改進YOLOX的輕量級安全帽檢測方法
2023-01-13 11:57:04呂志軒馬志鋼
計算機工程與應用 2023年1期
呂志軒,魏 霞,馬志鋼
新疆大學 電氣工程學院,烏魯木齊 830000
目前我國建筑行業仍處在一個持續發展的階段,每年建筑從業人員都在增加,根據國家統計局發布的數據顯示,與2016年相比,2020年我國工程監理從業人員增長39%,達到139萬人;執業人員增長60%,達到40萬人。隨著從業人數的增加,每年因為未佩戴安全帽產生的安全事故也隨之增加,給建筑行業帶來了人員和財產的損失。目前在建筑工地中,仍然采用人工監督的方法判斷工作人員是否佩戴安全帽,這種方法存在很大的缺陷,因為工作環境范圍大,一人監督的范圍有限很可能出現漏檢的區域,如果分配多人進行監督則會增加人工成本。因此有研究者從人員安全和工程建設成本兩個方面考慮,提出了基于目標檢測技術的安全帽檢測方法,該方法平衡了人員安全和工程建設成本之間的關系。近幾年目標檢測技術不斷發展,在對安全帽檢測方法的研究上也取得了一些成果,雖然基于目標檢測的安全帽檢測方法還未大范圍使用,但作為保障生產安全的一項重要技術,未來在建筑工地、煤礦、變電站等工作環境下需求廣泛。
目前對安全帽的檢測方法分為傳統檢測方法和基于卷積神經網絡的檢測方法。傳統的目標檢測方法依靠人工構造被檢測對象的特征,主要有HOG特征+SVM[1]、Harr特 征+Adaboost[2]、DPM特 征[3]等 算 法。Marayatr等[4]使用霍夫變換(Hough transform)方法檢測摩托車行進過程中的頭盔形態特征,檢測準確率達到77%。這些傳統算法僅適用于固定的特征,一旦檢測目標的特征發生變化或者特征具有多樣性,檢測的準確性便會下降,魯棒性較差。為了解決傳統檢測算法出現的問題,研究人員提出了基于卷積神經網絡的目標檢測方法。2014年,Girshick等[5]提出了R-CNN卷積神經網絡檢測方法,該方法將目標檢測分為兩階段(two-stage),第一階段使用一個網絡模型生成預選框(proposal),第二階段使用另一個網絡模型對預選框進
行檢測與判別來得到物體的類別和位置信息。2016年,Redmon等[6]在R-CNN的基礎了提出了單階段(one-stage)檢測方法YOLO(you only look once),該方法只使用一個網絡來獲得物體的類別和位置信息,提高了對物體的檢測速度;2018年,Law等[7]對單階段檢測方法進一步改進,提出了無錨框(anchor free)類型網絡檢測方法CornerNet,該方法對物體關鍵點進行檢測來得到位置信息,大幅減少網絡參數,由此基于卷積神經網絡的目標檢測方法逐漸走向成熟。在目前基于卷積神經網絡的方法中,YOLO系列目標檢測方法對物體的檢測表現較好,被很多研究者用于安全帽檢測研究。王雨生等[8]使用YOLOv4與YCbCr顏色空間交叉篩選的方法來檢測安全帽;Fu等[9]在YOLOv5上新增了一個特征輸出來檢測小目標安全帽,并使用聚類方法得到更合適的先驗錨框;高明華等[10]改進YOLOv3中的交并比函數和數據增強方法,使得對交通目標的檢測精度達到86.3%;蔣潤熙等[11]將YOLOv5的主干網絡換為Hour-Glass網絡,將對安全帽的檢測精度提高到了84.3%。
以上安全帽檢測方法都有較好的檢測精度,但在施工環境下進行實時檢測時要求模型不僅需要高檢測精度,還需要輕量化參數權重滿足較低算力的硬件配置。因此本文使用輕量級網絡結構的YOLOX-s作為基線模型,首先設計了分支注意力模塊(branch attention,BA),將基線模型的預測端輸出按通道承載信息類別不同拆為兩部分分別輸入BA的上下分支,在提高模型檢測精度的同時減少加入注意力模塊帶來的計算量,接著,用馬賽克(Mosaic)方法拼接數據集生成復雜背景模擬施工中的復雜環境,通過在線困難樣本挖掘(OHEM)搜索拼接數據里的困難樣本進行再訓練,提高模型在復雜環境下的魯棒性,增加施工環境中安全帽的檢測精度,然后,設計一種余弦退火算法(cosine decay warm restarts,CDWR)在模型訓練中調節學習率,在學習率曲線中加入預熱(warm up)使得模型權重逐步穩定,加入重啟(restart)增加模型權重跳出局部最優的能力,加快訓練收斂的同時使模型達到更小損失值,最后,在safety helmet wearing數據集上進行測試,驗證模型的檢測性能。
1 YOLOX網絡模型介紹
YOLOX是Ge等[12]對YOLOv3網絡進行改進后提出的新一代目標檢測網絡,相較于之前的YOLOv3、YOLOv4[13]、YOLOv5網絡,YOLOX最大的改進是取消了在預測端(prediction)使用多個錨框預測物體的位置和類別,使網絡檢測頭處的參數量減少約66%。YOLOX繼承了YOLOv5的網絡拆分功能,可以將網絡按大小劃分為:YOLOX-s、YOLOX-m、YOLOX-l、YOLOX-x、YOLOX-Darknet53,其 中 輕 量 級 模 型YOLOX-s的網絡深度和寬度最小,網絡參數量為9.0 MB,權重文件大小為35 MB,與YOLO系列中最具代表性的YOLOv3相比參數量減小了85.46%,權重減小了85.77%。
YOLOX-s的結構如圖1所示,網絡結構分為輸入端、主干網絡、頸部、預測端四個部分。在輸入端部分,YOLOX-s可以使用數據增強方法對輸入的圖像進行預處理;主干網絡部分使用CBL模塊和SSP[14]模塊來增強網絡的特征提取能力;頸部使用FPN結構進行特征融合;預測端部分使用解耦頭(decoupled head)將經過特征融合后的輸出拆分為類別概率、位置、置信度三部分,分別進行計算并拼接后得到預測結果,最后預測端部分會將三個不同尺度大小的預測結果合并,輸出預測結果。

