基于樣本擴充與IDANN的刀具狀態識別方法
2023-02-13 02:36:42董紹江蔣明佑羅召霞
重慶大學學報 2023年1期
董紹江,蔣明佑,羅召霞
(1.重慶交通大學 機電與車輛工程學院,重慶 400047;2.西南交通大學 磁浮技術與磁浮列車教育部重點實驗室,成都 610031)
刀具作為機床的重要組成部分,其狀態對于產品的加工質量、表面精度及整個設備系統的正常運維具有重要影響。當刀具磨損到一定程度時,如果持續使用,會引起切削力、切削溫度及切削振動等明顯變化,降低切削性能[1]。美國肯納金屬公司研究表明,刀具的有效檢測可避免因刀具損壞導致的工件損壞及設備故障,節約費用30%[2]。刀具的磨損狀態監測是加強刀具智能監測識別能力、提高識別精度、增強泛化性和魯棒性的重要保障。
針對刀具狀態監測提出的方法很多,目前常用的刀具狀態識別算法有人工神經網絡(ANN)、隱馬爾可夫模型(HMM)和支持向量機(SVM)等[3]。Coppel等[4]將人工神經網絡同遺傳算法、蟻群算法相結合構建了自適應控制優化系統,有效監測了銑刀的磨損狀態;Cao等[5]利用小波包變換和Hilbert-Huang變換(HHT)實現端銑過程中的顫振識別,提高了加工生產率和零件質量;Zhu等[6]利用隱馬爾可夫模型和基于切削力的節點平均能量,實現了切削過程中磨損量的預測;Zhang等[7]針對球頭銑刀提出了一種基于最小二乘支持向量機的刀具磨損識別模型,識別效果較優。
以上方法在進行刀具狀態識別時通常有兩個基本假設:1)用于學習的訓練樣本與測試樣本滿足獨立同分布假設[8];2)具有足夠的可訓練樣本。但是實際的刀具損耗中數據更新迅速,原先可利用的訓練樣本很快過期,且新數據標注過程繁瑣,導致以上兩個假設通常很難滿足。針對這一問題,Sun等[9]構建了深度遷移網絡模型,并以相對熵離散度(Kullback-Leibler divergence)為衡量標準來降低不同刀具特征間的差異;郝碧君等[10]在原有時頻域特征基礎上,通過小波包分解來獲取新的能量特征以擴充訓練數據;對于少量訓練數據無法訓練出較強泛化能力模型的情況,遷移學習利用與目標數據不同但相關的輔助數據,極大提高了機器學習算法在目標域上的準確率[11]。
