水電廠跨區數據融合安全策略及方法研究
2022-12-26 08:26:32張洪濤張軍華宋美艷張會軍仝亮張冰
中國農村水利水電 2022年12期
關鍵詞:融合
張洪濤,張軍華,宋美艷,張會軍,仝亮,張冰
(1.華能瀾滄江水電股份有限公司,云南昆明 650214;2.南京南瑞繼保工程技術有限公司,江蘇南京 211002;3.西安熱工研究院有限公司,陜西西安 710054)
0 引言
水電廠多采用非線性傳感器輸出,加上現場環境溫度、濕度、電源波動等因素,存在很大的輸出信號波動,監測困難,難以及時反映被測物理量。而且機組受到不穩定和不精準數據影響,容易出現停機故障,經常進入檢修狀態。隨著水電廠規模不斷擴大,需要的工業技術也在不斷更新,水電廠控制系統日趨復雜,這對水電廠生產過程控制系統提出了更高的技術要求。由于系統無需對每一個生產環節在精準時間上進行控制,從而使模糊邏輯控制能夠應用于生產過程。將控制系統中熟練的操作經驗轉化為模糊規則,使用該方法之前,系統的維護狀態完全取決于現場人員的調試,在許多情況下,沒有得到適當的維護或維修。為此,對跨區數據安全融合是具有必要性的。陳泗貞等[1]使用了一種在COMTRADE 模型支持下應用的多源故障數據融合方法,利用集對分析理論,分析多源故障數據,并整合相同故障事件數據。以COMTRADE 文件格式為基礎,結合BF 算法對齊故障事件整合時間,實現數據融合;田明明等[2]提出了一種在復雜環境下,利用多傳感器融合數據的方法,該方法通過使用多傳感器采集故障數據,通過當前節點傳輸程度,引入支持度來修正傳輸信任度,并在數據融合階段,不斷重復上述過程,直到融合收斂為止,完成數據融合。盡管上述兩種方法能夠融合數據,但不能保證數據融合的安全性。為解決該問題,提出了水電廠跨區數據融合安全策略及方法。
1 水電廠跨區多元異構冗余數據濾波處理
在實際跨區數據傳輸環境中,傳感器節點受到輸電線路的電磁影響,信號在傳輸過程中受到噪聲干擾,導致數據傳輸質量較低。當相同類型的多個傳感器不斷地監視相同的設備狀態時,產生大量冗余數據。在數據傳輸過程中,海量冗余數據的傳輸,浪費了通信網絡的帶寬資源,甚至導致網絡擁塞。被噪聲干擾的監測數據傳送到控制中心,也會對設備狀態的準確評價產生不可忽視的影響。在電力設備多源數據中,存在著數據冗余和“真假”值篩選的矛盾。根據電力設備多源數據的特點和存在的問題,提出一種事件驅動的多源冗余數據融合方法[3],降低了節點間通信量的冗余數據傳輸,提高區域間多個異構數據融合的效率。
1.1 基于需求協方差的干擾事件判定
選擇需求協方差來描述融合誤差與事件之間的關系,由于更新值與真實值之間的差異,需求協方差是穩定的,所以干擾事件判定策略由需求協方差定義。其基本思想如下所示:

