基于輕量化YOLOv4的交通信息實時檢測方法
2023-02-03 03:01:32郭克友
計算機應用 2023年1期
郭克友,李 雪,楊 民
(北京工商大學 人工智能學院,北京 100048)
0 引言
隨著相關技術的發展,人們對交通監控系統的需求不斷增加,安全輔助駕駛系統的技術也逐漸走進大眾的視野。車輛目標檢測是安全輔助駕駛領域極具挑戰的問題,該領域主要分為傳統目標檢測算法和基于深度學習的檢測算法。
傳統目標檢測方法主要分為三類:以高斯混合模型(Mixture Of Gaussians,MOG)[1]、MOG2[2]和幾何多重網格(Geometric MultiGid,GMG)[3]為代表的背景差分法;以兩幀差法[4]、三幀差法[5]為代表的幀差分法;以及利用相鄰兩幀中對應的灰度保持不變原理評估二維圖像變化的光流場法[6]。然而,傳統目標檢測算法存在魯棒性差、適應性弱等缺陷[7]。
近年來,深度學習技術在目標檢測等任務中取得了巨大的成就。基于深度學習的目標檢測主要分為兩大類[8]:1)基于區域建議的方法,這類算法的典型代表是R-CNN(Region Convolutional Neural Network)[9]、SPP-net(Spatial Pyramid Pooling network)[10]、Fast R-CNN[11]、Faster R-CNN[12]等;2)基于無區域建議的方法,這類方法主要采用回歸的思想,比較典型的算法如YOLO(You Only Look Once)、SSD(Single Shot multi-box Detector)[13]。基于區域建議的方法精度高但速度慢,訓練時間較長;基于無區域建議的方法準確度低,對小物體的檢測效果較差,但速度快。
目前,應用最廣泛的是YOLO 系列檢測算法。YOLOv1[14]的檢測速度非常快,遷移能力強,但是對很小的群體檢測效果不好;YOLOv2[15]經多種改進方法后,檢測速度得到大幅提升,但檢測精度提升效果并不明顯;YOLOv3[16]中提供了Darknet-53 以及輕量級的Tiny-Darknet 骨干網絡,使用者可根據需求選擇不同的骨干網絡,其靈活性使得它在實際的工程中受到了大家的青睞;YOLOv4[17]在傳統YOLO 的基礎上添加了許多實用技巧,實現了檢測速度和檢測精度的最佳權衡;YOLOv5 在性能上略弱于YOLOv4,但在靈活性以及速度上都遠優于YOLOv4。
為應對復雜路況下車輛多目標實時檢測的挑戰,本文選擇檢測精度和檢測速度較為平衡的YOLOv4 作為研究對象。為進一步提高模型的檢測精度,并且使其能夠部署在移動端,提出一種輕量化的YOLOv4 交通信息實時檢測方法。由于現有的大型公開數據集對道路復雜場景的適用性不強,本文針對真實交通場景構建了與之對應的數據集,并在測試前對數據集進行K-means++[18]聚類處理;除此之外,為提高檢測性能,對YOLOv4 網絡進行修改,大幅提高車輛目標的檢測速率。
1 改進的YOLOv4
YOLOv4 網絡模型結構如圖1 所示,它保留了YOLOv3 的Head 部分,將主干網絡修改為CSPDarkent53(Cross Stage Partial Darknet53),同時采用空間金字塔池化(Spatial Pyramid Pooling,SSP)擴大感受野,PANet(Path Aggregation Network)作為Neck 部分,并使用了多種訓練技巧,對激活函數和損失函數進行了優化,使YOLOv4 在檢測精度和檢測的速度方面均有所提升[19-20]。

