基于改進SSD 的航拍飛機目標檢測方法
2023-02-22 23:41:36喻佳成張靈靈
液晶與顯示 2023年1期
李 靜,喻佳成,張靈靈
(1.西安工業大學 電子信息工程學院,陜西 西安 710021;2.西安工業大學 兵器科學與技術學院,陜西 西安 710021)
1 引言
近年來,隨著無人機技術與目標檢測技術的快速發展,通過結合兩者來獲取空間數據已經成為當下的主流趨勢。尤其是在軍用領域,因無人機具有機動性強、隱蔽性好、成本低的優點,使用無人機來獲取軍事場所的目標信息已經成為重點研究對象[1-3]。隨著計算機算力的提高和卷積神經網絡強大的特征提取能力被發掘,很多研究人員將其應用于目標檢測[4-6]、目標跟蹤[7-8]等領域,以深度學習為基礎的目標檢測技術已逐步應用在航拍圖像的目標檢測任務當中[9-11]。
目前,通過深度學習來提取特征并完成檢測任務的方法主要有兩類:兩階段和單階段目標檢測算法。兩階段目標檢測算法采用先確定待檢區然后確定目標位置信息與類別的思想,典型代表有R-CNN[12]、Faster R-CNN[13]等。以YOLO[14-16]、SSD[17]算法為代表的單階段目標檢測算法則不去單獨地確定待檢區,而是直接確定待檢目標的位置信息與類別信息。YOLO 算法將待檢測圖像劃分為多個網格,使用每個網格來檢測一個目標,這樣雖然能夠快速地完成檢測,但是對于航拍圖像中的小目標檢測效果不佳。SSD 算法將金字塔特征層級的思想應用在目標檢測問題中,使用不同尺寸的特征圖檢測不同大小的目標,對于小目標的檢測效果有所提高,因此許多學者以SSD 算法為基礎對其改進來完成航拍圖像中的目標檢測任務。Jisoo Jeng[18]等人提出的R-SSD 算法使用特征金字塔(Feature Pyramid Networks,FPN)[19]的方法將深層網絡提取的特征圖與淺層網絡提取的特征圖進行融合構成了語義、細節信息豐富的特征圖用于檢測,提高了小目標的檢測精度,但是大量的融合操作導致模型參數變大,檢測速率下降。Fu 等人[20]提出的DSSD 算法通過反卷積以及跳躍連接的方式來融合深層網絡與淺層網絡,豐富了淺層網絡的語義信息,對航拍圖像中的目標檢測效果較好,但是模型參數過大,檢測速度較慢。Chen 等人[21]提出的改進多尺度特征融合SSD 算法跳躍式地將兩層深層網絡特征圖與淺層網絡特征圖融合,很好地解決了航拍圖像中小目標檢測效果不好的問題,但是融合機制過于復雜,導致網絡結構大,檢測速度大幅下降。