受上述研究啟發,筆者提出了一種基于樣本擴充與改進領域對抗網絡(sample expansion and improved domain adversarial training of neural networks,SE-IDANN)的遷移學習刀具狀態識別方法。通過二次特征提取與Smote算法擴充樣本量;將Wasserstein距離[12]作為衡量標準引入模型,提高兩個域的分布對稱性;加入殘差塊,在避免梯度爆炸的同時將模型特征提取層加深,進而提高目標刀具磨損識別準確率。
1 基于一次特征的二次特征提取與Smote樣本擴充算法
1.1 二次特征提取原理
本研究中所用刀具數據提取的一次特征包括時域特征、頻域特征、時頻域特征和時序特征。其中時域特征為絕對平均值、均方根值、歪度峭度值等;頻域特征為頻域幅值平均值、頻域幅值標準差等;時頻域特征為能量特征比(即小波包分解后能量集中頻段值與全頻段能量總和之比);時序特征為近似熵、自回歸系數、傅里葉變換系數等。
受數據量影響,一次特征的維度可能無法滿足深層數模型的特征提取需求,因此將每個樣本的一次特征進行二次特征提取,以擴大特征數量。表1為提取的二次統計學特征。

表1 二次統計特征
表中的波形指標反應刀具磨損與崩壞的變化情況;脈沖指標用以監測信號中是否存在沖擊;歪度指標是概率密度函數不對稱性程度的度量;峰值指標不受振動信號絕對水平所左右,不易出現測量誤差;裕度指標和峭度指標對沖激脈沖較為敏感。
1.2 Smote樣本擴充原理
受原始數據量影響,原有樣本數較少,可能無法滿足層數較深的網絡訓練需求,因此對原始樣本進行樣本擴充。
傳統隨機過采樣采取簡單復制樣本的策略增加少數類樣本,實際并未產生新的樣本,且容易產生過擬合。Smote算法[13]是根據少數類樣本分布人工合成新樣本添加到數據集中,基于原有樣本產生的新樣本獨立于原始樣本,這在一定程度上增加了可遷移樣本量。Smote算法新樣本點產生如圖1所示。
