基于改進MFCC融合特征及FA-PNN的駕駛員路怒情緒識別
2023-01-29 13:27:00李尚卿王曉原
計算機工程與應用 2023年2期
李尚卿,王曉原,2,張 楊,李 浩,項 徽
1.青島科技大學 機電工程學院,山東 青島266000
2.青島科技大學 智能綠色制造技術與裝備協同創新中心,山東 青島266000
在已有的交通事故致因分析中,有研究表明人為因素占到90%以上[1],在人為因素中,“路怒”正是造成交通事故的重要原因之一,其用以形容在交通阻塞情況下開車壓力與挫折所導致的憤怒情緒[2],既有研究表明,我國約有60.72%的機動車駕駛員有“路怒”的經歷[3]。語音是表達情緒信息的重要載體,在語音情感識別領域,高效的語音特征和適合的識別模型一直是較熱門的研究方向。語音的聲學特征分為兩類:時域和頻域特征,普遍使用的時域特征有音高、短時能量、短時過零率、平均幅度、諧波噪聲比、自相關系數等;頻域特征有共振峰頻率、Mel頻率倒譜系數(MFCC)、線性預測倒譜系數(LPCC)、線譜對(LSP)等;Sato等人[4]使用基于MFCC的情感識別系統證明了頻域特征比時域特征對于情感識別具有更好的準確率。Bozkurt等人[5]計算了共振峰位置信息并與MFCC進行融合,在柏林數據庫上得到了16.5%的識別率。Milton等人[6]將MFCC、音調、共振峰等特征組合,在柏林數據庫、Savee數據庫、Enterface數據庫上得到了82.8%、56.3%和74.3%的準確率。Ton-That等人[7]介紹了一種語音情感分類的方法,根據MFCC特征,基于模糊推理方法進行語音情感的識別。Ancilin等人[8]利用幅值譜代替能量譜,改進MFCC特征參數進行語音情感識別,在烏爾都語數據庫中識別率達到95.25%。既有的研究表明通過將梅爾頻率倒譜系數進行改進或與其他特征融合,情感識別率得到了提高。基于此,本文以路怒情緒為研究對象,利用模擬駕駛系統建立數據集,分析駕駛員語音的頻譜特性,將短時能量及短時過零率和改進MFCC特征融合構成特征參數向量。
獲得特征參數后,利用模型對情感進行識別。目前常用的識別模型主要有支持向量機(support vector machine,SVM)、近鄰算法(K-nearest neighbor,KNN)、BP神經網絡(back propagation,BP)、概率神經網絡(PNN)、學習向量化神經網絡(learning vector quantization,LVQ)等。Shahin等人[9]證明神經網絡算法比SVM識別準確率提升4.6%。Mohanty等人[10]證明PNN在情緒識別領域具有顯著優勢。Pawar等人[11]證明神經網絡算法相對于近鄰算法更好的性能評估。螢火蟲算法(FA)是2009年Yang教授提出的一種啟發式算法。Huang等人[12]構建了基于螢火蟲算法優化徑向基神經網絡(radial basis function neural network,RBFNN)的嵌入式系統,結果表明系統控制性能更優。Bacanin等人[13]利用螢火蟲算法尋找卷積神經網絡超參數,提高軸向腦腫瘤圖像分類的效率。既有的研究表明,在語音情感識別領域,神經網絡算法分類性能更好,同時,螢火蟲算法優化神經網絡可以提高準確率和魯棒性。基于此,本文利用螢火蟲算法(firefly algorithm,FA)優化概率神經網絡(PNN),建立一種駕駛員路怒情緒識別模型,在Matlab R2019a環境下利用實測數據對模型進行驗證及對比分析。
1 語音數據集的構建
1.1 采集裝備、對象及數據要求
本研究語音數據集在駕駛員路怒情緒以及非路怒情緒下進行采集,考慮到路怒情緒下駕駛員駕車具有一定的危險性,所以組織模擬駕駛實驗。交互式模擬駕駛系統由力反饋方向盤、擋桿、駕駛座椅器以及Assetto Corsa軟件構成,如圖1。本實驗對于實驗人員條件要求以及音頻數據的格式要求如表1。

