一種基于span的實體和關系聯合抽取方法*
2022-12-22 11:32:54吳宏明李莎莎吳慶波
計算機工程與科學 2022年3期
余 杰,紀 斌,吳宏明,任 意,李莎莎,馬 俊,吳慶波
(1.國防科技大學計算機學院,湖南 長沙 410073;2.中央軍委裝備發展部裝備項目管理中心,北京 100034;3.陸軍項目管理中心,北京 100071)
1 引言
本文研究句內命名實體和關系的聯合抽取。與流水線模式的分步抽取方法相比,實體和關系的聯合抽取模式可以減輕錯誤級聯傳播并促進信息之間的相互使用,因此引起了諸多研究者的關注。
通常,聯合抽取模式是通過基于序列標注的方法實現的[1]。
最近大量的研究人員摒棄了基于序列標注的方法,提出了基于span的聯合抽取模式。此模式首先將句子的文本處理為文本span,這些span被稱為基于span的候選實體;然后計算span語義表示并對其進行分類,以獲得預測的實體;接下來組合span,構成基于span的候選關系元組,并計算這些候選元組的語義表示;最后對候選關系元組進行分類,得到關系三元組。該模式進一步提高了聯合抽取性能,然而存在以下3個問題:
(1)構成span的不同token對span語義表示的貢獻應有所不同,本文稱其為span特定特征。但是,現有的方法將span的每個token視為同等重要或僅考慮span頭尾token的語義表示,而忽略了這些重要特征。
(2)現有研究方法忽略了關系元組的局部上下文信息或僅通過max pooling的方法對其進行計算,因而不能充分捕獲其中包含的信息。而局部上下文中包含的信息,可能在關系預測中起到關鍵作用。
(3)在span分類和關系分類中均忽略了句子級的上下文信息,而這些信息可能是兩者的重要補償信息。
為了解決上述問題,本文提出了一種基于span的實體關系聯合抽取模型,該模型使用attention機制捕獲的span特定特征和句子上下文語義表示來增強實體和關系的語義表示。具體來說,(1)使用MLP(Multi Layer Perceptrons)attention[2]計算span特定特征的語義表示;(2)通過將span特定特征的語義表示作為Q(query),將句子token序列的語義表示作為K(key)和V(value),使用Multi-Head attention計算句子的上下文語義表示,用于強化span的語義表示;(3)通過將關系元組語義表示作為query,將相應的token語義序列作為key和value,使用Multi-Head attention分別計算關系的局部和句子級上下文語義表示,用于強化關系的語義表示。
本文使用BERT(Bidirectional Encoder Representation from Transformers)[3]實現基于span的實體和關系聯合抽取模型,并研究了上述3個問題,在ACE2005、CoNLL2004和ADE 3個基準數據集上進行了大量的實驗。實驗結果表明,本文提出的模型超越了以前的最優模型,在3個基準數據集上均達到了當前的最優性能。
2 相關工作
傳統上,流水線模式將實體關系抽取分為2個子任務,即實體識別和關系分類。大量的研究工作將神經網絡應用于這2個子任務中,例如將RNN(Recurrent Neural Network)[4]、CNN(Convolutional Neural Network)[5]用于實體識別中;將RNN[6]、CNN[7]和Transformer[8]等用于關系分類中。
