基于KNN的人臉識別算法融合方法
2023-01-19 07:07:08胡楊王家興宛根訓(xùn)田青王寧孫煒晨公安部第一研究所
警察技術(shù) 2022年6期
胡楊 王家興 宛根訓(xùn) 田青 王寧 孫煒晨 公安部第一研究所
引言
隨著人工智能技術(shù)不斷發(fā)展,生物識別技術(shù)儼然已成為個人身份識別或認證技術(shù)的重要方式。人臉識別作為生物特征識別的重要分支之一,它的無侵害性和對用戶最自然、最直觀的識別方式更容易被大眾接受。近年來,人臉識別技術(shù)在刑事偵破、出入口控制、信息安全等公安行業(yè)領(lǐng)域呈現(xiàn)出廣闊的應(yīng)用前景。目前公安機關(guān)絕大多數(shù)的應(yīng)用場景都是在非控制條件或非配合條件下進行,應(yīng)用場景更加復(fù)雜,對算法魯棒性的要求更高。
1比N人臉識別技術(shù)一般采用深度學(xué)習(xí)和卷積神經(jīng)網(wǎng)絡(luò)技術(shù),不同的神經(jīng)網(wǎng)絡(luò)架構(gòu)層出不窮,在不同場景不同業(yè)務(wù)下各有利弊。在實際應(yīng)用中,算法廠商出于自身知識產(chǎn)權(quán)保護只提供比對分數(shù)結(jié)果,所以多算法融合方式主要是基于分數(shù)的融合。目前常用的分數(shù)級融合[1]有基于密度的融合、基于歸一化的融合、基于分類器的融合、線性加權(quán)融合[2]、投票決策融合等等。
基于密度的融合首先將分數(shù)轉(zhuǎn)換為后驗概率,然后根據(jù)貝葉斯做出決策。Snelick等[3]使用一種參數(shù)化方法獲取分數(shù)的條件概率密度。基于歸一化的融合將分數(shù)首先進行歸一化,然后使用統(tǒng)一的融合規(guī)則獲取一個新的分數(shù)。Wang等[4]提出了一種根據(jù)FAR和TAR來計算不同分類器權(quán)重的融合方法;He[5]根據(jù)均值和方差提出了RHE歸一化的方法。基于分類器的融合往往將多個分數(shù)作為一個多維向量從而進行分類。Wang等[6]將人臉和虹膜通過支持向量機進行融合;Kumar等[7]采用粒子群優(yōu)化算法來選取最優(yōu)融合策略。
基于歸一化的融合方法無需訓(xùn)練, 實現(xiàn)簡單, 較少考慮到匹配分數(shù)分布的特殊性;基于密度的融合需要對密度進行準(zhǔn)確的估計,實現(xiàn)復(fù)雜,時空開銷大,需要大量訓(xùn)練樣本;線性加權(quán)融合、投票決策融合過于簡單,很難取得很好的識別效果。
