集成強化學習算法的柔性作業(yè)車間調度問題研究
2023-02-17 15:01:04焦小剛
中國機械工程 2023年2期
關鍵詞:動作
張 凱 畢 利 焦小剛
寧夏大學信息工程學院,銀川,750021
0 引言
柔性作業(yè)車間調度問題(flexible job-shop scheduling problem,F(xiàn)JSP)自提出以來已被廣泛研究[1-2],共有三類求解方式:基于規(guī)則、基于元啟發(fā)式[3-7]和基于強化學習[8]。
基于規(guī)則的方法無法保證最優(yōu)解,基于元啟發(fā)式的方法計算量大且易于陷入局部最優(yōu)解。為提出更好的解決方案,近年來,學者使用強化學習(reinforcement learning,RL)求解FJSP。XUE等[9]指出,基于強化學習求解調度問題需要解決2個問題:如何將調度問題轉化為強化學習問題,如何保證強化學習能得到調度問題合適的解。基于Q-learning 的遺傳算法的參數調整方法可自動調參并找到最優(yōu)參數[10]。LUO[11]利用深度Q網絡算法解決了有隨機任務插入的動態(tài)柔性車間調度問題。ZHANG等[12]使用析取圖表示車間調度的狀態(tài),通過 PPO(proximal policy optimization)算法同時訓練智能體的策略和析取圖組成的圖神經網絡,實驗結果表明該方法優(yōu)于傳統(tǒng)方法。
目前,采用強化學習主流算法求解FJSP存在兩個問題:①將FJSP轉換為馬爾可夫決策過程(Markov decision process,MDP)時,針對不同求解目標構建不同的狀態(tài)特征、動作空間、獎勵函數,狀態(tài)中的一些隱性關系難以獲得;②使用強化學習算法訓練求解時,只用到單一算法,不能充分體現(xiàn)和利用算法的改進、優(yōu)化、融合。針對上述兩個問題,筆者在求解目標為最大完工最小化時構建一種新的MDP,并提出D5QN算法進行求解。實驗結果表明該方法可使最大完工時間最小化的指標進一步提高。
1 問題建模
FJSP描述為n個工件{J1,J2,…,Jn}在m臺機器{M1,M2,…,Mm}上加工。每個工件包含一道或多道工序。工序是預先確定的,每道工序可以在不同加工機器上完成,工序的加工時間隨加工機器的不同而不同。
1.1 目標
標為最小化最大完工時間,即
(1)
式中,i為工件號;Ci為工件i的完工時間。
1.2 符號表示
FJSP的符號和決策變量的說明見表1。

表1 FJSP符號描述Tab.1 FJSP symbol description
1.3 約束表示
問題模型共有6個約束條件:①1臺機器一次只能加工1個工件;②工件的一道工序只能由1臺機器完成;③工序開始后,加工不能中斷;④工件的優(yōu)先級相同;⑤不同工件的工序沒有先后約束,每個工件的工序有先后約束;⑥所有工件在零時刻都可被加工。FJSP約束的公式描述和含義如表2所示。