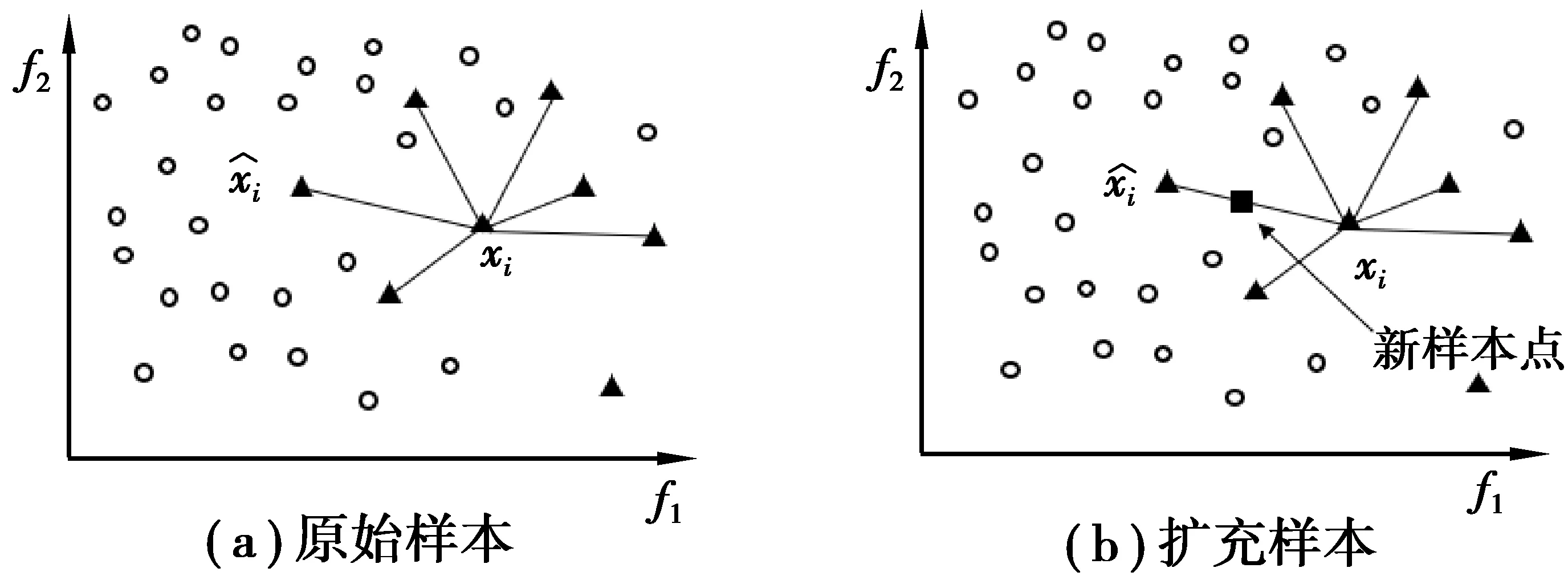
圖1 Smote新樣本產生
對于少數類樣本中的每個樣本x,以歐氏距離計算它到少數類樣本集smin中所有樣本的距離,得到其k近鄰(k-nearest neighbor)。根據樣本不平衡比例設置一個采樣倍率N,對于每個少數類樣本x,從其k近鄰中隨機選擇若干個樣本。對于每個選出的第i個近鄰xi,分別與原樣本按照公式(1)構建新的樣本。
xnew=x+rand(0,1)|x-xi|。
(1)
2 基于Wasserstein距離的數據分布相似性分析
利用Wasserstein距離作為數據分布相似性的標準進行分析,在原有DANN模型基礎上引入Wasserstein距離用于衡量兩個分布之間的差異。相比于KL離散度和JS離散度(Jensen-Shannon divergence),即使兩個支撐集沒有重疊或者重疊很少,Wasserstein距離仍能衡量兩個分布的相似度。Wasserstein距離定義如式(2)所示:
(2)
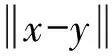
神經網絡本身具有特征變換的能力,將Wasserstein距離作為損失值引入DANN,通過最小化源域與目標域數據在映射空間下的Wasserstein距離,得到降維后的特征空間。在該特征空間下,目標域與源域具有相同或者非常相近的數據分布。
3 DANN網絡算法原理
DANN網絡[14]的目標是把具有不同分布的目標域與源域數據映射到同一特征空間,通過對抗準則使其在該空間上的距離縮小,然后用源域訓練好的分類器對目標域數據分類。數據映射過程如圖2所示。

圖2 DANN網絡數據映射過程
DANN網絡由特征提取器(feature extractor)、類別分類器(category classifier)和域判別器(domain classifier)組成。特征提取器和類別分類器共同構成一個前饋神經網絡。在特征提取器后面加入域判別器,并通過梯度反轉層(gradient reversal layer,GRL)連接。DANN的網絡結構及傳播過程如圖3所示,圖中f為提取的特征,y為分類結果,Ly為類別分類損失值,Ld為域判別損失值。