圖1 YOLOX-s的網絡結構圖Fig.1 Network structure diagram of YOLOX-s
2 網絡模型改進與創新
2.1 數據增強
在復雜的施工環境下,多變的天氣、工作中的塵埃以及密集的工作人員是影響模型檢測效果的因素;考慮到數據集中的大部分圖像中被檢測物體數量少、物體背景清晰、單一,不符合施工復雜環境的要求,這會影響訓練模型后的檢測性能。因此,本文將在線困難樣本挖掘(OHEM)[15]和Mosaic數據增強方法結合來提高數據的多樣性以及困難樣本的數量。
在進行數據增強前,首先對safety helmet wearing安全帽數據集進行分析,得到如圖2所示的安全帽標記框面積分布情況。

圖2 數據集標記框面積分布情況Fig.2 Distribution of dataset true frame size
由分布圖可以看出標記框面積集中在10 000以下,在整個數據集中大部分安全帽的標記框寬度和長度集中在50個像素左右,若輸入圖片大小為416×416像素,標記框面積約占圖像總面積的0.029%,因此可以看出數據集中的目標大多屬于小目標類型。
在目標檢測中,數據集中的圖片分辨率不高,小目標物體信息少、噪音多,這些問題是檢測小目標實際且常見的困難問題。為了解決模型在檢測小目標安全帽時遇到的以上問題,在模型訓練過程中加入在線困難目標挖掘方法。每一輪訓練周期結束,模型會篩選出10%損失值最高的數據標記為困難樣本,在下一輪訓練周期被標記為困難樣本的數據將被加入到訓練集中繼續進行訓練,直到網絡對其的檢測損失值低于其余10%數據。加入OHEM后的模型訓練流程圖如圖3所示。

