自適應(yīng)置信度閾值的非限制場景車牌檢測算法
2023-02-03 03:01:30劉小宇陳懷新劉壁源
計算機(jī)應(yīng)用 2023年1期
劉小宇,陳懷新*,劉壁源,林 英,馬 騰
(1.電子科技大學(xué) 資源與環(huán)境學(xué)院,成都 611731;2.成都天奧信息科技有限公司,成都 611731)
0 引言
近年來,世界各國都在積極引導(dǎo)和支持智慧城市的建設(shè),智慧交通作為智慧城市的重要組成部分,得到了大量關(guān)注與發(fā)展,出現(xiàn)了諸多如自動駕駛、電子收費、停車場門禁控制、交通監(jiān)控與執(zhí)法等技術(shù)與應(yīng)用場景的結(jié)合。在這些應(yīng)用的實現(xiàn)中,車牌作為車輛的唯一身份標(biāo)識,對其進(jìn)行檢測是首要解決的問題。但智慧交通中的車牌檢測應(yīng)用場景由于自然天氣與環(huán)境光照、拍攝設(shè)備選擇與架設(shè),以及車輛位置與駕駛速度等因素影響,拍攝圖像具有不同背景、不同分辨率、不同拍攝角度、不同車牌尺度以及不同清晰程度等特點,如何使車牌檢測模型在不同工程應(yīng)用場景中適用于以上非限制條件,仍是一個有待研究的問題。
目前,大多數(shù)車牌檢測方法在Faster R-CNN(Faster Region-Conventional Neural Network)[1]、SSD(Single Shot MultiBox Detector)[2]、YOLO(You Only Look Once)系列[3-4]等錨框類目標(biāo)檢測方法基礎(chǔ)上針對單一場景的條件特點進(jìn)行了改進(jìn),并在特定數(shù)據(jù)集上取得了良好的檢測性能。如:艾曼[5]選用以ResNet101[6]作為主干的Faster R-CNN 作為車牌檢測方法,其首先使用基于錨框機(jī)制的區(qū)域建議網(wǎng)絡(luò)(Region Proposal Network,RPN)生成適配實驗數(shù)據(jù)集的車牌建議區(qū)域,再通過Fast RCNN(Fast Region-Conventional Neural Network)[7]對建議區(qū)域進(jìn)行對車牌的分類回歸;何穎剛等[8]選擇SSD 作為車牌檢測方法,在多尺度特征圖上基于多尺寸錨框進(jìn)行車牌分類回歸。吳仁彪等[9]針對民用民航車牌數(shù)據(jù)集中車牌目標(biāo)尺寸較大的情況,選擇YOLOv3[4]作為車牌檢測方法并改進(jìn)。首先使用層次聚類方法得到適配數(shù)據(jù)集的錨框數(shù)量和初始簇中心,更改YOLOv3 的錨框參數(shù);然后移除網(wǎng)絡(luò)對小目標(biāo)的檢測模塊,提高檢測速度。馬巧梅等[10]針對中國城市停車場數(shù)據(jù)集(Chinese City Parking Dataset,CCPD)[11]等復(fù)雜環(huán)境數(shù)據(jù)集,同樣選擇YOLOv3 作為車牌檢測方法并改進(jìn)。首先使用多尺度(Multi-Scale Retinex,MSR)算法[12]對圖像進(jìn)行數(shù)據(jù)增強預(yù)處理,降低環(huán)境噪聲干擾;然后根據(jù)K-means++算法[13]為數(shù)據(jù)集選取適配錨框尺寸,并增加對大尺度特征圖的融合與檢測,提升小目標(biāo)檢測精度。但上述錨框類方法訓(xùn)練得到的網(wǎng)絡(luò)模型泛化性較差,均需針對實際數(shù)據(jù)集設(shè)置適配的錨框參數(shù),甚至改進(jìn)了多尺度融合機(jī)制,增加或減少對某種尺寸目標(biāo)的檢測,使其難以直接復(fù)用在限制條件不同的真實應(yīng)用場景中。
為此,本文構(gòu)建了一種適用于非限制場景下非限制條件的車牌檢測深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN)模型架構(gòu),主要工作如下:1)在傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)目標(biāo)檢測模型的基礎(chǔ)上,使用圖像語義分割預(yù)測頭,實現(xiàn)無錨框檢測方式,避免錨框檢測算法的尺寸適配問題,復(fù)用簡單;2)使用邊框回歸預(yù)測頭,提高模型泛化性能;3)使用自適應(yīng)置信度閾值預(yù)測頭,減少漏檢與誤檢情況,提高模型檢測精度;4)在網(wǎng)絡(luò)模型訓(xùn)練中設(shè)計可微分二值變換聯(lián)合學(xué)習(xí)置信度與置信度閾值,優(yōu)化分割結(jié)果,提高模型檢測精度;5)考慮到智慧交通存在移動平臺端的存儲要求與實時處理要求,本文在網(wǎng)絡(luò)模型部分使用輕量級神經(jīng)網(wǎng)絡(luò)作為模型的特征提取骨干,減少網(wǎng)絡(luò)參數(shù)量,使其可以在移動平臺部署,并提高網(wǎng)絡(luò)檢測速度;然后,提出連通感知非極大值抑制(Connectivity