社交媒體文本數據的抑郁癥檢測研究綜述
2023-02-28 09:19:20徐東東蔡肖紅
計算機工程與應用 2023年4期
徐東東,蔡肖紅,劉 靜,曹 慧
山東中醫藥大學 智能與信息工程學院,濟南 250355
抑郁癥是全世界主要致殘原因,也是造成全球疾病總負擔的主要因素之一[1],其主要特點有持續的悲傷、失去興趣或快樂等。抑郁癥會給患者身心帶來極大的影響且容易復發,當抑郁癥發展到中度或重度時,將成為一個嚴重的健康疾患甚至導致患者自殺[2],從而對家庭和社會造成嚴重的損失。
目前,抑郁癥的診斷主要基于國際疾病分類標準(international classification of diseases,ICD)和精神疾病診斷統計手冊(diagnostic and statistical manual of mental disorders,DSM),這種診斷方式易受患者的主觀信念和醫師的診斷經驗影響[3]。此外,現代社會對于抑郁癥等精神類疾病的接受程度普遍較低,抑郁癥患者自身也常由于存在病恥感和對精神疾病缺乏了解等原因而沒有選擇求醫,結果造成眾多患者因未得到及時、準確的診斷而錯失最佳治療機會[1]。
隨著互聯網的興起,人們越來越傾向于在社交媒體上分享自己的生活狀態,且患有精神疾病的人也以傾訴自己的精神狀態作為一種解脫[4]。同時,越來越多的證據表明,社交媒體平臺上發布的特定語言和情緒可能提供了關于抑郁癥的線索[5-8]。在此背景下,機器學習也逐漸被運用到基于社交媒體文本數據的抑郁癥檢測中[9-11]。基于傳統機器學習的方法可以執行自動、客觀和有效的評估[12],但是其性能在很大程度上依賴于特征的構建和選擇,并且泛化性受到所使用特征和算法的限制。而深度學習以理解復雜自然語言句子的上下文為目標,徹底改變了潛在特征提取過程。現有的基于深度學習的抑郁癥檢測系統能夠執行預處理、特征提取和抑郁癥檢測等連續過程,實現了端到端的全自動化抑郁癥檢測[13],在抑郁癥的預防和治療方面具有重大意義。
目前,國外關于利用機器學習在基于社交媒體文本數據的抑郁癥檢測研究仍在不斷發展進步,但國內少有關于此領域的研究和報告。本文對在社交媒體文本中運用機器學習檢測抑郁癥進行綜述,以期為國內研究提供借鑒。
1 機器學習及流程概述
機器學習(machine learning,ML)是指利用計算機通過對已有數據進行自主學習以改善自身功能,從而能夠在下一次執行相同任務時做得更好或者效率更高的一種技術。機器學習可根據用于學習的數據性質分為監督學習、無監督學習、半監督學習,也可根據模型結構的深度分為傳統機器學習和深度學習[14]。
利用機器學習方法在基于社交媒體文本數據中檢測抑郁癥的一般流程如圖1 所示,主要分為以下步驟:數據采集,數據預處理(基礎預處理和特征工程),利用機器學習算法對文本表示進行學習,以及使用測試數據評估已學習好的模型。

圖1 利用機器學習方法檢測抑郁癥的一般流程Fig.1 General process of detecting depression using machine learning
目前,廣泛使用在社交媒體文本中檢測抑郁癥的傳統機器學習算法有邏輯回歸(logistic regression,LR)、決策樹(decision tree,DT)、支持向量機(support vector machine,SVM)、樸素貝葉斯(naive Bayes,NB)和隨機森林(random forest,RF)等。而隨著深度學習的發展,卷積神經網絡(convolutional neural network,CNN)、循環神經網絡(recurrent neural network,RNN)和基于Transformers 的雙向編碼器表示(bidirectional encoder representation from transformers,BERT)等算法得以推廣和使用。