圖1 交互式模擬駕駛系統Fig.1 Interactive driving simulation system

表1 實驗要求規范Table 1 Experimental requirements and specifications
1.2 實驗內容
對40名實驗對象按照從1~40的序號進行編號,對實驗對象進行模擬駕駛訓練,使其能夠熟練操控模擬駕駛系統。在模擬駕駛實驗開始之前,從網絡上收集真實駕駛情況下行車記錄儀記錄的路怒視頻中駕駛員的話語,各取頻率出現最高的50句話,形成實驗誘發情緒的文本材料[14]。
本文采用的情緒誘發方法為組合情感誘發方法[15]。一種為虛擬現實情感誘發法[16],另一種文本材料誘發法,能夠輔助刺激鞏固誘發的情緒,避免駕駛員在實驗過程中由于情緒消散導致采集的實驗數據不準確。
模擬駕駛實驗中,利用虛擬的駕駛環境激發駕駛員的憤怒情緒,其具體的實現方式為:每次駕駛實驗安排2名駕駛員,其中模擬駕駛座椅的實驗者為主要測試者,輔助測試者的作用是在實驗過程中,對主要研究對象的車輛做出強行變道、加塞、時快時慢駕車等行為[17],目的是誘發主要研究對象的憤怒情緒并保持。文本材料由平板顯示在顯示器下方,保持在駕駛員視線范圍之內,輔助刺激主要研究者的路怒情緒。對于非路怒情緒采用音樂情緒誘發法,所用音頻取自中國情緒刺激材料庫中的中國情緒音樂材料庫(CAMS)。
本實驗是對40名實驗對象依次進行實驗,實驗過程中,以主要研究對象誘發出的話語為次數基準,每個主要研究對象兩類情緒誘發次數都不少于25次,采集到2 000份樣本數據。最后,每個主要研究對象對自己的音頻進行自我評價并標注情感類型。針對研究者可能存在不準確的主觀評價,本研究利用聽辨評判法保證數據集標注的可靠性,每條樣本由5名未參與實驗的人員進行評判。
1.3 類別標注
