基于TMU-Net網絡的蘋果果心分割方法
2023-01-13 00:46:34劉長勇李思佳查志華鄧紅濤
農業工程學報 2022年16期
劉長勇,李思佳,史 慧,查志華,鄧紅濤
基于TMU-Net網絡的蘋果果心分割方法
劉長勇1,李思佳3,史 慧2,查志華2,鄧紅濤2※
(1. 新疆農墾科學院,石河子 832000;2.石河子大學機械電氣工程學院,石河子 832000;3. 中山大學電子與通信工程學院,深圳 510275)
針對蘋果內在品質檢測過程中傳統測量果心大小方法效率低、準確性差等問題,該研究提出一種基于TMU-Net網絡自動分割果心的方法,將Transformer編碼器融入U-Net網絡結構中,構建改進U型卷積網絡TMU-Net模型。模型由特征提取模塊、特征處理模塊、解碼器、特征拼接模塊組成,以VGG-16前13層作為主干特征提取網絡,在跳躍連接中疊加多重殘差空洞卷積(Multiple Residual Dilated Convolution,MRDC)模塊,增大感受野的同時增強了模型對底層特征提取能力。采用數據增強技術對果心數據集擴充后,利用遷移學習方法凍結特定的網絡層,對TMU-Net模型進行訓練。試驗結果表明:引入遷移學習并使用最佳訓練方式使模型分割精確率提高了22.48個百分點;TMU-Net網絡模型在果心分割任務中實現了96.72%的精確率,與U-Net、PSPNet、DeeplabV3+網絡對比,精確率分別提升了14.28、9.98、7.15個百分點。該方法能夠精準、有效地實現果心分割,可為實現蘋果內在品質智能檢測提供參考。
模型;圖像分割;果心分割;TMU-Net網絡;多重殘差空洞卷積;Transformer;遷移學習
0 引 言
蘋果果心比例是評價蘋果內在品質的重要指標[1]。目前,果心數據主要依靠人工測量獲取,這種方法不僅工作量大、效率低,而且蘋果果心形狀不規則、邊緣凹凸等因素導致手工測量誤差大,難以滿足當前發展的需求。
隨著計算機理論和硬件設備的快速發展,機器視覺技術在工業中取得了廣泛應用[2]。劉浩等[3]通過轉換色彩空間,選取合適的色度閾值實現果心區域分割,但是圖像中往往存在一些不確定的噪聲點,單一的閾值分割精度較低。胡智元[4]通過Canny邊緣檢測算法、霍夫變換特征提取算法、梯度下降算法等多種方法結合實現水果位置信息的計算,但是水果的不規則形狀和表皮顏色的深淺對定位效果影響較大。上述方法只能提取圖像的低級特征,難以準確提取出邊緣細節,識別精度有限。
近年來,深度學習技術在圖像分割領域的應用取得了顯著成功[5-7]。Chen等[8]提出的DeeplabV3+模型通過在編碼器中使用大量的空洞卷積,使每個卷積輸出都包含了較大范圍的信息。U-Net[9]是基于編碼器與解碼器結構的網絡,由主干特征提取、加強特征提取、跳躍連接(skip-connection)三部分組成,能夠融合低層次和高層次的語義信息,近年來被研究者優化后廣泛應用于農業圖像分割領域[10-11]。在模型結構融合中,Ge等[12]提出將不同分辨率的圖像作為網絡的輸入,使用空洞卷積代替U-Net中間3層的標準卷積,在膀胱癌數據集中取得了較高精度,為U-Net模型優化提供了新思路。Maji等[13]通過在跳躍連接中引入注意門(Attention gates),只將相關信息進行特征拼接,并采用引導解碼器(guided decoder)增強每一層的特征表示能力。Song等[14]將可分離卷積融合在SegNet網絡中,并結合條件隨機場模型對向日葵遙感圖像進行倒伏識別,取得了較好的識別效果。
雖然卷積神經網絡(Convolutional Neural Network,CNN)有較強的特征表示能力,但是由于卷積運算的固有局部性,其在紋理和形狀差異較大的目標結構中表現出的性能較弱,為了克服這種局限性,現有的研究提出建立基于注意力機制的卷積神經網絡。Transformer[15]最初應用于自然語言處理(Natural Language Processing,NLP)領域,與之前基于CNN的方法不同,其采用完全依賴于注意力機制的卷積算子,具有強大的全局信息獲取能力,在各種圖像識別任務中達到甚至超越了現有網絡模型[16-17]。已有學者展開了在卷積神經網絡中融合Transformer[15]結構的研究。賈偉寬等[18]針對綠色目標果實檢測,提出一種基于Transformer的優化模型,將卷積神經網絡提取到的特征輸入Transformer編碼-解碼器,可并行處理多個對象,提高了檢測效率。針對動物骨骼關鍵點檢測,張飛宇等[19]通過在HRNet模型中引入Transformer編碼器和多尺度信息融合模塊,提高了網絡高維特征提取能力,大大提升了檢測效率和精度。安小松等[20]將Transformer應用于缺陷柑橘分選,通過預測果實路徑指導機器手臂準確抓取缺陷柑橘,實現快速分選。以上研究為開展Transformer融合CNN應用于蘋果果心的精確分割提供了參考和可行性依據。