圖3 模型訓練步驟Fig.3 Model training steps
同時為了提高模型在復雜環境下的檢測能力以及魯棒性,在每一批次訓練前使用馬賽克(Mosaic)方法進行數據增強。Mosaic將訓練集中抽取的4張圖片進行隨機大小縮放、色域變換、水平翻轉,然后將經過變換后的4張圖片拼接在一起形成一張初始數據集中沒有的圖片輸入模型進行訓練。如圖4為經過Mosaic數據增強后的結果,圖4(a)由4張單獨圖片合并為一張安全帽更加密集的圖像,模擬施工環境下密集人員工作時佩戴安全帽的情況,圖4(b)為多張施工塵埃環境下造成背景模糊的圖像被Mosaic合并在一起,形成一張新模糊背景圖像,圖4(c)將沙塵、晴天、雨天、雪天背景安全帽合并,新形成的圖像背景復雜多樣,能夠避免單張圖像背景單一的問題,圖4(d)分別選取了塵埃背景、密集人群、不同天氣下的圖片,使用Mosaic方法合并后的新數據具備了施工中復雜環境的所有情況,并且因為每一批次抽取的圖像均不同,所以Mosaic能在提高數據集多樣性的同時避免數據訓練時出現過擬合狀況,同時Mosaic將多張圖片合并創造了和復雜環境相似的背景,提高模型訓練過程中對復雜環境下安全帽的檢測能力。

圖4 經過數據增強后的圖片Fig.4 Data enhanced pictures
OHEM與Mosaic相結合的數據增強方法能提高模型對小目標安全帽的檢測能力,避免數據集反復訓練產生過擬合情況。因為safety helmet wearing數據集中大部分安全帽都為小目標,而小目標物體檢測難度高產生的損失值大,因此使用OHEM搜索時小目標安全帽數量越多的圖像越容易被標記困難樣本反復訓練,從更多次訓練中提高對小目標特征的檢測能力;同時為了避免OHEM搜索困難樣本時標記同一批圖片造成過擬合,在訓練時使用Mosaic方法從訓練集中隨機抽取圖片拼接,OHEM根據比較拼接圖片的損失值來標記樣本,若第一次拼接的4張圖片被標記,則下一次訓練這4張仍被拼接在一起的概率僅為0.152%,且經過Mosaic隨機大小縮放、色域變換、水平翻轉后,每一次訓練圖片的大小顏色都與之前不同,極大降低了反復訓練相同圖片過擬合的可能。
2.2 分支注意力模塊
輕量級網絡模型YOLOX-s參數量少,但相對YOLOX的其他結構網絡檢測精度較低,為彌補精度方面的不足,在模型中加入分支注意力模塊(branch attention,BA)。
注意力模塊包括通道注意力模塊(channel attention,CA)和空間注意力模塊(special attention,SA)。CA的作用是計算出輸入特征每個通道對應的權重,模塊結構如圖5所示,首先對輸入特征F進行通道間的最大池化和平均池化得到特征描述Favg和Fmax,將特征描述輸入三層全連接層構成的多層感知器MLP,結果相加使用激活函數Sigmoid處理,得到一維通道注意力權重MC∈RC×1×1。MC的計算公式如下:

圖5 通道注意力模塊結構Fig.5 Structure of channel attention module

式中F是圖片經過YOLOX-s模型處理后的輸出特征,AvgPool是通道間的平均池化函數,MaxPool是通道間的最大池化函數,MLP是多層感知器,σ表示Sigmoid[16]函數。
SA的作用是計算出每個特征點對應的權重。模塊結構如圖6所示,首先對輸入特征F進行全局最大池化和平均池化,并對得到的兩個特征描述Fmax、Favg進行拼接、卷積和激活函數處理,得到二維空間注意力權重MS∈。MS的計算公式如下:

圖6 空間注意力模塊結構Fig.6 Structure of special attention module

式中AvgPool是空間上的平均池化函數,MaxPool是空間上的最大池化函數,Conv是卷積函數,⊕表示特征合并操作,其余符號均與公式(1)相同。
普通注意力模塊(CBAM)[17]中通道注意力模塊和空間注意力模塊為串聯連接,訓練過程中預測端輸出的所有通道都經過CA和SA的處理,但預測端輸出的通道有一部分對空間信息敏感,另一部分對通道信息敏感,因此將所有通道輸入普通注意力模塊增加了計算量,并且CA中使用全連接層來提取空間特征效率不高的同時增加了網絡的計算量。為了解決以上兩點問題,對注意力模塊進行改進。首先,圖像特征在經過解耦頭(decoupled head)后會被分成三部分:第一部分是物體位置通道Freg∈R4×H×W,第二部分是置信度通道Fcof∈R1×H×W,第三部分是物體的類別通道Fcls∈RC×H×W,Freg上的特征點記錄著預測框中心點相較于當前特征點的偏移量信息(x,y)與預測框的寬高信息(w,h),對應4個通道,Fcof上的每個特征點代表對應預測框內存在被檢測物體的概率信息,Fcls的各個通道內容代表模型所要檢測的各個類別的概率信息。將類別通道僅輸入CA模塊計算得到通道權重,將物體位置通道和置信度通道僅輸入SA模塊進行計算得到空間權重;其次,將CA模塊中的多層感知器結構換成濾波器大小為1×1的卷積層,通過以上操作來減小計算量。改進后的通道注意力權重M′C計算公式為公式(3),空間注意力權重MS的計算公式為公式(2),注意力模塊對輸入特征的總體計算公式為公式(4)。

