基于統計模型的西江枯季中長期徑流預報研究
2023-01-10 06:18:40藍羽棲農振昌韋永江
人民珠江 2022年12期
藍羽棲,張 尹,農振昌,韋永江
(1.水利部珠江水利委員會水文局,廣東 廣州 510611;2.龍灘水電開發有限公司龍灘水力發電廠,廣西 河池 547300)
流域水安全保障是維持經濟社會高質量發展的重要一環,在新形勢新背景下,保障流域水安全對經濟社會的發展有著至關重要的作用[1]。然而,隨著經濟社會的快速發展,受咸潮、水污染和過度開發等問題的威脅,枯水期水資源供需矛盾愈發突出[2]。西江作為珠江流域來水的主要來源,其中長期來水預報對于珠江下游特別是珠江三角洲枯水期意義非凡。2021年汛期,西江來水為1946年以來同期第四枯,主汛期(6—8月)“當汛不汛”,來水均持續偏少。且流域沒有出現編號洪水,西江梧州站最高水位為近3年最低,受降雨偏少影響,2021年汛期,西江流域骨干水庫來水較多年同期偏少3~4成。面對前期不容樂觀的來水形勢,此時,可靠的中長期徑流預報成為了實現西江枯水期水庫群聯合優化調度、提高水資源利用效率的關鍵前提,對抗旱保供水工作具有深刻的科學價值。為提高西江水量調度水平,探求流域內主要站點和重要水庫中長期徑流預報方法具有重要意義。
針對中長期徑流預報,目前通行的方法是在分析水文要素自身的演變規律或挖掘與徑流相關的前期水文氣象資料的基礎上,構建徑流時間序列模型或前期水文氣象要素與預報月徑流的映射關系,從而提供科學的、預見期較長的徑流預測結果。近年來,針對統計模型在水文領域中的應用已有了諸多研究,隨著計算機的應用與發展,機器學習也逐步被引入到中長期預報中。目前常用的統計學方法有隨機森林法[3-4]、神經網絡算法[5]、季節自回歸等[6],如胡義明等[7]基于AdaBoost模型、隨機森林模型和支持向量機模型在淮河流域進行了月徑流預報,比較分析了各模型的預報效果和特點,發現AdaBoost模型整體上優于其他2個機器學習模型;酈于杰等[8]將支持向量回歸機應用于漢江皇莊站的中長期徑流預報,并對預報結果進行了不確定性分析,實現了高精度的定值預報并以置信區間的方式量化了預報的可靠度;常新雨等[9]采用灰色關聯分析法篩選預報因子,構建了基于數據驅動的深度神經網絡、Elman神經網絡和支持向量機3種模型并運用于黃龍灘水庫旬月徑流預報,發現支持向量機在洪峰預報上誤差更小。