基于知識增強的文本隱喻識別圖編碼方法
2023-01-30 10:23:50黃河燕
計算機研究與發展 2023年1期
黃河燕 劉 嘯 劉 茜
(北京理工大學計算機學院 北京 100081)
(北京海量語言信息處理與云計算工程研究中心 北京 100081)
(北京理工大學東南信息技術研究院 福建莆田 351100)(hhy63@bit.edu.cn)
隱喻(metaphor)是一種在自然語言中廣泛存在的語言現象.當借用某一概念的屬性和特點來看待和使用另一個概念時,隱喻現象就發生了[1].文本隱喻識別(metaphor detection)作 為 自 然 語 言 處 理 (natural language processing,NLP)中的一個重要語義理解任務,獲得越來越多研究者的廣泛關注.其目標是:從文本中識別出表現為隱喻的詞匯.表1給出了4條包含隱喻詞匯的文本樣例,其中粗體顯示的單詞“went(出現)”“kill(終止)”“invested(投入)”“forged(建立)”表示隱喻現象,在句子中體現出了該單詞原本所不具有的語義.

Table 1 Examples of Sentences with Metaphor Words表1 包含隱喻詞匯的文本樣例
隱喻識別方法的發展大致分為3個階段:
1)早期隱喻識別研究處于特征向量構建階段.傳統隱喻識別方法采用人工編制的特征抽取器,將輸入文本轉化為特征向量,包括上下文特征[2]、詞性特征[3]、屬性特征[4]、語音視覺特征[5]等,對在特定上下文中出現的詞或短語進行隱喻現象的識別.
2)隨著深度學習在自然語言處理中的流行,隱喻識別的研究進入樸素序列建模階段.該階段的方法[6-8]一般利用文本表示學習替代人工編制的特征抽取器,將每個詞轉化為詞向量,使用卷積神經網絡(convolution neural network, CNN)、 循 環 神 經 網 絡(recurrent neural network,RNN)等基礎算法搭建編碼器,對輸入的文本進行序列編碼和建模,進而利用全連接網絡實現分類.
3)在外部知識融合階段,研究者發現單純的神經網絡方法受到數據集規模和標注稀疏性問題的制約,由此衍生出探索外部知識結合神經網絡模型尋求突破的方法.有研究者探索了基于預訓練引入其他任務知識的方式[9-10]和結合粗粒度句法知識的方法[11].
然而,現有的隱喻識別深度學習模型對詞法和句法知識的利用不充分,主要體現為2個局限性:
1)忽略了詞級別的義項知識.一詞多義現象在自然語言處理中是常見的現象和難點.隱喻現象的判定就與詞義有關,若一個詞在上下文中所表現的含義不為它本義,那么這種現象很可能就是隱喻.現有的隱喻識別深度學習方法沒有顯式地利用詞義項知識,在建模過程中會對區分詞義產生困難,從而產生對更大標注數據規模的需求.
2)忽略了細粒度句法知識.句法分析中的關系具有設定完備的標簽和方向性,它們是句法知識中的重要組成部分,可以幫助在文本建模時的信息傳遞.但是,現有的隱喻識別方法舍棄了句法分析中關系的標簽和方向性,僅僅利用了粗類別的句法知識,使得模型難以對復雜語境進行建模.
針對2個局限,本文提出基于知識增強的圖編碼方法(knowledge-enhanced graph encoding method,KEG)來進行文本中的隱喻識別.該方法首先利用預訓練語言模型為輸入文本構建上下文向量,利用詞義項知識訓練得到語義向量,拼接形成文本語義表示;然后,根據細粒度句法知識構建信息圖,利用圖循環神經網絡建模輸入文本序列,通過邊感注意力機制和邊綁定權重進行細粒度上下文計算,迭代進行信息傳遞,得到代表詞信息的節點向量和代表句子信息的全局向量;最后,利用條件隨機場進行序列建模,計算和解碼最佳輸出標簽序列,實現隱喻識別.
本文將所提出的KEG模型在4個國際公開數據集 VUA-VERB[12],VUA-ALLPOS[12],TroFi[13], MOH-X[5]上分別與3類先進的隱喻識別方法進行了對比.實驗結果表明,KEG模型在這4個數據集上的F1值和準確率均獲得提升,在圖編碼方法中結合詞義項知識和細粒度句法知識對隱喻識別的性能有明顯增強.
本文的主要貢獻分為3個方面:
1)提出融合細粒度句法信息的圖編碼方法,提出邊感注意力機制和邊綁定權重在圖神經網絡中進行細粒度上下文計算,并利用句子級別細粒度句法知識構建信息圖實現信息傳遞,進而實現了對復雜語境的高效建模.
2)利用詞義項知識學習詞義向量,并利用注意力機制將詞義向量和上下文向量結合,增強文本的語義表示,降低對一詞多義現象建模的困難,以此獲得融合了語境信息和詞義信息的文本表示.
3)相比于先進的隱喻識別方法,本文提出的KEG模型在國際公開數據集VUA-VERB,VUA-ALLPOS,TroFi,MOH-X上均獲得提升.
1 相關工作
本節將從隱喻識別方法和數據集構建這2個方面介紹相關工作.
1.1 隱喻識別方法
早期的隱喻識別方法主要是基于特征向量的方法,依賴人工設計的特征提取器,將文本轉化為特征向量,進而針對在特定上下文中的單個詞或短語,實現隱喻識別.例如,Dunn[14]設計了文本特征,以回歸任務的設定實現句子級隱喻識別.Jang等人[2]提出了一種顯式利用對話中的全局上下文來檢測隱喻的方法.Klebanov等人[3]利用語義分類來做動詞的隱喻分類,從正交的一元語法(1-gram)特征開始,嘗試了各種定義動詞語義類的方法(語法的、基于資源的、分布的),并測量了這些類對一篇文章中的所有動詞分類為隱喻或非隱喻的有效性.Bulat等人[4]提出了第1種基于屬性規范的隱喻識別方法.Shutova等人[5]提出了第1種同時從語言和視覺數據中提取知識的隱喻識別方法.Gutiérrez等人[15]探討文本隱喻的上下文構成在組合分布語義模型框架中的特殊性,并提出了一種將隱喻特征作為向量空間中的線性變換來學習的方法.但是受制于設計特征提取器的復雜性和涵蓋面的不完全性,該類方法難以遷移到新數據集上.
隨著深度學習在自然語言處理中的飛速發展和廣泛應用,隱喻識別的方法逐步轉向利用文本表示學習來代替人工設計的特征向量的方法.此外,序列建模的方式也在隱喻識別中逐步流行.本文稱該階段的隱喻識別方法為樸素序列建模的方法.例如,Rei等人[8]提出一種詞對級別的隱喻識別方法,提出了第1個用于捕獲隱喻含義組合的神經網絡架構,并在MOH數據集[16]和TSV數據集[17]上進行測試.Gao等人[7]提出利用雙向長短期記憶網絡(long short-term memory,LSTM)做序列標注,并結合注意力機制實現詞級別分類的文本隱喻識別方法.Mao等人[6]提出結合2種語言學理論的神經網絡模型,針對SPV理論[18]設計了基于上下文和目標詞的多頭窗口注意力機制,針對MIP理論[19]設計了基于詞本意和語境含義的表示結合方法.雖然深度學習的方法可以避免大量的手工特征,但是樸素序列建模的方法忽略了在自然語言處理領域中長期積累并被廣泛證明有效的各類知識.
