基于嵌入式平臺的車前紅外行人檢測方法研究*
2023-01-31 02:09:54張良李鑫趙曉敏蔣瑞洋張國棟
汽車技術 2023年1期
張良 李鑫 趙曉敏 蔣瑞洋 張國棟
(合肥工業大學,合肥 230009)
主題詞:目標檢測 紅外圖像 開源推理加速庫 注意力機制 Jetson TX2平臺
1 前言
當前,無人駕駛技術發展迅猛,保障行人的安全是無人駕駛領域的重要研究內容。目前,針對可見光圖像的深度學習目標檢測算法已取得豐碩的成果[1-3],但是可見光技術依賴于良好的光照條件,在夜晚、昏暗隧道或光照過強等場景下,可見光技術應用效果較差,甚至不能應用。紅外行人檢測技術基于物體自身熱輻射和反射成像原理,受光照條件影響小,可以全天候工作,因此在無人駕駛領域具有重要的研究和應用價值[4]。
近年來,隨著行人檢測技術的日趨成熟和計算機硬件的快速發展,實時行人檢測的應用場景逐漸增加,將行人檢測模型部署在移動終端已經成為一大趨勢。但由于行人檢測任務的復雜性,行人檢測模型往往有很多參數,計算量大,對于內存、存儲容量和計算能力均有限的嵌入式設備來說,很難滿足行人檢測的實時性要求。因此,平衡行人檢測模型的檢測速度和準確性,并將其高效地部署到嵌入式設備中,是當前的熱門研究方向[5-6]。文獻[7]將改進的YOLOv3 模型應用于嵌入式平臺,然后進行紅外人體檢測,平均準確率相較于YOLOv3模型提高3.26%,檢測速度達到16幀/s;文獻[8]對YOLOv4模型進行剪枝以降低模型復雜度,并部署于嵌入式平臺,達到了75.60%的紅外行人識別準確率。現有研究雖實現了神經網絡在嵌入式平臺上的部署,但總體而言,其模型參數量依然較為龐大,識別速度和準確率仍有待提高。
本文提出2 種基于嵌入式平臺的車前紅外行人檢測方法,旨在達到檢測速度和平均準確率的良好平衡:使用推理加速庫TensorRT 優化輕量化網絡YOLOv4-tiny[9],提高推理速度;以YOLOv4-tiny 模型作為算法的基本框架,結合空間金字塔池化(Spatial Pyramid Pooling,SPP)模塊、卷積塊注意模塊(Convolutional Block Attention Module,CBAM)和3 個檢測層(3 Layer,3L),提升其平均準確率。最后均部署于Jetson TX2嵌入式平臺,驗證所提出方法的有效性。
2 方法原理
本文提出2 種車前紅外行人檢測方法:一是利用TensorRT推理加速原理,對YOLOv4-tiny網絡模型進行推理加速,然后進行行人檢測;二是使用YOLOv4-tiny+3L+SPP+CBAM(本文稱為YOLOv4-tiny-I)網絡模型檢測行人。
2.1 YOLOv4-tiny網絡架構
