利用強化學習開展比例導引律的導航比設計
2023-01-05 10:48:36李慶波李芳董瑞星樊瑞山謝文龍
兵工學報 2022年12期
李慶波, 李芳, 董瑞星, 樊瑞山, 謝文龍
(上海機電工程研究所, 上海 201109)
0 引言
制導規(guī)律是指根據(jù)導彈和目標的相對運動關(guān)系,導引導彈按一定的飛行軌跡對目標實施精確打擊攔截。制導規(guī)律是導彈精確制導的技術(shù)核心,制導規(guī)律的研究是精確制導武器研究的關(guān)鍵。
國內(nèi)外關(guān)于末制導規(guī)律的研究目前已有大量的理論成果,例如基于最優(yōu)控制理論的最優(yōu)制導律[1]、將最優(yōu)控制理論與微分對策理論相結(jié)合的微分對策制導律[2]、基于模糊控制理論的模糊制導律[3]、神經(jīng)網(wǎng)絡末制導律[4]以及被廣泛研究的變結(jié)構(gòu)制導規(guī)律[5-6]。盡管制導規(guī)律的理論成果眾多,但受制于工程實現(xiàn)條件,目前在導彈制導中應用最廣泛的仍是比例導引末制導律。
由于比例導引規(guī)律實現(xiàn)簡單、工程易用性強,許多專家學者開展了基于比例導引的進一步研究。李新三等[7]基于模型靜態(tài)預測規(guī)劃方法設計了一種協(xié)同比例制導律;閆梁等[8]從普適性制導律的角度出發(fā),設計了一種末端碰撞角約束限制的偏置比例制導律;李波等[9]提出一種基于遺傳算法的模糊比例導引規(guī)律;李轅等[10]設計了針對高速目標攔截特點的三維聯(lián)合比例制導律;白國玉等[11]提出一種自動選擇攔截模式并調(diào)整攔截彈速度,兼具順、逆軌攔截能力的全向真比例制導律;秦瀟等[12]考慮用擴張狀態(tài)觀測器對目標的機動形式進行在線估計,設計了一種帶有目標機動補償?shù)姆幢壤茖桑籗u等[13]設計了一種考慮零控脫靶以及飛行器間安全距離的偏置比例導引律;王榮剛等[14]提出一種攔截高速運動目標廣義相對偏置比例制導律。
關(guān)于比例導引規(guī)律的擴展研究通常是在傳統(tǒng)比例導引的基礎上增加修正項,如重力補償、導彈軸向加速度補償、目標機動補償及碰撞角約束等環(huán)節(jié)。因此無論對于何種比例導引,都無法避開傳統(tǒng)比例導引中以視線角速度為輸入量的導航比設計過程。文獻[15]建議導航比范圍為2~6之間,然而這是一個相對寬泛的取值區(qū)間,在此范圍內(nèi)的不同取值對導彈制導攔截性能具有顯著的影響。