式中:給定的協方差閾值β是一個重要參數,其決定了在t時刻節點i與其他節點之間的通信頻率。該參數的選擇也與判定環境有關,如果未觸發干擾事件,則=0,說明在t時刻節點i不與其他節點之間通信,也就不會進行跨區數據交換;如果觸發干擾事件,則=1,說明在t時刻節點i與其他節點之間通信,需要進行跨區數據交換。
1.2 基于事件驅動的濾波處理
為了減少冗余事件的傳輸,結合基于需求協方差的干擾事件判定策略,提出了基于事件驅動的濾波處理流程,主要有四個步驟:目標狀態監測、事件監測、融合和狀態估計。
首先,在每次濾波循環期間,更新鄰節點估計值,公式為:

然后,事件監聽器策略就會根據事件來判斷事件是否發生,如果發生了,則為鄰居節點范圍內的節點數據通信交換和鄰居節點范圍通信;若未出現最佳融合誤差,借助卡爾曼濾波算法處理相關數據,無需與鄰居節點通信,減少冗余數據的傳輸[4]。
最后,在t時刻節點i的測量值和相鄰節點間通信的估計值基礎上,通過公式(4)得到節點最優估計值。
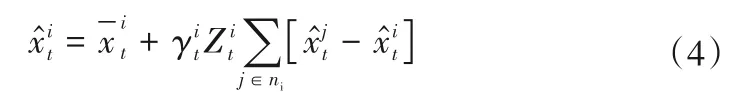
2 基于改進粗糙集的水電廠跨區安全數據融合
根據上述獲取的節點最優估計值,利用改進粗糙集搜索待融合數據,并使用物化視圖和觸發器捕捉方式,完成水電廠跨區安全數據融合。
2.1 基于改進粗糙集的待融合數據搜索
為縮短數據融合時間,使用雙向同時搜索和協作模式,檢索待融合數據表中的條件屬性,并將其組合,等待再次搜索。基于此,設計的基于改進粗糙集的待融合數據搜索流程,如圖1所示。
由圖1可知,在三維陣列S中,定義條件屬性為Cori,決策屬性為Dori。為了減少數據計算結果冗余度,設計的基于改進粗糙集數據融合流程詳細步驟如下:
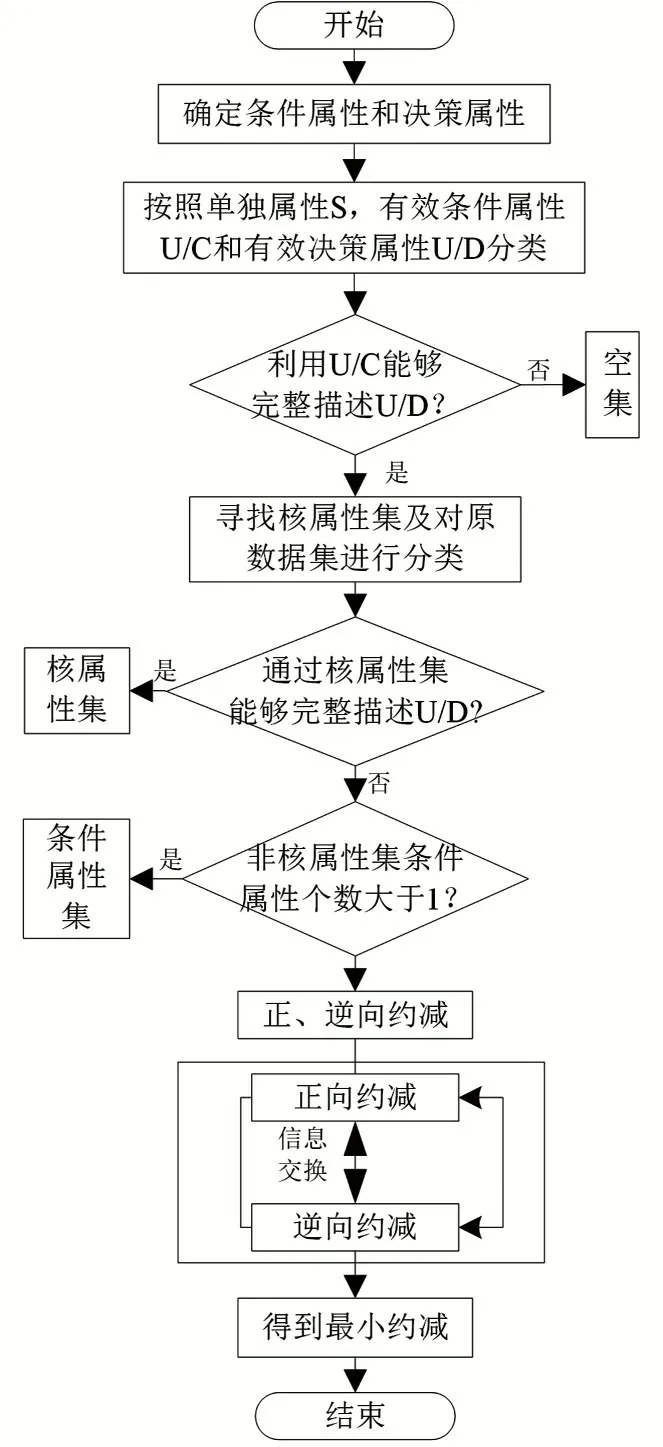
圖1 基于改進粗糙集的待融合數據搜索流程Fig.1 Search process of data to be fused based on improved rough set
步驟1:對一個預處理屬性得到所有不重復的條件屬性集C和決策屬性集D,再用相應編號屬性對S進行分割,得到了U/C和U/D值。用該方法進行U/D交叉運算,如果所得到的運算集合小于原U/C中的非空集,就說明U/C不能正確區分U/D[5]。
步驟2:該組合包含了所有m個非core 條件屬性,而相鄰位置標記f_stop、R_stop 和NEAR_flag,所有m的非核心條件屬性集都被組合起來C'(f_stop 表示正向搜索停止、r_stop 表示逆向搜索停止、near_flag 表示當正向約減的非核實屬性數目和逆向約減的非核實屬性數目鄰近時,標志為1)[6]。
