基于云儲存的氣象數據動態可視化重建算法設計
2023-01-24 12:51:44高曉靜艾文文王博妮張嵐許福根
電子設計工程 2023年2期
關鍵詞:可視化
高曉靜,艾文文,王博妮,張嵐,許福根
(江蘇省氣象局,江蘇南京 210019)
隨著大數據技術在氣象檢測數字化中的應用,氣象部門積累了大量歷史氣象數據。如何儲存和處理產生的海量數據,并及時將檢測結果進行可視化分析,成為了氣象領域相關學者研究的熱點課題之一[1-3]。各類先進、精密的設備不間斷地產生海量數據,這些數據的背后蘊含著一定的邏輯關系,可為氣象災害風險評估提供必要的數據支撐[4]。
傳統數據挖掘分析方法在面對以兆為數量級高速增長的數據時,存在處理速度慢、計算效率低等缺點;而云計算技術則在海量數據計算方面展示出了強大的優勢[5-9]。利用云計算技術來儲存與處理海量氣象數據,已成為當前的研究熱點方向之一。借助動態監測技術,并將分析結果利用計算機圖形技術以圖像的形式展示出來,可提高人們對氣象信息的整體認知,進而降低氣象災害帶來的損失[10-13]。
該文針對氣象數據采集途徑和數據特點,使用云儲存技術進行氣象數據的儲存與處理,并提高數據處理效率。采用基于視頻壓縮編碼的方法將氣象數據進行分解,并利用雙線性插值法對其進行修正,最終通過壓縮矩陣Apriori 改進算法完成數據壓縮。
1 云儲存技術結構
根據研究對象的不同,氣象數據可分為地面氣象數據、高空氣象數據、海洋氣象數據和衛星探測資料等,這些氣象數據通常包含了一系列氣象要素:氣溫、氣壓、濕度、風速、紫外線指數及降水量等。這表明氣象數據為多源多維數據。由于數據采集方式的不同,地面站與高空站采集到的氣象數據為關于時間的連續性數據,這些數據也關聯了采集地的地理信息。
針對氣象數據的上述特點,面向氣象動態數據可視化重構算法的云儲存技術被設計為五層結構:基礎設施層、平臺層、應用層、大數據層及用戶層,具體架構設計如圖1 所示。

圖1 該文云儲存架構設計
其中,基礎設施層為主要用于氣象數據動態可視化的物理設備,主要有主機、儲存器、數據中心及網絡設備等。在云計算環境下,原有的基礎設施需要進行云化處理,這些設備的計算資源與儲存資源可實時動態調動,以實現資源的整合并提高資源利用率。平臺層主要依托基礎設施層進行云計算平臺的搭建,涉及數據的儲存、計算等操作。該文使用Hadoop 分布式文件系統進行文件冗余儲存,同時采用MapReduce 實現氣象數據的并行計算。應用層在平臺層的基礎上進行應用開發,實現氣象站點、云平臺的管理與監控等應用;大數據層則為應用層提供必要的數據支撐;用戶層為氣象業務部門、氣象科研部門以及其他需要氣象信息的行業提供訪問渠道,從而實現氣象數據的共享。
2 氣象數據可視化重建算法
2.1 氣象數據的預處理
考慮到氣象數據的傳輸途徑為無線網絡,在網絡環境下傳輸海量數據進行可視化應用,對數據處理算法的效率和速度要求較高[14-16]。該文根據相鄰空間標量場與矢量場數據的特點,采用視頻壓縮編碼的方式對數據重新進行編碼,以提高數據傳輸的速度。
由于不同氣象監測設備的數據格式不統一,無法建立相關聯的可視化成像算法,因此需要將數據格式進行統一化處理。該文用于可視化重建算法的數據,在結構上分為數據頭和數據主體兩個部分。數據頭為統一的儲存日期、時間、預報時效、經度格距、緯度格距以及數據的類型信息;數據主體則為具體內容。
以溫度數據為例,該文利用多維數據分解算法按照不同的時間,將四維數據分解成一系列同一空間的三維數據體;再將三維數據體按照不同高度分解成一系列結構一致的二維網格數據。這些網格數據代表著某時刻、某高度、某空間位置的溫度信息,四維數據分解為二維數據體示意圖如圖2 所示。
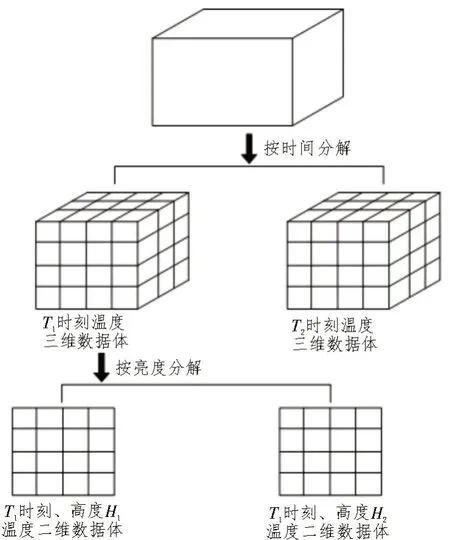
圖2 四維數據分解為二維數據體示意圖
考慮到大多數氣象設備采集到的數據存在精度低、可視化效果差的問題,需要進行插值處理來提高數據量。通常采用左上、左下、右上、右下這4個數據來獲得采樣點的數值。當這4 個網格點的數值相差較小時,則直接選取距離該采樣點最近的網格點數值作為采樣值,從而降低計算量。其取值示意圖如圖3 所示。而當4 個網格點的數值差異較大時,采用雙線性插值法來獲得采樣點數值,如圖4 所示。假定P為采樣點,其坐標被定義為P(x,y),其數值為F(x,y)。而基于雙線性插值法的表達式如下所示:

圖3 不插值采樣點取值示意圖


圖4 基于雙線性插值采樣點取值示意圖
經過雙線性插值處理后的溫度數據具有以下特點:
1)具有時間、高度、經度、維度四維特征;
2)在不同高度層面上,經度、維度組成的二維網格數據是規則的二維網絡數據;
3)數據量顯著增加,新增了大量的無效圖像化數據。
針對上述特點,由于采用了視頻圖像格式進行數據傳輸會產生無意義的2 GB 和Alpha通道,且這部分數據具有各向同值的特點,所以壓縮操作對后續數據可視化處理并不會產生較大影響。
2.2 改進Apriori算法
為了提高對氣象數據的潛在聯系與規律數據挖掘的能力,需要對數據進行關聯。由于氣象數據的體量較大,使用少數計算機進行大規模數據處理需要消耗大量的時間;而云計算技術采用并行算法,則可顯著提高數據關聯的效率。關聯規則是數據挖掘的一個重要領域,其目的是發現各類數據之間的關聯性,實現數據的整體把控。對于任意一個事務數據庫,關聯規則被用來產生支持度和置信度,所生成的數值均不小于預定的最小值。
傳統基于矩陣的改進Apriori 算法需要巨大的計算量,并在連接時生成過多的候選結果,增加較多的無用元素。針對此問題,該文將矩陣中重復的事務整合成一列,通過設定一個權值數組w來儲存重復事務的條數,同時另外設定數組m,儲存矩陣中元素為1 的列數。通過數組m來獲取事務的長度,進而縮短壓縮矩陣的時間。為了降低無用元素的個數,需要對矩陣的行與列進行壓縮。
定理1:假定集合的項均按照字典順序進行排列。當從k項集合生成k+1 項集合時,若這兩個集合前k-1 項不一致,則稱這兩個集合為不可連接的。
推論1:根據頻繁項集I支持度的計數遞增順序將每個項目集合中的元素進行排序,若存在兩個頻繁項集Ix和Iy是不可連接的,則Ix、Iy后續的項目集合均為不可連接。
由于無法連接的項集對數據挖掘的意義較小,根據以上定理和推論,可將矩陣中不能與相鄰項集連接的子集行向量刪除。同時修改數組m,將剩下的行向量按原順序組成新的矩陣,進而縮小矩陣的規模。
在四維數據體被雙線性插值處理為規則二維網格數據后,采用色彩空間變換方法將規則二維數據處理為RGB 圖像;然后使用VP9 視頻編碼器和色度子采樣模型將RGB 圖像轉化為視頻數據,實現數據的可視化。在這一過程中,VP9 編碼以最大冗余來進行編碼壓縮,從而保證數據質量。
3 測試與驗證
該文測試使用的數據來自中國科學院國家空間科學中心網站,主要包含溫度數據和風速數據兩類,如表1 所示。測試硬件采用了Intel Core i7-6700HQ處理器、16 GB 內存、1 TB 固態硬盤以及Nvidia GeForce GTX 960M 顯卡;軟件則選用了Win7 64 位操作系統、HTML、CSS、JavaScript 等編輯語言。