導彈制導攔截的過程實際上是導彈與目標的博弈過程,而導航比的選取問題就是這個博弈過程中制導控制的決策過程。強化學習利用試錯法不斷與環(huán)境交互來改善自己的行為,從而優(yōu)化自身的應對策略,同時強化學習具有對環(huán)境的先驗知識要求低的優(yōu)點,是一種可以應用到實時環(huán)境中的學習方式[16-17]。
近些年,強化學習在導彈制導中的應用開始引起學者關(guān)注,陳中原等[18]提出基于強化學習的多彈協(xié)同攻擊智能制導律,用以降低脫靶量和攻擊時間誤差。梁晨等[19]針對執(zhí)行機構(gòu)部分失效條件下導彈對機動目標的攔截問題,提出一種基于深度強化元學習和剩余飛行時間感知邏輯函數(shù)的攻擊角度約束三維制導律。
本文采用強化學習的方法開展導航比的設計,嘗試利用大數(shù)據(jù)決策替代傳統(tǒng)的經(jīng)驗取值設計,解決比例導引規(guī)律設計過程中的共性問題,盡可能提升導彈對目標的打擊攔截能力。
1 基本設計思路
1.1 比例導引規(guī)律
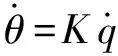
(1)
式中:K為待設計的系數(shù)。
導彈和目標的相對運動關(guān)系如圖1所示。圖1中,M表示導彈,T表示目標,v表示導彈速度,vT表示目標速度,η表示導彈速度軸與視線軸的夾角,ηT表示目標速度軸與視線軸的夾角,θ表示導彈速度傾角,q表示彈目視線角,xM為水平方向。
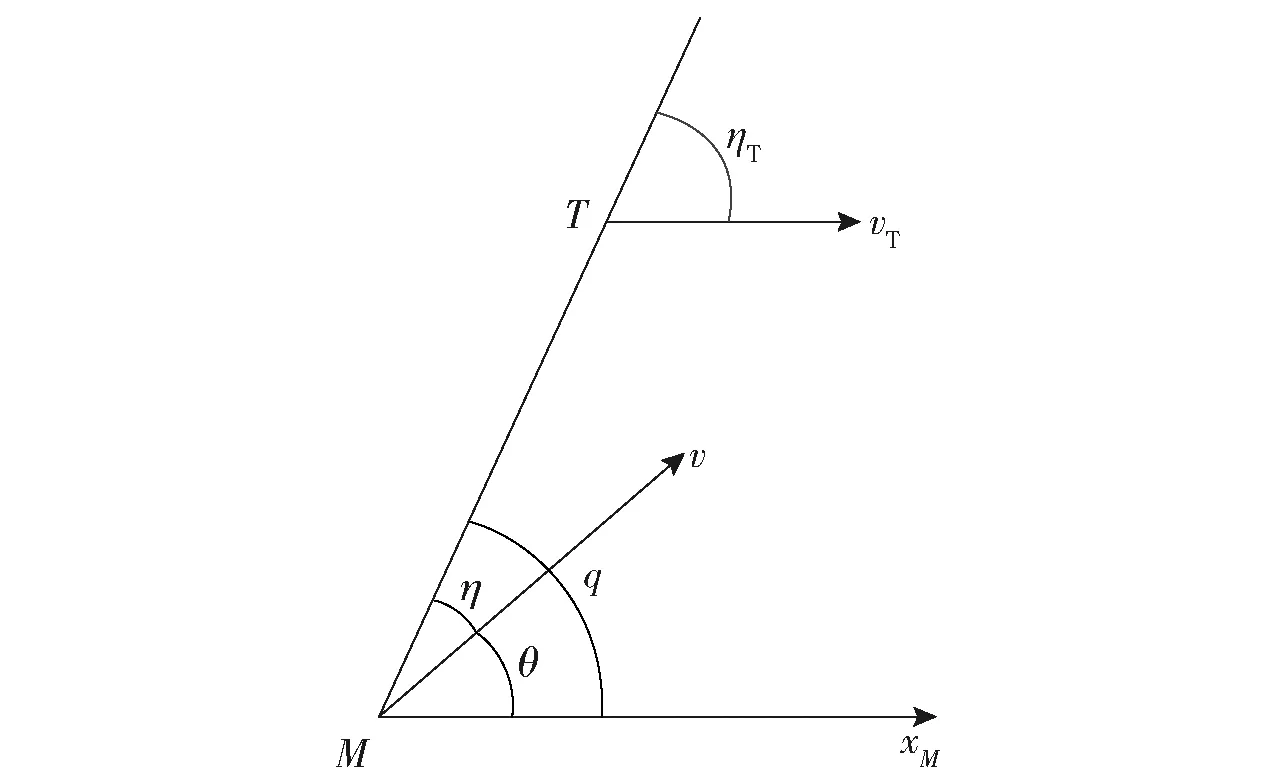
圖1 導彈和目標相對運動關(guān)系Fig.1 Relative motion diagram of missile and target
(2)
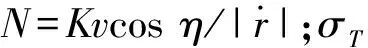
從(2)式可以看出,為保證系統(tǒng)穩(wěn)定,則要求有效導航比N>2。
在工程應用中,近似認為cosη,可將(1)式改寫為
(3)
式中:nc為導彈的過載指令;g為重力加速度。
從(3)式可知,比例導引規(guī)律算法簡單,且僅需要外部提供彈目相對速度及視線角速度信息,這是比例導引規(guī)律能夠在工程中獲得廣泛應用的根本原因。為保證本文的算法具備工程易用性,本文將在比例導引規(guī)律的基礎上開展設計。
1.2 強化學習基本理論
強化學習任務通常使用馬爾可夫決策過程來描述[20]:機器處于環(huán)境E中,狀態(tài)空間為S,其中每個狀態(tài)為機器感知到的環(huán)境的描述,機器能采取的動作構(gòu)成了動作空間A,若某個動作a∈A作用在當前狀態(tài)s上,則潛在的轉(zhuǎn)移函數(shù)P將使得環(huán)境從當前狀態(tài)按照某種概率轉(zhuǎn)移到另一個狀態(tài),在轉(zhuǎn)移到另一個狀態(tài)的同時,環(huán)境會根據(jù)潛在的“獎賞”函數(shù)R反饋給機器一個獎賞。綜合起來,強化學習任務對應了四元組E=〈S,A,P,R〉。圖2所示為強化學習原理示意圖。