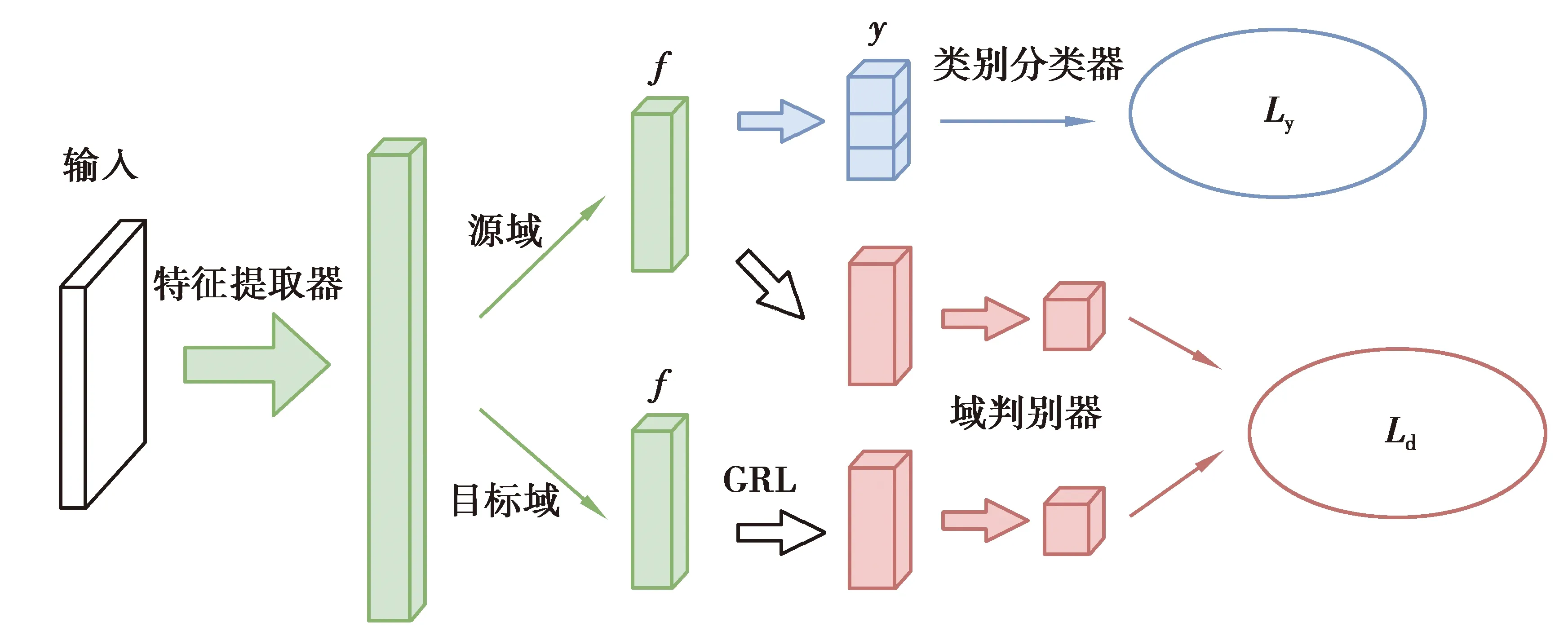
圖3 DANN網絡結構及傳播過程
DANN的損失值包含類別分類損失與域判別損失兩部分。類別分類損失定義如下:
(3)
式中:(xi,yi)為輸入樣本及其標簽,Gf為特征提取過程,Gy為類別分類過程。
源域上的訓練優化目標為:
(4)
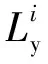
域判別損失定義如下:
(5)
式中:di為第i個樣本的二元標簽,表示該樣本屬于目標域還是源域;Gd為域判別器輸出。
則域判別器訓練優化目標為:
(6)
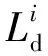
DANN網絡模型的總目標函數為:
(7)
式中E為總損失值。
4 IDANN網絡
在原有DANN基礎上進行改進,加深特征提取器網絡層數并加入殘差塊,殘差塊結構如圖4所示,圖中s為網絡輸入,F(s)為殘差塊在第二層激活函數之前的輸出,RelU為激活函數。
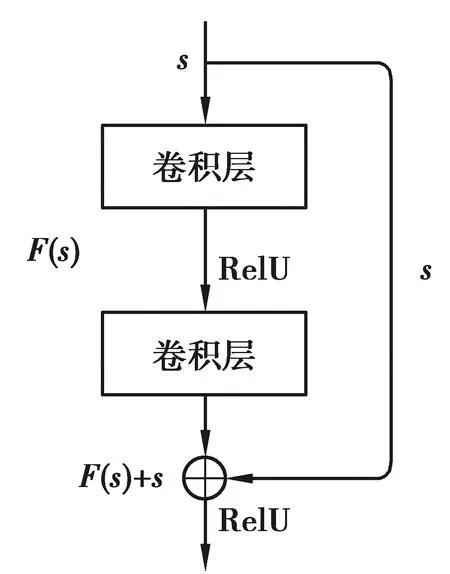
圖4 殘差塊結構
這一改變使特征提取更加深刻,并有效解決了由于神經網絡深度增加性能反而下降的問題。殘差塊的輸出為:
σ(F(s)+s)=σ(W2σ(W1s)+s),
(8)
式中:W1和W2為第一、二層網絡權重,σ為激活函數。
使用Wasserstein距離作為新的網絡損失值加入模型,這一改變使目標域與源域在映射空間下的分布更接近。
將源域與目標域特征提取器的輸出作為Wasserstein距離的計算輸入,并將Wasserstein距離的計算結果作為新損失值加入網絡,反向傳播更新模型參數的同時優化源域與目標域的數據分布。模型的最終優化目標為:
E′(W,b,V,c,U,z)=E(W,b,V,c,U,z)+w(P1,P2),
(9)
式中:w(P1,P2)為目標域與源域的Wasserstein距離;E′為調整后總損失值。