在本研究的評判方法中,采用度量值為1、3、5、7、9五個等級表達情感的強度,分別為極弱、較弱、一般、較強、極強。每個聽辨人對數據樣本都會給出一個評判的結果為評判值。本方法融合所有聽辨人的評判結果,利用加權融合的準則得到每個樣本的最終評判結果,并作為最終情感標注。公式如式(1):

式中,gr為聽辨人評判結果的融合權重;為情感樣本;R為聽辯人總數,R=5;r為聽辨人。計算融合權值gr,先計算聽辯人間的相似性ρpq,再得到一致度矩陣ρ,根據矩陣計算平均一致度ρˉr,歸一化后即可得到,公式如下:
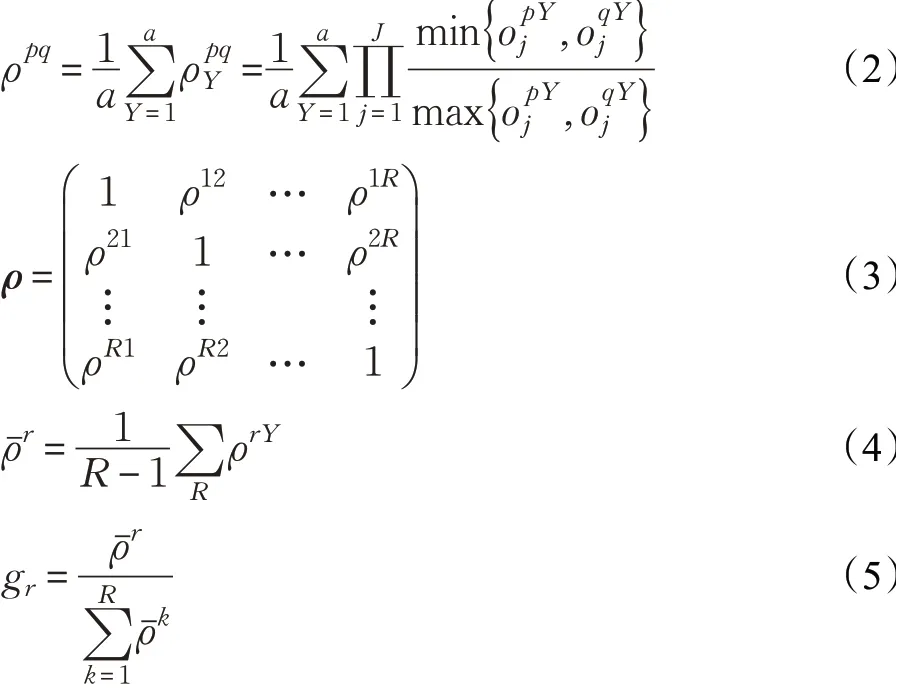
式(2)中,p、q為兩個聽辨人;J為情感類別種類,J=2;a為樣本總數,a=2 000。本研究得到的語料庫中有2 000個樣本,其中路怒情緒樣本和非路怒數據各1 000個。
2 特征分析方法
2.1 頻譜特征分析
本文以三維聲譜圖對駕駛員語音信號進行分析。聲譜圖從時間、頻率以及能量強度三個維度描述信號語音信號的特征。圖2給出了路怒和非路怒情緒下具有代表性的三維聲譜圖。
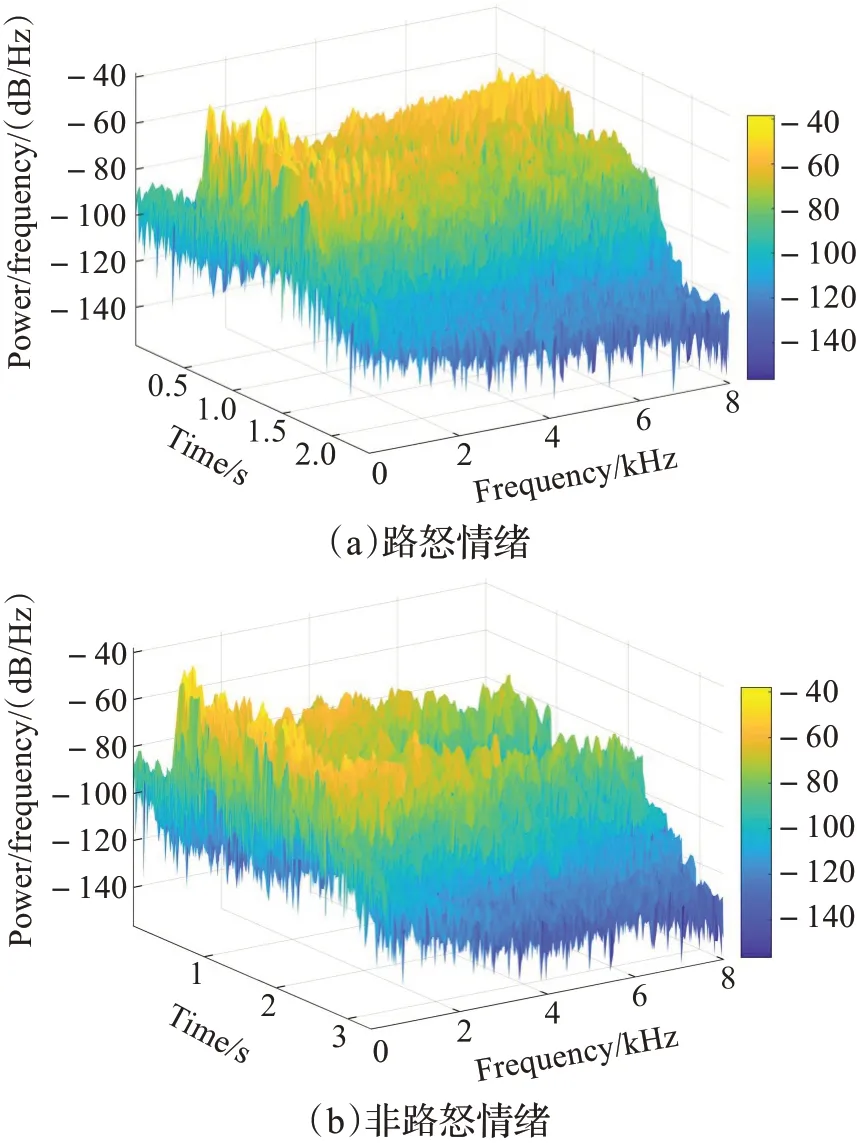
圖2 路怒及非路怒情緒下的語譜圖Fig.2 Spectrum of road rage and non-road rage
通過分析發現:駕駛員非路怒情緒下的頻率能量集中分布于1 000~4 000 Hz,而路怒情緒下的頻率能量集中分布于2 000~8 000 Hz,說明不同情緒的頻率集中分布范圍差異較大,從而能量分布和豐富度也相差較大,同時,反應出非路怒情緒下語音信號的能量變化相對平穩,相鄰兩幀信號之間的相似度高。
2.2 特征提取
2.2.1 預處理
預加重,根據上述頻譜特征得出路怒情緒語音的頻率能量大部分集中于2 000~8 000 Hz,頻率高于2 000 Hz時會有10 dB的衰減,通過預加重能補償高頻能量,其函數如式(6):

