基于LightGBM的水質預測模型研究與應用
2023-01-31 00:15:16歐陽群文
智能城市 2022年11期
歐陽群文
(廣州市城建規劃設計院有限公司,廣東廣州 510000)
廣州以河長制為“統領”,深入開展清四亂和源頭控污工作,全市水環境治理水平及治理成效實現了根本性提升,完成了對原有黑臭河湖的治理。然而河道水安全和水環境依然較為脆弱,各類問題有反彈風險,治水成效難以鞏固,河湖水質存在返黑返臭風險。隨著廣州河長制工作的不斷深入,以信息化為主要手段的河長管理機制不斷更新迭代,并積累了大量數據[1-3]。但現有的廣州河長信息管理系統主要功能是收集整理和發布河湖管理方面的基本信息,缺乏對數據的深入分析與挖掘,并沒有結合實際需求進行模型的開發,例如如何進行水質預警、如何根據預報結果進行針對性治理等[4]。利用數據資源指導實際工作是河長制信息化推進的主要方向。鑒于此,文章利用廣州河長管理信息系統中的數據(下稱“系統數據”),通過對數據進行深入挖掘與分析,基于擅長挖掘數據縱深的LightGBM(light gradient boosting machine)算法建立水質預測模型。通過建模型預測水質等級,并據此分析河湖水質變化趨勢及系統數據的重要程度,從而提高河長對河湖事件的預測能力以及河湖管理的執行能力,全面促進河長制實施。
1 模型目標及算法選擇
模型中,采取廣州河長管理信息系統數據(河涌問題數據、河長行為數據等)、河涌上月水質數據作為特征數據,河涌本月水質數據作為標簽數據,通過多分類機器學習算法深入挖掘特征數據與標簽數據之間的映射關系,得到一個可以根據上月特征數據預測當月水質的機器學習模型,即LightGBM的水質預測模型。通過內業模型輸出結果指導外業對于水質較差以及有變差趨勢的河涌,并執行定向巡查,通過多分類機器學習算法實現水質預測的目標。
2 基于LightBGM的水質預測模型構建
