘆斌 蔡瑞杰 朱肖雅 楊啟超 劉勝利
(數學工程與先進計算國家重點實驗室(信息工程大學)鄭州 450001)
利用漏洞發起網絡攻擊仍是當前網絡攻擊中的主要方式.漏洞攻擊能夠使目標設備癱瘓、實現對目標設備的突破控制,或者對重要文件的竊取.在利用漏洞發起的攻擊中,危害性最高的漏洞之一為內存錯誤漏洞.內存錯誤漏洞包括內存溢出漏洞、內存泄漏漏洞和內存釋放后重用漏洞等,這些漏洞能夠實現任意代碼執行,造成密鑰、口令等信息的泄露.在通用漏 洞披露組織(Common Vulnerabilities and Exposures,CVE)發 布的2021 年最危險的25 種軟件脆弱性分析[1]中,CWE-787[2]即越界寫(out-of-bounds write,OOBW)排在了 第1 位,CWE-125[3]即越界 讀(out-of-bounds read,OOBR)排在第3 位以及CWE-119[4]即不當的內存緩沖區范圍內的操作限制排在第17 位.內存溢出漏洞和內存泄漏漏洞的發生常常跟內存的拷貝相關,在進行內存拷貝的時候缺少對長度的檢查,或者對特殊的字節進行轉換時發生長度的變化,都會導致對內存的越界寫或者越界讀[5].因此內存拷貝類函數(下文簡稱拷貝類函數)的識別對內存錯誤漏洞的發現和修補具有重大意義和價值.
本文提出了一種拷貝類函數識別技術CPYFinder(copy function finder).該技術在不依賴函數名、符號表等信息的情況下,對函數的控制流進行分析,并將二進制代碼轉換成中間語言代碼進行數據流的分析,識別二進制程序中的拷貝類函數.本文的主要貢獻包括4 個方面:
1)分析了不同架構下拷貝類函數的特點,構建了基于靜態的分析方法的拷貝類函數識別模型.
2)提出并實現了二進制程序中拷貝類函數識別技術CPYFinder,該方法不依賴函數名、符號表等信息,能夠識別無論是C 語言庫中還是用戶自定義實現的拷貝類函數.
3)提出的CPYFinder 具有良好的適用性和擴展性,通過將二進制代碼轉換成中間語言代碼進行數據流的分析,使得支持x86,ARM,MIPS,PowerPC 指令集架構的二進制程序.
4)從GitHub 上收集了拷貝類函數,構建了測試數據集進行測試,并選取了真實的CVE 漏洞函數進行了測試.實驗結果表明CPYFinder 具有更好的表現,在精準率和召回率上得到更好的平衡,并且具有較低的運行時耗.CPYFinder 對提高下游分析任務具有重大價值.
1 相關工作
拷貝類函數的識別對二進制程序中內存錯誤漏洞的發現和修補具有重大意義和價值.由于版權或者安全的需要,軟件供應商在程序發布的時候往往是以二進制的形式進行發行,甚至會剝除程序中的函數名、符號表等信息.因此安全研究員只能在缺少源碼的情況下對二進制程序進行分析,進而發現程序中的脆弱點并提供給供應商進行漏洞的修補.相比于對源代碼的分析[6],由于二進制代碼中丟失了高級語言具有的信息,例如C/C++中的函數原型、變量名、數據結構等信息,因此對二進制程序進行分析具有更大的挑戰.針對二進制程序的分析技術主要有二進制代碼審計[7]、污點分析[8-9]、符號執行[10-11]等,這些技術在漏洞發現和分析中具有較好的效果.然而這些技術在一定程度上依賴函數名、符號表等信息,例如Mouzarani 等人[12]在提出的基于混合符號執行的模糊測試技術中仍需要借助符號表對memcpy,strcpy等函數的識別.DTaint[13]和SaTC[14]等在進行靜態污點分析中需要借助函數名,例如memcpy,strncpy等函數,來定位關鍵函數,進而進行后續的污點記錄和傳播等操作.當二進制程序剝除了函數名等信息時,上述技術的效果將會受到嚴重影響.
此外,當前的研究中還存在一個被忽視的問題:開發者在開發程序時會自定義實現類似于內存拷貝功能的函數,進而會引入內存錯誤漏洞.例如,漏洞CVE-2020-8 423[15]發生在一個TP-Link TL-WR841N V10 路由器設備中,由函數intstringModify(char*dst,size_tsize,char*src)引發的 棧溢出漏洞.盡 管BootStomp[8],Karonte[9],SaTC[14]考慮到了對拷貝類函數的識別,但是它們的識別方法依據簡單的代碼特征:1)從內存中加載數據;2)存儲數據到內存中;3)增加1 個單元(字節byte、字word 等)的偏移值.然而滿足上述3 個特征的函數并不一定具有拷貝數據的功能,而且會遺漏用戶自定義實現的拷貝類函數,因此具有較高的誤報率和漏報率.
當前針對剝除函數名等信息的二進制程序中的函數識別技術,主要是以靜態簽名的方法為主,例如IDA Pro 中使用 庫函數 快速識 別技術(fast library identification and recognition technology,FLIRT)[16],工具Radare2[17]使用Zsignature 技術對程序中的函數名進行識別,此類方法能夠識別出簽名庫中包含已經簽名的函數,例如strcpy,memcpy等函數.然而基于簽名的函數識別技術容易受編譯器類型(GCC,ICC,Clang 等)、編譯器版本(v5.4.0,v9.2.0 等)、優化等級(O0~O3)以及目標程序的架構(x86,ARM,MIPS 等)的影響.而且,每種優化等級又可以分為數十種優化選項[18](在GCC v7.5.0 中O0 開 啟了58 種優化 選項,O1 開啟了92 種優化選項,O2 開啟了130 種優化選項,O3 開啟了142 種優化選項),這些優化選項可以通過配置進行手動地開啟和關閉.因此,這些選項組合起來將產生成千上萬種編譯方案,即同一份源碼經過不同的編譯配置編譯后會產生成千上萬個函數,但這些函數的靜態簽名存在一定的差異,給基于簽名的函數識別造成了阻礙.因此,為準確地識別函數需要構建各種各樣的函數簽名,這些工作顯得尤為繁重.此外,基于簽名的函數識別只能識別已知的函數,對于未知的拷貝類函數(簽名庫中不包含該函數的簽名)則無法識別,這仍是一個亟待解決的問題.
因此,為解決當前研究中存在的依賴函數名等信息、無法識別未知的拷貝類函數以及識別的誤報率較高等問題,本文提出了一種新穎的拷貝類函數識別技術CPYFinder,用于對剝除函數名等信息的二進制程序中拷貝類函數的識別.該方法基于拷貝類函數的代碼結構特征和數據流特征,通過對函數的控制流[19]和數據流[20]進行分析,識別二進制程序中具有內存拷貝功能的函數.CPYFinder 一定程度上避免了編譯器和優化等級的影響,不依賴于函數名的信息,并且能夠識別開發者自定義實現的內存拷貝類函數,通過將二進制代碼轉換成中間語言表示(intermediate representation,IR)代碼進行數據流的分析,使得CPYFinder 適用于x86,ARM,MIPS,PowerPC(PowerPC與PPC 等同)等指令集的二進制程序,具有良好的適用性和擴展性,以及較高的準確率.
經過實驗評估表明,CPYFinder 相比于最新的工作BootStomp 和SaTC,在對無論C 語言庫中的拷貝類函數還是對用戶自定義實現的拷貝類函數的識別上都具有更好的表現;在精準率和召回率上得到更好的平衡.在實際的路由器固件的5 個CVE 漏洞函數測試中,BootStomp 和SaTC 均未發現導致漏洞的拷貝類函數,而CPYFinder 發現4 個漏洞函數.在識別效率測試中發現,CPYFinder 具有更高的識別效率;在增加數據流分析的情況下與SaTC 耗時幾乎相同,耗時僅相當于BootStomp 的19%.CPYFinder 能夠為下游的分析任務,例如污點分析[21]、符號執行[12]、模糊測試[22]等提供支持,在對內存錯誤漏洞的發現和檢測上具有較高的價值.
2 問題描述及相關技術
本節主要介紹相關的定義、結合具體的實例對拷貝類函數識別的重要性進行介紹、對現有方法存在的問題進行分析以及對VEX IR 中間語言進行簡要介紹.
2.1 相關概念
1)內存拷貝類函數(memory copy function)[8].將數據從內存中的一段區域(源地址)直接或者經過處理(例如對字節進行轉換)轉移到另一段內存區域(目的地址)中的函數,或者部分代碼片段實現了內存拷貝功能的函數.
2)函數控制流圖(control flow graph,CFG).函數方法內的程序執行流的圖,是對函數的執行流程進行簡化而得到,是為了突出函數的控制結構.本文以Gc表示程序的控制流圖,以V表示節點的集合,以E表示邊的集合.其中Gc=(V,E),V={v1,v2,…,vn},E={e1,e2,…,em}.需要注意的是CFG 圖是一個有向圖.通過對CFG 的遍歷來判斷其是否包含循環結構.
3)循環路徑(loop path,LP).從圖中的一個節點出發,沿著其相連接的邊進行遍歷,若還能回到這個節點,則該圖包含循環結構,其中從該節點出發又回到該節點的所有節點及其邊構成了循環的路徑.對于CFG 來說,循環路徑更多關注的是其路徑上的節點,即基本塊和基本塊內的指令,該指令序列組成了函數的執行流.
4)數據流圖(data flow graph,DFG).是記錄程序中的數據在內存或者寄存器間的傳播和轉移變化情況的圖.通過對變量或者內存的數據流進行跟蹤分析能夠判斷函數的行為.
對二進制程序中拷貝類函數識別的第1 步是二進制函數邊界的識別,二進制函數邊界識別的技術[23-24]已經相對成熟,以及現有的IDA Pro 工具已經滿足需要,這里不再贅述.
2.2 拷貝類函數識別的重要性
據本文研究發現,C 語言庫中封裝的拷貝類函數并不能滿足所有開發的需求,例如需要在內存拷貝時對字節進行處理或者轉換時無法再使用C 語言庫中的拷貝類函數,開發者只能自己開發相應功能的函數來滿足需求.此類拷貝類函數仍是安全研究需要關注的重點,對此類函數的不正確使用仍會造成內存錯誤漏洞的產生.
如圖1 所示,函數alps_lib_toupper在拷貝的時候將所有的小寫字母轉換為大寫字母,開發者調用此函數時缺乏對長度的檢查,導致了漏洞CVE-2017-6736[25]的產生;另一個例子是MIPS 架構下TP-Link WR940N 無線路由器中的一個棧溢出漏洞CVE-2017-13772[26],如 圖2 所 示,導致該 漏洞的 是函數ipAddrDispose中的一段負責內存拷貝(地址轉換)的代碼,導致該漏洞產生的基本塊路徑是loc_478568,loc_478550,loc_478560,該循環在一定條件下從寄存器$a1 指向的內存中取出1B 的數據存放到寄存器$v0 中,當$v0 的值與$t0 的值不相等時,將寄存器$v0 中的數據存放到0x1C($a2)指向的內存中,由于缺少對長度嚴格的檢查導致了漏洞的產生.

