基于PaddlePaddle和VGG的戴口罩人臉識別方法設計
2023-02-23 04:55:16仝星王濤田青宛根訓張瑤崔璐公安部第一研究所
警察技術 2023年1期
仝星 王濤 田青 宛根訓 張瑤 崔璐 公安部第一研究所
引言
后疫情時代的到來,使得佩戴口罩出行成為人們生活中的常態。佩戴口罩在保護大眾生命安全防線的同時,也給人臉識別算法帶來了新的挑戰。佩戴口罩會嚴重影響識別精度,但取下口罩進行人臉識別會增加感染新冠肺炎的概率。通過Python來實現生物特征識別是人臉識別較常見的模式,但是關于口罩遮擋面部這種情況的人臉識別還是相對較少。針對這一問題,本文提出一種基于VGG的模型并通過 PaddlePaddle應用平臺實現人臉識別,提升了在佩戴口罩場景下的人臉識別精度,同時有效保證人們在疫情期間出入公共場所的安全,對疫情防控具有十分重要的意義。
一、神經網絡
(一)VGG模型
VGG模型是由牛津大學VGG(Visual Geometry Group)組在2014年ILSVRC提出的。該模型相比以往模型進一步加寬和加深了網絡結構,它的核心是五組卷積操作,每兩組之間做Max-Pooling空間降維。同一組內采用多次連續的3×3卷積,卷積核的數目由較淺組的64增多到最深組的512,同一組內的卷積核數目是一樣的。卷積之后接兩層全連接層,之后是分類層。由于每組內卷積層的不同,有11、13、16、19層這幾種模型。VGG模型結構相對簡潔,提出之后也有很多文章基于此模型進行研究,如在ImageNet上首次公開超過人眼識別的模型就是借鑒VGG模型的結構。
VGG模型相較傳統模型,是調用多個小尺寸(2×2或3×3)的卷積層的堆疊替換原有的大卷積核(5×5或7×7),此方案使得模型比較容易形成較深的網絡結構,比單個卷積層擁有更強的非線性映射能力,在同等參數或參數量更少的情況下,可以對圖像的特性有著更深的學習度,做更復雜的分類任務。VGG模型結構如圖1所示。

(二)訓練過程
模型的訓練過程實際就是輸入圖像經過網絡結構到獲取結果的過程,在實際工程中,可以通過不同方案對目標網絡進行訓練,模型會逐漸掌握輸入和輸出間的映射關系。本方案中主要利用反向傳播算法。
反向傳播算法通過鏈式法則從輸出層一直向前一層遞歸計算,是更新網絡結構參數的核心。方案需要優先獲得實際結果和預期結果的差值,隨后將差值從后向前一層一層傳遞,經過調整各層的權重值來逐漸減小誤差。
假設用δ表示誤差,δJ(l)表示第l層的第j個節點激勵值的誤差,δ(l)表 示第l層激勵值的誤差矩陣,xj(l)表示第l層第j個節點的激勵值,x(l)表示第l層的激勵矩陣,共有L層,即l=1,2,3,...L,y代表輸出標簽矩陣,公式如(1)所示。

由于第一層是輸入層,無誤差,可根據誤差表達式計算函數的偏導數。定義表示λ≠0情況下第l層第i行第j列的權重誤差,公式如(2)所示。
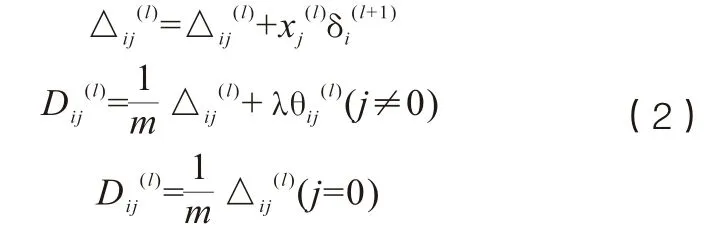
公式(2)所示是一次反向傳播時對權重值進行更新的過程,在訓練過程中會重復這個過程,直至模型收斂或者達到預設的訓練步數。
(三)模型優化
在模型訓練過程中,由于模型復雜度過高或訓練數據集的樣本不充足,會導致過擬合現象的發生,最終使模型的泛化能力大幅降低。如圖2所示,當模型復雜度超過一定范圍的時候,訓練集的準確率雖然不斷提高,但是測試集的準確率卻在降低,此時出現了過擬合現象。