Aware Non-Maximum Suppression,CANMS),減少頂點還原數(shù)量與交并比(Intersection over Union,IoU)計算次數(shù),提高后處理效率。
實驗結(jié)果表明,本文所提方法在非限制場景的非限制條件下均能獲得優(yōu)異的檢測結(jié)果,泛化性強,而且不必考慮錨框與目標(biāo)尺寸適配問題,模型復(fù)用簡單,處理速度快,具有工程應(yīng)用前景。
1 非限制場景車牌檢測方法
針對智慧交通的應(yīng)用場景,本文提出了一種基于自適應(yīng)置信度閾值的非限制場景車牌檢測(Unrestricted Scene License Plate Detection,USLPD)方法,從模型構(gòu)建與網(wǎng)絡(luò)參數(shù)優(yōu)化來提高車牌檢測泛化能力;從選取輕量級骨干網(wǎng)絡(luò)與改進(jìn)非極大值抑制(Non-Maximum Suppression,NMS)后處理方法來提高車牌檢測速度,考慮實際應(yīng)用中的移動平臺部署。
1.1 USLPD模型構(gòu)架
本文提出的車牌檢測網(wǎng)絡(luò)模型構(gòu)架如圖1 所示。首先,使用輕量級骨干網(wǎng)絡(luò)提取圖像特征,然后根據(jù)U-shape[14]的思想完成高低層特征{C1,C2,C3,C4}的多尺度融合,最后在下采樣4 倍的融合特征圖P上密集預(yù)測分類置信度S(score map)與自適應(yīng)分類置信度閾值T(threshold map),同時回歸旋轉(zhuǎn)候選邊界框的幾何信息G(geometry map)。其中,置信度分?jǐn)?shù)圖與自適應(yīng)置信度閾值圖經(jīng)過二值變換得到圖像的車牌二值分割圖B(binary map)。
1.1.1 目標(biāo)特征提取骨干網(wǎng)絡(luò)
在特征提取方面,本文考慮了三種當(dāng)前比較流行的輕量級網(wǎng)絡(luò):基于殘差網(wǎng)絡(luò)的ResNet18[6]、基于深度可分離卷積的MobileNetV3[15],以及結(jié)合CNN 與ViT(Vision Transformer)[16]優(yōu)勢的MobileViT[17],其中,深度殘差網(wǎng)絡(luò)(Deep Residual Network,ResNet)是目前應(yīng)用最廣泛的CNN 特征提取網(wǎng)絡(luò),獲得了ImageNet 分類任務(wù)精度第一名。它引入殘差學(xué)習(xí)單元,提高信息流通,避免因網(wǎng)絡(luò)過深引起的梯度消失問題與退化問題,加速網(wǎng)絡(luò)收斂,提升了圖像分類水平。
本文通過實驗研究的效果分析及技術(shù)指標(biāo)對比,選取ResNet18 網(wǎng)絡(luò)作為模型特征提取骨干,最適用于車牌檢測應(yīng)用場景。
1.1.2 自適應(yīng)置信度閾值分割回歸預(yù)測頭
本文對基于錨框的車牌檢測算法(如Faster R-CNN、YOLO 系列[3-4]等)進(jìn)行分析,該類算法需要提前根據(jù)不同場景預(yù)設(shè)貼合目標(biāo)尺寸的錨框,并用實際數(shù)據(jù)對網(wǎng)絡(luò)參數(shù)進(jìn)行微調(diào),否則易出現(xiàn)模型檢測精度下降等問題,對場景遷移不夠友好,泛化性較差;而若在模型訓(xùn)練時設(shè)置多種錨框尺寸,又會帶來冗余計算的問題。
對此,本文采用分割與回歸相結(jié)合的無錨框檢測方式,如圖1 所示,在輸出層中,使用1×1 卷積對融合層輸出的多尺度特征圖P進(jìn)行密集預(yù)測,得到置信度分?jǐn)?shù)圖(score map)、候選邊界框幾何信息圖(geometry map)以及自適應(yīng)置信度閾值圖(threshold map),它們的作用如圖2 所示,其中DB 表示可微分二值化(Differentiable Binarization,DB),C 表 示Concat。