針對現有算法對航拍圖像中的小目標檢測效果不佳、實時性不足等問題,基于SSD 算法進行改進,引入一種特征融合機制通過逐層地將深層特征圖與淺層特征圖進行融合,構成具有豐富語義、細節信息的特征圖用于檢測,并在網絡特征圖輸出處引入混合注意力機制,在不會過多增加計算量的基礎上使網絡優先將注意力放在有用信息上并抑制復雜背景等無用信息,最后優化默認框參數,進一步提升小目標檢測精度。
2 SSD 算法基本原理
SSD 模型是典型的單階段檢測算法,將預測問題轉換成列回歸問題,在保證檢測精度的同時提高了檢測速度。采用金字塔特征層級的思想,即在不同尺度的特征層上預測不同大小的物體,使用具有較高分辨率的淺層特征圖來預測小物體,分辨率較低的深層特征圖來預測較大的物體,相對提高了對小目標的檢測精度。SSD 模型由骨干網絡和額外卷積層兩部分組成,具體模型框架如圖1 所示。

圖1 SSD 模型結構Fig.1 Structure of SSD model
SSD 模型以VGG16 作為主干網絡,貫穿至VGG16 的Conv5_3 層并將max_pooling5 的步距由2 調整至1。額外卷積層由Conv6~Conv11 組成,并逐層將特征圖的尺寸縮小構成金字塔層級,提取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv10_2 作為預測特征圖來檢測不同大小的目標。SSD 模型在提取到的預測特征圖上會生成數量不同的預測框,對于每個預測特征圖都會有n×n個中心點并且每個中心點都會生成m個預測框。Conv4_3~Conv11_2 層n和m的取值分別為38,19,10,5,3,1 和4,6,6,6,4,4。最后,通過非極大值抑制算法和設置的置信度閾值消去位置、類別不符合的預測框,輸出檢測結果。
3 改進的SSD 算法
3.1 改進SSD 算法框架
SSD 模型使用金字塔特征層級的思想,用不同尺度的特征層來檢測不同大小的目標。其中淺層特征圖負責檢測小目標,而在航拍圖像中小目標檢測效果不好的原因主要有兩點,分別是淺層特征圖沒有具備足夠的紋理、位置等細節信息和語義信息匱乏。針對這兩點原因,本文設計了一種特征融合機制,首先就淺層特征圖的細節信息不夠豐富和缺乏語義信息的問題,引入細節信息補充特征層(Details complement feature layer,DCFL)和自深向淺逐層融合的語義信息補充特征層(Semantic complements feature layer,SCFL)來增加Conv4_3 層的細節和紋理信息。然后引入混合注意力機制(Botteleneck-Attention-Module,BAM)來增強特征層對關鍵信息的提取能力。最后針對遙感圖像數據集尺度偏小,對默認框的尺度和數量進行優化。網絡結構如圖2 所示,FFM(Feature Fusion Module)為特征融合機制中的特征融合模塊。