YOLOv4-tiny 是YOLOv4作者[10]在其開源程序中提供的YOLOv4 的簡化版本,降低了模型對硬件的要求,適合部署于移動端或嵌入式端,其網絡結構如圖1 所示。其骨干網絡(CSPDarkNet53_Tiny)包含CBL(Conv+BN+LeakyRelu)模塊和跨階段殘差結構(Cross Stage Partial,CSP)模塊,CBL模塊的構成為卷積層(Conv)、批歸一化處理層(Batch Normalization,BN)、激活層(采用LeakyRelu 激活函數);CSP 模塊的構成為4 個CBL 層和1 個最大池化(Maxpool)層。骨干網絡用來進行特征提取,特征提取網絡末端使用2個特征層進行分類與位置回歸預測;利用特征金字塔思想[11]對相鄰尺度的特征圖通過串聯操作進行特征融合,輸出2 個檢測頭(Yolo Head)。
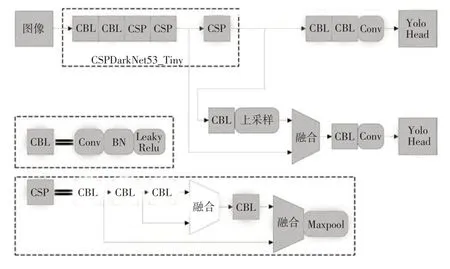
圖1 YOLOv4-tiny網絡結構
2.2 TensorRT推理加速原理
TensorRT是英偉達(NVIDIA)公司提出的用于推理的加速計算庫,其憑借對網絡結構的重構、操作的合并和網絡量化等優化方法實現高效的推理過程,其優化推理引擎只有前向傳播。TensorRT 能將所支持的深度學習網絡模型進行解析,并將解析后的網絡模型結構與TensorRT自身結構進行一一映射[12],之后便可將深度學習網絡模型轉移到TensorRT引擎中,以加速模型部署。
深度學習網絡往往層數較多,在模型部署推理時,GPU 需啟動不同的CUDA 核心對每個層進行運算,CUDA 核心雖有很強的計算能力,但數據的讀寫和CUDA 核心的啟動極為耗時,導致大量GPU 資源浪費。TensorRT 通過對層間的縱向合并(將卷積Conv、偏置Bias 和激活函數ReLU 合并成CBR 層)、橫向合并來減少模型層數,以便占用更少的CUDA 核心來完成相同的運算[13]。TensorRT合并具體操作如圖2所示。

圖2 TensorRT合并策略
2.3 YOLOv4-tiny-I網絡結構
YOLOv4-tiny 使用了13×13 和26×26 這2 種不同尺度的特征圖來預測檢測結果。由于行人形態姿勢不固定、行人所處環境復雜多變,會存在目標被部分遮擋和目標較小的情況,此時僅使用2 種尺度特征圖進行目標檢測易產生對遮擋目標和較小目標的識別率較低的情況。為了更好地檢測行人,本文所提出的網絡模型YOLOv4-tiny-I 使用19×19、38×38 和76×76 這3 種尺度特征圖來預測檢測結果,使用3種尺度不僅可提升檢測范圍,還能提供更豐富的淺層特征信息,進而能更好地將低層的特征和高層的特征融合起來進行多尺度圖像預測。YOLOv4-tiny-I網絡結構如圖3所示。

圖3 YOLOv4-tiny-I網絡結構
He 等[14]為了解決在一般卷積神經網絡結構中輸入網絡的圖片大小必須固定的問題,提出了空間金字塔池化思想,該思想使用多級大小空間窗口對輸入特征層進行多尺度池化并融合,從而能夠對以任意大小輸入的圖像產生相同尺度的輸出。借鑒He 等人提出的思想,本文使用如圖3中所示的空間金字塔池化SPP模塊,通過大小分別為5×5、9×9 和13×13 的池化窗口對特征圖進行池化,將多尺度特征進行融合,從而豐富語義信息。由于特征圖在深層網絡中空間信息較少,而SPP模塊可以提取物體不同范圍的全局特征和局部特征,將這些特征信息融合后便可以豐富深層特征圖上的空間信息。骨干網絡之后是特征圖空間信息較少的位置,在此處增加SPP模塊能夠使特征圖空間信息增多,有助于提高不同尺度紅外行人的識別和定位能力。故YOLOv4-tiny-I模型在骨干網絡后增加SPP模塊。