步驟3:從m個非核心條件屬性集中選取一個屬性的組合,可以對m個非核心條件屬性集進行約簡,逐漸增加屬性數量,增加的個數可表示為i_f,并結合屬性進行了分類,確定了分類結果。逆向恢復過程如下:在m個非核心條件屬性集中選取m個屬性的組合,屬性的數量逐漸減少。簡化后的數字可表示為i_r,結合核可判斷分類結果(i_f表示正向約減的非核實屬性數目,i_r表示逆向約減的非核實屬性數目)。
步驟4:當增加的個數組合和減少的個數組合不相鄰時,near_flag值為0,并保持不變,約減步驟為:
步驟4.1:如果在過程中可以區分U/D屬性組合,則逆向還原停止標志不為1 時,當前反推器的未校驗屬性數目和組合的編號位置應及時記錄,然后進入下一個周期組合;
步驟4.2:當逆向約減時,如果對當前逆向約減的非核屬性數目和逆向搜索停止屬性數目進行遍歷組合后找不到可以區分U/D的屬性組合時,當前逆向約減標記被設為1時,暫停當前逆向約減法;
步驟4.3:逆向恢復停止標志為1 時,如果恢復期間出現可區分U/D的屬性組合,目前的正向壓縮過程應該立即暫停,并且記錄未驗證的屬性的當前正向壓縮的數量以及相應的組合數目no_f。與此同時,逆向約減停止標志為1,以停止逆向約減過程。(no_f表示正向搜索屬性下的驗證組合編號)[7]。
步驟5:當增加的個數組合和減少的個數組合相鄰時,near_flag值為1,并保持不變,約減步驟為:
步驟5.1:在逆向恢復期間,r_stop 停止標志為0,正向恢復停止標志為1。在該期間,如果出現屬性組合U/D 時,就應立刻記錄該組合,并向R_RED集合中添加相關屬性。延續目前的逆向恢復過程,直到遍歷全部屬性,或者r_stop 停止標志變為1 為止(R_RED表示存放逆向約減過程中搜索到的非空集合);
步驟5.2:在遍歷之后,R_RED 不是空集,需判斷逆向約減等待過程標志是否為1。如果等待過程標志為1,說明在正向約減過程中,缺少相關屬性添加到R_RED 集合中,此時,f_stop 被設置為1,而這個集合就是非空集合。r_stop停止標志為1,則應立刻停止逆向約減,直到出現符合條件的組合為止;如果等待過程標志為0,說明正向約減過程中出現了屬性組合,并添加到R_RED集合中,此時逆向約減過程逐漸向正向約減過程過渡。
步驟5.3:在逆向約減過程中,如果r_stop停止標志是0而不是1時,遍歷全部屬性組合后,仍然無法獲取能夠區分U/D屬性的組合,應減少屬性組合編號。這樣,在最后一次搜索之后,重新記錄逆向約減過程中的所有編號,此時的f_stop標志為1。
步驟5.4:在重新編號后,判斷逆向約減過程中r_stop 停止標志,如果該標志為0,則說明正在進行正向約減過程,而正向約減過程的r_stop 停止標志為1 時,說明完成了約減過程,并未發現最小約減。如果r_stop停止標志為1,則說明正在進行逆向恢復過程,立刻記錄i_r 和no_r 編號(no_r 表示逆向搜索屬性下的驗證組合編號);