Fig.1 Memory copy function implemented by developer圖1 開發者實現的內存拷貝類函數
由此可見,不僅對C 語言庫中拷貝類函數的錯誤調用會導致內存錯誤漏洞,對開發者自定義實現的拷貝類函數調用也存在產生內存錯誤漏洞的風險.因此本文提出通過識別二進制程序中的拷貝類函數對具備內存拷貝功能的代碼片段進行檢測,以便為下游的分析任務,例如污點分析、模糊測試等提供更多的支持,提高分析的準確率和發現內存錯誤漏洞的可能性.
2.3 拷貝類函數的特點
本節將對拷貝類函數的特點、不同指令集下的變化以及檢測的難點進行分析.

Fig.2 Function for IP address conversion in the httpd service圖2 httpd 服務中IP 地址轉換的函數
在C 程序開發時,一般情況下開發者會直接調用庫中封裝好的內存拷貝類函數,如strcpy,memcpy等函數.圖3 展示了C 語言下函數strcpy的源碼經過編譯后的二進制代碼.圖4 展示了MIPS 指令集下的函數strncpy.從源碼中可以看出,對于內存中數據的轉移或者修改往往借助于while 或者for 循環進行實現,經過編譯器編譯后在二進制函數CFG 中的表現即為存在循環路徑.

