輔助駕駛的車輛與行人檢測模型YOLO-DNF
2022-12-22 11:47:04張修懿陳長興成寬洪
計算機工程與應用 2022年24期
張修懿,陳長興,杜 娟,李 佳,成寬洪
1.空軍工程大學 基礎部,西安 710051
2.西安理工大學 計算機科學與工程學院,西安 710048
目標檢測的任務是找出圖像中所有感興趣的目標并確定它們的位置與類別,其作為無人駕駛技術環境感知模塊的關鍵部分,可在車輛行駛過程中準確并快速地檢測周圍車輛與行人,用于輔助車輛規劃路徑、保障交通安全。該技術目前已成為計算機視覺領域的研究熱點,并在工業生產[1]、醫學影像[2]以及安防監控[3]等領域得到了廣泛的應用。
在目標檢測技術研究的早期常需要手工限定待檢目標的低級視覺特征如方向梯度直方圖[4](histogram of gradient,HoG)或加速穩健特征[5](speeded up robust features,SURF)等,在圖像中通過滑動窗口分區域計算上述特征后使用支持向量機[6](support vector machine,SVM),或可變形部件模型[7](deformable part-based mod‐el,DPM)等技術進行分類。這些傳統算法的檢測精度很大程度上取決于手工限定的特征是否貼切待檢目標及是否受到背景變化的干擾,因此以上算法適合于目標形似、背景固定的目標檢測場景。但車輛行駛中道路環境復雜,車輛與行人多樣,因此這類算法不適合用于車輛行駛環境。
卷積神經網絡(convolutional neural network,CNN)通過大量數據集訓練后,其仿生的多層神經元可以從原始圖像像素中學習待檢目標的深層特征,這些深層特征在復雜環境中有更強的區分表達能力。利用這一優勢,CNN在目標檢測領域取得了顯著的進展。
目前基于CNN的算法主要分為兩大類,兩階段檢測與一階段檢測。R-CNN[8],作為兩階段檢測的開創之作,在第一階段使用選擇性搜索算法提出一系列可能包含目標的感興趣區域(region of interest,RoI),在第二階段中利用CNN提取區域內的深層特征并據此進行分類和定位。針對每一個區域提案分別提取特征并檢測使R-CNN[8]具有較高的檢測精度,但復雜的提議算法和冗余的區域提案使得檢測器效率較低。Fast-RCNN[9]將卷積層位置提前,在每個位置上計算出一組特征向量,通過圖像與特征的位置映射關系使第二階段為每一個感興趣區域提取特征轉為計算其對應位置上的特征向量,降低了第二階段的計算量和計算時間。Faster-RCNN[10]提出區域提案網絡(region proposal network,RPN)以替代選擇性搜索算法,使一部分卷積層直接生成區域提案和區域內檢測特征,簡化了第一階段的計算流程。Fast-RCNN與Faster-RCNN[9]在R-CNN[8]的基礎上分別縮短了第一、第二階段的計算時間,但針對大量冗余的區域提案進行計算不可避免地拉低了檢測效率,為此不適用于車輛駕駛這種對實時性要求較高的檢測場景。
作為一階段檢測算法的代表作,YOLOv3[11]算法首先在圖像上平均劃分出分辨率不同的網格并在其頂點放置大小、形狀不同的錨框,由于這些錨框與CNN提取的特征存在位置映射關系,所以對特征進行預測和回歸就可以得到錨框中的目標類別以及位置。YOLOv3[11]算法以固定數量的錨框代替二階段算法中無定量且大量冗余的區域提案,大幅提升了檢測效率,滿足了車輛駕駛場景下檢測的實時性需求。但由于只在固定位置提取一定數量的特征會造成圖像中信息的遺漏,其檢測精度略低。
為了提高檢測精度,研究人員基于YOLOv3[11]進一步改進、搭建目標檢測模型,例如YOLOv4模型[12]中使用更優秀的CSPDarknet網絡來提升特征提取能力,Scaled-YOLOv4模型[13]通過縮放技術搭建更深的Scaled-CSP網絡也取得了檢測精度的提升。雖然YOLOv4[12]與Scaled-YOLOv4[13]模型都取得了精度的提升,但CNN的復雜化隨之帶來檢測速度變慢和檢測泛化性退化等新問題。更深和更復雜的網絡一方面需要的計算量與參數量更大,造成計算時間增加,檢測速度變慢,因此需要使用更經濟的計算結構。而在另一方面,網絡無根據的加深會引起泛化性的退化[14-15],使檢測難以適用于復雜多變的道路場景,為此需要對數據集進行拓展。
本文針對以上問題,進行了模型結構和數據拓展方面的研究,具體如下:
(1)針對復雜網絡計算量較大造成檢測速度慢的問題提出了Arrow-Block結構,與CSP-Block共同組建模型主干網絡,并通過分析結構學習能力和計算成本調整合適的網絡深度。
(2)針對模型泛化性不足難以擬合復雜的道路環境的問題使用HSV擾動和亮度增強的數據拓展方法提升模型泛化性能。
