反向梯度深度學習下重復網絡數據標注仿真
2022-11-29 13:24:28龐家樂
計算機仿真 2022年10期
龐家樂,張 彥
(北京交通大學,北京 100044)
1 引言
在信息的錄入與集成過程中,若含有冗余、異常等屬性的數據沒有及時被處理,直接影響數據后續處理的準確性。數據清洗作為一種應用非常廣泛的、能提高數據質量的方法之一,清洗對象主要以重復數據為主,包括缺失數據、重復數據以及亂碼數據等。其中,由于多數據融合而產生的重復數據是數據清洗的重點。標注重復網絡數據,一方面可以去除掉空間內重復存儲的數據集或者文件,優化存儲空間;同時也可以降低網絡傳輸壓力,為數據復制節省了部分網絡帶寬。目前,數據清洗技術已經非常成熟,但如何精準標注網絡重復數據仍是相關領域學者的重點分析難題。
文獻[1]通過無線傳感網絡的應用坐標系對數據重新配置,根據配置結果選擇其中存在的重復數據節點;然后,計算各個協議點的覆蓋面積大小,利用分類數據初始化的方法,使得各個協議點之間實現有效連接,完成無線傳感網絡重復數據的優化檢測。該方法未考慮數據屬性和唯一IP之間的關系,檢測標記效率過低,對于大規模的數據并不適合;文獻[2]提出利用多通道卷積機制,自動化提取和處理公式圖片內特征向量,使標記過程更能適應大規模的公式數量;將卷積神經網絡的輸出模式設置為端到端,降低因步驟過多而出現誤差累積的幾率;最后,將重復數據檢測問題量化為對重復公式的檢測,實現冗余數據標記。該方法對于不同質量的公式圖片均能實現重復性檢測,但是該方法的標注準確率較低。
基于此,本文基于反向梯度深度學習算法,提出一種新的重復網絡數據標注方法。首先,利用綜合加權法,檢測數據庫中的重復數據,再利用三區分快速算法對相似度過高的重復數據標注。仿真結果也表明,本文方法具有非常理想的標注效果,與其它方法相比,可在成本最低的前提下實現最高效率的檢測與標注。
2 重復網絡數據檢測
2.1 數據字符串編輯距離的計算
本文利用綜合加權法計算各個數據的屬性權重值[3],對每個數據字符串之間的編輯距離重新定義[4],得到數據與數據距離之間相似度值。實現過程如下所示:
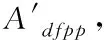
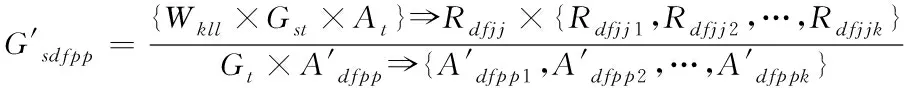
(1)
式中,Gst表示第s個操作者對屬性At設定的等級,Gt表示第t個屬性的最終統一等級。