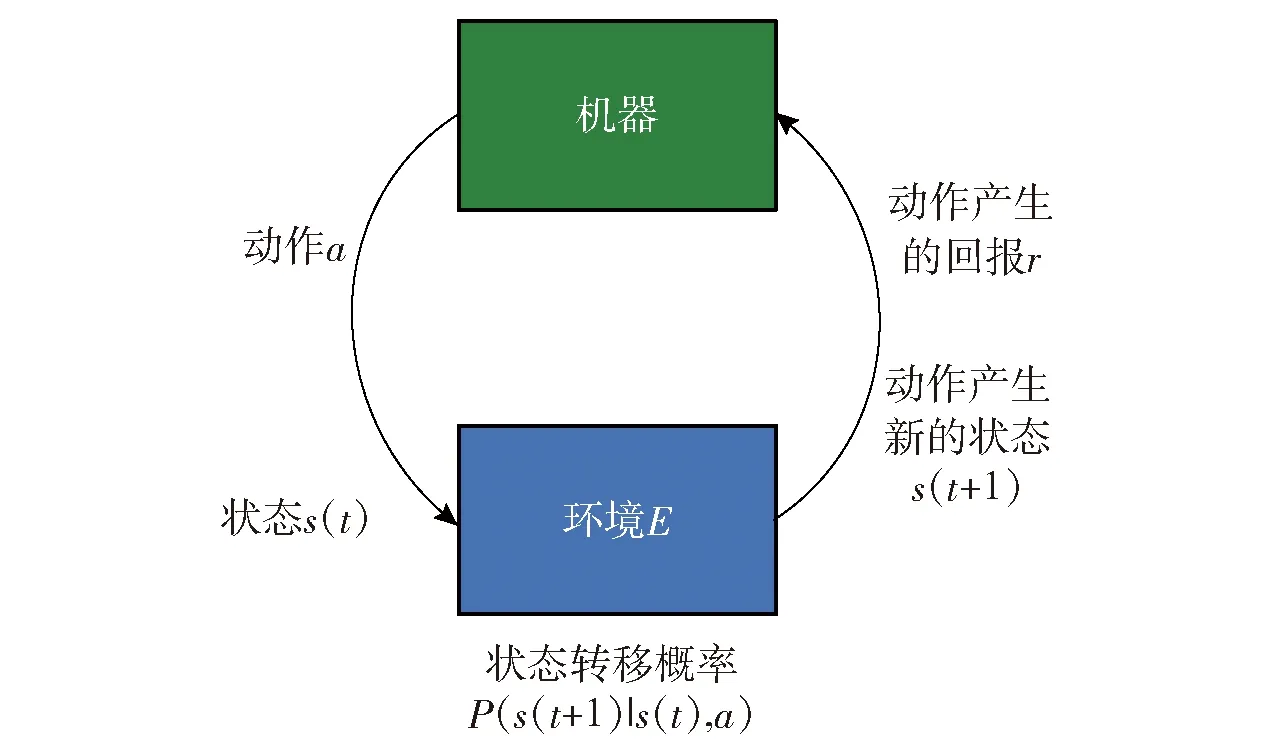
圖2 強化學習原理示意圖Fig.2 Schematic diagram of reinforcement learning
強化學習的目標是給定一個馬爾可夫決策過程,尋找最優(yōu)策略。所謂策略是指狀態(tài)到動作的映射,策略常用符號π表示,它是指給定狀態(tài)s時,動作集上的一個分布,即
π(a|s)=P[At=a|St=s]
(4)
式中:St表示在t時刻或階段所處的狀態(tài);At表示在t時刻或階段所執(zhí)行的動作。
策略的定義是通過條件概率給出的,即在狀態(tài)為s的條件下執(zhí)行動作a的概率。策略的優(yōu)劣取決于長期執(zhí)行這一策略后得到的累積獎勵,累積獎勵越高,說明策略越好。在強化學習任務中,學習的目的就是找到能使長期積累獎勵最大化的策略。
1.3 利用強化學習開展導航比設計的基本思路
為利用強化學習解決導彈制導規(guī)律設計問題,首先需將制導規(guī)律設計過程轉(zhuǎn)化為典型的馬爾可夫決策過程。為不增加工程實現(xiàn)的復雜度,本文在比例導引的基礎上,利用強化學習對導航比進行設計。對照馬爾可夫決策過程的四元組,建立導航比取值決策過程模型如圖3所示。
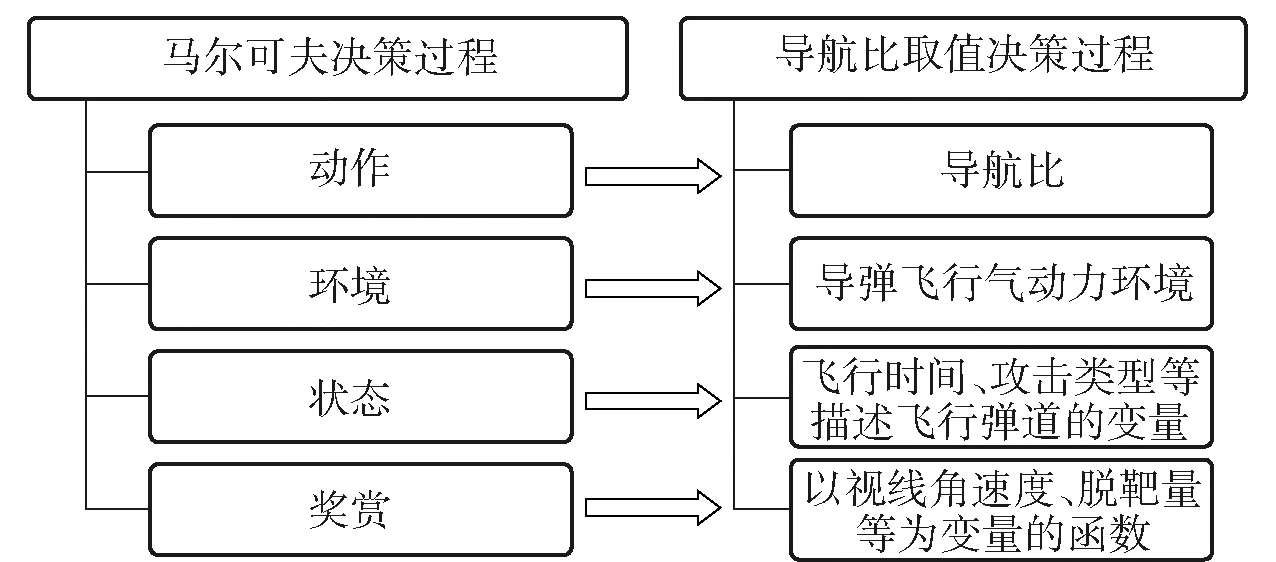
圖3 導航比取值決策問題模型關(guān)系示意圖Fig.3 Schematic diagram of navigation ratio decision model
利用強化學習開展導航比的設計過程可概述為:通過全空域大量典型彈道的仿真計算,評估導彈在不同飛行狀態(tài)下執(zhí)行不同導航比策略后的制導效果,按照一定的方法尋求能夠獲得最佳制導效果的導航比策略。
強化學習多采用ε-貪心或Softmax策略,其目的是在多次采樣過程中,既能獲得最優(yōu)的策略,同時也能在采樣過程中盡可能獲得較大的獎賞。但在進行導航比設計過程中,只關(guān)心最終獲得最優(yōu)的導航比策略,希望在采樣過程中盡可能獲得豐富的樣本,而不關(guān)心在采樣過程中獲得的實際獎賞。因此本文中的兩種方法均采用“僅探索”的策略開展導航比設計。
2 蒙特卡洛強化學習導引律設計
對標工程實際中廣泛應用的比例導引規(guī)律,力求設計一種工程應用簡單,制導精度更高的導引規(guī)律。為盡可能簡化算法設計,采用蒙特卡洛強化學習方法。