1 相關工作
1.1 YOLOv3檢測算法
車輛行駛過程中速度快,對目標檢測的實時性要求較高。由于一階段檢測算法YOLO系列根據卷積運算的位置不變特性只使用一次網絡計算就能完成對整張圖像進行檢測,相較二階段檢測算法具有速度快、計算量小的優點,鑒于此本文基于YOLOv3[11]檢測算法進行研究。YOLOv3[11]是該系列的代表作,其結構被分為主干網絡(BackBone)、特征融合層(Neck)和檢測頭(Head)三個部分。分別起到提取特征、融合特征和將特征轉為輸出信息的作用,算法結構如圖1所示。
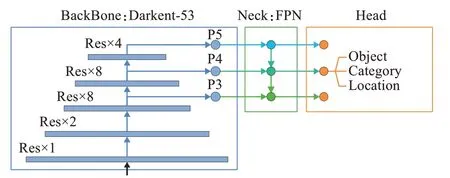
圖1 YOLOv3算法結構圖Fig.1 Schematic diagram of YOLOv3 algorithm structure
YOLOv3[11]的主干網絡使用了Darknet-53網絡。Darknet-53網絡利用五組Res-Block從網絡中遞進提取五組深度不同的特征P1~P5。Res-Block是Darknet-53[11]網絡中提取圖像特征的關鍵,每一組都由不同的數量的Res-Layer重復堆疊而成,依次為1-2-8-8-4。
YOLOv3[11]的特征融合層使用了特征金字塔(feature pyramid network,FPN)結構,FPN融合了Darknet-53網絡提取出的后3組特征進行,其中特征P5經過卷積組降維、上采樣后與特征P4拼接Concat融合成新的特征,重復向上便能夠將特征P4、P5融入特征P3。
YOLOv3[11]的檢測頭部分通過三個卷積層將網絡提取到的特征通過卷積輸出為前后景分類、目標類別分類和位置回歸數據。
鑒于YOLOv3[11]性能優良和結構清晰,本文以其為基礎框架進行優化。提出低計算成本、高特征提取能力的ACNet作為模型的主干網絡,具體細節及設計思路于2.1節展開。
1.2 數據集與數據增強
CNN的學習建立在數據之上,數據分布影響著網絡的學習方向和最終的學習成果,因此需要根據應用場景選擇合適的數據集。訓練和測試車輛與行人檢測模型常采用KITTI[16]和SODA10M數據集[17],其圖像均在車輛上以固定的視角進行采集,因此相較于其他公開數據集更加貼切實際的駕駛場景。KITTI數據集[16]類別涵蓋汽車、貨車、行人,圖像拍攝于白天的德國卡爾斯魯厄市市區,數據多樣性較低,對于車輛駕駛的實際檢測需求而言研究價值不強。SODA10M數據集[17]類別涵蓋行人、自行車、汽車、卡車、公交車、三輪車,訓練集圖像僅拍攝于白天的上海市市區,而測試集覆蓋了夜間的其他城市,道路環境包括鄉村和高速公路。具體分布如表1所示。
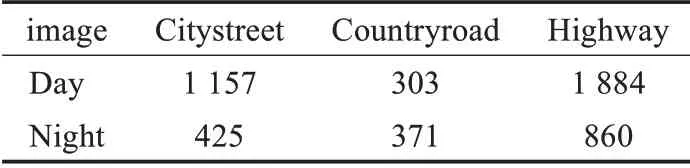
表1 測試集圖像分布Table 1 Testset image distribution
雖然模型使用SODA10M數據集[17]訓練會難以擬合測試集多樣的圖像分布,但也正因為訓練集的數據多樣性小于測試集而更貼切實際工程中有限的數據集無法包含無限的實際駕駛場景。鑒于此本文選用SODA10M數據集[17]進行模型訓練與測試。
車輛行駛的道路復雜多樣,雖然車輛和行人在不同道路上的樣本視覺差距較小,但在夜晚和白天不同光照下差距較大。僅使用訓練集進行訓練網絡會在夜晚檢測精度較低,難以滿足夜間車輛駕駛的檢測需要。數據增強是訓練CNN的常用策略,可以幫助擴展數據的多樣性,增強網絡的泛化性并避免網絡學習至局部損失最小值[18]。HSV域擾動[19]通過在訓練中以50%的概率隨機改變圖像的色相、飽和度、對比度以及亮度拓展訓練集圖像的色彩分布,使得對圖像顏色、亮度變化具有一定的泛化性,擾動效果如圖2所示。

圖2 HSV擾動效果對比圖Fig.2 Comparison of HSV disturbance effect
通過HSV域隨機擾動,每張圖像的色彩和亮度都產生多種變化。雖然數據集的色彩與光照分布得到了擴充,但擾動后的圖像仍與夜晚差距較大,為此本文分析了白天與夜晚圖像亮度的差距,通過在訓練中降低圖像亮度來彌補與實際檢測的差距,具體細節于2.1節展開。
2 模型結構與數據增強
2.1 YOLO-DNF模型結構
YOLO-DNF模型遵循YOLOv3[11]的基礎框架,整體網絡仍分為主干網絡、特征融合層和檢測頭三部分,其中主干網絡使用低計算成本、強特征提取能力的ACNet,特征融合層和檢測頭保持原結構,整體結構如圖3所示。
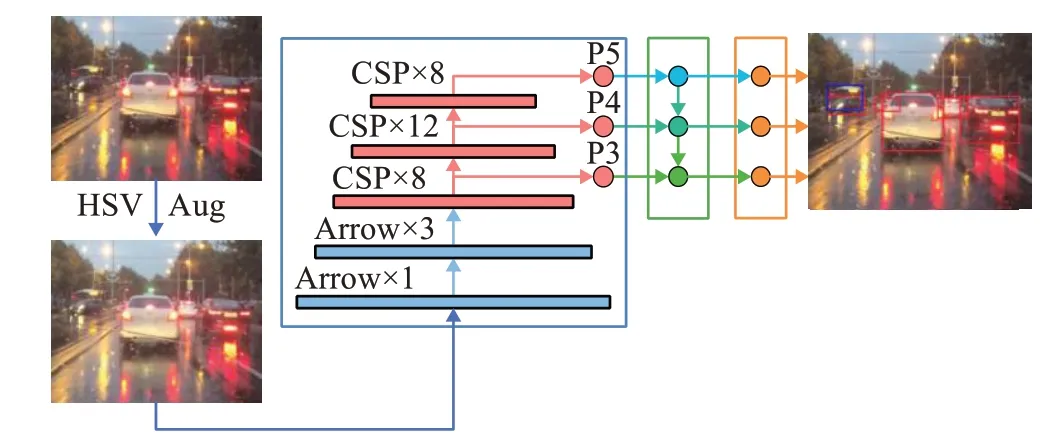
圖3 YOLO-DNF算法結構圖Fig.3 Schematic diagram of YOLO-DNF algorithm structure