式中F1是類別通道,F2是位置與置信度合并后的通道,MS是空間注意力模塊,M′C是經過改進的通道注意力模塊。改進后的分支注意力模塊(BA)結構如圖7所示。

圖7 分支注意力模塊結構Fig.7 Structure of branch channel attention module
特征F∈R(C+5)×H×W(C是輸入特征的類別數,H、W是輸入特征的高和寬)輸入分支注意力模塊后將分為類別通道F1∈RC×H×W與位置、置信度合并后的通道F2∈R5×H×W。F1經過通道注意力模塊由公式(3)計算得到通道權重MC∈RC×1×1,通道權重MC被定義為一個由檢測類別數量(C)個1×1張量組成的張量矩陣,其中第Ci∈{ }1,2,…,C個張量的數值大小代表當前圖片對應第Ci∈{ }1,2,…,C個類別的權重,將所有張量的權重合并形成矩陣權重,矩陣權重中數值最高的一個張量值對應的類別最有可能為輸入圖片的類別。F2通道處理過程與F1類似,通過公式(2)計算得到空間權重MS∈R1×H×W,MS權重矩陣是1個高為H寬為W的二維張量,由H×W個張量元素Cij∈{{1,2,…,W},{1,2,…,H}}組成,每個張量元素對應的權重越大代表該位置的信息越重要。計算權重MS時置信度通道Fcof起到了決定位置權重大小的作用,因為Fcof上的每個特征點的數值大小代表存在被檢測物體的概率,因此Fcof中特征值越接近1的特征點存在物體的可能性越大,該特征點對應Freg越精確,同理Fcof特征值越趨近0的特征點存在物體的概率越小,對應位置處的Freg值也趨近于0,計算得到的權重越小,因此在計算MS過程中,高特征值對應的Fcof位置更有可能獲得高注意力權重。將權重與對應通道相乘得到輸出特征,對經過注意力模塊處理的輸出特征F′1與F′2進行合并得到對圖片一次訓練后的結果F′。
類別通道F1與位置、置信度通道F2在輸入注意力模塊后要經過Sigmoid函數處理,將原本值域在的空間權重和通道權重值變換到(0,1)區間內,當一張圖片上的物體類別與位置特征被檢測出來,對應的通道權重與通道上特征點的權重將接近于1,錯誤類別和位置的特征點權重向0靠近。
2.3 學習率控制算法
在訓練模型過程中使用隨機梯度下降(stochastic gradient descent,SGD)[18]作為優化器(optimizer),使用指數下降算法(exponential LR,ELR)[19]控制optimizer學習率的大小,改變模型權重更新時的迭代步長。ELR作為學習率控制器下降曲線如圖8(a)所示,隨著訓練batch次數的增加ELR控制的學習率按指數減少,更新步長逐漸趨近于0,符合梯度下降算法在初始時用大步長尋找最小值范圍,逐步減小步長向最小點靠近的尋優規律;但由于目標優化函數曲線上可能分布著多個局部最小值(local minima),僅有一個全局最小值(global minima),ELR算法控制的SGD優化器很容易陷入局部最優,如圖9所示,初始時較大學習率下的大步長讓模型很容易跳過前兩個local minima,之后學習率持續減小,到達第三個local minima時模型權重更新步長太小而陷入局部最小點。