圖1 YOLOv4網絡結構Fig.1 Network structure of YOLOv4
CSPDarknet 作為YOLOv4 算法的主干網絡,經特征融合后,輸出層的尺寸分別變為輸入尺寸的1/8、1/16、1/32。CSPDarknet53 將原有的Darkent53 中的殘差塊改為CSP 網絡結構。CSP-DarkNet 在每組Residual block 加上一個Cross Stage Partial 結構;并且,CSP-DarkNet 中還取消了Bottleneck的結構,減少了參數使其更容易訓練。
SPP 以及PANet 將主干網絡提取的特征圖進行融合,SPP對全連接層前的卷積層進行不同池化大小的池化,然后拼接,由此增加網絡感受野。PANet提出了一種bottom-up的信息傳播路徑增強方式,通過對特征的反復提取實現了了不同特征圖之間的特征交互。PANet 可以準確地保存空間信息,有助于正確定位像素點,增強實例分割的過程。
最后,YOLOv4 Head 進行大小為3×3 和1×1 兩次卷積,對特征層的3 個先驗框進行目標及目標種類的判別,并進行非極大抑制處理和先驗框調整,最后得到預測框。
為了進一步提高模型的檢測速率,減少模型的參數量,本文對YOLOv4 檢測算法做如下改進:由MobileNet-v3 構成主干特征提取模塊,經過特征提取后可以得到52×52、26×26、13×13 共3 個尺度的特征層,減少模型參數量;使用帶泄露修正線性單元(Leaky Rectified Linear Unit,LeakyReLU)激活函數代替MobileNet-v3 淺層網絡中的ReLU 激活函數,提高檢測精度;利用深度卷積網絡代替傳統卷積網絡。下面對網絡結構的設計和參數設置進行闡述。
1.1 主干特征提取網絡
2019 年,Google 公司在MobileNet 的基礎上提出了MobileNet-v3 網絡,在保持輕量化的同時,MobileNet-v3 模型進行了部分優化,經優化后的MobileNet 模型衍生出MobileNet-v3-Large 和MobileNet-v3-Small 兩個版本。在ILSVRC(ImageNet Large Scale Visual Recognition Challenge)分類任務中:MobileNet-v3-Large 的準確率與檢測速度相較于MobileNet-v2 模型分別提高了3.2% 和15%,MobileNetv3-Small 模型相較于MobileNet-v2 模型則分別提高了4.6%和5%;在COCO 數據集的檢測過程中,在滿足精度的同時,與使用MobileNet-v2 模型相比,MoboileNet-v3-Large 的檢測速率提升了25%[21]。MobileNet-v3 的整體結構如圖2 所示。

圖2 MobileNet-v3結構Fig.2 Structure of MobileNet-v3
MobileNet-v3 在核心構架中引入了名為Squeeze-and-Excitation 的神經網絡(SeNet),該網絡的核心思想是通過顯式建模網絡卷積特征通道之間的相互依賴關系來提高網絡的質量,即通過學習來自動獲取每個特征通道的重要程度,并以此為依據提升有用的特征,抑制用處較小的特征。本文將MobileNet-v3 代替傳統YOLOv4 的主干的網絡,以減少參數量,使模型更加輕量化。
1.2 深度可分離卷積
在深度可分離卷積出現之前,神經網絡基本由不同尺度的卷積核堆疊而成,伴隨技術的發展,人們對網絡模型的精度要求不斷提高[22]。面對不斷增加的深度核模型參數量,為了在保證模型精度的情況減少參數量,2017 年谷歌公司提出了基于深度可分離卷積的MobileNet[23],隨后提出了MobileNet-v2[24]、MobileNet-v3[25]系列網絡。
MobileNet-v3 使用深度可分離卷積代替標準卷積塊,深度可分離卷積(DepthWise Conv)由深度卷積和逐點卷積(PointWise Conv)組成,由此可大幅減少模型的理論參數(Params)和每秒峰值速度(FLoating-point Operations Per Second,FLOPs)。
設輸入數據為M×M×N,卷積核大小為K×K×P,設置步長為1,標準卷積操作利用卷積內核提取特征,隨后將特征進行組合產生新的表示效果[26]。如圖3(a)所示,此時,標準卷積的參數量為:

計算量為:

深度可分離卷積是將提取特征和結合特征分為深度卷積和逐點卷積兩步,如圖3(b)所示:在深度卷積過程中,主要對每一個輸入通道進行一個卷積核的操作,然后利用1 ×1 的卷積將深度卷積的輸出結果結合到特征中;隨后通過1 × 1 卷積計算深度卷積的輸出線性特征組合為新的特征。深度卷積和1 × 1 卷積(逐點卷積)組成了深度可分離卷積[27],其參數量為:
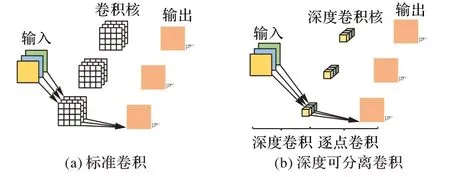
圖3 標準卷積與深度可分離卷積Fig.3 Standard convolution and depth separable convolution

計算量為:

兩種卷積對應參數比為:

通過對比可知,深度可分離卷積與標準卷積相比更加高效,故本文用深度可分離卷積代替原始YOLOv4 網絡中的標準卷積,以提高檢測效率。
1.3 損失函數
MobileNet-v3 淺層部分利用線性整流單元(Rectified Linear Unit,ReLU)作為激活函數,該函數主要分為兩部分:在小于0 的部分,激活函數輸出為0;在大于0 的部分,激活函數的輸出為輸入,計算方法如式(7)。