圖1 USLPD網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 Network structure of USLPD

圖2 USLPD預(yù)測頭設(shè)計Fig.2 Prediction head design of USLPD
圖2 中,score map 是對輸入圖像下采樣4 倍的語義分割結(jié)果,每個像素點的值代表其屬于車牌類別的置信度。基于分割的方法可以避免使用錨框,但需要復(fù)雜的后處理來將像素預(yù)測結(jié)果分組到檢測的車牌實例中,導(dǎo)致推理過程中帶來較大的時間成本,并且對目標(biāo)尺度的魯棒性有限,無法完整檢測出大尺度目標(biāo)。
因此,在USLPD 的預(yù)測頭中通過geometry map 加入了對候選邊界框的幾何信息回歸預(yù)測。geometry map 共包含5 個通道,分別代表對應(yīng)像素點(x,y)到基于該點預(yù)測的車牌邊界框的四邊界距離(d1,d2,d3,d4)與旋轉(zhuǎn)角度θ,如圖3 所示。geometry map 中的值均是假設(shè)像素點在車牌內(nèi)部預(yù)測得到,而后經(jīng)過式(1)變換,得到候選車牌邊界框的頂點坐標(biāo)

圖3 邊框回歸的幾何信息Fig.3 Geometric information of bounding box regression

在score map 與geometry map 的預(yù)測結(jié)果中,無論是基于分割的目標(biāo)檢測方法還是基于回歸的目標(biāo)檢測方法,均需根據(jù)置信度閾值過濾低置信度的像素點與候選邊界框,保留高置信度的預(yù)測結(jié)果。在傳統(tǒng)方法中,置信度閾值往往是根據(jù)經(jīng)驗預(yù)設(shè)的一個固定值,但這會導(dǎo)致出現(xiàn)車牌邊緣部分因為特征不明顯、置信度較低而被漏檢的情況,以及干擾目標(biāo)因為相似的文本特征、置信度較高而被誤檢的情況。
因此,本文在預(yù)測頭部分加入了threshold map,在預(yù)測置信度的同時,使用同一特征生成匹配的置信度閾值,改善固定閾值造成的誤檢與漏檢情況,提高分割精度。
1.2 可微分二值網(wǎng)絡(luò)模型訓(xùn)練
本文使用監(jiān)督學(xué)習(xí)的方法訓(xùn)練車牌檢測模型USLPD。對于邊框回歸預(yù)測信息,使用圖3 所示的標(biāo)簽信息與IoU 損失進(jìn)行學(xué)習(xí)。對于分類信息的預(yù)測,不同于以往的監(jiān)督學(xué)習(xí)方法(每張預(yù)測圖都擁有對應(yīng)的監(jiān)督標(biāo)簽),考慮了置信度分?jǐn)?shù)圖與置信度閾值圖之間的緊密聯(lián)系,將二值變換加入訓(xùn)練過程,結(jié)合置信度與閾值得到二值圖,然后與最終的車牌分割監(jiān)督標(biāo)簽協(xié)同計算二分類Dice 損失,聯(lián)合學(xué)習(xí)置信度與閾值。
標(biāo)準(zhǔn)的二值變換如式(2)所示,不可微,無法通過反向傳播學(xué)習(xí)網(wǎng)絡(luò)參數(shù),因此,采用行為類似于標(biāo)準(zhǔn)二值變換的近似階躍函數(shù)來替代標(biāo)準(zhǔn)二值變換,使其能夠在訓(xùn)練階段隨網(wǎng)絡(luò)進(jìn)行優(yōu)化,如式(3)所示:

其中:Bi,j為二值圖B中第i行、第j列的元素;Si,j為置信度分?jǐn)?shù)圖S中第i行、第j列的元素,t為預(yù)設(shè)的固定閾值。

同時,為了加速網(wǎng)絡(luò)的學(xué)習(xí),使用相同的二值監(jiān)督標(biāo)簽與Dice 損失對分?jǐn)?shù)圖進(jìn)行學(xué)習(xí)。
本文構(gòu)建的網(wǎng)絡(luò)模型損失函數(shù)L由分類部分的損失LC與幾何信息部分的損失LG組成,如式(4)所示:

其中:分類部分的損失LC為置信度分?jǐn)?shù)圖(score map)的損失Ls和近似二值圖(appriximate binary map)的損失Lb之和,如式(5)所示;Ls與Lb均采用二分類Dice 損失,如式(6)所示:
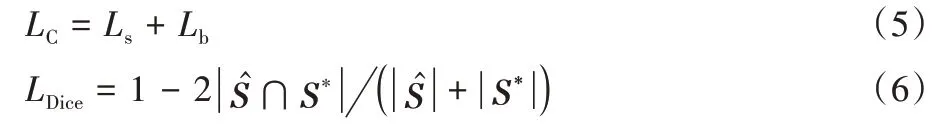
其中:為分?jǐn)?shù)圖或近似二值圖的預(yù)測值;S*為二者的監(jiān)督標(biāo)簽值。
另一方面,幾何損失LG由旋轉(zhuǎn)矩形框中軸對齊邊界框(Axis Aligned Bounding Box,AABB)部分的IoU 損失LAABB和旋轉(zhuǎn)角度損失Lθ組成,如式(7)~(8):