蒙特卡洛強化學習的基本思想[20]是:進行大量不同策略或不同條件的試驗,通過求取每種策略的平均積累獎勵作為期望積累獎勵的近似,從而完成對策略優(yōu)劣的評估和策略的迭代。
2.1 四要素的確定與設計
對照強化學習的要素,具體策略求解模型如下:
1)環(huán)境E。整個導彈制導仿真模型。具體包含大氣模型、基于氣動吹風及飛行試驗辨識獲得的氣動參數(shù)、發(fā)動機推力參數(shù)、質(zhì)量和重心參數(shù)、理論彈道模型、控制系統(tǒng)模型、導引頭和控制艙等要素。
2)狀態(tài)S。本節(jié)主要考慮工程實際應用,設計一種模型簡單、工程實現(xiàn)性強的導航比算法,為此將整個制導的狀態(tài)進行簡化,僅考慮飛行時間和目標攻擊方式兩個狀態(tài)。
目標攻擊狀態(tài)集合為{迎攻,尾追};
飛行時間分段離散化集合為{1,2,3,4},具體分段方式如圖4所示。圖4中,ts為基于飛行時間的分段序號,Tqk為起控時間,Tmz為裝定或計算的預計遭遇時間。

圖4 飛行時間分段離散化Fig.4 Flight time piecewise discretization
3)動作A。在不同狀態(tài)條件下,導航比的取值。將導航比離散化為
N∈[2∶0.2∶6]
(5)
即存在21種導航比的取值。
4)獎賞R。本文的設計是以視線角速度收斂的程度和最終的脫靶量來評估導航比策略的優(yōu)劣,具體獎賞策略如下:
①視線角速度獎賞策略。將視線角速度進行離散化處理,離散化分段如圖5所示。

圖5 視線角速度分段離散化Fig.5 LOS rate piecewise discretization
在進行狀態(tài)切換時,視線角速度由低狀態(tài)(分段序號較小值)向高狀態(tài)(分段序號較大值)變化,對上一個狀態(tài)- 動作對進行懲罰,即給予該狀態(tài)- 動作對負向獎勵;相反,如果視線角速度反向變化,則對上一個狀態(tài)- 動作對進行獎勵,即給予該狀態(tài)- 動作對正向獎勵;如果視線角速度在狀態(tài)切換過程中仍保持在當前分段,則不進行獎勵和懲罰。本文在計算過程中具體采用的關(guān)于視線角速度的獎賞算法如圖6所示。
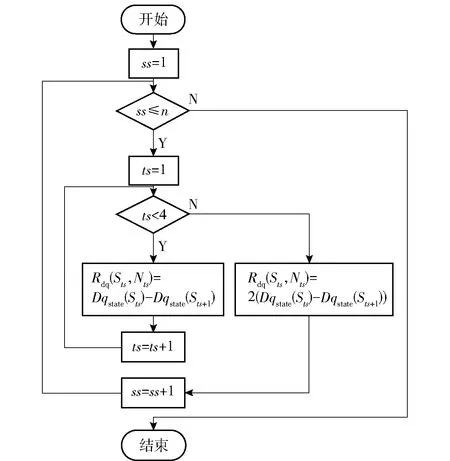
圖6 視線角速度獎賞策略流程圖Fig.6 Flow chart of LOS rate reward strategy
