基于負載狀態的ICN 緩存替換算法研究
2023-01-08 16:48:38曾理,倪宏,韓銳
電子設計工程 2023年1期
曾 理,倪 宏,韓 銳
(1.中國科學院聲學研究所國家網絡新媒體工程技術研究中心,北京 100190;2.中國科學院大學,北京 100049)
泛在化緩存[1]決定了ICN(Information Centric Networking,信息中心網絡)的性能優勢,其可有效減少冗余數據的傳輸,緩解網絡帶寬的壓力,降低傳輸時延[2]。緩存替換在ICN 路由器內部時刻都在發生,每一次替換過程都會對網絡性能產生影響[3]。目前,ICN 緩存替換算法的研究集中在對內容未來流行度的預測[4-6],或是根據拓撲信息和鄰居節點緩存信息來優化緩存空間[7-9],但這些研究在帶來額外計算開銷或控制開銷的同時,相較于傳統LRU(Least Recently Used,最近最少使用)替換算法,其性能并未得到明顯改善[10]。
隨著節點緩存容量和計算能力的限制被打破[11],不同類型的流量競爭有限的帶寬資源已成為ICN 路由器發生擁塞的主要原因之一[12]。針對這一問題,為了避免節點因高緩存命中率引發嚴重帶寬競爭,該文提出一種基于節點負載狀態的緩存替換算法,監測節點是否長期處于帶寬競爭狀態,并采用自適應替換窗口將一些較為流行的內容主動替換,減少帶寬競爭的發生頻率和持續時間,降低節點丟包率。
1 ICN路由器的帶寬競爭
文獻[12]認為ICN 中擁塞發生的原因除緩沖區溢出外,還可以進一步歸納為過度的帶寬資源競爭。具體來說,假設請求報文以速率γ抵達路由器,τc是緩存服務所需的吞吐量(γ≤τc),而對于ICN 路由器的實時轉發吞吐量τf,某時刻很有可能出現來自外部流量的轉發吞吐量與來自內部流量的緩存服務吞吐量之和大于端口帶寬B,從而造成擁塞丟包,即τf+τc>B。ICN 中每個數據報文都需要通過一個請求報文“拉”給用戶[13],因此可以通過來預測帶寬競爭的發生(是數據報文的平均尺寸)。
2 算法設計與建模
2.1 算法設計
如果ICN 路由器在一段時間內持續處于帶寬競爭狀態,則可以認為節點應該主動替換一些流行度較高的內容,從而減少帶寬競爭發生的頻率和持續的時間。
節點帶寬競爭狀態隨網絡波動而動態變化,為了準確加以檢測,算法采用時間間隔為T的開關信號對其進行采樣。如圖1 所示,如果采樣時刻節點帶寬競爭發生且請求到達速率高于閾值,則用1表示;如果采樣時路由器尚有空閑的帶寬,則用0 表示。由于固定時間窗偏移的方法容易忽視抽樣信號前后窗口的相關性而造成誤判,算法采用長度為W的滑動時間窗口(如圖中W1,W2,…,Wn)來跟蹤統計離散時間下的節點狀態,W的值根據RTT(Round-Trip Time,往返時延)、路由器排隊時延來決定。如果時間窗內帶寬競爭出現次數大于,算法則判斷節點處于持續的帶寬競爭。滑動窗口監測考慮了請求報文之間的相關性,能夠做出更精準的判斷,但代價是增加了管理開銷。