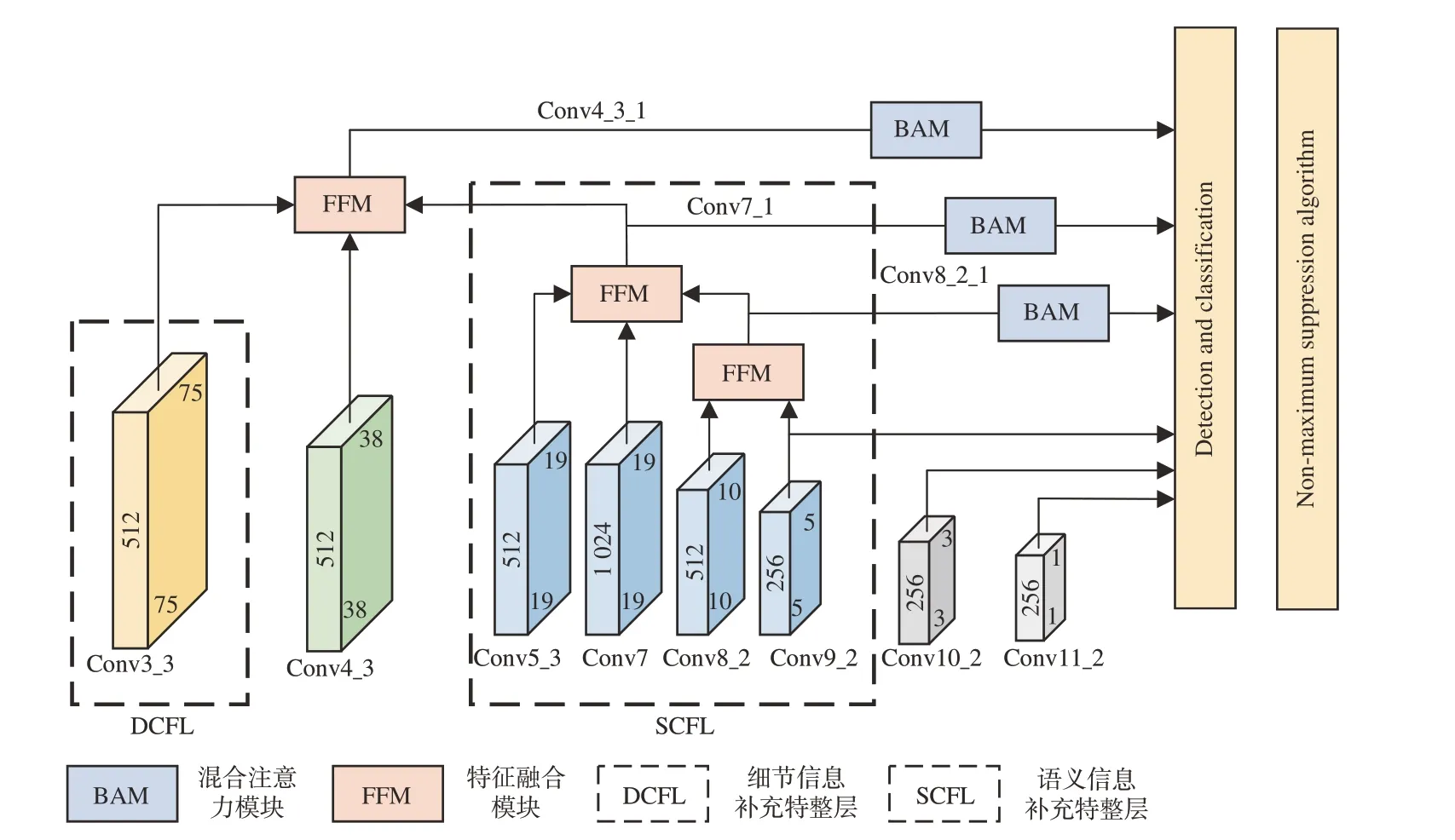
圖2 改進SSD 模型結構Fig.2 Structure of improved SSD model
3.2 特征融合機制
在SSD 框架中,對小目標的檢測主要由淺層網絡中Conv4_3 層輸出的特征圖完成。但因為細節信息不夠豐富以及語義信息匱乏兩點原因,導致對航拍圖像中的小目標檢測效果不佳。因此引入細節信息補充層和語義信息補充層與Conv4_3 層經過特征融合模塊(FFM)輸出新的Conv4_3_1 層的特征圖,用來對小目標進行檢測。
對于細節信息補充特征層(DCFL),應當選取尺寸大、感受野小、細節信息豐富的Conv3_3層。而語義信息補充層(SCFL)是由深層特征圖通過遞歸反向路徑逐層融合而來。在以往的特征融合過程中,直接將深層的特征圖與淺層特征圖進行融合來增加淺層特征圖中的語義信息,這樣忽略了層與層之間的連接關系,導致丟失過多的關鍵信息。具體的融合過程如式(1)~(3)所示:
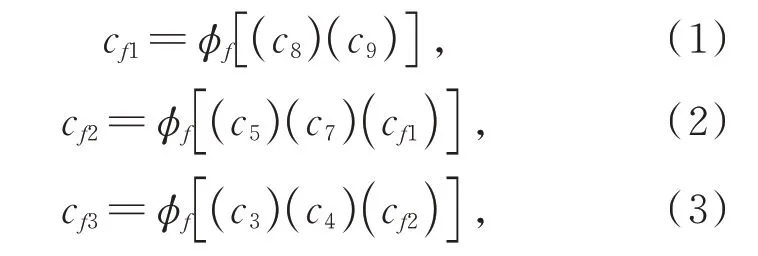
式中:cfi(i=1,2,3)為融合后的特征層,ci(i=3,4,5,7,8,9)為融合層,?f為特征融合模塊。首先選取Conv8_2 和Conv9_2 層作為遞歸反向路徑的起始層。不選取Conv10_2 和Conv11_2 的原因是這兩個特征層尺寸過小,所包含信息太少,融合之后對目標定位與分類精度并沒有提升,反而使模型的訓練與檢測速度變慢。將Conv8_2 和Conv9_2經過特征融合模塊后的輸出結果Conv8_2_1 再與兩個相鄰的特征層Conv7 和Conv5_3 送入特征融合模塊得到最終的語義信息補充特征層。特征融合模塊將本文特征融合機制中選取的特征層進行融合,首先對Conv3_3、Conv4_2 和Conv7_1這3 個特征層進行融合,如圖3 所示,其具體步驟如下:
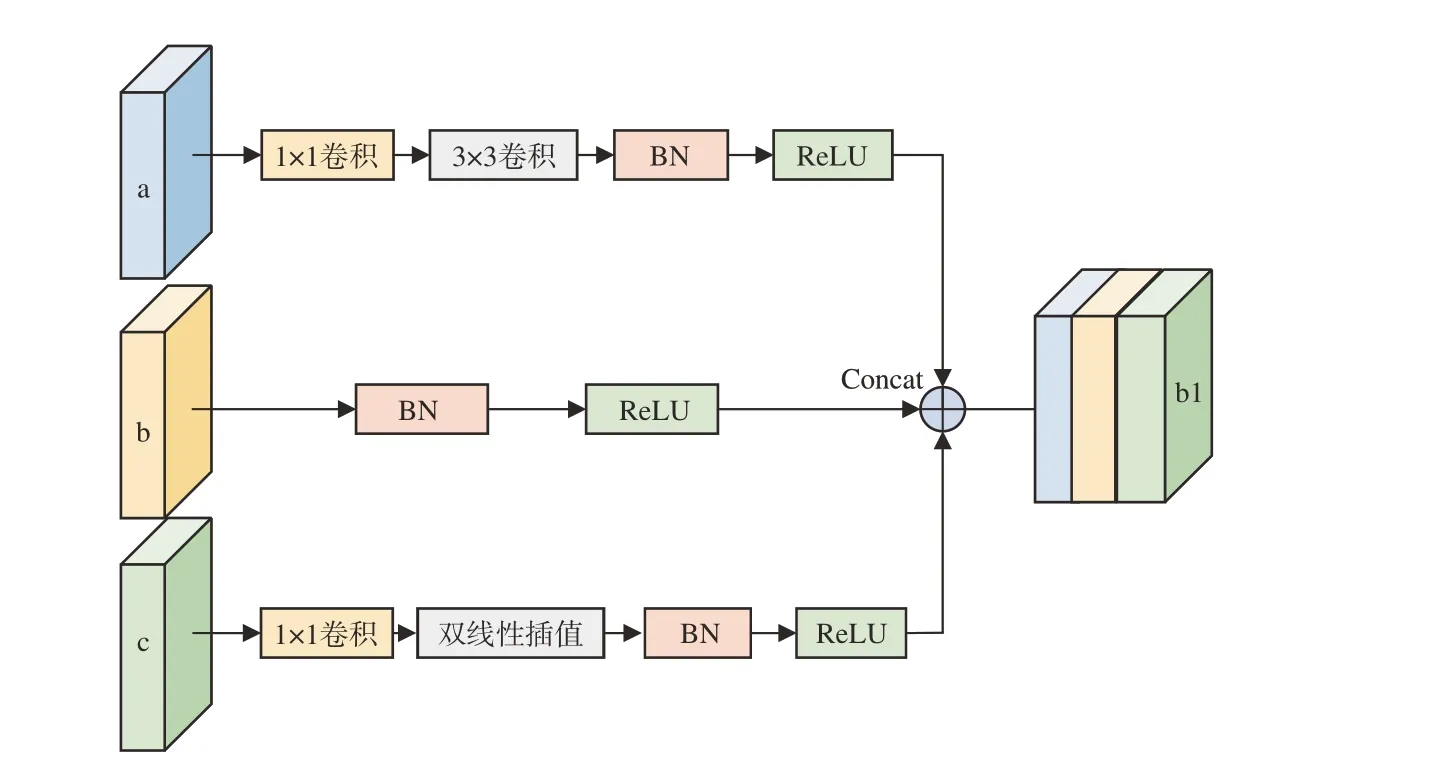
圖3 特征融合過程示意圖Fig.3 Schematic diagram of the FFM process