因此,本研究提出了一種融合Transformer的改進U型卷積網絡結構,通過Transformer編碼器增強網絡的全局信息獲取能力,改善卷積運算的固有局部性,并使用VGG-16網絡[21]的前13層作為主干特征提取網絡,加強對蘋果圖像細節特征的提取;在跳躍連接路徑中引入多重殘差空洞卷積(Multiple Residual Dilated Convolution,MRDC),通過疊加不同空洞率的卷積操作提取多尺度信息,從而減小來自編碼器和解碼器的特征之間存在的語義差異;訓練過程中通過加載預訓練權重并在訓練前期凍結部分層的方式進行遷移學習,以期提高果心分割精度,為蘋果去心研究提供新思路。
1 材料與方法
1.1 數據采集與數據集制作
1.1.1 圖像采集
選取紅富士、嘎拉、黃元帥三類蘋果(產地:新疆)。使用配有索尼IMX377感光芯片的KS12A884攝像頭作為采集設備,最大分辨率為3 840×2 880(像素)。依據NY/T 2316—2013蘋果評價指標規范[1],沿蘋果最大橫徑處切開,得到兩個樣本。如圖1所示,采集時將樣本放置于大小為50 cm×50 cm×50 cm(長×寬×高)的影棚中,樣本橫切面距攝像頭12 cm且與攝像頭平行。圖像采集過程中每個蘋果樣本旋轉90°進行兩次拍攝,并將圖像大小統一調整為800×600(像素),最終得到的蘋果樣本圖像如圖2所示。

圖1 采集設備

圖2 蘋果圖像
1.1.2 數據增強
訓練深度學習網絡模型參數需要足夠的樣本數據。因此,本文對采集的311幅樣本圖像隨機采用平移、水平翻轉、垂直翻轉和高斯模糊的方法來進行數據增強,以提高模型的泛化能力[22]。通過數據增強,最終共獲得933幅樣本圖像。
數據增強過程中,每張原始圖片會輸出兩張不同的增強效果圖,并且每種增強方式被觸發的概率均為25%。進行平移變換時,隨機產生平移方向,但平移的距離不超過100像素。高斯模糊處理時,隨機添加均值為0,方差為0.01的高斯白噪聲。
1.1.3 數據集制作
本研究采用VOC數據集格式,使用圖像標注工具Labelme標注果心區域。標注完成后得到的類別標簽、坐標等標注信息存為.json文件,經處理后生成8位彩色標簽圖,其中每個像素點的值代表了該像素所屬的種類。將擴充后的樣本圖像依據留出法[22]按7∶2∶1的比例劃分,分別得到訓練集、驗證集和測試集。
1.2 改進U型卷積網絡TMU-Net
U-Net[23]網絡是典型的“U型”編碼-解碼架構,其編碼器和解碼器之間引入了跳躍連接,能夠融合不同層次的語義信息,從而提升網絡性能。但簡單的跳躍連接忽略了特征之間存在的語義差異,導致其對形狀不規則且拐角尖銳的果心分割效果較差,無法精確分割果心邊緣,且難以識別圖像中的模糊目標。
針對上述問題,本研究提出一種融合Transformer改進U型卷積網絡TMU-Net(Transformer Multiple U Networks),該模型以VGG-16的前13層作為特征提取網絡,引入Transformer編碼器進行特征處理,增強網絡的全局特征提取能力,在解碼路徑中,對特征圖進行上采樣操作,并在跳躍連接中引入多重殘差空洞卷積(MRDC),以彌補編碼器和解碼器特征之間存在的語義差異,最后使用預測映射函數對卷積層的輸出進行像素分類,獲得分割結果。
1.2.1 TMU-Net網絡結構
TMU-Net主要由4部分組成:特征提取模塊、特征處理模塊、解碼器、特征拼接模塊。網絡結構如圖3所示。
特征提取模塊:VGG-16中13個卷積層均采用大小為3×3的卷積核,5個池化層均采用2×2的池化核,最后為3個全連接層,其結構與U-Net的編碼結構相似。本研究中對VGG-16網絡進行裁剪,僅保留前13個卷積層作為特征提取網絡,并使用其在ImageNet數據集中的預訓練權重,幫助網絡進行特征學習。