通過式(2)計算數據屬性取值種數,減少數據因屬性取值不同而出現計算復雜情況,在一定程度上提高算法的整體計算效率。
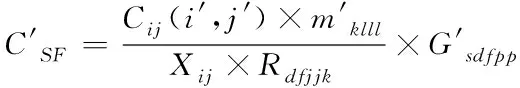
(2)
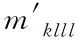
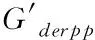
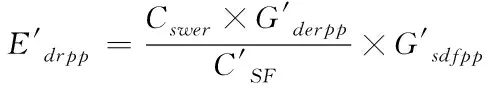
(3)
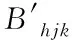
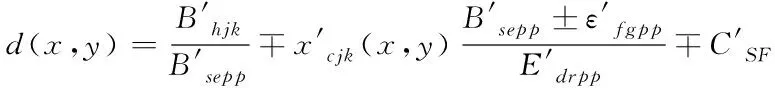
(4)
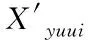
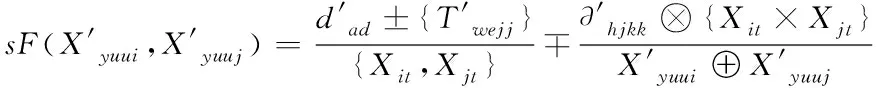
(5)

綜上所述,網絡中的重復數據利用綜合加權法計算各個數據屬性的權重值后,重新定義每個數據字符串之間的編輯距離,得到各個數據距離之間的相似度值,為后續進行重復數據的檢測做好準備工作。
2.2 重復數據檢測
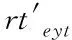
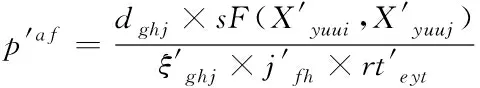
(6)

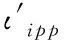
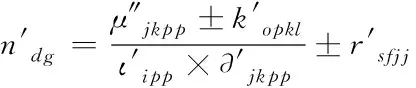
(7)
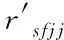
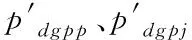
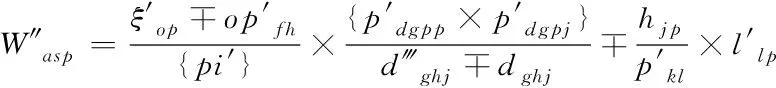
(8)
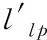
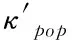
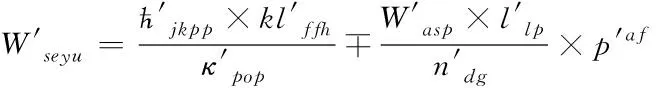
(9)
3 反向梯度深度學習下重復網絡數據標注
在實際的應用網絡中,流動數據量是非常巨大的,要對所有數據逐一檢測和重復數據標記是非常困難的。因此,本文引入反向梯度學習算法,實現過程如下所示:
1)由于網絡數據庫中記錄的數據并不只有一個關鍵字,所以可以通過設置ID編號形式對其重新設定[9]。ID編號的權重值為0,不影響后續的計算過程中,可忽略不計。
2)建立數據關系記錄屬性表。遍歷所有數據,根據數據的屬性建立不同的屬性記錄庫,在屬性記錄庫中根據每個屬性建立屬性值記錄表。該表中記錄了各個數據不同的屬性值,以及屬性值相同的數據信息。這里所做的工作與倒排索引的思想類似,將“單詞”與“文本”按照倒排索引鏈表的結構進行排列,其中的記錄就用ID編號來表示。
3)將數據記錄設定為R={R1,R2,…,Rl},用l來表示數據記錄的數量,與之對應的某個數據記錄為Ri(1≤i≤l)。這兩個數據記錄的任意一個屬性p間關系用公式表示為:
M=A(Rip,Rjp)={0,1}(1≤i≤l,1≤j≤l,1≤p≤n)
(10)
式中,Rip=(ID1,ID2,…,IDm),IDm表示某個數據屬性值出現相似或重復的記錄次數,n表示任意一個數據記錄具有n個屬性值的長度值,p表示某個屬性的第p個屬性值。
當M=1時,可以判定這兩個數據記錄在p屬性下具有非常相似甚至重復部分;當M=0時,則可以判定這兩個數據在p屬性下相似程度較低、不存在重復的情況。按照這種思路,對數據庫中的所有數據在某屬性下進行計算比較。經過比較,還可以得到數據記錄屬性值的具體值。對數據記錄之間的相似度定義過程如(11)所示
Qi,j,p=M*Wp
(11)

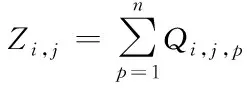
(12)
式中,Zi,j表示數據記錄i與數據記錄j之間的相似程度高低。
4)給定相似閾值U,用來判定二者之間是否存在重復。
Zi,j?U
(13)
5)在比較屬性值記錄表中的數據屬性時,如果按照順序逐個比較會花費大量的時間。因此,本文引入快速排序算法,按照從大到小的順序排列,當出現了相等的兩個屬性值后,把該數據挑選出來,后續不再進行比較,減少計算時間。本文采用的是三區間比較方法,使得挑選出來的數據不再進行排列比較,只允許大于或者小于選定的數再進行排列比較。假設選定的數值為x,那么只針對大于x或者小于x的數值進行排列比較即可,如圖1所示。
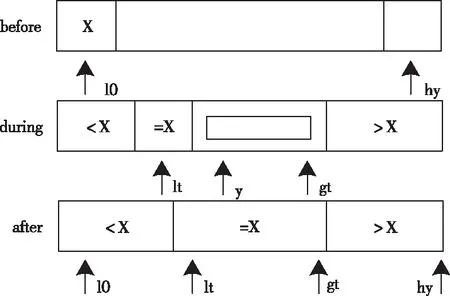
圖1 三區間數值排序示意圖