上述研究大多采用的是機器學習方法,也均取得了較好的預報效果。然而,盡管機器學習方法學習能力強、容錯性能高,但對數據容量具有較高要求,相比之下統計相關分析類和時間序列類方法原理簡單、應用方便、耗時短,因此后者仍是實際中長期徑流預報應用的常用方法。鑒于此,本文基于均生函數、周期分析、多元逐步回歸3種統計模型對西江流域枯季月徑流和整個枯水期徑流開展應用研究。
1 研究區域及資料
西江是珠江流域的主干流,發源于云南省曲靖市烏蒙山余脈的馬雄山東麓,自西向東流經云南、貴州、廣西、廣東4省(自治區),至廣東佛山市三水區思賢滘,全長2 075 km,平均坡降0.58‰,流域面積353 120 km2,占珠江流域總面積的77.8%。干流從上而下由南盤江、紅水河、黔江、潯江及西江5個河段組成。本文以龍灘水庫和梧州水文站為代表進行枯季徑流中長期預報方法的應用研究。
龍灘水庫位于西江流域干流紅水河河段(圖1),是廣西境內最大的水電工程,也是西江防洪工程體系的控制性工程。龍灘水庫以發電為主,兼具防洪、航運等綜合效益。壩址以上流域面積98 500 km2,占紅水河流域面積的71.2%。本文選取龍灘水庫1958—2020年天然徑流枯水期6個月(10月、11月、12月、次年1月、次年2月、次年3月)的數據,分別對各月、整個枯水期建立統計模型進行徑流模擬,其中1958—2004年采用龍灘實測入庫流量,2005—2020年采用經上游天生橋一級水庫、光照水電站還原后的龍灘天然入庫流量。
梧州水文站位于西江干流與支流桂江匯合口以下約3 km處(圖1),東經111°20′、北緯23°28′,是西江流域的出口控制站,集水面積327 046 km2。本文選取梧州站1963—2020年天然徑流枯水期6個月的數據,其中1963—2005年采用梧州實測流量,2006—2020年采用經上游天生橋一級水庫、光照水電站、龍灘水庫、百色水庫4座水庫還原后的梧州天然流量。