在神經網絡中,神經元的連接方式與數量對于其特征學習和提取能力至關重要,而神經元的連接方式與數量反映到目標檢測模型中正是主干網絡中卷積模塊結構以及網絡深度。本文通過分析主流目標檢測模型中主干網絡的結構以及深度提出的具有低成本高特征提取能力的ACNet,其具體結構如表2。
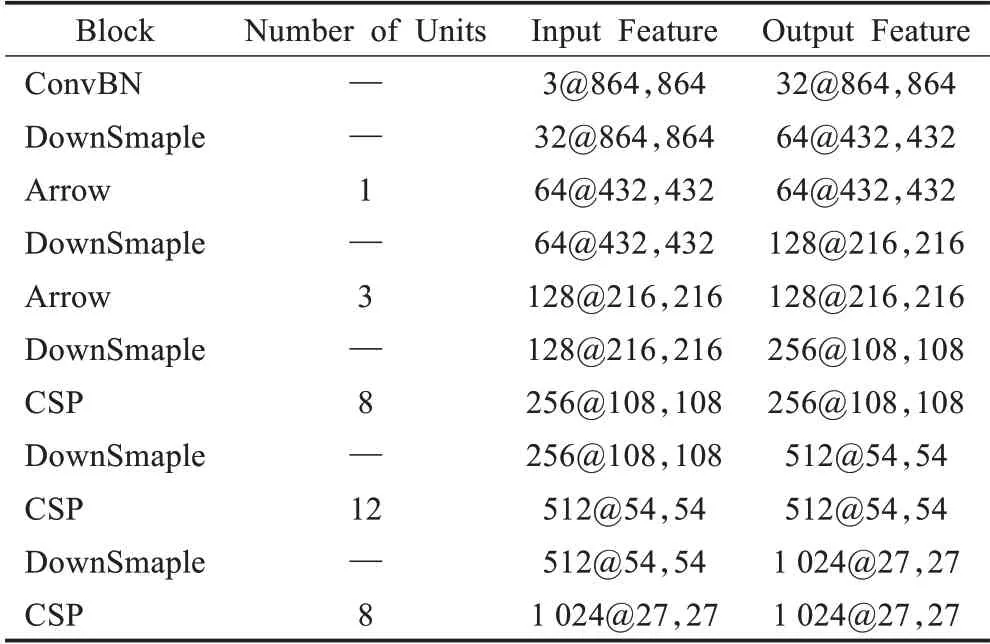
表2 ACNet網絡結構Table 2 ACNet network structure
2.1.1 卷積結構
適用于目標檢測的卷積結構需要考慮特征提取能力與計算成本的問題,本文通過分析該領域中常用的卷積模塊Res-Block以及CSP-Block選擇ACNet中的卷積結構。
卷積模塊Res-Block因獨特的Shortcut傳導方式和卷積維度變化而具有相較普通卷積層更強的特征提取能力。整體模塊由數個基礎單元Res-Layer堆疊連接而成,隨著堆疊單元Res-Layer數量的增加,Res-Block中特征維度變化愈加頻繁,這需要占據更大的內存訪問成本并花費更多的計算時間。
卷積模塊CSP-Block由Arrow-Block以及四個卷積核尺寸為1×1的卷積層組成。在模塊起始處通過兩個降維卷積將特征劃分成兩路,兩路特征的維度皆被降至原始特征的一半。其中一路特征在經過Arrow-Block及卷積計算后與另一路特征作通道拼接,拼接得到的特征經歸一化及非線性激活后作最后一次卷積計算完成融合,卷積融合后的特征作為CSP-Block整體模塊的計算結果輸出。CSP-Block通過特征劃分避免了不斷學習重復的信息,并通過特征融合使得淺層的神經元在反向傳播中直接獲得深層的反饋從而接受更大梯度,因此相較Res-Block具有更強的提取能力,且特征維度變換頻率固定。
Arrow-Block作為卷積模塊CSP-Block的一部分,并未在主流的目標檢測模型中單獨使用過,其結構與Res-Block相似,同樣使用Shortcut連接并由數個基礎單元Arrow-Layer堆疊連接而成,區別僅在于其計算過程中特征維度保持不變,避免數據讀取時維度頻繁變換,因此可以降低內存訪問成本。
Res-Block、Arrow-Block中基礎單元以及CSP-Block的具體結構如圖4所示。
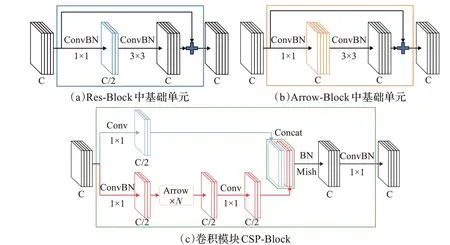
圖4 不同模塊卷積結構示意圖Fig.4 Schematic diagram of convolutional structure in different modules
搭建目標檢測模型的主干網絡時常通過在卷積模塊中使用一定數量的堆疊單元來控制網絡深度,此時卷積模塊的特征提取能力與計算成本同時受到模塊結構與堆疊單元數量的影響。作為計算密集型算法,卷積神經網絡的計算成本包括數據運算與內存訪問兩方面,其中卷積層的數據運算成本可用浮點數運算次數(floatingpoint operations,FLOPs)表示,內存訪問成本可用內存訪問次數(memory access cost,MAC)表示,忽略卷積層中的歸一化與非線性激活,卷積層的FLOPs與MAC的計算如式(1)與式(2)所示:

式(1)與式(2)中h和w代表特征圖的高和寬,C代表特征圖的維度,K代表卷積核大小,角標in和out表明該參數屬于輸入或輸出特征圖,鑒于網絡中卷積層的輸入特征通道數Cin皆大于等于32且為2的高次冪,因此可忽略式(1)中的常數因子1。
卷積模塊Res-Block結構單一,其計算成本為單個基礎單元Res-Layer的計算成本乘以其堆疊單元數量N,結合卷積模塊中卷積層的參數可依據式(1)與(2)得到卷積模塊Res-Block的計算成本式(3)與式(4):
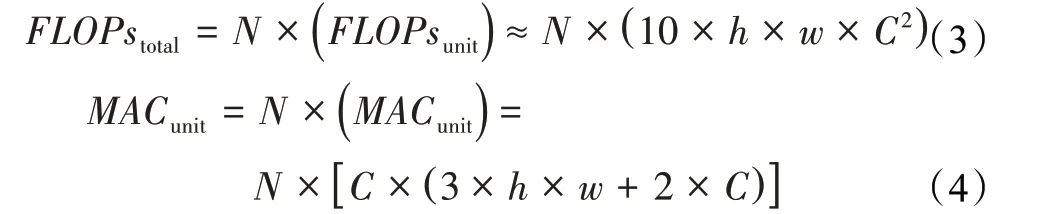
與之不同的是卷積模塊CSP-Block中除了使用了模塊Arrow-Block,還額外使用4個卷積層以劃分與融合特征,因此卷積模塊CSP-Block的計算成本可分為堆疊單元unit部分以及劃分與融合extra部分。結合卷積模塊中卷積層的參數可依據式(1)與式(2)得到卷積模塊CSP-Block的計算成本式(5)與式(6):
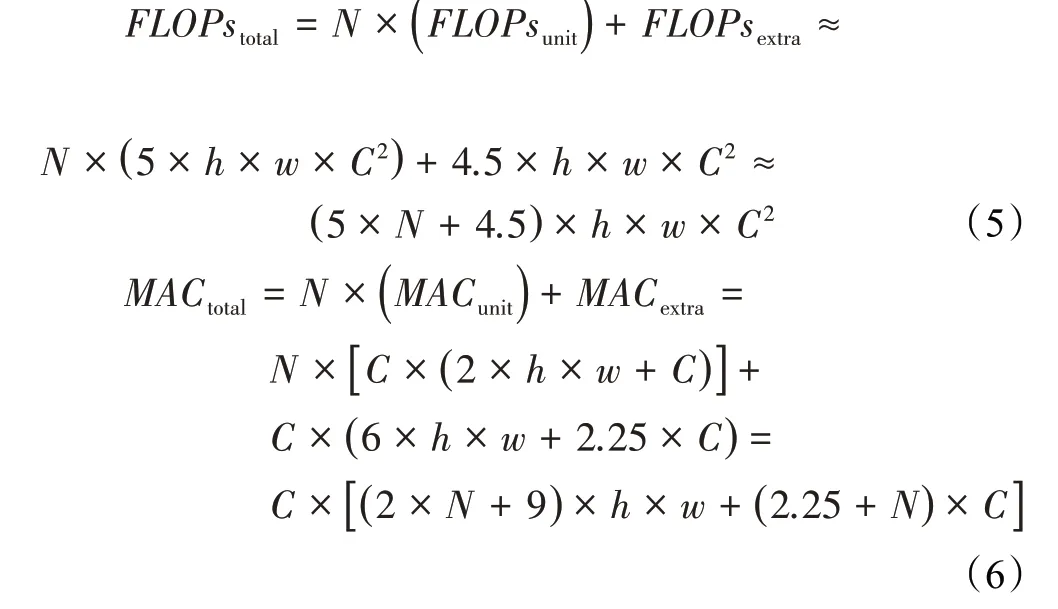
依據式(3)~(6)可以得出在堆疊同樣數量基本單元的情況下卷積模塊CSP-Block與Res-Block針對不同維度、分辨率的特征圖進行卷積計算所消耗的計算成本。為了數據對比清晰易察,本文選取維度與分辨率的中位數組合(256,108)計算卷積模塊CSP-Block與Res-Block的計算成本對比結果得到圖5。
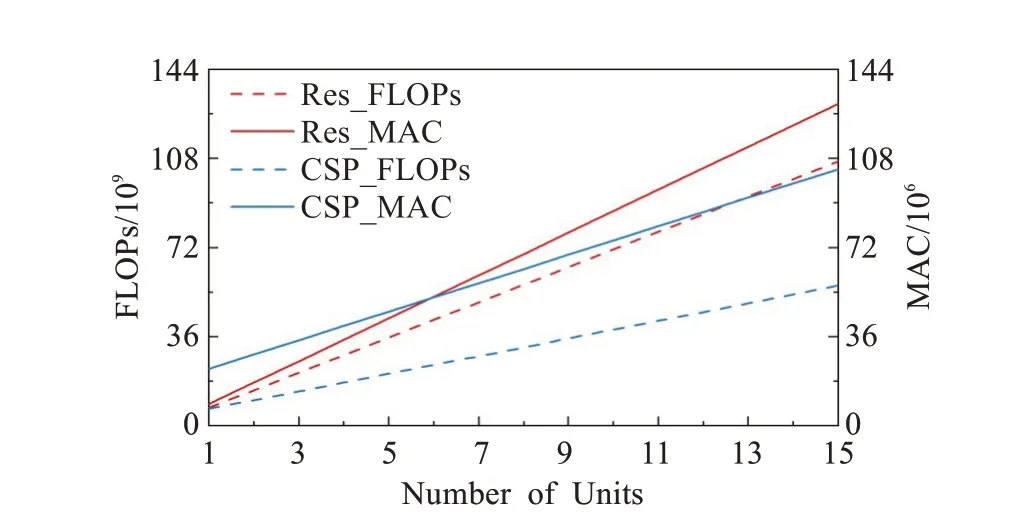