近年來,結合知識的方法在隱喻識別中取得了更好的性能.這類方法主要可以分為2種類型:1)通過引入其他任務中的知識來輔助隱喻識別.例如,Chen等人[9]提出利用2個數據集相互微調BERT模型[20],并利用習語檢測任務(idiom detection)的標注數據對BERT模型進一步微調.Su等人[10]提出利用孿生Transformer編碼器[21]編碼文本,并在閱讀理解任務的框架下利用預訓練的RoBERTa初始化模型權重[22],同時為每一個詞級別分類設計查詢文本和上下文文本,進而實現隱喻識別.這類方法在ACL2020會議的隱喻識別評測任務[23]中取得了靠前的排名.2)結合粗粒度句法知識的方法.例如,Rohanian等人[11]提出使用多詞表達式(multiword experssion,MWE)結構信息結合省略類別的句法信息,利用圖卷積神經網絡[24]進行編碼,從而實現隱喻識別.該類方法沒有考慮到詞級別義項知識在隱喻識別中的潛力,也忽略了句法信息中的細粒度信息對復雜語境建模的有效性.本文將從這2種類型入手,利用知識增強的圖編碼方法實現文本隱喻識別.
1.2 數據集構建
數據集構建在隱喻識別中是一個重要的研究方向,分為單語數據集構建和多語數據集構建2個方面.
在單語數據集方面,Steen等人[25]構建了VUAMC數據集,具有萬級的標注實例,被用于NAACL2018會議[12]和ACL2020會議[23]的隱喻識別評測任務中.Birke等人[13]基于《華爾街日報》的新聞內容構建了TroFi語料庫.Mohammad等人[16]針對動詞構建了一個句子級別的隱喻識別標注語料庫MOH,Shutova等人[5]在此基礎上針對“動詞–主語”和“動詞–賓語”對進一步標注了MOH-X數據集.Klebanov等人[26]利用240篇非英語母語作者完成的文章作為語料,標注了TOEFL隱喻識別語料庫,被用于ACL2020會議[23]的隱喻識別評測任務中.
在多語隱喻識別標注方面,Tsvetkov等人[17]針對“主語–謂語–賓語”三元組構建了一個句子級別的隱喻識別標注的語料庫,包含英語訓練集和英語、俄語、西班牙語、波斯語測試集.Levin等人[27]在這4個語種上,針對多種詞對級別,構建了隱喻識別標注語料庫CCM,包括“主語–動詞”“動詞–賓語”“動詞–副詞”“名詞–形容詞”“名詞–名詞”“名詞–復合詞”等類型.之后Mohler等人[28]構建了英語、俄語、西班牙語、波斯語的多種詞對級別的隱喻識別標注語料庫LCC,包括動詞、名詞、多詞表達式、形容詞、副詞之間的詞對.
此外,還有研究者針對隱喻現象中的屬性構建了數據集.例如,Parde等人[29]在VUAMC語料庫之上,針對有句法關系的詞對,標注了規模較大的隱喻重要性(metaphor novelty)語料庫.Tredici等人[30]探討了隱喻性與動詞分布特征之間的關系,引入語料庫衍生指標POM,標注了某個動詞所在的任何表達式的隱喻性上限.
為了與各類先進的隱喻識別方法進行對比,本文采用了被廣泛用于實驗對比的VUAMC數據集、TroFi數據集和MOH-X數據集進行實驗.
2 本文方法
在本節中,我們主要介紹基于知識增強的圖編碼方法在文本隱喻識別中的應用,將帶標簽的有向句法信息融入圖神經網絡中,并提出KEG模型.
2.1 基本定義
本文提出基于知識增強的文本隱喻識別圖編碼方法.本文用S={s1,s2,…,sn}表示長度為n個詞的句子.文本隱喻識別任務是為句子S中的每一個詞si計算一個0-1標簽yi,表示該詞是否為隱喻.
2.2 總體框架
圖1所示為KEG模型整體網絡結構,主要分為3 個部分:1)文本編碼層;2)圖網絡層;3)解碼層.對于一個句子S={s1,s2,…,sn},首先在文本編碼層中結合知識轉換為上下文向量序列Ec={ec1,ec2,…,ecn}和語義向量序列Es={es1,es2,…,esn},進而將兩者進行拼接得到詞表示序列E={e1,e2,…,en};接著構建句子S對應的信息圖GS,利用圖網絡層結合圖信息進行編碼,得到圖編碼向量序列Q={q1,q2,…,qn};最后利用解碼層對圖編碼向量序列進行解碼,獲取各個單詞對應的預測標簽Y={y1,y2,…,yn},其中yi∈{L,M}, L 表示不存在隱喻(literal), M 表示隱喻(metaphorical).
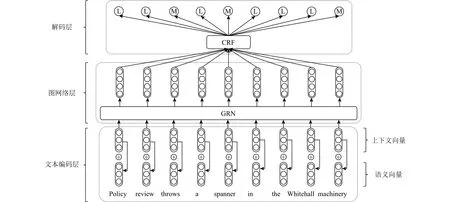
Fig.1 Overall network framework of KEG圖1 KEG整體網絡架構圖
2.3 文本編碼層
本文采用的語義表示分為上下文向量和語義向量2個部分.
2.3.1 上下文向量構建
預訓練語言模型在自然語言處理任務中十分廣泛,取得了良好的成績和明顯的效果.本文采用BERT模型[20]計算上下文向量.BERT模型是一個預訓練編碼器,由多層Transformer編碼層[21]堆疊而成.具體地,對于一個句子S={s1,s2,…,sn},首先進行詞塊(word piece)劃分;然后將詞塊序列輸入 BERT 模型,獲得最后一層Transformer編碼層的輸出向量序列作為詞塊上下文向量序列;最后取每個詞的第1個詞塊上下文向量作為該詞的上下文向量,從而形成句子S的上下文向量序列Ec={ec1,ec2,…,ecn}.