表1 原始數據氣象數據明細
從表1 可以看出,溫度場和風場在緯度方向上并不是等間隔的,這對后期可視化處理效果具有較大影響。原始數據在經過雙線性插值處理后,變為規則數據如表2 所示。在表2 中,溫度場數據和風場數據在緯度方向已轉變為5°的間隔數據,且整體數據量有所增加。

表2 插值后氣象數據明細
為了驗證該文所提出的視頻壓縮編碼方法(M3)在數據傳輸方面的優勢,使用局域網環境進行對比實驗。對照組采用基于DAT(M1)和分包ZIP(M2)兩種數據傳輸方法進行同等可視化質量數據傳輸試驗。在試驗中,同等可視化質量被定義為單幀圖像分辨率為1 080 P,其具有相同的數據可視化實際空間分辨率和比例尺數值。為了降低網絡傳輸的影響,均采用HTTP 協議進行數據的網絡傳輸,并采用連續25 幀的數據傳輸量以降低緩存效率與傳輸丟包的影響。對比實驗結果如圖5 所示。
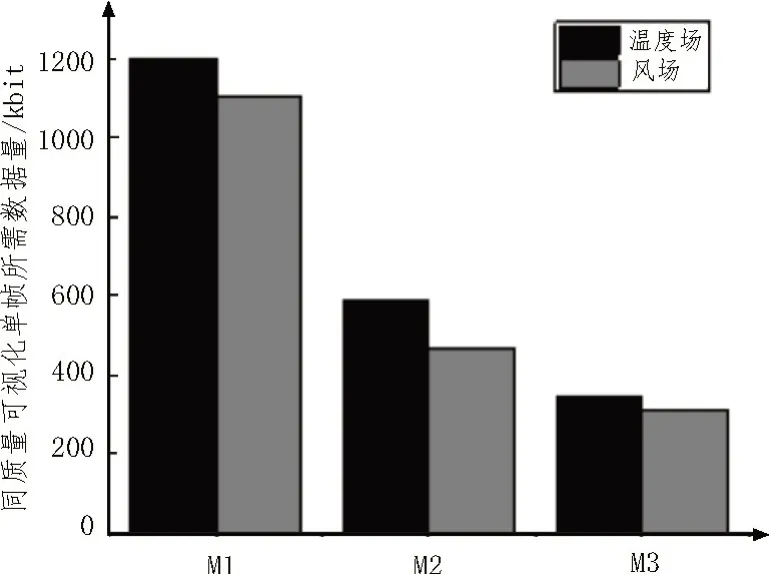
圖5 不同方法所需數據量對比
從圖5 可以看出,在進行同質量可視化單幀圖像處理時,三種數據傳輸方法所需的數據量具有明顯差異。針對溫度場和風場,二進制化的DAT 格式所需的數據量比分包ZIP 壓縮需要的數據量多52.1%。這是因為分包ZIP 壓縮能夠去除冗余的數據,大幅減小需要傳輸的數據。而該文所提出的基于視頻壓縮編碼算法在進行同質量可視化單幀圖像處理時,所需的數據量在三種數據傳輸方法中最小,比分包ZIP 壓縮算法低31.8%。這是因為基于視頻壓縮編碼方法傳輸的數據是每一層網格數據的差異值,而不是原始數據。在保證數據信息不丟失的情況下,降低了傳輸數據量。
4 結束語
該文利用云計算平臺進行氣象數據可視化處理,有效提高了海量數據的儲存效率和計算能力。所述方法利用視頻壓縮編碼算法實現了網格化的數據降維,通過引入雙線性插值法完成了分解后的必要性修正,最后基于改進Apriori 算法實現了數據的大幅壓縮。實驗驗證結果表明,該文所提出的基于云儲存的氣象數據動態可視化重建算法,在提高數據傳輸速率方面具有良好的工程應用價值。
猜你喜歡
江蘇安全生產(2022年7期)2022-08-24 02:11:52
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
北京測繪(2022年6期)2022-08-01 09:19:06
選煤技術(2022年2期)2022-06-06 09:13:12
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
山東農業工程學院學報(2019年11期)2020-01-19 02:49:22
傳媒評論(2019年4期)2019-07-13 05:49:14