圖6中:ss表示執(zhí)行的彈道序號,共計n條彈道;Dqstate(Sts)表示在Sts狀態(tài)時,視線角速度分段序號;記錄(Tmz-0.3)時刻的視線角速度狀態(tài)為Dqstate(S5);Rdq(Sts,Nts)表示在Sts狀態(tài)時,導航比采用Nts所獲得的視線角速度獎賞。
②脫靶量獎賞策略。將脫靶量進行離散化并設置對應的獎勵如圖7所示。
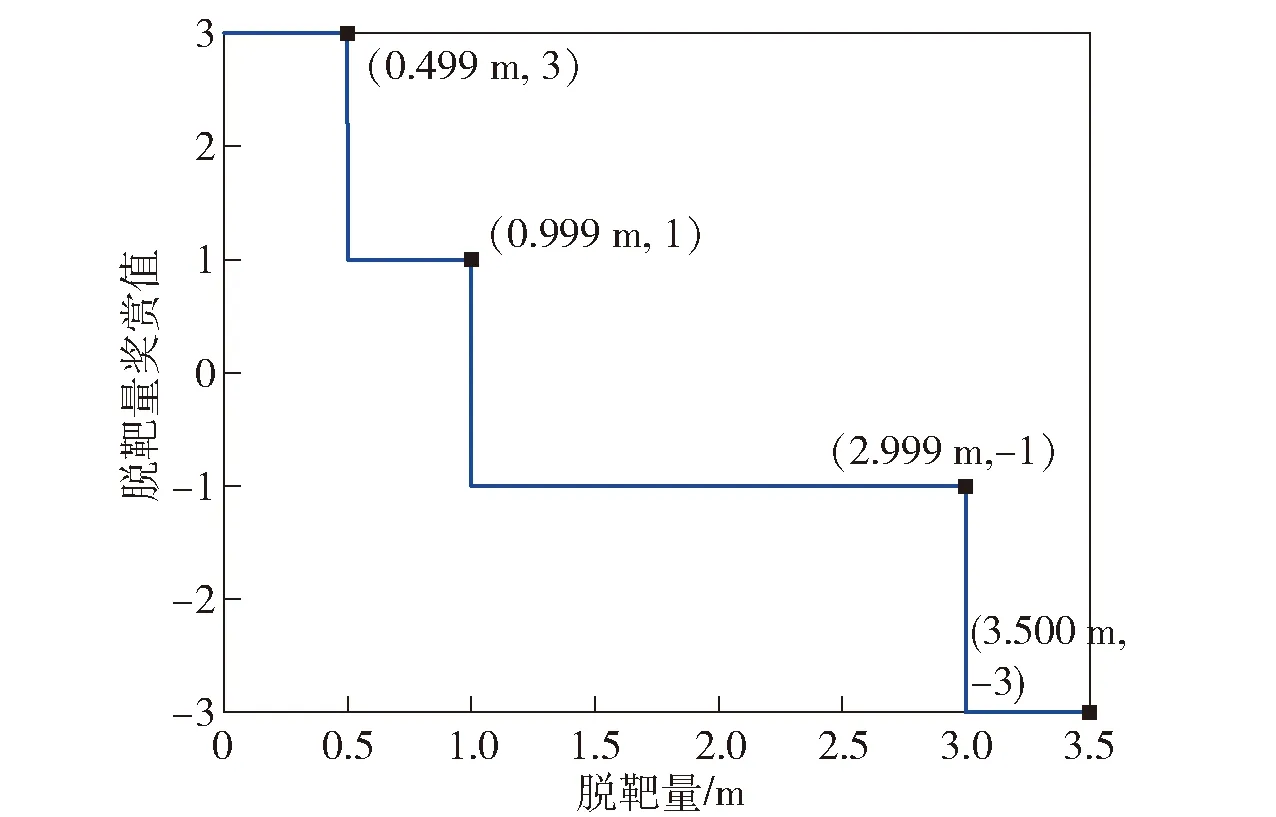
圖7 脫靶量獎賞策略示意圖Fig.7 Flow chart of miss distance reward strategy
需補充說明地是,為便于描述,本節(jié)中的飛行分段、動作集合及視線角速度分段是以某防空導彈為背景的實例化設計,在方法推廣過程中需結(jié)合應用對象的特性對飛行分段等進行適應性調(diào)整,后續(xù)章節(jié)中的具體分段劃分及參數(shù)設計也需結(jié)合應用對象的特征進行調(diào)整。
2.2 策略評估及求解
2.2.1 狀態(tài)動作值函數(shù)計算
強化學習使用狀態(tài)動作值函數(shù)來評估策略的優(yōu)劣。狀態(tài)動作值函數(shù)用Q(Sts,Nts)表示,表征在狀態(tài)Sts條件下,導航比采用Nts所取得的平均積累獎勵。Q(Sts,Nts)值越大,表明策略越好。
本文利用折扣積累獎賞γ計算不同狀態(tài)- 動作對的平均積累獎勵,以此近似估計狀態(tài)動作值函數(shù)Q(Sts,Nts)。算法實現(xiàn)過程如圖8所示。圖8中,Rmd(Sts,Nts)表示在Sts狀態(tài)時,導航比采用Nts所獲得的脫靶量獎賞,γ為折扣系數(shù),在本文的實現(xiàn)中,令γ=0.5。
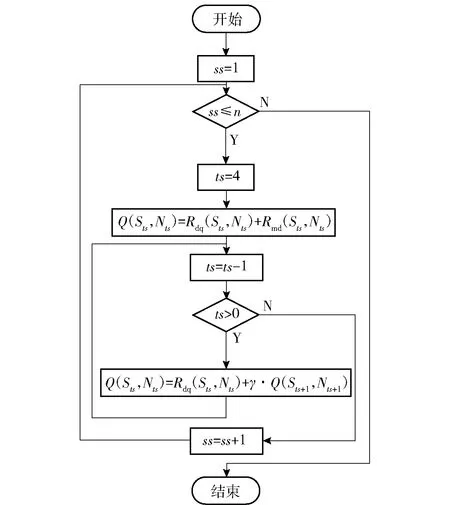
圖8 狀態(tài)動作值函數(shù)算法流程圖Fig.8 Flow chart of state-action value function algorithm
2.2.2 逐段求解最優(yōu)導航比
在算法的實際操作中,本文結(jié)合導彈制導這一特殊問題,本文設計了一種逐段求取最佳導航比的方法,具體方法如下:
1)將飛行段1、2和3的導航比設定為2~6之間的隨機值,通過大量不同彈道,分別計算在飛行段4中不同導航比對應的平均積累獎勵R4,其中R4最大時對應的導航比為飛行段4的最佳導航比N4;
2)將飛行段4的導航比設置為最佳導航比,飛行段1和2的導航比設定為2~6之間的隨機值,過大量不同彈道,分別計算在飛行段3中不同導航比對應的平均積累獎勵R3,其中R3最大時對應的導航比為飛行段3的最佳導航比N3;
3)按照同樣的方法獲取飛行段2和飛行段1的最佳導航比。具體過程如圖9所示。