使用1×1卷積核對Conv3_1和Conv7_1兩個特征層進行通道降維處理,變為原來通道數的1/4,Conv4_3 變為原來通道數的1/2。然后使用雙線性插值對Conv7_1 進行上采樣處理,使其尺度擴大一倍,與Conv4_3 的尺度保持一致。使用3×3 卷積核對Conv3_3 進行下采樣處理,使其尺度縮小一倍,與Conv4_3 保持一致。然后將進行過上、下采樣處理后的Conv7_1 和Conv3_1 以及Conv4_3經過批歸一化(BN)層和ReLU 激活函數,最后采用concat融合方式讓網絡去學習融合特征,避免造成信息的損失。融合輸出為Conv4_3_1。對于Conv7_1 的融合過程與Conv4_3_1 的融合過程類似。對于Conv8_2 和Conv9_2 兩個特征層進行融合,沒有了需要下采樣的特征層,將Conv8_2和Conv9_2 使用1×1 卷積核,將Conv8_2 通道數降維處理變為原來的1/2,Conv9_2 通道數不變,然后將Conv9_2 進行雙線性插值使其尺度變為原尺度的1 倍,與Conv8_2 一致。經過批歸一化(BN)層和ReLU 激活函數,最后采用Concat 融合得到融合特征層Conv8_2_1。
為了驗證經過特征融合后的Conv4_3_1 層具有更豐富的細節信息與語義信息,將其特征圖輸出并與原網絡的Conv4_3 層的特征圖進行對比,如圖4 所示。通過原網絡的Conv4_3 層輸出與融合后的Conv4_3_1 輸出對比可以看出,在飛機目標處原網絡僅提取到很少的特征,而融合后飛機目標部分的輪廓、細節信息顯示更為明顯,顯然具備更多特征。理論上,融合后的特征層可以預測到更多的目標,精度也會有所提升。

圖4 融合前后的特征圖對比Fig.4 Feature map comparison before and after fusion
3.3 混合注意力機制
在特征融合機制中,為了獲得更多的細節、語義信息,將多個特征層的特征通道進行了疊加,但是并沒有反映不同通道之間的重要性和相關性以及沒有考慮特征圖的空間層面上的重要性,因此引入了一種混合空間與通道的注意力機制(Botteleneck-Attention-Module,BAM)[22]。BAM 在通道注意力機制SE-Net(Squeeze-and-Excitation Networks,SE-Net)[23]的基礎上添加了空間壓縮生成的空間注意力向量與SE-Net 生成的通道注意力向量進行疊加,得到既有空間注意力又有通道注意力的向量,其具體網絡模型的結構圖如圖5 所示。