Fig.3 Implementation of strcpy function in C library圖3 C 語言庫中strcpy 函數的實現
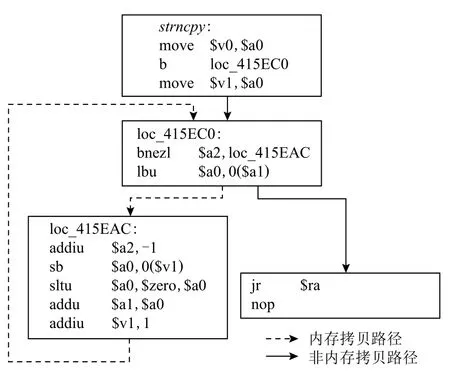
Fig.4 The strncpy function under the MIPS instruction set圖4 MIPS 指令集下的strncpy 函數
然而并不是所有的內存拷貝函數都存在循環路徑,如圖5 所示為x86 指令集下的函數memcpy,從圖中可以看出該函數不存在循環路徑,原因是x86 指令集下存在特殊的指令可以直接實現字節的連續轉移,如rep movsb,rep movsd 指令等,即由于x86 指令集下存在rep 指令可以完成重復的功能,借助此指令來完成內存的拷貝.但由于其他指令集下,如ARM,MIPS,PPC 不存在這種特殊的指令,則需要借助循環來實現內存的拷貝.此外,由于rep 只能實現無變化的數據拷貝,因此x86 指令下二進制同樣存在基于循環實現的內存拷貝類函數.因此CFG 中存在循環路徑仍是拷貝類函數最大的特點.內存拷貝類函數一定存在對內存的訪問,即對內存進行讀寫,因此在循環路徑中一定要存在對內存的讀取和寫入指令,在反匯編代碼中即表現為存在內存的加載和存儲的操作碼,例如在MIPS 指令下為lbu 和sb(如圖4 所示,在基本塊loc_415EC0 和基本塊loc_415EAC 中);在數據流的層面表現為,字節從內存的一個區域流向了另一段內存區域.以MIPS 下的函數strncpy為例,如圖4 所示,即字節從寄存器$a1 指向的內存流向了寄存器$v1 指向的內存中,此過程未對數據進行修改.
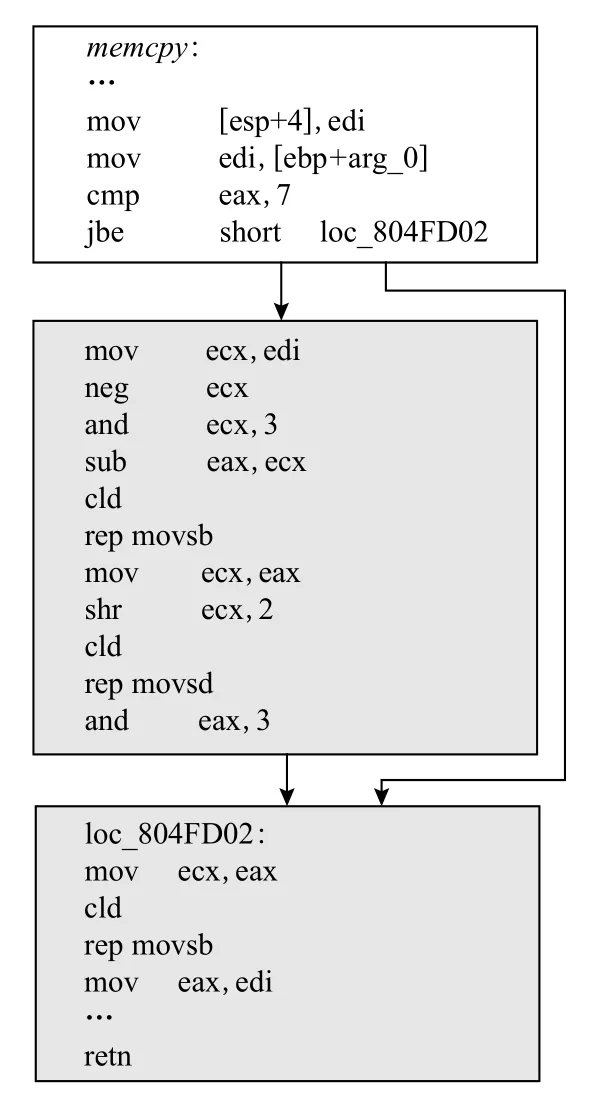
Fig.5 The memcpy function under the x86 instruction set圖5 x86 指令集下的memcpy 函數
拷貝類函數的另一個特點就是存在偏移的更新,即需要對內存地址進行更新,以便將數據儲存到連續的內存單元.以簡單的拷貝類函數為例,如圖4 所示,即存在對寄存器$v1(addiu $v1,1)的更新.然而,自定義實現的拷貝類函數可能包含更多的復雜操作以及分支判斷,導致循環路徑上可能包含多個基本塊,并不是如圖4 中所示的那樣只有兩個基本塊,并且編譯器的優化也對函數造成一定的影響,數據流會經過多次的轉移變化,因此拷貝類函數并不是像BootStomp 以及SaTC 中所提的特征那么簡單,對其的檢測需要更準確的數據流特征.
2.4 現有相關方法及其不足
基于循環路徑的溢出漏洞檢測在二進制程序分析中和源碼分析中都存在諸多的應用,例如2012 年,Rawat 等人[27]提出檢測二進制程序中由循環路徑導致的溢出漏洞(buffer overflow inducing loops,BOILs),實現了一個輕量級的靜態分析工具來檢測BOILs.然而此方法未對數據流進行分析,僅依靠BOILs 的特征進行檢測,并且只支持x86 的二進制程序.2020 年,Luo 等人[28]提出在源碼層面檢測由循環路徑導致的溢出漏洞,由于該方法針對的是源代碼,而二進制程序丟失了源碼中較多的語義、變量類型、結構體等信息,難度更大,該方法不適用于對二進制程序的分析.
隨著靜態污點分析技術和物聯網技術的發展,研究者開始將靜態污點分析應用到對固件的脆弱性檢測中,如Redini 等人先后在2017 年和2020 年分別提出BootStomp[8]和Karonte[9],使用靜態污點分析來檢測安卓手機中bootloader 的脆弱性和嵌入式設備系統中,如路由器、網絡攝像頭等由于多二進制交互而產生的漏洞.如圖6 所示,Karonte 仍需要借助函數名的信息.2021 年,Chen 等人[14]提出使用靜態污點分析檢測嵌入式設備中與前端關鍵字關聯的漏洞技術SaTC,如圖7 所示,借助函數名信息對嵌入式設備的固件進行靜態分析依賴于對拷貝類函數的識別.然而當前的方法依賴于函數名等信息,并且僅僅通過簡單的特征匹配模式進行檢測,存在較高的漏報率和誤報率.