圖5 卷積模塊計算成本對比圖Fig.5 Comparison of calculation cost for convolutional block
如圖5所示,卷積模塊CSP-Block的計算成本低于Res-Block,且當堆疊單元增多時差距更為明顯。這是因為卷積模塊CSP-Block在起始處將特征維度降低一半且在堆疊單元部分計算時特征維度保持不變,因此堆疊同樣數量基本單元時卷積模塊CSP-Block中unit部分的計算成本小于Res-Block。隨著堆疊單元的增加,extra部分的計算成本在整個卷積模塊中占比越來越小,使得整體計算成本的差距增大。又因為劃分與融合機制,卷積模塊CSP-Block相較Res-Block具有更強的特征提取能力,因此CSP-Block模塊能夠以較低的計算成本在堆疊單元較多的區域發揮較強的特征提取能力。
但當堆疊單元較少時,extra部分的計算成本在整體模塊中占比較大,依據式(5)與式(6)可得到隨著堆疊單元增加extra部分所耗計算成本在卷積模塊CSP-Block中占比變化趨勢圖6,其中特征維度與分辨率仍選擇中位數組合(256,108)。
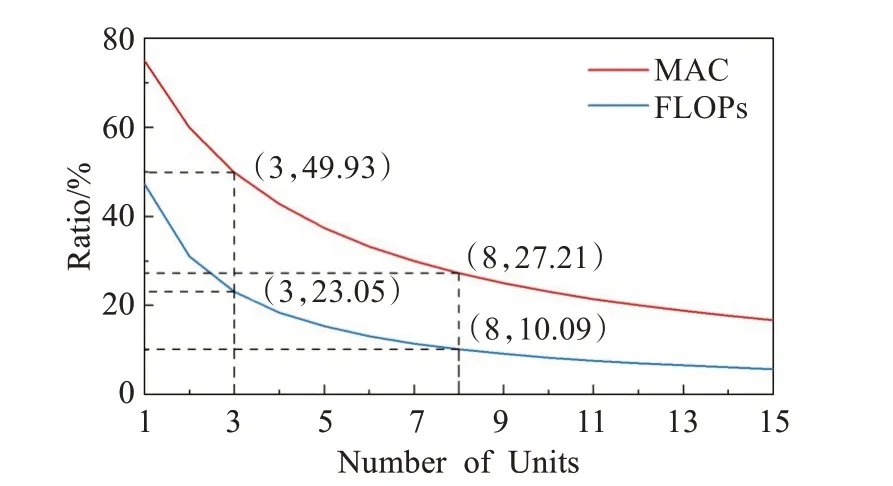
圖6 CSP-Block模塊中extra部分計算成本占比與單元數關系Fig.6 Relationship between ratio of extra component in total calculation cost of CSP-Block and amount of units
如圖6所示,當堆疊單元數為1~3時extra部分數據運算成本FLOPs占據整體卷積模塊CSP-Block的47.33%~23.05%,內存訪問成本MAC更是達到整體卷積模塊的74.94%~49.93%。這意味著當堆疊單元較少時特征與融合機制會消耗卷積模塊中絕大部分的計算成本。但此時各層神經元相距較近,學習的內容類似,且梯度傳遞衰減效應較弱,劃分和融合機制對于CSPBlock模塊的特征提取能力增益較小。即當堆疊單元較少時,CSP-Block模塊相較Arrow-Block模塊在消耗更多的計算成本的條件下特征提取能力的提升極為有限。因此在堆疊單元較少的區域Arrow-Block模塊能夠以犧牲較少特征提取能力為代價大幅減少計算成本。
基于上述考慮,本文提出的ACNet將于堆疊單元數較少處使用Arrow-Block模塊,于較多處使用CSP-Block模塊,Arrow-Block搭配CSP-Block的組合使得網絡保持了較強的特征提取能力和較低的計算成本,此外由于Arrow-Block也是CSP-Block模塊的一部分,因此ACNet網絡的硬件實現方式也較為簡單。
2.1.2 網絡深度
確定ACNet網絡的深度,即確定Arrow-Block模塊與CSP-Block模塊中堆疊單元的數量。當卷積結構相同但深度不同時,主干網絡的特征提取能力以及計算成本都會改變。例如同樣使用CSP-Block模塊的CSP‐Darknet網絡[12]與Scaled-CSP網絡[13],其各自的堆疊單元數量如表3所示。
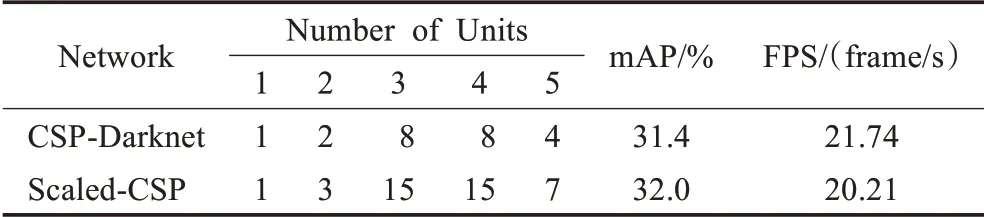
表3 CSP-Darknet與Scaled-CSP網絡深度對比Table 3 Comparison between CSP-Darknet and Scaled-CSP in network depths
通過對比兩種網絡堆疊單元數量可發現:(1)兩種網絡的堆疊單元在P1、P2層都較少,而在P3~P5層較多。(2)兩種網絡的堆疊單元在P1、P2層差距較小,而在P3~P5層較大。(3)網絡更深的Scaled-CSP[13]精度高于CSP-Darknet[12],但檢測速度低于CSP-Darknet[12]。因此ACNet網絡將在P1、P2層以1~3的堆疊單元數量使用Arrow-Block模塊,而在P3~P5層使用CSP-Block模塊,其中P3~P5層CSP-Block模塊內堆疊單元數量通過分析其在不同層的計算成本來決定。
CSP-Block模塊中堆疊單元的計算成本已由式(5)與式(6)中FLOPsunit給出。由于P3~P5層的特征維度從256至1 024以二次冪遞增,且特征圖分辨率由108至27以二次冪遞減可知單個Arrow-Layer單元的數據運算成本FLOPs不受所處位置的影響。而內存訪問成本MAC同時受到分辨率與維度變化的影響,選取式(6)中unit部分計算可得到P3~P5層單個Arrow-Layer單元內存訪問成本MAC的相對百分比變化圖,如圖7所示。
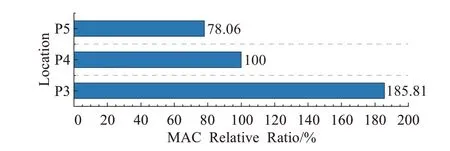