其中,n為信號,μ∈[0.9,1],一般情況下取μ=0.95。
分幀加窗,由于音頻的短時平穩性[18],可以對信號分幀處理,通常每秒取33~100幀,幀的長度一般為10~30 ms[19],同時采用交疊分段的方法,保持音頻信號的連續性,用窗函數w(n)乘以原始信號s(n),形成分幀加窗后的音頻信號為sw(n)=s(n)*w(n),本文采用漢明窗,窗函數公式如式(7):

式中,N為幀長,0≤n≤N-1。
2.2.2 短時能量

短時能量(short time energy)是指語音中的能量以幀數為單位的量值,假定當前為第i幀,則該幀音頻信號的短時能量公式如式(8):其中,si(n)是第i幀預處理后的音頻信號,N為幀長,E(i)為第i幀音頻信號的短時能量值。如圖3中所示,路怒情緒下的語音和非路怒情緒下的語音能量幅度相差明顯,本研究取每個樣本短時能量的最大值、最小值、均值、方差為特征參數。
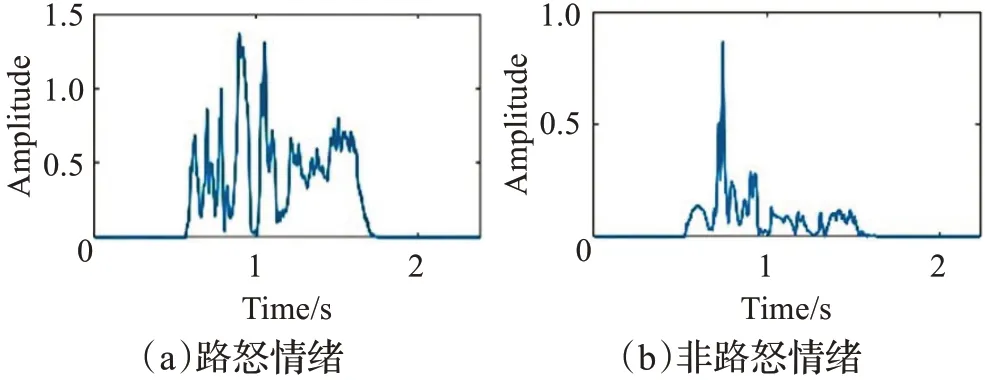
圖3 路怒及非路怒情緒下的短時能量Fig.3 Short-term energy in road rage and non-road rage
2.2.3 短時過零率
短時過零率(short time zero crossing rate)表示信號在波形中穿過橫軸(零點)的次數,如圖4所示,路怒情況下語音過零的次數明顯多于非路怒情況,本研究取每個樣本的最大短時過零率值為特征參數,短時過零率公式如式(9):
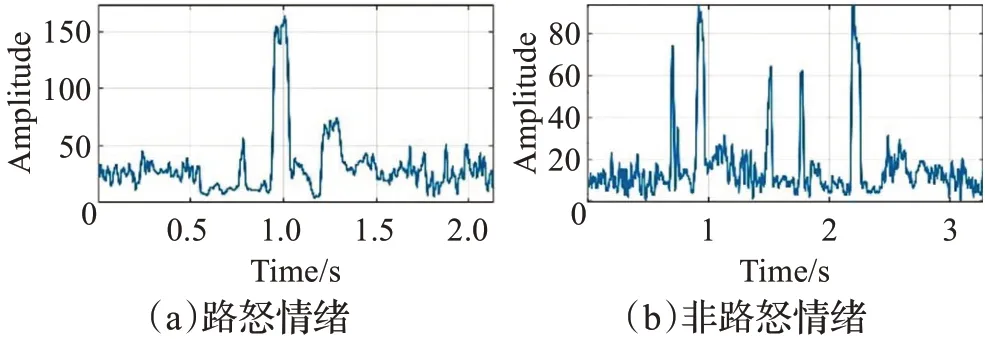
圖4 路怒及非路怒情緒下的短時過零率Fig.4 Short-time zero crossing rate of road rage and non-road rage
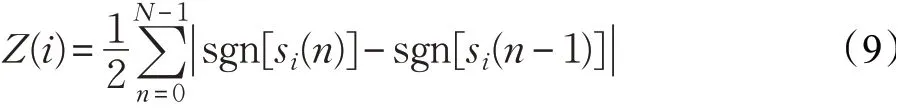
式中,音頻信號沒有負值,sgn[*]是符號函數,如式(10):

2.2.4 MFCC的改進及提取
MFCC(Mel frequency cepstral coefficients)梅爾頻率倒譜系數,是語音信號處理中最為常用的特征參數。傳統MFCC中,通過求其一階差分來描述不同幀數的動態變化,但是只能獲得有限的動態特性,不能充分獲取信號的動態特征。針對這個問題,本文利用經驗模態分解(empirical mode decomposition,EMD)將音頻信號按照時間尺度自適應分解,得到若干個本征模函數(intrinsic mode function,IMF)分量。改進MFCC特征提取流程如圖5,具體步驟如下:
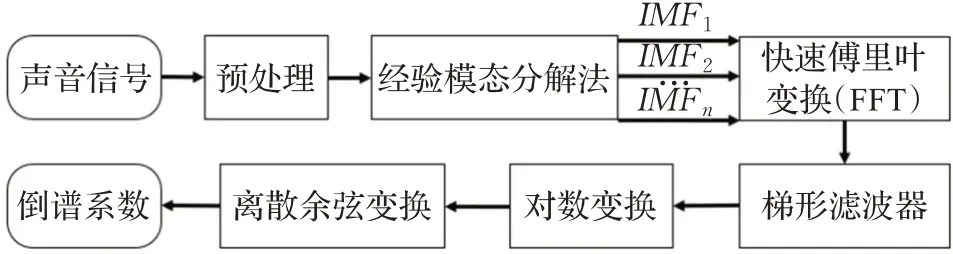
圖5 改進MFCC特征提取流程圖Fig.5 Flowchart of improved MFCC feature extraction
預處理后得到信號Si(n),其中下標i表示分幀加窗后的第i幀。
(1)確定語音信號Si(n)的局部極大值和極小值點,得到上下包絡線z1(n)和z2(n),計算h(n),公式如式(11):

其中,m1(n)為上下包絡線的均值。
(2)IMF分量有兩個限制條件。在時域內:①過零點和極值點數目相等或最多差一個;②上下包絡線的均值為0。若h1(n)不滿足限制條件,則將h1(n)重新作為待分解信號輸入,重復上述步驟(1),直到滿足限制條件,確定第一個IMF記為c1(n)。
(3)從S(n)中分離出c1(n)后得到r1(n),將r1(n)作為輸入信號,重復步驟(1)、(2)。