Fig.6 Static taint analysis in Karonte relies on function name information圖6 Karonte 中靜態污點分析依賴于函數名信息

Fig.7 Static taint analysis in SaTC relies on function name information圖7 SaTC 中靜態污點分析依賴于函數名信息
本文研究發現,由于拷貝類函數多種多樣,僅僅依靠模式匹配很難識別出拷貝類函數.因此本文在CFG 分析和模式匹配的基礎上,增加對函數的DFG的分析,通過對DFG 的分析來提高拷貝類函數識別的準確率,降低誤報率和漏報率,并且為了支持多指令集架構,將不同指令的二進制代碼轉換為VEX IR代碼進行分析,使得該方法具有較高的適用性.
2.5 VEX IR 中間語言
由于IR 能夠保留指令的語義信息,具有出色的可拓展性,可以將不同指令集的代碼進行歸一化,被廣泛應用于跨指令集的程序分析[29-30].其中較為著名的是VEX IR,由于其支持的指令集架構相對齊全,并且提供了Python 的API[31],被較多的二進制分析工具angr[32],MockingBird[33],Binmatch[34]使用.為了能夠支持對多指令集架構的二進制程序進行分析,本文選用VEX IR 作為中間語言對函數的數據流進行分析.
本節對VEX IR 的指令類型進行了梳理,并給出了對應的操作碼和示例,結果如表1 所示.將VEX IR指令分為8 種類型,分別為寄存器訪問、內存訪問、算術運算、邏輯運算、移位運算、轉換、函數調用以及其他指令.其中,寄存器訪問指令是對寄存器的讀取和寫入,內存訪問指令是從內存中加載數據和將數據存儲到內存中;函數調用指令會修改pc寄存器的值,并給出一個關鍵字Ijk_Call;其他指令包括比較指令以及其他不常見的指令,如ITE(if-then-else).通過對VEX IR 指令的分析獲取變量間的數據流動.

Table 1 Instruction Types and Examples of VEX IR表1 VEX IR 的指令類型及示例
3 拷貝類函數識別
拷貝類函數識別是給定一個二進制函數(匯編代碼或二進制代碼),在不借助符號表的情況下,通過靜態分析技術或者動態分析技術來判斷該函數是否具有內存拷貝的功能.二進制程序中拷貝函數識別是給定一個含有n個函數的二進制程序B(剝離或者保留函數名等信息),即B={f1,f2,…,fi,…,fn},其中fi為包含m個基本塊的二進制函數(通常以函數的起始地址命名),fi={b1,b2,…,bj,…,bm},bi為函數fi的基本塊.用L={bk|bk∈fi∧k∈LP}表示參與循環的基本塊,其中k為基本塊編號,LP為循環的路徑,由CFG 遍歷算法獲得保存著參與循環的基本塊的編號.因此當LP=? 時,函數不為拷貝類函數(x86 指令集除外).對二進制程序中每個函數進行識別,判斷是否為拷貝類函數,輸出該二進制程序中對所有函數的識別結果.
本文對具備拷貝類功能的函數研究發現,具備拷貝功能的函數可能不單單完成一項任務,即將數據從一段內存區域轉移到另一段內存區域,它可能具備更多其他的功能,例如數據轉移后的處理.因此可以將拷貝類函數分為粗粒度的拷貝類函數和細粒度的拷貝類函數.細粒度的拷貝類函數只完成內存拷貝的功能;粗粒度的拷貝類函數除了做內存拷貝的功能外,還存在更多的功能.因此為減少待分析函數的數量,可以通過對函數的復雜程度進行過濾,例如以基本塊的數量進行過濾,通常情況下細粒度的拷貝類函數的基本塊數量小于50(這里閾值的設置根據對當前的拷貝類函數分析所得,實際應用中可以根據具體的后續任務需求設置閾值進行過濾).
4 拷貝類函數識別技術
本節對二進制程序中拷貝類函數識別技術進行詳細介紹.二進制程序中拷貝類函數識別技術CPYFinder 的流程如圖8 所示:

Fig.8 Workflow of memory copy function identification圖8 內存拷貝類函數識別的流程
CPYFinder 總共分為6 個模塊:CFG 提取和循環檢測模塊、循環指令提取模塊、VEX IR 指令生成模塊、數據流構建模塊、數據流分析模塊和拷貝類函數識別模塊.其中:CFG 提取和循環檢測模塊主要分析二進制程序中是否包含循環路徑;循環指令提取模塊借助于IDA Pro 等逆向分析工具從二進制程序中提取循環路徑上的指令;VEX IR 指令生成模塊借助于pyvex 工具將指令轉換為中間語言指令,方便系統支持對多種指令集架構的程序進行分析;數據流構建和數據流分析模塊從VEX IR 指令提取變量間的數據關系,并對其進行分析;拷貝類函數識別模塊依據拷貝類函數數據流的特點對函數循環路徑上的數據流進行判斷.具體的拷貝類函數識別算法如算法1 所示.
算法1.拷貝類函數識別算法.
輸入:函數起始地址;
輸出:函數是否為拷貝類函數(值為0 或1).
4.1 函數控制流的生成及循環識別
在第2 節中,本文對拷貝類函數的特點進行了分析,除了x86 指令集下存在使用rep movsb 等實現內存拷貝的特殊指令(x86 下需要添加對rep movsb 指令進行檢測),在ARM,MIPS,PowerPC 指令集下拷貝類函數均需借助循環進行內存數據的轉移.因此,對循環的檢測是拷貝類函數識別的基礎.CPYFinder首先對二進制函數的CFG 進行提取,以判斷函數執行流中是否存在循環,在非x86 指令集下,CFG 不包含循環則直接視為非拷貝類函數.
CFG 中保存著函數內基本塊間的關系,通過對匯編指令的解析可以獲取基本塊之間的關系,IDA Pro提供了API 即函數FlowChart()來獲取二進制函數的基本塊以及基本塊間的關系,因此本文直接借助IDA Pro 獲取基本塊間的關系.為了快速地生成圖以及對后續的處理,選擇使用networkx 庫[35](用于創建、操作和處理復雜網絡的Python 庫).通過將基本塊間的關系輸出到networkx 的創建圖的API 函數DiGraph()中,生成函數的CFG(算法1 行②和③).
在獲得了函數的CFG 后,為進一步判斷是否為拷貝類函數,需要判斷CFG 是否包含循環.由于判斷圖結構中是否包含環,以及對算法的效率的分析是圖論中研究的內容,這里不再做探討.此外,判斷圖結構中是否包含環的算法已經十分成熟,這里將利用networkx 提供的函數simple_cycles()判斷CFG 是否包含循環路徑以及生成循環路徑,用于后續循環內數據流的生成(算法1 行④).當CFG 包含循環路徑時,進行后續的拷貝類函數的識別;當CFG 中無循環路徑,并且該二進制程序非x86 指令集,認為此函數為非拷貝類函數(對于x86 指令集的函數,如果指令中存在rep movsb 等指令,認為是拷貝類函數).
4.2 基于VEX IR 的數據流生成與分析
L={bk|bk∈fi∧k∈LP}
在獲取了循環路徑后,為了支持多指令集架構并方便后續的處理,將基本塊的指令全部轉換為VEX IR 指令,然后對VEX IR 指令進行過濾分析,構建變量之間的數據關系(算法1 行⑥和⑦).如圖9 所示,為ARM 指令集下二進制字節碼E5 F1 E0 01 生成的匯編代碼(圖9 行1)和VEX IR代碼(圖9 行3~10).CPYFinder 依據表1 中指令的類型,使用正則表達式對指令的變量進行提取,將指令中的變量分為目的和源,即(dst,src),其中由于存在指令對多個變量進行操作,例如Add 操作,因此,源操作數src又記錄為(src1,src2),然后根據指令的類型和特點對源變量和目的變量構建數據流關系.在整個變量關系記錄過程中,只記錄變量之間的關系,不記錄常量.以圖9 的行4 為例說明,數據流動方向為從r1 到t18(VEX IR 的臨時變量以t開頭),行5 數據流動方向為從t18 流向了t17,不記錄常量0x00000001流向了t17,依次構建所有的變量之間的關系.由于pc,eip等特殊的寄存器與拷貝類函數的判斷無關,因此在進行變量關系生成時會將此類的寄存器過濾掉,不做處理,圖9 中變量的關系記錄為{(t18,r1),(t17,t18),(t20,t17),(t38,t20),(lr,t38),(r1,t17)}.