表2 FJSP約束表示Tab.2 FJSP constraint representation
2 強化學習和D5QN
2.1 強化學習
強化學習表述為一個智能體如何在一個復雜不確定的環(huán)境里面最大化它能獲得的獎勵,如圖1所示,其中,下標t表示當前時間步,t+1表示下一時間步。
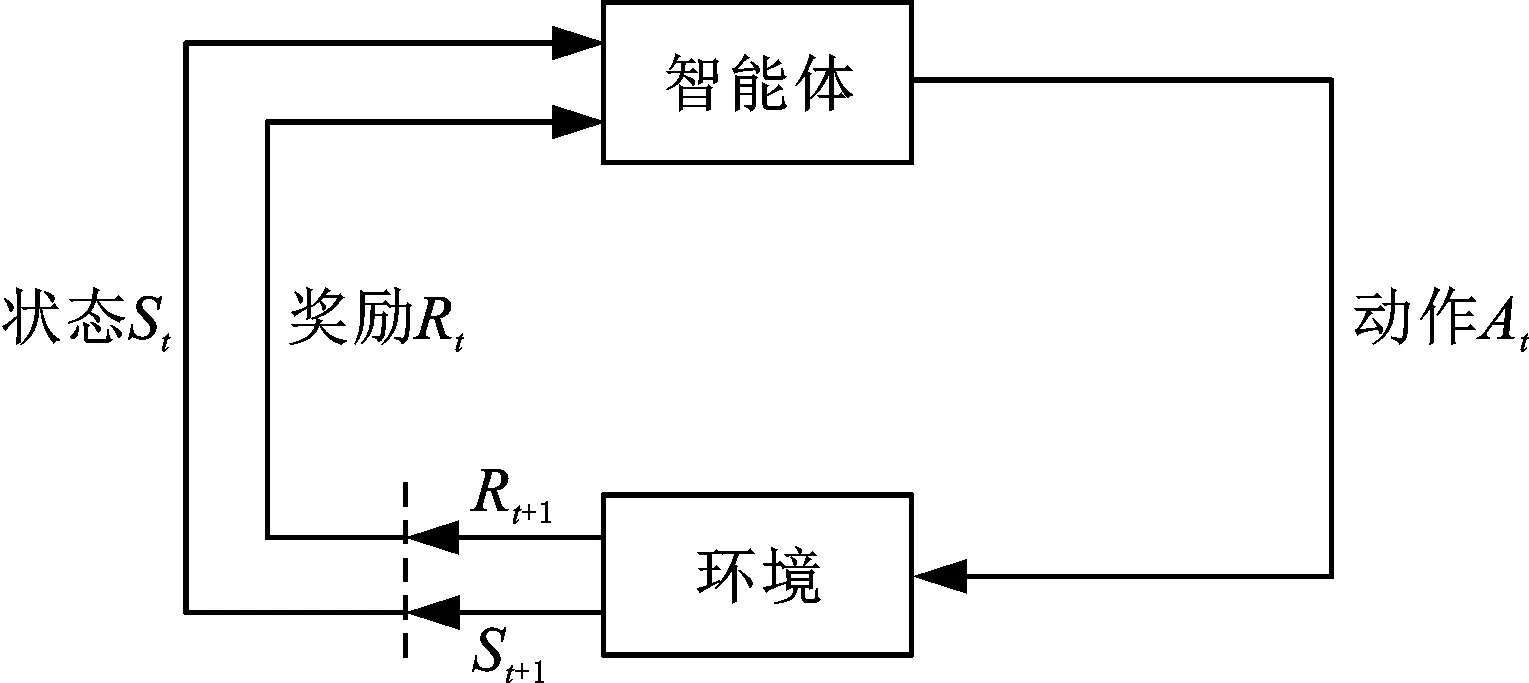
圖1 強化學習Fig.1 Reinforcement learning
強化學習過程可以被建模為一個由5元組(S,A,P,γ,R)表示的馬爾可夫決策過程。其中,S表示環(huán)境目前的狀態(tài);A表示智能體采取的動作;P表示從一個狀態(tài)轉移到下一個狀態(tài)的概率;γ為折扣因子,取值區(qū)間為(0,1);R表示智能體采取一個動作后給予的獎勵。智能體根據特定的策略與周圍的環(huán)境進行交互,通過當前狀態(tài)st(st∈S),下標t表示當前時間點,根據策略π(S→A)執(zhí)行動作at(at∈A),得到一個新的狀態(tài)st+1和轉移概率p(st+1|st,at)∈P(S×A→S),并得到獎勵rt(rt∈R)。智能體的目標是找到最優(yōu)策略π*,使動作在狀態(tài)預期的長期回報總和最大。選取動作的價值函數為
qπ*(s,a)=maxqπ(s,a)
(2)
2.2 DQN及其優(yōu)化
(1)深度Q網絡(deep Q-network,DQN)結合強化學習和深度學習,提出經驗回放和目標網絡兩個技巧,針對傳統(tǒng)Q-Learning方式無法處理連續(xù)價值函數的問題,通過函數qφ(s,a)來表示近似狀態(tài)價值函數:
qφ(s,a)≈qπ(s,a)
(3)
(2)雙深度Q網絡(double DQN,DQN)用來解決DQN算法在訓練時函數q值往往被高估的問題,即同時存在兩個網絡:網絡Q決定的哪一個動作的q值最大,網絡Q′計算q值。q值更新的方式為
(4)


(5)
(4)優(yōu)先級經驗回放(prioritized experience replay,PER)指的是以一定的優(yōu)先級進行經驗回放,即增大重要數據的采樣幾率,以達到更好的訓練效果,在DQN中添加優(yōu)先經驗回放后表現(xiàn)為圖2。

圖2 優(yōu)先經驗回放機制Fig.2 Priority experience playback mechanism
(5)競爭深度Q網絡(dueling DQN)在DQN的基礎上,將深度Q網絡的計算過程分為兩步。第一步計算一個與輸入有關的標量V(s);第二步會計算向量A(s,a),最后的網絡是將兩步的結果組合,網絡結構如圖3所示。