CBAM由Woo等[15]于2018年提出,該模塊由通道注意力模塊(Channel Attention Module,CAM)和空間注意力模塊(Spatial Attention Module,SAM)構成,如圖4 所示。CBAM通過學習的方式,在目標檢測網絡的特征通道維度及特征空間維度計算原始特征圖的注意力權重圖,然后將注意力權重圖賦予原始特征圖,從而使網絡重點關注目標區域。在實際紅外行人檢測識別過程中,行人背景包含大量混淆信息,現有的網絡往往無法將其剔除,導致訓練后得到的權重信息中摻雜大量的混淆信息,影響檢測性能。因此,模型YOLOv4-tiny-I 在增添SPP模塊的基礎上,引入CBAM模塊來關注重點特征并抑制非必要特征。CBAM 的CAM 模塊對通道進行重新加權、SAM針對特征圖上每個像素進行加權,高階特征引導低階特征進行通道注意力獲取,低階特征反向指導高階特征進行空間注意力篩選,從而使得網絡特征圖中有目標物體的區域權重提高,進而提高網絡檢測精度。YOLOv4-tiny-I 模型在3 個檢測頭之前引入CBAM 模塊,可以避免背景像素對檢測頭的干擾,同時能夠使網絡具備對不同級別特征圖進行信息整合的能力。
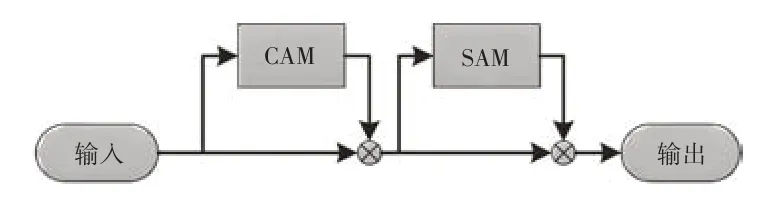
圖4 CBAM注意力模塊
3 試驗驗證
為了評估本文提出的2種紅外行人檢測方法,設計了相關試驗進行驗證。
3.1 環境配置及訓練參數
在本文所有試驗中,網絡模型均在Google Colab 云服務器進行訓練,訓練好的模型均部署于NVIDIA 的嵌入式開發板Jetson TX2 上進行測試,TX2 設備如圖5 所示。試驗基于Darknet框架進行。平臺的相關參數如表1所示。
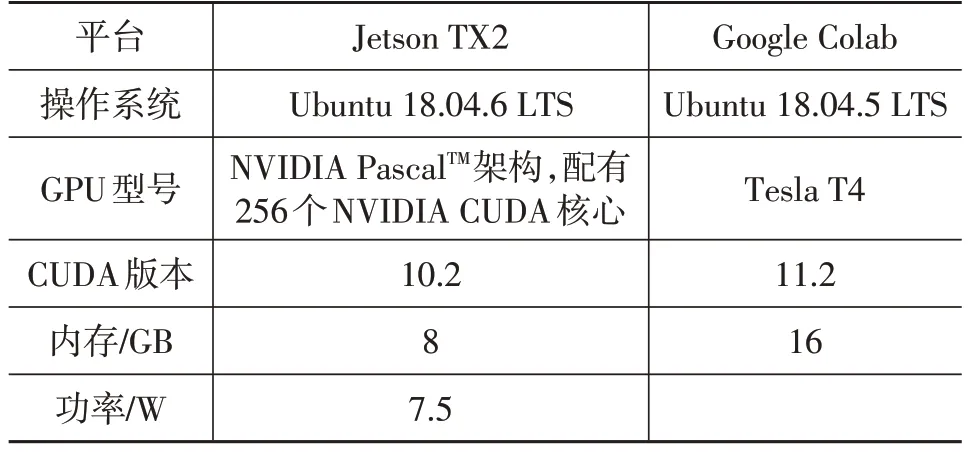
表1 平臺參數

圖5 Jetson TX2設備
訓練網絡模型時,采用的訓練超參數均保持一致。輸入批量大小Batch 設置為64,初始化學習率為0.001,梯度下降動量參數設置為0.9,權重衰減正則項系數設置為0.000 5。
3.2 數據集與錨框
試驗采用菲力爾(FLIR)公司于2018年7月發布的公開紅外數據集[16]。該數據集采集地點為美國加利福尼亞州圣巴巴拉市的街道和公路上,時間為11 月至次年5 月期間的日間(60%)和夜間(40%),采用紅外熱像儀進行采集,紅外分辨率為640×512。FLIR數據集文件包含3個文件夾train、val、video,類別包含人、汽車、自行車、狗和其他,對train、val 文件夾進行處理篩選出包含行人類別的圖片共7 044 張,將其按照5∶1 的比例劃分為訓練集和測試集。劃分后的部分FLIR 數據集如圖6所示。