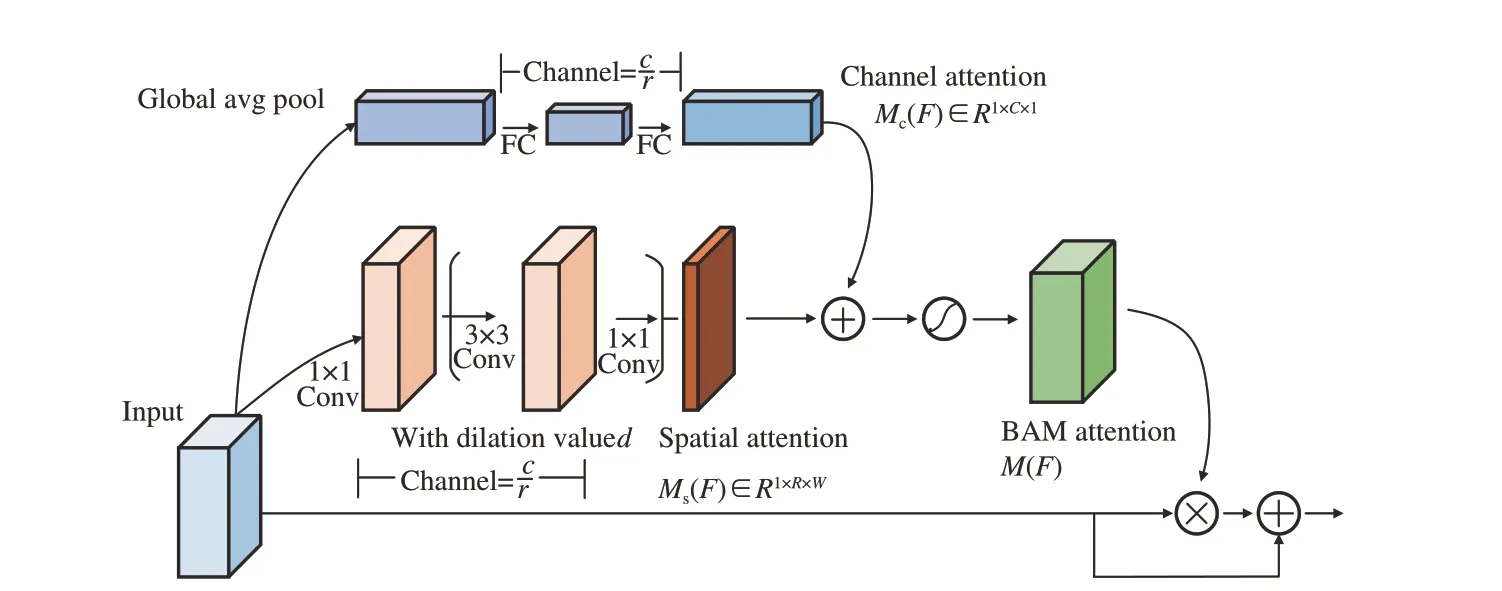
圖5 BAM 示意圖Fig.5 Schematic diagram of the bottleneck attention module
對于構建空間注意力向量,首先將輸入的特征圖使用1×1 卷積核進行通道壓縮,其次使用兩個3×3 卷積核來增大感受野,然后再次使用一個1×1 卷積核將通道數變為1,最后經過歸一化操作調整空間分支的輸出尺度構成空間注意力向量。對于構建通道注意力向量,首先將輸入的特征圖使用全局平均池化將輸入圖像的寬、高壓縮為1×1,然后利用多層感知機制學習每個通道的估計,最后經過歸一化操作得到通道注意力向量。將得到的空間注意力向量與通道注意力向量疊加并且經過Sigmoid 函數得到最終的混合注意力向量,整體過程如式(4)~(6)所示:
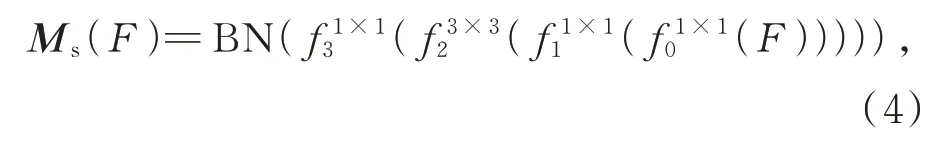

式中F為輸入的特征圖為不同大小的卷積核,Ms(F)為歸一化操作,Ms(F)為空間注意力向量,Avgpool 為全局平均池化,MLP 為多層感知機制,Mc(F)為通道注意力向量,M(F)為混合注意力向量,σ為Sigmoid 函數,BN 為批歸一化層。
使用Grad-CAM[24]技術來直觀地展示模型中引入混合注意力模塊的有效性。熱力圖顏色區域越深說明該區域對類別識別的影響越大。如圖6 所示,在添加通道注意力機制后,模型開始關注右側的目標。在加入混合注意力機制后,模型對右側目標的關注度是優于通道注意力機制的。

圖6 熱力圖可視化Fig.6 Visualization of heat maps
3.4 先驗框參數優化
SSD 模型用不同尺度的特征圖來檢測不同大小的目標,因此不同的特征層會產生不同大小的先驗框并且先驗框的大小符合線性遞增的原則:隨著特征層尺度的減小,先驗框的尺寸增大,具體如式(7)~(9)所示:
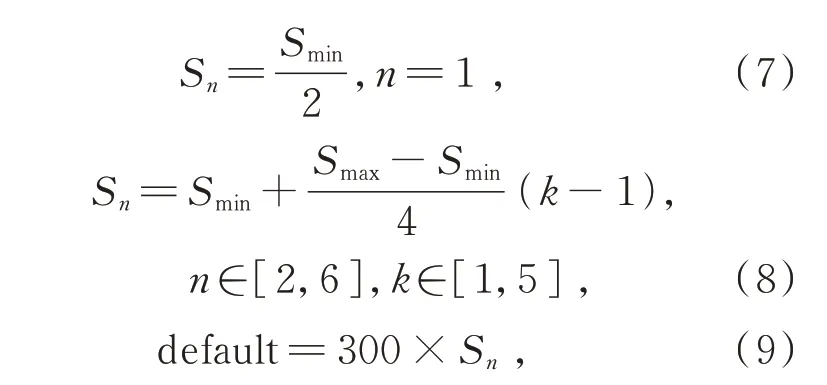
式中Sn為6 個特征層的先驗框對于原圖的比例;Smin和Smax為比例的最大值與最小值,在原SSD框架中取0.2 和0.9;default 為先驗框的尺寸。
通過統計數據集中標注框與原圖的比例,如圖7 所示,可以看出飛機目標的最小尺寸約為22×22,在原SSD 模型中當Smin設置為0.2 時,最淺層特征層先驗框的尺寸為30×30,不能覆蓋數據集中最小尺寸的飛機目標。因此根據數據集中最小目標的尺寸對先驗框進行調整,將Smin的值調整為0.14,根據式(8)可以計算出此時最小的先驗框尺寸為21×21,基本上可以覆蓋輸入圖像中的各種形狀和大小的目標。尺寸調整前后的先驗框尺寸如表1 所示。