衡量抑郁癥檢測算法性能的常用評價指標有準確率(accuracy,Acc)、精確率(precision,P)、召回率(recall,R)和F1 值。而這些評價指標沒有考慮到時間因素,對此Losada 等人[15]提出了早期風險檢測誤差(early risk detection error,ERDE)指標。該指標同時考慮二元決策的正確性和模型做出決策所用的延遲,而延遲通過在模型給出預測之前所輸入文章(帖子或評論)的數量(k)來衡量。ERDE指標的計算如式(1)所示:
其中,d為模型所做出的決策,gt為黃金真理(golden truth),cfp和cfn分別為假陽性和假陰性的代價。函數lco(k)(∈[0,1])代表檢測真陽性的延遲的代價,其計算公式如式(2)所示。o為延遲成本函數中代價增長更快的k軸的位置,也是lco和ERDEo的下標,決定著延遲做出決定的代價的高昂程度。圖2為lc5(k)和lc50(k)的函數圖像。ctp通常被設置為與cfn相同的值。在抑郁癥數據集中,假設共有p個不同的個體,因此模型將做出p個決定,總體ERDE值將是這p個ERDE值的平均值。
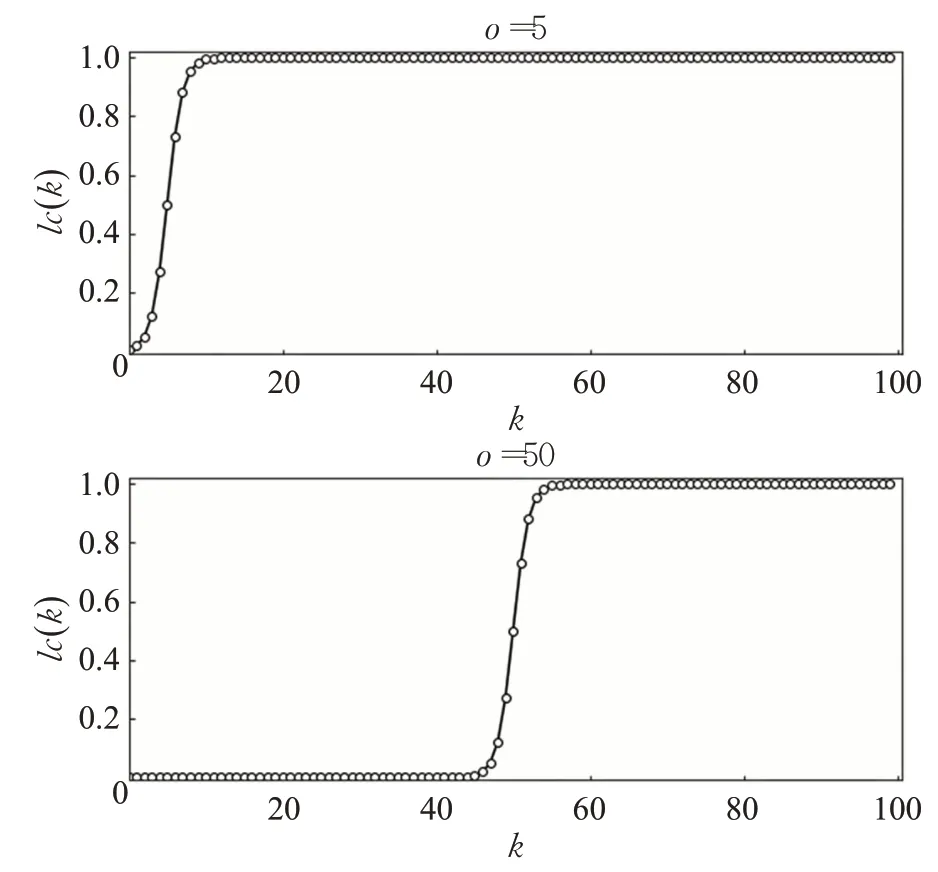
圖2 延遲成本函數lc5(k)和lc50(k)Fig.2 Latency cost functions lc5(k)and lc50(k)
2 數據采集與預處理
2.1 社交媒體文本數據采集
社交媒體文本數據主要來源于各社交媒體中用戶發布的帖子和評論。研究者們用于抑郁癥檢測的數據一般是從Reddit、Twitter和新浪微博等平臺上爬取或使用API獲取。目前,常用的公開數據集較少,主要有RSDD(Reddit self-reported depression diagnosis)數據集[16]、ERisk(early risk prediction on the Internet)任務中的抑郁癥早期檢測數據集ERiskD 2017[17]和ERiskD 2018[18]、CLPsych 2015(computational linguistics and clinical psychology)共享任務中用于抑郁癥檢測任務的數據集CLPD[19]和由Shen 等人利用Twitter API 創建的抑郁癥檢測數據集MDDL[1]。上述數據集由用戶發布的帖子集合構成,一般根據用戶自我陳述的診斷(諸如“我已經被診斷為抑郁癥”等)和人工審查進行標注。各數據集的統計信息見表1。
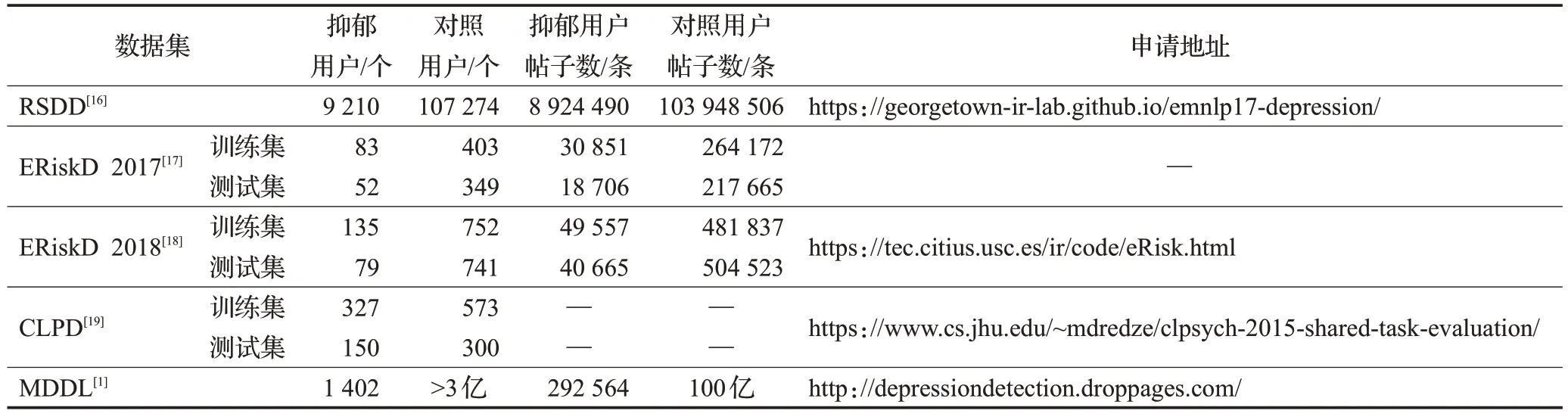
表1 常用公開數據集統計信息Table 1 Statistics of common public datasets
2.2 數據預處理
原始數據經過基礎預處理和特征工程生成文本表示,然后輸入機器學習模型進行分類檢測。基礎預處理一般包含數據清洗、分詞和標準化等步驟,其意義在于減少詞匯量和非重要信息所帶來的干擾。特征工程旨在從原始語料或經過基礎預處理的文本數據中生成計算機能夠理解的數值化數據。
自然語言處理中的文本表示可分為基礎特征表示、靜態詞嵌入和語境詞嵌入,具體如圖3所示。基礎特征表示需人工構建特征以表示文本,通常與傳統機器學習方法搭配使用,也可以作為深度學習的輸入;靜態詞嵌入和語境詞嵌入則一般與深度學習結合使用。
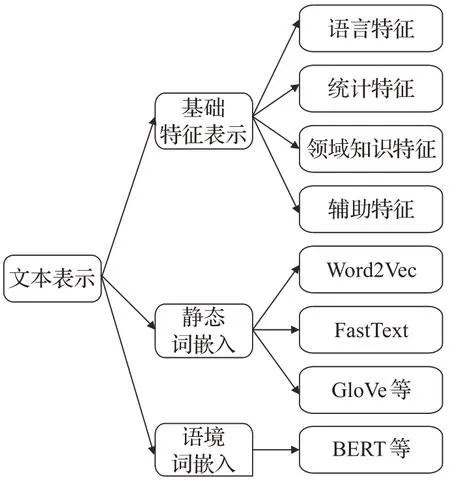