圖7 P3~P5處Arrow-Layer單元MAC相對百分比Fig.7 MAC of Arrow-Layer in P3 to P5
如圖7所示單個Arrow-Layer單元的內存訪問成本MAC隨著特征的深入而降低,這表明ACNet可通過降低P3、P4處堆疊單元數量,增加P5處堆疊單元數量的方法以較低的計算成本實現較高的計算精度,因此ACNet選擇以1-3-8-12-8的單元堆疊數組合搭建網絡。重新計算Darknet-53[11]、CSPDarknet[12]、Scaled-CSP[13]與ACNet網絡整體與逐層的數據運算成本FLOPs和內存訪問成本MAC,計算成本結果如圖8所示。
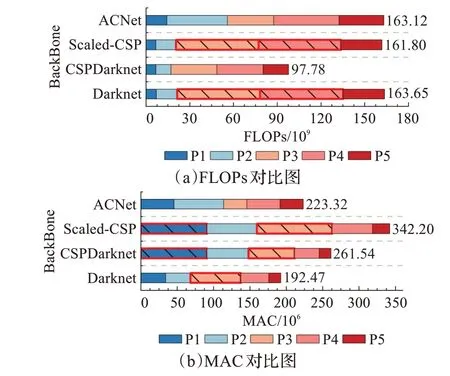
圖8 卷積網絡整體及逐層計算成本對比圖Fig.8 Comparison of different convolutional network overall and layer-by-layer calculation cost
通過對比四種網絡的計算成本可以發現:(1)與Darknet-53[11]及CSPDarknet[12]網絡相比,ACNet在加深網絡的同時通過搭配Arrow-Block與CSP-Block模塊因而并未消耗過多的計算成本,其中數據運算成本小于較淺層網絡Darknet-53[11],而內存訪問成本更是低于CSP‐Darknet[12]網絡。(2)與Scaled-CSP[13]網絡相比,ACNet網絡通過將堆疊單元較少處的卷積模塊替換為Arrow-Block從而實現了內存訪問成本MAC的大幅縮減。(3)與Darknet-53[11]、CSPDarknet[12]及Scaled-CSP[13]相比,ACNet網絡層與層之間數據運算成本FLOPs及內存訪問成本MAC相差較小,并未出現明顯的計算瓶頸(圖8中以紅色邊框及黑色斜杠填充突出標記),避免了因特定層較大計算量阻礙其他層計算而延緩檢測速度。(5)ACNet網絡在P1、P2層數據運算成本FLOPs略高,這是由于Arrow-Block單獨使用時特征維度未經卷積層降低,但由于P1、P2層特征維度處于64、128的較低階段,因此使用完整的維度進行計算并不會造成網絡整體計算成本過高。
通過卷積結構和網絡深度上的設計,ACNet具有低計算成本、高特征提取能力的優勢。為了驗證這一優勢可以帶來實質的性能提升,將ACNet網絡Darknet-53[11]、CSPDarknet[12]、Scaled-CSP[13]以及額外設計的三組網絡進行對比,對比細節可見實驗(1)與實驗(2)。
2.2 HSV域數據增強
道路圖像在夜晚與白天最明顯的差別在于光照,對比分析訓練集與測試集圖像在HSV域中的亮度可知,測試集中所有白天圖像的亮度均值為112.86,與訓練集相等;而黑夜圖像亮度均值為63.66。做出測試集中圖像亮度均值歸一化直方圖進行對比,直方圖如圖9所示。
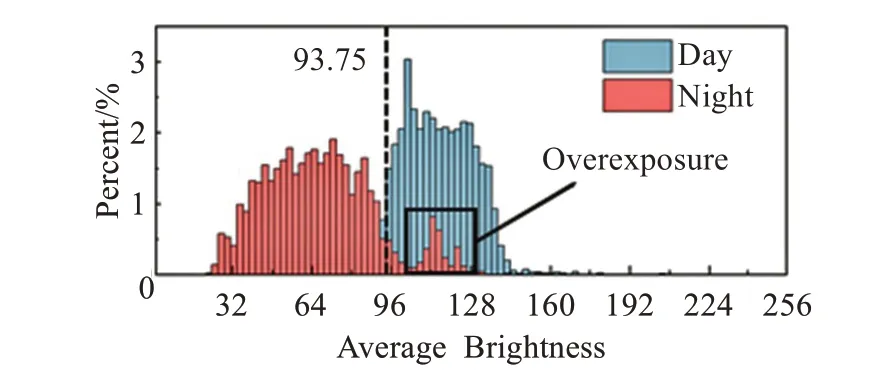
圖9 測試集圖像亮度均值歸一化直方圖Fig.9 Normalized histogram of mean of image brightness in test set
均值直方圖如圖9所示,夜晚與白天圖像亮度均值在93.75處區分最大,即只有8.05%的白天圖像亮度均值小于93.75以及10.38%的夜間圖像亮度均值大于該值。若在訓練時將所有圖像的亮度調整至93.75則可以模擬一個“黃昏”的光照場景,使得訓練集圖像光照分布趨近白天與夜晚之間,進而增強模型對于夜間目標的泛化性。具體而言亮度處理在進行推理前首先通過亮度均值判斷所處光照條件,并將其均值調整至93.75使圖像處于“黃昏”光照場景中。由于在RGB色域中調整亮度需要先計算圖像亮度再調整R、G、B取值,而在HSV域中可直接調整對應亮度,因此為了減少計算過程中精度損耗及亮度計算引起的額外耗時,YOLO-DNF將亮度處理并入HSV域與HSV擾動一同進行,統稱為HSV域數據增強。
除減少白天與夜間圖像的亮度差距以外,HSV域數據增強還可以削弱車燈、路燈光照過強引起的過曝光效應(Overexposure)。從圖9的亮度均值歸一化直方圖中可見,有部分夜間圖像的亮度均值處在105~127.5的區間內,這是由夜間行車時車輛燈光以及道路照明過強所致。拍攝于白天的圖像中下車燈不明顯,較少或者不會有過曝光現象發生,因此在僅含白天圖像的訓練集中訓練后神經網絡學習到的特征多傾向于刻畫完整的車輛或行人;而拍攝于夜間的圖像中車燈的亮度與周圍區域差別極大,車體形狀被車燈及車燈引起的光暈效應破壞,這將導致神經網絡難以擬合夜間的車輛,使得網絡泛化性較差。本文提出的HSV域亮度增強策略將圖像的亮度均值統一至93.75處,使得亮度較強的夜間圖像亮度降低,從而減輕車燈、路燈過曝光對檢測的干擾。HSV域數據增強具體效果如圖10對比所示。