圖3 Dueling DQN網絡結構圖Fig.3 Dueling DQN network structure diagram
2.3 D5QN算法
在DQN算法的基礎上,集成DQN、noisy DQN、PER DQN和dueling DQN,提出D5QN算法。D5QN可有效利用每種算法的優(yōu)點,即使用神經網絡擬合狀態(tài),使用DQN避免過度估計,加入噪聲增加探索多樣性,使用優(yōu)先經驗回放加快訓練,使用競爭網絡提高訓練q值,并且每種優(yōu)化方式不會相互產生負影響,達到取長補短的效果。D5QN算法流程偽代碼如下,其中,yi為當前網絡要求解的目標值。

偽代碼1:D5QN算法流程初始化緩沖池D大小為N初始化當前網絡Q權重為θ初始化目標網絡Q^權重θ-=θ對于每一個回合episode=1:L 初始化狀態(tài)s1中的n個特征表述為向量φ1 為Q網絡添加一個新的高斯噪聲 對于每一個時間步t(T為回合中的最大時間步數,T=p) 以一定的概率ε選擇一個隨機的動作at 否則動作at=argmaxaq~(s,a) 執(zhí)行動作at,觀察下一個狀態(tài)st+1,計算獎勵rt 獲得新的特征向量φt+1 存儲四元組(φt,at,rt,φt+1)到緩沖池D,且為該四元組添加優(yōu)先級 在D中以權重概率的方式選擇一個batch_size (φj,aj,rj,φj+1) yj=rj當前步數調度結束rj+γQ^(φj+1,argmaxa'Q(φj+1,a';θ);θ-)其他 通過目標與當前Q網絡差值(yj-Q(φj,aj;θ))2執(zhí)行梯度下降,從而更新Q網絡中的參數θC步更新Q^=Q(將目標網絡更新為當前網絡,C為所經歷的時間步數)
3 模型求解
求解FJSP時,首先將FJSP轉化為MDP,然后通過D5QN算法求解。本章依次描述狀態(tài)、動作、獎勵、求解過程。
3.1 狀態(tài)描述
通過提取調度過程的重要特征來近似描述某一時刻的調度狀態(tài)。調度環(huán)境在某一時刻的狀態(tài)由一組向量表示。每個值或每組值(用向量表示)描述如表3所示。

表3 MDP狀態(tài)描述Tab.3 MDP status description
表3描述調度過程中的狀態(tài)表示的一系列指標。每個量和向量元素的值都在0~1之間,且每個指標在0時刻的初始值均為0。調度過程中某時刻的狀態(tài)可表示為
φ=(Mr1,Mr2,…,Mrm,Mw1,Mw2,…,Mwm,
Jr1,Jr2,…,Jrn,Mr,Mrr,Mw,Mww,Jr,Jrr,Or)
(6)
3.2 動作設計
針對所要求解的目標——最大完工時間最小化,設計出映射目標的三組動作。每組動作包含
m個動作(與機器總數相同),具體描述見表4,其中,Ωt為t時刻可調度的(機器、工件)列表(隨機打亂);Ωj為第j(j=1,2,3)組動作的可加工(機器,工件)列表(按照特定指標排序);Aj為第j組動作的可選動作集合;aj為第j組動作中選取的具體動作標號;Mk、Ji分別為最終選取的機器和工件的編號。

表4 動作表述Tab.4 Action statement
每組可用的動作少于m個即Ωt的大小小于m(多數情況下如此)時,采取循環(huán)隊列的方式繼續(xù)從頭選取。
該動作表述方式有三個優(yōu)點:①可以選取的動作均與求解的目標緊密關聯(lián),即通過加工時間、機器利用率、工件完成率來反映最大完工時間;②確保動作多樣化,即每組動作的可選擇數量為機器數量(每一個動作中包含對應一個機器),保證某一時刻下選取動作時每個機器均可能被選擇;③循環(huán)隊列方式可使隊列中隊首的元素(對應的動作)被采用的概率增大。例如:當前空閑機器數量為3,總機器數量為5,如果當前選擇的動作編號4對應第4個機器,該機器不可用,則最終選取編號為1,即該機器編號對可用機器總數取余數。
3.3 獎勵設計
獎勵的設計直接影響訓練的最終效果,是最為關鍵的步驟之一。最大完工時間最小化求解目標在MDP中屬于“獎勵罕見”的情況,最后一步操作完成時才知道最終完工時間。所以在非終止步驟,需要對問題求解進行轉換,即對獎勵進行間接映射,從而更好地完成訓練。
考慮到最大完工時間最小可以間接反映為每個機器的利用率和每個工件的完成率盡可能均衡,所以每一步盡最大可能均衡機器的使用率和工件完成率。
單一規(guī)則調度后,可以估算出完工時間的范圍,如果完成調度時時間超出預設的完工時間(超參數)Cbest,則產生很大的負獎勵,否則產生正獎勵。強化學習中,獎勵有正有負才能達到更好的訓練結果。獎勵的描述如偽代碼2所示。其中,reward表示每一次調度完成時的及時獎勵。