1.3 基于CANMS的車牌區(qū)域檢測后處理
根據(jù)分割回歸預(yù)測機(jī)制的特性可知,在分割圖上,預(yù)測同一車牌目標(biāo)的像素點鄰接,不同車牌的像素點分離,并且邊框回歸的預(yù)測圖(geometry map)與二值分割圖(binary map)像素點一一對應(yīng)。因此,本文對NMS 進(jìn)行改進(jìn),提出CANMS 的后處理方法。
CANMS 首先利用網(wǎng)絡(luò)輸出的置信度分?jǐn)?shù)圖(score map)與置信度閾值圖(threshold map)做標(biāo)準(zhǔn)二值變換,得到二值分割圖(binary map);然后,在分割圖(binary map)上使用牛連強等[18]提出的方法快速求得連通區(qū)域,并根據(jù)置信度對同一個連通區(qū)域內(nèi)像素點所對應(yīng)的幾何信息進(jìn)行加權(quán)融合,得到該連通區(qū)域所對應(yīng)的候選邊界框幾何信息,并使用式(1)進(jìn)行頂點坐標(biāo)還原;最后,針對少數(shù)同一車牌存在多個連通區(qū)域的情況,繼續(xù)使用局部感知非極大值抑制(Locality-Aware NMS,LANMS)[19]融合篩選連通區(qū)域候選邊界框,得到最終檢測結(jié)果。
CANMS 可以大幅減少密集預(yù)測中的頂點還原數(shù)量與NMS 中的IoU 計算次數(shù),提高車牌區(qū)域檢測的后處理速度。
2 實驗與結(jié)果分析
本實驗硬件配置為Intel Xeon E5-2620 處理器,64 GB 內(nèi)存,NVIDIA TITAN RTX 顯卡。軟件運行環(huán)境為64 位Ubuntu 18.04 操作系統(tǒng)下搭建的PyTorch1.7 深度學(xué)習(xí)框架。
本文從CCPD 數(shù)據(jù)集中選取6 000 張圖片作為訓(xùn)練數(shù)據(jù)集,對模型進(jìn)行端到端訓(xùn)練,整個訓(xùn)練過程使用Adam 優(yōu)化器對損失函數(shù)做優(yōu)化,完成100 輪訓(xùn)練。初始學(xué)習(xí)率為0.001,權(quán)重衰減率為0.1,批量大小為24,在網(wǎng)絡(luò)進(jìn)行50 輪訓(xùn)練后,學(xué)習(xí)率設(shè)為0.000 1。當(dāng)模型訓(xùn)練至79 輪時,精度達(dá)到最佳。
2.1 數(shù)據(jù)集
為驗證非限制場景車牌檢測算法USLPD 的檢測性能,本文選用了4 個數(shù)據(jù)集:公共數(shù)據(jù)集CCPD[11]、能源車綠色車牌數(shù)據(jù)集、實采停車場場景數(shù)據(jù)集與實采天橋場景數(shù)據(jù)集。并且與其他研究不同的是,本文僅使用CCPD 作為訓(xùn)練數(shù)據(jù)集,其余3 個數(shù)據(jù)集則用于泛化性測試,不參與訓(xùn)練。
1)CCPD 數(shù)據(jù)集。
CCPD 由中國科學(xué)技術(shù)大學(xué)團(tuán)隊創(chuàng)建,是用于車牌檢測識別的大型國內(nèi)停車場車牌數(shù)據(jù)集。該數(shù)據(jù)集在合肥市停車場進(jìn)行采集,采集時間為7:30 — 22:00,拍攝的車牌圖像涉及多種復(fù)雜環(huán)境,包括模糊、傾斜、雨雪霧天等,共35 萬張,每張圖像尺寸為720×1 160×3。
在實驗中,本文從CCPD 數(shù)據(jù)集的9 個場景中隨機(jī)選取了Base、Blur、Weather、Rotate、DB、FN 等6 個場景各1 000 張圖片作為訓(xùn)練數(shù)據(jù)集,各500 張圖片作為基本的性能評測數(shù)據(jù)集,訓(xùn)練測試比例為2∶1。其中:Base 數(shù)據(jù)集是各種常見情況下的車牌;Blur 數(shù)據(jù)集是相機(jī)抖動造成圖片模糊的車牌;Weather 數(shù)據(jù)集是雨雪霧天氣下拍攝的車牌;Rotate 數(shù)據(jù)集是水平傾斜[20°,25°]、垂直傾斜[-10°,10°]的形變車牌;DB 數(shù)據(jù)集是光線較暗或者較亮情況下拍攝的車牌;FN 數(shù)據(jù)集是距離攝像頭相對較遠(yuǎn)或相對較近的車牌。這6 個場景基本包含了車牌檢測應(yīng)用場景的各種非限制條件特點。
2)能源車綠色車牌數(shù)據(jù)集。
CCPD 數(shù)據(jù)集中圖像均為藍(lán)色車牌,缺少近年來日益增多的新能源汽車車牌。因此,為驗證僅學(xué)習(xí)藍(lán)色車牌的USLPD 模型對能源車車牌的檢測泛化能力,本文從互聯(lián)網(wǎng)搜集了1 000 張綠色車牌圖像作為測試數(shù)據(jù)集。
3)實采停車場景數(shù)據(jù)集。
為驗證USLPD 模型對自動駕駛、電子收費、停車場門禁控制等近距離應(yīng)用場景的泛化性,本文在實際停車場中根據(jù)應(yīng)用特點的限制條件拍攝了500 張類似圖片作為測試數(shù)據(jù)集,包含日間與晚間、拍攝距離遠(yuǎn)中近、多個車牌目標(biāo)并存等圖像,分辨率為1 280×720、1 920×1 080、3 840×2 160,質(zhì)量比CCPD 數(shù)據(jù)集更高。
4)實采天橋場景數(shù)據(jù)集。
為驗證USLPD 模型對道路監(jiān)控類等遠(yuǎn)距離、大場景、多車道的應(yīng)用泛化性,本文在天橋拍攝了500 張圖片作為測試集,包含因車速快而造成的運動模糊圖片、CCPD 數(shù)據(jù)集缺少的車輛密集圖片和大型新能源汽車的黃綠色車牌等,分辨率為1 280×720、1 920×1 080、3 840×2 160。
2.2 評價指標(biāo)
為了評估本文方法對車牌檢測的有效性,實驗使用準(zhǔn)確率(Precision,P)與召回率(Recall,R)作為評價指標(biāo),具體定義如式(16)~(17)所示:

其 中:TP(True Positive)、FP(False Positive)、FN(False Negative)分別表示正確檢測的車牌邊界框數(shù)、錯誤預(yù)測的車牌邊界框數(shù)與漏檢的車牌邊界框數(shù)。準(zhǔn)確率越高,代表誤檢越少;召回率越高,代表漏檢越少。
2.3 結(jié)果分析
2.3.1 網(wǎng)絡(luò)模型分析比較
在特征提取骨干網(wǎng)絡(luò)方面,MobileNetV3、MobileViT 與ResNet18 各有優(yōu)勢,實驗性能對比結(jié)果如表1 所示,在車牌檢測應(yīng)用中,以MobileNetV3 與MobileViT 為主干的USLPD 模型雖然參數(shù)量(Params,即模型所需學(xué)習(xí)的參數(shù)總數(shù))比以ResNet18 為主干的USLPD 模型少,但在精度、每秒處理幀數(shù)(Frames Per Second,F(xiàn)PS)上都不及ResNet18,因此,最終選擇ResNet18 作為USLPD 模型提取圖像特征的骨干網(wǎng)絡(luò)。
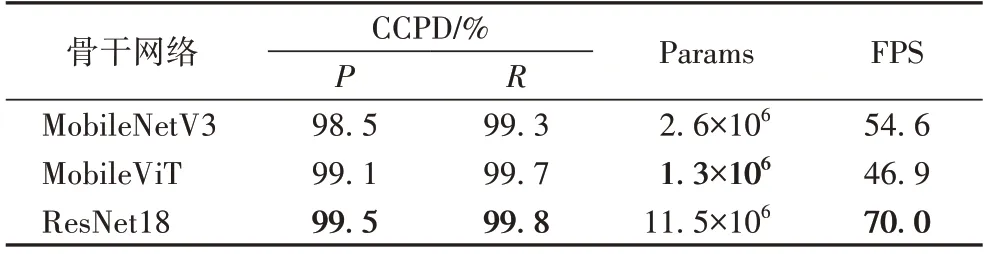
表1 不同骨干網(wǎng)絡(luò)CCPD數(shù)據(jù)集檢測性能比較Tab.1 Comparison of detection performance among different backbone networks on CCPD dataset
2.3.2 車牌檢測對比實驗
對所提出的網(wǎng)絡(luò)模型進(jìn)行公共數(shù)據(jù)集檢測效果評估,結(jié)果如圖4 所示,可以看出本文模型能夠準(zhǔn)確、完整檢測出不同背景下不同形態(tài)的車牌區(qū)域。

圖4 CCPD上的車牌檢測結(jié)果Fig.4 License plate detection results on CCPD dataset
為了定量評估算法性能,將訓(xùn)練得到的USLPD 模型與目前具有代表性的車牌檢測方法進(jìn)行性能對比,結(jié)果如表2所示。從表2 中的實驗結(jié)果可以看出,本文所提出的USLPD模型在準(zhǔn)確率與召回率上優(yōu)于Faster R-CNN、SSD、YOLO 系列等基于錨框的檢測方法,達(dá)到了99.5%的準(zhǔn)確率與99.8%的召回率,驗證了USLPD 具有良好的學(xué)習(xí)能力與優(yōu)越的非限制條件車牌檢測能力。