其中,r1(n)代表語音信號的趨勢分量,最終在滿足rt(n)小于Sd后停止迭代,Sd為單調性函數,公式如式(13):
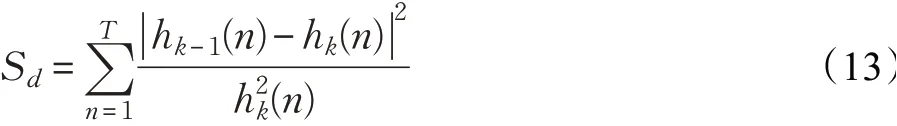
式中,T為信號時間長度,原始信號可以由P個IMF分量和趨勢余項的和表示,如式(14):

對信號S(n)進行FFT變換并計算每一幀譜線能量,如式(15):

式中,i表示第i幀,k表示頻域中的第k條譜線。傳統MFCC采用三角濾波器組,三角形的特性使得每個通帶的頂點與相鄰通帶的起點或終點相交構成交疊區域。導致交疊區域內信號的能量值會分配到相鄰通帶中。致使每個通帶的輸出在統計上不均等[20]。針對這個問題,本文選用梯形濾波器組,使得通帶能量相互不影響,保證每個通帶的輸出在統計原則上均等。
在頻譜范圍內設置濾波器Hm(l),0≤m≤M,M為濾波器個數,一般濾波器個數為12~24,為了使得截取分析的數據更精確,本研究取M=23。每個濾波器具有梯形濾波特性,其中心頻率為f(m),傳遞函數如式(16):為梅爾頻率,是由實際頻率根據

其中人耳聽覺特性轉化而來的頻率尺度,公式如式(17),中心頻率f(m)如式(18):

式中,f0為原始頻率;fh和fl分別為最高頻率和最低頻率。根據求出的每幀譜線的能量計算在每個通帶中的能量,將能量取對數后計算DCT倒譜,得到最終參數,公式如式(19):
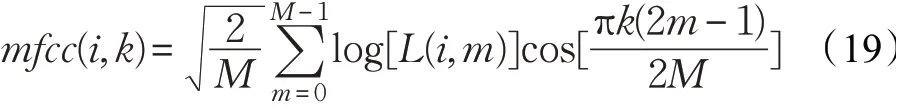
2.3 特征融合
本文采用改進MFCC與時域分析中的短時能量、短時過零率在特征層融合得到關鍵語音信號的新特征矢量,改進MFCC特征向量為T1=[FY1,FY2,…,FYR],共23維;短時能量利用其最大值、最小值、均值、方差構成特征向量為T2=[EY1,EY2,EY3,EY4];短時過零率的特征向量為T3=[HY1];融合后特征向量T,如式(20):

融合特征向量構成如表2。

表2 特征向量Table 2 Eigenvectors
進行數據歸一化。利用離差標準化方法,使結果值映射到[0,1]之間。函數如式(21):

式中,a′為原始數據。部分實驗數據列舉如表3。

表3 實驗數據Table 3 Experimental data
3 識別模型建立
本研究搭建了改進MFCC融合特征與FA-PNN組合的識別模型。根據駕駛員語音特性將頻域MFCC參數改進后與時域中短時能量及短時過零率參數融合歸一化后構成特征向量,利用FA優化PNN神經網絡,構建識別模型,流程如圖6所示。PNN是利用貝葉斯決策規則和高斯Parcen激活函數的一種前饋網絡模型。其網絡直接從訓練范例中加載數據,無迭代過程,所以學習速度快,適用于需求實時性較高的場所,并且它具有徑向基神經網絡與概率密度估計原理的優點,在模式分類方面具有較為顯著的優勢,符合本研究的要求。
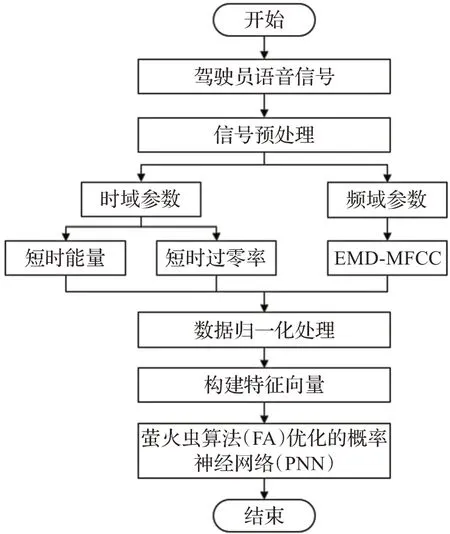
圖6 識別模型流程圖Fig.6 Flowchart of model identification
PNN網絡有輸入層、模式層、求和層和輸出層。本研究特征參數為28維,即輸入層神經元數為28,即數據維數d=28;高斯核函數連接輸入層和模式層,求得輸入層和模式層中神經元之間的匹配程度。模式層輸出為相似度,公式如式(22),在求和層做模式層輸出的加權平均,公式如式(23),輸出層取求和層中最大值作為輸出的識別結果,公式如式(24)。
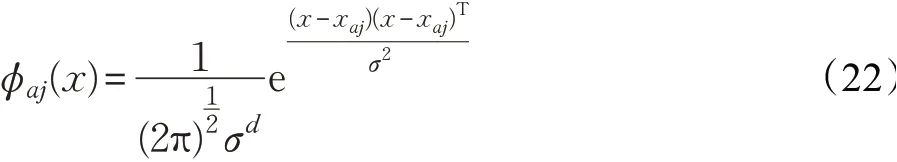