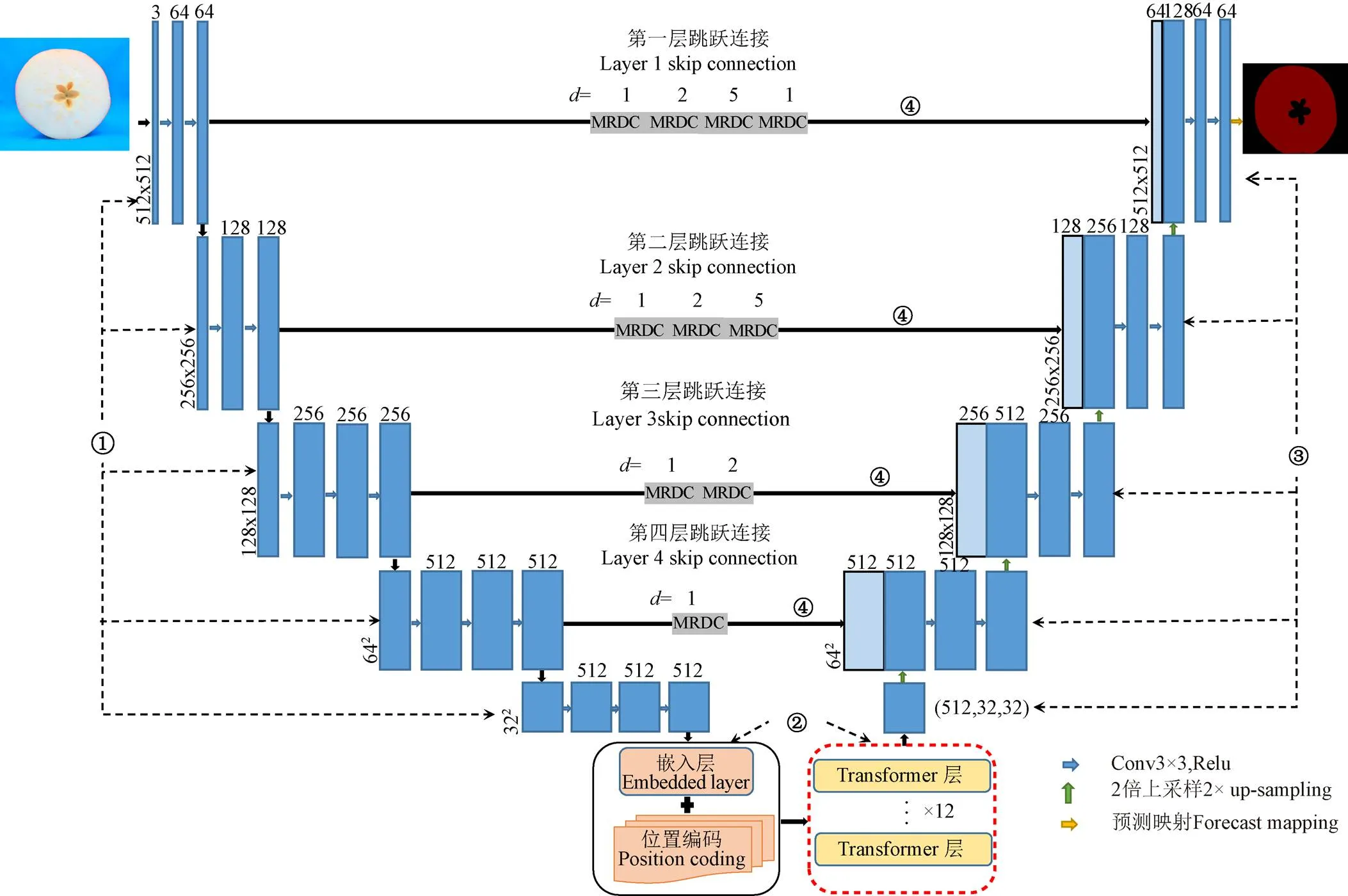
注:①:特征提取模塊;②:特征處理模塊;③:解碼器;④:特征拼接模塊;d:空洞率;MRDC:多重殘差空洞卷積。
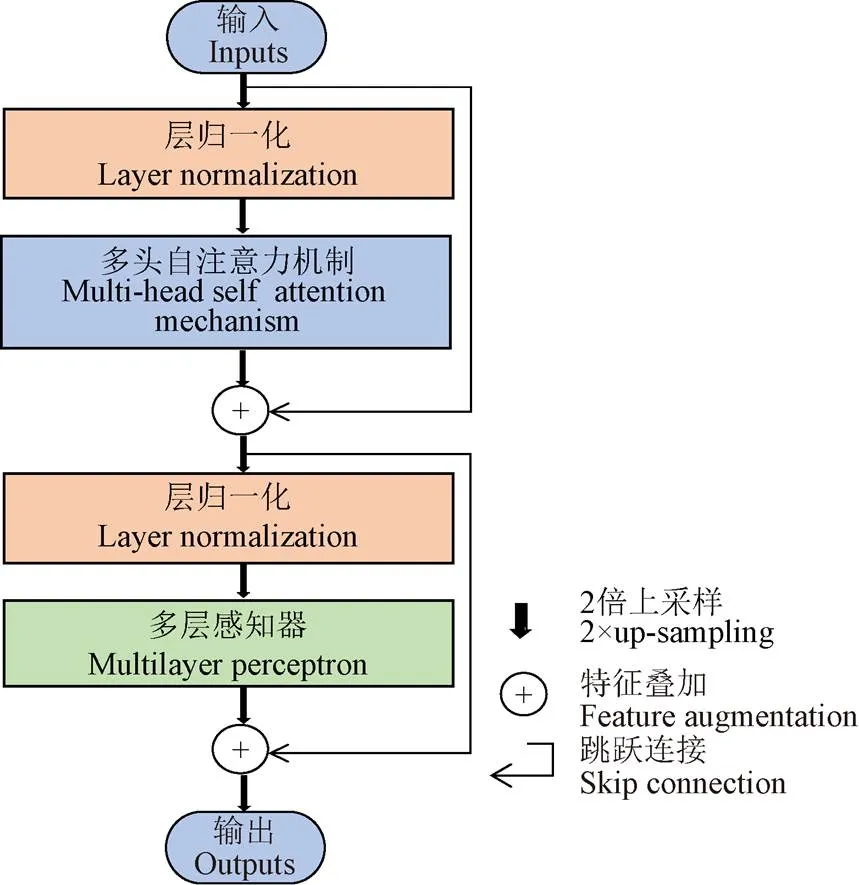
圖4 Transformer層結構
解碼器:在編碼器中卷積和池化操作將圖像進行降維,壓縮圖像分辨率,導致部分細節信息損失。解碼路徑中,通過兩倍上采樣在一定程度上補全圖像信息,使圖像恢復至原始尺寸以便對每一個像素點進行分類。
特征拼接模塊:在U-Net以及類似的U型體系結構中,跳躍連接將圖像的細粒度特征與抽象特征進行拼接,傳遞丟失的空間信息。然而來自編碼器的特征是較為原始的,來自解碼器的特征則是經過網絡深層計算得到的,二者之間存在語義差異,直接將兩組不兼容的特征進行拼接會在網絡學習過程中產生不一致性,從而影響最后的預測結果。為了解決上述問題,本研究重新設計了跳躍連接,如圖4所示,通過多重殘差空洞卷積(MRDC)對來自編碼器的特征進一步計算處理,與對應的解碼器特征進行拼接。空洞卷積[24]擴大了卷積核的感受野,通過空洞率調整卷積核中非零值之間的間隔數量,卷積核大小計算式為
=·(-1)+1 (1)
式中為空洞卷積的卷積核尺寸;為空洞率;為原始卷積核尺寸。由于空洞卷積引入了0值,大小為的卷積區域實際參與計算的像素點僅有個,因此空洞卷積只能以網格形式提取圖像信息,破壞了局部信息的連續性。為了減小上述問題對分割效果的影響,本研究疊加使用不同的空洞率,使其能覆蓋更多的底層特征,其中空洞率的組合采用混合膨脹卷積(Hybrid Dilated Convolution,HDC)[25]中的組合要求。
為了彌補拼接特征之間的語義差異,不同跳躍連接路徑上卷積塊的個數隨著編碼器深度的減小而增加。同時在卷積塊中引入1×1卷積作為殘差連接,使網絡訓練更加容易。為了彌補拼接特征之間存在的語義差異,不同跳躍連接路徑上的卷積塊個數隨著編碼器深度的減小而增加,如圖5所示,第四層的編碼器特征得到的計算處理較多,因此僅使用一個MRDC模塊,而第一層的編碼器特征得到的計算處理較少,需使用多個MRDC模塊進一步處理,從而使網絡達到更好的性能。
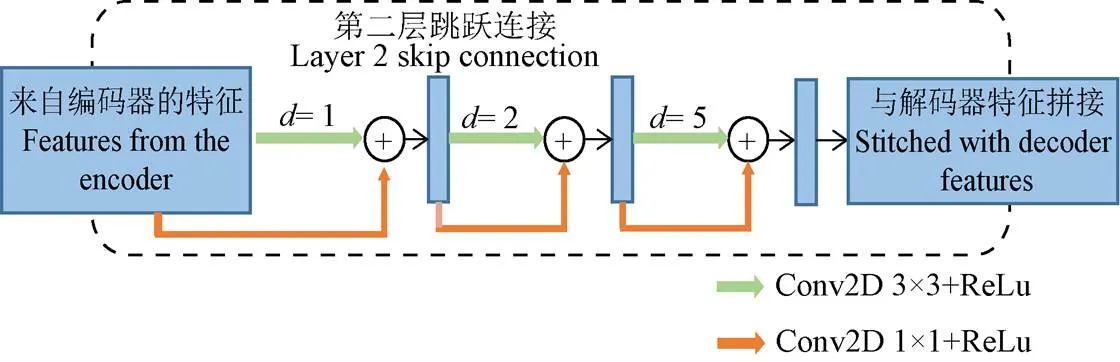
圖5 TMU-Net中第二個跳躍連接結構
綜上所述,TMU-Net模型以VGG-16網絡的前13層作為特征提取網絡,用于捕獲低層次細節特征,Transformer編碼器能增強網絡的全局特征提取能力,彌補卷積操作的局部性,引入多重殘差空洞卷積后的跳躍連接能夠減小拼接特征之間存在的語義差異,最終完成果心分割。
1.2.2 構建損失函數
試驗中采用交叉熵損失(Cross Entropy Loss)與Dice Loss結合作為模型的損失函數。交叉熵損失函數的計算公式為
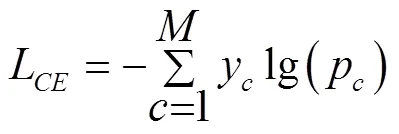
式中L為交叉熵損失;是樣本的類別個數;y僅有0和1兩種取值,若樣本類別與當前類別一致,y取1,否則y取0;p為當前樣本預測屬于類的概率。Dice Loss最早由Milletari等[26]提出,用于評價樣本的相似性,被廣泛應用于圖像分割領域。Dice Loss的計算與Dice系數有關,Dice系數用來度量集合相似度,在分割任務中其表達式為
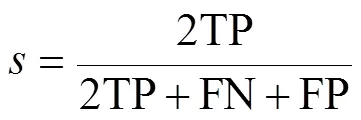
式中為Dice系數;TP、FN、FP分別代表真陽性、假陰性、假陽性的像素個數。Dice Loss計算公式為
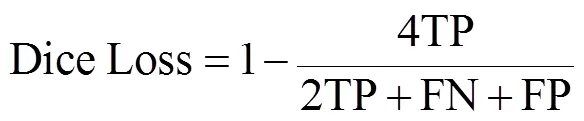
Dice Loss能減少樣本不均衡帶來的影響,但是在訓練過程中不夠穩定,不利于網絡收斂,因此本研究中結合交叉熵損失函數來穩定訓練過程。
1.3 遷移學習
遷移學習是將一項任務中學到的知識進行存儲,并將其用于解決相關但不同的問題。給定源域、源任務、目標域、目標任務,遷移學習在源域和源任務中學到的知識有助于改進目標任務中預測函數的學習能力,在源域數據量充足而目標域數據量較少時能有效提升模型性能。
本研究利用模型遷移的方法,將VGG-16和Transformer的預訓練權重共享于TMU-Net網絡模型的特征空間,能夠使TMU-Net網絡模型獲得更好的初始性能,幫助模型更快地學習,提高模型訓練的效率和魯棒性。