模型構建環節包括數據整合、樣本劃分、數據預處理、特征工程、模型訓練及參數優化、模型結果分析評價、變量重要性評分及內外業融合分析。
2.1 數據整合
根據廣州河長管理信息系統中的不同數據源,將不同來源的數據整合成一張建模寬表。由于每條河涌對應多個河長,故河涌對應的河長行為數據采用均值平滑方法處理,即采用多個河長的行為數據均值作為特征數據。
2.2 樣本劃分
考慮到樣本數據比較有限,為了保證模型能夠充分地訓練,需要擴大訓練集的占比,所以采取9∶1的比例將1 771條樣本數據劃分成訓練集及測試集,其中訓練集1 593條,測試集178條。
2.3 數據預處理
鑒于設備故障、網絡通信等不可控因素的影響,原始數據中可能存在臟數據、缺失數據等情況。因此,首先對原始數據進行預處理。預處理工作主要包括數據清洗、特征分類、缺失值處理、異常值檢測等,包括數據清晰、特征分類、數據缺失值處理、數據異常值處理。
2.4 特征工程
特征工程是指將預處理后的數據進行加工,轉變為模型所需要的特征數據,同時將原有特征通過計算、組合等方式轉換為新的特征[5-9]。研究中,對于河涌問題數據進行了縱向(多級河長)與橫向(同級河長上報的不同問題)的特征工程處理,共得到31個特征數據。
2.5 模型訓練及參數優化
將上月特征數據作為輸入,當月水質等級預測作為輸出,構建基于LightGBM的水質預測模型。采用LightGBM算法在訓練集中訓練模型,并通過模型在驗證集上的表現進行算法參數優化。初步訓練時,設置參數如下:決策樹的數量設置為200,樹最大深度設置為3,其他參數均使用默認參數。初步訓練的準確率為48.31%,參數優化效果以此基準模型作為參考。
LightGBM模型參數較多,研究選取LightGBM最重要的7個參數進行算法優化,以準確率為評價指標通過網格搜索法選取最優參數。優化的結果如圖1所示,評價指標均為測試集上的準確率。
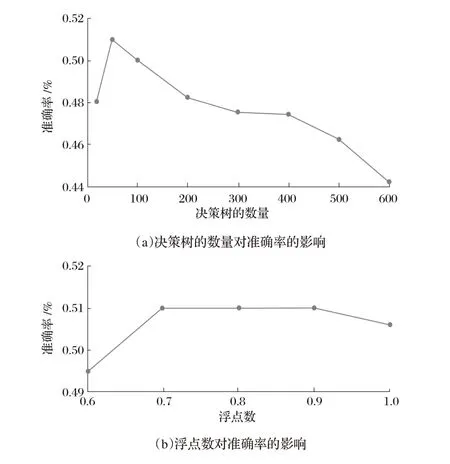
