Transformer在計算機視覺領域的研究綜述
2023-01-13 11:56:42魏宏楊錢育蓉
計算機工程與應用 2023年1期
李 翔,張 濤,張 哲,魏宏楊,錢育蓉
新疆大學 軟件學院,烏魯木齊 830002
Transformer[1]是一種基于自注意力機制的模型,不僅在建模全局上下文方面表現強大,而且在大規模預訓練下對下游任務表現出卓越的可轉移性。這種成功在機器翻譯和自然語言處理(NLP)領域上得到了廣泛的見證。2018年,Devlin等人[2]在Transformer的基礎上提出了基于掩碼機制雙向編碼結構的Bert模型,在多種語言任務上達到了先進水平。此外,包括Bert在內許多基于Transformer的語言模型,如GPTv1-3[3-5]、Ro-BERTa[6]、T5[7]等都展現出了強大的性能。
在計算機視覺任務中,由于CNN固有的歸納偏好[8],如平移不變性、局部性等特性,一直占據著主導地位(CNN[9]、ResNet[10]等)。然而CNN有限的感受野使其難以捕獲全局上下文信息。受Transformer模型在語言任務上成功的啟發,最近多項研究將Transformer應用于計算機視覺任務中。Parmar等人[11]基于Transformer解碼器的自回歸序列生成或轉化問題提出了Image Transformer模型用于圖像生成任務。Carion等人[12]基于Transformer提出了DETR(一種端到端目標檢測),其性能取得了與Faster-RCNN相當的水平。最近Dosovitskiy等人[13]提出的另一個視覺Transformer模型ViT,在結構完全采用Transformer的標準結構。ViT在多個圖像識別基準任務上取得了最先進的水平。除了基本的圖像分類之外,Transformer還被用于解決各種其他計算機視覺問題,包括目標檢測[14-15]、語義分割[16]、圖像處理和視頻任務[17]等等。由于其卓越的性能,越來越多的研究人員提出了基于Transformer的模型來改進廣泛的視覺任務。
目前,基于Transformer的視覺模型數量迅速增加,迫切需要對現有研究進行整體的概括。在本文中,重點對視覺Transformer的最新進展進行全面概述,并討論進一步改進的潛在方向。為了方便未來對不同結構模型的研究,將Transformer模型按結構分類,主要分為純Transformer、CNN+Transformer混合結構以及利用Transformer改進的CNN結構。
雖然Transformer在計算機視覺領域上展現了其先進的性能,但也面臨著參數量大、結構復雜、尺寸大小不可調節等問題。本文分別從訓練技巧、補丁嵌入、自注意力機制、金字塔架構等多方面介紹了Transformer的各種改進結構。在本文最后一部分,給出了結論和面臨的一些問題,并對未來的發展方向進行展望。
1 Transformer基本結構
2017年,Vaswani等人[1]首次提出了Transformer模型(如圖1所示),它是由6個編碼器-解碼器模塊組成,每個編碼器模塊由一個多頭自注意層和一個前饋神經網絡層組成;每個解碼器模塊由三層組成,第一層和第三層類似于編碼器模塊,中間是交叉注意力層,該注意力層k、v的輸入是由相應編碼器模塊的輸出組成。本章主要對Transformer中各個模塊的特點進行介紹。

圖1 Transformer整體結構Fig.1 Transformer overall structure
1.1 位置編碼
由于Transformer的輸入是一種單詞(句子)特征序列(這種序列具有置換不變性),而Transformer中Attention模塊是無法捕捉輸入的順序,因此模型就無法區分輸入序列中不同位置的單詞。為了得到輸入序列的位置信息,Transformer將位置編碼添加到輸入序列中以捕獲序列中每個單詞的相對或絕對位置信息。
(1)絕對位置編碼
絕對位置編碼通過預定義的函數生成[1]或訓練學習得到[2],具有與輸入序列相同的維度,采用相加操作將位置信息添加到輸入序列中。文獻[1]中使用交替正弦函數和余弦函數來定義絕對位置編碼,其公式如下:

其中pos是目標在序列中的位置,i是維度,d是位置編碼維度。
(2)相對位置編碼。
相對位置編碼不同于絕對位置編碼直接在其輸入序列加入位置信息,而是通過擴展自我注意機制,以有效地考慮相對位置或序列元素之間的距離。在計算Attention時考慮當前位置與被Attention位置的相對距離。文獻[18]中考慮輸入元素之間的成對關系在注意力計算中加入了相對位置向量Ri,j,公式如下:

對Ri,j設置了截斷、丟棄長遠距離的無效信息,從而減少了計算量,可以使模型泛化到在訓練過程中未見的序列長度。
其他方式的位置編碼。除了上述方法之外,還有一些其他類型的位置編碼,例如遞歸式的位置編碼[19]、CNN式位置編碼[20]、復數式位置編碼[21]、條件位置編碼CPVT[22]等。
1.2 自注意力機制
注意力機制模仿了生物觀察行為的內部過程,即一種將內部經驗和外部感覺對齊從而增加部分區域的觀察精細度的機制。注意力機制可以快速提取稀疏數據的重要特征,因而被廣泛應用于自然語言處理、語音和計算機視覺等領域。注意力機制現在已成為神經網絡領域的一個重要概念。其快速發展的原因主要有3個:首先,它是解決多任務較為先進的算法;其次,被廣泛用于提高神經網絡的可解釋性;第三,有助于克服RNN中的一些挑戰,如隨著輸入長度的增加導致性能下降,以及輸入順序不合理導致的計算效率低下。
自注意力機制是注意力機制的改進,其減少了對外部信息的依賴,更擅長捕捉數據或特征的內部相關性,通過對序列中元素之間的所有成對交互關系進行建模,讓機器注意到整個輸入中不同部分之間的相關性。自注意力層通過定義3個可學習的權重矩陣{WQ,WK,WV},將輸入序列投影到這些權重矩陣上,得到三元組Q=XWQ,K=XWK,V=XWV。自注意力計算公式如下:

其中dk等于矩陣K的維度大小。
(1)多頭注意力
多頭注意力(如圖1左部分)是在單頭注意力的基礎上將輸入序列X在其通道維度上劃分成h個頭,即[B,dim]→[B,h,dim/h]。每個頭使用不同的可學習權重{WQi,WKi,WVi},對應生成不同的{Qi,Ki,Vi}組。由于注意力在不同的子空間中分布不同,使用多頭注意力機制可以形成多個子空間,從而將輸入映射到不同的空間中,使模型學習到輸入數據之間不同角度的關聯關系。多頭注意力總的參數量不變只改變每個頭的維度,計算量和單頭自注意力相當。
多頭自注意力機制中并行使用多個自注意力模塊,不同頭部關注不同的信息(如全局信息和局部信息)可以豐富注意力的多樣性,從而增加模型的表達能力。
(2)局部注意力
局部注意力僅在相鄰的部分區域內執行注意力,解決了全局注意力計算開銷過大的問題。對于視覺圖像平面空間上局部區域計算,Parmar等人[11]提出了2D局部注意力模塊,網絡可以更均勻地平衡水平和垂直方向相鄰空間上的局部上下文信息(如圖2所示),大大降低了計算復雜度。其中,圖2(a)是local attention整體結構(由局部注意力和前饋網絡組成),輸入一個單通道像素q,預測生成像素q′。mi表示先前預測生成的像素塊,pq和pi是位置編碼。圖2(b)是2D local attention執行過程圖。q表示最后預測生成的像素,白色網格表示對預測位置貢獻為0具有屏蔽作用,青色矩形為最后生成的所有像素區域。

圖2 局部注意力Fig.2 Local attention
(3)稀疏注意力機制
局部注意力雖然可以減少計算量,但其無法捕獲全局上下文信息。Child等人[23]提出了稀疏注意力機制,通過top-k選擇將全局注意退化為稀疏注意。這樣可以保留最有助于引起注意的部分,并刪除其他無關的信息。這種選擇性方法在保存重要信息和消除噪聲方面是有效的,可以使注意力更多地集中在最有貢獻的價值因素上。稀疏注意力有兩種方式,第一種步長注意力(如圖3(c)所示)是在局部注意力的基礎同時每隔N個位置取一個元素進行注意力計算。但是對于一些沒有周期性結構的數據(如文本),步長注意力關注的信息可能與該元素并不一定是最相關的信,可以采用固定式注意力(如圖3(d)所示)將先前預測的特定位置的信息傳播到未來所有需要預測的元素中,具體公式如下:

圖3 4種注意力方案Fig.3 Four attention schemes

其中c是超參數。
1.3 前饋神經網絡及其層歸一化
Transformer中除了注意力子層之外,每個編碼器和解碼器都包含一個完全連接的前饋神經網絡,該模塊由兩個線性層組成,中間包含一個ReLU激活層。前饋網絡對序列中不同位置的元素使用相同的處理方式,雖然不同位置的線性變換是相同的,但它們在層與層之間使用不同的參數。其計算公式如下:

其中,輸入輸出維度是512,內層的維度是2 048。
隨著網絡深度的增加,數據的分布會不斷發生變化。為了保證數據特征分布的穩定性,Transformer在注意力層和前饋網絡層之前加入layer normalization層,這樣可以加速模型的收斂速度,該過程也被稱為前歸一化,其計算公式如下:

然而每個殘差塊輸出的激活值被直接合并到主分支上。隨著層數的加深該激活值會逐層累積,使得主分支的振幅會越來越大。導致深層的振幅明顯大于淺層的振幅,而不同層中振幅的差異過大會導致訓練不穩定。為了緩解這個問題,Swin-Transformer v2[24]提出一種后歸一化處理,將layer normalization層從每個子層之前移到每個子層之后,這樣可以使得每個殘差塊的輸出在合并回主分支之前被歸一化。當網絡層數增加時,主分支的振幅不會累積,其激活幅度也比原始的前歸一化處理要溫和得多,可以大大提高大型視覺模型的穩定性。
2 視覺Transformer
2.1 Transformer在視覺上的應用
本節重點從圖像分類、目標檢測兩個應用場景出發,介紹了Transformer在視覺任務上一些應用以及相應的改進方法。
2.1.1 圖像分類ViT網絡及其改進
Dosovitskiy等人[13]首次提出了ViT(如圖4所示),將原始的Transformer應用于圖像分類任務,是一種完全基于自注意力機制的純Transformer結構,網絡結構中不包含CNN。

圖4 視覺Transformer(ViT)Fig.4 Vision Transformer(ViT)
對于輸入的2D(X∈RC×H×W)圖像數據,ViT將其重新塑造成一系列扁平的2D圖像塊XP∈Rn×(p2×C),其中C是通道數。將輸入分辨率為(H,W)的原始圖像,劃分為每個分辨率為(p,p)的圖像塊(補丁),其有效的輸入序列長度為n=HW/p2。ViT也采用了與Bert類似的[class]分類標記,該標記可以表示整個圖像的特征信息,被用于下游的分類任務中。ViT通常在大型數據集上預訓練,針對較小的下游任務預訓練。在ImageNet數據集上取得了88.55% Top-1的準確率,超越了ResNet系列模型,打破了CNN在視覺任務上的壟斷,相較于CNN具有更強泛化能力。
ViT取得了突破性的進展,但在機器視覺領域中也有其缺陷:(1)ViT輸入的token是固定長度的,然而圖像尺度變化非常大;(2)ViT的計算復雜度非常高,不利于具有高分辨率圖像的視覺應用。針對這些問題,Liu等人[25]提出了Swin Transformer,通過應用與CNN相似的分層結構來處理圖像,使Transformer模型能夠靈活處理不同尺度的圖片。Swin Transformer采用了窗口注意力機制,只對窗口內的像素區域執行注意力計算,將ViT token數量平方關系的計算復雜度降低至線性關系。
2.1.2 目標檢測DETR網絡及其改進
Carion等人[12]提出的DETR,使用CNN主干網絡提取緊湊特征表示,然后利用Transformer編碼器-解碼器和簡單的前饋網絡(FFN)做出最終的目標檢測任務(如圖5所示)。DETR將目標檢測視為集合預測問題,簡化了目標檢測的整體流程,將需要手動設計的技巧如非極大值抑制和錨框生成刪除,根據目標和全局上下文之間的關系,直接并行輸出最終的預測集,實現了端到端的自動訓練和學習。在COCO[26]數據集上,DETR的平均精確度AP為42%,在速度和精度上優于Faster-RCNN。