1.4 試驗設計
1.4.1 TMU-Net網絡結構訓練環境
硬件環境:算法處理平臺為MistGPU服務器,處理器為Intel Core i7,16GB內存,顯卡型號為NVIDIA Titan RTX。
軟件環境:采用Linux操作系統,編程語言為Python3.7.8,使用深度學習框架Pytorch1.9.0進行網絡搭建。
1.4.2 訓練參數及方法
模型訓練過程分為凍結與解凍兩個階段,前10個訓練輪次(Epoch)采用較大的學習率,凍結部分網絡參數,防止權值被破壞,僅對網絡進行微調,將更多的資源用于訓練網絡后半部分的參數,從而提高訓練的效率。解凍階段整個網絡的參數都會發生改變,因此采用較小的學習率。試驗中每完成一個Epoch迭代便保存一次權重文件。本研究中網絡優化器選用Adam優化器,凍結訓練階段初始學習率設置為10-4,解凍訓練階段初始學習率設置為10-5,批次輸入樣本數為2,采用衰減率為0.9的隨機梯度下降法訓練50個輪次。
1.4.3 模型評價指標
本研究采用交并比(Intersection Over Union,IOU)、精確率(Precision)、召回率(Recall)、F1值(F1-score)作為模型評價指標。
交并比為預測區域和真實區域重疊部分與集合部分的比值。精確率與召回率的計算公式如下:
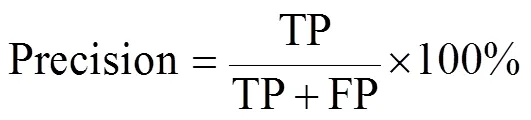

精確率表示預測正確的正樣本數量與全部預測為正樣本的樣本數量之比,即“查準率”。召回率表示預測正確的正樣本數量與真實正樣本數量之比,即“查全率”。F1值(F1-score)是調和平均值,綜合考慮了精確率與召回率,計算公式為

2 結果與分析
2.1 遷移學習訓練對模型性能的影響
訓練過程中使用預訓練權重,模型中VGG-16的預訓練權重來自VOC拓展數據集,Transformer層的預訓練權重來自ImageNet數據集。
本研究對比了不同訓練方式對網絡模型分割效果的影響:①不使用預訓練權重,直接對網絡模型進行訓練;②使用VGG-16預訓練權重,凍結所有層;③使用Transformer預訓練權重,凍結所有層;④使用VGG-16和Transformer預訓練權重,凍結所有層;⑤使用VGG-16和Transformer預訓練權重,凍結特定層。訓練方式⑤凍結了Transformer編碼器所在層的參數,凍結層位置如圖 3的虛線框所示。最終得到的試驗結果如表1所示。
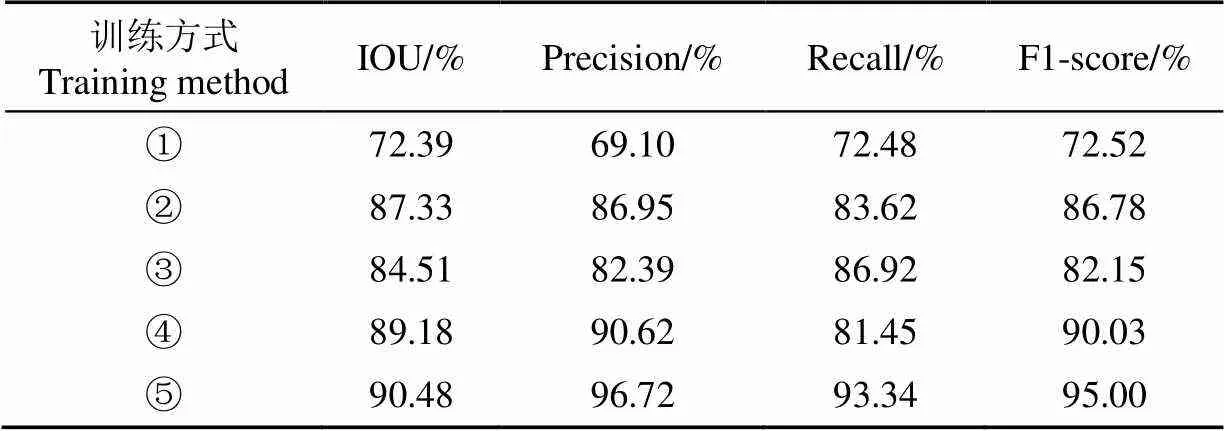
表1 不同訓練方式的試驗結果
注:訓練方式中的序號①~⑤分別為:未使用遷移學習的訓練方式、僅使用VGG-16權重遷移訓練的方式、僅使用Transformer權重遷移訓練的方式、使用VGG-16和Transformer權重遷移訓練的方式、使用VGG-16和Transformer權重并凍結特定層遷移訓練的方式;IOU表示交并比,Precision表示精確率,Recall表示召回率,F1-score表示F1值。
Note: The serial numbers ①-⑤ in the training methods are: the training method without transfer learning, the method using only VGG-16 weight transfer training, the method using only Transformer weight transfer training, the method using VGG-16 and Transformer weight transfer training, the method using VGG-16 and Transformer weights and freezing specific layer transfer training; IOU represents intersection-union ratio, Precision represents precision, Recall represents recall, and F1-score represents F1 value.