步驟5.5:如果可以完全區分U/D 屬性的組合,并且停止標志f_stop 不是1,那么它就可以被完全區分,如果可以完全區分U/D 屬性的組合,并且停止標志f_stop 不是1,那么它就可以被完全區分,
步驟5.6:如果遍歷當前條件屬性組合,沒有發現完全區分U/D的屬性,則保證約減標記f_stop 不是1,就可以將等待標志設置為1,由此完成基于改進粗糙集的待融合數據搜索[8]。
2.2 跨區數據安全融合
在搜索到基于改進粗糙集的待融合數據后,構建水電廠跨區數據安全融合體系,如圖2所示。
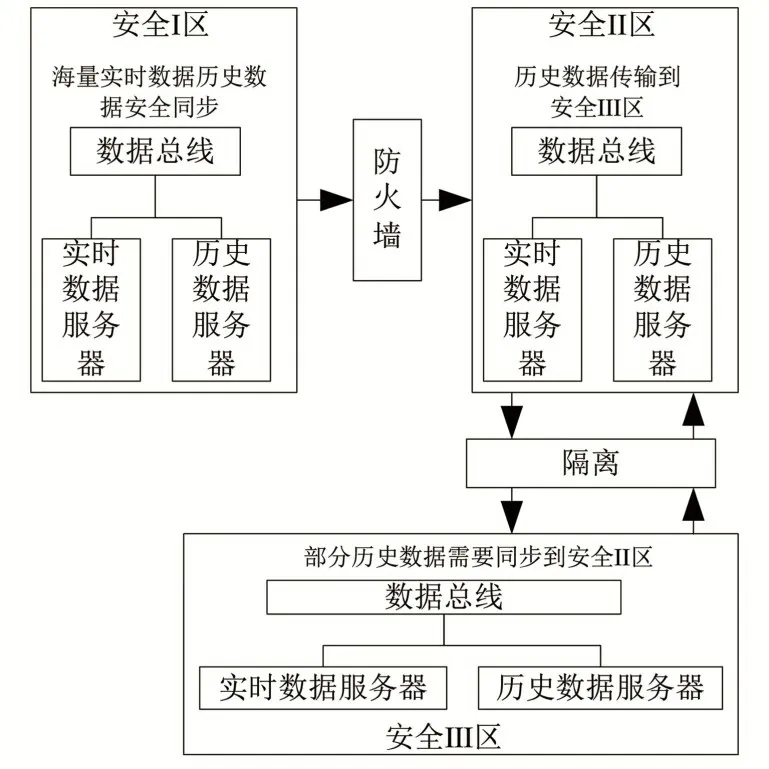
圖2 水電廠跨區數據安全融合體系Fig.2 Cross-district data fusion system in hydropower plants
由圖2可知,水電廠跨區除了需要實時傳輸海量數據之外,還需在水電廠安全Ⅰ、Ⅱ、Ⅲ區之間同步傳輸頻率較低、數據一致性高的歷史數據。尤其是Ⅲ區,對于歷史數據中的綜合業務數據極為敏感,該方法要求數據具有高度一致性,且不能出現數據丟失現象,為此,需要使用比使用總線實時傳輸數據更加可靠的安全傳輸方式,即在保證跨區數據安全融合前提下再進行數據傳輸。
2.2.1 基于物化視圖的安全I、Ⅱ區數據安全融合策略
智能水電廠安全I、Ⅱ區之間有防火墻,通過安全I 區歷史數據庫服務器節點與安全Ⅱ區的歷史數據庫服務器節點之間的物理通道,利用物化視圖法實現從I 區安全歷史數據庫到II區歷史數據庫的單向數據同步。通過物化視圖法預測數據存儲結果,這樣在表連接或聚合過程中就可以避免查詢過于耗時問題的出現,并能迅速得到結果,由此能夠形成更加穩定可靠的跨區數據安全融合通道。
構建的基于物化視圖的跨區數據安全融合通道,如圖3所示。
圖3 基于物化視圖的跨區數據安全融合通道Fig.3 Cross-district data security fusion channel based on materialized view
由圖3 可知,利用數據庫物化視圖實現多個區之間數據安全融合,詳細步驟為:
步驟一:為源服務器上現有基礎表創建一個實體化視圖日志,在該日志中存儲有關數據庫軟件自動更新的所有數據;
步驟二:創建目標服務器上的鏡像,當鏡像創建完成時,指定一個區域,這樣就可以在同步刷新過程中確定數據源的位置;
步驟三:對目標服務器執行完整更新,以便與源數據庫中的基表以及目標數據庫中鏡像表內容進行匹配。
步驟四:定期更新源服務器日志,獲取在目標服務器上配置計劃的數據庫任務。通過物化視圖將安全I區歷史數據同步到安全Ⅱ區,以確保數據的可靠性和完整性。但安全Ⅱ區中的歷史數據只能讀取,不能修改。按照預設的時間間隔來及時更新資源任務,并將更新結果記錄到目標服務器映像表中,由此完成跨區數據安全融合操作。