圖9 導航比逐段求解示意圖Fig.9 Diagram of navigation ratio piecewise solution
3 基于Q-learning強化學習的多狀態(tài)自適應導航比設計
第2節(jié)中,在進行導航比設計過程中,僅考慮了目標的攻擊方式和制導的飛行分段兩個方面的狀態(tài),在實際制導過程中,涉及的飛行狀態(tài)遠不止以上兩方面內(nèi)容。本節(jié)將進一步增加對環(huán)境的狀態(tài)描述,最終目的是設計一種能夠根據(jù)復雜飛行狀態(tài)自適應調(diào)整的導航比,由于狀態(tài)變量的增加,導航比設計過程中需要采集更多的樣本,進行更大數(shù)量級的彈道仿真。為進一步提升學習效率,本節(jié)采用Q-learning算法開展導航比的設計。
3.1 四要素的確定與設計
四要素中的環(huán)境E和動作A的對應關(guān)系與2.1節(jié)的設計一致,此處不再贅述:
1)狀態(tài)S。在本節(jié)中,除了對飛行時間進行分段以外,進一步細化了初始裝定的目標初始裝定速度的大小,將視線角速度狀態(tài)和遭遇時間也作為對環(huán)境的狀態(tài)描述。首先是對狀態(tài)進行離散化分段,本文中對各狀態(tài)的分段方法如圖10所示。圖10中,ts(Sts)、Dqstate(Sts)、Tmzstate(Sts)、vt0state(Sts)分別表示在狀態(tài)Sts條件下離散化的飛行時間、視線角速度、預計遭遇時間和目標初始速度的分段值。
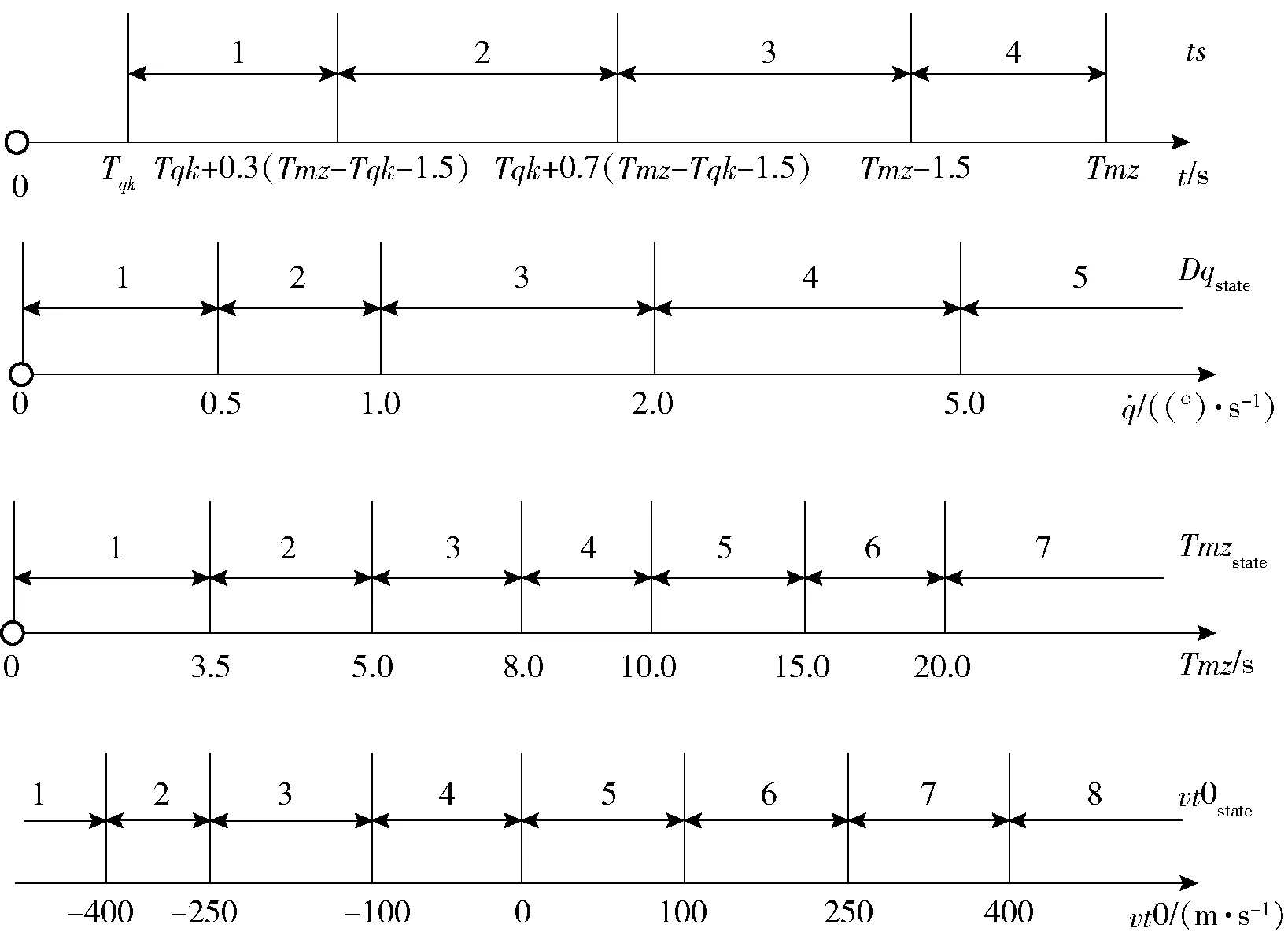
圖10 制導狀態(tài)分段Fig.10 Diagram of guidance state segments
2)獎賞R。由于狀態(tài)的細分,必須對獎勵算法進行相應的細分,否則難以在同一狀態(tài)下有效區(qū)分不同策略的優(yōu)劣。
視線角速度獎賞策略為
(6)
脫靶量獎賞策略為
Rmd=8e-0.47md-5
(7)
式中:md為最終的脫靶量。
脫靶量獎賞值隨脫靶量的大小的變化關(guān)系如圖11所示。
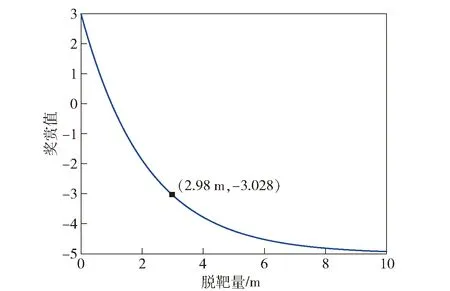
圖11 脫靶量獎賞函數(shù)曲線Fig.11 Curve of miss distance reward function
3.2 策略評估算法
采用Q-learning強化學習算法進行策略評估,具體算法如圖12所示。
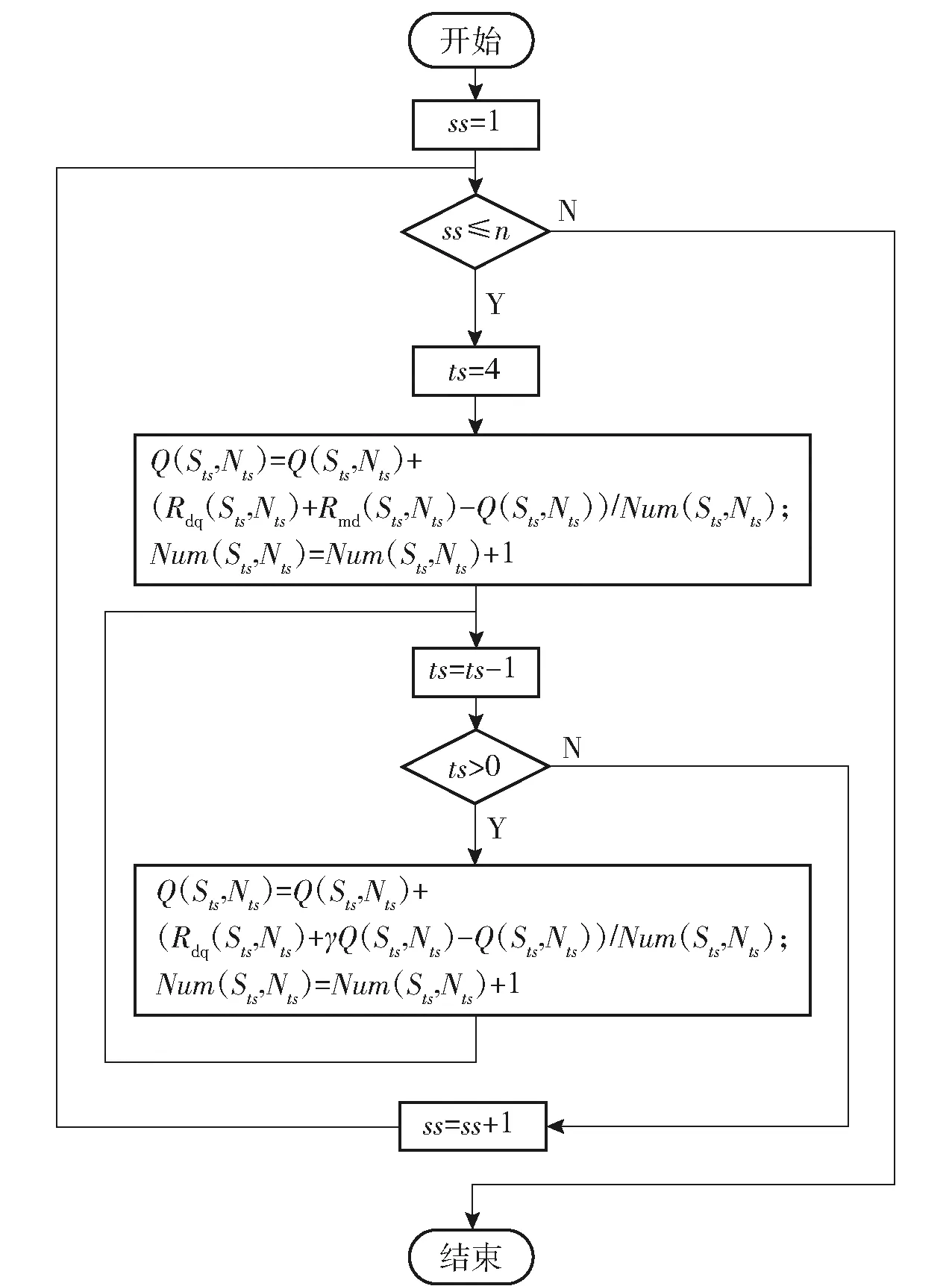