圖3 文本表示分類Fig.3 Classification of text representation
基礎特征表示能夠提取文本中的關鍵信息,甚至能夠考慮到單詞出現的次序,但是不能夠結合上下文語義信息,而上下文語義信息在自然語言理解中至關重要。靜態詞嵌入的方法表達了單詞原本的含義、單詞相似度甚至是上下文關系,通常與深度神經網絡配合使用,在自然語言處理中具有不錯的效果。基于語境的詞嵌入盡可能地學習單詞的上下文語義,其極大規模的數據量、訓練強度和模型容量,以及利用無監督模型的訓練方式,使得它擁有強大的語言表征能力和特征提取能力,在多項自然語言處理任務中表現優異。
3 基于傳統機器學習的抑郁癥檢測
傳統機器學習利用社交媒體文本數據對用戶進行抑郁癥檢測主要分為兩個研究方向:基于不同特征的研究和基于不同機器學習算法的研究。基于不同特征檢測抑郁癥專注于發掘多樣、可靠的特征,其使用的算法通常是諸如支持向量機等經典的單一算法;基于不同機器學習算法的研究則側重于構建更復雜、綜合的算法。
3.1 基于不同基礎特征的檢測
運用傳統機器學習進行抑郁癥檢測前,需要從用戶帖子中人為構建特征。不同基礎特征及其特點如表2所示。其中語言特征能夠顯示抑郁癥患者與心理健康者不同的語言風格,進而揭示兩者不同的心理過程。常用的語言特征是語言探索與字詞計數(linguistic inquiryand word count,LIWC)。LIWC將文本中的單詞與特定詞典進行比對,從而輸出單詞的類別和詞頻。Nguyen等人[20]證明了LIWC在帖子級別預測抑郁癥時顯示出強大的指示力。Fatima等人[21]利用LIWC對抑郁癥帖子和非抑郁癥帖子進行了較好的區分。
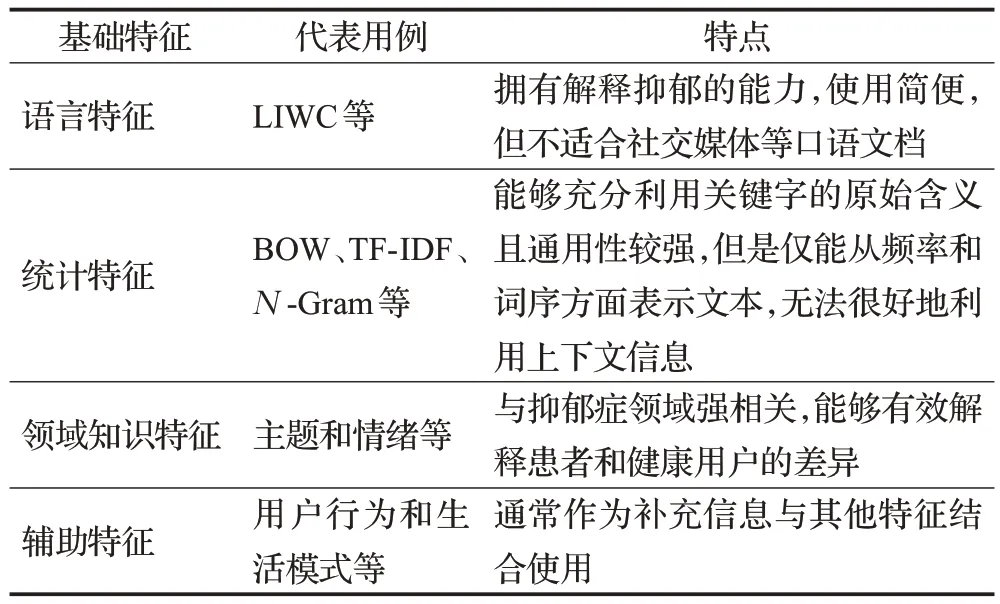
表2 不同基礎特征及其特點Table 2 Various basic features and their characteristics
語言特征提供了解釋抑郁的能力,且僅通過分析單詞語義就能夠使用,但是它更適合于新聞或文章等正式文檔,而非社交媒體帖子等非正式或口語文檔。與基于語言模式的方法相比,基于詞袋(bag of words,BOW)和詞頻逆向文件詞頻(term frequency inverse document frequency,TF-IDF)等統計特征通過統計單詞頻率,從而充分利用關鍵字的原始含義[22]且通用性更強。Prieto 等人[23]使用簡單的詞袋模型,提取N-Gram 特征并應用基于相關性的特征選擇后進行抑郁癥的檢測,實現了較好的分類精度和速度提升。Dos Santos 等人[12]則發現TF-IDF可以從非常小的數據集中做出潛在有用的預測。
對于精神疾病的檢測而言,諸如主題和情緒等領域知識特征顯示出良好的有效性。通常,抑郁癥患者與心理健康用戶所感興趣的主題有所不同,因此可根據談論主題的區別將兩類人群進行有效區分。例如,Nguyen等人[24]發現主題和語言心理特征是高度有效的預測因子,聯合兩種特征在帖子級別檢測抑郁癥,達到了很好的效果。基于情緒的特征則能從更抽象的情緒方面提供信息且更具相關性,同樣可以有效地揭示抑郁癥患者和心理健康用戶之間的差異。例如,Chen等人[25]在LIWC的基礎上加入一組細粒度情感特征,證明了情感特征的有效性。Leiva 等人[26]引入TF-IDF 的同時,還引入了三情感極性特征(積極、中性、消極情緒),證明包含情感分析的方法比僅利用TF-IDF的方法更準確。