該函數的收斂速度快,不存在飽和區間,在大于0 的部分梯度固定為1,能有效解決Sigmoid 中存在的梯度消失問題;但是當一個巨大的梯度經過ReLU 神經元時,ReLU 函數將不具有激活功能,產生“Dead Neuron”現象。
為避免“Dead Neuron”現象發生,本文中MobileNet-v3 特征提取網絡采用帶泄露修正線性單元(Leaky Rectified Linear Unit,LeakyReLU)代替傳統的ReLU 函數,該函數可有效地避免上述現象發生。其計算方式如下:

實際中,LeakyReLU 的α取值一般是0.01。在使用過程中,對于LeakyReLU 激活函數輸入小于零的部分,也可以計算得到梯度,而不是像ReLU 一樣值為0,由此可避免ReLU函數存在的梯度方向鋸齒問題。
2 數據集構建
2.1 數據集的制作
本實驗采用的數據集由搭載HP-F515 行車記錄儀的實驗平臺在北京市內真實道路場景下進行采集,包括城市主干道、橋梁公路、信號岔口等。采集流程為:為模擬駕駛員真實駕駛情況,將行車記錄儀搭載于后視鏡處,行車路線全長11 km,行駛時間分別為15:00—17:00 和19:00—21:00,該時間段內,測試路線車流量較大,存在部分擁堵路段。
對錄制的視頻進行分幀,設置大小為1 920×1 080,并依據正常公路場景下的車輛目標類型將車輛目標分為3 種,分別是大型車(large vehicle)、中型車(medium)和小型車(compact car)。實驗共計12 614 張圖片,并將標簽分別設置為2、3、4,具體情況如表1 所示。

表1 三種目標及其標簽Tab.1 Three types of objects and their labels
2.2 性能測評指標
目標檢測中,常通過準確率P(Precision)、召回率R(Recall),計算平均精度(Average Precision,AP),平均精度均值(mean Average Precision,mAP)作為目標檢測的評價指標,如式(9)~(11)所示:

其中:TP為檢測正確的目標數量;FP為檢測錯誤的目標數量;FN表示漏檢數量表示所有缺陷類別的AP 值總和;Nclass表示缺陷總類別數。
本文另選檢測速度作為模型性能的評價指標之一,利用每秒可處理圖像幀數量(Frames Per Second,FPS)作為檢測速度的評價指標。FPS 計算公式如下:

其中:Numfigure表述樣本檢測數量;TIME表示檢測耗費的時間。
2.3 錨框優化
K-means 算法隨機產生聚類中心,使得每次聚類效果不盡相同,進而影響模型的檢測效果。為解決初始聚類中心不斷變化等問題,本文采用K-means++算法進行先驗框的計算。設本文數據集內包含N個樣本,數據集表示為α={xi|xi=(xi1,xi2,xi3,L,xim),i=1,2,…,N},取集合α中k個數據作為初始的聚類中心點P={pj|pj=(pj1,pj2,pj3,L,pjm),j=1,2,…,k}。通過式(13)可得樣本點xi到質心pj在m維空間的歐氏距離d,隨后依據式(14)遍歷每個樣本數據被選為下一個聚類中心的概率C[28]。

重復上述步驟,直到選出k個聚類中心。分別計算樣本點數據xi到k個聚類中心的歐氏距離d,按照鄰近原則將樣本點歸類到距離其最近的聚類中心簇中,取聚類中心簇內的樣本點,計算均值用來表示聚類中心,經過迭代,計算誤差平方和,直到ISSE取最小值。其中ISSE又稱為畸變程度,ISSE越小,表明畸變程度越低,簇內樣本點的關系越緊密。畸變程度會根據類別的增加而降低。