當神經網絡出現過擬合時,通常的做法有模型正則化、降低模型復雜度、增加樣本數量、Dropout等。本方案利用了模型正則化與Dropout方法對模型進行了優化。
1. 模型正則化
模型正則化有L1正則化和L2正則化。
L1正則化會生成稀疏權值矩陣,即生成一個稀疏模型,可用于特征選擇;L1正則化是在原來代價函數的后面加一個L1正則化項,如公式(3)所示,其中c0是原始代價函數,后面一項是L1正則項。

L2正則化具有防止模型過擬合的能力,L2正則化是在原來代價函數的后面加上一個L2正則化項,如公式(4)所示,其中c0是原始代價函數,后面一項是L2正則項。

在神經網絡中,正則化傾向于更小的權重值。在權重值較小的情況下,數據的隨機變化不會對神經網絡模型造成太大的影響,不會對噪聲過于敏感。

2. Dropout
Dropout是通過隨機斷開神經網絡之間的連接,從而改變神經網絡的結構來防止過擬合出現的方法。如圖3所示,訓練開始時,神經網絡會隨機剔除中間層一半的神經元(假如Dropout的概率為0.5),圖中虛線部分是被剔除神經元。隨后在剩下的神經元上完成正向和反向傳播,最終更新權值參數。這個過程完成后,神經網絡恢復原來的結構,再次剔除中間層一半的神經元,繼續進行權值的更新,一直重復上述過程。
Dropout通過不斷隨機刪除隱藏層的神經元,來達到減少神經元之間依賴,增加局部數據簇差異性,使神經網絡能夠學習到更加健壯的特性的同時,提升算法魯棒性能。