2.3.2 語義向量構建
語義向量構建如圖2所示.雖然上下文向量中蘊含了語境信息,但是缺少語義知識.本文利用語義知識對上下文向量進行增強,即利用WordNet中每個詞的義項標注信息訓練義項向量.本文繼承Chen等人[31]的方法,首先利用skip-gram算法[32]訓練詞向量,使用WordNet中每個義項的自然語言釋義文本中詞向量的平均值作為義項向量的初始值;然后利用義項 初 始 值 設 計 了 詞 義 消 歧(word dense disambiguation,WSD)模塊,用其在Wikipedia語料庫上產生詞義消歧結果;最后修改skip-gram的目標函數,從而重新訓練詞向量和義項向量.獲得預訓練的義項向量之后,對句子S中的每一個詞si通過詞根(lemma)匹配查找所有可能的義項,然后使用注意力機制根據上下文向量計算語義向量,具體的計算公式為
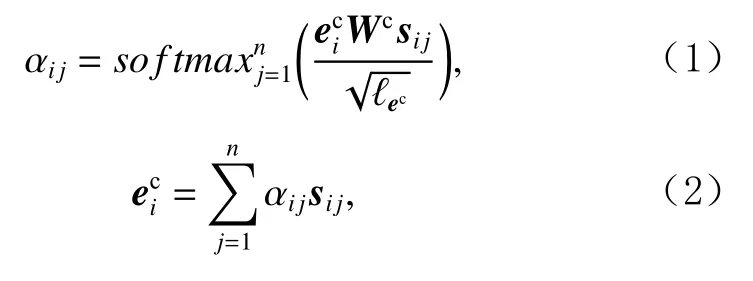
其中,Wc為模型參數, ?ec為上下文向量的維度, αij為義項向量的權重.
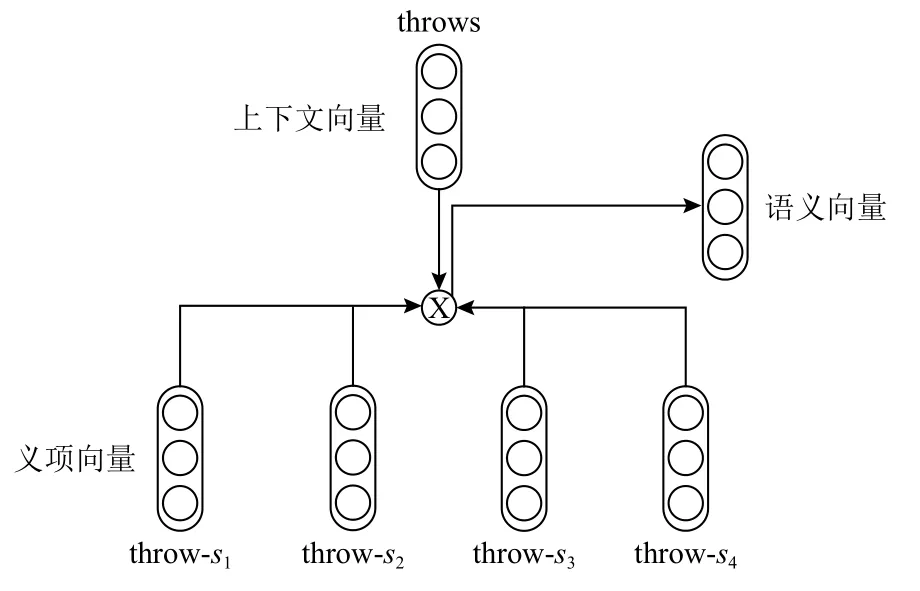
Fig.2 Structure of the encoding layer圖2 文本編碼層結構

其中 [⊕ ]為向量拼接操作.
2.4 圖網絡層
圖神經網絡作為編碼器在許多自然語言處理中有著很大的應用價值.其在自然語言處理領域的經典應用[11,33-34]中通常使用依存分析(dependency parsing)工具,將句子轉化成依存樹,以詞作為節點,使用粗 粒 度 句 法 知 識(coarse-grained syntactic knowledge)構建信息圖,進而指導圖神經網絡的信息傳遞.
由于堆疊圖神經網絡會導致模型參數增加,從而增加過擬合的風險,本文擴展圖循環神經網絡[35-36]作為圖網絡層的編碼器.一個圖循環神經網絡以一個圖的鄰接矩陣、詞表示e、 初始時刻的節點向量h0和全局向量g0作為輸入,利用多層之間參數共享的特性,經過K次迭代式狀態傳遞,輸出最終時刻的節點向量hK和全局向量gK.
同時,針對目前圖神經網絡方法在自然語言處理應用中僅僅利用到粗粒度句法知識的局限,本文提出將細粒度句法知識(fine-grained syntactic knowledge)與圖循環神經網絡(graph recurrent neural network)相結合的方法,首先利用邊感注意力機制(edge-aware attention mechanism)和邊綁定權重(edge-tied weight)進行細粒度上下文計算,接著利用圖循環神經網絡結合細粒度信息進行K次狀態傳遞.下面,本文將從圖構建、細粒度上下文計算和狀態傳遞3個方面介紹圖網絡層.
2.4.1 圖構建
首先為句子S={s1,s2,…,sn}構造一個信息圖GS.其中,節點為句子S中的詞,邊為詞之間的關系.本文繼承圖神經網絡在自然語言處理中的經典應用方法[11,33-34],利用句子S的依存樹TS作為信息圖GS的基本結構,并在圖中每個節點上增加了自環 [s elf].但是與傳統構圖方法不同的是,本文一方面保留了依存樹TS中邊的方向信息;另一方面在圖中加入了代表文本序列順序的邊 [s eq],從而將序列建模信息與句法信息相結合.信息圖GS的 鄰接矩陣中從節點i到節點j的有向邊
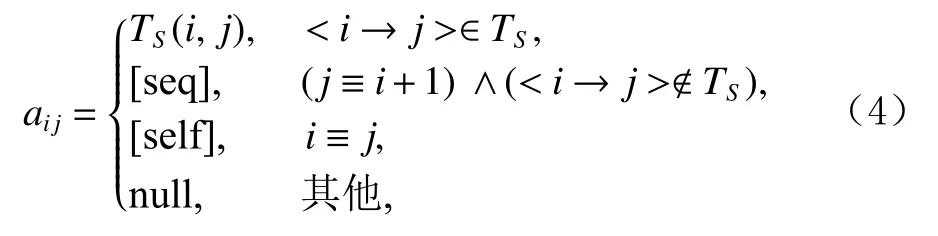
其中 n ull 表示有向邊
2.4.2 細粒度上下文計算
本節提出利用邊感注意力機制和邊綁定權重進行細粒度上下文計算,其中結合的細粒度句法知識包括有向信息和句法類別信息.具體地,本節將為句子S中的詞si構 造時刻t的傳入上下文向量和傳出上下文向量.
首先利用基于雙線性(bilinear)的邊感注意力機制分別計算傳入和傳出邊的權重和.