除了利用語言、統計和領域知識特征外,不少學者對輔助特征進行了探索。輔助特征例如用戶的行為特征和生活模式特征等,通常作為上述特征的補充,能夠從更為現實和細致的角度將抑郁癥用戶和健康用戶進行對比,并且可利用的信息也更加全面。Hu 等人[27]在語言特征的基礎上加入行為特征,并比較不同時間觀察窗口下模型的分類精度,發現語言和行為特征可以準確識別用戶是否抑郁,而在觀察時間為2 個月時,效果最好。Chen等人[25]組合LIWC和生活模式特征,證明了組合特征的有效性。
整體看來,在基于社交媒體文本數據的抑郁癥檢測中,最原始的單一特征往往缺乏足夠的信息,因而更多的特征被不斷探索和加入。在綜合的特征下,用戶的各種信息能夠得到利用,但是過多的甚至冗余的特征又會使模型運行效率下降。因此在利用傳統機器學習方法進行抑郁癥檢測的領域中,構建何種特征以及如何選擇具有代表性的特征仍然是一個重要問題;此外,如何構建合適的學習算法以和選擇的特征相匹配,從而使模型發揮更好的性能,也是值得考慮的問題。
3.2 基于不同算法類型的檢測
在機器學習中,特征的構建和選擇至關重要,而學習算法的選擇和改進同樣舉足輕重,二者相輔相成。在基于社交媒體文本數據的抑郁癥檢測中,研究者們對于算法的研究旨在匹配多種特征以提高檢測性能,解決標記數據量少和不支持增量學習等現實問題,以及進行抑郁癥的早期檢測等。
綜合的特征能夠較為全面地包含抑郁癥用戶的信息,但是并不是所有的學習算法都能夠與之進行匹配而發揮出良好的效果。為此,許多學者進行了探索。例如,Peng等人[28]基于用戶檔案特征、用戶行為特征和帖子文本特征,提出使用多核支持向量機進行抑郁文本分類。多核支持向量機能夠針對不同特征自適應選擇最優核,因而相比于單一核的支持向量機性能更好。盡管多核支持向量機性能表現良好,但仍存在一些限制,比如不適合更大的數據集,對缺失數據更敏感等。而集成學習能夠克服單一分類器的局限,從而在檢測性能和泛化性上得到提升。例如,Liu等人[29]使用特征選擇方法,將多個單一分類器作為基學習器,并將邏輯回歸作為組合策略來構建堆疊模型。提出的模型既能夠降低數據維度,提高模型效率,又克服了單一模型自身的局限性,提升了模型的泛化性,在抑郁癥患者識別中的準確率高達90.27%。
經典機器學習在社交媒體上識別抑郁癥要么需要足夠的歷史數據,要么不支持增量學習。為解決這些問題,Tariq 等人[30]采用聯合了隨機森林、支持向量機和樸素貝葉斯的半監督聯合訓練模型。提出的模型只需要少量的標記數據便可將大量未標記的數據進行標記,從而節省了大量的人力成本。Burdisso等人[31]提出支持在文本流上進行增量訓練的SS3模型,在抑郁癥早期檢測方面取得了先進的表現。SS3模型雖然表現突出,但是存在的一個缺陷是模型的輸入部分使用詞袋進行處理,因而無法考慮文本詞序等問題。
經典的抑郁癥檢測方法時效性差,原因在于抑郁癥檢測需要患者首先能夠意識到自身的心理問題,其次需要患者克服病恥感去求醫,這一過程往往需要很長時間。通常患者被確診為抑郁癥時,已經到達嚴重的程度甚至存在自殺的傾向。考慮到這些問題,許多學者對抑郁癥的早期檢測進行了研究。Briand 等人[32]認為來自新用戶的帖子若在語義上接近風險用戶的帖子,則新用戶也可能處于患抑郁癥的風險中。為此,構建了信息檢索子系統和監督學習子系統,每個子系統的預測輸出根據一種決策算法進行合并。提出的模型不僅能夠檢測現有用戶的患病情況,而且能夠盡早地對新增用戶進行抑郁癥的檢測。Cacheda等人[10]提出雙例方法進行抑郁癥的早期檢測。雙例方法使用兩個獨立的隨機森林分類器,一個用于檢測抑郁個體,另一個用于識別非抑郁個體,兩個選項(抑郁和非抑郁)獨立預測,從而避免了單例方法中兩選項相互競爭所造成的延遲。結果表明,雙例方法的性能明顯優于單例方法,并且能夠將當前最先進的模型檢測性能提高10%以上。