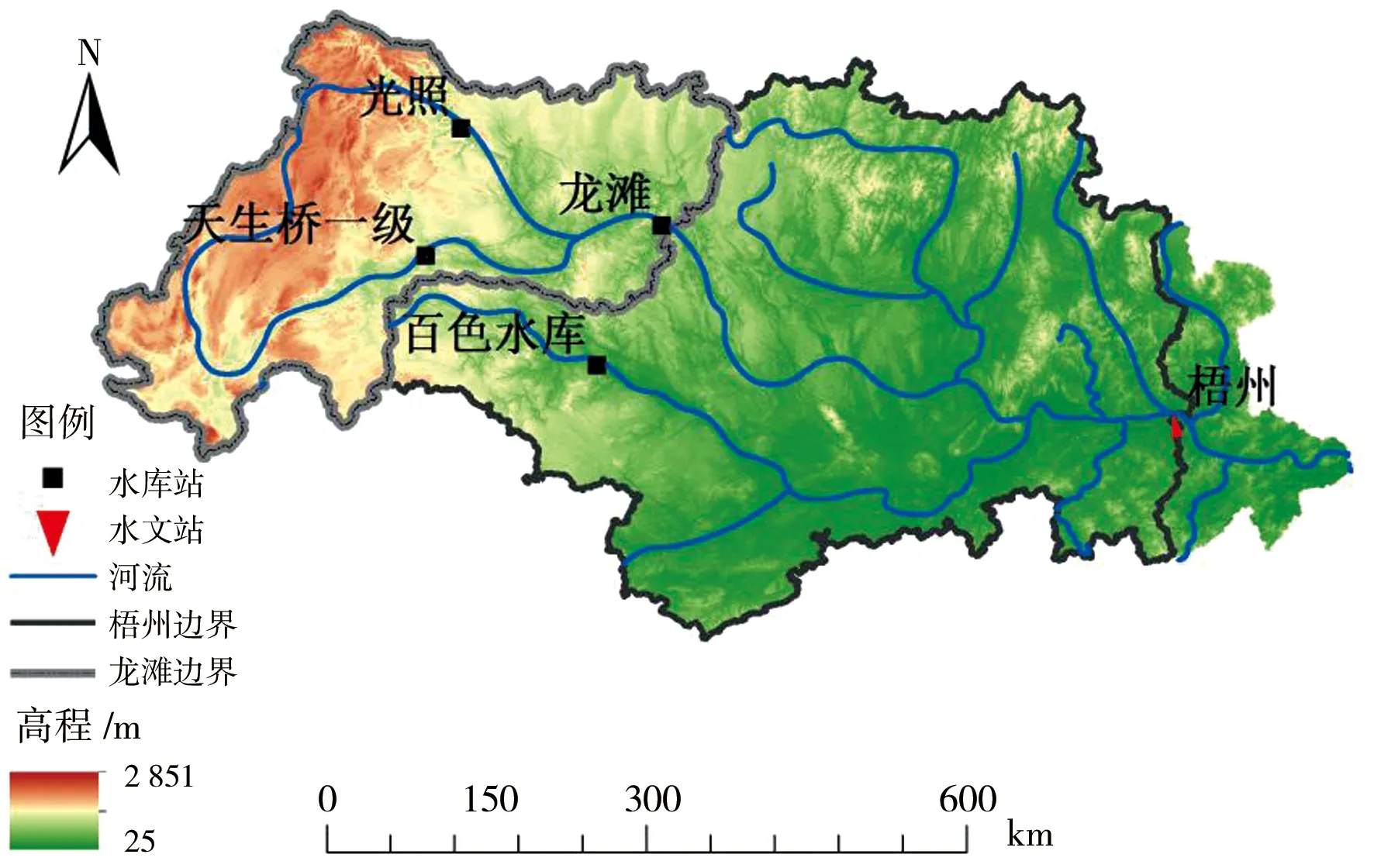
圖1 研究區域
收集了國家氣候中心1956—2020年的130項氣候監測指數資料(由于需要利用前期氣候指數資料,故起始年份向前推2年)、龍灘水庫和梧州以上流域的前期降雨流量資料(4—9月)作為多元逐步回歸的初選因子集。
2 研究方法
2.1 均生函數
均生函數預報方法的基本思想是假定事物過去存在的趨勢會延伸到未來,在分析時間序列變量的基礎上構建預報模型,通過向外延伸時間趨勢進而確定未來預報結果[10-11]。
設任意長度的時間序列X(t) (t=1,2,…,N),構造其均生函數如下:
(1)
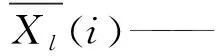
由此得到L(L=lmax=[N/2])階均生矩陣,通過對均生函數作周期外延進一步構造出外延矩陣,最后從中篩選出B個相關性強的序列,并基于此構建多元回歸模型進行模擬預測。
2.2 周期分析
周期分析法的基本思想是將變量隨時間的變化當做是由多個不同周期的周期波疊加而成的[12-13]。在給定置信度條件下,采用F檢驗的方法識別周期波,并對所識別的各周期波進行外延,線性疊加后可用于預測。設水文要素序列x(t),周期分析法基本計算式如下:
(2)
式中Pi(t)——第i個周期波序列;l——識別到的周期波個數;ε(t)——誤差項。
2.3 多元逐步回歸
采用氣象因子作為預報因子進行多元回歸計算的方式較為常見[14-15]。通過對在國家氣候中心網站下載的88項大氣環流指數、26項海溫指數和16項其他氣象指數,共計130項天氣學因子與對應的水文要素進行分析綜合,同時考慮前期流域降雨、江河來水等因素與預報對象具有較大相關性,本文將其與上述130項天氣學因子共同作為預報因子,用逐步回歸分析方法與預報對象建立方程,并從中篩選出物理意義明確、統計貢獻顯著的預報因子,對預測對象進行定量預測。多元逐步回歸基本計算式如下:
y=b0+b1·x1+b2·x2+b3·x3+…+bn·xn
(3)
式中y——預報對象;bn——回歸系數;xn——預報因子;n——因子個數。
2.4 精度評價指標
2.4.1變幅誤差(M)
采用GB/T 22482—2008《水文情報預報規范》[16]中針對中長期定量預報的精度評定方法,即以多年同期實測變幅的20%作為許可誤差,當預報值與實測值間的絕對誤差小于許可誤差時判定為合格(M<20%),否則不合格。M計算方法如下:
(4)
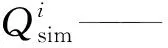
2.4.2平均絕對百分比誤差(MAPE)
該指標反映了預報值相對于實測值的偏離程度,MAPE越接近于0,則模擬效果越好。MAPE計算方法如下:
(5)

3 預報結果分析
以龍灘水庫和梧州水文站為例,采用上述均生函數、周期分析和多元逐步回歸3種統計方法分別構建徑流預報模型,預報時段為當年10月至次年3月各月(6個時段)和整個枯水期(1個時段),即2個斷面各有3×7個預報模型。考慮到率定期與驗證期的長度比一般符合3∶1左右的原則,對于龍灘水庫,以1958—2004年作為模型率定期,2005—2020年作為模型驗證期;對于梧州站,以1963—2005年作為率定期,2006—2020年作為驗證期。采用變幅誤差和平均絕對百分比誤差2個指標對各模型預報結果進行精度評定,龍灘水庫、梧州站各月和整個枯水期的徑流預報精度情況見表1、2。

表1 龍灘入庫各月、枯水期徑流預報精度統計 %
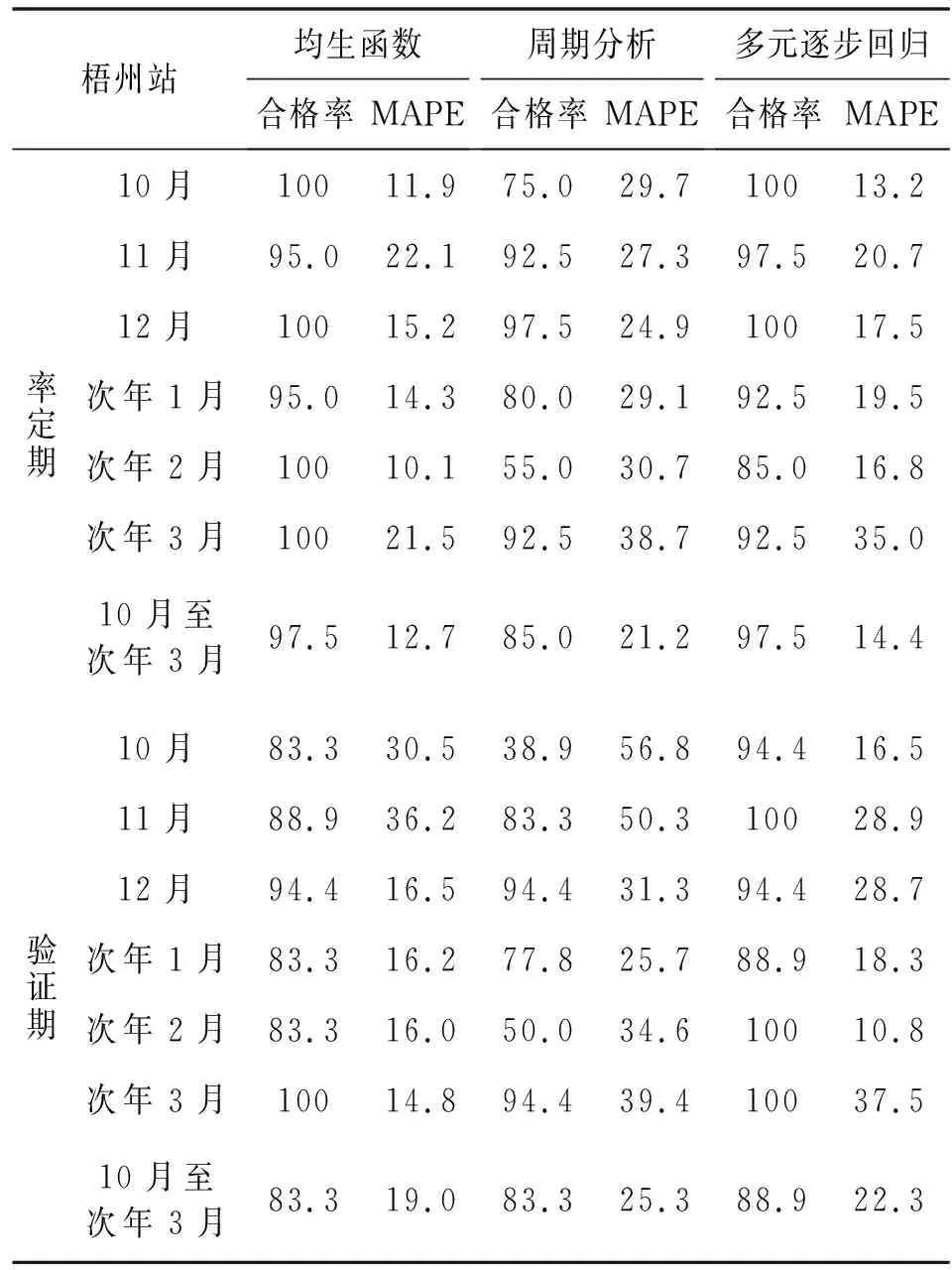
表2 梧州站各月、枯水期徑流預報精度統計 %
將2個斷面統一考慮,由表1、2可知,在率定期內,3種模型10月至次年3月各月和整個枯水期(10月至次年3月)的平均合格率均超過了75%,其中均生函數模型合格率在91.5%~100%,平均合格率為97.4%,多元逐步回歸模型在80.9%~100%,平均合格率為92.8%,周期分析較其他2個模型略低,2個斷面14個模型的合格率在55.0%~97.5%,平均合格率為78.8%;3種模型對應平均MAPE值均在30%以內,其中均生函數、多元逐步回歸2個模型平均MAPE值分別為15.3%和19.2%,均在20%以內,而周期分析模型相對較高,平均MAPE值為29.1%。