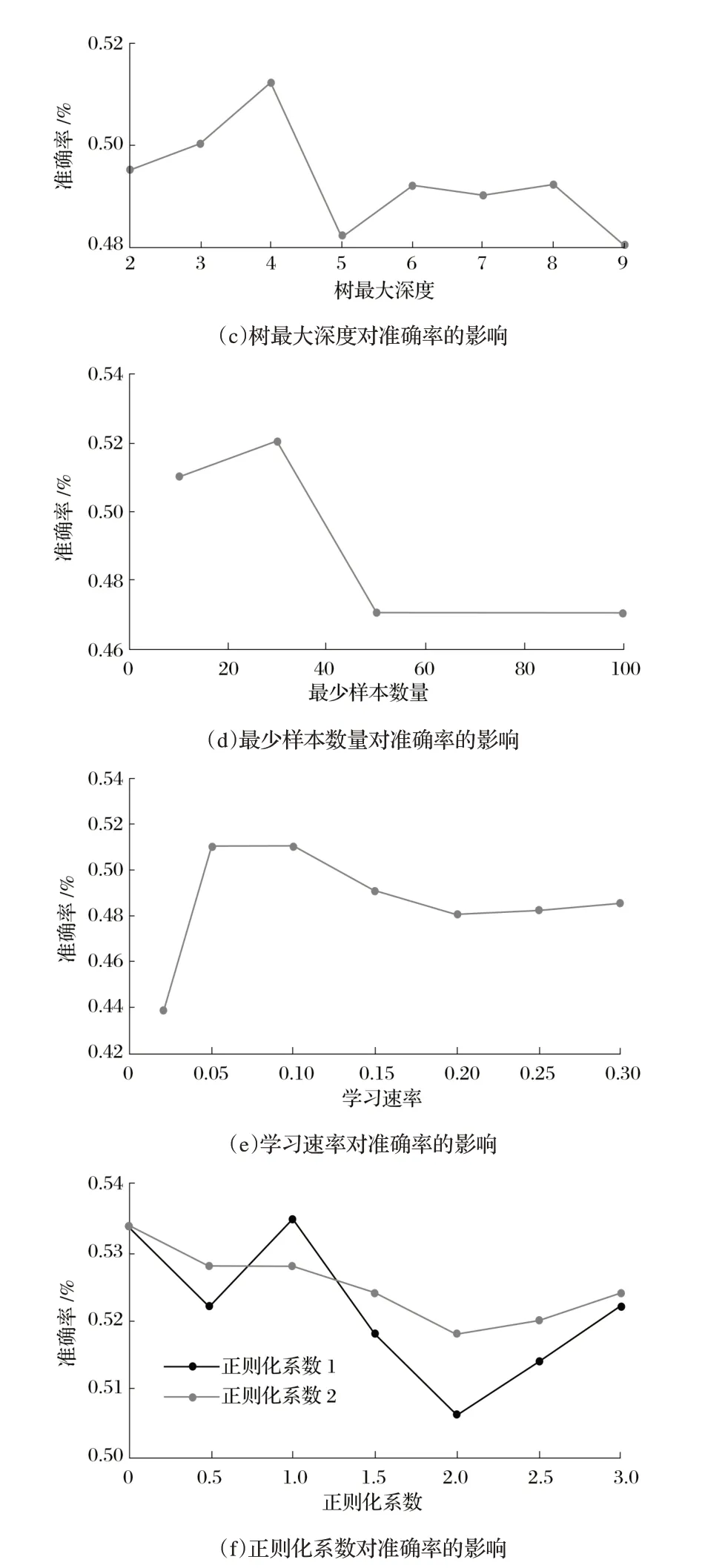
圖1 LightGBM模型參數調優結果
由圖1可知,將決策樹的數量初始值設為20,準確率為0.48,當決策樹的數量取50時,準確率變為0.51,繼續增大決策樹的數量到100、200、300、400、500、600,準確率呈現下降趨勢。將浮點數設定為0.6~1.0的調整范圍,當浮點數取值為0.7、0.8、0.9時,準確率趨于穩定。當樹最大深度取值小于4時,準確率上升,當取值大于4時,準確率呈上下波動變化,但均小于取值為4的準確率。最小樣本數量在4種取值下(10、30、50和100)的準確率分別為0.51、0.52、0.47和0.47。將正則化系數設定為0~3.0的調整范圍,隨著參數增大,模型預測效果反而變差,調參后最優解仍保持為0。選擇兩種正則化系數進行調參,正則化系數1.0與正則化系數2.0參數取值范圍相同,調參后最優解為1。對于學習速率,0.1為最佳取值。由以上分析可知,參數決策樹的數量、浮點數、樹最大深度、最小樣本數量、正則化系數1、正則化系數2.0、學習速率的最優取值分別為50.0、0.9、4.0、30.0、0、1.0、0.1。特征選擇結果如表1所示。
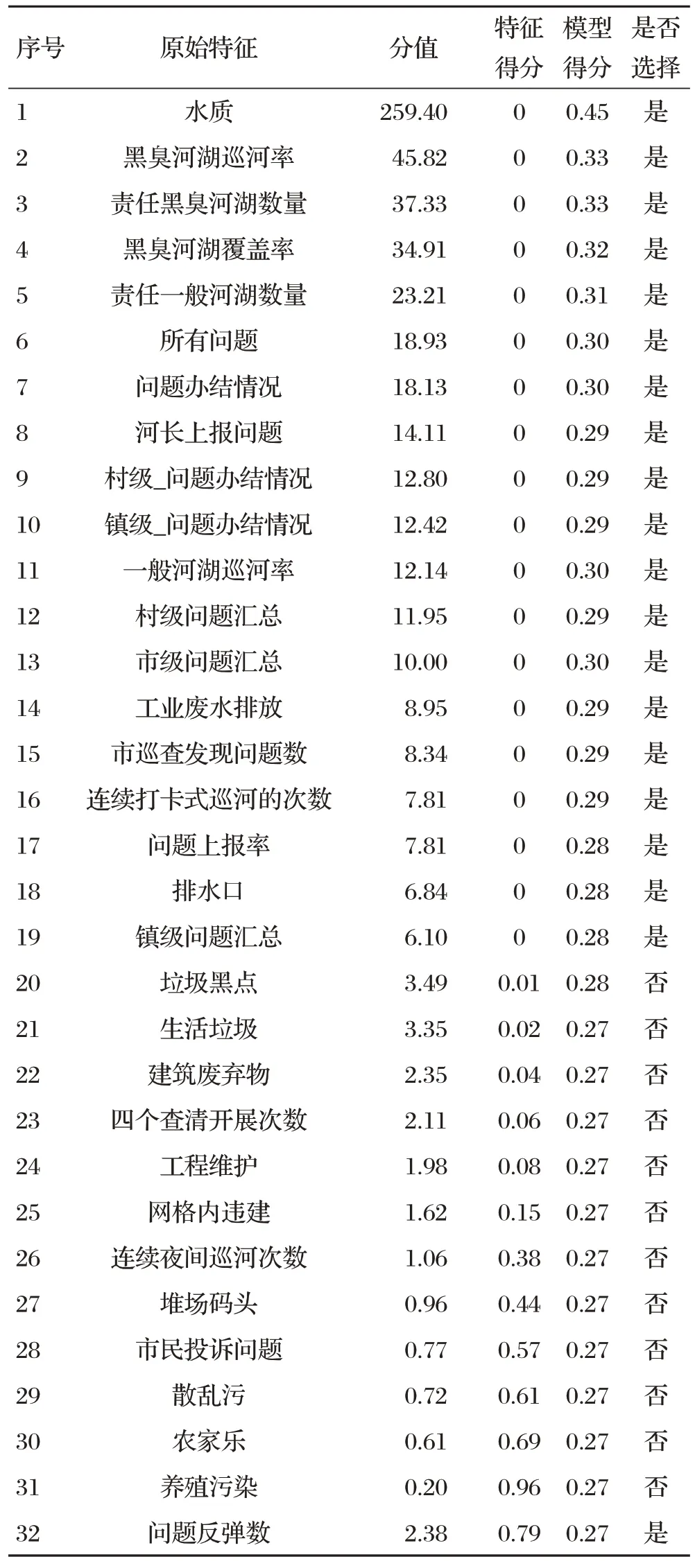
表1 特征選擇結果
2.6 模型結果分析評價
研究采用“準確率”為評價指標。將上述尋優的參數代入模型,輸出預測結果。通過混淆矩陣可以得出,Ⅱ類、Ⅵ類(劣五類)水質的河涌預測比較準確,Ⅱ類、Ⅲ類水質容易相互混淆。總體準確率為53.37%。除了準確率之外,還可以通過針對某一類別的查準率、查全率分析模型的分類結果。對于重點關注的Ⅴ類、Ⅵ類(劣五類)水質,計算其查準率、查全率。Ⅴ類查準率為40%,Ⅴ類查全率為11.76%,Ⅵ類查準率為63.16%,Ⅵ類查全率為68.57%。