圖8 三種不同的學習率下降曲線Fig.8 Decline curves of three different learning rates
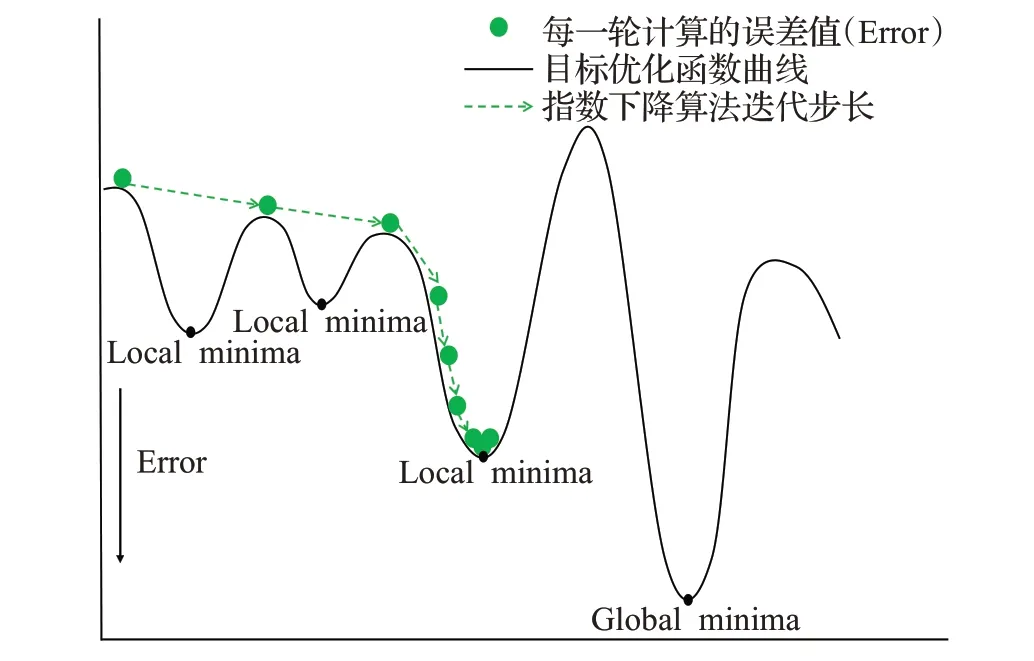
圖9 指數下降算法控制下的尋優過程Fig.9 Optimization process controlled by exponential LR
文獻[20]將模擬退火算法與正余弦算法結合,提出的余弦退火算法(cosine annealing warm restarts,CAWR)解決了模型陷入局部最優的問題,學習率下降曲線如圖8(b)所示。CAWR算法中加入了重啟(restart)機制,在學習率下降到一個較低點時重啟返回到原點,通過這種方法增大步長跳出局部最小點,但由于CAWR每次重啟時均回到初始值,初始較大的步長可能導致模型跳出global minima。如圖10中CAWR控制的優化器在到達第三個local minima后學習率降為最小值,這時restart學習率增大步長使模型跳出了局部最小點繼續尋優,但global minima處的再一次的restart讓模型跳出了全局最小點;因此余弦退火算法優化器可以找到目標優化函數的最優值,但很難在最優值點處達到穩定,增加了模型訓練達到收斂的時間。

圖10 余弦退火算法控制下的尋優過程Fig.10 Optimization process controlled by cosine annealing warm restarts
為了解決指數下降算法的局部最優問題和余弦退火算法重啟機制造成的模型訓練收斂時間慢的問題,將指數下降算法的逐步下降規律與余弦退火算法的重啟機制結合,設計一種新的余弦退火算法(CDWR)。首先,在算法中加入重啟機制,將restart次數減小為3次,同時增加每個restart后的batch數量來保證模型重啟跳出局部最優后能達到下一個穩定值,然后,每次restart后降低學習率最大值為前一峰值的2/3,總體上逐步減小權重更新步長,在保持模型有跳出局部最優能力的情況下逐漸變得穩定,最后,在算法中加入預熱[21](warm up)機制,學習率在訓練開始時設置為0逐漸增大,模型在學習率增大過程中進行預熱訓練,直到達到設定值后開始正式訓練,因為初始時模型權重是隨機值,較大的學習率讓權重大幅度振蕩,而warm up使權重達到穩定之后再開始正式訓練,模型收斂速度會變得更快,CDWR算法的下降曲線如圖8(c)所示。CDWR算法的尋優過程如圖11所示,在初始warm up階段權重步長逐漸變大,在到達第三個local minima處陷入局部最小,此時經過restart后跳出局部最小點逐步到達global minima,這時模型再次restart后學習率僅能達到第一次的2/3,此學習率下優化器的步長已經不能跳出當前全局最小點,之后模型權重在global minima左右擺動直到到達全局最小點。

圖11 改進余弦退火算法控制下的尋優過程Fig.11 Optimization process controlled by cosine decay warm restarts
CDWR算法的計算公式如下:

式中Ti是當前訓練批次數,T是總訓練批次數,Twarm是預熱批次數,Thold是學習率維持不變批次數,μmax是學習率最大值,μmin是學習率最小值,φ是幅度變化常數,lr是當前學習率大小,count是跳出局部最優次數。
3 實驗
3.1 實驗數據集
實驗數據使用的是safety helmet wearing數據集共7 581張圖片,數據集中的圖片來自谷歌和百度,并且使用Labelimg對圖片進行了標定,符合實驗訓練要求。使用其中3 241張圖片進行實驗,訓練集和測試集的比例設置為9∶1,訓練集圖片數量為2 624張,驗證集數量293張,測試集數量324張。
3.2 實驗環境
實驗在Win10操作系統上進行訓練和測試,顯卡使用NVIDIA Tesla K80,深度學習框架為Pytorch,使用GPU進行運算,使用CUDA并行架構來提高計算能力,在訓練過程中訓練批次大小(batch size)設置為32,初始學習率(learning rate)設置為0.01,實驗所需的具體運行環境如表1所示。

表1 實驗訓練環境配置Table 1 Experimental training environment configuration
3.3 模型訓練
實驗中訓練集圖片數量2 624張,1個訓練批次(batch size)包含32張圖片,1個訓練周期(epoch)包含82個訓練批次,本次實驗總共訓練100個周期,8 200個批次,262 400張圖片。在訓練過程中,每完成1個訓練批次(batch size)調節1次學習率,實驗總共調節8 200次學習率,學習率由改進余弦退火算法(CDWR)調節。
3.4 評價指標
能反映網絡模型性能的因素主要有網絡模型的檢測精度、檢測速度和模型的權重大小,對以上因素進行評價需要恰當的評價指標。本文使用召回率(recall)、精確率(precision)、平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)指標來評價模型的檢測精度,使用幀率(frame per second,FPS)指標來評價模型的檢測速度,使用模型參數量(parameter)指標來評價模型的權重大小,使用損失值(loss)指標來評價模型的訓練情況。
3.4.1 召回率和準確率
召回率和準確率的計算方法為公式(6)和(7):

式中,R表示召回率,P表示準確率;TP為預測正確的正樣本數,FN為預測錯誤的負樣本數,FP為預測錯誤的正樣本數。
3.4.2 平均精度和平均精度均值
平均精度和平均精度均值的計算方法為公式(8)和(9):

式中,AP為平均精度,mAP為平均精度均值,PA為不同檢測類別均精度的計算需要用到召回率和準確率;在模型實驗結束后會得到所有數據的召回率和準確率值,將這兩個值作為橫縱坐標軸,可以繪制出模型的PR曲線圖,使用積分計算出曲線圖的面積,就可以得到模型的平均精度AP,AP值用于評估模型在單個檢測類別上的表現;所有類別的AP的平均值就是mAP值,模型的mAP值越高,其檢測性能越好。
3.4.3 幀率
幀率(FPS)表示模型每秒處理圖片的數量,模型的幀率越大處理圖片的速度越快,模型的檢測速度也越快。
3.4.4 參數量
模型參數量和計算量的計算如公式(10):

其中,Params表示在一個卷積層且不考慮偏置條件下的參數量,公式中K為卷積核大小,Ci、Co為輸入輸出通道數量,H、W為輸入特征的大小。
3.4.5 損失值

在訓練中使用二值交叉熵損失函數來計算損失值,式中Yi為類別標簽,p(Yi)為目標被預測為該類別的概率,N為被預測為該類別的目標數量。將模型訓練過程中的所有損失值繪制成曲線圖,可以得到模型訓練時的損失下降情況和收斂情況。
3.5 實驗結果及分析
3.5.1 消融實驗
為了驗證各個模塊對YOLOX-s2檢測效果的影響,在safety helmet waring數據集上進行消融實驗,實驗以YOLOX-s作為基線模型,逐漸增加模塊測試模型的性能結果,消融實驗結果如表2所示。