Si為樣本點xi的輪廓系數,b(xi)是xi到聚類中心簇的平均距離,a(xi)是b(xi)中的最小值。

St是樣本點輪廓系數的平均值,它反映了聚類的密集度和離散度,由式(17)可知,St介于0~1,St越大,表明類內樣本的密集度越高,各類樣本的離散度越高,聚類效果越好。
K-Means++算法通過輪廓系數和ISSE的值得出分類效果最好的最佳簇類數量。對自制數據集重新聚類后得到9 組先驗框為(50.84,43.92),(90.80,61.82),(26,87.25),(24.26,49.68),(51.35,189.15),(81.4,57.78),(38.16,38.13),(19.64,21.95),(90.7,124.8)。
3 實驗與結果分析
3.1 實驗環境配置
硬件配置為Intel Core i7-7700CPU @3.60 GHz,內存為16 GB,GPU 為NVIDIA GeForce GTX1080Ti,深度學習框架為Pytorch1.2.0 版本;CUDA 版本為11.3;Python 版本為3.8.10。
本實驗基于Pytorch 深度學習框架,數據集基于第2 章的數據預處理,訓練過程為350 epoch,前50個epoch利用凍結網絡方式進行訓練,學習率為0.001;之后的300個epoch學習率為0.000 1,訓練過程采用了退火余弦算法以及標簽平滑。
3.2 改進模型有效性評價
為驗證改進方法對YOLOv4 模型的性能影響,對上述4種改進方法進行消融實驗,結果如表2 所示。其中:“√”表示在網絡實驗中使用了該改進策略,“—”表示未使用該策略。由表2 可知,將主干網絡替換為MobileNet-v3 后,權值文件大小由161 MB 變為了53.7 MB;通過利用深度可分離卷積代替原始YOLOv4 網絡中的標準卷積,大幅減少了網絡結構中的參數量;輕量化后的模型與原模型相比,本文所提出輕量YOLOv4 算法的mAP 下降并不明顯,仍可以保持較好的性能。

表2 消融實驗結果對比Tab.2 Comparison of ablation experimental results
3.3 性能評價
AP、Recall、Precision 和F1 結果如表3 所示。YOLOv4 算法獲得了90.64%的準確率均值,91.6%的召回率均值,91.33%的F1 均值;輕量化的YOLOv4 算法獲得了92.9%準確率均值,90.71%的召回率均值,92%的F1 均值。

表3 輕量化YOLOv4與其他YOLO算法對比Tab.3 Comparison of lightweight YOLOv4 and other YOLO algorithms
mAP 與FPS 結果如表4 所示,可以看出,當輸入分辨率一致時,輕量化的YOLOv4 檢測算法在實時性上有所上升,雖然mAP 下降了0.76 個百分點,但是檢測速率提升了79%,不僅可以減少誤檢、漏檢還能保證檢測精度,提高檢測速度。

表4 網絡模型檢測速度及均值平均精度對比Tab.4 Comparison of detection speed and mAP
本文使用MobileNet-v3 和深度可分離卷積代替YOLOv4的主干網絡和標準卷積使計算量下降到1.1 × 107,檢測速度由原始47.74 FPS 升高至85.60 FPS。從以上分析可知,輕量化的YOLOv4 檢測算法相較于YOLOv4 檢測算法在保證檢測精度的同時,提高了檢測效率;但與同樣為輕量化系列的Tiny YOLOv4 以及YOLOx 相比在檢測速度方面仍有較大差距。
3.4 效果測試
為了進一步直觀地展示本文算法的有效性,圖4、5 展示了原始YOLO 系列檢測算法和輕量化的YOLOv4 檢測算法在車輛目標數據集的檢測結果。
圖4 是道路情況較為簡單(道路中的車輛不存在遮擋情況)時的檢測結果,可以看出三類檢測器對車輛目標的檢測效果均良好:當道路中出現較多車輛,且車輛間不存在大量重疊和遮擋的情況下,檢測器的檢測效果相當,均可檢測出道路中的中型車以及小型車;當道路中出現不完整車輛目標、遮擋目標和小目標時,原始YOLOv4 檢測模型、Tiny YOLOv4 以及YOLOx模型對遠處目標的檢測效果比輕量化YOLOv4略差。

圖4 不存在重疊目標時的檢測結果對比Fig.4 Comparison of detection results without overlapping targets
存在重疊目標時的檢測結果如圖5 所示。通過圖5 的對比,面對道路車輛較多,且存在明顯遮擋現象的情況:原始YOLOv4 檢測算法可以檢測出1 個大型車,無法識別遠處的車輛小目標;Tiny YOLOv4 無法檢測出遠處車輛小目標;輕量化的YOLOv4檢測算法共測出2個車輛目標,包含遠處的小目標車輛;YOLOx檢測器也可檢測出2個車輛目標,但其檢測精確度不如輕量化的YOLOv4。當車輛目標數量增多,但車輛之間的重疊情況較少時,遠處的小目標可以在輕量化的YOLOv4 檢測模型中被測得,但是原始YOLOv4、Tiny YOLOv4以及YOLOx 都存在遠處的重疊目標的漏檢現象,其中Tiny YOLOv4檢測器漏檢情況較原始YOLOv4檢測器較為嚴重;當道路中出現柵欄等遮擋物且車輛目標較多的情況下,原始YOLOv4 檢測器檢測出了2 個車輛小目標,Tiny YOLOv4 檢測器僅檢測出1 個車輛小目標,YOLOx 檢測出了3 個車輛目標,面對遮擋目標存在一定的漏檢情況,輕量化的YOLOv4 檢測器檢測出了3個近處目標以及1個遠處小目標。