因此,5類水質河涌的查準及查全表現較低,尤其是查全率,原因在于訓練樣本中Ⅴ類水質河涌的樣本數過少,模型無法學習到相應特征。雖然Ⅴ類水質的模型效果并不理想,但Ⅵ類水質的查準和查全比較理想,查全率達到68.57%,Ⅵ類水質的模型效果對于河涌黑臭預警、水質惡化預警有重要意義。
2.7 特征重要性分析
研究中采用Gini Importance方法得到重要性評估結果如圖2所示。
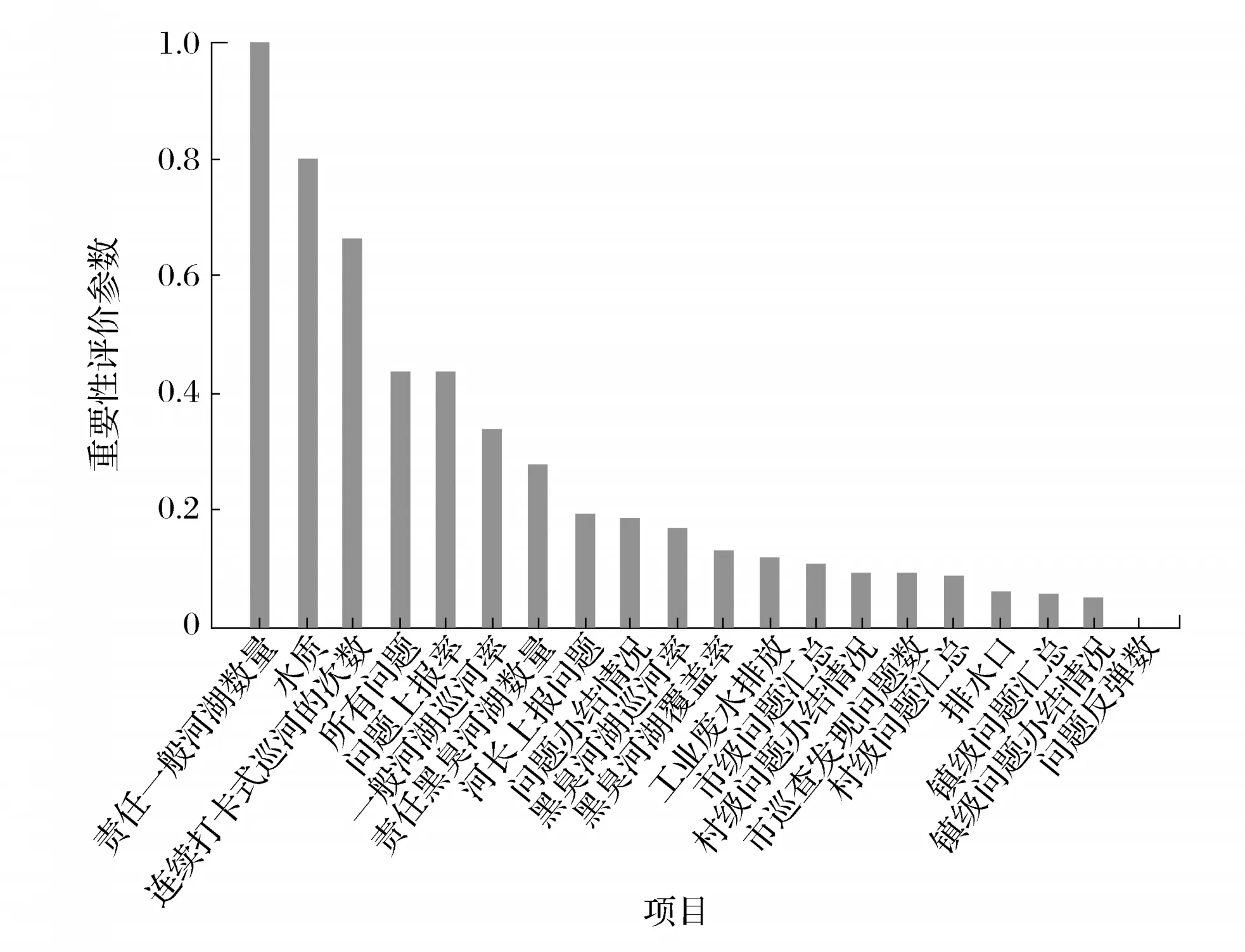
圖2 變量重要性評價結果
由圖2可知,責任一般河湖數量、上月水質、連續打卡式巡河的次數是影響水質的3個重要特征。責任一般河湖數量是指河涌對應河長所管轄的一般河湖數量,反映出河涌管理者的精力分散程度,由此結果可以推測,河涌管理者的精力分散程度對水質有較大影響,此結論對于河長的人手分配、河涌分配具有指導意義。連續打卡式巡河次數反映出河長巡河行為對水質的影響,此結論對河長管理、培訓、督導具有指導意義。另外,特征重要性分析結果表明,所有問題、問題上報率、一般河湖巡河率等特征對河涌水質也會產生較大影響。此外,可以發現在眾多河涌問題中,工業廢水排放是影響水質的最大問題。
3 模型驗證及模型應用
3.1 模型驗證
為了進一步驗證模型效果,采用后一個月具有水質數據的河涌共計422條作為驗證樣本,將河涌的前一個月特征數據輸入訓練好的模型中,輸出各河涌后一個月水質預測數據,根據輸出的預測結果與實際結果進行比對,對模型進行驗證。
驗證結果顯示其總體準確率為53.10%,基本不變。對于重點關注的Ⅴ類、Ⅵ類(劣五類)水質,計算其查準率、查全率分別為:Ⅴ類查準率為40%、Ⅴ類查全率為18.60%、Ⅵ類查準率為63.63%、Ⅵ類查全率為67.96%。與測試集的模型效果相比,總體準確率略有下降,但Ⅴ類查全率有明顯提升、Ⅵ類查準率略微提升,Ⅵ類查全率略微下降,模型錯分樣本大部分集中在Ⅱ、Ⅲ、Ⅳ類水質。總體來說,模型效果與測試集上相當,說明模型比較穩定、泛化能力強,具有應用價值。