考慮以上方法的優(yōu)缺點,本文采用了基于分類器的融合方法,提出了一種基于KNN的人臉識別算法融合方法,能夠適應(yīng)不同公安實戰(zhàn)應(yīng)用場景需求,提升人臉識別的準(zhǔn)確率且節(jié)約計算資源。
一、基于KNN的算法融合
基于KNN的人臉識別算法融合方法是將多算法引擎返回的不同結(jié)果使用KNN算法進行融合判定并返回最終人臉識別結(jié)果。
(一)總體框架
基于KNN的人臉識別算法融合方法的總體框架如圖1所示,主要包括多算法引擎輪詢模塊、算法引擎池模塊、多算法決策模塊、算法選擇器模塊和KNN算法融合模塊。

(二)多算法決策
多算法決策模塊根據(jù)算法引擎返回的分數(shù)和Top N之間的分布情況決定是否進行多算法比對,從而達到識別準(zhǔn)確性和并發(fā)能力的平衡。對于單一算法引擎返回分數(shù)較高且Top N之間分數(shù)分布分散的情況,多算法決策模塊不再進行其他算法比對;對于單一算法引擎返回分數(shù)較低或Top N之間分數(shù)分布集中而造成的“沒有把握”的情況,通過算法選擇器選擇其他算法進一步比對,然后將兩家算法引擎返回的結(jié)果送入KNN算法融合模塊進行融合判定,提升識別準(zhǔn)確率。
在實際場景中,多算法應(yīng)用的主要難點是不同算法引擎分數(shù)代表的意義不同,高分數(shù)值的標(biāo)準(zhǔn)也不同,例如以達到99%以上的識別準(zhǔn)確率為要求,算法引擎1的分數(shù)需要達到97分以上,算法引擎2的分數(shù)需要達到98分以上,算法引擎3的分數(shù)需要達到96分以上。
在1比N應(yīng)用中,返回結(jié)果排序靠前和排序靠后的分差越大越好,在本文中使用方差函數(shù)來衡量Top N之間分數(shù)分布情況,公式如(1)和(2)所示。
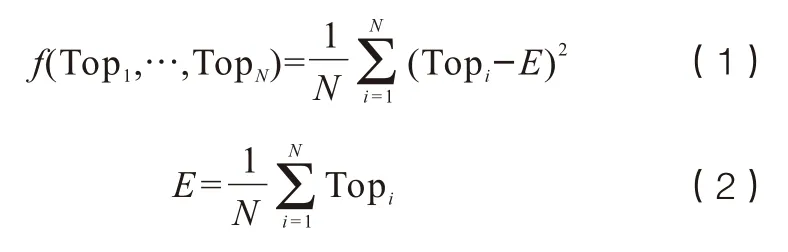
一般情況下,返回正確結(jié)果的分數(shù)和返回錯誤結(jié)果的分數(shù)之間分差較大。這里我們根據(jù)經(jīng)驗值,N取2,即比較返回前兩個結(jié)果的方差。多算法決策模塊在進行判定時,如果方差小于閾值V,即代表TopN結(jié)果分值接近,需要進行多算法比對融合。不同算法引擎之間的方差閾值V不同,這里設(shè)置算法引擎1的方差閾值為V1,算法引擎2的方差閾值為V2,算法引擎3的方差閾值V3為1.5。