綜合來看,3個模型在率定期均具有良好的預報效果,其中均生函數模型和多元逐步回歸模型明顯優于周期分析模型。
相對于率定期而言,驗證期的預報精度略有降低,其中均生函數模型驗證期平均合格率為89.6%,周期分析模型為74.8%,分別較率定期下降了7.8%和4.0%,而多元逐步回歸模型不降反升,平均合格率為94.5%,較率定期上升了1.7%;3種模型對應平均MAPE值較率定期總體存在不同程度的增漲,相似地,其中均生函數模型和周期分析模型均增漲10%,而多元回歸模型僅增漲5%,說明多元回歸模型具有較強的泛化能力,模型穩定性更強,這可能是因為相比前兩種模型僅分析自身演變規律,多元回歸模型使用前期水文氣象因子作為依據,獲得了更多的預報信息。精確到各月時發現,龍灘水庫次年二月的MAPE值均較高,但合格率卻不低,這是因為2010年2月龍灘天然來水是1958年以來最枯,較多年同期偏少92%,所以該年MAPE值異常偏高,導致平均MAPE值也更高。
為了更直觀地查看和對比3種模型的預報效果,圖2、3分別給出了整個時間序列內上游龍灘水庫和下游梧州站預報值和實測值的散點關系。
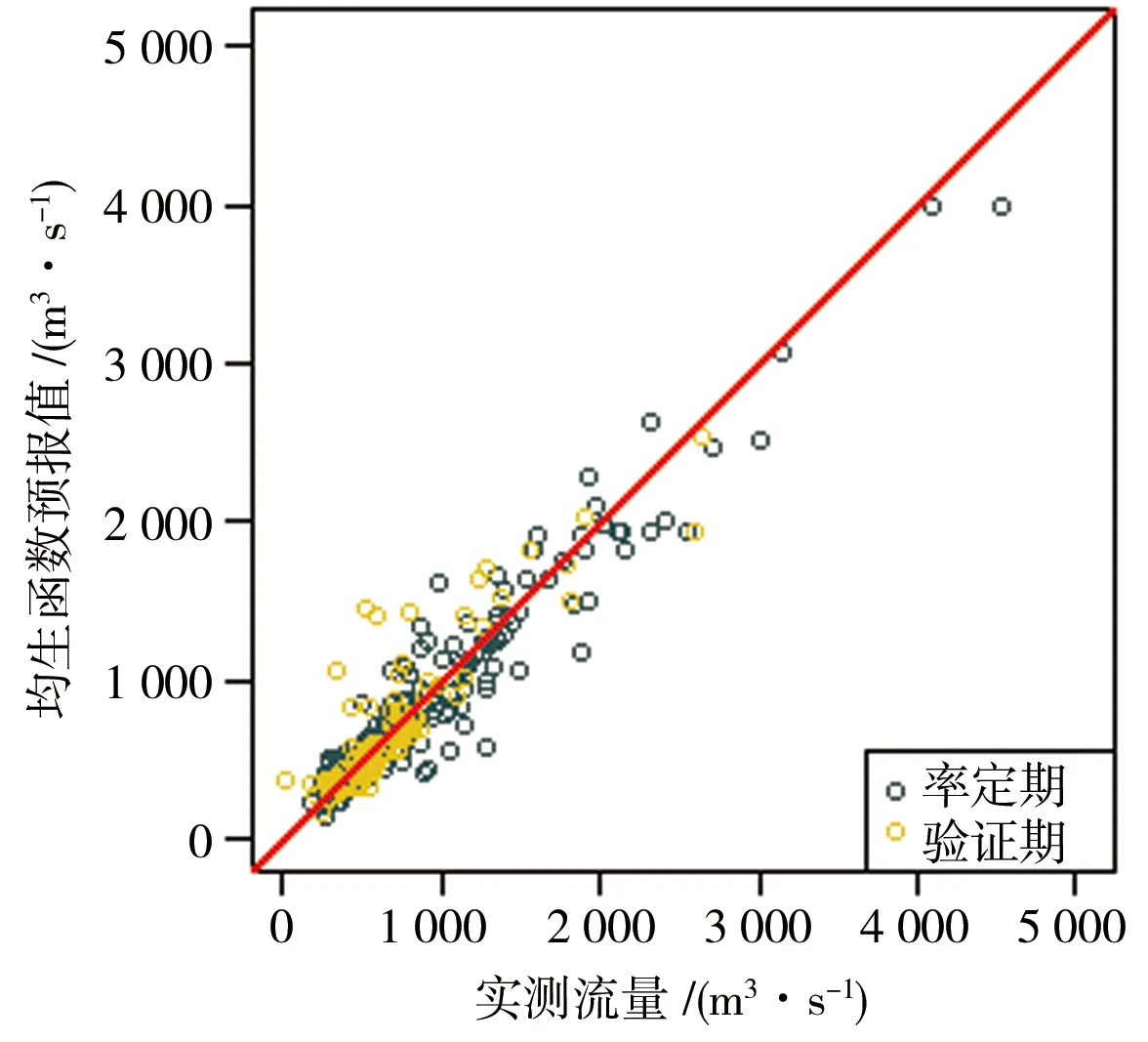
a)均生函數預報

a)均生函數預報
由圖2、3可以明顯看到,在率定期與驗證期內,均生函數模型和多元逐步回歸模型的散點均聚攏分布在45°線(圖中紅線)附近,且線兩側散點個數比重相當,說明2個模型對枯水期各月流量均具有較好的預報效果。相比之下周期分析模型45°線兩側雖也分布均勻,但散點較離散,且隨著量級增加,預報的偏差越大,上半部分散點大多分布于紅線以下,即在流量量級較大時周期分析模型存在預報偏低現象。由此可知,均生函數模型和多元回歸模型的預報精度整體較周期分析模型更高,在高流量值的預報上誤差更小。另外,通過對比龍灘入庫和梧州站可以看到,前者各模型散點分布更聚集,究其原因,可能與梧州站以上眾多水庫的調度調節有關,隨著水庫的增建和人類活動的影響增加,經4座水庫還原后的梧州站還原流量并不是真正的天然流量,序列資料一致性遭到一定程度的破壞,導致模型精度降低。