實體和關系的聯合抽取通常被形式化為序列標注任務。研究人員首先提出的方法是表格填充方法[9],該方法用token標簽和關系標簽分別填充表格的對角線和非對角線。最近,許多研究人員專注于利用深度神經網絡來實現這一任務,例如BiLSTM(Bidirectional Long-Short Term Memory)和CNN的結合[10]。
最近,有學者提出了基于span的實體關系聯合抽取方法,用于解決序列標注方法中存在的問題,如無法抽取重疊的實體。Dixit等人[2]通過BiLSTM獲得span語義表示來實現實體關系聯合抽取方法,然后將ELMo(Embeddings from Language Models)、單詞和字符嵌入拼接起來,并在span和關系分類中實現了共享。Luan等人[11]獲取span語義表示的方法與Lee等人[12]采用的方法相同,但他們通過引入共指消除任務增強了span語義表示。在文獻[11]的基礎上Luan等人[13]提出了DyGIE(Dynamic Graph Information Extraction),該模型通過動態構造span交互圖來捕獲span之間的交互。Wadden等人[14]使用BERT替代DyGIE中的BiLSTM,提出了DyGIE++,進一步提高了模型性能。最近,Eberts等人[15]提出了SpERT(Span-based Entity and Relation Transformer),一個簡單但有效的基于span的聯合抽取模型,該模型將BERT作為編碼器,并使用2個多層前饋神經網絡FFNN(Feed Forward Neural Network)分別對span和關系進行分類。
本文提出了一種基于span的實體和關系聯合抽取模型,與已有研究方法不同的是,本文使用attention機制捕獲span特定特征和上下文語義表示,進一步強化span和關系的語義表示。通過計算目標序列語義表示與源序列語義表示之間的匹配程度,attention機制可得到源序列上的注意力得分,即權重得分。因此,信息越重要,其權重得分就越高。根據權重得分的計算方式進行分類,attention機制具有多種變體,例如Additive attention[16]、Dot-Product attention[17]和Multi-Head attention[18]等。
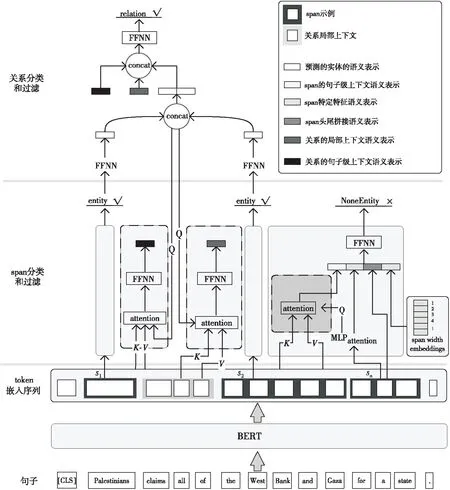
Figure 1 Architecture of the proposed joint entity and relation extraction model
3 基于span的實體和關系聯合抽取模型
圖1所示為本文提出的模型架構。本文提出的模型使用BERT作為編碼器,即使用Transformer[18]模塊將單詞嵌入映射到BERT嵌入。根據這些嵌入表示,計算span語義表示并執行span分類和過濾(3.1節);然后,組織關系元組,計算關系元組語義表示并執行關系分類和過濾(3.2節);最后,介紹模型的損失函數(3.3節)。
首先定義一個句子和該句子的一個span:
句子:S=(t1,t2,t3,…,tn)