(三)基于KNN算法融合判定
不同算法引擎如果返回結(jié)果不同,則需要使用KNN算法進行融合判定。KNN算法又被稱為k近鄰算法,是機器學(xué)習(xí)算法中應(yīng)用最廣泛的分類算法之一[8]。KNN算法對于任意n維輸入向量,分別對應(yīng)特征空間中的一個點,通過計算每個已知類別標(biāo)簽的樣本數(shù)據(jù)到未知類別標(biāo)簽的樣本數(shù)據(jù)的距離,選擇最近的k個已知標(biāo)簽,采用多數(shù)表決的方式來預(yù)測未知樣本數(shù)據(jù)類別,如圖2所示。
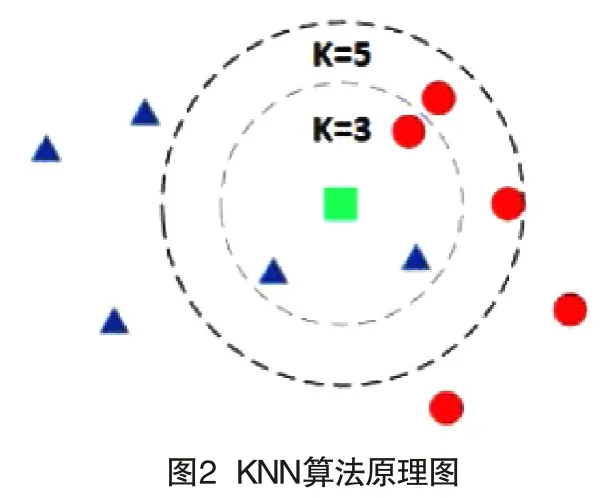
假設(shè)給定一個訓(xùn)練數(shù)據(jù)集T={(x1,y1) ,(x2,y2) ,…,(xN,yN)}作為輸入,其中xi是 每個已知類別樣本的輸入特征向量,yi∈Y={c1,c2, …,cn}屬于類別標(biāo)簽,i=1,2,…,N。根據(jù)設(shè)定好的距離度量規(guī)則,在給定的數(shù)據(jù)集T中通過計算尋找與未知類別標(biāo)簽樣本x最近的k個樣本,記為NK(x)。接著根據(jù)少數(shù)服從多數(shù)的原則,采用投票表決方式選出未知標(biāo)簽樣本x所屬類別,公式如(3)所示。
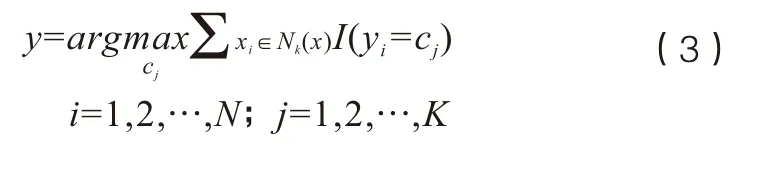

在公式(3)中,I(g)是指示函數(shù),當(dāng)為真的時候,輸出為1,否則輸出為0。
兩個樣本點之間距離度量用來衡量空間上的差異性,距離越短,表示相似程度越高;反之,相似程度越低。在KNN算法中,常用的距離度量方式有歐氏距離、曼哈頓距離、余弦距離等。曼哈頓距離和歐式距離原理上都是明可夫斯基距離在一定特殊條件下的應(yīng)用,它們在數(shù)學(xué)公式的表現(xiàn)形式上類似。明可夫斯基公式如(4)所示。
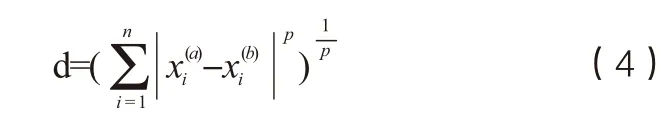
在公式(4)中,p是一個超參數(shù),當(dāng)p=1的時候,就是曼哈頓距離;當(dāng)p=2時,就得到了歐式距離。