總體來看,在利用傳統機器學習進行抑郁癥檢測上,特征的構建和選擇已經較為全面和成熟,并且匹配多特征的算法也取得了良好的成果。但是當前研究對于標記數據量少等現實問題的探索較少,這在未來應當加強。此外,已有部分研究者對于抑郁癥的早期檢測進行探究,并且提出了新穎的方法,但是總體上,此類算法所取得的效果仍具有一定的提升空間。
抑郁癥檢測中的傳統機器學習算法總結如表3所示。
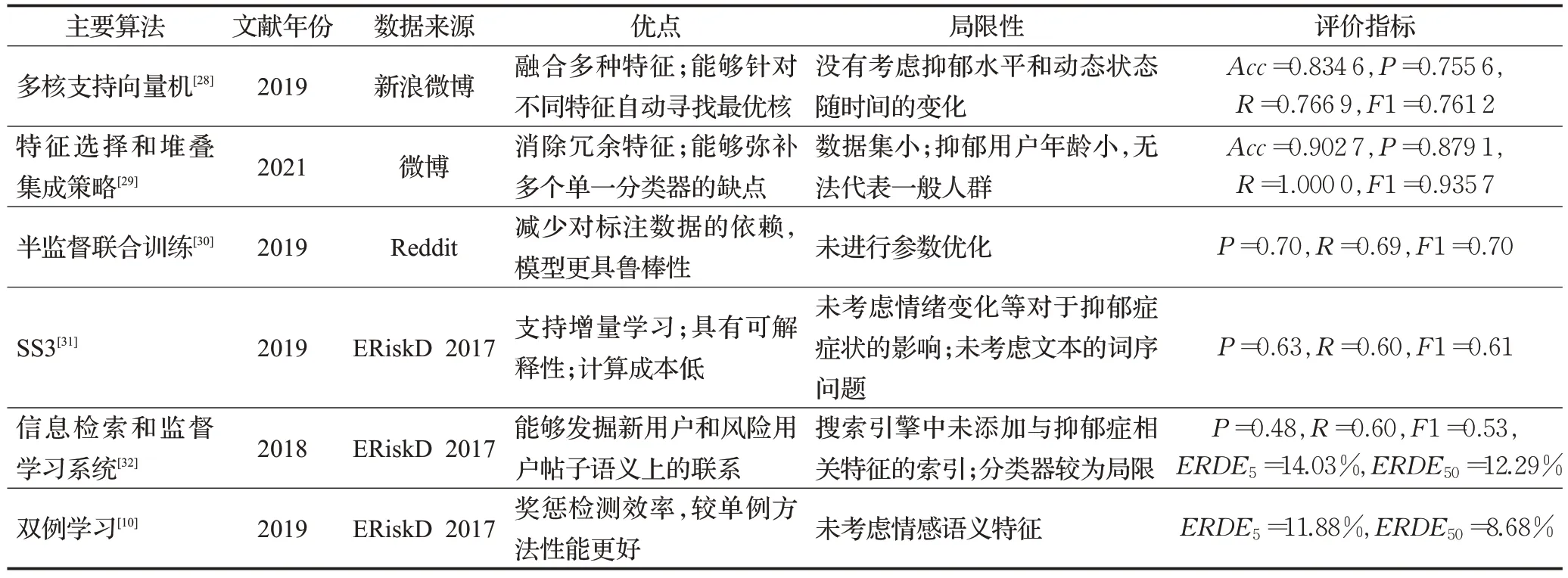
表3 抑郁癥檢測中的傳統機器學習算法總結Table 3 Summary of traditional machine learning algorithms for depression detection
4 基于深度學習的抑郁癥檢測
傳統機器學習需要人工構建大量特征,但是構建有效的特征往往會耗費研究者大量的時間和精力,而深度學習能夠基于原始文本向量自動進行特征提取,并且擁有對事物進行抽象概括的能力。在許多情況尤其是擁有大量數據時,深度學習表現出優秀的性能。在基于社交媒體文本數據的抑郁癥檢測中,常用的深度學習算法有CNN、RNN,加入注意力組件的算法和基于Transformers的BERT等。
4.1 基于CNN的抑郁癥檢測
在基于社交媒體文本數據的抑郁癥檢測中,CNN由于強大的特征抽取能力而被研究和使用。利用CNN進行抑郁癥檢測的基本框架如圖4 所示。文本數據通過詞嵌入技術轉化為數值化數據,形成詞嵌入矩陣;然后利用多個不同大小的卷積核進行卷積操作;最后通過池化層和全連接層后輸出為二分類結果。
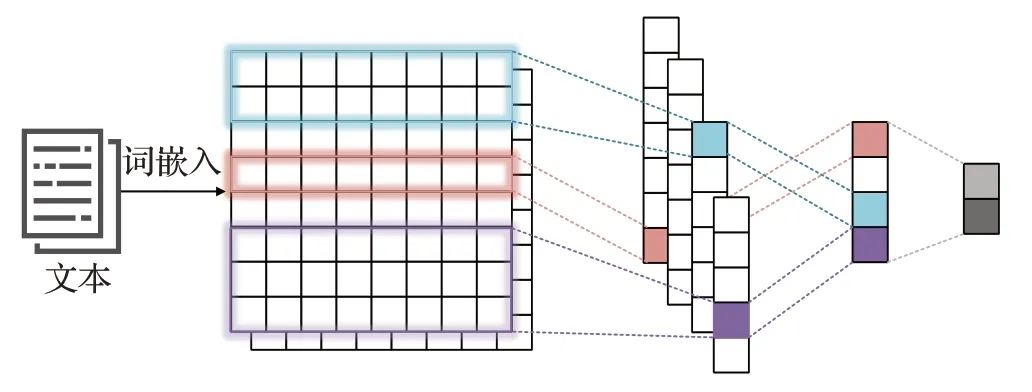
圖4 基于CNN的抑郁癥檢測框架Fig.4 Depression detection framework based on CNN
在應用中,Trotzek等人[33]將基于維基百科的FastText預訓練詞嵌入輸入CNN,同時利用邏輯回歸處理用戶級語言元數據,最后將兩者的輸出進行簡單融合進而分類。結果顯示,構建的模型在抑郁癥的早期檢測中的綜合性能最好。考慮到現實數據大多存在類別不平衡的問題,Kim 等人[34]在CNN 基礎上加入SMOTE(synthetic minority oversampling technique),從而克服了數據的類別不平衡帶來的性能損失。在利用CNN進行特征提取過程中,門控單元能夠突出重要信息和剔除不重要信息,找出問題的關鍵影響因素和減少網絡的參數量,使得模型性能進一步提升。Rao 等人[35]在CNN 中加入門控單元,結合門控單元的CNN 擁有強特征抽取能力的同時可以過濾掉不重要的信息,因而模型能夠選擇性地捕捉用戶帖子中的關鍵情緒信息,具有較強的檢測性能和穩定性。
4.2 基于RNN的抑郁癥檢測
CNN 能夠提取文本中的局部信息,且具有良好的并行計算能力,但是無法捕捉長距離的文本語義信息。相較于CNN,RNN 由于引入了記憶單元而能夠存儲先前文本的信息,在文本數據的處理上具有一定優勢。RNN的基本框架如圖5所示。RNN單元按次序讀取各個單詞的詞嵌入信息,其中hi為隱藏層的輸出單元,包含了上一時間步hi-1的信息。傳統的RNN存在梯度消失(gradient vanishing)問題,為此學者們提出RNN的變體模型LSTM(long short-term memory)和GRU(gated recurrent unit),旨在解決傳統RNN的梯度消失問題。
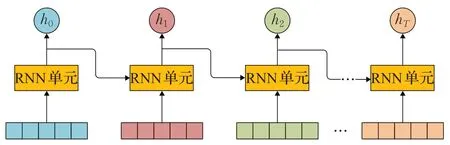