在相同的訓練環境下,同時使用VGG-16和Transformer的預訓練權重比使用單個預訓練權重效果更優,說明多權重同時遷移訓練的方式更適合TMU-Net網絡模型。在訓練過程中,訓練方式⑤與未使用遷移學習的訓練方式①相比,IOU、精確率、召回率、F1值分別提升了18.09、27.62、20.86、22.48個百分點;與凍結網絡所有層參數的訓練方式④相比,IOU、精確率、召回率、F1值分別提升了1.30、6.10、11.89、4.97個百分點。因此,使用遷移學習并選擇凍結合適的網絡層進行訓練可以有效提升模型的檢測性能。
2.2 數據增強對模型性能的影響
為了保證試驗設置的合理性,在其他參數相同的條件下,分別使用擴充前后的數據集對TMU-Net網絡模型進行訓練,試驗結果如表2所示。
由表2可知,相比于原始數據集,使用擴增數據集訓練,TMU-Net網絡模型的IOU、精確率、召回率、F1值分別提高27.28、36.62、29.81、32.06個百分點。說明使用擴增數據集訓練效果更好。

表2 不同大小數據集的試驗結果
2.3 MRDC模塊對模型性能的影響
在其他參數相同的條件下,本研究對使用MRDC模塊前后的模型進行訓練,并在測試集上進行驗證,試驗結果如表3所示。相比于未使用MRDC模塊,優化的TMU-Net模型分割的IOU、精確率、召回率、F1值分別提高了1.59、6.49、11.87、4.65個百分點,說明MRDC模塊有效地提升了網絡模型的性能。
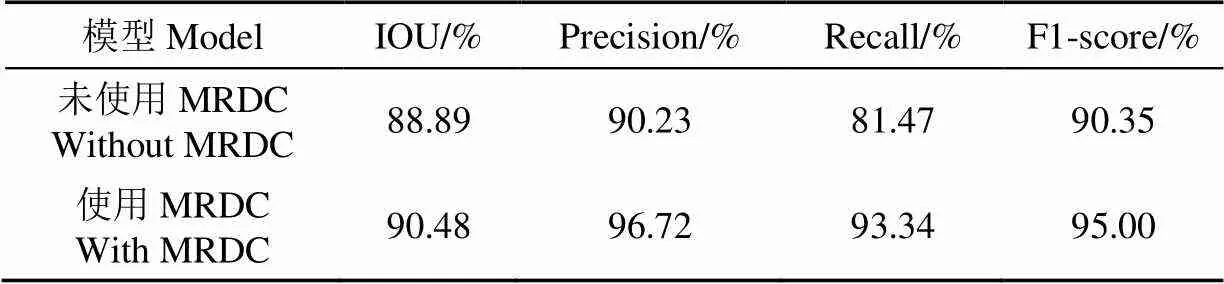
表3 使用MRDC模塊前后的試驗結果
為了更直觀、清楚地看到MRDC模塊在蘋果橫切面不同區域特征提取的效果,本文將U-Net與TMU-Net中每一層跳躍連接的輸出特征進行熱力圖可視化,熱力圖中高溫區域(紅色區域)顏色越深,表明網絡對該區域的關注度越高,提取到的特征越多,如圖6所示。
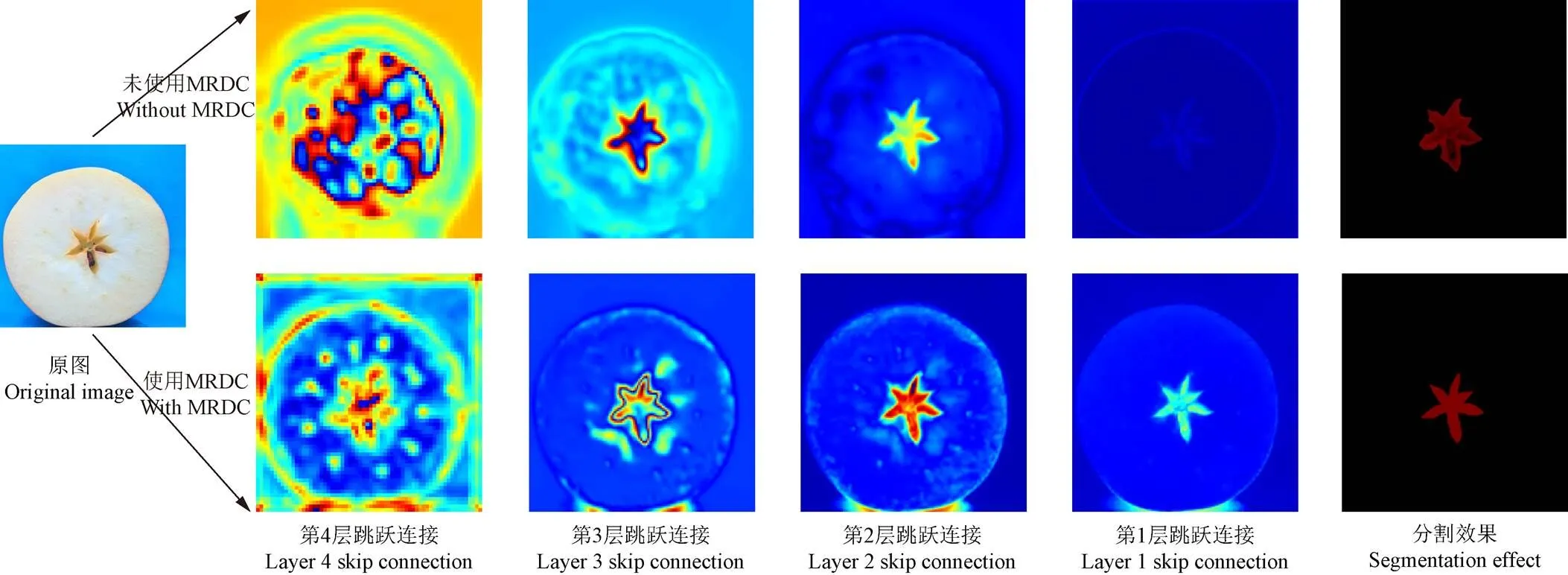
圖6 不同跳躍連接輸出特征可視化圖
通過熱力圖縱向比較可知,第4層跳躍連接中使用MRDC模塊的TMU-Net提取的特征能夠較為準確的覆蓋果心區域,對圖像中的其他區域也有一定的識別能力。在TMU-Net模型的第3層和第2層跳躍連接中,未使用MRDC模塊的TMU-Net提取的果心特征輪廓較為模糊,果心區域存在部分損失,而使用MRDC模塊的TMU-Net對果心邊緣的提取更加精細,并且網絡進行預測時對果心區域的關注度更高。
2.4 TMU-Net網絡模型改進效果
U-Net、PSPNe和DeeplabV3+作為語義分割中的經典模型,具有檢測準確度高、模型創新性強的特點。因此,在果心分割效果試驗中,選取U-Net模型、PSPNet模型、DeeplabV3+模型與TMU-Net模型進行分割效果對比。不同網絡模型的蘋果果心分割效果如圖7所示,真實標簽為自人工標注的果心邊界標簽。通過橫向對比可知,對于形狀較均勻的蘋果果心,如樣本1,TMU-Net模型可以較為準確和全面地分割果心,DeeplabV3+模型所分割的果心各角會有細微的錯誤分割現象,而PSPNet模型分割出的果心各角連接處有明顯的錯誤分割現象;樣本2的果心較細,需要處理的細節較多,與其他模型相比,TMU-Net網絡對細節的分割效果最佳,PSPNet與U-Net網絡模型,在果心各角連接處分割錯誤面積較多,嚴重影響結果;雖然樣本3的原始圖像較為模糊,但TMU-Net的分割結果最接近真實標簽,其余網絡分割的錯誤區域過多,難以精確識別果心的邊緣輪廓,進一步表明本研究做出的改進是有效的。
通過縱向對比可知,TMU-Net對精細的尖銳邊角及連接處的分割效果優于圓滑的邊沿;DeeplabV3+模型對原始圖片的質量要求較高,對于低清晰度圖片,該模型只能分出大致形狀,難以應用在實際任務中;PSPNet與U-Net網絡模型,在本次果心分割任務中,只能分割出果心的大致范圍。說明以上兩個模型對果心的特征利用不夠,信息丟失的情況嚴重,不適合做果心類的小目標精細分割任務。

注:分割結果中,藍色部分代表正確分割的區域,綠色部分代表未分割到的區域,紅色部分代表誤分割的區域。
為了全面分析TMU-Net模型與U-Net模型、PSPNet模型、DeeplabV3+模型的分割性能差異,在其他參數相同的試驗條件下,使用本研究構建的果心數據集訓練50個輪次,各模型訓練精度損失(Loss)和交并比(IOU)變化曲線如圖8和圖9。
如圖8所示,在訓練初期網絡的損失值快速下降,隨著迭代次數的增加,在模型迭代至4 000次時,各模型的損失值逐漸趨于平緩,最終模型達到收斂。相較與其他模型,TMU-Net網絡模型在迭代至2 000次時,損失函數基本保持不變,說明此時模型已經收斂,該模型的收斂速度最快。當達到穩定后,TMU-Net網絡損失曲線始終處于最下方且波動幅度更小,表明模型達到預期訓練效果。