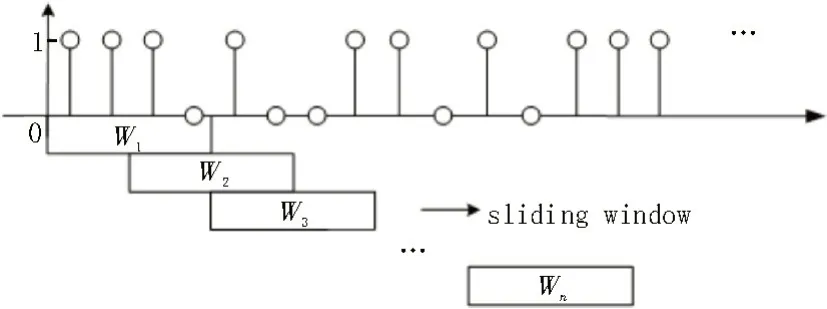
圖1 基于滑動窗口抽樣檢測帶寬競爭
對于內容流行度的評估,在最新的研究中,無論是通過多元線性回歸方法[14],還是通過數據塊間的相關性[15]對內容未來請求規律進行預測,文獻[10]都已經證明基于流行度的替換算法相比起LRU 替換算法的性能提升并不明顯。因此所提算法仍使用LRU隊列來篩選流行內容。
當檢測到帶寬競爭持續發生時,算法通過變長窗口替換隊列首部的熱門數據,這在一定程度上解決了LRU 時間新近性的問題。考慮到現實路由器中有多個端口,為了更精準地替換導致節點擁塞的數據塊,算法將記錄每個數據塊被請求次數和請求報文到達端口的映射,當某個端口Bp被檢測到帶寬競爭持續發生,變長窗口僅會替換請求曾從該端口抵達的數據。如圖2 所示,若端口1 持續發生帶寬競爭,LRU 隊列上僅第2、3、5、6 的數據被替換,第1 和4數據塊的請求因未曾抵達過端口1 而被保留。假設替換窗口長度用L表示,當檢測到帶寬競爭發生時,替換窗口增加固定值a。當帶寬競爭狀態持續了Q個檢測窗口,替換窗口將會成倍增長。a與Q的取值由路由器緩存容量(LRU 隊列長度)來決定。
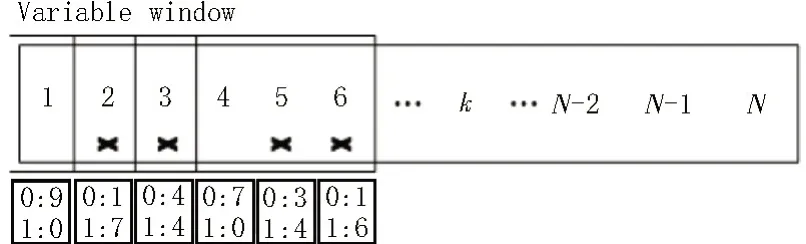
圖2 可變窗口選擇熱門數據
2.2 替換窗口長度變化規則建模
基于帶寬競爭監測的替換算法中,替換窗口長度變化的行為可以用一個離散馬爾科夫過程來建模。
如圖3 所示,S0代表窗口長度為0 的初始狀態,此時不需要主動對流行內容進行替換;當監測到帶寬競爭持續發生時,替換窗口長度將會增加固定值a并處于S1態;S2態代表帶寬競爭狀態持續了Q個時間窗口以上,窗口長度將會翻倍。因此可以看出,帶寬競爭狀態持續時間對于各狀態之間的轉換起著至關重要的作用。為了清晰地表達轉移概率,首先定義函數f如式(1)所示:
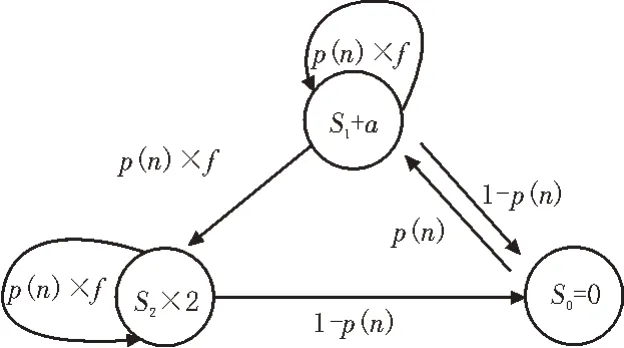
圖3 可變窗口的馬爾科夫建模

因此,可以得到如式(2)的狀態概率轉移矩陣:

其中,p(n)是n時刻路由器抽樣檢測到帶寬持續競爭的概率。
替換窗口變化過程可通過式(3)來建模:
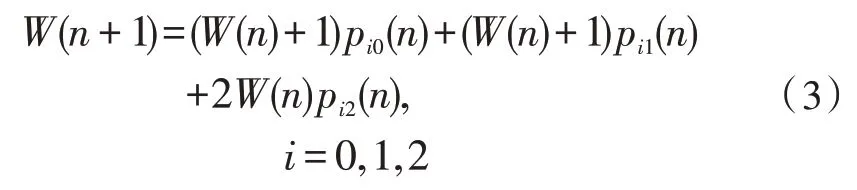
n時刻LRU 隊列的長度可以表示為:
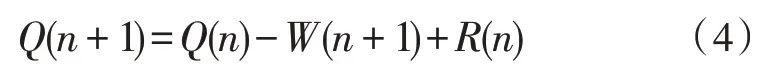
3 實驗與分析
3.1 實驗設置