式(22)中xaj為第a個樣本的第j個中心;σ為平滑因子。式(23)中,vaj表示第a個樣本為j類別的輸出;L表示神經元個數,L=28。
利用螢火蟲算法優化平滑因子,平滑因子作為PNN神經網絡的唯一的重要輸入參數,其取值不同會直接影響到整個樣本模式的概率密度函數的分布[21],對模型的識別性能有直接的影響。本文利用螢火蟲算法對平滑因子σ進行尋優,螢火蟲算法在局部和全局優化、魯棒性能等方面有著獨特優勢,算法概念簡單,流程清晰,需要調整的參數較少,收斂速度較快,同時搜索精度較高,更加容易實現。螢火蟲群都受種群中亮度最大的螢火蟲的吸引,并改變自身位置向其靠攏。將平滑因子σ隨機初始化為向量σ=[σ1,σ2,…,σs],作為螢火蟲的初始種群,隨機分布位置。本研究中FA算法的目標函數定義為均方根誤差(root mean square error,RMSE),如式(25):

式中,J表示PNN網絡輸出層的節點個數,等于類別數;yi、ci分別表示PNN網絡輸出層的第i個節點的測試輸出和期望輸出。具體公式如下:
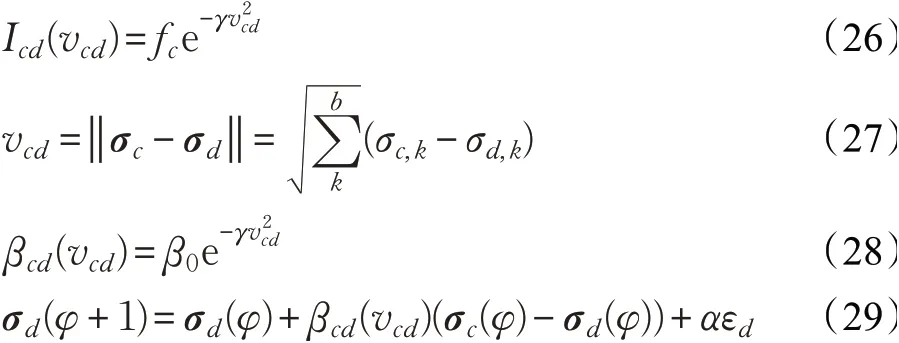
式(26)中,γ表示光吸收因子;式(27)中,d為空間維數,σc,k為螢火蟲c在d維空間中的第k個分量;式(28)中,β0表示最大吸引力值;式(29)中,φ表示迭代次數;σc、σd分別為螢火蟲c和d的空間位置;α表示步長因子;βcd為c對d的吸引力;εd為[0,1]上服從高斯分布的隨機因子。優化模型流程如圖7所示,具體步驟如下:
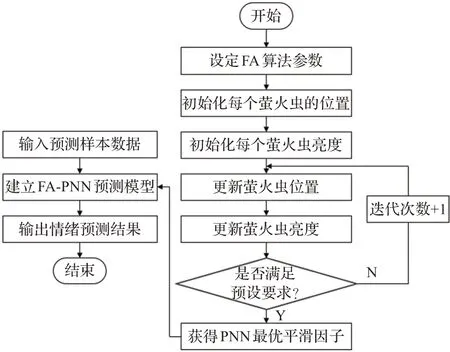
圖7 FA-PNN算法流程圖Fig.7 Fa-PNN algorithm flow chart
步驟1初始化螢火蟲的位置,將平滑因子σ作為螢火蟲個體,σ=40,σ∈(0,4),初始化螢火蟲位置。然后設定光吸收因子γ=1.0、步長因子α=0.2、最大吸引力值β0=1.0,設定當前迭代次數φ=1。
步驟2每個螢火蟲的亮度Icd根據式(26)計算,吸引力βcd根據式(28)計算。亮度決定螢火蟲的移動方向,吸引力決定移動距離。
步驟3式(29)更新計算螢火蟲的位置。
步驟4在每個螢火蟲的位置更新后,利用式(25)再次計算亮度。判斷是否滿足目標函數收斂或到達最大迭代次數,進行步驟5;否則φ=φ+1,返回步驟3。