從圖1中可以看出,按照從左到右的掃描順序,指針lt始終保持[lo…lt]中的數字比x小,其它指針gt保持[g(t+1)…hy]中的數字比x大,指針y保持[lt…(y-1)]中的數字與x相等。[y…gt]之間的數字表示沒有進行排列比較的數字,y從lo處開始進行掃描:
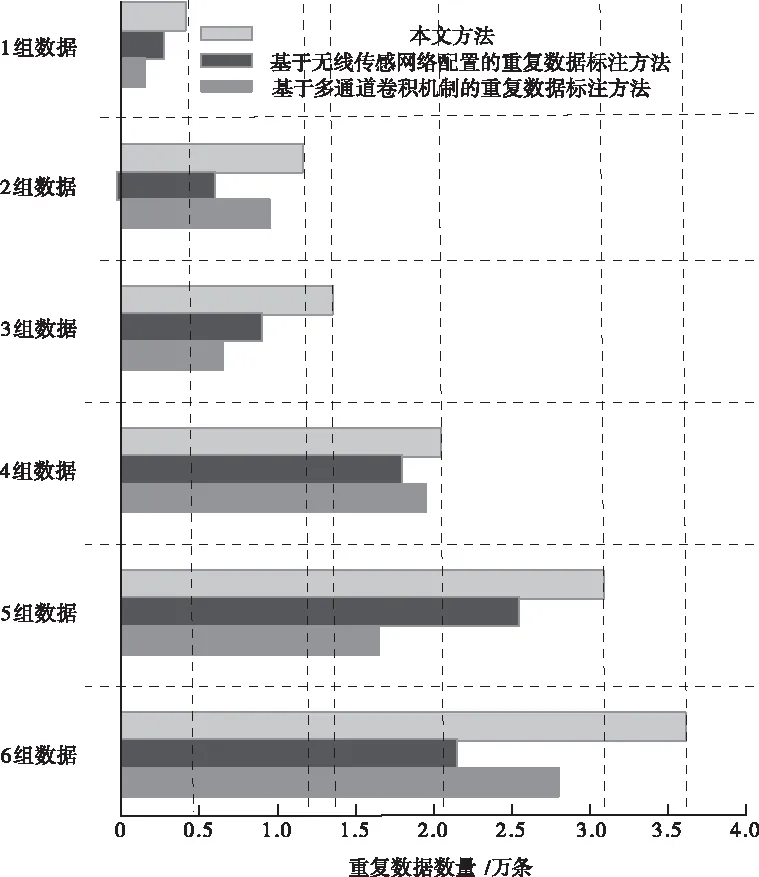
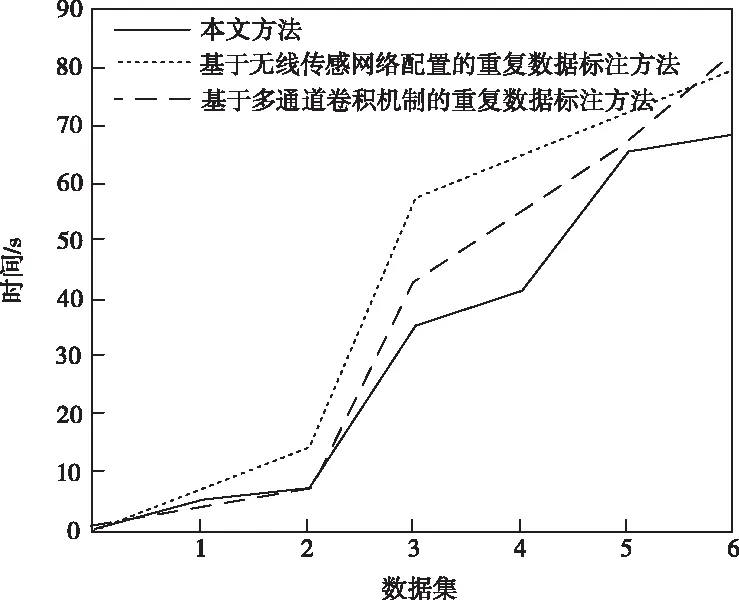
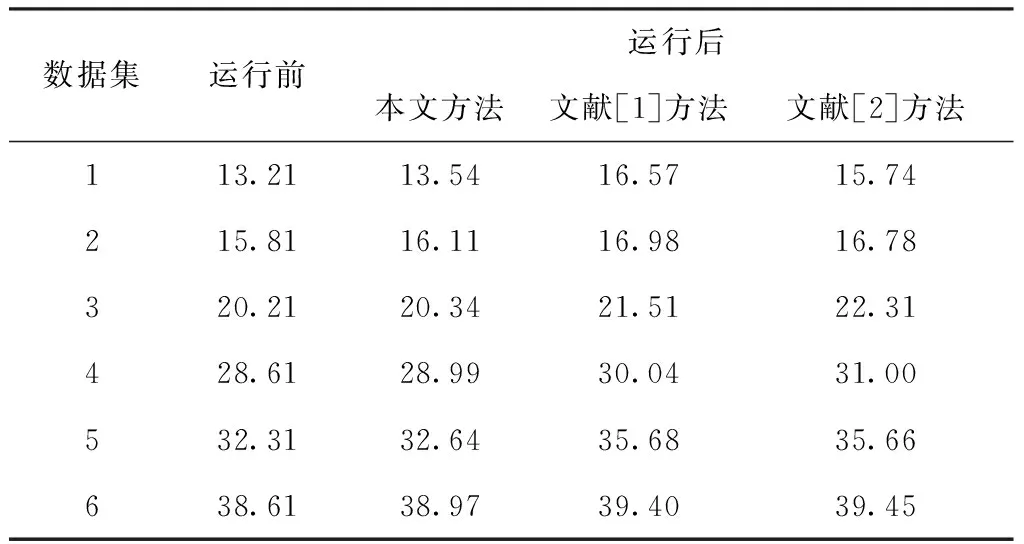
當a[y] 當a[y]>v時,交換a[y]和a[gt],gt指針會出現自減的情況; 當a[y]=v時,y指針出現自增的情況。 1)為網絡數據庫中的數據記錄設置唯一的ID編號,同時構建屬性記錄庫,在記錄庫中為每個屬性設置專屬的屬性值記錄表。 2)為數據庫中的每個數據都構建一個單獨的屬性值記錄表,將數據的屬性值與ID編號存入到數據庫中,形成數據關系表,后續進行排列與比較時直接參考該表即可。 3)完成以上操作后,根據屬性值記錄表和數據關系表,從屬性記錄庫中挑選數據,利用三區分快速算法按照數據屬性值從大到小的順序排列,與讀取的屬性值比較,以此來判斷數據之間是否存在相似度過高或者重復的情況。 當出現相似度過高或者重復的情況時,用相應的權重值乘以1,挑選出來,當相似度過低時,結果直接等于0,不做任何計算。 將數據記錄與屬性值記錄表中的數據逐一進行比較,最后的比較結果整合為數據之間的相似度值。 4)根據上述數據之間的相似度值以及預先設定的閾值大小,來判斷數據之間是否存在相似度過高或者重復的情況。 5)當網絡數據庫中錄入了新的數據后,重復以上操作步驟,實現新數據與數據庫內其它數據之間的相似度比較,以此實現對相似度過高或者重復數據的有效檢測與標注。 仿真用到的計算機為Inter 133702.40GHzCPU,編程選擇的是JAVA語言。實驗中用到是Oraclellg數據庫中隨機選取的6組數據,6組數據的數據量分別為45.6萬、53.6萬、184.7萬、207.9萬、294.5萬、315.5萬,運用相關技術對數據進行處理,使其分別包含0.48萬、1.21萬、1.35萬、2.15萬、3.12萬、3.66萬條重復數據。為了進一步驗證本文方法的性能,與文獻[1]提出的基于無線傳感網絡配置的重復數據標注方法以及文獻[2]提出的基于多通道卷積機制的重復數據標注方法展開了對比實驗。 