如圖9所示,當訓練前5個輪次時,各網絡模型的IOU隨著輪次的增加而快速增長,在此過程中,PSPNet網絡模型的IOU曲線在最低處。當各網絡模型的IOU值出現拐點后,訓練輪次的增加對U-Net網絡模型、DeeplabV3+網絡模型和TMU-Net網絡模型的IOU值的提升影響不大,但PSPNet網絡模型的IOU值在緩慢提升,在此過程中,U-Net模型的IOU值逐漸轉變為較低水平。通過對比發現,相較與其他模型,TMU-Net模型的IOU曲線一直處于最上方,IOU值最終穩定在90.48%,說明在訓練初期便達到了較好的性能。
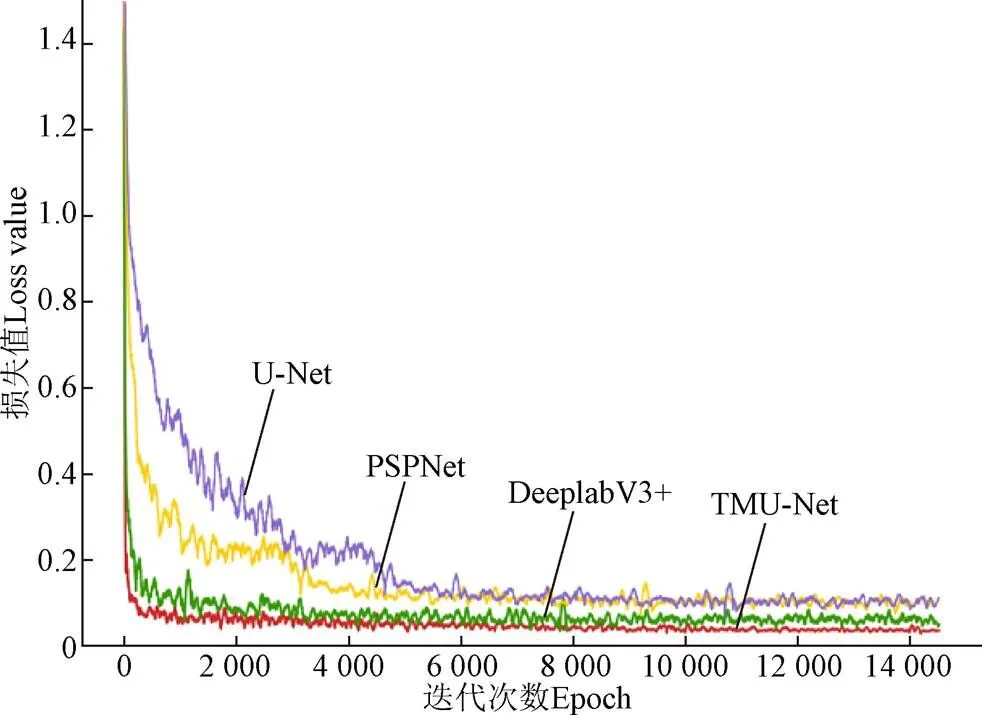
圖8 損失值隨迭代次數變化曲線
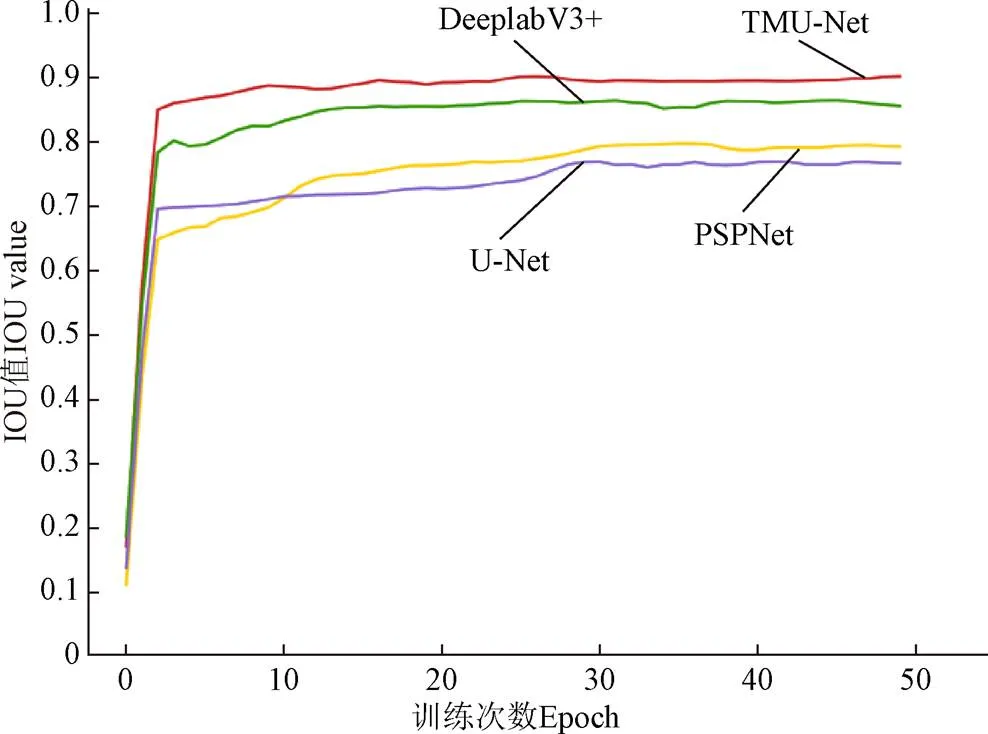
圖9 IOU值隨訓練輪次變化曲線
將訓練好的不同網絡模型在果心測試集圖像上進行模型測試,以IOU、Precision、Recall、F1-score為評價依據,試驗結果如表4所示。
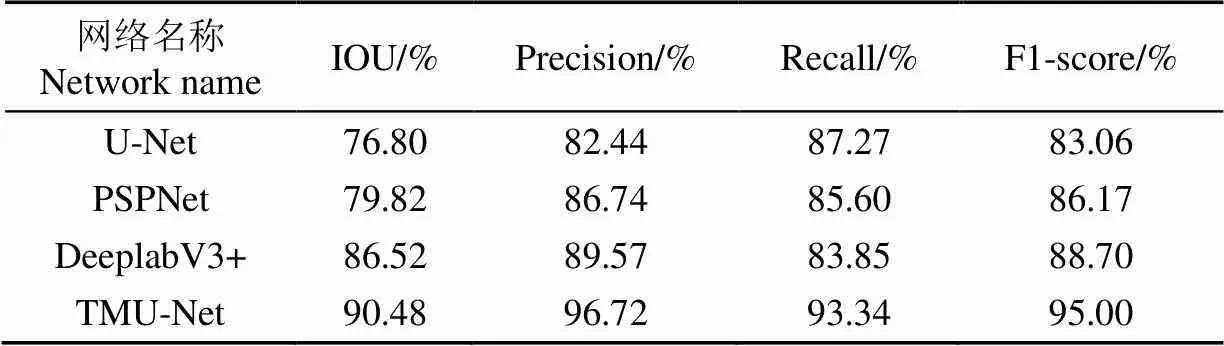
表4 不同網絡模型對果芯分割效果的精度評價
由表4可知,與U-Net模型相比,TMU-Net模型在果心分割任務中性能有大幅提升,其中IOU值、精確率、F1值分別提升了13.68、14.28、11.94個百分點;與性能較好的DeeplabV3+網絡相比,IOU值、精確率、F1值分別提升了3.96、7.15、6.30個百分點;與PSPNet模型對比,精確率提升了9.98個百分點。在單張圖片的推理時間中,TMU-Net模型平均耗時為1.688 s。將現階段手工測量方法改為智能識別,在考量不同智能識別方法的性能時,檢測精度要求比檢測時間更關鍵,單個果心檢測時間在“秒”數量級都可滿足檢測要求,所以TMU-Net模型1.688 s的檢測時長已滿足需求。
3 結 論
為滿足蘋果內在品質檢測中精準定位果心的需求,本研究提出了一種針對小目標精細分割的模型TMU-Net。該模型在U-Net網絡模型的基礎上以VGG-16前13層作為主干特征提取網絡,并將Transformer編碼器融入網絡結構、在跳躍連接中疊加多重殘差空洞卷積(Multiple Residual Dilated Convolution,MRDC)模塊,構建了TMU-Net網絡模型,該模型實現了蘋果果心的精準分割,為蘋果內在品質自動檢測提供了技術參考,主要結論如下:
1)VGG-16網絡的前13層和Transformer編碼器的引入,有效地提高了網絡的特征提取能力,與原始的U-Net網絡模型相比,交并比(Intersection Over Union,IOU)、精確率、F1值分別提升13.68、14.28、11.94個百分點,在一定程度上提高了模型分割的性能。
2)MRDC模塊可以使模型獲取豐富的底層信息,因此模型在果心的尖銳拐角及連接處,能夠實現精準分割,模型的分割精度高達96.72%,與未使用MRDC模塊的TMU-Net模型相比提升6.49個百分點,已滿足實際應用水平。
3)通過數字圖像處理技術中的隨機平移、水平鏡像、垂直鏡像、高斯模糊等方法對原始數據集進行數據增強,構建了適合網絡模型訓練的果心數據集。從對比結果可以看出,數據增強后的數據集從能有效提升模型的各項性能, IOU、精確率、召回率、F1值分別提高27.28、36.62、29.81、32.06個百分點,因此,增強了網絡的泛化能力,避免網絡在訓練過程中出現過擬合問題的問題。
4)采用雙權重遷移訓練并部分凍結特征層的訓練方式,與采用雙權重遷移訓練并凍結所有層的訓練方式相比,IOU、精確率、召回率、F1值分別提升了1.30、6.10、11.89、4.97個百分點。通過模型訓練曲線可以看出,該訓練方式還可以加快訓練時的收斂速度。
[1] 中華人民共和國農業部. NY/T2316—2013蘋果品質指標評價規范[S]. 北京:農業部農產品加工標準化技術委員會,2013.
[2] Hu Q, Jiang Y, Zhang J B, et al. Development of an automatic identification system autonomous positioning system[J]. Sensors, 2015, 15(11): 28574-28591.
[3] 劉浩,袁野,莊守望,等. 一種用于水果去核的視覺識別方法:CN106203527A[P]. 2016-07-18.
[4] 胡智元. 新型水果榨汁機定位關鍵技術研究[D]. 贛州:江西理工大學,2018.