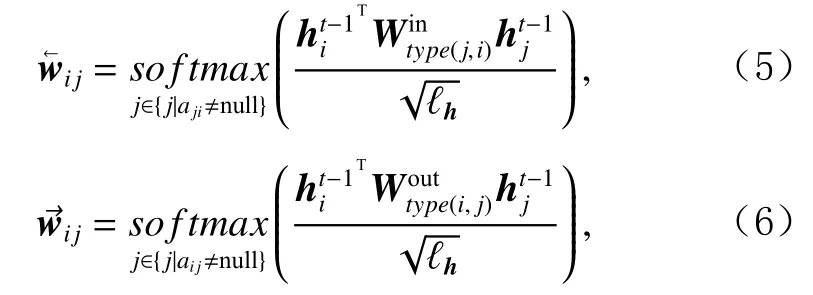
其中,Win和Wout為模型參數, ?h為節點向量ht?1的維度,type(i,j)表示信息圖GS中有向邊
接著,時刻t的傳入和傳出上下文向量和被表示為時刻t? 1的節點向量ht?1與有向邊類別權重k的帶權和.具體計算公式為
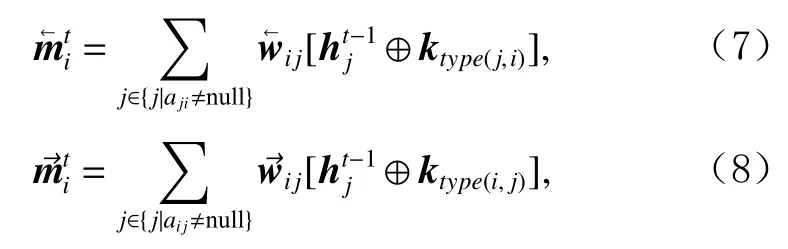
其中初始節點向量h0被初始化為零向量0.
2.4.3 狀態傳遞
本文擴展經典的圖循環神經網絡[35-36],結合細粒度上下文進行狀態傳遞.本文以時刻t? 1到時刻t為例進行說明.本文提出的圖網絡層分別采用2個門控循環單元[37](gated recurrent unit,GRU)作為節點向量ht和全局向量gt的更新框架.圖3為圖循環神經網絡的狀態傳遞示例圖.
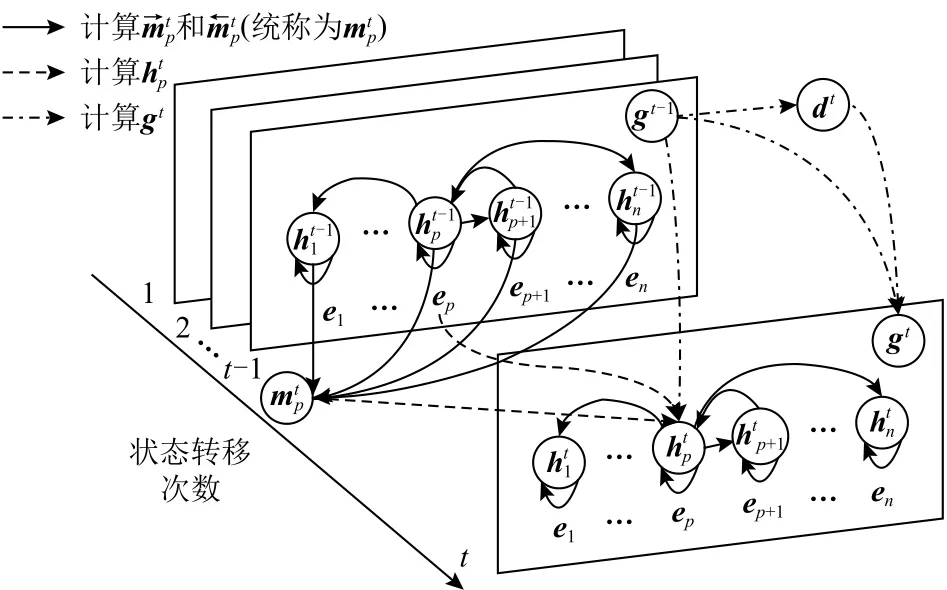
Fig.3 Layer structure of the graph recurrent neural network圖3 圖循環神經網絡層結構
為了更新句子S中詞si所 對應的的節點向量,首先將拼接詞表示ei、 細粒度上下文向量和、時刻t?1的全局向量gt?1得到含有更新信息的向量,然后 分別計算重置門和更新門的狀態,最后計算時刻t的節點向量具體更新過程為:
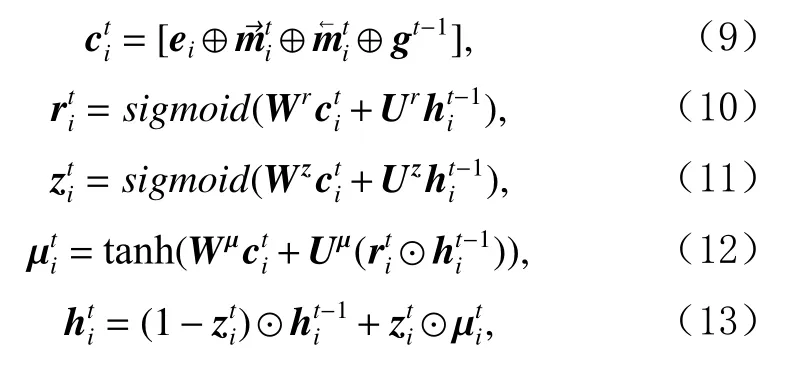
其中Wr,Ur,Wz,Uz,Wμ,Uμ為模型參數, ⊙ 為向量和矩陣的元素積(element-wise product)操作,初始全局向量g0也被初始化為零向量0.
相似地,本文為了更新句子S對應的全局向量gt,首先將節點向量求平均得到全局更新信息向量dt,然后分別計算重置門和更新門的狀態,最后計算時刻t的全局向量gt.具體更新過程為:
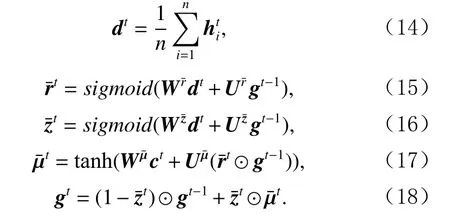
最終,經過K次狀態傳遞,圖網絡層輸出最終的節點向量hK和全局向量gK.
2.5 解碼層
由于任務目標是對句子S中每一個詞進行二分類判斷是否隱喻,最終本方法產生一個標簽序列本文采用條件隨機場(condition random field,CRF)[38]作為解碼層.
首先采用前饋網絡將圖網絡層輸出的每個詞所對應的最終節點向量轉化為輸出分值向量.解碼層中對一個標簽序列的評分為
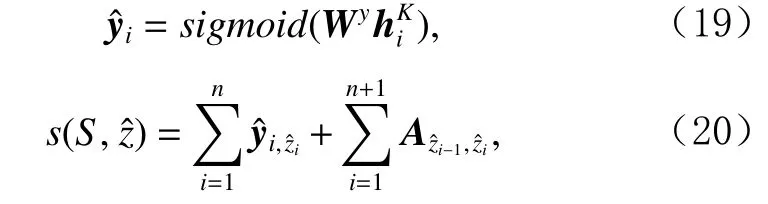
其中Wy和A為模型參數.為了描述得更具一般性和簡潔性,本文在序列的首尾加入了表示標簽序列開始和終結的特殊標志 [s tart]和 [e nd]作為和.