圖5 RNN基本框架Fig.5 Basic framework of RNN
在利用RNN 及其變體LSTM 進行抑郁癥檢測中,Amanat等人[36]構建了RNN-LSTM模型,證明了RNN性能優于CNN。而與LSTM相比,BiLSTM增加了對后文的訓練,充分利用了前后文的語義信息,能夠使序列分類問題的模型性能得以提升。Ahmad 等人[37]提出使用BiLSTM進行抑郁癥檢測,通過對比發現,BiLSTM在各項指標上都優于LSTM,但是未考慮數據類別不平衡問題;Cong 等人[38]構建了X-A-BiLSTM 模型,發現在BiLSTM上使用XGBoost能夠緩解數據不平衡問題。
4.3 基于CNN-RNN和注意力機制的抑郁癥檢測
理論上,CNN-RNN體系結構擁有CNN優秀的特征提取能力和RNN 的序列建模能力,在基于社交媒體文本數據的抑郁癥檢測中,有學者對其進行了探索。Aragón等人[39]將用戶帖子的內容轉化為子情緒序列,通過CNN 提取特征后,使用雙向門控循環單元(BiGRU)捕獲子情緒序列的上下文,最后利用注意力機制提取句子中的重要子情緒。研究發現,提出的模型相較于單一的CNN 和RNN,精度提升了7%和12%。同時,在數據規模較小時,標準CNN 和RNNN 性能不及傳統機器學習方法。Zogan 等人[40]構建由堆疊BiGRU 和CNN 與結合注意力的BiGRU 組合的DepressionNet 框架,其中堆疊BiGRU 用于處理用戶行為特征,CNN 與結合注意力的BiGRU 用于提取用戶帖子的摘要,通過將用戶行為和用戶發帖史進行融合來自動檢測抑郁癥。實驗表明,CNN+BiGRU模型已經達到不錯的精度,而提出的模型相較于CNN+BiGRU 在各項指標中至少提升了2%的性能。
在抑郁癥檢測中,注意力機制能夠對信息進行權重分配,即賦予與抑郁癥相關的重要信息更高的權重,從而使模型學習到用戶帖子中包含的關鍵信息,提升檢測性能。在社交媒體中,許多精神疾病患者傾向于通過隱喻等方式間接表達自己的感受和情緒[41-42]。鑒于此,Zhang等人[43]提出MAM(metaphor-based attention model)模型,試圖通過發掘隱喻中的關鍵信息來更好地檢測抑郁癥。MAM 模型通過RNN_MHCA(recurrent neural network multi-head contextual attention)[44-45]模塊獲得句子隱喻和文本隱喻特征,然后基于隱喻特征計算注意權重。實驗表明,帶有注意力的MAM模型能夠學習到用戶隱性情緒信息,并且證實了隱喻信息在抑郁癥檢測中的有效性。同樣,Almars[46]提出使用注意機制來分析與抑郁癥相關的阿拉伯語文本數據,在BiLSTM的基礎上加入注意力機制,從而使模型學習到抑郁癥的重要隱藏特征。相較于BiLSTM,提出的模型在準確率方面提升了3%。Ren 等人[47]提出包含注意力機制的EAN(emotion-based attention network)模型。實驗中,Ren等人通過模型對比證明了注意力機制能夠有效提升模型性能,并且證實了情感語義信息在抑郁癥檢測中的有效性。