圖10 HSV域數據增強效果對比圖Fig.10 Comparison of HSV domain data enhancement effects
3 實驗
本實驗訓練和驗證均在SODA10M數據集[17]中展開且并未使用其他數據集進行預訓練。實驗設置:每個模型訓練207輪次,每批次訓練4張圖像,圖像分辨率為864×864(為了充分發揮兩階段檢測模型的精度優勢,Faster-RCNN[9]模型遵循SODA10M論文中設置的1 920×1 080分辨率進行訓練與測試),批次學習率為0.000 125,在前10 053步中學習率線性增長,于第166、186輪學習率衰減一倍。訓練中使用SGD優化器,動量和權重衰減為0.9和0.000 5。
實驗硬件環境:CPU使用5核Intel?Xeon?Silver 4210R@2.40 GHz,GPU使用NVIDIA GeForce RTX 3090(顯存24 GB),內存大小24 GB,計算機系統為Ubuntu 18.04。實驗軟件環境:編程語言采用Python,深度學習框架采用PaddlePaddle,軟件計算平臺使用CUDA 11.2及CUDNN 8.0.5。
為了驗證本文提出的YOLO-DNF模型性能優良以及各項改動合理有效,共設置了以下4組實驗以作對比:
(1)僅使用CSP-Block、Arrow-Block卷積模塊搭建兩款主干網絡All_Arrow以及All_CSP,使用與ACNet相反的卷積模塊順序搭建CA(CSP-Arrow)Net網絡。All_Arrow、All_CSP以及CANet三種網絡均與ACNet網絡保持同樣的堆疊單元數量以驗證本文提出的ACNet網絡可在一定程度上平衡計算成本以及特征提取能力。
(2)固定使用FPN作為目標檢測模型的特征融合層以驗證本文所提出的ACNet主干網絡相較Darknet[11]、CSPDarknet[12]及Scaled-CSP[13]網絡具有較低計算成本以及較強的特征提取能力。
(3)將YOLO-DNF模型與經典通用目標檢測模型Faster-RCNN[9]、YOLOV3[11]、YOLOV4[12]、Scaled-YO‐LOv4[13]以及新型車輛與行人專用檢測模型Lite-YO‐LOv3[20]、ResNext50-SSD[21]進行對比以驗證本文所提出的YOLO-DNF模型具有一定的性能優勢。
(4)在實驗(3)中固定每個模型使用的數據增強策略、損失函數、學習率變化等訓練策略相同,每個模型以是否使用HSV域增強為區別分別訓練、測試兩次以驗證本文所提出的HSV域數據增強策略對于模型夜間檢測能力以及泛化性的提升。
實驗對比的指標包括模型檢測精度mAP以及檢測速度FPS。除了在SODA10M[17]的測試集中測試整體精度,額外將SODA10M[17]的測試集劃分成白天與夜間兩個子集并分別測試以驗證模型對于光照變化的泛化性。
3.1 主干網絡實驗
3.1.1 消融實驗
為了驗證本文依據堆疊單元數量選擇并搭配Arrow-Block與CSP-Block兩種卷積模塊所組建的ACNet網絡可在一定程度平衡網絡的計算成本以及特征提取能力,保持P1~P5各層與ACNet相同的堆疊單元數量分別搭建三款主干網絡All_Arrow、All_CSP以及CANet以作比較。其中All_Arrow與All_CSP網絡僅包含卷積模塊Arrow-Block或CSP-Block,CANet與ACNet保持相反的卷積模塊搭配,即在P1~P2層使用CSP-Block并在P3~P5層使用Arrow-Block。四種網絡的對比實驗結果如圖11與表4所示。
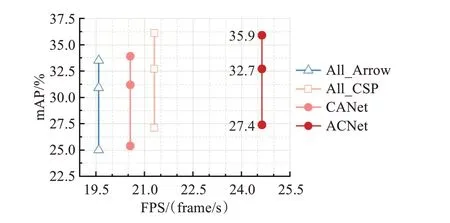
圖11 主干網絡結構消融實驗檢測精度與速度對比圖Fig.11 Comparison of detection accuracy and speed in backbone structure ablation experiment
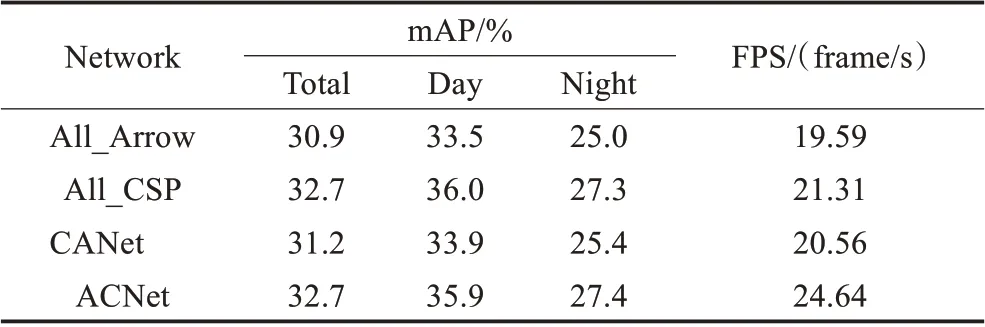
表4 主干網絡結構消融實驗檢測精度與速度對比Table 4 Comparison of detection accuracy and speed in backbone structure ablation experiment