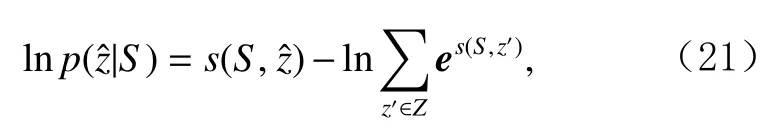
其中Z為包含所有可能的標簽序列的集合.在測試階段和驗證階段,通過維特比算法(Viterbi algorithm)對輸出標簽序列進行解碼.
3 實驗與分析
3.1 數據集
實驗中使用的數據集包括NAACL2018評測任務中使用的VUA-VERB和VUA-ALLPOS數據集[12]、TroFi數據集[13]和MOH-X數據集[5].數據統計信息如表2所示,包括數據集中單詞(token)總數、數據集中句子總數、標注為隱喻的數量、標注為隱喻的數量占所有標注結果中的百分比、平均每個句子中的單詞數.在實驗中按照相關工作[6-7,9-12,23]對VUA-VERB和VUA-ALLPOS數據集進行訓練集、開發集、測試集劃分,并在TroFi和MOH-X數據集上進行10折交叉驗證.

Table 2 Statistics of Datasets表2 數據集統計信息
VUA-VERB和VUA-ALLPOS數據集[12]分別源于依照MIP規則[19]對句子為單位所標注的VUAMC阿姆斯特丹隱喻語料庫[25],具有超過2000個被標注為隱喻的不同詞匯.NAACL2018會議的隱喻識別評測任務[12]首次基于VUAMC語料庫設置了VERB和ALLPOS這2個賽道,并分別形成了VUA-VERB和VUA-ALLPOS數據集,并被沿用于ACL2020會議的隱喻識別評測任務[23]中.
TroFi數據集[13]是由包含1987—1989年《華爾街日報》新聞內容的第1版WSJ語料庫[39]中的句子組成,標注人員針對每個句子中的動詞進行了隱喻標注.TroFi數據集只有50個被標注為隱喻的不同詞匯,且其中句子的平均長度是本文所采用的數據集中最長的.
MOH-X數據集[5]來源于MOH數據集[16],其中的句子來自WordNet中義項的例句.在該數據集中,標注人員針對每個句子中的“動詞–主語”對和“動詞–賓語”對進行了隱喻標注,得到了214個不同的詞匯.MOH-X數據集中句子的平均長度是本文所采用的數據集中最短的.
3.2 實驗設置及超參數
本文所提出的模型在實驗中所使用的超參數均由在VUA-VERB的測試集上針對F1值的格搜索(grid search)得出,具體數值如表3 所示.
模型采用BERT-Large的權值初始化上下文向量構建模塊,并在訓練時采用學習率熱身(warm-up)方法,即總共訓練50個回合(epoch),在前5個回合中,模型各部分的學習率從0開始線性增長至最大值,并在之后的回合中線性衰減至0.本文采用AdamW算法[40]對參數進行優化.在后續的實驗中,為了保證公平起見,根據開發集上的評測結果選擇一組F1值最高的模型參數,然后在測試集上評測使用了這組參數的模型并記錄各項指標.為了減少模型中隨機種子對結果的影響,后續實驗結果表格中的值為3次運行結果的平均值.
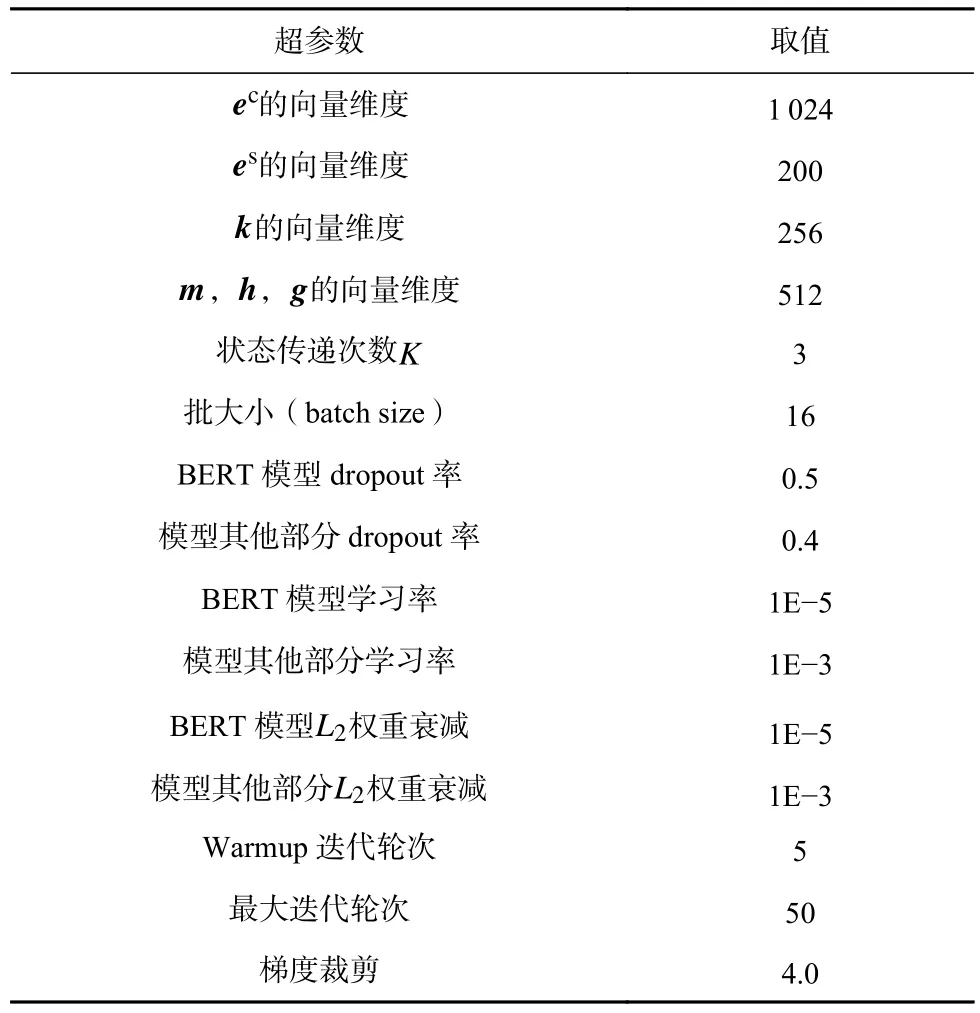
Table 3 Hyper-Parameters Used in Our Experiment表3 本文實驗中使用的超參數
3.3 評價指標
與相關工作[6-7,9-12,23]相同,本文采用精確率(precision,P)、召回率(recall,R)、F1 值和準確率(accuracy,Acc)作為實驗的評價指標.