Hu Zhiyuan. Research on Key Positioning Technology of New Fruit Juicer[D]. Ganzhou: Jiangxi University of Technology, 2018. (in Chinese with English abstract)
[5] 鐘昌源,胡澤林,李淼,等. 基于分組注意力模塊的實時農作物病害葉片語義分割模型[J]. 農業工程學報,2021,37(4):208-215.
Zhong Changyuan, Hu Zelin, Li Miao, et al. Real-time crop disease leaf semantic segmentation model based on group attention module[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(4): 208-215. (in Chinese with English abstract)
[6] 孫志同,朱珊娜,高鄭杰,等. 基于波段增強的DeepLabv3+多光譜影像葡萄種植區識別[J]. 農業工程學報,2022,38(7):229-236.
Sun Zhitong, Zhu Shanna, Gao Zhengjie, et al. Grape planting area recognition based on band enhanced DeepLabv3+ multi-spectral image[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(7): 229-236. (in Chinese with English abstract)
[7] 楊蜀秦,王鵬飛,王帥,等. 基于多頭自注意力DeepLab v3+的無人機遙感影像小麥倒伏檢測[J/OL]. 農業機械學報(2022-06-23) [2022-07-23]http: //kns. cnki. net/kc ms/detail/11. 196 4. S. 2022, 06, 22. 1158. 012. html.
Yang Shuqin, Wang Pengfei, Wang Shuai, et al. Wheat lodging detection based on multi-head self-attention DeepLabv3+ UAV remote sensing image [J/OL]. Transactions of the Chinese Society for Agricultural Machinery (2022-06-23) [2022-07-23]http: //kns. cnki. net/kcms/detail/11. 1964. S. 2022, 06, 22. 1158. 012. html. (in Chinese with English abstract)
[8] Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European conference on computer vision (ECCV). Munich, Germany: 2018: 801-818.
[9] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Munich, Germany: Technical University Munich, 2015: 234-241.
[10] 饒秀勤,朱逸航,張延寧,等. 基于語義分割的作物壟間導航路徑識別[J]. 農業工程學報,2021,37(20):179-186.
Rao Xiuqin, Zhu Yihang, Zhang Yanning, et al. Navigation path recognition between crop ridges based on semantic segmentation[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(20): 179-186. (in Chinese with English abstract)
[11] 趙晉陵,詹媛媛,王娟,等. 基于SE-UNet的冬小麥種植區域提取方法[J/OL]. 農業機械學報(2022-07-12) [2022-07-23]http: //kns. cnki. net/kcms/detail/11. 1964. S. 20220711. 1350. 016. html.