在本方法中,輸入的樣本維度為8維,分別是算法引擎1返回的Top 1分數(shù)、算法引擎2返回的Top 1分數(shù)、圖像質(zhì)量分數(shù)、圖像光照分數(shù)、圖像清晰度分數(shù)、人臉picth角度、人臉yaw角度、人臉roll角度。具體的算法實現(xiàn)過程如下:
(1) 第一步計算已知類別標(biāo)簽的樣本數(shù)據(jù)點到未知類別標(biāo)簽的樣本數(shù)據(jù)點距離,并記錄下來;
(2) 第二步把上一步計算好的所有距離按照從小到大的順序依次排序;
(3) 第三步選擇前個距離最近的已知類別標(biāo)簽的樣本數(shù)據(jù)點,統(tǒng)計它們所屬類別出現(xiàn)的頻率;
(4) 第四步將出現(xiàn)頻率最高的類別當(dāng)作未知樣本數(shù)據(jù)的預(yù)測類別標(biāo)簽。
在KNN算法中,k值參數(shù)的選擇對于模型的訓(xùn)練起到?jīng)Q定性影響。若k值選擇過小,相當(dāng)于用較小領(lǐng)域中的訓(xùn)練實例進行預(yù)測,很可能忽略一些有用的信息,致使模型的復(fù)雜度增加從而出現(xiàn)過擬合的現(xiàn)象;若k值選取過大,雖然模型的復(fù)雜度會降低,但會增加學(xué)習(xí)的近似誤差,從而使得模型整體變得簡單,在實際應(yīng)用中表現(xiàn)效果變差。
(四)整體流程
基于KNN的人臉識別算法融合方法流程如圖3所示,首先輸入人臉圖像根據(jù)多算法引擎輪詢①選擇算法引擎,如選擇算法引擎1模型,則進入多算法決策②。算法引擎1返回該人員Top1-Top2分數(shù)及人臉屬性等信息,如果Top 1分數(shù)大于閾值T1且Top 1和Top 2分數(shù)的方差大于閾值V1,表明單一算法引擎可達到較高準(zhǔn)確率,不再進行多算法比對融合;如果Top 1分數(shù)小于等于閾值T1或Top 1和Top 2分數(shù)的方差小于等于閾值V1,則進入算法選擇器③調(diào)用另外一個算法引擎進行多算法比對,最后進行KNN算法融合輸出。根據(jù)多算法融合輸出策略,若兩個算法引擎返回結(jié)果相同,則直接返回最終結(jié)果;若返回結(jié)果不同,則使用KNN算法融合兩個算法并返回結(jié)果。
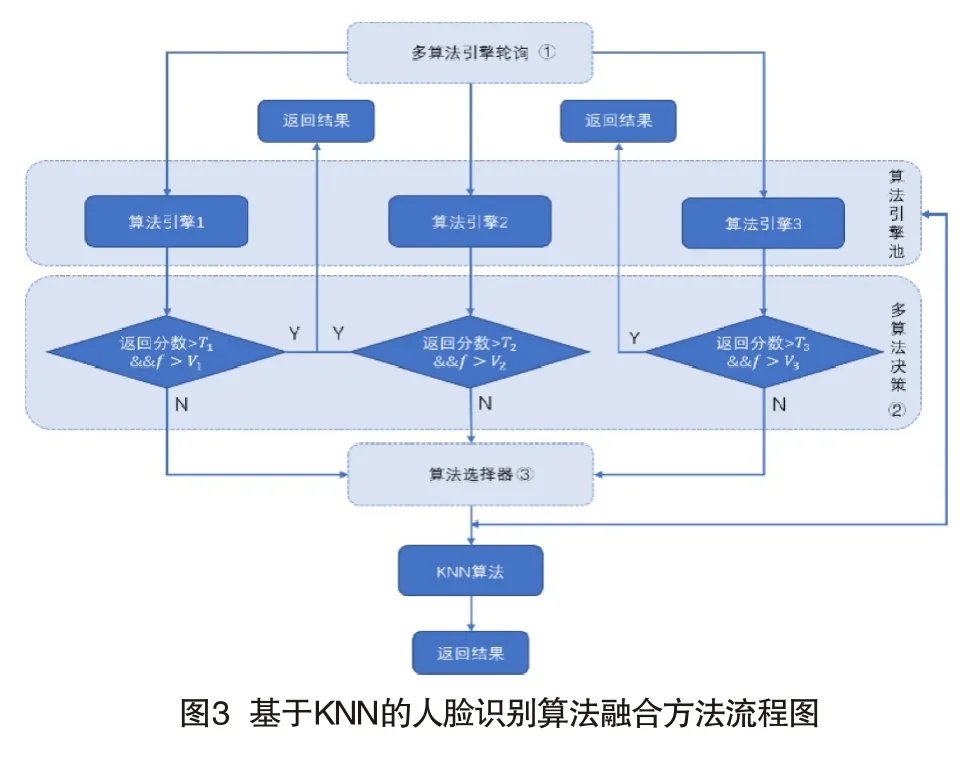
二、實驗結(jié)果
(一)實驗環(huán)境
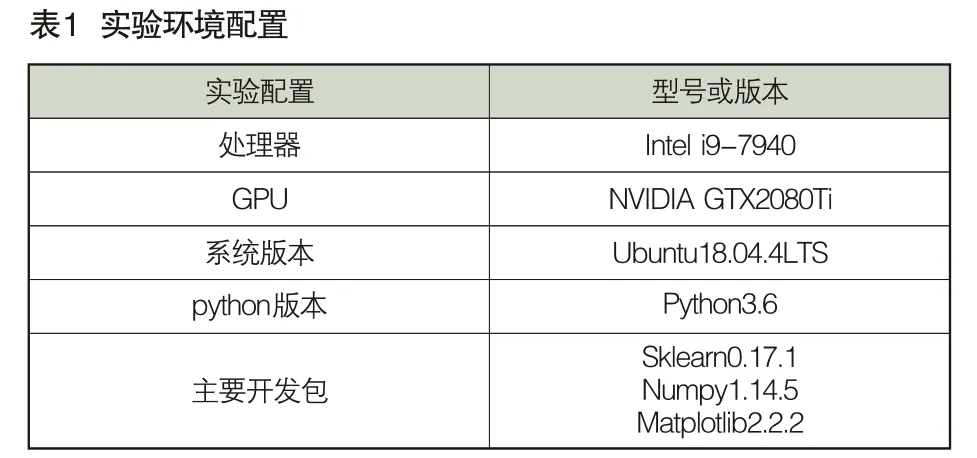
本文實驗環(huán)境配置如表1所示。
?