根據對比結果可發現本文所提出的ACNet網絡相較All_Arrow、All_CSP以及CANet三種網絡在檢測精度與速度方面取得了最好的成績。通過網絡All_Arrow、All_CSP與ACNet的對比可發現使用單一卷積模塊搭建而成的網絡無法同時滿足低計算成本與強特征提取能力的要求,而通過搭配Arrow-Block與CSP-Block所組建的ACNet網絡可以使兩種卷積模塊取長補短。值得注意的是All_CSP網絡的總體檢測精度與ACNet保持一致,檢測速度有所降低,其中白天精度略高而夜間精度略低,表明當CSP-Block處于淺層區P1、P2時其劃分與融合的傳導機制在特征提取能力方面收益極低,且會拉升網絡計算成本,減緩檢測速度。CANet與ACNet網絡的對比則表明Arrow-Block適合用在堆疊單元較少的淺層區P1、P2且CSP-Block適合用在堆疊單元較多的深層區P3~P5。需要再次說明的是在網絡All_Arrow以及CANet中深層區P3~P5使用的Arrow-Block模塊并未對輸入特征進行降維,此時256至1 024的高維度卷積計算會消耗大量的計算成本,造成檢測速度的大幅下降。
3.1.2 對比實驗
為了驗證本文所提出ACNet網絡具有低成本、高特征提取能力的優勢,固定卷積模型中除主干網絡以外的其他 部 分,分 別 使 用Darknet[11]、CSPDarknet[12]、Scaled-CSP[13]及ACNet作為模型主干網絡進行訓練和測試。實驗結果如圖12與表5所示。
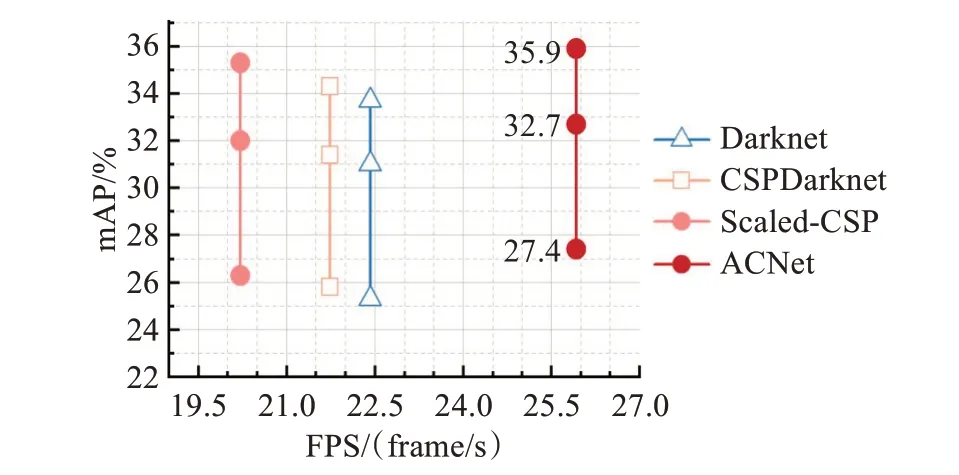
圖12 使用不同主干網絡的模型檢測精度與速度對比圖Fig.12 Comparison of model detection accuracy and speed using different backbone
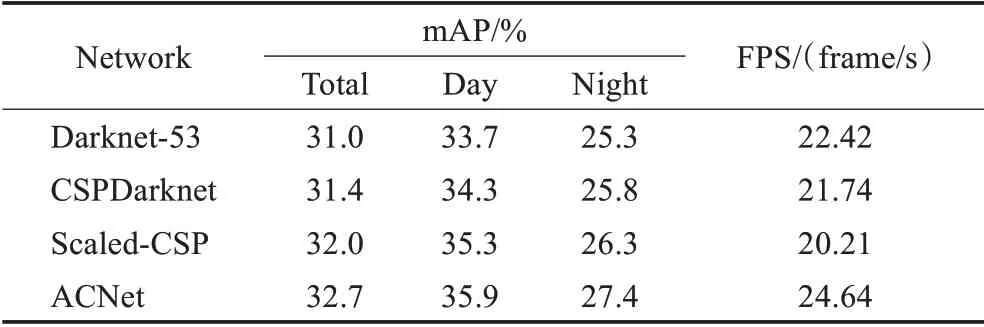
表5 使用不同主干網絡的模型檢測精度與速度對比Table 5 Comparison of model detection accuracy and speed using different backbone
根據對比結果可發現本文提出的ACNet在精度與速度兩方面均取得了最好成績,表明了通過分析卷積結構的特征提取能力與計算成本設計出的ACNet主干網絡具有較強的學習能力以及較低的計算成本。各主干網絡的檢測效果視覺對比如圖13所示。

圖13 使用不同主干網絡的檢測效果圖Fig.13 Results of detection using various backbone networks
3.2 檢測模型對比實驗
為了驗證本文所出提的YOLO-DNF模型在目標檢測技術研究快速發展的當下新穎且有效,將YOLO-DNF模型與四種流行的通用目標檢測模型Faster-RCNN[10]、YOLOv3[11]、YOLOv4[12]、Scaled-YOLOv4[13]以及兩種新型車輛與行人專用檢測模型Lite-YOLOv3[20]、ResNext50-SSD[21]進行對比比較。
為了驗證本文所提出的HSV域數據增強策略可以改善模型夜間檢測能力,提升模型對于亮度變化的泛化性,所有模型在訓練時保持數據增強策略、損失函數、學習率變化等訓練策略一致,并以是否使用HSV域增強策略為區別分別訓練、測試兩次。比較結果如圖14與表6所示。
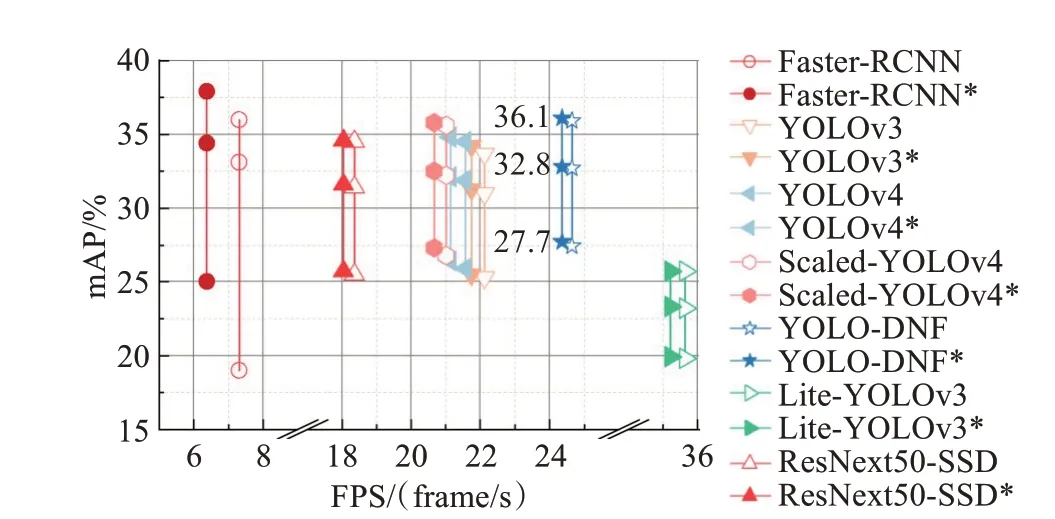
圖14 不同模型檢測精度與速度對比圖Fig.14 Comparison of detection accuracy and speed of different models
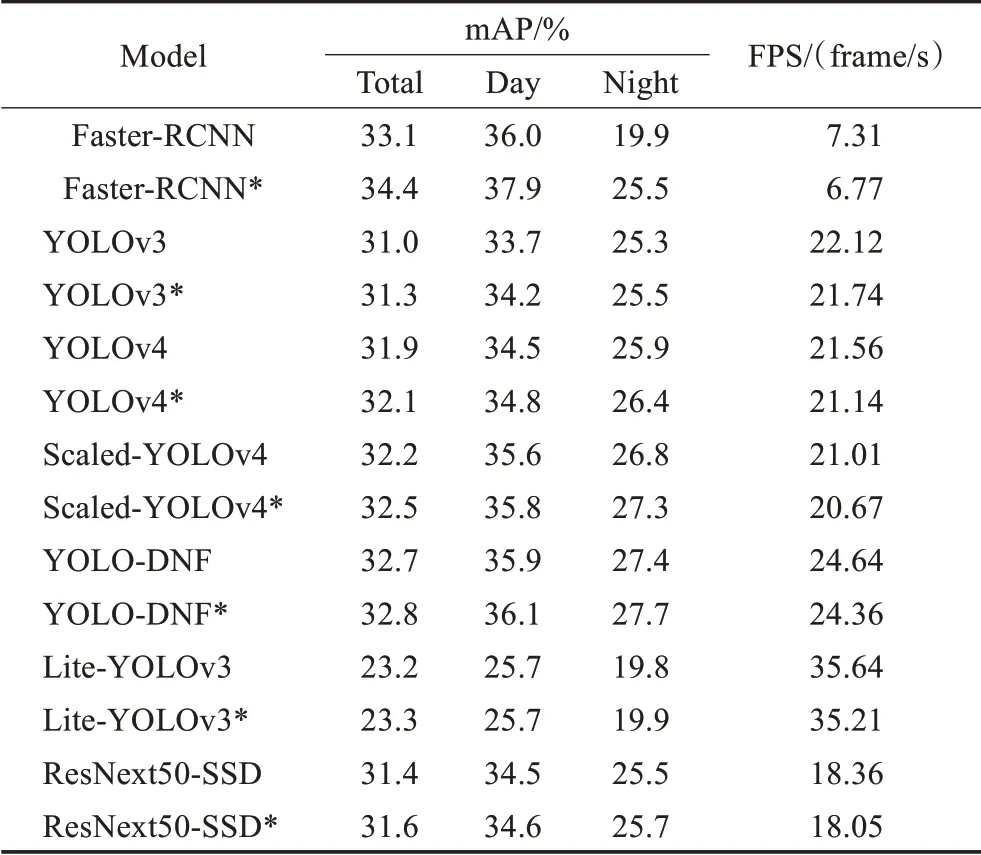
表6 不同模型檢測精度與速度對比表Table 6 Comparison of detection accuracy and speed of different models
通過模型之間對比可以得出本文所提出的YOLODNF模型具有較為均衡的表現。在速度方面,YOLODNF模型達到了Faster R-CNN[10]的3.37倍,同時也領先YOLOv3[11]、YOLOv4[12]以 及Scaled-YOLOv4[13]的2~4 frame/s。在精度方面,雖然YOLO-DNF模型總精度落后于Faster R-CNN[10],但是差距集中表現在白天部分的2.2%,而夜間檢測精度達到了最高的27.7%。與一階 段 模 型YOLOv3[11]、YOLOv4[12]以 及Scaled-YO‐LOv4[13]相比,YOLO-DNF在白天與黑夜均取得了精度領先。在與新型車輛與行人專用檢測模型Lite-YO‐LOv3[20]、ResNext50-SSD[21]的對比中可以發現YOLODNF模型仍處于速度與精度雙優的均衡位置。Lite-YOLOv3[20]模型由于使用了輕量化的網絡而取得了速度的大幅提升,但輕量化的網絡特征提取能力不足,使得其精度較低。ResNext50-SSD[21]模型雖然使用了結構更為復雜的網絡,但其檢測框架SSD相較YOLOv3略有劣勢,因此ResNext50-SSD[21]模型在檢測精度與速度方面均略遜本文所提出的YOLO-DNF模型。