圖5 DETR模型結構Fig.5 DETR model structrue
DETR具有良好的性能,但與現有的CNN模型相比,它需要更長的訓練周期才能收斂。在COCO基準測試中,DETR需要迭代500次才能收斂,這比Faster R-CNN慢10到20倍。Zhu等人[14]提出的Deformable DETR模型,結合了形變卷積[27]稀疏空間采樣的優點和Transformer長遠關系建模提出了可變形注意模塊,該模塊只關注所有特征圖中突出的關鍵元素,可以自擴展到聚合多尺度特征,而無需借助FPN(特征金字塔)模塊[28],取得了比DETR更好的結果且訓練收斂速度也更快。Sun等人[29]表明導致DETR收斂緩慢的主要這些問題提出了兩種解決方案,即TSP-FCOS和TSP-RCNN。該方法不僅比原始DETR收斂速度快得多,而且在檢測精度和其他基線方面也明顯優于DETR。
其次,DETR在檢測小物體的性能上相對較低。目前目標檢測模型通常利用多尺度特征從高分辨率特征圖中檢測小物體,然而高分辨率特征圖會導致DETR不可接受的復雜性。Zheng等人[30]提出的ACT模型,一種自適應聚類注意力,通過使用局部敏感哈希(LSH)自適應地對查詢特征進行聚類,并使用原型鍵在查詢鍵交互附件進行聚類,降低了高分辨率圖像的計算成本,同時在準確性上也取得了良好的性能。
2.1.3 其他應用方面
其他基于Transformer在視覺各領域中的應用:有Image Transformer模型用于圖像生成任務;SETR用于圖像分割模型,使用Transformer編碼器替換基于堆疊卷積層的編碼器進行特征提取;ViT-FRCNN[31]模型主要是將ViT與FRCNN的結合用于大型目標檢測任務中。有基于掩模的視覺Transformer(MVT)[32]用于野外的面部表情識別任務。表1對Transformer不同的應用場景進行了分類。

表1 關于Transformer在視覺任務中的應用Table 1 About application of Transformer in visual tasks
2.2 基于Transformer泛化性能不足的改進
本節介紹了提高Transformer泛化性能的改進方法。現有的工作主要在知識蒸餾、特征融合、樣本量以及泛化能力幾個方面Transformer提出各種改進進行研究。
2.2.1 基于知識蒸餾的改進
知識蒸餾可以解釋為將教師網絡學到的信息壓縮到學生網絡中。Touvron等人[33]提出的DeiT(如圖6所示)在Transformer的輸入序列中加入了蒸餾token,該蒸餾token與分類token地位相當都參與了整體信息的交互過程,蒸餾token通過使用Convnet教師網絡對比學習,可以將卷積的歸納偏好和局部性等特性融合到網絡中使DeiT更好地學習。蒸餾學習的過程有兩種方式:一種是hard-label蒸餾,直接將教師網絡的輸出坐標標簽;另一種是使用KL散度衡量教師網絡和學生絡的輸出。實驗結果表明,Transformer通過蒸餾策略可以取得更好的性能。

圖6 DeiT模型結構Fig.6 DeiT model structure
2.2.2 針對訓練樣本不足的改進
最近的研究發現[13,33],基于Transformer的網絡模型參數量很大,如果訓練樣本不足,很容易造成過擬合。為了解決這一問題,可以在訓練過程中應用數據增強和正則化技術,例如Mixup[51]和CutMix等基于混合的數據增強方法能夠明顯提高視覺Transformer的泛化能力[33]。CutMix混合標簽公式如下:

其中λ是混合標簽后的裁剪面積比。如圖7為上述幾種數據增強方法的效果對比圖。

圖7 數據增強方法Fig.7 Data augmentation methods
然而基于混合生成圖像中可能沒有有效對象,但標簽空間仍有響應。Chen等人[52]提出了TransMix方法,該方法基于Transformer中的注意力圖生成混合標簽。TransMix網絡根據每個數據點在注意圖中的響應動態地重新分配標簽權重,標簽的分配不再是裁剪到輸入圖像的顯著區域而是從更準確的標簽空間中分配標簽,可以改進各種ViT模型性能,對下游密集預測任務(圖像分割、目標檢測等)表現出了較好的可移植性。其權重分配計算公式如下:

其中,·↓為最近鄰下采樣,M是圖像覆蓋區域的位置。
2.2.3 針對提高泛化能力的改進
泛化能力是指網絡對新樣本的可擴展能力。對于泛化能力的改進可以從兩個方面進行:一方面由于網絡對數據學習的不充分,導致泛化能力不足,Jiang等人[53]提出了補丁標記MixToken,將除了分類token以外的所有補丁token生成一個軟標簽計算loss,通過多監督的方式學習提高模型的性能,該方法有利于具有密集預測的下游任務,例如語義分割。另一方面由于高容量的ViT模型容易對訓練樣本過擬合,對新樣本表現欠擬合,通過自監督學習圖像重要的表征信息,可以提高模型的泛化能力,Chen等人[54]提出的MoCoV3,通過將同一圖像不同變換作為正例,不同圖像作為負例,使用雙分支網絡對比學習圖像的表征信息。
此外,基于Transformer自監督學習在自然語言處理中的成功啟發(如BERT掩碼自編碼等),He等人[48]提出了一種簡單、有效且可擴展的掩碼自編碼器MAE,從輸入序列中隨機屏蔽掉75%的圖像塊,然后在像素空間中重建被屏蔽的圖像塊。MAE是一種非對稱的編碼器-解碼器結構(如圖8所示),其中編碼器僅作用于無掩碼標記塊,而解碼器通過隱表達與掩碼標記信息進行原始圖像重建.該結構采用小型解碼器大幅度減少了計算量,同時也能很容易地將MAE擴展到一些大型視覺模型中。在ViT-Huge模型上使用MAE自監督預訓練后,僅在ImageNet上微調就可以達到87.8%的準確率。在對象檢測、實例分割和語義分割的遷移學習中,使用MAE預訓練要優于有監督的預訓練。

圖8 非對稱編碼器-解碼器結構(MAE)Fig.8 Asymmetric encoder-decoder structure(MAE)
2.3 基于Transformer面向結構模塊的改進
目前遵循ViT的范式,已經提出了一系列Transformer變體來提高視覺任務的性能。主要的改進結構包括補丁嵌入、自注意力改進和金字塔架構等,本節主要從這幾個方面介紹[35]了最新的一些研究方法。
2.3.1 針對補丁嵌入的改進方法
(1)基于提高特征提取能力的補丁嵌入方法
Han等人[35]提出的TNT(如圖9所示),將補丁劃分為多個更小的子補丁(例如,將27×27的補丁再細分為9個3×3的塊,并計算這些塊之間的注意),引入了一種新穎的Transformer in Transformer架構,用于對patch級和pixel級的表征建模。該架構利用Inner Transformer block塊從pixel中提取局部特征,Outer Transformer block聚合全局的特征,通過線性變換成將pixel級特征投影到patch空間中將補丁和子補丁的特征進行聚合以增強表示能力。

圖9 TNT網絡結構Fig.9 TNT network structure
Yuan等人[42]提出的CeiT,結合CNN提取low-level特征的能力設計了一個image-to-token(I2T)模塊,該模塊從生成的low-level特征中提取patch。
Wang等人[55]提出的CrossFormer,利用跨尺度嵌入層CEL為每個階段生成補丁嵌入,在第一個CEL層利用4個不同大小的卷積核提取特征,將卷積得到的結果拼接起來作為補丁嵌入。
(2)基于長度受限的補丁嵌入
許多視覺Transformer模型面臨的主要挑戰是需要更多的補丁數才能獲得合理的結果,而隨著補丁數的增加其計算量平方增加。Ryoo等人[56]提出了一種新的視覺特征學習器TokenLearner(如圖10所示),對于輸入x,通過s個ai函數(該函數由一系列卷積組成)學到一個空間權重(H×W×1)去乘以x然后通過全局池化,最終得到一個長度為s的token序列。TokenLearner可以基于圖像自適應地生成更少數量的補丁,而不是依賴于圖像均勻分配補丁。實驗表明使用TokenLearner可以節省一半或更多的內存和計算量,而且分類性能并不會下降甚至可以提高準確率。
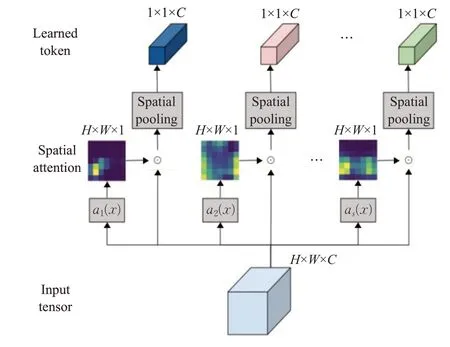
圖10 TokenLearner模塊Fig.10 TokenLearner module
PSViT[57]采用補丁池化在空間維度上減少補丁的數量。T2T-ViT[40]通過T2T模塊遞歸地將相鄰的補丁組合成為單個補丁,這樣可以對相鄰的補丁表示進行跨局部建模同時減少了一半的補丁數。
2.3.2 針對自注意力機制的改進方法
(1)基于注意力機制的改進方法
PSViT]將相鄰的Transformer層之間建立注意力共享[57,以重用相鄰層之間具有強相關性的注意力圖。Shazeer等人[58]提出了一種交談注意力機制,在softmax操作前引入對多頭注意力之間的線性映射,以增加多個注意力機制間的信息交流。文獻[59]探索了高維空間中的注意力擴展,并應用卷積來增強注意力圖。Zhou等人[60]提出了DeepViT模型,通過重新生成注意力圖以增加不同層的多樣性。CaiT將補丁之間的自注意力層與類注意力層分離[61],使類標記專注于抽取圖片的信息。XCiT利用互協方差注意力(XCA)跨特征通道執行自注意力計算[62],其操作具有線性復雜性,可以對高分辨率圖像進行有效處理。表2總結了上述幾種方法的參數量和計算量的一些情況。