圖7 待檢測目標真實框與原圖比值Fig.7 Size ratio of the real frame in the original image

表1 每層特征圖上的先驗框尺寸Tab.1 Priori boxes and numbers on layer of feature maps
4 實驗與結果分析
4.1 數據集與參數設置
本實驗在自制的航拍飛機數據集上進行。其中航拍的飛機圖片共3 581 張,按照7∶1∶2 的比例劃分為訓練集、驗證集和測試集,其中訓練集包含2 506 張圖片,驗證集包含358 張圖片,測試集包含717 張圖片。航拍數據集按照Pascal VOC2012 的格式建立,場景中大多數目標均為小目標。實驗在Windows 操作系統下進行,其中CPU 為AMD Ryzen5 5600x6-Core Processor,內存為16G,GPU為NVIDIA GeForce RTX 2080Ti,采 用Pytorch作為深度學習框架。初始學習率為0.000 1,動量因子參數為0.9,批處理大小為16,優化算法采用隨機梯度下降,衰減系數為0.1,最大迭代次數為120 000 次。
為了提高測量的精度,可在同一放大倍率下對不同的圓直徑進行測量并分別計算出每一個像素所代表的長度,然后求平均值作為在該放大倍率下的比例尺。
4.2 實驗評價指標
本文采用平均精度(Average Precision,AP)和每秒檢測圖像的幀數(Frame Per Second,FPS)作為評價指標。其中AP 是在0~1 范圍之間由準確率(Precision)和召回率(Recall)繪制的曲線與坐標軸之間的面積。準確率、召回率和精度(AP)的定義如式(10)~(12)所示:
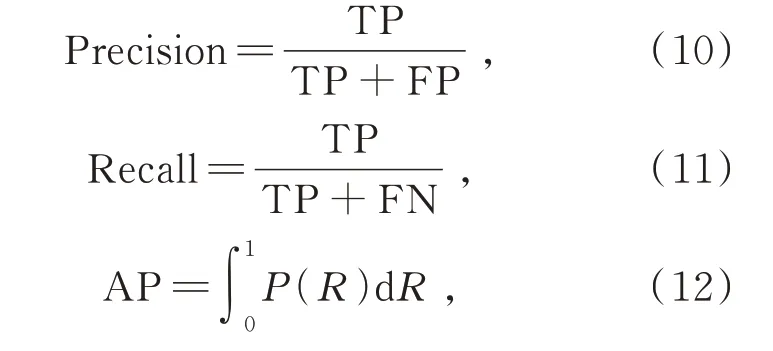
其中:TP 為正樣本中的比例,FP 為負樣本正例,FN 為負樣本中的負例。
4.3 實驗結果分析
為了對改進SSD 模型的性能進行評估,在自制的航拍圖像數據集進行訓練和測試,實驗結果如表2 所示。