步驟5將得到的平滑因子σ作為PNN網絡的參數進行訓練,得到識別模型。
將樣本導入模型中進行訓練,FA-PNN中平滑因子的優化過程如圖8所示,橫坐標表示迭代次數,縱坐標表示訓練樣本的輸出值與實際值的均方誤差,從圖中可以得出,當優化到第6代左右達到了局部最優,RMSE值為0.223,當達到33代時逃離局部最優,33代后值為0,表示PNN網絡的訓練樣本的輸出值與實際值的均方根誤差值為0,最優時σ=1.1,即設定PNN網絡參數平滑因子為1.1。
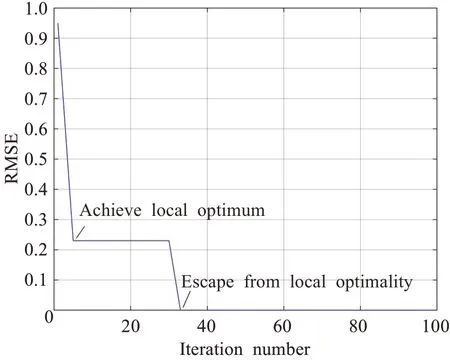
圖8 FA-PNN的迭代過程Fig.8 Iterative process of FA-PNN
4 模型驗證與對比分析
實驗1由于汽車內設備存在一定的噪聲,信噪比是指電子設備中信號與噪聲的比例,信噪比越大噪聲越小,以此來進行模型抗噪性能的評判。本研究針對不同信噪比情況下傳統MFCC、改進MFCC、融合特征三種特征提取方法兩類情緒樣本進行識別正確率對比,如圖9所示,圖中表明,信噪比越高,三種特征提取方法識別正確率均越高,但隨著信噪比的降低,傳統MFCC正確率下降最快,改進MFCC正確率高于傳統MFCC,融合特征參數正確率最優;同時,改進MFCC特征在25~30 dB準確率快速提高,而傳統MFCC在30 dB后才快速提高,證明了本特征提取方法相比傳統方法具有較好的抗噪性,體現了較好的魯棒性。
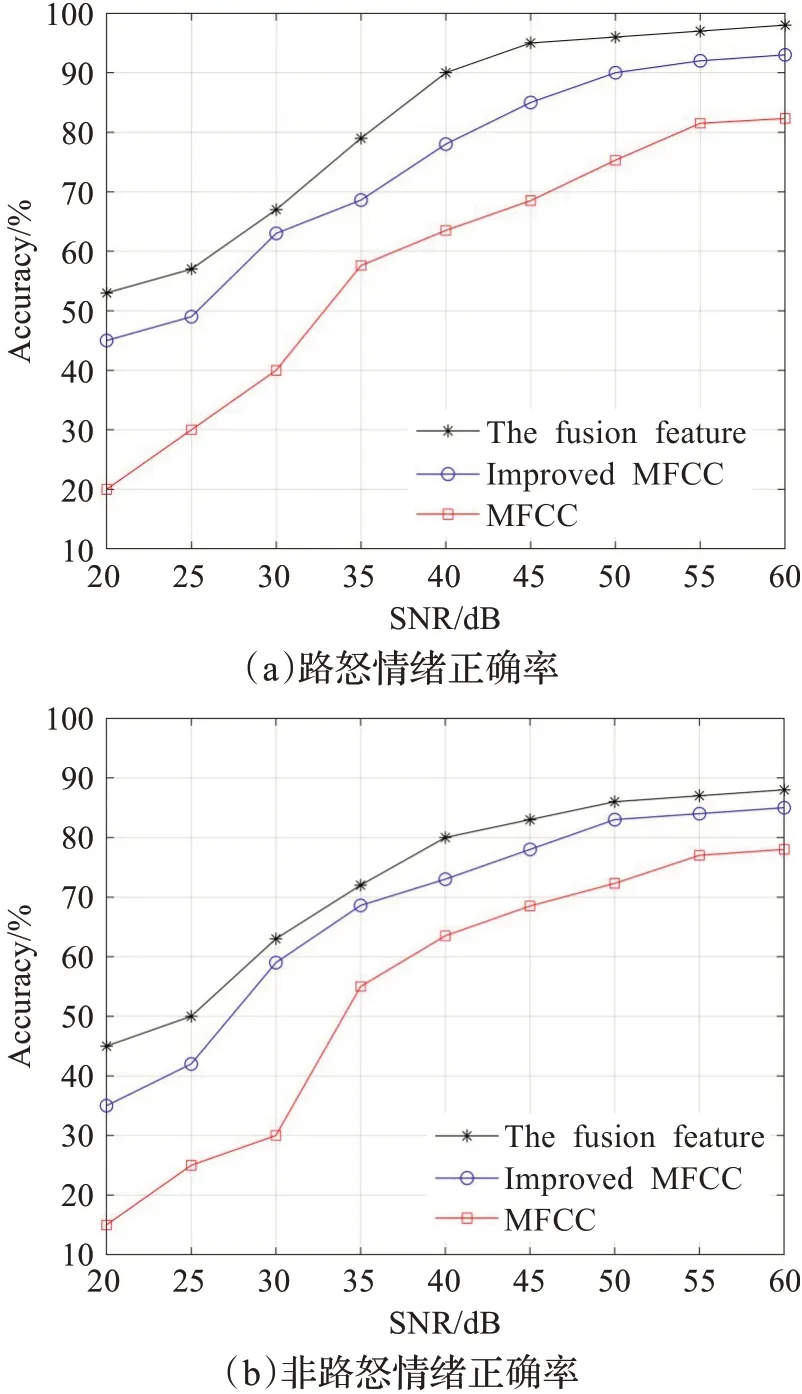
圖9 不同信噪比正確率Fig.9 Accuracy of different SNR
實驗2為了驗證優化識別算法的優越性,本文利用融合特征處理后的相同數據,分別輸入傳統PNN和FA-PNN神經網絡進行訓練并測試,同時輸入傳統模型SVM、BP、KNN、LVQ進行對比分析。利用真陽性(true positive,TP)、真陰性(true negative,TN)、假陽性(false positive,FP)、假陰性(false negative,FN)計算準確率、精確率、F1-Score值、召回率對兩種神經網絡的識別結果進行評估,由于精確率和召回率之間存在相對性影響,所以引進F1-Score值,F1-Score值為精確值和召回率的調和平均,因此,該指標更加合理,得分范圍為[0,1],得分越高,性能越好。公式如下:

兩種神經網絡測試結果的混淆矩陣如圖10。根據圖10(a)可知,對于FA-PNN神經網絡,在100組的路怒情緒樣本中,有98組樣本識別正確,有2組樣本被模型判為非路怒情緒;在100組的非路怒情緒樣本中,有88組樣本識別正確,有12組樣本被模型判為路怒情緒。根據圖10(b)可知,對于PNN神經網絡,在100組的路怒情緒樣本中,有87組樣本識別正確,有13組樣本被模型判為非路怒情緒;在100組的非路怒情緒樣本中,有77組樣本識別正確,有23組樣本被模型判為路怒情緒。
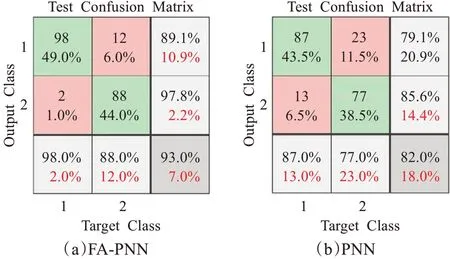
圖10 混淆矩陣Fig.10 Confusion matrix
從表4可以得出本研究的網絡模型相比傳統的PNN神經網絡識別準確率提高了11個百分點,F1值相對傳統PNN網絡提高了0.104 7,PNN網絡的識別準確率較低于LVQ網絡,但FA-PNN網絡相對于SVM、BP、KNN、LVQ模型平均識別準確率提高了約10個百分點,F1值也有所提高,說明本研究方法具有很好的性能。綜上所述,改進MFCC融合特征與FA-PNN組合的識別模型識別效果要明顯優于傳統MFCC及常用識別模型。
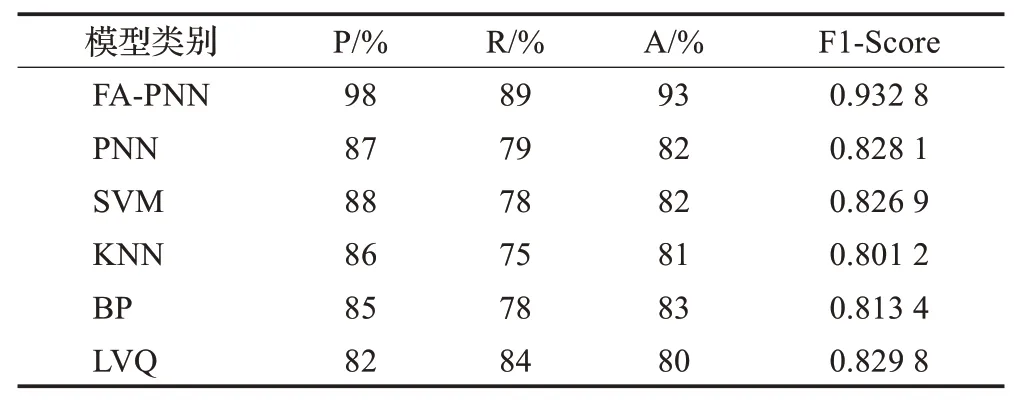
表4 評估結果表Table 4 Evaluation results
5 結論
駕駛員路怒情緒的識別研究對于降低道路安全隱患具有重大意義,語音信號處理技術為汽車主動安全駕駛預警研究提供了新方法。本文利用模擬駕駛系統采集駕駛員語音數據,根據語音的頻譜特性,將時域中短時能量及短時過零率特征參數和改進MFCC特征參數融合構成特征參數向量,利用螢火蟲算法優化PNN神經網絡,實現駕駛員路怒情緒的識別。與傳統MFCC特征參數及傳統PNN神經網絡進行了對比實驗,結果表明,相同神經網絡下,改進MFCC融合特征提取方法對于傳統MFCC特征提取方法,在不同信噪比情況下識別正確率高而且抗噪性能更優。相同特征提取方法下,FA-PNN模型識別準確率為93%,相比傳統PNN模型提高11個百分點;F1-Score為0.932 8,相比傳統PNN模型提高0.104 7,同時也明顯優于其他傳統識別模型。因此,本文所提出的識別方法在識別駕駛員路怒情緒方面表現優異。在本文中,只考慮了駕駛員的語音信息,后續研究中將進一步分析駕駛員語音特性及文本信息,進一步提高駕駛員路怒識別方法的精度和魯棒性。
猜你喜歡
汽車實用技術(2022年14期)2022-07-30 06:13:42
汽車實用技術(2022年4期)2022-03-07 06:07:20
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
電子制作(2018年11期)2018-08-04 03:25:42
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
公民與法治(2016年4期)2016-05-17 04:09:26
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