Fig.9 Assembly code and VEX IR code圖9 匯編代碼和VEX IR 代碼
在對所有的VEX IR 代碼遍歷的同時記錄直接參與內存訪問(加載指令點記錄為LD點,存儲指令點記錄為ST點)和參與算術運算的變量,例如圖9 中的行5 和行6,其中行5 為加運算操作,行6 為從t17指向的內存單元中加載數據.在對所有的VEX IR 指令遍歷后,生成了所有變量之間的關系、內存加載變量集合、內存存儲變量集合、算術運算變量集合.圖9中的所 有數據 為變量關系{(t18,r1),(t17,t18),(t20,t17),(t38,t20),(lr,t38),(r1,t17)}、內存加 載集合 為[t20]、內存存儲集合為 ?、算術運算變量集合為[t17].由于圖9 中VEX IR 指令中無ST指令,因此內存存儲集合為空.
在獲取上述數據后,將所有變量之間的關系輸入到函數DiGraph()中構建DFG.經過大量的分析發現,拷貝類函數的DFG 具有5 個特征:
特征1.數據流圖上存在LD點;
特征2.數據流圖中存在ST點;
特征3.存在從LD點到ST點的路徑,并且LD點先于ST點出現;
特征4.數據流圖上存在環結構,并且環上存在算術運算;
特征5.環上的點能夠到達特征3 上的ST點.
基于5 個特征,對函數的循環內的數據流進行分析,數據流滿足5 個特征的函數被認為是拷貝類函數.這里以存在LD點和ST點(特征1 和特征2)的數據流圖為例進行具體識別過程的描述.使用networkx的路徑通過函數all_simple_paths()來判斷DFG 中是否存在LD點到ST點的路徑(特征3),如果不存在該路徑,則認為不滿足拷貝類函數數據流的特征.當從LD點到ST點存在路徑時,則進一步判斷DFG 中是否存在環結構,并且環上節點的關系是否存在算術運算(特征4),如果滿足特征4,就繼續判定環上的點能否到達滿足特征5 的ST點,如果滿足上述所有特征,認為此函數為拷貝類函數.由于函數內可能存在多條循環路徑,因此只要存在1 條循環路徑的DFG滿足5 個特征,則認為此函數為拷貝類函數.
4.3 對特殊拷貝類函數的處理
正如第2 節中的函數alps_lib_toupper存在函數在循環塊內調用其他函數的情況,因此,本文認為在內存拷貝中調用了其他函數的函數為特殊拷貝類函數.此類函數由于函數的調用會導致數據流的中斷,因此需要對變量間的數據流進行連接,即在函數的參數與函數的返回寄存器之間建立數據流關系.當發現循環中存在函數調用時,對被調用函數的參數傳遞情況及返回值寄存器使用情況進行分析;當函數調用后存在返回值寄存器被使用的情況,則將被調用函數參數與返回值寄存器之間構建數據流,當前方法中是將函數的第2 個參數與函數返回值寄存器建立數據流.如果返回值寄存器未被使用,則直接在第2 個參數和第1 個參數間建立數據流關系(一般情況下,目的寄存器是第1 個參數,源地址寄存器是第2 個參數,返回值寄存器的值會指向目的寄存器).對于不同的指令集,其參數的傳遞方式和結果返回的方式(返回值寄存器)均不同,因此需要對各個指令集根據其參數傳遞方式的約定進行數據流的連接,對于x86 指令集則根據其利用棧進行參數傳遞的方式,追溯壓入棧的指令和變量,與返回值寄存器進行連接;對于ARM,MIPS,PPC,由于都是首先使用寄存器進行參數的傳遞,參數寄存器不足時采用棧進行參數傳遞.研究發現,通常情況下參數寄存器即可滿足此類拷貝類函數中的參數傳遞,因此,直接在參數寄存器之間和返回值寄存器之間或者參數寄存器之間建立數據流關系,以避免數據流的中斷,導致對特殊拷貝類函數的遺漏.
5 實驗評估
本節從不同的角度利用CPYFinder 對拷貝類函數識別的效果進行評估,并與現有方法BootStomp,Karonte,SaTC 進行對比,包括對庫函數識別效果、自定義函數識別效果、多架構的支持、受編譯器的影響和編譯優化等級的影響、在實際的漏洞函數檢測中的效果以及識別的運行效率等進行評估.
5.1 實驗設置和數據集
1)實驗環境.實驗所使用計算機的配置為Intel?CoreTM6-core、3.7 GHz i7-8700K CPU 和32 GB RAM.軟件為Python(版本為3.7.9)、pyvex(版本為9.0.6136)、networkx(版本為2.5)、IDA Pro(版本7.5)以及基 于buildroot 構建的交叉編譯環境用于生成不同架構的二進制程序.
2)對比方 法.BootStomp(Usenix17),Karonte(S&P20),SaTC(Usenix21)(由于Karonte 與SaTC 對拷貝類函數實現完全相同,本文只與SaTC 進行對比),經過分析發現由于SaTC 借助于工具angr 來識別函數的參數個數,在識別過程中限制了參數的個數n即2≤n≤ 3,由于angr 對參數個數錯誤的識別,導致很多拷貝類函數被過濾掉,例如函數strcpy實際上存在2 個參數,而angr 識別出來的參數個數為4,因此,本文對SaTC進行修改后,取消其對參數個數限制的方法為SaTC+.
3)工具實現.CPYFinder 基于IDAPython 和pyvex進行實現,并借助于network 對CFG 和DFG 進行處理.表2 展示各個方法實現主要依賴的工具和支持的指令集.