為了驗證該文提出的緩存替換算法的性能,仿真實驗采用Icarus 模擬器在GEANT 網絡拓撲下與另外兩種傳統的替換算法LRU、FIFO(First Input First Output,先入先出)進行對比實驗。Icarus 是一個輕量級的仿真軟件,可以允許用戶輕易地測試定制的ICN 緩存和路由策略。GEANT 是面向研究和教育團體的一個泛歐洲數據網絡,總共包含40 個節點,其中8 個邊緣請求者,13 個內容提供者,19 個ICN 路由器。仿真實驗的各項設置參數如下:1)請求到達速率符合泊松分布;2)內容流行度符合α=0.8 的ZiPf分布;3)內容數據塊總數量為1×105個;4)預熱ICN緩存網絡的請求數目為1×105個;5)實際用于測量統計的請求數目為2×105個;6)請求者發送請求的速率為80~100 個/s;7)節點采用的緩存策略:LCE(Leave Copy Everywhere,處處緩存)和一種基于介數中心性的緩存策略[16];8)窗口持續閾值n=5。
假設路由器每個端口的處理能力為每秒處理150 個數據塊,并且路由器為每個端口維護一條轉發隊列queuef和緩存響應隊列queuec,當兩條隊列排隊的待處理的數據塊數目超過端口處理能力(帶寬)時,則視為帶寬競爭發生。抽樣間隔T為0.2 s,監控窗口時長為2 s,當窗口中帶寬競爭次數超過6 次時,視為一次持續帶寬競爭。
ICN路由器緩存容量S作為變量參與實驗對比,其取值為500、1 000、1 500、2 000、2 500、3 000、3 500、4 000,其中替換窗口每次增加的固定值a為0.002×S。實驗中,ICN 傳輸協議將會在檢測到用戶請求超時后重新發出請求。同一場景下的各個實驗獨立運行5次,并以95%的置信區間對結果進行分析。
3.2 仿真結果分析
圖4 顯示了不同替換算法在部署了不同緩存策略的緩存系統中的平均緩存命中率。很明顯,比起基于介數中心性的緩存策略,LCE 能幫助系統獲得較高的緩存命中率。對于緩存替換算法,由于FIFO算法完全不考慮內容流行度,LRU 能獲得較好的緩存命中率。在部署了基于介數中心性策略的緩存系統中,LRU 的性能表現最差,甚至與FIFO 接近,這是由于部分介數較高的節點承擔了大量轉發任務的同時,較高的緩存命中率使得請求并發響應增多,從而導致帶寬競爭狀態持續存在,丟包率上升,降低了整個系統的平均命中率。

圖4 不同緩存策略系統采用不同替換算法的緩存命中率對比
另外,隨著節點緩存容量的提高,采用LRU 算法的緩存命中率先是急劇提升,然后增速降緩。這說明單純提高節點緩存容量對整體網絡的性能改善有限。從圖中可以看出,與LRU 相比,該文的優化算法有明顯的性能改善,在采用基于介數中心性策略的緩存系統中提升最明顯,緩存命中率最高能夠提高14.3%。這是因為所提替換算法使介數較高的“中心節點”減少了帶寬競爭持續時間,從而減少了丟包率。