模型迭代訓練過程中,反向傳播更新的最優參數為:
(10)
(11)

IDANN跨刀具磨損狀態識別模型流程如圖5所示,圖中的Lw為經W距離計算后的損失值。
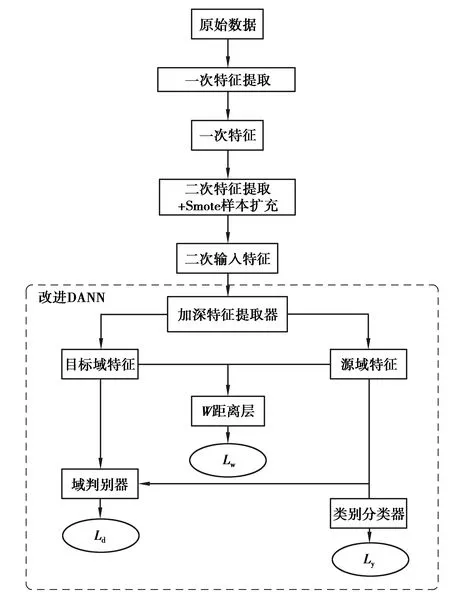
圖5 IDANN跨刀具磨損狀態識別流程
5 試驗對比驗證
采用美國紐約預測與健康管理學會2010年高速數控機床刀具健康預測競賽開放數據(Prognostics and Health Management Society, PHM2010)[15]和美國航空航天局艾姆斯研究中心銑削數據(NASA Milling Data Set)[16]兩個數據集進行方法驗證。將PHM2010試驗作為主要試驗,NASA Milling Data Set試驗作為方法遷移的驗證試驗。
5.1 PHM2010試驗設置
PHM2010刀具數據集為試驗選用的加工條件及信號采集參數(表2)。

表2 PHM2010試驗參數
試驗在CNC數控銑床的刀具進給方向(X)、主軸徑向(Y)、主軸軸向(Z)安裝了加速度振動信號傳感器,在夾具及工件上安裝了測力儀及聲發射傳感器。試驗對6把銑刀(C1、C2、C3、C4、C5、C6)進行了全壽命周期試驗,每把刀具進行了315次銑削加工。采集了X、Y、Z3個方向的銑削力信號、三向銑削振動信號和聲發射均方根值,共7組信號。其中C1、C4、C6測量了切削刃的后刀面磨損量,取3個切削刃的磨損量均值作為刀具磨損結果,3把銑刀的磨損量均值曲線如圖6所示。根據刀具磨損過程的一般規律[17]及磨損量均值,將刀具磨損狀態分為3類。其中小于85 μm時磨損較快,為初級磨損,這一階段,切削刃與加工表面接觸為一條直線,切削應力集中;85 μm到140 μm時磨損相對緩慢,為中級磨損,這一階段,磨損面寬度增加,磨損量呈現均勻增加;大于140 μm時磨損急劇,為過度磨損,這一階段,刀具由切削轉為啃削,溫度升高,磨損強度大大加劇。

圖6 PHM2010刀具磨損量均值曲線