2.2.2 基于觸發器方式捕捉的安全Ⅱ、Ⅲ區數據安全融合策略
安全Ⅱ、Ⅲ區歷史數據庫是物理隔離的,通過使用數據庫觸發模式,可以有效地捕獲數據表中記錄的所有更改內容,并能夠定期地和其他安全區域同步。基于觸發器方式捕捉的數據融合原理,如圖4所示。
由圖4可知,該模式用于捕捉數據的變化,開發安全隔離程序,在Ⅱ、Ⅲ區實現數據融合,詳細步驟為:
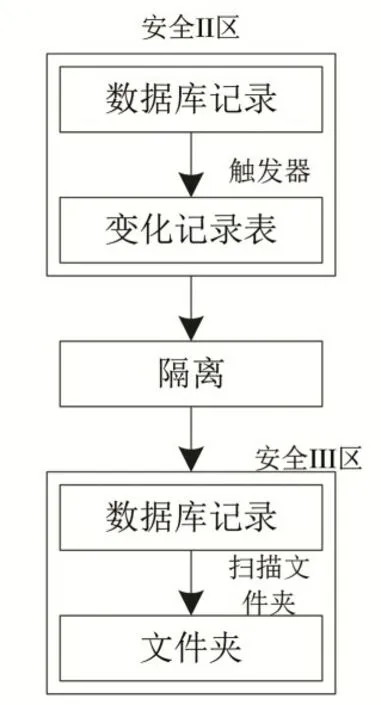
圖4 基于觸發器方式捕捉的數據融合原理Fig.4 Data fusion principle based on flip-flop capture
步驟一:利用單片機平臺的安全隔離軟件組態界面,對安全Ⅱ區數據庫中需要傳輸數據的基表設置觸發器,捕捉該表中添加、刪除、變更操作的數據,并將這些更改保存到I 區臨時數據表中。根據不同應用,選擇傳輸的數據表。安全Ⅱ區數據庫配置的基表中,任何數據的增加、刪除、更改和操作時間都將記錄在臨時數據表中。
步驟二:安全Ⅱ區網關服務器的安全隔離客戶端軟件定期對臨時數據表進行掃描,將數據按指定格式形成文件,存儲在獨立且指定的文件位置。安全性隔離裝置將這些文件傳送到安全Ⅲ區網關的指定文件夾中。與此同時,清除臨時數據表中冗余數據。
步驟三:定時掃描安全Ⅲ區網關指定文件夾,當安全隔離服務器軟件檢測到更新文件后,根據安全Ⅲ區數據庫中的文件內容及時更新,完成數據融合。
3 結語
智能化水電廠集成平臺數據庫是整個系統運行的基礎,數據的一致性和準確性直接影響到各種應用的可靠性。利用跨區域數據融合功能,實現各個安全區數據的實時性、一致性。通過基于物化視圖的跨區數據安全融合通道和觸發器捕捉方式,實現水電廠跨區數據安全融合。該方法對于大數據集尤其有效,而現階段水電行業已積累了大量各類數據,使用該方法能夠獲取更多有意義、有價值的數據,提高水電行業的管理水平。
然而,現有方法仍存在不足,主要是對某一數據集來說搜索速度不夠快。因此,改進應集中在提高搜索能力和自動優化搜索位置方面。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
數學年刊A輯(中文版)(2022年4期)2022-02-16 08:17:34
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
無線電通信技術(2021年4期)2021-07-13 08:58:28
無線電通信技術(2021年3期)2021-06-08 03:33:48
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
福利中國(2015年4期)2015-01-03 08:03:38