由表2可知,本文所提的改進SSD 模型與兩階段的目標檢測模型Faster R-CNN 相比,精度提高了3.35%,檢測速度提高了24.1,說明本文的模型在檢測準確率和速度上均優于兩階段的檢測算法。與經典的改進SSD 模型DSSD 相比精度分別提高了4.26%,檢測速度較DSSD 提高了19.4。與YOLOv3 相比,精度提高了4.03%,檢測速度降低了3.1。與YOLOv4 相比精度提高了1.4%,檢測速度降低了6.6。與主打檢測速度的輕量級網絡YOLOv4-tiny 相比精度提高了6.4%,檢測速度降低了30.4。實驗表明,改進的SSD 模型能夠提升對小目標檢測的效果,并且也能夠滿足實時檢測的要求。圖8 為不同方法在不同場景下航拍飛機圖像上的檢測結果,其中從上到下依次為小目標密集區域、復雜背景區、多尺度目標區。

表2 各算法在航拍飛機數據集上的檢測精度Tab.2 Detection accuracy of each algorithm in aerial aircraft data set
由圖8 可以看出,在小目標密集區域,對于圖最左側的幾個極小的飛機目標,改進的SSD 模型可以全部檢測到,YOLOv4 模型漏檢了一個,其他的模型都有較多的目標沒有檢測到。在復雜背景區域,最右側的目標較小且機身顏色與地面顏色十分相似,改進的SSD 模型可以全部檢測出,并且在圖的左側沒有出現誤檢的情況;YO‐LOv4 模型對于右側的小目標漏檢了一個并且左側出現了一個誤檢的情況;YOLOv4-tiny 模型對于右側與背景顏色相近的目標均沒有檢測出并且在左側存在多個誤檢的情況;YOLOv3 模型相比于YOLOv4-tiny 模型能夠檢測到更多的目標,但是也有多個目標未能檢測到且存在誤檢的情況;其他模型也存在漏檢、誤檢的情況。在多尺度目標區域可以看出,所有模型對于較大尺度的模型都檢測到,但對于圖中最上方和右側以及左側靠下位置的小目標,只有改進的SSD 模型可以全部檢測出,YOLOv4 模型沒有檢測到左側的小目標,YOLOv4-tiny 有較多小目標,沒有檢測到,YOLOv3 模型除沒有檢測到的小目標還出現了一個誤檢的目標。通過在不同場景下與不同方法的對比可以得出,改進的SSD 模型相比于其他模型能夠更好地檢測出小目標,并且對于一些復雜場景下的目標也可以做到正確識別。

圖8 不同方法在不同場景下的檢測結果Fig.8 Detection results of different algorithms in different scenarios
圖9 為在存在外界干擾的特殊環境時的改進SSD 模型的檢測結果,其中圖9(a)為飛機與周圍環境顏色相近,圖9(b)為航拍時受到云的遮擋,圖9(c)為飛機隱蔽在樹林中。可以看出改進的SSD 模型在3 種特殊的環境中均可以識別到目標,驗證了改進的SSD 模型在受到一定環境因素干擾時仍然有著較好的檢測結果。