注意力機制不僅能夠提高模型性能,而且能通過可視化其權重分數,分析與抑郁癥強相關的單詞和句子,從而為發掘抑郁癥的重要關聯因素提供線索。Song等人[48]提出的特征注意網絡(feature attention network,FAN)綜合了用戶的抑郁癥狀、情感、反復性思考和寫作風格特征,能夠模擬專家對抑郁癥進行診斷的過程。FAN模型通過分析注意力權重來產生解釋性,并證實了情感信息在抑郁癥檢測中的重要作用,但是模型的總體性能并不算杰出。Uban等人[49]結合情感等信息,將層次注意網絡(hierarchical attention networks,HAN)用于抑郁癥的檢測,最后通過分析網絡層中數據的抽象表示等方法充分解釋了模型預測。但是HAN模型更多地是對文本語言相關信息的考慮,而忽略了對用戶行為、時間等特征的建模。Zogan 等人[50]提出基于HAN 的混合模型MDHAN(multi-aspect depression detection hierarchical attention network)。該模型結合文本、行為、時間和語義方面的特征,提高了預測性能,并通過分析注意力權重解釋了模型預測方法,但是該模型尚缺乏對于情感的分析。
4.4 基于BERT的抑郁癥檢測
Transformer模型利用了自注意力編碼器,能夠自主發掘同一句子中各單詞之間的相關性,從而獲得更深層次的編碼信息。此外,Transformer完全拋棄了類似循環神經網絡結構的使用,使得運算速度和對于長句的處理能力大幅提升,而基于兩層雙向Transformers 的BERT預訓練語言模型,更是具有強大的對語義信息建模的能力,其網絡結構如圖6 所示。BERT 需將句子前后分別加入標識符作為分隔,然后將單詞的位置信息、段落信息和單詞嵌入作為兩層Transformer 編碼器的輸入。BERT 既可以作為一種詞嵌入技術,也可在其后直接加上一個簡單的分類器作為分類模型。
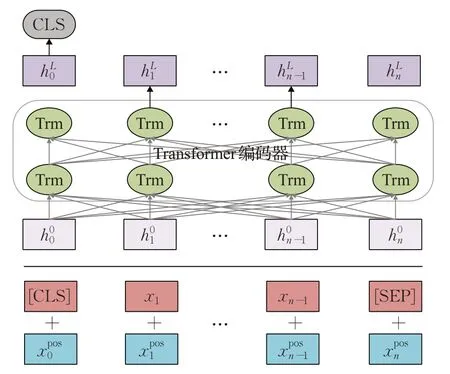
圖6 BERT模型結構Fig.6 Structure of BERT model
在抑郁癥檢測領域,Yadav 等人[51]率先提出一種新的基于BERT 的多任務學習框架FiLaMTL(figurative language enabled multi-task learning framework)。該框架能夠通過檢測比喻用法的輔助任務來準確識別抑郁癥狀。研究結果顯示,BERT具有強特征提取能力,但是在通用語料上訓練的BERT 不能夠很好地適應特定領域。同時,實驗結果也充分證明了引入比喻用法檢測對抑郁癥狀識別的有效性。相比通用的預訓練模型,領域內預訓練能夠學習到特定領域中數據的分布,往往在特定領域中表現更佳。Wang 等人[52]運用BERT 在抑郁癥數據集進行領域內預訓練(in-domain pretraining,IDP),發現在抑郁癥檢測和抑郁程度分類任務中,領域內預訓練的BERT在所有提出的基于Transformers的模型中取得最佳性能。為解決經典BERT 模型因體量巨大而難以在實際應用中部署等問題,Zeberga 等人[53]提出了一個新的框架,該框架應用將知識從大型預訓練網絡(BERT)轉移到小型網絡(Distiled_BERT)的知識蒸餾技術。相較于BERT,Distiled_BERT不僅進一步提升了檢測性能,而且模型的體量相對較小。在對結構進行了改進的BERT 的應用中,Khan 等人[54]采用DeBERTa(decoding-enhanced BERT with disentangled attention)模型進行抑郁癥與其他疾病的區分。DeBERTa 的改進之處在于引入了解耦注意力機制和增強型掩碼解碼器,因而能夠同時考慮詞匯的內容、相對位置與絕對位置信息,即充分地學習了單詞的內容及其依賴關系,在與多個先進模型的對比中,該模型在區分抑郁癥與其他疾病方面表現最佳。