偽代碼2:獎勵描述if調度尚未結束 if調度已用時間≥Cbest 終止調度,reward=-100 else if Mr增大 and Jr增大 reward=1 else reward=-1 end if end ifelse if完工時間≥Cbest reward=-100 else reward=(Cbest-完工時間)*10+0.01 end ifend if
3.4 算法流程實現(xiàn)
狀態(tài)、動作、獎勵設計完成之后,采用D5QN算法求解,利用全連接網絡描述Q網絡的網絡結構。圖4反映了FJSP轉化為MDP以及通過D5QN算法求解的過程。

圖4 D5QN算法求解FJSPFig.4 D5QN algorithm to solve FJSP
4 實驗
程序在Windows10 64bit的個人電腦(CPU I7-7700、內存8GB)上運行。語言環(huán)境基于python 3.9.12、conda 4.12.0,問題環(huán)境基于OpenAIGym編寫,深度網絡基于torch 1.11.0和numpy 1.21.5編寫。
為驗證所提出方法的優(yōu)越性,首先將D5QN與其他單一優(yōu)化DQN算法進行對比。其次,在相同數據集下與文獻[13-14]的方法,以及與基于規(guī)則和元啟發(fā)式的方法進行對比。
4.1 D5QN與單一優(yōu)化DQN的對比
將D5QN算法與其他單一優(yōu)化DQN算法對比,Mk算例集上各個算法求解的最優(yōu)結果如表5所示,加粗數字為所有算法求出的最好解。Mk算例集在提出之時,規(guī)定最優(yōu)解是一個范圍。
表5表明,相同的MDP下,某些單一優(yōu)化DQN算法在某些算例下可以取得最優(yōu)解,但D5QN算法最優(yōu)解不劣于其他DQN優(yōu)化算法的最優(yōu)解。
D5QN在Mk09上求解時,迭代次數和完工時間如圖5所示。由于noisy DQN、PER DQN和dueling DQN效果相似,故將DQN、dueling DQN、D5QN三種算法作對比,3種算法求解的迭代次數和平均完工時間的關系如圖6所示,由圖6可以得出D5QN算法的收斂速度和最終收斂效果優(yōu)于其他算法。