span:s=(ti,ti+1,ti+2,…,ti+j)
其中,t表示token,一個token指代文本中的一個單詞或一個符號,如標點符號、特殊符號等;下標(例如1,2,3,…)表示token在文本中的位置索引。在span中,下標j表示span的長度閾值。
3.1 span分類和過濾
首先,將NoneEntity類型添加到預定義的實體類型集合(表示為η)中。若span的類型不屬于任何預定義的實體類型,那么它的類型為NoneEntity。
如圖1所示,用于分類的span語義表示由4部分組成,即:(1)span頭尾token語義表示的拼接;(2)span特定特征的語義表示;(3)span的句子級上下文語義表示(span width embeddings);(4)span寬度語義表示。本文用Xi表示tokenti的BERT嵌入,則S和s的BERT嵌入序列表示分別如式(1)和式(2)所示:
BS=(X0,X1,X2,…,Xn)
(1)
Bs=(Xi,Xi+1,Xi+2,…,Xi+j)
(2)
其中X0表示特定字符[CLS]的BERT嵌入。
(1)span頭尾token語義表示的拼接:如果span包含多個token,則將span頭token和尾token的BERT嵌入拼接。否則,復制單個token的BERT嵌入并將其拼接起來。以s為例,其拼接結果為:
Hs=[Xi;Xi+j]
(2)span特定特征的語義表示:本文使用MLP attention[2]計算span特定特征的語義表示,以s為例,其特定特征計算的形式化表示如式(3)所示:
Vk=MLPk(Xk)
s.t.k∈[i,i+j]
(3)
(4)
(5)
其中,Vk是標量;αk是Xk的attention權重,由Softmax函數計算得出;Fs是根據attention權重和Bs計算得到的span特定特征的語義表示。通過這種方式可以評估span包含的每個token的重要性,并且token越重要,它持有的attention權重就越大。通過將Fs作為Q(query),BS作為K(key)和V(value),使用Multi-Head attention計算span的句子級的上下文語義表示。以s為例,上述計算可形式化如式(6)所示:
Ts=Attention(Fs,BS,BS)
(6)
(3)span寬度嵌入:在模型訓練過程中為每個span寬度(1,2,…)訓練一個寬度嵌入表示[3],因此可以從寬度嵌入矩陣中為s查找寬度為j+1的嵌入表示Wj+1。
(4)span分類:用于分類的span語義表示由4部分拼接而成,其形式化表示如式(7)所示:
Rs=(Ts,Fs,Hs,Wj+1)
(7)
Rs首先輸入到一個多層FFNN,然后將輸出結果輸入到一個Softmax分類器,輸出結果為s在實體類型空間(包括NoneEntity)上的后驗概率分布值,如式(8)所示:
ys=Softmax(FFNN(Rs))
(8)
(5)span過濾:通過搜索得分最高的類別,ys預測得到s的實體類型。本文保留未分類為NoneEntity的span,并構成一個預測的實體集ε。
3.2 關系過濾和篩選
首先,將NoneRelation類型添加到預定義的關系類型集合(表示為γ)中。設s1和s2是2個span,用于關系分類的關系元組定義如式(9)所示:
〈s1,s2〉∈{ε?ε}