Table 2 Comparison of Existing Methods and CPYFinder表2 現有方法與CPYFinder 對比
4)數據集.本文首先對C 語言庫中的拷貝類函數進行分析,根據其應用程序編程接口(application programming interface,API)編寫一個主程序來調用所有string.h 和wchar.h 中的函數拷貝類函數,如表3 所示,列出了C 語言庫中的拷貝類函數,其中string.h 為普通拷貝類函數,wchar.h 為寬字符拷貝類函數,用于測試不同工具的效果.此外為驗證對用戶自定義實現(非C 語言庫中)的拷貝類函數的識別效果,本文從Github(Netgear R7000 路由器代碼[36]以 及Mirai 代 碼[37])上搜集了22 個此類的函數,整合到一個C 程序中進行編譯測試.

Table 3 Memory Copy Functions Used in the Experiment表3 實驗中使用的內存拷貝類函數
5)評估標準.本文使用精準率(precision,P),以及召回率(recall,R)來評估本文所提方法的效果,精準率和召回率越高效果越好.
TP為將拷貝類函數識別為拷貝類函數的數量 ;FP為將非拷貝類函數識別為拷貝類函數的數量 ;FN為將拷貝類函數識別為非拷貝類函數的數量.
6)編譯器以及優化等級.如表4 所示為實驗評估中使用的編譯器、編譯器類型及優化選項,使用GCC 和Clang 這2 個編譯 器進行測試,并使用buildroot 構建了不同指令集的交叉工具鏈,用于生成不同目標架構的程序(在當前的Clang 編譯器中,O3優化等級與O4 優化等級仍相同).

Table 4 Compilers Used in the Evaluation Experiments表4 評估實驗中所使用的編譯器
5.2 實驗結果
5.2.1 對C 語言庫中拷貝類函數的識別效果
為了驗證對C 語言庫中拷貝類函數的識別效果,本文編寫C 代碼,調用string.h 和wchar.h 庫中的函數來編譯成不同的二進制程序(由于BootStomp 只支持ARM 指令),這里使用靜態方法將源代碼編譯成ARM 架構的二進制程序,使用的編譯器版本為4.5.4,4.6.4,4.7.4,4.8.5,優化等級為O0,此外由于5.0 以上版本的GCC 使用的libc 庫在拷貝類函數的實現,不同的拷貝類函數會調用同一個函數,導致拷貝類函數的種類下降,例如strcpy,strncpy的拷貝功能的實現是直接調用函數memcpy進行的,這些函數本身不存在拷貝類函數的特點,只是函數memcpy的封裝,因此這里未使用高版本的編譯器.各個方法的識別效果如表5 所示,從表5 中可以看出,CPYFinder 的效果優于其他3 種方法,即BootStomp,SaTC 和SaTC+.盡管BootStomp 具有較高的精準率P,但是召回率R卻不高于0.5,盡管SaTC+識別效果好于SaTC(后續實驗只與SaTC+進行對比),但是仍低于BootStomp 和CPYFinder,而在實際分析中,為避免遺漏關鍵函數,應該在保證召回率的情況下提高精準率.分析發現,誤報的函數來源于編譯器的靜態編譯會引入其他的函數,例如__do_global_dtors_aux,__getdents函數,由于靜態分析數據流的準確性有限,導致誤報的產生.此外,CPYFinder 在gcc-4.7.4-0 上的識別效果最好,精準率到達了0.81,召回率為1.0.
從表5 中可以看出編譯器版本對拷貝類函數識別存在一定的影響.總的來說,對C 語言庫中拷貝類函數的識別,CPYFinder 優于BootStomp,SaTC 和SaTC+.

Table 5 Comparison of Methods for Identifying Memory Copy Functions in C Libraries表5 各方法對C 語言庫中內存拷貝函數識別對比
5.2.2 用戶自定義的拷貝類函數的識別效果
為了測試用戶自定義實現的拷貝類函數的識別效果,正如5.1 節中介紹,本文從開源庫中收集了相關的用戶自定義實現的拷貝類函數,使用不同的編譯器編譯成ARM 程序進行測試,測試結果如表6 所示.從表6 中可以看出,BootStomp 雖然對庫函數中拷貝類函數識別效果好于SaTC+,但是對自定義實現的拷貝類函數識別效果較差,雖然其準確率幾乎為1,但是召回率幾乎為0.從表6 中準確率和召回率得出結論:CPYFinder 對自定義拷貝類函數識別的效果好于BootStomp 和SaTC+,并且隨著編譯器版本的升級,識別效果越好.