圖12 策略評估算法流程圖Fig.12 Flow chart of strategy evaluation algorithm
圖12中:Q(Sts,Nts)表示在Sts狀態(tài)時,導航比采用Nts所獲得的平均積累獎勵;Num(Sts,Nts)表示狀態(tài)Sts和動作Nts所發(fā)生的次數(shù);N′為基于平均概率分布的隨機導航比取值,且滿足N′∈[2∶0.2∶6]。
4 仿真對比
基于某型防空導彈,分別利用蒙特卡洛和Q-learning強化學習開展導航比設計,蒙特卡洛強化學習設計結(jié)果如表1所示。
通過以上設計結(jié)果可知,蒙特卡洛強化學習方法設計實現(xiàn)的導航比算法簡單,工程易用性強。
根據(jù)Q-learning強化學習最終獲得的導航比與狀態(tài)集合一一對應,限于篇幅,本文未列出具體的參數(shù)結(jié)果。
本文通過從批量彈道中,任意抽取一定數(shù)目的彈道,利用3種導航比設計方法開展數(shù)字彈道仿真計算,對比不同設計方法下的脫靶量分布情況。
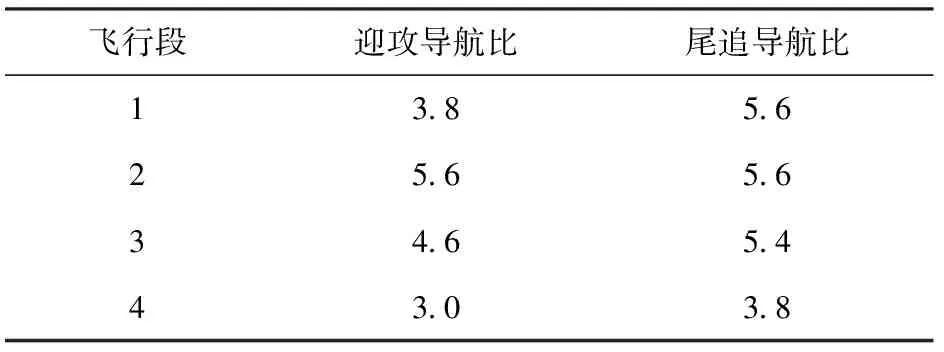
表1 導航比策略表Table 1 Navigation ratio strategies
3種設計方法依次為傳統(tǒng)經(jīng)驗設計比例導引規(guī)律(APN)、利用蒙特卡洛強化學習設計的比例導引規(guī)律(MTPN)和利用Q-learning強化學習設計的比例導引規(guī)律(QLPN),其中APN的設計結(jié)果涉及到裝備技術(shù)狀態(tài),此處不進行描述。
為避免單次抽取可能存在的偶然性,本文開展了彈道抽樣,分別統(tǒng)計每次抽樣彈道的脫靶量情況。第1次抽取是從4 789條彈道(受制于篇幅限制,彈道不一一列出)中,每間隔17條彈道抽取一條,共計282條彈道,第2次抽取是從4 789條彈道中,每間隔13條彈道抽取一條,共計369條彈道。選取兩個質(zhì)數(shù)(17和13)進行等間隔抽取,可使得兩次彈道抽取的重復率較低。
兩次基于脫靶量md的彈道計數(shù)統(tǒng)計結(jié)果分別如表2和表3所示。

表2 第1次不同脫靶量下的彈道計數(shù)Table 2 Trajectory number under different miss distances in the first simulation

表3 第2次不同脫靶量下的彈道計數(shù)Table 3 Trajectory number under different miss distances in the second simulation
以其中一條彈道為例,對比3種狀態(tài)下的視線角速度變化曲線如圖13所示。