圖6 FLIR紅外數據集
使用K-means++聚類算法得到各模型的先驗框尺寸:YOLOv4-tiny 模型的為(11,19)、(14,32)、(19,51)、(29,74)、(46,122)、(78,196);YOLOv4-tiny-I 模型的為(11,23)、(13,37)、(15,50)、(17,65)、(21,82)、(22,48)、(28,80)、(36,120)、(61,201)。
3.3 評價指標
在車輛前方紅外行人的檢測中,需要考慮網絡的檢測準確率與實時性。本文選取平均準確率(mean Average Precision,mAP)和幀率作為紅外行人檢測的評價指標。mAP 與準確率(Precision)P、召回率(Recall)R有關,相關計算公式為:


式中,T為被正確劃分到正樣本的數量;F為被錯誤劃分到正樣本的數量;N為被錯誤劃分到負樣本的數量;M為類別總數,本文僅檢測行人,故取M=1;A(k)為第k類的平均準確率。
3.4 試驗結果
YOLOv4-tiny 模型在檢測時會將輸入圖片進行尺寸標準化,輸入尺寸設置越大,平均準確率越高,但檢測速度會下降。為了選擇合適的圖片輸入尺寸,設置了對比試驗,如表2 所示。以輸入尺寸608×608 為基準,輸入尺寸高于該基準時幀率下降較多,對檢測實時性不利;輸入尺寸低于該基準時平均準確率較低,對精準檢測不利。綜合檢測精度和速度,當輸入尺寸設置為608×608時,網絡檢測精度較高且檢測速度也較快。因此選定圖像輸入尺寸為608×608。

表2 圖片輸入尺寸對檢測性能的影響
為了測試與YOLOv4-tiny 網絡結合的每個模塊對紅外行人檢測的影響,設置了對比試驗,并將原始FLIR數據集video文件夾下的圖片轉成視頻文件用于評估網絡模型。試驗結果如表3所示。由表3可以看出:
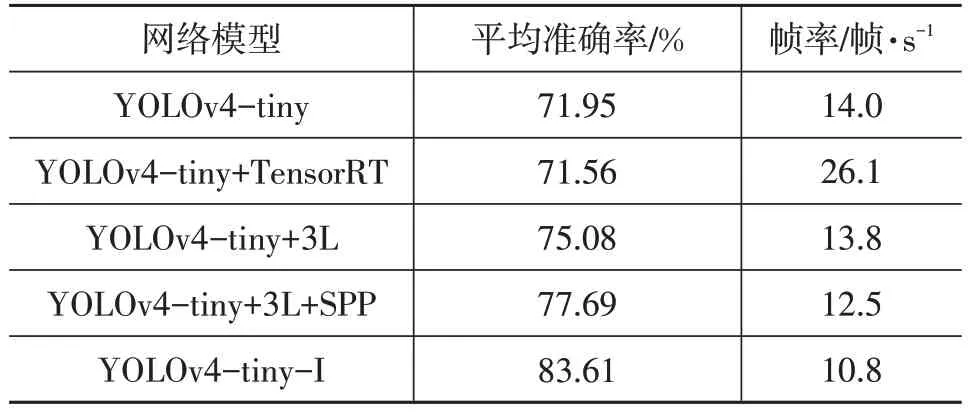
表3 嵌入式模型部署對比結果
a.相較于原始網絡YOLOv4-tiny,模型YOLOv4-tiny+TensorRT 的準確率降低了0.54%,這是由于TensorRT 在推理加速時采用了半精度加速推理策略對網絡權重進行量化所導致的[17],但模型YOLOv4-tiny+TensorRT 的推理速度提升了86.43%,達到26.1 幀/s,做到了實時檢測;
b.模型YOLOv4-tiny+3L增加了1個YOLO 層,該YOLO 層結構不復雜,故幀率相較于YOLOv4-tiny 僅下降1.43%,平均準確率相較于YOLOv4-tiny 增加4.35%,說明增加1個YOLO層能夠有效改善模型檢測性能;
c.在增加1 個YOLO 層的基礎上再增加SPP 模塊,幀率小幅下降,平均準確率相較于YOLOv4-tiny+3L增加3.48%,說明SPP 模塊有效地豐富了深層特征圖上的空間信息,提升了網絡檢測準確率;