對比同一模型是否使用HSV域數據增強策略則可發現本文所提出的HSV域數據增強在損失速度可以忽略不計的情況下提升了模型的夜間檢測精度,增強了模型對于光照條件變化的泛化性。
由于車輛與行人形狀、面積差異大,模型在檢測時難度不同,為了反應模型在差異較大的目標類別之間檢測能力的差距,將視覺特征類似的行人、騎自行車者歸于行人(Pedestrian)類,并將汽車、卡車、公交車、三輪車歸于車輛(Vehicle)類,針對兩類目標分別測試精度。進行比較的模型包括經典通用目標檢測模型Faster-RCNN[9]、YOLOV3[11]、YOLOV4[12]、Scaled-YOLOv4[13]以及新型車輛與行人專用檢測模型Lite-YOLOv3[20]、ResNext50-SSD[21],模型訓練、測試時都采用了HSV域增強策略。實驗結果如表7所示。
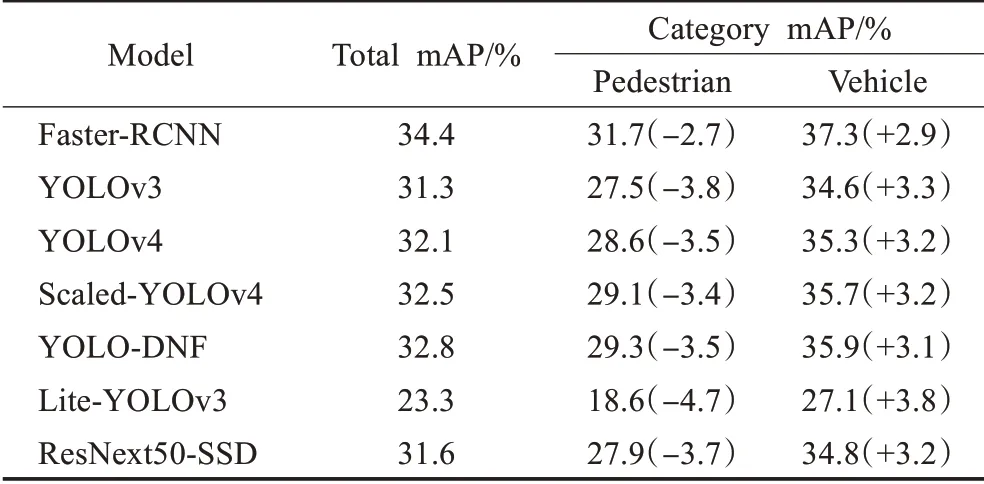
表7 不同模型檢測行人類與車輛類目標精度對比表Table 7 Comparison of detection accuracy of different models for pedestrians and vehicles
根據表7可知各類模型在檢測行人類目標時精度略低,而檢測車輛類目標時精度略高。這是由兩方面原因導致的,一方面是由于行人類目標普遍面積較小,在檢測時容易遺漏;另一方面是樣本不均衡,在訓練集中行人類目標僅占27.85%,網絡對于該類目標學習不充分。
依據表7可以發現兩階段檢測模型Faster-RCNN[9]模型在行人類與車輛類目標之間檢測精度差距較小,而ResNext50-SSD[21]模型精度差距較大,這是由于兩階段檢測模型提出大量RoI會重復檢查小目標,而SSD算法在同一位置上僅推理一次。以一階段目標檢測YOLO算法為基礎的YOLOV3[11]、YOLOV4[12]、Scaled-YOLOv4[13]、YOLO-DNF及Lite-YOLOv3[20]模型在行人類與車輛類目標之間檢測精度也有差距,但Lite-YOLOv3[20]、YOLOV3[11]模型的差距要大于YOLO-DNF模型,這反應了YOLO-DNF模型具有較強的特征提取能力。而模型YOLOV4[12]、Scaled-YOLOv4[13]在行人類與車輛類目標之間檢測精度的差距小于YOLO-DNF,這是由于其特征融合層的改進增強了多尺度檢測的能力,為YOLODNF模型后續的改進指明了方向。
YOLO-DNF模型與其他檢測模型的檢測效果對比圖如圖15所示。

圖15 不同模型的檢測效果圖Fig.15 Detection effects of different models
如圖15所示,在白天光照條件下,兩階段檢測模型Faster-RCNN[9]檢測出了原圖中的所有目標,本文提出的YOLO-DNF模型僅遺漏一個“自行車”小目標,YO‐LOV3[11]、YOLOV4[12]、Scaled-YOLOv4[13]以 及 新 型 車 輛與行人專用檢測模型Lite-YOLOv3[20]、ResNext50-SSD[21],均存在不同程度的目標遺漏。在夜間光照條件下,通過對比同模型的兩次檢測結果可發現:在訓練中使用本文提出的HSV域數據增強策略后模型的檢測效果有所提升,其中該策略對于Faster-RCNN[9]模型的提升較為明顯,使該模型檢測出的目標增加了4個。使用了HSV域數據增強策略后的YOLO-DNF模型檢測效果最好,檢測出了原圖中的所有目標,其余檢測模型仍存在不同程度的目標遺漏。模型的檢測效果與圖14及表6所示的模型檢測精度對比數據相一致。
4 結束語
為了服務車輛實際駕駛場景的目標檢測需求,本文通過對當下主流目標檢測技術的研究,提出了新型目標檢測模型YOLO-DNF,搭建了具有低計算成本、高特征提取能力優勢的主干網絡ACNet網絡,并在卷積神經網絡的訓練和檢測中使用HSV域數據增強策略提升模型的夜間檢測能力,大大增強了網絡的泛化性。最后,YOLO-DNF模型在SODA10M數據集中以24.36 frame/s圖像的檢測幀率達到32.8%的檢測精度,其中夜間檢測精度達到了27.7%,檢測精度與速度得到明顯提升,應用場景也進一步擴大。
后續研究將進一步依據YOLO-DNF模型繼續優化,引入半監督訓練來提升模型的泛化性,設計一種基于車載設備的高性能輔助駕駛技術。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