綜上,在利用深度學習模型進行抑郁癥檢測的研究中,研究者們從平衡數據類別、特征提取方法和結合多維度特征等角度進行了探索并取得了較好效果。總體看來,相較于傳統機器學習,深度學習由于能夠自動提取特征而具有更強的穩定性和泛化性,且能夠達到更杰出的檢測性能。但是深度學習模型的參數量相對較大,且往往需要大規模數據的支撐,在小數據集上深度學習的性能可能不及傳統機器學習。在深度學習方法上,需要關注的是注意力機制和BERT 預訓練模型。注意力機制能夠提升模型性能,并且能夠為模型預測提供一定的解釋性,具有在臨床進行應用的潛力。BERT 類模型雖然具有強特征提取能力,能夠提取文本中表示抑郁的關鍵信息,從而達到可觀的性能。但是其結構較為復雜,模型參數量巨大,不利于進行重新訓練。而使用通用的預訓練BERT模型又勢必會造成性能上的損失,尤其是在抑郁癥這類具有醫學特點的領域。
抑郁癥檢測中的深度學習算法總結如表4所示。
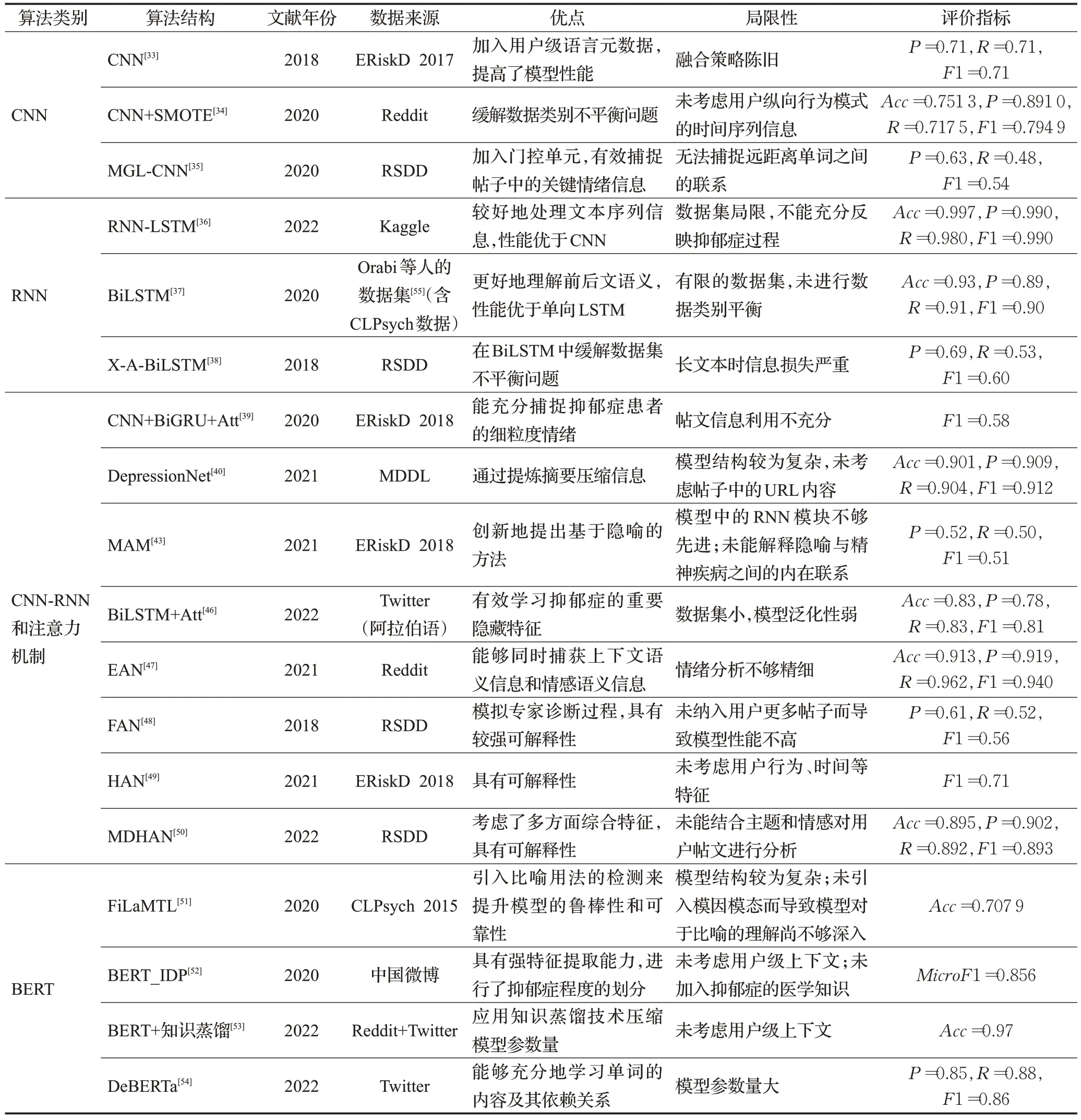
表4 抑郁癥檢測中的深度學習算法總結Table 4 Summary of deep learning algorithms for depression detection
5 總結與展望
社交媒體日益成為人們情感表達的平臺,抑郁癥等心理疾病也逐漸成為人們關注的焦點,從社交媒體用戶發布的文本信息中尋找抑郁癥的線索,已被諸多學者探索和研究。本文基于上述文獻總結當前研究的不足并大膽地對未來研究方向進行展望。
5.1 現有研究所面臨的問題
(1)缺乏中文數據集。數據是進行科學研究的基礎,而當前國內尚缺乏大型公開公認的社交媒體中文抑郁癥數據集,這在一定程度上限制了國內抑郁癥領域的研究和發展。
(2)模型對于抑郁癥的解釋不夠深入。雖然當前已有許多研究者致力于研究模型的解釋性,但其是以分析注意力權重為主。此類分析僅能夠展示與抑郁癥強相關的單詞和句子,而不能揭示抑郁癥的發病機理以及模型的推理過程。
(3)缺乏基于隱喻的抑郁癥檢測研究。患有抑郁癥等精神疾病的人群在隱喻的用詞上與普通人群有所差異,當前也有少數研究證實了發掘隱喻等表達在區分抑郁癥患者和普通人群中的有效性。總體來看,目前基于隱喻的檢測是一種較新的思路和方法,擁有較大的研究空間。
(4)BERT 模型訓練成本高。當前的BERT 模型普遍存在著參數量巨大、對數據量要求高和耗費資源大等問題,這些缺陷使得研究者只能在公開的、已訓練完成的模型上進行微調,而沒有充足的資源進行從頭訓練,從而難以對模型本身做出改進和提出適用于抑郁癥領域的高精度模型。
5.2 未來研究展望
(1)中文數據集的創建可以借鑒國外數據集構建的思路,即可以通過在微博等社交媒體平臺結合自動篩選用戶自我診斷的陳述和人工審查的方式創建中文數據集。此外,在數據集樣本標注較少的情況下,構建弱監督學習方法進行抑郁癥檢測將是重要的研究方向。
(2)當前構建的模型多以數據為驅動,這樣的模型難以去深入發掘內部的運行過程,而如果將模型嵌入抑郁癥知識,讓模型去學習人類進行知識推理的過程,或許能夠清晰地解釋模型及其運行結果。因此,將抑郁癥知識,例如以知識圖譜的形式與深度學習方法進行結合,從而構建具有解釋性的抑郁癥檢測模型,是非常具有現實意義的方向。
(3)目前基于隱喻的抑郁癥檢測尚處于起步階段,隱喻特征與抑郁癥等精神疾病的內在聯系還有待進一步論證和研究,并且如何構建模型以發掘隱喻特征也應當予以大量研究。
(4)BERT模型具有強特征提取能力,但是因其訓練成本過高而限制了在領域中的應用。因此,在保證精度的前提下,探索更精簡、效率更高的BERT 模型或者其他預訓練模型,是未來應繼續重點關注的話題。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
創業家(2015年5期)2015-02-27 07:53:25