s.t.s1≠s2
(9)
如圖1所示,用于分類的關系語義表示由3部分組成,即:(1)構成關系的2個預測的實體的語義表示拼接;(2)關系的局部上下文語義表示;(3)關系的句子級上下文語義表示。
(1)關系元組語義表示的拼接:將s1和s2的語義表示分別形式化為Rs1和Rs2(本質為span的語義表示)。在拼接Rs1和Rs2之前,本文首先使用2個不同的多層前饋神經網絡FFNN分別減小其維度,拼接結果如式(10)所示:
Hr=[FFNN(Rs1);FFNN(Rs2)]
(10)
(2)關系的局部上下文語義表示:令Bc表示s1和s2之間的局部上下文的BERT嵌入序列,其形式化表示如式(11)所示:
Bc=(Xm,Xm+1,Xm+2,…,Xm+n)
(11)
通過將Hr作為Q(query),Bc作為K(key)和V(value),使用Multi-Head attention計算關系的局部上下文語義表示,如式(12)所示:
Fr=Attention(Hr,Bc,Bc)
(12)
(3)關系的句子級的上下文語義表示:通過將Hr作為Q,Bs作為K和V,使用Multi-Head attention計算關系的句子級上下文語義表示,其形式化表示如式(13)所示:
Tr=Attention(Hr,Bs,Bs)
(13)
(4)關系分類:在將Fr和Tr融合到關系語義表示之前,本文首先將2個不同的多層FFNN應用到Fr和Tr,以控制其維度,目的是使它們在關系的語義表示中保持適當的比例,用于分類的關系語義表示可形式化為:
Rr=[Hr;FFNN(Fr);FFNN(Tr)]
(14)
類似于span分類,Rr首先輸入到一個多層FFNN,然后將輸出結果輸入到一個Softmax分類器,產生〈s1,s2〉在關系類型空間(包括NoneRelation)上的后驗概率分布,如式(15)所示:
yr=Softmax(FFNN(Rr))
(15)
(5)關系過濾:通過搜索得分最高的類別,yr可以預測出〈s1,s2〉的關系類型。本文保留預測為非NoneRelation的關系元組并構成關系三元組。
3.3 損失函數
本文將聯合抽取模型的損失函數定義如式(16)所示:
L=0.4Ls+0.6Lr
(16)
其中,Ls表示span分類的交叉熵損失,Lr表示關系分類的二元交叉熵損失。由于關系分類的性能通常比實體識別性能差,因此本文對Lr賦予更大的權重,旨在讓模型更多地關注關系分類。
4 實驗
4.1 數據集
本文模型在ACE2005[19]、CoNLL2004[20]和ADE(Adverse-Effect-Drug)[21]3個基準數據集上進行實驗,以下將3個數據集簡稱為ACE05、CoNLL04和ADE。
(1)ACE05英文數據集由多領域的新聞報道組成,例如廣播、新聞專線等。該數據集預定義了7個實體類型和6個關系類型。本文遵循當前已有研究工作中提出的training/dev/test數據集劃分標準。其中包括351份訓練數據,80份驗證數據和80份測試數據,這其中又有437份包含重疊實體。
(2)CoNLL04數據集包括來自華爾街日報和AP的新聞語料,本文遵循當前已有研究工作中提出的training/dev/test數據集劃分標準。其中包括910份訓練數據,243份驗證數據和288份測試數據。