表2 模型的參數量和計算量對比Table 2 Comparison of model params and FLOPS
(2)針對局部區域改進的局部注意力機制
Swin Transformer[25]在局部窗口內執行注意力計算。RegionViT提出了區域到局部的注意力計算[43]。Multi-scale vision Longformer[63]利用Longformer[64]設計了自注意力模塊,加入了局部上下文信息。KVT引入了KNN注意力[65]利用圖像塊的局部性通過僅計算具有前k個相似標記的注意力來忽略不相關的標記。CSWin Transformer提出了一種新穎的十字形窗口自注意力[45],在其基礎上Pale Transformer提出了一種改進的自注意力機制PS-attention[47],在一個Pale-shaped的區域內進行自注意力的計算(圖11中介紹了Transformer不同注意力機制的效果圖),可以在與其他的局部自注意力機制相似的計算復雜度下捕獲更豐富的上下文信息。DAT提出了一種新的可變形的局部自注意力模塊[66],該模塊以數據依賴的方式選擇自注意力中key和value對的位置。這種更靈活的自注意力模塊能夠聚焦于更相關的區域信息。Han等人[67]從稀疏連接、權重共享和動態權重等方面揭示了局部視覺Transformer的網絡特征。

圖11 Transformer中不同自注意力機制Fig.11 Different self-attention mechanisms in Transformer
(3)基于局部注意力與全局注意力相結合的改進方法
盡管局部窗口[25]的自注意力機制是計算友好的,但缺少豐富的上下文信息。為了捕獲更豐富的上下文信息。Twins將每個子窗口概括為一個代表元素執行全局子采樣注意力(GSA)[36]。CAT將每個通道的特征圖分離并使用自注意力來獲取整個特征圖中的全局信息[68]。Focal Transformer引入了焦點自我注意以捕獲全局和局部關系[44]。CrossFormer引入了長短距離注意力(LSDA)[55],以捕捉局部和全局視覺信息。TransCNN設計一種分層多頭注意力模塊(H-MHSA)[46]可以更有效地對全局關系進行建模。
2.3.3 針對提高計算效率的改進結構——金字塔結構
金字塔結構一般常用于卷積網絡中,通過縮減空間尺度以增大感受野,同時也能減少計算量。但是對于Transformer其本身就是全局感受野,可以直接堆疊相同的Transformer encoder層。而對于密集預測任務中當輸入圖像增大時,ViT計算量會急劇上升,如果直接增大patch size(如16×16)得到粗粒度的特征,這對于密集任務來會有較大的損失。
Wang等人[34]提出的PVT是第一個采用特征金字塔的Transformer結構,包含了漸進式收縮金字塔和空間縮減注意力模塊SRA(如圖12所示),SRA通過reshape恢復3-D(H×W×C)特征圖,重新均分為大小R×R的補丁塊將K、V的補丁數量縮小R倍,相較于ViT其漸進式收縮金字塔能大大減少大型特征圖的計算量,可以替代視覺任務中CNN骨干網絡。