對測試集中的每一個標注結果,本文提出的模型會對其進行二分類,產生一個預測結果.將標注結果與預測結果一致,且為隱喻的詞數量記為TP,不為隱喻的詞數量記為TN;標注結果與預測結果不一致,且預測結果為隱喻的詞數量記為FP,不為隱喻的詞數量記為FN.則精確率P、召回率R、F1值、準確率Acc分別計算得到:

3.4 KEG與SOTA方法比較
為了驗證本文提出的KEG模型的有效性,本文設置3組對比模型,包含了3類SOTA方法.
第1組是樸素序列建模的方法,其中的模型均未采用詞級別義項知識或句子級別細粒度句法知識,具體模型為:
1)RNN_ELMo[7]將GloVe向量[41]和 ELMo 向量[42]拼接作為詞級別特征,使用雙向LSTM進行編碼,對輸出的隱狀態采用softmax分類器進行序列分類.
2)RNN_BERT[20]依照RNN_ELMo的序列分類框架,將BERT-Large模型后4層輸出向量作為特征.
3)RNN_HG[6]在 RNN_ELMo 模 型的基礎 上 ,在利用雙向LSTM對詞級別特征進行編碼之后,將雙向LSTM輸出的隱狀態與GloVe向量拼接,然后采用softmax分類器進行序列分類.
4)RNN_MHCA[6]在 RNN_ELMo模型的基礎上強化了softmax分類器的輸入,利用多頭注意力機制為雙向LSTM輸出的隱狀態計算了上下文向量,并將它們拼接后輸入softmax分類器.
第2組是采用其他任務的知識來輔助增強隱喻識別的方法,具體模型為:
1)Go Figure![9]是在 ACL2020 會議的隱喻識別評測任務[23]中VUA榜單排名第2的模型,采用基于微調預訓練BERT模型的多任務架構,將習語識別作為輔助任務,引入其他修辭語言(figurative language)識別任務的知識,通過學習到更具一般性的BERT參數增強隱喻識別的效果.
2)DeepMet-S[10]是一個基于 RoBERTa[22]的閱讀理解(reading comprehension)式隱喻識別模型,其多模型集成(ensemble)的結果在ACL2020會議的隱喻識別評測任務[23]中VUA榜單排名第1.DeepMet-S將需要被識別的句子作為上下文,為句中每一個需要進行隱喻識別的詞建立了問題提示(prompt),利用其他任務的知識進行隱喻識別.
第3組是結合粗粒度句法知識的方法,具體為:
1)GCN_BERT[11]首先利用預訓練BERT模型對詞進行編碼,然后利用粗類別依存分析結果結合注意力機制為句子構建了僅含無類別邊的信息圖,并采用圖卷積神經網絡[24]進行編碼.
2)MWE[11]在GCN_BERT的基礎上,利用額外的圖卷積神經網絡[24]編碼了屬于粗類別句法知識的多詞表達式結構信息,并與原網絡的編碼進行拼接.
表4展示了本文提出的KEG模型與上述3組SOTA模型的對比結果.
在第1組對比實驗中,與樸素序列建模方法進行比較,KEG模型在4個數據集上均取得了更高的F1值,在除VUA-ALLPOS數據集之外也取得了更高的準確率.相比于RNN_HG和RNN_MHCA,在F1值方面分別提升了 8.1,1.2,4.3,1.8個百分點.這體現了知識增強的圖編碼方法相對樸素序列建模方法有助于提升隱喻識別的性能.樸素序列建模方法僅依靠詞向量將文本轉化為輸入向量,雙向LSTM進行序列建模,會出現長距離依賴關系難以捕獲的問題.而KEG不僅豐富了輸入向量,也利用句法知識和信息圖能更直接捕獲到文本中的依賴關系,是樸素序列建模方法不具備的優勢.
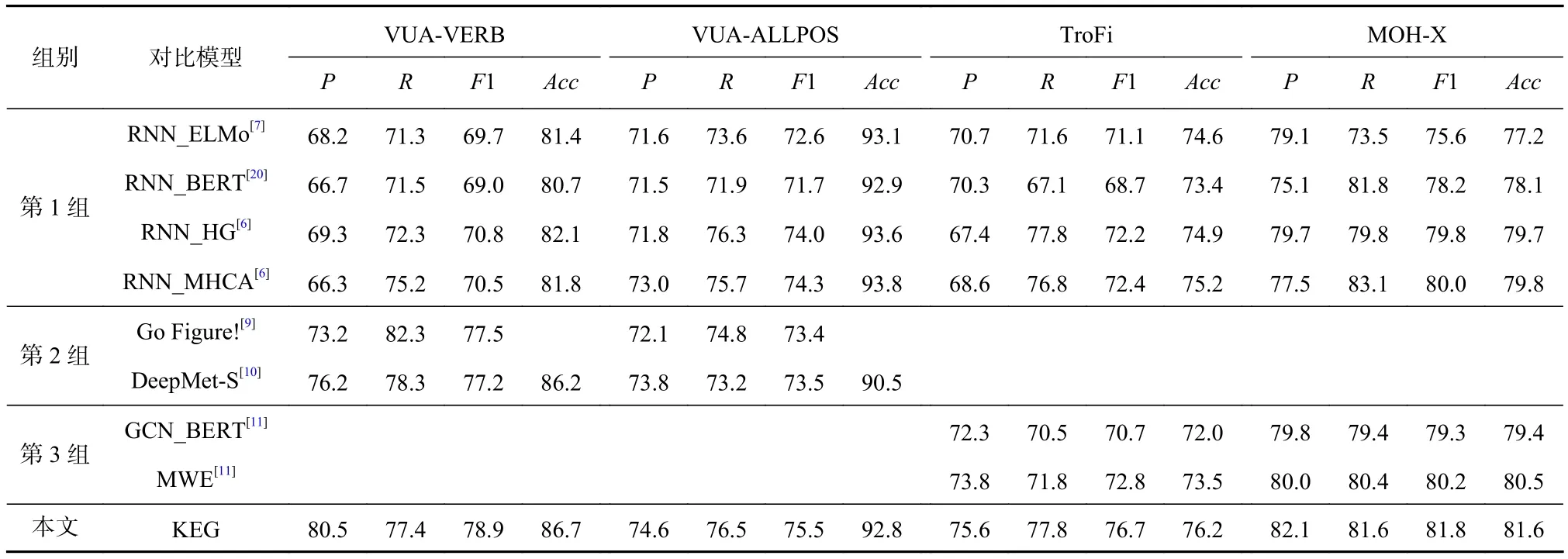
Table 4 Experimental Results of KEG and SOTA Methods表4 KEG與SOTA方法對比的實驗結果 %
在第2組對比實驗中,還比較了采用其他任務知識來增強隱喻識別的方法.從實驗結果來看,第2組中結合知識的方法在VUA-VERB上明顯優于第1組中的樸素序列建模方法.此外,相比結合習語識別進行多任務建模的Go Figure!模型,KEG在VUA-VERB和VUA-ALLPOS上的F1值分別提升了1.4和2.1個百分點.相比于閱讀理解架構的DeepMet-S,KEG在VUA-VERB和VUA-ALLPOS上的F1值分別提升了1.7和2.0個百分點.這表明結合知識是可以有效提升隱喻識別的性能,而且本文提出的KEG引入詞級別和句子級別2方面的知識在VUA-VERB和VUAALLPOS數據集上可以取得更優的效果.