為了進一步分析帶寬競爭對網絡性能的影響,實驗觀察了不同緩存系統中介數最高節點的丟包率(S=3 000)以及系統的瓶頸重傳概率,結果如圖5、6 所示;平均重傳概率是用戶發出的請求總數(包含重傳請求)與測試請求數(200 000)的比值,其能在一定程度描述網絡的擁塞情況。結果顯示無論部署什么緩存策略,介數最高的路由器丟包率都要高于系統的平均重傳概率,這證明在考慮帶寬資源受限的約束下,“中心”路由器是網絡性能的瓶頸。

圖5 不同緩存策略系統中介數最高節點采用不同緩存替換算法的丟包率對比
而該文的替換算法極大改善了部署基于介數中心性策略的緩存系統中“中心節點”的丟包率,但在部署LCE 的緩存系統中改善卻不明顯,這是因為LCE 策略使得緩存系統的“中心”節點帶寬競爭產生的主要原因是轉發流量過多。
如圖6 所示,LRU 算法總是能在系統中產生最高的重傳概率,性能表現最差。與LRU 相比,該文的替換算法既有較好的緩存命中率,同時系統平均重傳概率也比LRU 低,在基于介數中心性策略的系統中性能改善最高能達到34.9%,這是因為該算法減少了帶寬競爭,進而減少了因丟包造成重傳。
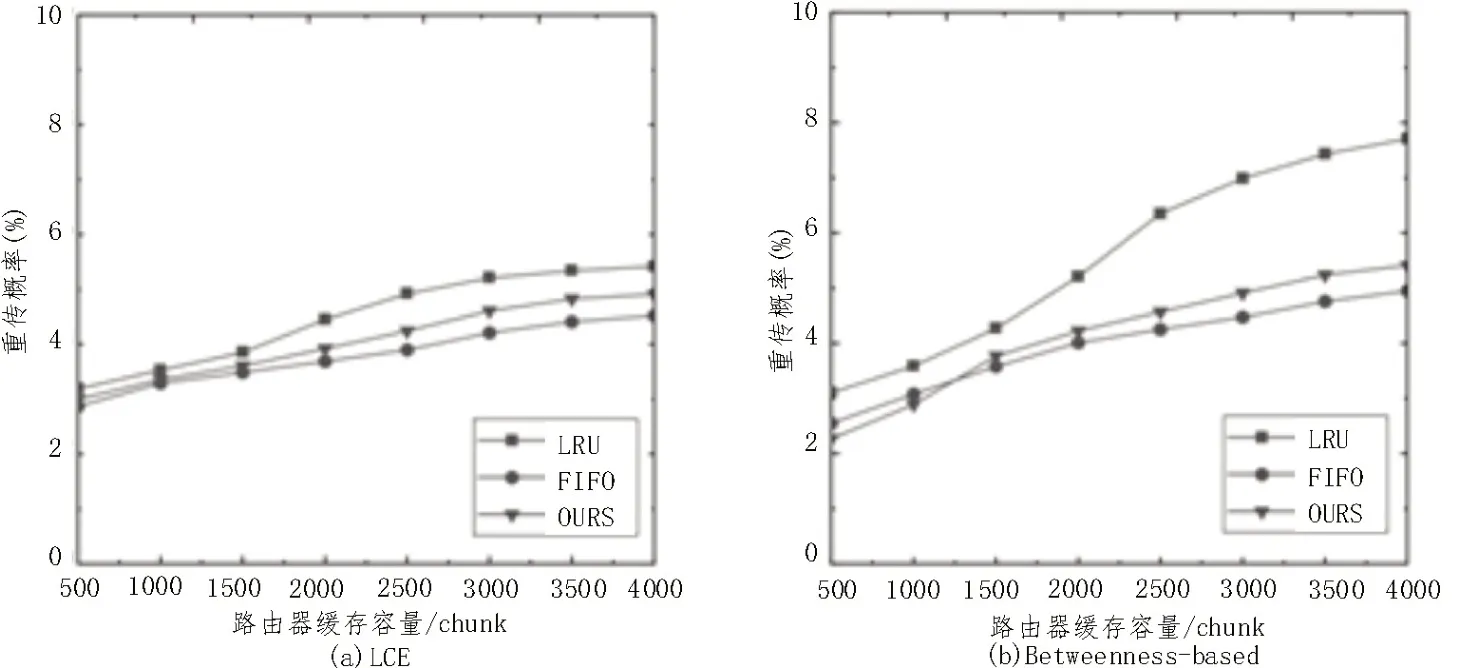
圖6 不同緩存策略系統采用不同替換算法的重傳概率對比
圖7 對比了不同替換算法在不同緩存策略系統中用戶內容下載時延。隨著節點緩存容量增加、系統平均命中率的提高,用戶下載時延在不斷減少。對比其他兩種緩存替換算法,該文的替換算法性能表現最好,這是因為其有效抑制了路由器帶寬競爭持續的時間導致節點丟包率和重傳概率減少,從而大幅度降低了用戶內容下載平均時延。在基于介數中心性策略的系統中,與LRU 算法相比,內容下載時延最多可節省11.3%。
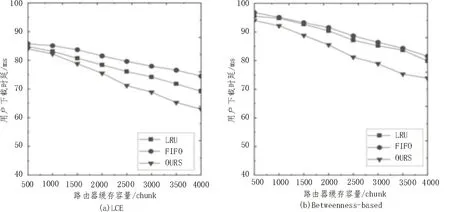
圖7 不同緩存策略系統采用不同替換算法的內容下載時延對比
4 結論
該文針對ICN 緩存節點因持續處于帶寬資源競爭狀態導致網絡擁塞加重的問題,提出了一種基于路由器負載狀態的緩存替換算法。該算法通過監控持續帶寬競爭狀態來改善LRU 的性能,并在采用不同的策略(LCE,基于介數中心性的策略)的緩存系統中進行性能對比。實驗結果表明,所提優化算法能夠有效地改善LRU 算法的不足,并在內容下載時延、平均緩存命中率、重傳率上都獲得了較好的性能提升。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
裝備制造技術(2019年12期)2019-12-25 03:06:46
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
數學大世界(2018年1期)2018-04-12 05:39:14