對這3把銑刀分別進行了交叉驗證:C1、C6作為訓練集,C4作為測試集,定義為試驗A;C1、C4作為訓練集,C6作為測試集,定義為試驗B;C4、C6作為訓練集,C1作為測試集,此處定義為試驗C。
5.2 PHM2010試驗刀具特征提取
提取的特征包括時域、頻域、時頻域、時序共53種239個特征。在原有239個特征基礎上對每個樣本的一次特征進行二次特征提取,所提特征如1.1節所述,最終提取252個特征。
采用Smote算法按比例擴充,以B試驗為例,原始訓練集測試集樣本比為2∶1,將訓練集樣本按4∶1比例擴充,擴充后各磨損狀態樣本量為(0∶556,1∶1 540,2∶424),樣本量達到2 520,擴充后訓練集測試集比為8∶1。擴充前后數據在11號、91號、238號特征維度下的對比結果如圖7所示。

圖7 PHM2010樣本擴充前后對比
5.3 IDANN網絡參數設計
試驗使用PyTorch機器學習庫進行DANN網絡模型設計。使用Adam優化器進行模型參數更新,學習率為10-3,迭代輪數為3 000,隨機失活率(Dropout)為0.5,激活函數為ReLU,其中類別分類器與域判別器分別包含3層與2層全連接層,特征提取器為2個卷積池化層與3個殘差結構的組合。模型參數如表3所示。
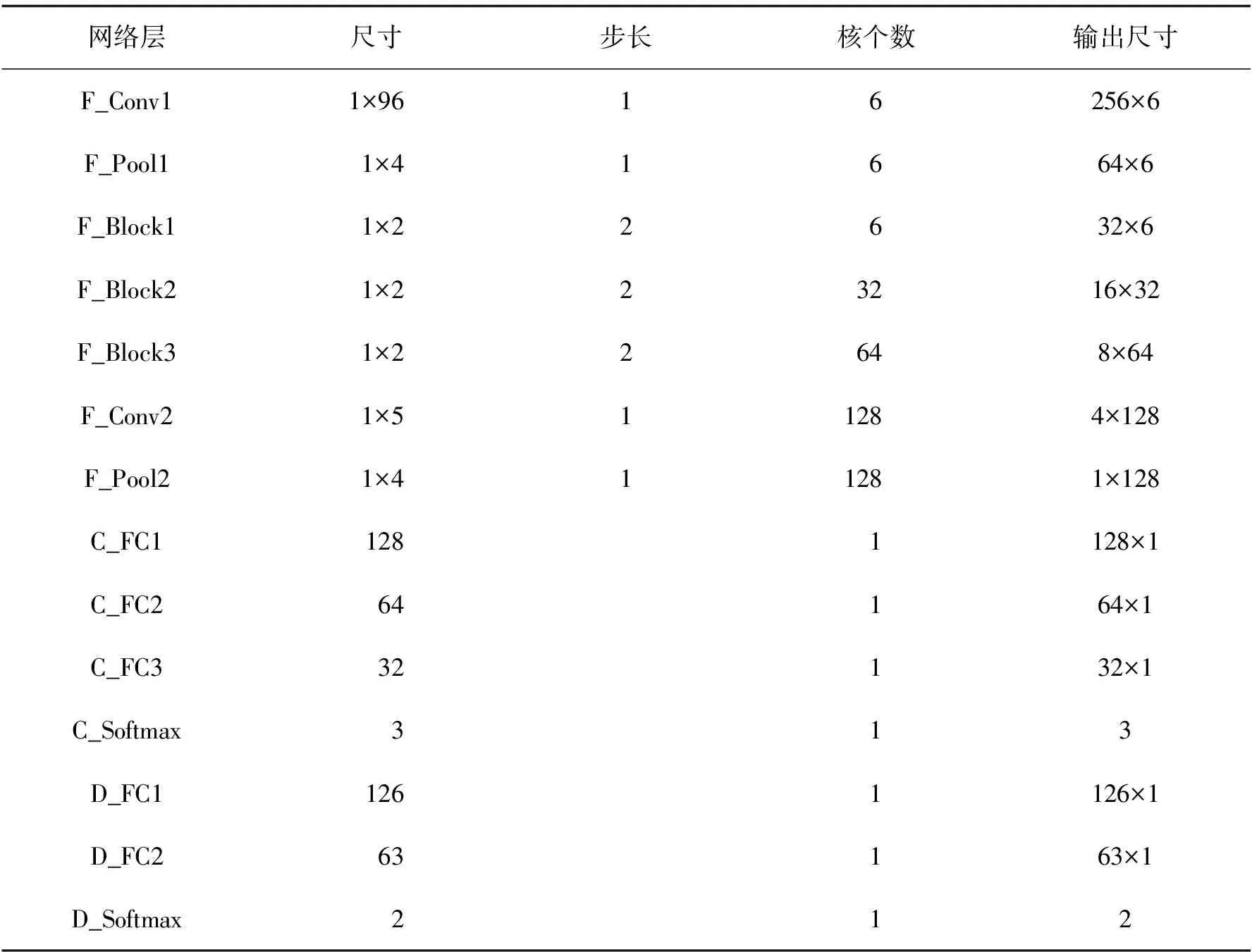
表3 IDANN模型參數
特征提取器的第一卷積層F_Conv1使用寬卷積核,能有效削弱高頻噪聲對特征提取的影響,起到抗干擾作用[18]。F_Conv1卷積核尺寸為1×9,步長為1×1,卷積核個數為6。每個F_Block包含4個殘差塊,每個殘差塊包含2個卷積層,每層卷積核尺寸、卷積核個數相同,其中第一個殘差塊卷積層的步長為2×1,其他為1×1。在FC層之間加入Dropout層,防止模型過擬合。將兩個域的特征提取器輸出作為Wasserstein距離計算的輸入,并將此計算結果作為損失值嵌入模型。
試驗選取CNN、ResNet、DANN作為對比模型。其中CNN為2層卷積池化層與全連接層組合,ResNet為3個殘差結構與全連接層組合,DANN為未添加殘差結構與Wasserstein距離指標的DANN模型,對比模型相關參數即為表3的各部分參數。