Table 6 Comparison of Methods on the Identification of Custom Memory Copy Functions表6 各方法對自定義內存拷貝類函數識別對比
5.2.3 不同指令集及優化等級下的識別效果
為了展示CPYFinder 對不同架構的拷貝類函數識別效果以及受優化等級的影響,本文將源碼使用GCC 編譯器版本5.4.0 編譯成4 種架構的程序(x86,ARM,MIPS,PPC)以及不同的優化等級(O0~O3).由于BootStomp 和SaTC 不完全支持上述指令集架構,因此不再測試BootStomp 和SaTC 受指令集架構的影響,首先測試CPYFinder 受指令集架構和優化等級的影響,然后在ARM 架構的程序上測試BootStomp,SaTC 和CPYFinder 受優化等級的影響.從表7 中可以看出,CPYFinder 支持x86,ARM,MIPS,PPC 指令集架構的二進制程序,并且識別的精準率和召回率幾乎相同.此外,CPYFinder 會受編譯優化等級的影響,在無優化(O0 等級)下識別的效果最好,隨著編譯優化等級的提升,召回率和精準率均會略微下降.從表8中可以看出,除了BootStomp 在O1 優化下表現較好,SaTC 和CPYFinder 均是在O0 下表現較好.
5.2.4 不同編譯器下拷貝類函數的識別效果
為了展示不同方法受編譯器種類以及優化等級的影響,本文將使用不同源碼版本的GCC 和Clang編譯器以O1 優化等級將源碼編譯成ARM 架構的二進制程序,各個方法識別的效果如表9 所示.
從識別的結果來看,BootStomp 識別的精準率為1,但是召回率卻極低;而SaTC+識別的精準率和召回率均低于CPYFinder.此外,3 種方法識別的效果均顯示對Clang 編譯的程序識別效果更好.因此,從表9 數據可得出結論:CPYFinder 識別效果好于BootStomp和SaTC+,并且對Clang 編譯的程序的識別效果優于由GCC 編譯生成的程序.

Table 7 Effect of Different Instruction Sets and Optimization Levels on the Identification表7 不同指令集及優化等級對識別的影響
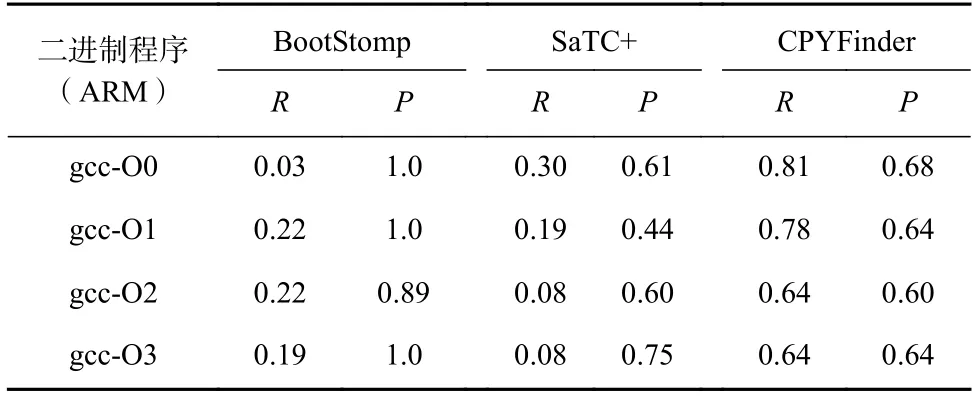
Table 8 Effect of Optimization Level on the Identification of Each Method表8 優化等級對各個方法識別的影響

Table 9 Comparison of the Identification Effect of Each Method Under Different Compilers表9 不同編譯器下各方法的識別效果對比
此外,本文還測試了Clang 編譯下,不同版本(3.9.1,6.0.1)以及不同優化等級(O0~O4)對拷貝類函數識別效果的影響,對比結果如表10 所示.從表10中可以看出,BootStomp 和CPYFinder 受Clang 優化等級的影響均較少,并且在版本較高(6.0.1 版本)的編譯器下,識別效果更好;而SaTC+受編譯優化等級的影響較大,隨著編譯優化等級的升高,其識別效果逐漸下降.此外,BootStomp 和SaTC+存在精準率P和召回率R均為0 的情況.在Clang 編譯的ARM 程序下,CPYFinder識別的效果好于BootStomp 和SaTC+的識別效果.

Table 10 Effect of Clang Compiler on the Identification of Memory Copy Function表10 Clang 編譯器對內存拷貝類函數識別的影響
5.2.5 固件中已知漏洞函數的檢測
為了測試CPYFinder 在實際固件中拷貝類函數識別的效果,本文收集了近5 年來公開分析的路由器設備固件中的漏洞,其中多數與函數strcpy相關,由于函數strcpy作為導入函數調用,無法對其進行識別,不符合實驗的要求,因此,最終篩選出由循環拷貝導致的溢出漏洞,共獲得了5 個CVE,如表11 所示.這5 個漏洞分別發現于TP-Link 和D-Link 的路由器設備固件中,總共4 個固件(其中CVE-2018-3950和CVE-2018-3951 由同一個程序中的不同函數導致),這4 個固件均是MIPS 指令集架構的二進制程序,并且均是在由循環實現的內存拷貝中由于對長度未進行校驗導致的棧溢出漏洞,并且循環路徑中包含多個基本塊.對這5 個導致棧溢出漏洞的函數進行識別測試,判斷BootStomp,SaTC+,CPYFinder 是否能夠識別出這5 個函數為拷貝類函數,即是否存在內存拷貝的代碼片段.

Table 11 Identification Results for Overflow Vulnerabilities Caused by Loop Copy表11 對由循環拷貝導致的溢出漏洞的識別結果
測試結果如表11 所示,BootStomp 由于不支持MIPS 架構的二進制程序的識別,給出的結果全為*,SaTC+未識別出這5 個函數,其中在包含CVE-2018-3950 和CVE-2018-3951 的程序中運行時直接崩潰,未給出結果.而CPYFinder 識別出4 個溢出漏洞,其中導致CVE-2018-11013 的漏洞函數未檢測出,導致CVE-2018-11013 的函數未檢測出的原因如圖10 所示.經過分析發現,由于該循環內首先對數據進行存儲(基本塊loc_41EB04 中第1 條指令sb v1,0x40(v1,0x40(v0)),然后進行數據的加載(基本塊loc_41EB04中第3 條指令lbu v1,0(v1,0(a0)),這與4.2 節設定的數據流的特征3 沖突,導致對函數websRedirect識別為非拷貝類函數,在關閉特征3 的限制后,CPYFinder能夠識別出該CVE,但是隨之CPYFinder 的識別精準率會下降,誤報率會增加,在實際的固件程序分析中,可以根據需要來決定是否開啟特征3 的限制.
綜上所述,基于控制流和數據流的CPYFinder 在實際的漏洞函數發現上,效果遠遠好于基于特征匹配的BootStomp 和SaTC+.
5.2.6 效率分析
本節對BootStomp,SaTC,SaTC+,CPYFinder 在拷貝類函數識別中的效率進行分析,選取的程序為5.2.1 節中測試的程序,各個方法時耗的對比結果如表12 所示,CPYFinder 的效率遠遠高于BootStomp 和SaTC.由于不再對函數參數個數進行分析,SaTC+的時耗低于SaTC.因此,CPYFinder 在較高的精準率P和較高的召回率R情況下仍具有較低的時耗.其中CPYFinder 只用了相當于BootStomp 19%的時間,與SaTC 和SaTC+的耗時相當.盡管CPYFinder 對數據流進行了分析,然而由于SaTC 是基于angr 開發的,angr在分析二進制程序時的效率較低,因此CPYFinder 借助于IDA Pro 盡管增加了數據流分析但整個耗時卻幾乎未增加,而BootStomp 借助了IDA Pro 的反編譯引擎,由于反編譯分析耗時較久,因此BootStomp 的耗時較高.