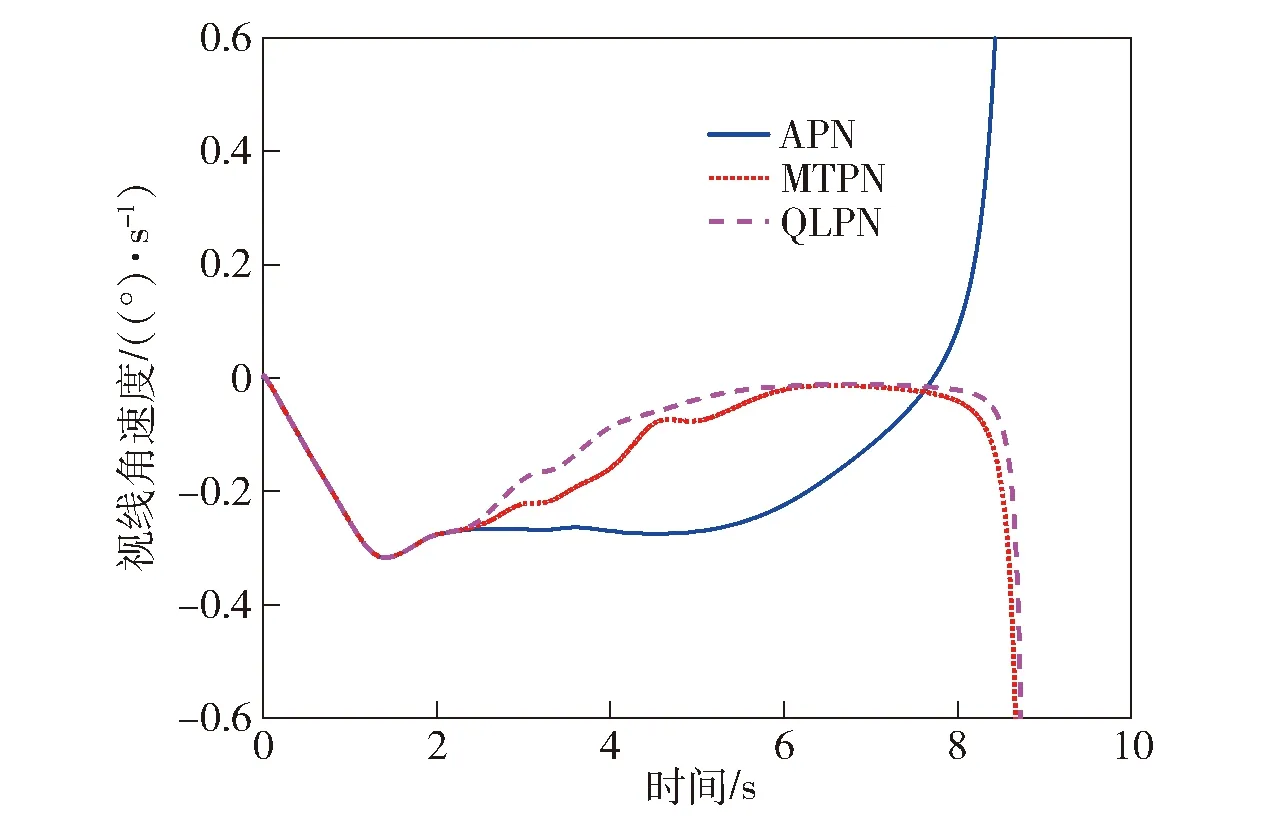
圖13 視線角速度對比曲線Fig.13 Line-of-sight rate comparison
從脫靶量的統(tǒng)計結(jié)果可知,MTPN比APN在制導過程中具有較為明顯的優(yōu)勢,能夠有效提升導彈制導精度;而QLPN由于使用了更多的狀態(tài)對環(huán)境進行描述,比MTPN在減小脫靶量方面有進一步提升;從視線角速度曲線對比來看,MTPN和QLPN比APN的視線角速度收斂更快,且在末端發(fā)散更晚,同時QLPN略優(yōu)于MTPN。
5 結(jié)論
本文在比例導引的基礎上,提出了利用強化學習方法開展導航比設計的思路,通過大數(shù)據(jù)統(tǒng)計與決策替代傳統(tǒng)的經(jīng)驗設計。在此基礎上分別采用蒙特卡洛強化學習方法和Q-learning強化學習方法開展了導航比的設計與仿真對比驗證。得出以下主要結(jié)論:
1)利用蒙特卡洛強化學習的設計方法僅考慮極少的飛行要素,對信息測量的維度和精度要求與工程在用的比例導引規(guī)律完全一致,因此具有算法簡單,工程應用性強的突出優(yōu)點,同時在制導精度上相比傳統(tǒng)的制導律設計具有顯著的提升。
2)利用Q-learning強化學習的設計方法考慮了更多的飛行要素,相比于蒙特卡洛強化學習的方法具有更好的制導性能。但描述環(huán)境的狀態(tài)越多,相應的狀態(tài)維度就越高,在工程應用中,可根據(jù)復雜度的考慮,對描述環(huán)境的狀態(tài)進行刪減。
在工程實踐中,導引規(guī)律的設計還受到一些現(xiàn)實條件的約束,例如雷達導引頭視線角速度精度隨距離的增加而降低,因此在遠距時需限制導航比的取值。本文設計初衷是實現(xiàn)工程化,后續(xù)將近一步考慮各種實際約束,實現(xiàn)算法的工程應用與推廣。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
現(xiàn)代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
中學生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
藝術(shù)啟蒙(2018年7期)2018-08-23 09:14:18
數(shù)學大世界(2018年1期)2018-04-12 05:39:14
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