在第3組對比實驗中,比較了結合粗粒度句法知識的方法.KEG在TroFi和MOH-X上均取得了更優的F1值和準確率.MWE的各項指標均高于GCN_BERT.相比于MWE模型,KEG分別在F1值方面提升了3.9和1.6個百分點,在準確率方面提升了2.7和1.1個百分點.MWE和GCN_BERT均基于堆疊的圖卷積神經網絡進行隱喻識別,僅利用句法分析中的無向關系構建信息圖,還舍棄了細粒度的類別信息.本文提出的KEG擴展了圖循環神經網絡架構進行圖編碼,利用循環迭代的方式達到堆疊圖卷積神經網絡的目的,包含更少的參數,降低了過擬合的風險.此外,KEG可以建模細粒度的句法知識,對信息的利用率更高.KEG還利用詞級別義項知識豐富了輸入向量,是MWE所不具備的優勢.
綜上可見,本文提出的KEG模型優于對比的3類SOTA方法,本文提出的詞級別義項知識和細粒度句法知識應用于隱喻識別任務具有一定的優越性.
3.5 狀態傳遞次數K對比分析
狀態傳遞次數K是本文提出的KEG模型中的一個重要超參數.為了驗證狀態傳遞次數對實驗結果的影響,在3.4節的實驗基礎上,本節設置不同的狀態傳遞次數K值,得到不同的實驗結果,如表5所示:
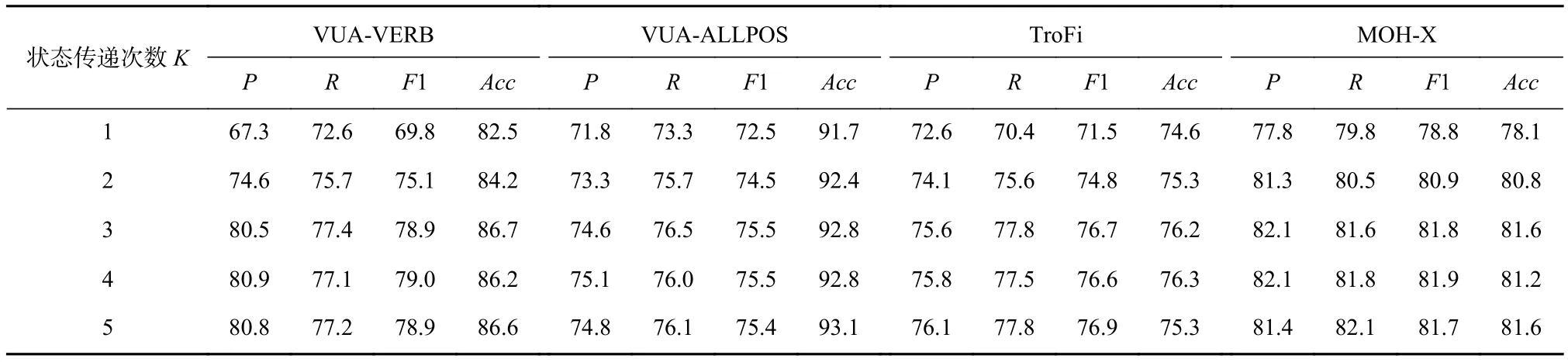
Table 5 Experimental Results With Different State Transition Times表5 對比不同狀態傳遞次數的實驗結果%
實驗結果表明,當狀態傳遞次數K從1增大到3時,在4個數據集上的F1值和準確率均有所提升,其中F1值提升了9.1,3.0,5.2,3.0個百分點,準確率提升了 4.2,1.1,1.6,3.5個百分點.增大狀態傳遞次數K可以使模型學習到句子中距離更長的依賴關系,這證明了在一定范圍內增加狀態傳遞次數有利于提升模型的性能.當狀態傳遞次數K從3增大到5時,在4個數據集上的F1值和準確率并沒有觀察到明顯提升.而且增大狀態傳遞次數K會導致模型運行所需時間變長.所以,實驗中的狀態傳遞次數K并不是越大越好.由于在4個數據集上,狀態傳遞次數K= 3時取得了較優的F1值和準確率,并且在K> 3時評價指標均無明顯提升.考慮到模型運行時間,本文在所有數據集上統一選擇了狀態傳遞次數K= 3時的實驗結果作為KEG性能的對比和分析.
3.6 上下文向量對比分析
本文提出的KEG方法中構建了上下文向量.為了驗證上下文向量對實驗結果的影響,本文在KEG的基礎上分別使用word2vec[32](記為KEG-word2vec),GloVe[41](記為KEG-GloVe),ELMo[42](記為KEG-ELMo)算法訓練的詞向量替換上下文向量,與使用BERT構建上下文向量的KEG進行對比,實驗結果如表6所示.
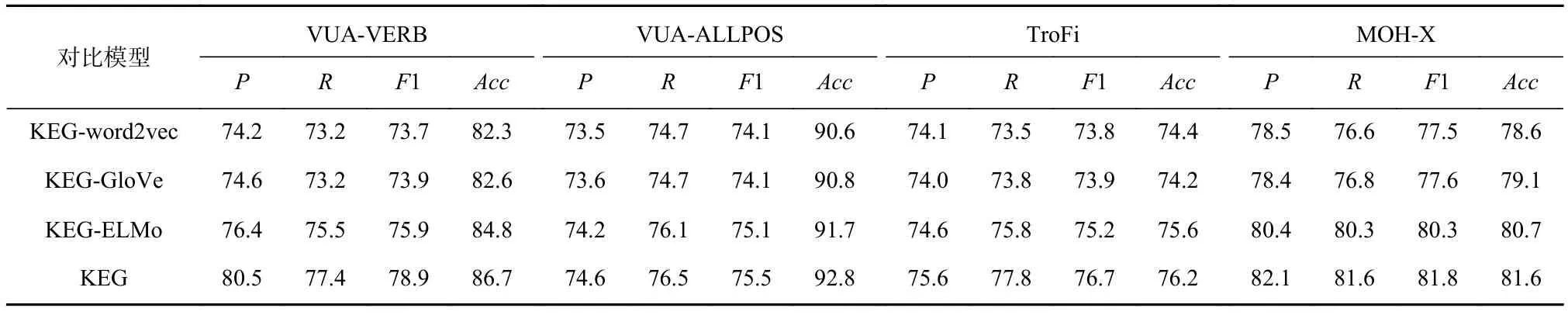
Table 6 Experimental Results of Constructing Word Vectors and Context Vectors表6 詞向量和上下文向量構建方法的實驗結果 %
根據實驗結果,使用BERT構建上下文向量的KEG相對于使用word2vec訓練詞向量的方法,在4個數據集上均有性能提升,F1值提升了5.2,1.4,2.9,4.3個百分點,準確率提升了 4.4,2.2,1.8,3.0個百分點.原因在于,KEG-word2vec通過靜態查表的方式將每個詞轉化為對應的詞向量,同一個詞在不同上下文中產生的詞向量相同;而KEG則利用BERT中的編碼器動態地根據上下文的內容實時計算一個向量表示,具有更強的編碼能力.