圖5 D5QN算法在Mk09上的迭代次數和完工時間圖Fig.5 The number of iterations and completion time of the D5QN algorithm on Mk09
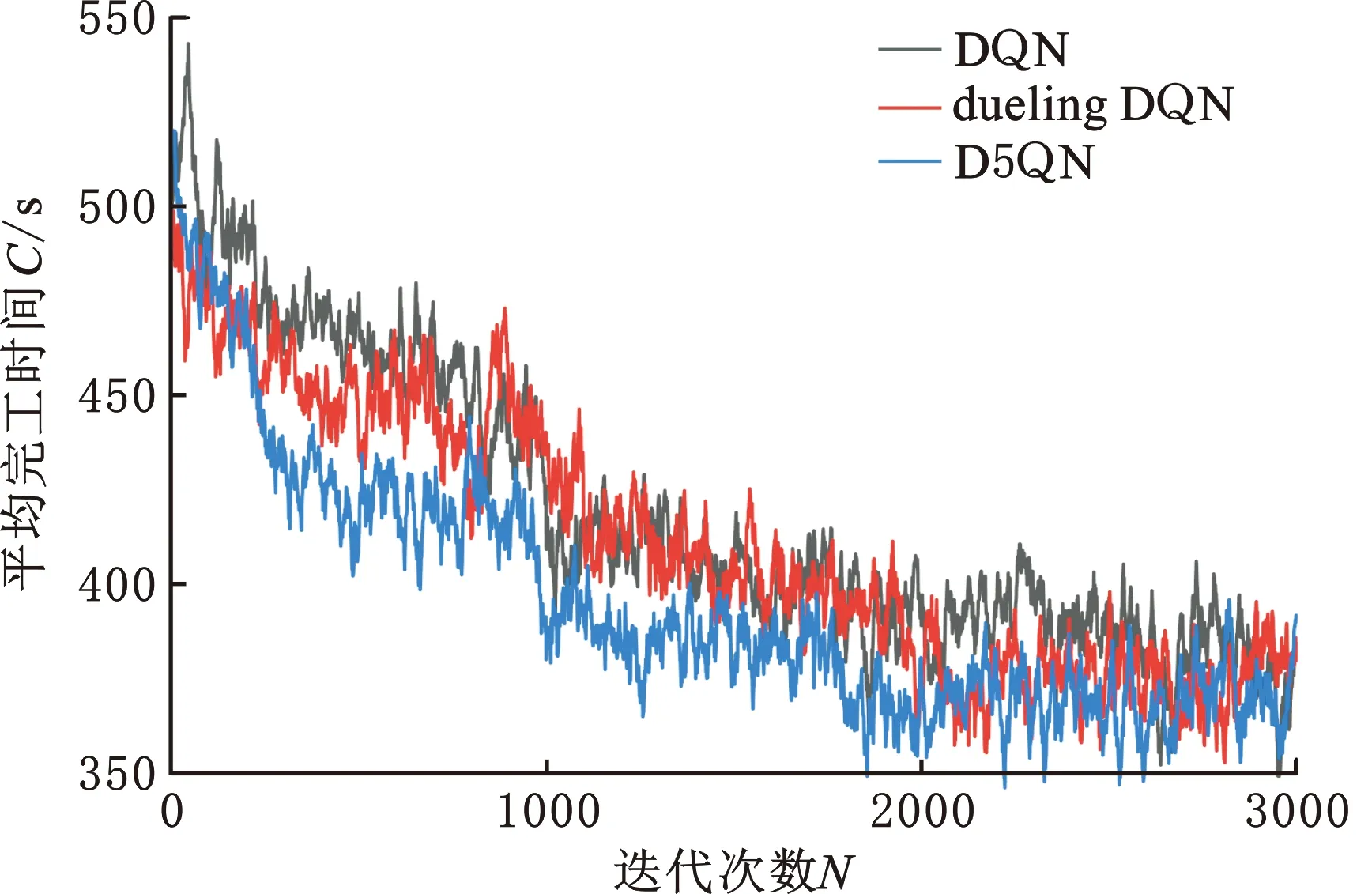
圖6 DQN、dueling DQN、D5QN在Mk09訓練集上平均完工時間Fig.6 Average completion time of DQN,dueling DQN,D5QN on Mk09 training set
4.2 D5QN與其他算法對比
表6所示為基于規(guī)則組合的三種方式(SPT+EF[13]、SRPT+EF[13]、SRPT+SPT[13])、遺傳算法(genetic algorithm,GA[13])、其他強化學習算法(AC-SD[14]、PPO[13])和D5QN算法的最優(yōu)結果。遺傳算法和其他強化學習算法可以在某些算例下取得與D5QN相同的結果,但D5QN在每種算例下均可以取得最優(yōu)解(加粗數值)。

表6 D5QN和其他方式求解FJSP最短完工時間Tab.6 D5QN and other ways to solve FJSP minimum makepan
圖7、圖8中,GA、AC-SD(actor critic-SD)、PPO和D5QN在求解出的最優(yōu)解上優(yōu)于基于規(guī)則組合的方式,且D5QN在求出的最優(yōu)解(指標:最大完工時間最小)上比GA和PPO、AC-SD算法效果更好。

圖7 不同方式求解Mk01~Mk10平均最短完工時間Fig.7 Different ways to solve Mk01~Mk10 average shortest completion time

圖8 不同方式求解Mk01~Mk10總最小完工時間對比Fig.8 Comparison of total minimum completion time for solving Mk01~Mk10 in different ways
實驗結果均表明D5QN在求解Mk01~Mk10時均可取得最優(yōu)解,優(yōu)于單一優(yōu)化DQN算法、基于規(guī)則方法、遺傳算法和其他強化學習算法。
5 結論
為了求得FJSP的更優(yōu)解,將FJSP轉換為馬爾可夫決策過程,并通過集成了DQN、DDQN、noisy DQN、PER DQN和dueling DQN 5種算法的D5QN算法進行求解。
FJSP中的經典問題集Mk01~Mk10的求解結果驗證了D5QN算法的可行性和有效性。未來針對多目標、動態(tài)環(huán)境下的FJSP,嘗試使用更多方式構建MDP并通過其他強化學習改進算法,繼而進一步提高求解質量。
猜你喜歡
作文周刊·小學一年級版(2022年16期)2022-05-07 11:28:30
作文周刊·小學一年級版(2021年8期)2021-07-07 11:00:47
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語文·低年級(2014年10期)2015-01-14 14:46:27