二、實驗設計
(一)數據集
實驗數據集包括4128張人臉圖像。其中未佩戴口罩的圖片數量為2188張,佩戴口罩的圖片數量為1940張。這些人臉圖像來自于不同場景,如火車站、證件照、手機自拍照等,在光照、角度、遮擋上有明顯區別。
部分數據通過人臉關鍵點檢測方法,在現有人臉數據集上對人臉模擬實現口罩遮擋,本文制作了3種類型的口罩遮擋案例,包括鼻子及以下遮擋、嘴巴及以下遮擋、下巴及以下遮擋,每個類型的口罩遮擋又有各種佩戴狀態,使模型有更好的泛化能力。
(二)搭建實驗環境
PaddlePaddle(Parallel Distributed Deep Learning)是百度公司推出的開源、分布式的深度學習使用平臺,其架構是基于神經網絡開發的。它將數據讀取、功能層、優化方式、訓練等操作過程分別構建成類,組合構成整個網絡。PaddlePaddle簡化了構造神經網絡過程,能夠提供更簡便的使用方式,用戶不需要更改主體文件。PaddlePaddle設計和定位是“易用、高效、靈活、可擴展”,分布式部署也是它的優點。相比偏底層的谷歌TensorFlow,PaddlePaddle具有更易用的API、更好的封裝、更快速的業務集成,讓開發者開發精力放在構建深度學習模型的高層部分。同時,在自然語言處理上有很多現成的應用,比如情感分類、神經機器翻譯、閱讀理解等,使用起來相對簡單。此外PaddlePaddle支持多機多卡訓練,并且本身支持多種集群方式。
本方案搭建的是PaddlePaddle-GPU環境。首先進行顯卡驅動的安裝,之后下載并安裝CUDA,本方案選用的版本是CUDA10.0,此外還需將CUDA路徑添加到系統環境變量中。接下來用pip工具安裝cuDNN和PaddlePaddle-GPU。
(三)定義網絡結構與訓練
訓練前首先配置好運行環境,導入工程需要加載的基礎庫、第三方庫和深度學習框架。隨后需要將數據集做預處理操作,包括解壓用于識別的圖像數據,獲取所有數據圖片的地址并將其保存到指定位置,之后創建數據集讀取器,通過數據集讀取器讀取訓練或測試需要的圖片數據。
在平臺內定義VGG模型,堆疊卷積池。輸入準備好的自制數據集,通過數據顯示訓練集準確率(acc)和訓練集損失率(loss)加載出訓練出來的模型,把要預測的數據放到訓練模型里進行預測,最終輸出預測的結果。在實際調參過程中,本方法采用了交叉驗證的方式來尋找算法的最優值。交叉驗證用于防止模型過于復雜而引起的過擬合,是一種統計學上將數據樣本切割成較小子集的實用方法。先在一個子集上做分析,而其它子集則用來做后續對此分析的確認及驗證。一開始的子集被稱為訓練集,而其它的子集則被稱為驗證集或測試集。交叉驗證法在很大程度上保證了模型的穩定和可靠性,提高了模型的泛化能力。
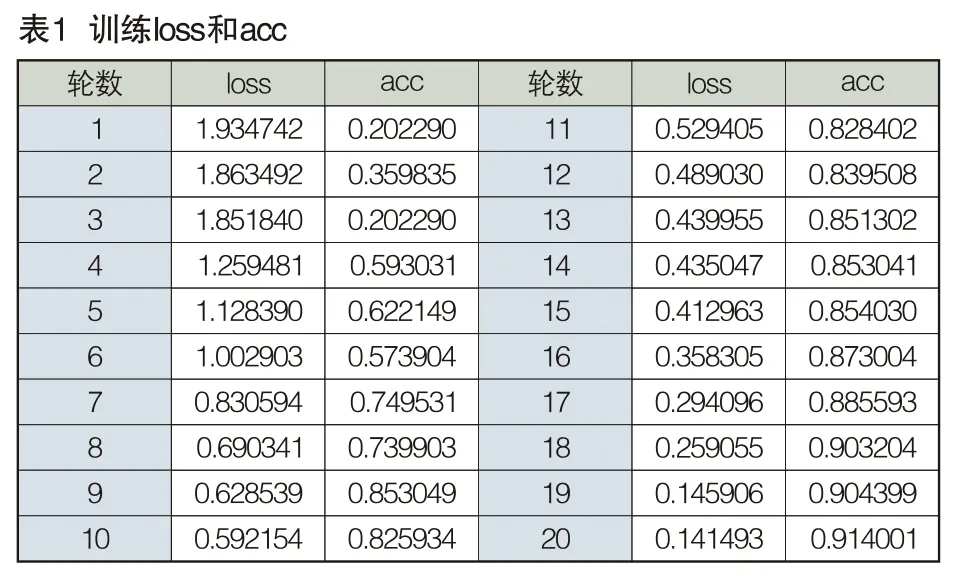
通過對數據集進行20輪訓練并將每一輪訓練的acc和loss列出來,最終與測試集進行比對優化,得到訓練模型。
?
由表1數據可知acc會隨著訓練的輪數增加而增加,最終達到91.4%;損失值隨著訓練的輪數增加而降低,最終達到14%。acc和loss數值均達到期望。
三、結語
本方法通過PaddlePaddle深度學習平臺,設計并實現了一種基于VGG的口罩人臉識別方法。通過測試,方法對佩戴口罩和未佩戴口罩的樣本都在模型中成功預測,識別精度達到91.4%,可以在被識別人佩戴口罩的場景下有效提升識別準確率。
在疫情防控形勢嚴峻復雜的當前,本方法可用于車站、地鐵、機場等人員密度大、防疫任務重的重點防控區域,可以在佩戴口罩與無口罩并存的復雜場景下完成精準識別,為公安部門疫情防控中基于人臉識別的無接觸管控有效賦能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2017年17期)2017-12-18 06:40:55
電子制作(2017年1期)2017-05-17 03:54:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
計算機工程(2015年8期)2015-07-03 12:19:07