將本文方法與其它兩種方法在重復數據檢測與標注數量方面進行對比實驗,實驗結果如圖2所示。 圖2 三種方法重復數據檢測與標注數量對比 從圖2中可以看出,當面對數據量跨度較大的數據集時,本文方法始終展現出了較高的檢測精度與標注能力。文獻兩種算法檢測精度波動起伏較大,且偏離正確值較遠。這是由于這兩種方法沒有對數據記錄的屬性計算賦值,只考慮了主觀因素,而沒有將客觀因素考慮在內,由此導致了較大的誤差。而本文方法可以深入挖掘數據之間的內在聯系,對相似度過高或者重復的數據可以實現精準的檢測與標注。 接下來利用三種方法從檢測與標注所需時間方面展開對比仿真,結果如圖3所示。 圖3 三種方法檢測與標注所需時間對比 從圖3中可以看出,本文方法檢測與標注所花費的時間最少,并且隨著數據量的不斷增加,文獻方法所花費的時間增長幅度越來越大。這是由于本文方法在進行重復數據檢測與標注的同時,利用三區分快速算法,將已經完成比較的數據不再重復計算,只針對大于或小于特定數值的數據進行排列比較,在一定程度上提高了算法整體的運算效率。 接下來對三種算法在進行重復數據的檢測與標注時,本地服務器吞吐量情況進行對比,實驗結果如圖4所示。 圖4 三種方法本地服務器吞吐量對比 從圖4中可以看出,三種方法中本文方法本地服務器吞吐量下降幅度最大,說明運用本文方法不會對服務器性能產生較大的影響。其它兩種方法均占用了大量的本地服務器存儲空間。這是由于本文方法將經過比較的數據挑選出來,不再重復進行計算,在提高了算法計算效率的同時減少了計算成本。 本地服務器CPU占用情況如表1所示。 表1 本地服務器CPU占用情況對比/% 從表1中可以看出,相較于其它兩種方法來說,運行本文方法占用的CPU內存最少。這說明在運行本文方法時,對服務器內其它程序的運行不會產生較大的影響。 本文利用反向梯度深度學習算法實現對網絡數據庫中重復數據的檢測與標注,并與無線傳感網絡和深度卷積神經網絡兩種方法展開對比實驗,結果表明本文方法可以在花費時間最少的前提下可實現最高精度的檢測與標注,并且不限制數據集中數據量的多少。4 算法實現步驟
5 仿真研究
5.1 仿真環境
5.2 重復數據檢測與標注數量對比
5.3 重復數據檢測與標注時間對比
5.4 本地服務器吞吐量及CPU占用率對比

6 結論
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