(3)ADE旨在從醫學文獻中抽取藥物相關的不良反應,預定義了2個實體類型(即Adverse-Effect和Drug)和1個關系類型,即Adverse-Effect。該數據集由4 272個句子組成,其中1 695個包含重疊實體。本文在該數據集上進行10重交叉驗證實驗。
4.2 實驗設置
本文使用English BERT-base-cased model作為嵌入生成器。在本文模型訓練期間訓練FFNN和attention的模型參數并且對BERT模型參數進行微調。本文將模型訓練的batch大小設置為8,dropout設置為0.2,寬度嵌入的維度設置為50。Multi-Head attention頭數設置為8。學習率設置為5e-5,weight decay設置為0.01,梯度裁剪閾值設置為1,對不同數據集,本文設置了不同的epoch。對于所有數據集,span寬度閾值均初始化為10。本文采用動態負采樣策略來提高模型性能和魯棒性,其中實體和關系的負例采樣數量都是每個句子中正例的30倍。
4.3 基準模型
在3個基準數據集上,本文模型與以下模型進行比較。
(1)DyGIE++[14]是當前在ACE05數據集上基于span聯合抽取模式的最優模型,它通過引入共指消除任務來強化span和關系的語義表示。
(2)Multi-turn QA(Multi-turn Question & Answer)[22]是當前在ACE05和CoNLL04 2個數據集上基于序列標注的最優模型。它將實體和關系的聯合抽取形式化為一個多輪問答問題,但仍是基于序列標注的抽取模式。
(3)SpERT[15]是當前在ADE和CoNLL04 2個數據集上基于span聯合抽取模式的最優模型。
(4)Relation-Metric[23]是一種基于序列標注的聯合抽取模型,并且采用了多任務聯合學習模式。該模型在ADE數據集上取得了當前的最優性能。
4.4 實驗結果
本文提出的模型和當前性能最優的聯合抽取模型的比較結果如表1所示。本文提出的模型表示為SPANMulti-Head,表示使用Multi-Head attention計算上下文語義表示。在ACE05和CoNLL04 2個數據集上,本文采用準確率P(Precision)、召回率R(Recall)和微平均F1(micro-averageF1)評估指標。在ADE數據集上,本文采用準確率P(Precision)、召回率R(Recall)和宏平均F1(macro-averageF1)評估指標。這些指標均參照當前已發表的研究工作。對于ACE05和ADE 2個數據集,表1列出的所有結果均已將重疊實體考慮在內。
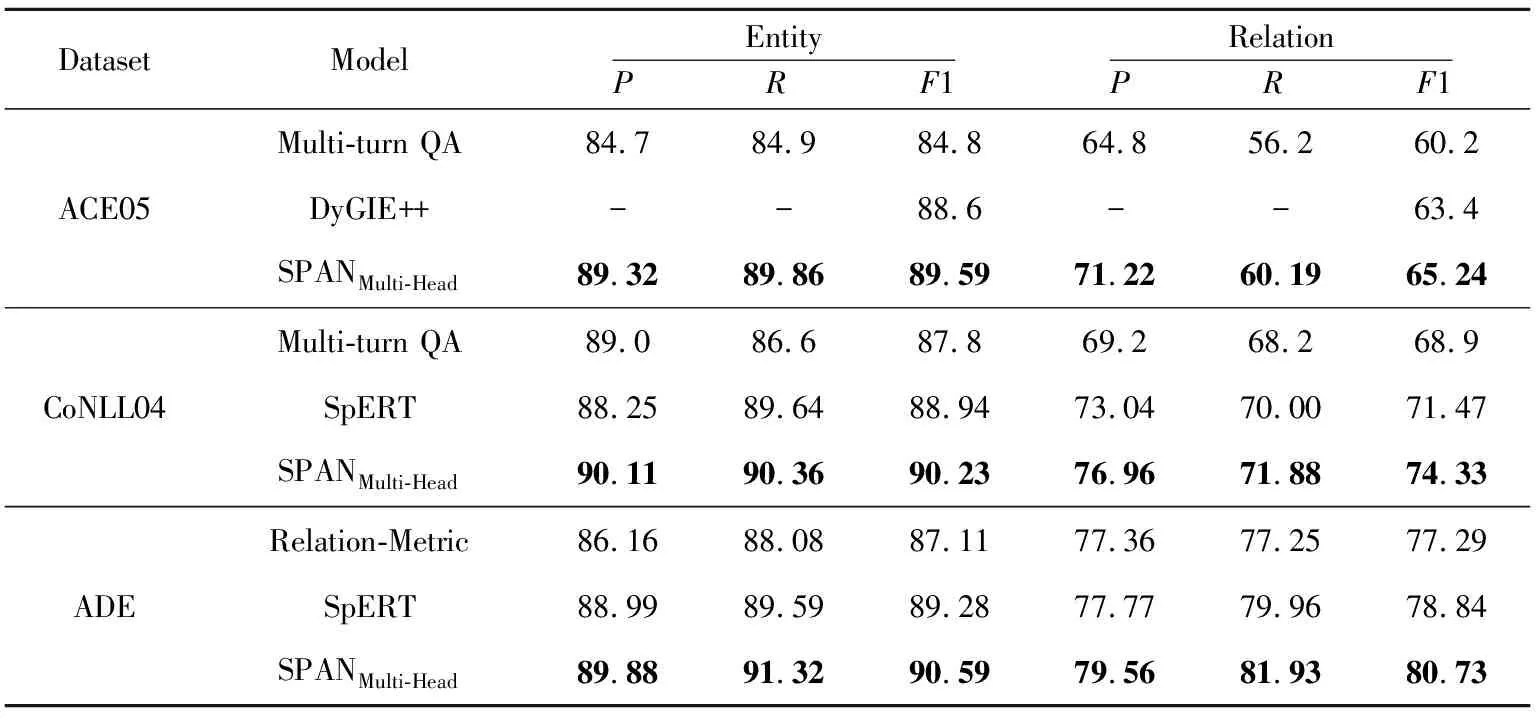
Table 1 Performance comparisons of different models on ACE05,CoNLL04 and ADE datesets
從表1可以看出,SPANMulti-Head在3個基準數據集上的性能均超過了當前已有的最優模型。具體來說,與SpERT相比,SPANMulti-Head在實體識別方面獲得了1.29(CoNLL04)和1.31(ADE)的絕對F1值提升,而在關系抽取方面則獲得了更佳的絕對F1值提升,分別為2.86(CoNLL04)和1.89(ADE)。本文將這些性能提高歸結于span特定特征和上下文表示。此外,與DyGIE++相比,在ACE05數據集上,SPANMulti-Head在實體識別和關系抽取上相比DyGIE++獲得了0.99和1.84的絕對F1值提升。但是,值得注意的是DyGIE++采用了多任務聯合學習的方式,通過引入共指消除任務進一步增強了span的語義表示,而本文方法并未引入共指消除。