圖9 特殊環境下的檢測結果Fig.9 Detection results in special environments
4.4 消融實驗
為了驗證改進的SSD 模型中各個模塊的有效性,在航拍的飛機數據集上使用具有不同模塊的模型進行消融實驗,迭代次數設置為120 000 次。包含的模塊有是否使用特征融合機制、是否使用混合注意力機制、是否對先驗框進行優化幾項區別。所有實驗結果記錄在表3 中,其中使用模塊時在表格中用對勾號表示,不使用時則表格的這一欄為空。
由表3可知,在SSD 原模型的基礎上添加了特征融合機制后,召回率和精度分別提高了13.1%和3.5%,代表檢測到的小目標增多,整體的檢測性能得到了提升,證明了將深層語義信息和淺層細節信息融合的有效性。準確率和幀率分別下降了0.4%和6.9 FPS,是因為檢測到的小目標增多,但是存在很小一部分的誤檢情況以及網絡增大,導致檢測速度下降。在添加混合注意力模塊(BAM)后,召回率和精度分別提升了8.5%和2.6%,證明了使用混合注意力機制可以使網絡關注有目標的區域來提升檢測效果。在優化先驗框參數后,召回率和精度分別提升了4.6%和1.6%,證明在對先驗框參數進行優化后可以改變感受野的大小,使其與目標大小更匹配,提高對小目標的檢測效果。在表3 最后一行可以看出,在將3 個模塊均添加到SSD 原模型上后,召回率提高了39.8%,精度提高了7.5%,證明了該算法的有效性,對小目標的檢測有著較大的提升。
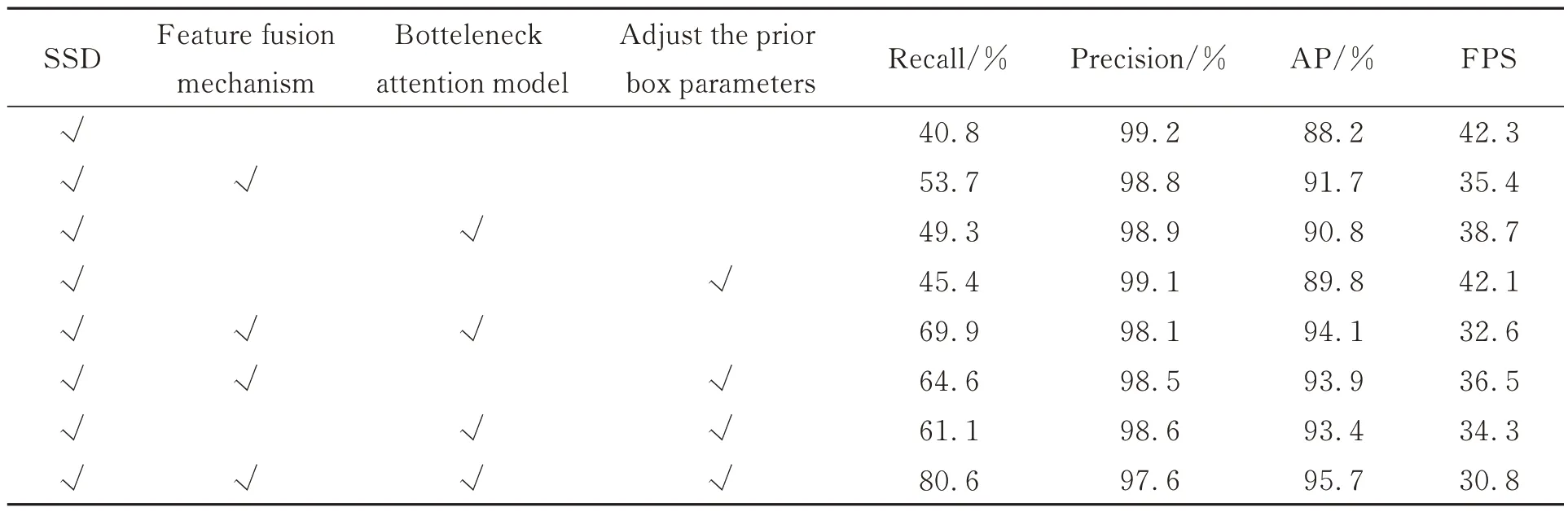
表3 各獨立模塊對航拍目標的檢測效果影響Tab.3 Influence of each independent module on aerial target detection
5 結論
為解決在航拍圖像中對于小目標檢測效果不佳的問題,通過引入特征融合機制、添加注意力機制和優化先驗框等措施,在SSD 算法的基礎上提出了一種改進的航拍圖像SSD 檢測算法。實驗結果表明,改進SSD 模型的檢測結果優于原SSD 模型,精度由原來的88.2%提升到95.7%且對不同場景下的航拍飛機小目標均有比較好的檢測結果,充分證明了方法的有效性。對比其他幾種經典的目標檢測算法,改進后模型在航拍目標檢測任務中具有更高的綜合性能。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