Fig.10 Vulnerable functions not identified by CPYFinder圖10 CPYFinder 未識別出的漏洞函數
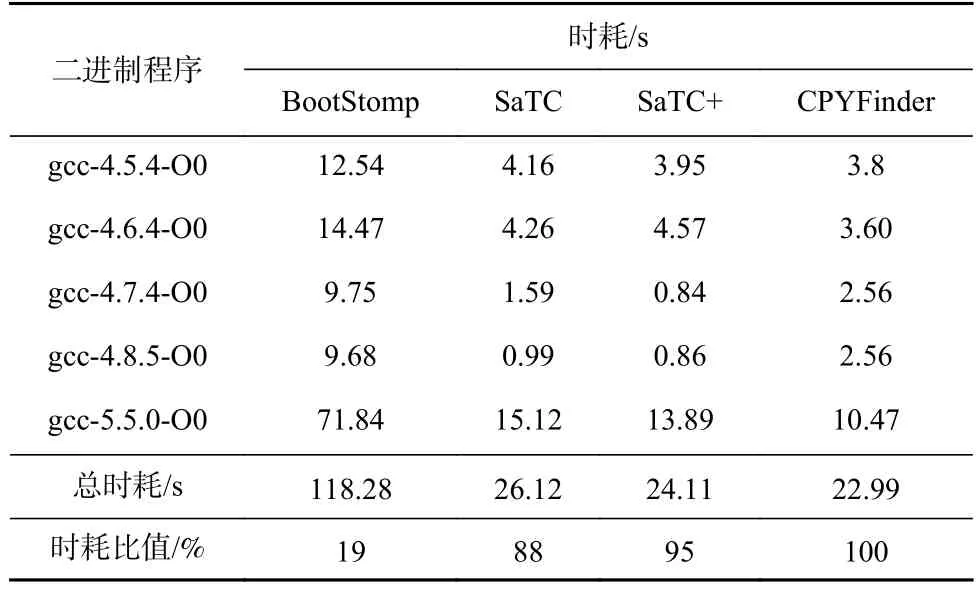
Table 12 Comparison of Time Consumption for Memory Copy Functions Identification表12 對內存拷貝類函數識別時耗對比
6 CPYFinder 與IDAPro 集成
為方便對工具的使用,本文將CPYFinder 以IDA插件的形式與IDA Pro 進行了集成,并實現可視化的結果輸出;支持對單個函數的識別和整個二進制程序中所有函數的識別,將識別分為single 和all 這2種識別模式,其中single 模式識別當前光標指向的地址所在的函數是否為拷貝類函數,如圖11 所示.single 模式的輸出如圖12 所示.對整個二進制程序的識別結果可視化界面如圖13 所示,該界面共分為5 個部分,其中Line 為檢測時的序號、Local Address展示函數的地址、Local Name 展示函數名、Loop Address 展示發現的拷貝函數的循環地址入口以及Is Copy Function 展示該函數是否為拷貝類函數(是為1,不是為0).借助于IDA Pro 的跳轉功能,能夠方便后續手工分析對結果的確認.

Fig.11 The interface that CPYFinder provides to the user for mode selection.圖11 CPYFinder 提供給用戶模式選擇的界面

Fig.12 Output of CPYFinder in single function mode圖12 CPYFinder 的單函數模式single 下的輸出

Fig.13 Visualization results of CPYFinder’s all-mode in IDA Pro圖13 CPYFinder 的all 模式在IDA Pro 中的可視化結果
7 討論
本文提出的拷貝類函數識別技術CPYFinder 通過將二進制函數轉換成中間語言VEX IR 進行數據流的分析,支持對多指令集架構(x86,ARM,MIPS,PPC)的二進制程序中拷貝類函數的識別,不依賴于符號表等信息,并且受編譯器版本、優化等級的影響較小.此外,CPYFinder 不僅能夠識別庫函數中的內存拷貝類函數,還能識別用戶自定義的內存拷貝類函數,具有較高的適用性.雖然基于靜態分析的識別方法具有快速、高效的特點,但是由于靜態數據流分析很難做到十分精確,并且由于用戶自定義實現的拷貝類函數多樣以及受編譯器和優化等級的影響,無可避免地會存在一定的誤報和漏報,所以在識別的準確率上具有一定局限性.在后續的研究中,嘗試將動態執行以及動靜態分析結合的方式應用到拷貝類函數的識別中,提高對拷貝類函數識別的準確率.
8 結束語
拷貝類函數的識別對內存錯誤漏洞的檢測具有重大價值,能夠提升下游分析任務的能力,如污點分析、符號執行等.本文提出了一種基于控制流和數據流分析的拷貝類函數識別技術CPYFinder,通過將二進制程序轉換為中間語言VEX IR,進行后續的數據流分析,提高了對拷貝類函數識別的精準率和召回率,使得CPYFinder 具有較高的適用性,并且具有較低的運行耗時,支持多種指令集架構(x86,ARM,MIPS,PPC).實驗結果表明,CPYFinder 不僅能夠有效地識別出C 語言庫中的拷貝類函數,還能夠識別用戶自定義實現的拷貝類函數,并且受編譯器版本、編譯優化等級的影響較小,能夠發現路由器固件中由此類函數導致的溢出漏洞,這對內存錯誤類漏洞的發現和分析具有重要作用.
作者貢獻聲明:尹小康負責算法和對比實驗的設計、算法的實現、初稿撰寫和修改;蘆斌完成算法和對比實驗可行性分析、論文的審閱;蔡瑞杰負責實驗結果分析、論文的修改;朱肖雅協助實驗數據收集、論文的修改;楊啟超負責論文的審閱、修改和完善;劉勝利提出研究問題、負責算法和實驗的可行性分析、論文的審閱和修改.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
人大建設(2019年12期)2019-05-21 02:55:44
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電子制作(2018年18期)2018-11-14 01:48:24
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
山東工業技術(2016年15期)2016-12-01 05:31:22
中國衛生(2015年3期)2015-11-19 02:53:32