5.4 NASA Milling Data Set試驗設計
本研究中同時將此方法遷移到NASA Milling Data Set數據集。試驗采集了AC主軸電機電流信號、DC主軸電機電流信號、工作臺振動信號、主軸振動信號、工作臺聲發射信號和主軸聲發射信號,共6組信號。選取第5、16工況下的數據為源域,第9工況數據作為目標域,進行跨刀具材料的磨損狀態識別,定義為試驗D;其中第5、9、16加工工況如表4所示。

表4 NASA Milling Data Set刀具加工工況
按照刀具的一般磨損規律及后刀面磨損量變化將刀具磨損狀態分為3類:小于250 μm為初級磨損,250 μm到500 μm為中級磨損,大于500 μm為過度磨損。3把刀的后刀面磨損VB曲線如圖8所示。

圖8 NASA Milling Data Set刀具后刀面磨損曲線
根據試驗需求,將每組加工數據切分成70個小樣本。經二次特征提取后,特征數達到331。采用Smote算法按5∶1比例擴充,訓練集測試集比由11∶9擴充為55∶9。擴充前后數據在11號、91號、238號特征維度下的對比結果如圖9所示。
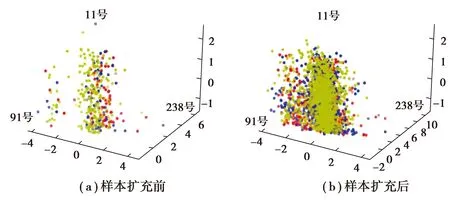
圖9 NASA Milling Data Set樣本擴充前后對比
6 試驗結果分析
針對PHM2010數據集分別進行了有、無樣本擴充條件下CNN、ResNet、DANN、IDANN模型的A、B、C試驗,識別正確率如圖10所示。
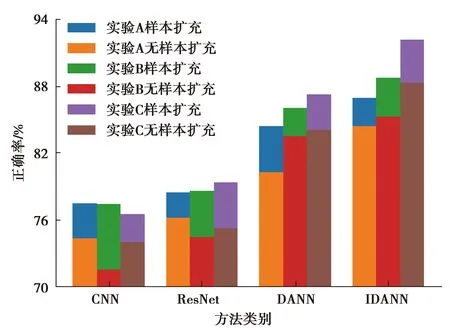
圖10 PHM 2010競賽數據識別正確率
由圖10知,采用樣本擴充后,所有模型的識別正確率均有所提升。證明擴充訓練樣本在一定程度上增加了可遷移樣本量,有助于目標域的分類。對比本研究中提出的遷移學習方法與傳統深度學習方法的效果,遷移學習的識別正確率均超過傳統深度學習識別正確率。