圖12 空間縮減注意力模塊Fig.12 Spatial-reduction attention module
PVTv2[37]和SegFormer[50]通過引入重疊補丁嵌入、深度卷積來改進原始PVT,PVTv2在空間縮減注意力模塊中利用具有線性復雜度的平均池化操作代替了PVT中的卷積操作。這種特征金字塔的設計思想使Transformer成為了視覺任務骨干網絡的一個替代方案,諸如Focal Transformer[44]、CrossFormer[55]、RegionViT[43]、Multiscale vision Longformer[63]等都采用了金字塔結構的設計方案。
除了上述方法之外,還有一些其他方向可以進一步改進視覺Transformer,例如位置編碼CPVT[22]、iRPE[69]、殘差連接優化策略LayerScale[61]、快捷連接[70]和去除注意力[51,71]、ResMLP[72]、FF Only[73]。
3 CNN+Transformer混合結構
基于深度學習的方法在計算機視覺領域最典型的應用便是CNN,通過共享卷積核來提取特征,一方面可以極大地降低參數量來避免更多冗余的計算從而提高網絡模型計算的效率,另一方面又結合卷積和池化使網絡具備一定的平移不變性和平移等變性。而Transformer依賴于更靈活的自注意力層,在提取全局語義信息和性能上限等方面的表現要優于CNN。目前新的研究方向是將這兩種網絡結構的優勢結合起來。本章從架構拼接、內部改進、特征融合幾個方面介紹了CNN+Transformer的混合模型。
3.1 基于結構拼接的混合結構
Carion等人[12]提出的DETR,利用ResNet主干網絡提取圖像緊湊特征表示生成一個低分辨率高質量的特征圖,有效地減少了輸入前Transformer圖像尺度大小,提高模型速度與性能。
Chen等人[74]提出的Trans-UNet,將Transformer與UNet相結合,利用Transformer從卷積網絡輸出的特征圖中提取全局上下文信息,然后結合Unet網絡的U型結構將其與高分辨率的CNN特征圖通過跳躍連結組合以實現精確的定位。在包括多器官分割和心臟分割在內的不同醫學應用中取得了優于各種競爭方法的性能。
Xiao等 人[75]提出的ViTc,將Transformer中Patch Embedding模塊替換成Convolution,使得替換后的Transformer更穩定收斂更快,在ImageNet數據集上效果更好。
3.2 基于卷積局部性改進的混合結構
Wu等人[38]提出的CvT結合了卷積投影來捕獲空間結構和低級細節。Refiner應用卷積來增強自注意力的局部特征提取能力[59]。CoaT通過引入卷積來增強自注意力設計了一種卷積注意力模塊該模塊[39],可以作為一種有效的自注意力替代方案。Uni-Former將卷積與自注意力的優點通過Transformer進行無縫集成[76],在淺層與深層分別聚合局部與全局特征,解決了高效表達學習的冗余與依賴問題。Liu等人[46]提出的TransCNN網絡,通過在自注意力塊后引入CNN層使網絡可以繼承Transformer和CNN的優點。CeiT將前饋網絡(FFN)與一個CNN層相結合[42],以促進相鄰補丁之間的相關性。Le-ViT[77]在non-local[78]的基礎上提出了一種用于快速推理圖像分類的混合神經網絡。PiT利用卷積池化層實現Transformer架構的空間降維[41]。ConViT引入了一個新的門控位置自注意力層(GPSA)[79]以模擬卷積層的局部性。
3.3 基于特征融合的改進方法
CNN與Transformer結合的另一形式是通過特征融合,采用一種并行的分支結構將中間特征進行融合。
(1)模型層特征融合
Peng等人[80]提出了Conformer(如圖13),通過并行結構將Transformer與CNN各自的特征通過橋架相互結合實現特征融合,使CNN的局部特征和Transformer的全局特征得到最大程度的保留。