4 結論
可靠的中長期徑流預報是流域開展科學的枯水期水量調度工作的重要依據。基于均生函數、周期分析、多元逐步回歸3種統計模型,本文對西江上游龍灘水庫、下游梧州水文站進行了自10月至次年3月各月以及整個枯水期的徑流預報,得出的結論如下。
a)3種模型均呈現出較好的預報效果,率定期和驗證期平均合格率均在75%以上,MAPE值基本在30%以內,其預報結果可為西江流域水量調度方案的編制提供技術參考。其中均生函數和多元逐步回歸的預報精度相近,且明顯高于周期分析,特別是在對極值的預報能力方面。
b)與均生函數和周期分析相比,多元逐步回歸模型穩定性更強。前兩者驗證期平均合格率較率定期均有所下降,后者不降反升,且仍保持在90%以上,MAPE值的增漲也最緩慢。
c)在預報天然流量時,序列資料的一致性程度會影響預報精度。就模型預報與實測的整體擬合情況而言,上游龍灘水庫較下游梧州站擬合得更好,這可能與梧州水文站作為西江控制站受到眾多水庫共同調控的影響有關。
d)由于計算思路不同,統計模型各有優劣,目前還不存在一個具有絕對優勢的通用模型,因此可以考慮通過融合多種模型的方式,達到優化預報效果的目的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代畜牧科技(2021年9期)2021-10-13 06:38:48
裝備制造技術(2021年1期)2021-05-21 07:55:24
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:13
中國衛生質量管理(2015年2期)2015-12-01 05:43:57
核科學與工程(2015年4期)2015-09-26 11:59:03
現代企業(2015年8期)2015-02-28 18:55:23