(二)數(shù)據(jù)集
實驗數(shù)據(jù)集包括10000張人臉圖像,共1000個人。相比于公開數(shù)據(jù)集CASIA-Webface、CelebA、LFW,本文實驗數(shù)據(jù)都是中國人臉且大多來自生活中不同場景,如火車站、證件照、手機自拍照、監(jiān)控視頻照片等等,在光照、角度、遮擋上有明顯區(qū)別,如圖4所示。在人臉數(shù)據(jù)集中選擇70%圖像作為訓(xùn)練集,其余30%作為測試集。

(三)實驗結(jié)果及分析
在實際調(diào)參過程中,本文采用了網(wǎng)格搜索和交叉驗證相結(jié)合的方式來尋找KNN算法的最優(yōu)k值。交叉驗證法是將樣本數(shù)據(jù)D等分為k個互斥的子集,滿足D=D1∪ D2∪ …∪Dk,然后在k個子集中,選擇k-1個子集當(dāng)作訓(xùn)練集,剩下一個子集則是測試集,因此每次都可得到k組訓(xùn)練集和測試集,最后實驗評估結(jié)果取k組平均值。交叉驗證法在很大程度上保證了模型的穩(wěn)定性和可靠性,提高了模型的泛化能力。
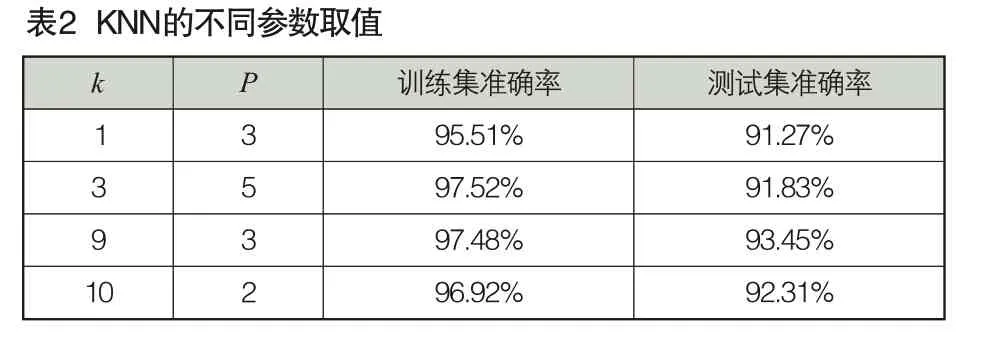
表2所示為KNN的k和p不同參數(shù)值在訓(xùn)練集和測試集的表現(xiàn)情況。模型經(jīng)過訓(xùn)練調(diào)參后,得到最優(yōu)參數(shù)k=3和p=9,在訓(xùn)練集上識別的準(zhǔn)確率達到97.48%,在測試集的識別準(zhǔn)確率達到93.45%。
?
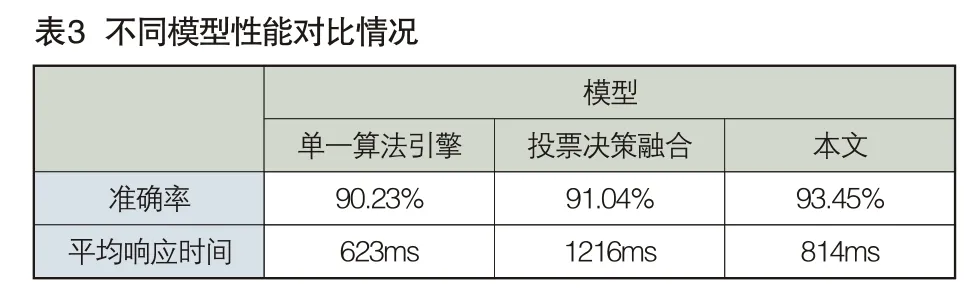
表3所示為基于KNN的人臉識別算法融合方法、單一算法引擎以及多家算法投票決策融合的性能對比情況。投票決策融合模型根據(jù)多家算法引擎的輸出結(jié)果,采用少數(shù)服從多數(shù)的投票原則得到最終的結(jié)果。從表中可以看出,基于KNN的人臉識別算法融合方法在測試集的準(zhǔn)確率最高為93.45%,在平均響應(yīng)時間上面也只有814ms,略高于單一算法引擎,遠低于投票決策模型。
?
三、結(jié)語
經(jīng)過多年的發(fā)展,人臉識別技術(shù)在公安行業(yè)領(lǐng)域已具備實戰(zhàn)應(yīng)用能力。單一的算法引擎由于受到人臉圖像質(zhì)量及算法本身性能限制,在實際應(yīng)用場景中識別的準(zhǔn)確性和魯棒性受到一定影響。本文提出了一種基于KNN的人臉識別算法融合方法,可以適應(yīng)不同復(fù)雜場景,在不大幅度犧牲計算資源的同時,提升了識別的準(zhǔn)確率,從而有效支撐了跨區(qū)域、跨場景的實戰(zhàn)應(yīng)用需求,對于全面提升公安機關(guān)打防管控水平具有重要的意義。
猜你喜歡
作文中學(xué)版(2022年1期)2022-04-14 08:00:34
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
學(xué)生天地(2020年31期)2020-06-01 02:32:06
商周刊(2017年22期)2017-11-09 05:08:31
計算機工程(2015年8期)2015-07-03 12:19:07
河南電力(2015年5期)2015-06-08 06:01:46
皖西學(xué)院學(xué)報(2015年5期)2015-02-28 17:52:46