Zhao Jinling, Zhan Yuanyuan, Wang Juan, et al. SE-UNet based extraction method for planting area of winter wheat[J/OL]. Transactions of the Chinese Society for Agricultural Machinery (2022-07-12) [2022-07-23]http: //kns. cnki. net/kcms/detail/11. 1964. S. 20220711. 1350. 016. html. (in Chinese with English abstract)
[12] Ge R, Cai H, Yuan X, et al. MD-UNET: Multii-nput dilated U-shape neural network for segment-ation of bladder cancer[J]. Computational Biology and Chemistry, 2021, 93: 107510-107510.
[13] Maji D, Sigedar P, Singh M. Attention Res-UNet with Guided Decoder for semantic segmentation of brain tumors[J]. Biomedical Signal Processing and Control, 2022, 71: 103077.
[14] Song Z, Zhang Z, Yang S, et al. Identifying sunflower lodging based on image fusion and deep semantic segmentation with UAV remote sensing imaging[J]. Computers and Electronics in Agriculture, 2020, 179: 105812.
[15] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30.
[16] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]//International Conference on Learning Representations (ICLR). Online: Yoshua Bengio, Yann LeCun, 2020.
[17] Zheng S, Lu J, Zhao H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Online: IEEE, 2021: 6881-6890.
[18] 賈偉寬,孟虎,馬曉慧,等. 基于優化Transformer網絡的綠色目標果實高效檢測模型[J]. 農業工程學報,2021,37(14):163-170.
Jia Weikuan, Meng Hu, Ma Xiaohui, et al. Efficient detection model of green target fruit based on optimized Transformer network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(14): 163-170. (in Chinese with English abstract)
[19] 張飛宇,王美麗,王正超. 引入Transformer和尺度融合的動物骨骼關鍵點檢測模型構建[J]. 農業工程學報,2021,37(23):179-185.
Zhang Feiyu, Wang Meili, Wang Zhengchao. Construction of the animal skeletons keypoint detection model based on transformer and scale fusion[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(23): 179-185. (in Chinese with English abstract)
[20] 安小松,宋竹平,梁千月,等. 基于CNN-Transformer的視覺缺陷柑橘分選方法[J/OL]. 華中農業大學學報(自然科學版),2022,41(4):158-169
An Xiaosong, Song Zhuping, Liang Qianyue, et al. Citrus sorting method for visual defects based on CNN transformer[J]. Journal of Huazhong Agricultural University (Natural SScience Edition), 2022, 41(4): 158-169. (in Chinese with English abstract)
[21] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[C]//International Conference on Learning Representations (ICLR). San Diego, CA, USA: Yoshua Bengio, Yann LeCun, 2015.
[22] Park P S, Kshirsagar A M. Correlation between successive values of Anderson's classification statistic in the hold-out method[J]. Statistics & Probability Letters, 1996, 27(3): 259-265.
[23] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]// International Conference on Medical Image Computing and Computer-assisted Intervention. Munich, Germany: Technical University Munich, 2015: 234-241.
[24] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[C]//International Conference on Learning Representations (ICLR). San Juan, Puerto Rico: Yoshua Bengio, Yann LeCun,2016
[25] Wang P, Chen P, Yuan Y, et al. Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, Nevada, USA: IEEE, 2018: 1451-1460.
[26] Milletari F, Navab N, Ahmadi S A. V-net: Fully convolutional neural networks for volumetric medical image segmentation[C]//2016 Fourth International Conference on 3D Vision (3DV). Stanford, CA, USA: IEEE, 2016: 565-571.
Apple core segmentation method based on TMU-Net network
Liu Changyong1, Li Sijia3, Shi Hui2, Zha Zhihua2, Deng Hongtao2※
(1.,832000,; 2.,,832000,; 3.,-,510275,)
Apple quality has been ever increasingly required with the improvement of living standards in recent years. The core ratio is one of the most significant factors to determine the quality of apples. But, the manual measurement on the fruit core cannot fully meet the current detection requirements, in terms of cost and accuracy at present. In this study, an automatic segmentation was proposed for the fruit core using a TMU-Net network model. Firstly, three common types of apples were selected in the Xinjiang of China. An acquisition device was then used to capture the 311 cross-sectional images of the fruit core. Secondly, the preprocessing operations were also conducted to enhance the original images, including translation, vertical mirroring, horizontal mirroring, and adding Gaussian noise. Better training was achieved in the expanded dataset, compared with the original. Specifically, the Intersection Over Union (IOU), Precision, Recall, and F1-score of the TMU-Net network increased by 27.28, 36.62, 29.81, and 32.06 percentage points, respectively. It infers that the data enhancement improved the robustness and generalization of the model after training. The Multiple Residual Dilated Convolution (MRDC) module was also constructed with the Cavity convolution in the different void ratios and shortcut connections. Shortcut connections are skipping one layers, they simply perform identity mapping. As such, the information loss was reduced in the jump connection part of the model. There was also less semantic difference between the encoder and the decoder. The MRDC module was finally used to verify the TMU-Net jump connection. The results showed that: 1) The MRDC module was introduced to effectively improve the segmentation performance of the model, in which the IOU, Precision, and F1-score were improved by 1.59, 6.49, and 4.65 percentage points, respectively. 2) The first 13 layers of VGG-16 network were used as the backbone to capture the low-level features. The Transformer encoder was integrated into the network structure to enhance the global extraction of the network, particularly for the locality of convolution operations. The segmentation shows that the TMU-Net network was much more precise to process the sharp corner and edge details of the fruit center, indicating the feasibility of the model in the segmentation task of the fruit center. 3) The TMU-Net model was trained under a variety of transfer learning. Therefore, freezing the training of specific network layers can be expected to effectively improve the indicators of the model. The training curve of the model showed that the training was used to accelerate the convergence speed. Subsequently, the TMU-Net, DeeplabV3+, U-Net, and PSPNet models were trained to verify the test set under the same experimental parameters. The IOU, Precision, Recall, and F1-score of the TMU-Net model increased by 3.96, 7.15, 9.49, and 6.30 percentage points, respectively, compared with the DeeplabV3+ model with better effect. Therefore, this TMU-Net model can be expected to accurately and effectively realize the fruit core segmentation. The finding can also provide a strong reference for the intelligent detection of apple quality.
models; image segmentation; core segmentation; TMU-Net network; MRDC; Transformer;transfer learning
10.11975/j.issn.1002-6819.2022.16.033
TP391.4;S126
A
1002-6819(2022)-16-0304-09
劉長勇,李思佳,史慧,等. 基于TMU-Net網絡的蘋果果心分割方法[J]. 農業工程學報,2022,38(16):304-312.doi:10.11975/j.issn.1002-6819.2022.16.033 http://www.tcsae.org
Liu Changyong, Li Sijia, Shi Hui, et al. Apple core segmentation method based on TMU-Net network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(16): 304-312. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.16.033 http://www.tcsae.org
2022-04-29
2022-08-12
國家自然科學基金(31860466);蘋果內在品質指標評價技術研究(KH011402)
劉長勇,高級實驗師,研究方向為食品質量安全。Email:lw01_inf@shzu.edu.cn
鄧紅濤,副教授,研究方向為人工智能。Email:denghtshzu@163.com
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
光學精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