表2 在CCPD上的不同檢測方法的性能對比 單位:%Tab.2 Performance comparison of different detection methods on CCPD unit:%
Faster R-CNN、SSD 和YOLO9000[3]方法由于對小目標(biāo)的檢測缺陷,在CCPD-FN 數(shù)據(jù)集上的準(zhǔn)確率較低,YOLOv3 則因在YOLO9000 基礎(chǔ)上加入了特征金字塔網(wǎng)絡(luò)(Feature Pyramid Network,F(xiàn)PN)[20],解決了YOLO[21]和YOLO9000 方法對小目標(biāo)的檢測難題,使得檢測精度大幅提升。YOLO 是YOLO 系列方法[3-4,21]的基礎(chǔ),它將輸入圖像劃分為n×n個網(wǎng)格(n由用戶確定,一般取值為7),每個網(wǎng)格預(yù)測中心點落于其中的目標(biāo),并回歸目標(biāo)邊界框。
除此之外,由于結(jié)合了Faster R-CNN 的錨框機(jī)制和YOLO[21]的回歸思想,SSD 方法檢測精度整體優(yōu)于Faster RCNN,而YOLO9000 雖在SSD 的基礎(chǔ)上增加了批量歸一化(Batch Normalization,BN)[22]、數(shù)據(jù)增強和高分辨率分類器等改進(jìn),但在車牌檢測任務(wù)上的精度卻低于SSD。
2.3.3 車牌檢測模型泛化性評測
本文對所提出的網(wǎng)絡(luò)模型在不同場景數(shù)據(jù)集的檢測效果結(jié)果如圖5 所示,可以看出本文模型能夠準(zhǔn)確、完整地檢測出不同真實應(yīng)用場景下不同特征的車牌區(qū)域。

圖5 實采測試集上的車牌檢測結(jié)果Fig.5 License plate detection results on real-world test sets
為了定量評估算法的泛化性能,本文將訓(xùn)練得到的USLPD 模型在能源車綠色車牌數(shù)據(jù)集、實采停車場場景數(shù)據(jù)集、實采天橋場景數(shù)據(jù)集上進(jìn)行車牌檢測,評估結(jié)果如表3所示。在這3 個與訓(xùn)練數(shù)據(jù)不同的數(shù)據(jù)集中,USLPD 模型在不經(jīng)過任何調(diào)整優(yōu)化的情況下,仍能達(dá)到90%以上的檢測精度,復(fù)用簡單,泛化性能滿足工程實用要求。

表3 不同數(shù)據(jù)集上的檢測性能 單位:%Tab.3 Detection performance on different datasets unit:%
3 結(jié)語
本文結(jié)合多個預(yù)測頭的不同優(yōu)勢,構(gòu)建了一個具有良好檢測能力及泛化能力的非限制場景車牌檢測算法網(wǎng)絡(luò)模型。通過可微分二值網(wǎng)絡(luò)模型訓(xùn)練方法,完成對分割、回歸預(yù)測頭的監(jiān)督學(xué)習(xí),以及對自適應(yīng)置信度閾值預(yù)測頭的無監(jiān)督學(xué)習(xí);同時,提出CANMS 算法提升后處理速度,通過實驗對比MobileNetV3、MobileViT 與ResNet18 等多個輕量級網(wǎng)絡(luò),確定模型骨干,提升網(wǎng)絡(luò)檢測速度。在CCPD 數(shù)據(jù)集、能源車綠色車牌數(shù)據(jù)集、實采停車場場景數(shù)據(jù)集及實采天橋場景數(shù)據(jù)集上的實驗結(jié)果表明,本文所提出的USLPD 算法檢測精度高、處理速率快、泛化能力強、模型復(fù)用簡單,可以滿足非限制場景非限制條件的車牌檢測性能要求。今后將進(jìn)一步研究車牌識別算法,將USLPD 應(yīng)用于端到端非限制場景車牌檢測識別系統(tǒng)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