d.本文所提出的YOLOv4-tiny-I模型在YOLOv4-tiny+3L+SPP 模型的基礎上又增加了3 個CBAM 模塊,所以幀率下降稍多,達到10.8 幀/s,但也能滿足車前紅外行人檢測的需要,平均準確率增幅明顯,相較于YOLOv4-tiny+3L+SPP 增加了7.62%,達到了83.61%,說明CBAM 模塊能夠將特征圖中有目標物體的區域權重提高,進而提高網絡檢測精度。
根據試驗結果,本文選取YOLOv4-tiny+TensorRT和YOLOv4-tiny-I 作為車前紅外行人檢測的2 種方法。為直觀展現模型檢測效果,選取部分圖像進行對比,如圖7 所示。從圖7a 和圖7b 中可以看出:YOLOv4-tiny+TensorRT和YOLOv4-tiny對行人識別效果基本一致,側面驗證了TensorRT 在加速模型檢測時模型準確率僅降低0.54%的試驗結果的正確性;在場景1中,騎行者所在區域和周圍背景區域相似,可以發現YOLOv4-tiny算法在該騎行者的定位上有些偏差(騎行者的腳沒有完全在目標檢測框內),而YOLOv4-tiny-I 算法中該騎行者完全在目標檢測框內;在場景2 中,有被遮擋的行人且行人目標較小,通過比較能夠發現,YOLOv4-tiny 未能識別到右側被遮擋的行人,而YOLOv4-tiny-I能成功識別出被遮擋的行人,驗證了在模型YOLOv4-tiny-I中使用的3個YOLO層的有效性;場景3為正常情況下的行人,可以發現3個模型對其均有很好的識別效果。


圖7 3種模型的檢測效果對比
4 結束語
本文提出2 種基于嵌入式平臺的車前紅外行人檢測方法,YOLOv4-tiny+TensorRT 和YOLOv4-tiny+3L+SPP+CBAM:通過TensorRT 推理加速YOLOv4-tiny模型來提升檢測速度;通過修改YOLOv4-tiny模型結構來提升檢測精度。第2種方法使用3個YOLO層進行多尺度圖像預測,同時引入SPP 模塊來加強多尺度特征融合,進一步豐富了深層特征圖的表達能力,并引入CBAM模塊來關注重點特征,同時抑制非必要特征。試驗結果表明:相較于原始網絡YOLOv4-tiny,所提出的第1種方法平均準確率降低0.54%,推理速度提升86.43%(達到26.1 幀/s);第2 種方法平均準確率提升16.21%,推理速度降低22.86%(達到10.8幀/s)。2種方法均能滿足車前紅外行人檢測的需要。在實際應用中,若對檢測速度要求高,可選用第1種方法,若對檢測精度要求高,可選用第2種方法。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
鐵道通信信號(2018年2期)2018-04-18 12:18:23
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電鍍與環保(2016年3期)2017-01-20 08:15:32
海峽科技與產業(2016年3期)2016-05-17 04:32:12
單片機與嵌入式系統應用(2014年9期)2014-03-11 15:35:13