圖13 DETR模型結構Fig.13 DETR model structrue
(2)交叉注意力特征融合
Chen等人[81]提出了MobileFormer,將MobileNet和Transformer并行化,使用雙向交叉注意力將兩者連接起來即mobile-former塊,與標準注意力相比k和v通過局部特征直接投影得到,節省了計算量使注意力更多樣化。實驗結果表明,該方法在準確性和計算效率都取得了顯著效果。
4 Transformer在CNN中的運用
4.1 基于CNN的注意力模塊
Wang等人[78]提出了Non-local模塊(如圖14的A)旨在通過全局注意力捕獲長距離依賴關系,將某個位置的輸出等于特征圖中所有位置的特征加權和,使局部CNN網絡得到了全局的感受野和更豐富的特征信息。
此外為了減少全局注意力計算的負擔,Huang等人[82]提出了十字交叉注意模塊,該模塊僅在十字交叉路徑上生成稀疏注意圖(如圖14的B),通過反復應用交叉注意力,每個像素位置都可以從所有其他像素中捕獲全局上下文信息。與Non-local塊相比,十字交叉注意力減少了11倍GPU顯存,具有O(√N)的復雜度。Srinivas等人[83]提出的BoTNet,將多頭注意力模塊multihead self-attention(MHSA)替代ResNet bottleneck中的3×3卷積,其他沒有任何改變,形成新的網絡結構,稱為bottleneck Transformer,相比于ResNet等網絡提高了再分類,目標檢測等任務中的表現,并且比EfficientNet快1.64倍。
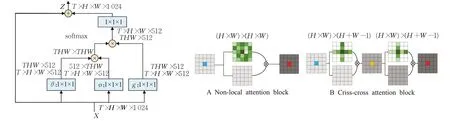
圖14 Non-local塊Fig.14 Non-local blocks
4.2 動態權重
動態權重是指為每個實例學習專門的連接權重,以增加模型的容量。文獻[67]中利用動態權重來增加網絡容量,在不增加模型復雜度和訓練數據的情況下提高了模型性能。
Hu等人[84]提出了LR-Net,根據局部窗口內像素與特征之間的組合關系重新聚合其權重。這種自適應權重聚合將幾何先驗引入網絡中,實驗表明該方法可以改進圖像識別任務。
大體上,動態權重在卷積網絡中應用可以分為兩類:一類是學習同構連接權重,如SENet[85]、動態卷積[86];另一類是學習每個區域或每個位置的權重(GENet[87]、Lite-HRNet[88]、Involution[89])。
4.3 其他方法
Trockman等人[90]提出的ConvMixer模型,僅使用的標準卷積直接將補丁作為輸入,其性能要優于ViT、MLP-Mixer以及ResNet等視覺模型。這種補丁嵌入結構允許所有下采樣同時發生,并立即降低內部分辨率,從而增加視覺感受野大小,使其更容易混合遠處的空間信息。如表3展示了ConvMixer與幾種方法的對比情況。

表3 ConvMixer對比實驗Table 3 ConvMixer comparative experiment
5 總結與展望
本文介紹了視覺Transformer模型基本原理和結構,分別從面向性能優化和面向結構改進兩個方面對視覺Transformer的關鍵研究問題和最新進展進行了概述和總結,同時以圖像分類和目標檢測為例介紹了Transformer在視覺任務上的應用情況。視覺Transformer作為一種新的視覺特征學習網絡,文中結合CNN對比總結了兩種網絡結構的差異性和優缺點,并提出了Transformer+CNN的混合結構。CNN和Transformer相結合具有比直接使用純Transformer更好的性能。然而兩者結合的方式有很多不同的方法,如文獻[7]中應用CNN提取緊湊特征,文獻[50]中重疊補丁生成等。兩者如何相結合才能更有效?對此,開發一個更強大通用的卷積ViT模型還需要進行更多研究。
目前,大多數Transformer變體模型計算成本很高,需要大量的硬件和計算資源[91-94]。未來一個新的研究方向是應用CNN剪枝原理對Transformer的可學習特征進行剪枝,降低資源成本,使模型可以更容易地部署在一些實時設備中(如智能手機、監控系統等)。自監督學習的方式可以在無標注數據上對模型進行表征學習,基于Transformer的自監督學習可以解決模型對數據的依賴性從而有望實現更強大的性能。此外,視覺Transformer采用了標準的感知器數據流方式,為時序數據、多模態數據融合和多任務學習提供了一種統一的建模方法,基于Transformer模型有望實現更好的信息融合和任務融合。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