3.2 模型應用
根據LightGBM水質預測多分類模型輸出結果,可以構建兩個重點河涌庫,其一是Ⅵ類(劣Ⅴ類)水質河涌庫;其二是水質惡化河涌庫,根據預測的水質等級與河涌上月水質等級做對比,等級衰退兩個以上的河涌應被列為“有水質惡化傾向”的河涌。在實際工作過程中,根據模型分析結果,分別對南沙區、荔灣區相關河涌進行現場調研反饋,從現場調研情況看,其河涌存在的問題能夠反映出河涌存在一定的黑臭風險。從而得出,基于LightGBM水質預測模型能有效指導外業定向巡查、定向督導河長,防患于未然,對于重點河涌進行提前干預,提前發現問題,防止河涌水質惡化以及反黑反臭。
4 結語
以廣州河長管理信息系統中2020年3月—11月的樣本數據為例,基于LightGBM的水質預測模型輸出結果,在訓練集和測試集上,準確率都超過了53%,重點類別河涌Ⅵ類(劣Ⅴ類)的查準率達到63%以上、查全率達到68%以上,模型整體預測效果較好,具有應用價值。同時將水質等級預測與重要性評估的內業工作成果相結合,針對性地對水質有變差趨勢的河涌及疑似劣Ⅴ類河涌開展外業專項巡查工作,找出重大污染源的來源以及分析河涌流域污染源的分布、特性。通過內業數據挖掘,并結合外業專項的巡查,能夠彌補內業發現問題的局限性,在有限的資源利用背景下,達到最優化分配,減少資源浪費,提升督導巡查效率和準確性,實現了對河長的定向督導,進一步壓實河長履職責任,提升履職水平。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
當代水產(2019年1期)2019-05-16 02:42:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
河南科技(2014年23期)2014-02-27 14:19:15