表2 消融實驗結果Table 2 Ablation experimental results
對比YOLOX-s和YOLOX-s+OHEM的性能,加入在線困難樣本挖掘方法的模型比基線模型mAP提升了0.88個百分點,recall提升了2.35個百分點,表明使用OHEM方法對難識別圖像反復檢測能在一定程度上提高對安全帽特征的提取能力,增加樣本中檢測到安全帽的數量。加入Mosaic的YOLOX-s+OHEM模型與YOLOX-s+OHEM相比mAP提升了3.39個百分點,F1提升0.3,precision提升2.65個百分點,recall提升3.58個百分點,證明對經過Mosaic預處理后的數據集訓練可以增強網絡識別定位物體的能力,提高模型在多數量小目標場景下及復雜環境下判別安全帽的能力。對比YOLOX-s+OHEM+Mosaic+CDWR和YOLOX-s+OHEM+Mosaic的性能,加入CDWR后的模型mAP僅提升了0.06個百分點,因為學習率控制器對模型的檢測效果影響較小,其最主要的作用是控制模型在更少的時間里達到收斂,模型收斂時間對比結果詳見3.5.3小節。
對比YOLOX-s+OHEM+Mosaic+CDWR和YOLOX-s+OHEM+Mosaic+CDWR+BA性能,加入分支注意力模塊后模型mAP提升2.36個百分點,F1提升0.4,precision提升5.29個百分點,recall提升2.34個百分點,表明分支注意力模塊可以對每層通道和通道特征點合理分配權重,提升網絡對存在物體區域的關注程度,獲得關鍵區域的類別與位置信息。
對比消融實驗的所有模型,向基線模型逐漸增加模塊后各改進模型的detection time和FPS變化幅度較小,證明在實驗中增加模塊提升模型準確率和召回率的同時,并沒有較大增加對圖片的檢測時間,改進模型的檢測速度仍然符合實時檢測要求。
3.5.2 注意力模塊可視化實驗
對加入分支注意力(BA)的仿真結果與未使用注意力模塊的仿真結果進行可視化處理,可視化處理結果如圖12所示,對比兩者的可視化圖可以發現使用BA的模型結果比原模型結果覆蓋了更多包含安全帽的面積。因為未加入注意力模塊的方法過于關注圖片中特征明顯的物體,容易檢測到帶有明顯特征的目標,但經常漏檢錯檢小目標與特征不明顯的目標。實驗中帶有BA的方法不僅關注主要特征,對較為次要的特征也給予了關注權重,因此可以提取到更多信息,仿真結果中也能檢測到更多的物體。

圖12 可視化處理結果Fig.12 Visual simulation results
BA模塊的兩個分支分別給類別通道的通道、位置與置信度通道的空間點分配不同大小的權重,根據權重大小反應通道和空間點的重要性,為了證明BA模塊的每個分支都有效果,將經過上分支的類別通道和經過下分支的位置與置信度通道進行像素值分布可視化。
實驗設置兩個類別通道,第一個通道為正確類別safety helmet,第二個通道設置為數據集中不存在的類別book,將模型訓練40個epoch后按通道像素值繪制直方圖,每個通道的像素值分布如圖13所示。圖13(a)為所要檢測物體正確類別通道的像素值分布情況,其像素點有多半像素值大于0,表明該通道極有可能是正確類別,對照組圖13(b)為第二個通道的像素值分布情況,由直方圖發現二通道的所有像素值均小于0,表明在檢測圖片中不存在該通道類別的物體。

圖13 類別通道像素值可視化Fig.13 Visualization of category channel pixel value
初始時位置與置信度通道的像素值分布情況如圖14(a)所示,通道上的像素值集中在0附近,存在較多像素值大于0.5的像素點(像素值大于0.5表示該特征點有很大概率存在物體)表明這時通道空間點的像素值為隨機分布,對圖像中物體位置、置信度信息描述仍不準確。經過40個epoch訓練后,位置與置信度通道的像素值的分布情況為14(b)所示,此時大部分空間點的像素值小于0,對應圖像中大多數不存在物體的特征點,只有少數像素值處于(0,1)之間,此時位置與置信度輸出特征包含了圖像中接近真實物體數量的位置與置信度信息。

圖14 位置與置信度通道像素值可視化Fig.14 Visualization of position-confidence channel pixel value
3.5.3 模型訓練結果
使用CDWR控制模型學習率并進行100個周期(epoch)的訓練后,YOLOX-s2模型的損失值變化情況如圖15所示。訓練到30個周期時模型的損失值逐漸趨于穩定但仍處于一個較高值,可以基本確定此時模型陷入局部最優;此時將學習率升高使模型訓練到60個周期時達到了更低點,證明模型跳出了局部最優點,同理當模型訓練到90個周期時損失再次達到更低點,在此之后損失值基本不再變化,從模型損失值的下降情況來看模型訓練結果較為理想。