圖5 存在重疊目標時的檢測結果對比Fig.5 Comparison of detection results with overlapping targets
為了對比三種模型算法針對不完整目標和小目標的檢測能力,選擇100 張含有大量重疊車輛目標以及小目標的圖片作為測試數據集,其檢測性能的對比如表5 所示,通過對比Recall、AP、F1 和Precision 值可看出,輕量化的YOLOv4 算法效果好于原始YOLOv4 和Tiny YOLOv4,略差于YOLOx。
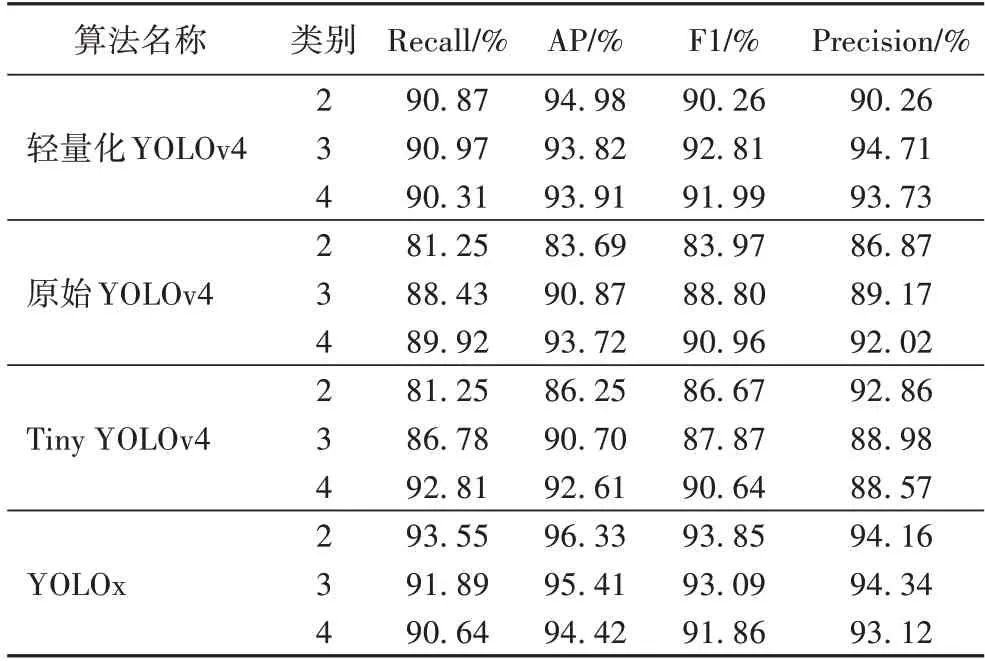
表5 針對不完整目標和小目標的檢測效果對比Tab.5 Detection results comparison for incomplete targets and small targets
綜合上述分析可知,輕量化的 YOLOv4 模型和其他模型都可以準確識別出近處的未被遮擋的完整目標,但是在部分復雜路況下:原始YOLOv4 無法識別出近處的被遮擋目標;Tiny YOLOv4 對近處的不完整目標存在一定的漏檢,對于不完整的目標、重疊目標以及遠處的小目標的漏檢情況較為嚴重;YOLOx 面對遠處遮擋小目標存在一定的漏檢現象;但輕量化的YOLOv4 算法能準確地識別出不完整目標、重疊目標以及遠處的小目標。
4 結語
本文提出了一種輕量化的YOLOv4 交通信息實時檢測算法,為模擬真實道路路況信息,利用行車記錄儀錄制不同時段的北京道路場景信息并制作相應數據集,隨后利用K-Means++算法對錨框進行聚類。使用MobileNet-v3 網絡代替YOLOv4 主干網絡,并將MobileNet-v3 網絡中的淺層激活函數替換為LeakyReLU 激活函數,最后將YOLOv4 中的標準卷積替換為深度可分離卷積降低運算量。實驗結果表明:輕量化的YOLOv4 檢測算法與原始YOLOv4 檢測算法相比,在檢測速率為85.6 FPS 時,mAP 值為94.24%,本文模型可以為原始YOLOv4 檢測算法進行針對復雜場景下的重疊目標、不完整目標和小目標提供輔助檢測;但本模型仍有改進空間,如何提高檢測速率,并使用與更豐富的檢測場景是接下來待解決的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