對比KEG-word2vec和KEG-GloVe可以發現,這2個模型在4個數據集上的性能相差不多,F1值和準確率的差距均不超過0.5個百分點.經過分析,這2個模型相似,都采用了靜態查表轉化詞向量的方式,產生相同維度的詞向量,并在訓練過程中對詞向量進行微調.
若將BERT方法替換為ELMo方法構建上下文向量,在4個數據集上的性能有所下降,F1值下降了3.0,0.4,1.5,1.5 個百分點,準確率下降了 1.9,1.1,0.6,0.9個百分點.KEG與KEG-ELMo相比,使用的編碼器參數更多,產生的上下文向量維度更大,進而有利于對上下文建模.
3.7 詞級別義項知識對比分析
為了驗證詞級別義項知識對實驗結果的影響,本文在KEG的基礎上去掉利用詞級別義項知識構造的語義向量(記為KEG-NOS),實驗結果與KEG進行對比,如表7所示:

Table 7 Experimental Results of KEG With and Without Lexicon Word Sense Knowledge表7 KEG有無詞級別義項知識的實驗結果 %
從表7分析可知,在KEG基礎上去掉利用詞級別義項知識構造的語義向量,在4個數據集上都出現了性能下降,其中F1值下降了 8.4,2.7,4.4,3.0個百分點,準確率下降了 4.0,0.7,0.8,2.8個百分點.由此可見,引入詞級別義項知識有助于隱喻識別.其原因在于,詞級別義項知識歸納了每個詞常用的幾種義項,并通過訓練詞義向量的方式,將常用的義項編碼成向量.進而通過注意力機制在當前上下文環境下對各義項進行加權,利用義項知識對上下文表示進行補充,具備更強的語境表現力,從而有助于隱喻識別的性能提升.
3.8 細粒度句法知識對比分析
本文提出的KEG方法中為了指導圖神經網絡的信息傳遞,引入了細粒度句法知識來構建信息圖.為了驗證細粒度句法知識對實驗結果的影響,本文設置了2組對比實驗:在第1組中,在KEG的基礎上,采用圖神經網絡經典應用[11,33-34]中利用粗粒度句法知識的方法構建信息圖(記為KEG-CSK);在第2組中,采用無向完全圖(undirected completed graph)作為信息圖(記為KEG-UCG),實驗結果對比如表8所示.
由表8可見,對比KEG-CSK與KEG,利用粗粒度句法知識的方法構建信息圖會在4個數據集上造成性能下降,其中F1值下降了 8.0,3.8,4.8,3.6個百分點,準確率下降了 5.4,2.6,1.5,3.3個百分點.通過分析,相對于KEG-CSK,本文提出的KEG中利用細粒度句法知識涵蓋了更為細致的信息,即有向邊和細粒度的邊類型標簽,并且通過KEG中的邊感注意力機制和邊綁定權重實現了在每次狀態傳遞中有向邊貢獻的計算,進而從出、入2個視角分別計算了上下文表示向量,具有更強的語境建模能力,有助于提升隱喻識別性能.

Table 8 Experimental Results of KEG With and Without Fine-Grained Syntactic Knowledge表8 KEG有無細粒度句法知識的實驗結果 %
另一方面,通過對比KEG-CSK和KEG-UCG可以發現,利用句法知識構建信息圖比直接利用完全圖作為信息圖時的性能更好,F1值提升了1.6,0.9,0.6,1.0個百分點,準確率提升了 0.7,0.8,0.7,1.2個百分點.經過分析,利用完全圖作為信息圖時,由于沒有考慮到不同邊的貢獻可能不同,經過多次狀態傳遞之后,各點的節點向量會趨于相似,喪失了其表示的獨立性.利用粗粒度句法信息構建信息圖以先驗知識指導的形式對完全圖進行剪枝,刪除了在狀態轉移中作用小的邊,保護了節點向量的獨立性,進而產生了更好的性能.這證明了計算信息圖中邊貢獻的必要性和融入句法知識對性能提升的有效性.
3.9 解碼方式對比分析
本文提出的KEG方法中采用了條件隨機場作為解碼層.為了驗證解碼方式對實驗結果的影響,本文按照文獻[7]中提出的位置分類架構,在KEG的基礎上,將一個序列的解碼拆分成多次給定位置的預測(KEG-C).具體地,在單次給定位置的預測中,首先在模型的文本編碼層加入位置向量,并在解碼時采用注意力機制,針對給定位置計算了所有詞的最終節點向量的加權和,進而利用類似式(19)的方式計算輸出分值進行訓練和測試.本節中將預測給定位置的KEG-C與序列解碼的KEG進行對比,對比實驗結果如表9所示:

Table 9 Experimental Results of Two Decoding Methods表9 2種解碼方式的實驗結果%
從表9可以看出,利用序列解碼的KEG比預測給定位置的KEG-C在4個數據集上的性能方面稍顯優勢,F1 值提升了 0.5,0.6,0.7,0.2個百分點,準確率提升了 0.2,0.6,0.3,0.1個百分點.經過分析,在訓練時,KEG利用序列解碼的方式將序列標簽作為整體進行優化,將多個位置的標簽監督信號聚合之后進行梯度下降;而KEG-C中的預測給定位置的方式在優化過程中顯得較為分散,所以可能需要更長的訓練時間才能達到與KEG相似的性能.但是由于使用的數據集規模相同,僅僅延長訓練時間可能會增大模型過擬合的風險.因此,在這種情況下,采用序列解碼的方式有助于模型學習到更健壯的監督信號,從而有助于隱喻識別.
4 結 論
本文提出一種基于知識增強的文本隱喻識別圖編碼方法.該方法包含3個部分,分別是文本編碼層、圖網絡層和解碼層.在文本編碼層,利用了預訓練語言模型計算輸入文本的上下文向量,與通過skipgram和詞義消歧共同訓練得到的詞義向量進行拼接,融合了詞義項知識,增強了語義表示.在圖網絡層,相比于傳統圖神經網絡建模文本的方法,構造了引入細粒度句法知識的信息圖,并設計了邊感注意力機制和邊綁定權重計算細粒度上下文;結合圖循環神經網絡進行迭代式狀態傳遞,并通過多層之間參數共享的特性,降低了模型參數,降低了過擬合的風險,有助于有效建模復雜語境.在解碼層,利用了條件隨機場對序列標簽進行計算.實驗證明,本文提出的方法在4個國際公開數據集上性能均有提升.
作者貢獻聲明:黃河燕指導并修改論文;劉嘯提出了算法思路和實驗方案,完成實驗并撰寫論文;劉茜提出算法和方案指導意見并修改論文.
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