圖15 模型在訓練過程中的損失變化情況Fig.15 Loss change of model during training
為檢測改進學習率對模型訓練時間的影響,分別將YOLOX-s2模型的學習率下降算法設置為指數下降算法(ELR)、余弦退火算法(CAWR)和本文提出的CDWR算法,在相同實驗環境下進行三次訓練。實驗結果如圖16所示,可以看出使用改進余弦退火控制學習率的曲線在第十個訓練周期時已經達到穩定,和另外兩個算法相比收斂時間較快,與原余弦退火算法相比收斂時間減少50%以上,并且在同樣的訓練周期下模型損失值能下降到一個更低點,與指數下降算法相同訓練周期下的損失值下降了1左右,與余弦退火算法相比損失值下降了0.5左右。

圖16 訓練中的模型損失變化曲線Fig.16 Model loss variation curve in training
3.5.4 對比實驗
實驗選擇目前目標檢測領域主流方法SSD、CenterNet、YOLOv3、YOLOv4、YOLOv5-s、YOLOX-s與本文方法進行比較,其中SSD、YOLOv3、YOLOv4[22]、YOLOv5-s是基于錨框的單階段類型檢測方法,Center-Net、YOLOX-s是無錨框(anchor free)類型檢測方法,YOLOv5-s、YOLOX-s、YOLOX-s2是輕量級檢測方法。對以上方法實驗后的性能結果,如表3所示。
從表3中可以看出,SSD、YOLOv3、YOLOv4作為基于錨框單階段檢測方法的準確率(precision)和召回率(recall)均達到60%以上,但參數量(params)較大模型權重(weight)均在100 MB以上,檢測時間(detection time)長,不適合配置在移動端且不滿足實時檢測要求。無錨框檢測方法CenterNet的precision為99.72%,在所有方法中領先,但recall僅為44.13%,表明該方法幾乎可以正確識別出檢測到的安全帽,但很難檢測到所有安全帽,同時params與weight太大,也不適合配置在移動端。對比輕量級網絡檢測方法YOLOv5-s、YOLOX-s和YOLOX-s2,YOLOv5-s的params與weight最小,僅為7.1×106和27.9 MB,但平均精度均值(mAP)在三者中最低,檢測效果相對較差,本文算法YOLOX-s2在略微增加params和weight的條件下,模型的mAP值達到95.11%,precision值為95.18%,recall值為90.23%,檢測性能領先于其他輕量級檢測方法,且較低的params和weight適合布置在移動端進行實時檢測。

表3 本文方法與現有方法性能比較Table 3 Performance of proposed method compared with existing methods
為對比本文方法YOLOX-s2與原方法YOLOX-s對施工場景下安全帽的檢測效果,選取多張施工場景下的圖像進行檢測。圖17(a)為YOLOX-s方法的檢測結果,圖17(b)為本文方法的檢測結果。從圖中可以看出,使用YOLOX-s對安全帽進行檢測存在錯檢和漏檢,而在YOLOX-s2中錯檢漏檢問題出現得更少,因此可以證明在YOLOX-s中加入經過改進的注意力模塊提高了模型特征提取和分析能力,使得模型對目標的預測準確率更高,在訓練過程中使用在OHEM與Mosaic結合的數據增強方法提高了模型對困難目標的檢測能力,讓YOLOX-s2模型能檢測到一些難以發現的小目標。

圖17 兩種模型檢測結果對比Fig.17 Comparison of test results of two models
4 結束語
本文對YOLOX網絡進行改進,使用在線困難樣本挖掘和Mosaic數據增強的方法重點訓練困難樣本,在模型預測端加入分支注意力模塊提高模型在復雜環境下的檢測精度,在訓練中使用CDWR算法替代指數下降算法控制學習率來減少模型訓練收斂時間。消融實驗結果表明對原始模型進行以上方法改進均在不同程度上提高了檢測性能。本文通過實驗證明YOLOX-s2方法的檢測精度和檢測時間符合施工環境下實時檢測安全帽的需求,并且適合移植到低算力平臺進行實驗。在后續研究中將繼續完善YOLOX-s2方法來提高檢測精度和檢測速度,同時將模型移植到移動端來進行測試。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