4.5 消融實驗
本節在ACE05測試集上進行消融實驗,以分析不同模型組件的影響。
(1)span特定特征和span的句子級上下文語義表示的影響。
表2給出了span特定特征和span的句子級上下文語義表示對本文提出模型的影響。其中,-SpanSpecific表示使用Bs的max pooling替換Rs中的[Fs,Hs];-SentenceLevel表示使用[CLS]的BERT嵌入替換Rs中的Ts;base表示執行以上2種消融操作。在ACE05測試集上,可觀察到span特定特征語義表示和span的句子級上下文語義表示均有益于實體識別和關系抽取,這是因為 span的語義表示在2個子任務中共享。

Table 2 Ablation results of span-specific and span sentence-level contextual representations
(2)關系的局部和句子級上下文語義表示的影響。
表3給出了關系的局部和句子級上下文語義表示對本文提出模型的影響,其中,-local表示使用Bc的max pooling替換Rr中的FFNN(Fr);-SentenceLevel表示去除Rr中FFNN(Tr);base是執行以上2種消融操作。
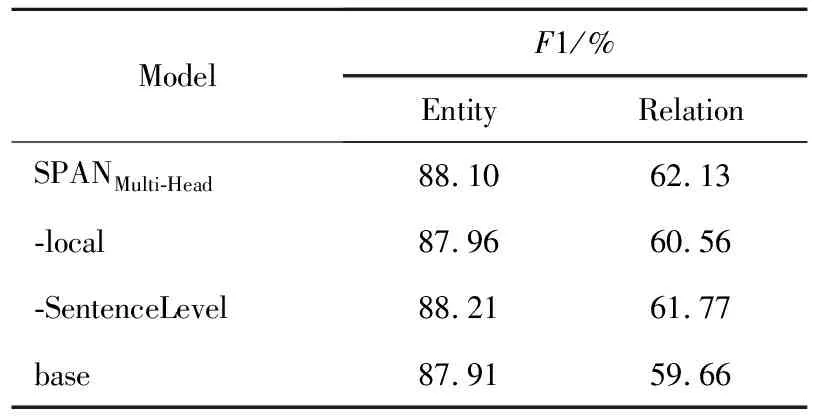
Table 3 Ablation results of relation local and sentence-level contextual representations
在ACE05驗證數據集上,可觀察到關系的局部和句子級的上下文語義表示明顯地有益于關系提取,然而對實體識別的影響卻可以忽略不計。一個可能的原因是,這些上下文語義表示直接構成關系的語義表示,然而僅通過梯度反向傳播影響span的語義表示。
值得注意的是,與關系的句子級上下文語義相比,關系的局部上下文語義對關系抽取的影響更大。原因之一是決定關系類型的信息主要存在于關系元組和局部上下文中。另一個原因是作為補償信息,關系的句子級上下文語義表示在關系語義表示中所占的比例相對較小,目的在于避免將噪聲引入關系的語義表示中。
5 結束語
本文提出了一種基于span的實體關系聯合抽取模型,該模型使用attention機制強化span和關系的語義表示。具體來說,使用MLP attention捕獲span特定特征,豐富了span的語義表示;使用Multi-Head attention捕獲句子局部和全局特征,進一步強化了span和關系的語義表示。本文提出的模型在3個基準數據集上的性能均超過了當前最優模型,創造了當前最優的聯合抽取性能。將來將研究通過減少span分類錯誤來進一步提高關系分類性能,還計劃探索更有效的方法用于編碼語義更為豐富的span和關系語義表示。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