其中,DANN與IDANN識別正確率超過82%,CNN與ResNet識別正確率低于82%。說明對于本研究中提出的跨刀具的磨損狀態識別任務,遷移學習識別效果更高。對比CNN與ResNet,ResNet正確率總體高于CNN,說明隨著網絡深度增加,特征提取更加深刻,分類效果更好。對比DANN與IDANN,IDANN正確率總體高于DANN,說明IDANN在加入Wasserstein距離指導后使源域目標域的數據分布更接近,遷移效果更好。SE-IDANN方法增加了可遷移樣本量,在加深特征提取深刻性的同時保證了源域和目標域的數據分布的對稱性,總體效果優于有或無樣本擴充條件下的CNN、ResNet和DANN方法。
試驗D識別結果如圖11所示。由圖11可知,在NASA Milling Data Set數據集下,有樣本擴充比于無樣本擴充識別正確率提高約7%,且有樣本擴充條件下正確率均超過85%。對比4種不同模型在有、無樣本擴充條件下的識別正確率,可得IDANN在有樣本擴充條件下正確率最高,超過90%。
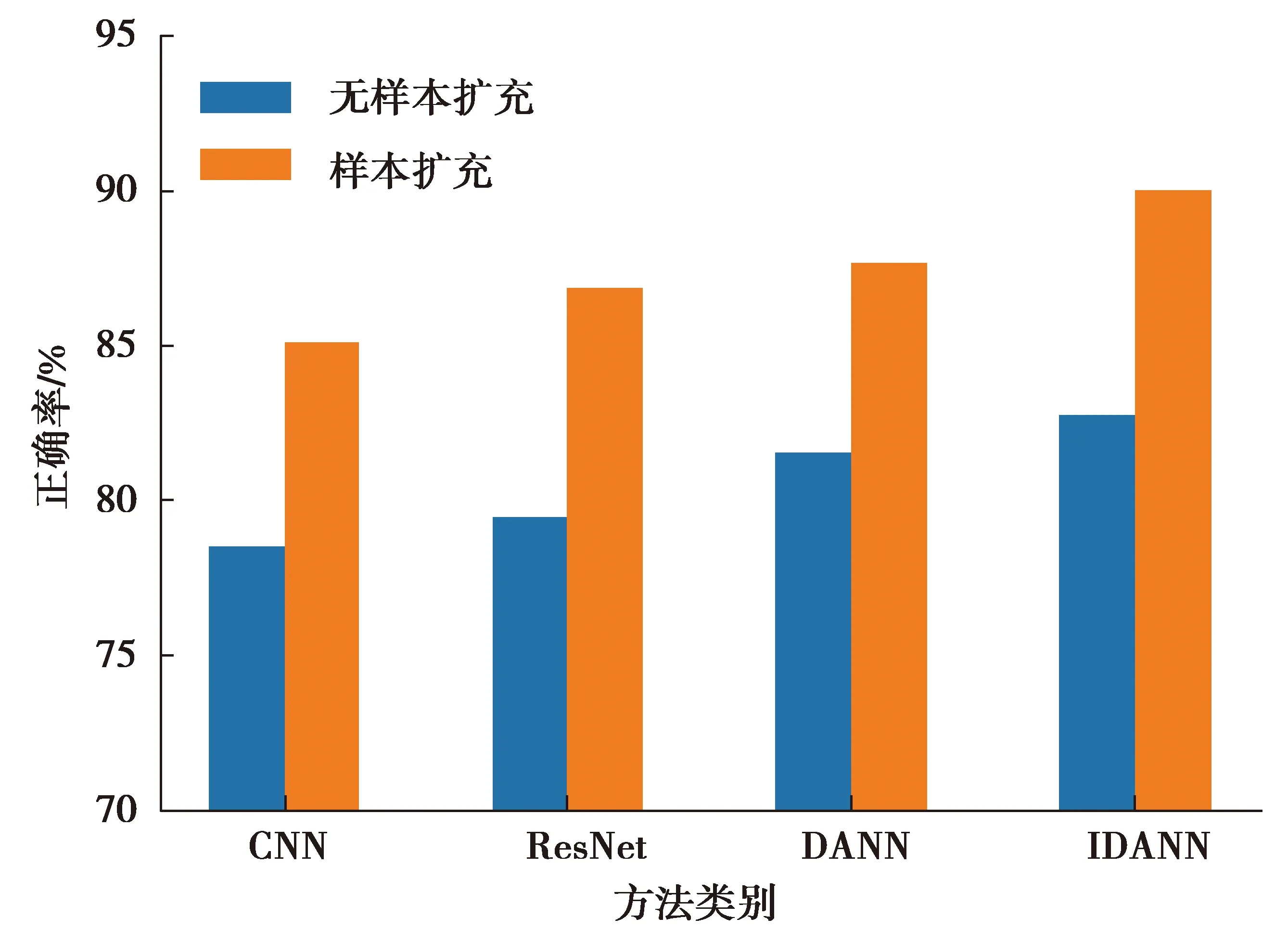
圖11 NASA Milling Data Set試驗識別正確率
7 結 論
本研究中結合原始數據特征,通過二次特征提取和Smote算法進行樣本擴充,將Wasserstein距離作為源域目標域分布相似性標準引入模型,模型特征提取器中加入殘差結構,在防止梯度爆炸的前提下加深網絡,以提高目標刀具磨損識別準確率。結合傳統深度學習模型與遷移學習模型進行了交叉對比驗證。結果證明,在跨刀具磨損狀態識別任務中,當目標域數據較少時,基于樣本擴充與IDANN的遷移學習方法對刀具狀態識別具有一定效果。
將該方法應用到其它數據集上實現了方法的遷移,結果證明該方法在其他數據集上同樣有效,實現了SE-IDANN在刀具磨損狀態識別領域的應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
光學精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
