基于改進(jìn)遮蓋策略的BERT 實(shí)現(xiàn)文本摘要
2022-11-18 14:01:20徐一鳴
電子設(shè)計工程 2022年22期
徐一鳴,易 黎
(1.武漢郵電科學(xué)研究院,湖北武漢 430074;2.南京烽火天地通信有限公司,江蘇南京 210019)
文本摘要任務(wù)的目標(biāo)是獲得一段文字的簡要壓縮版本,這個任務(wù)一般被分成抽取式文本摘要和生成式文本摘要。在該文中主要關(guān)注抽取式摘要。
現(xiàn)在,已經(jīng)有很多神經(jīng)網(wǎng)絡(luò)模型應(yīng)用在文本摘要任務(wù)上[1-6]。其中,BERT 預(yù)訓(xùn)練模型的使用,進(jìn)一步提升了抽取式摘要的效果。但是BERT 并不是具體針對某項下游任務(wù),并且其中預(yù)訓(xùn)練任務(wù)設(shè)計仍待商榷。于是人們根據(jù)不同任務(wù)對BERT 提出改進(jìn),針對中文數(shù)據(jù)集提出了ENRIE[7];MASS[8]提出了同時利用編碼器和解碼器進(jìn)行長序列遮蓋,提高了模型理解語義的能力;UNILM[9]改變了self-attention的應(yīng)用,將單向和雙向attention 相結(jié)合;SpanBERT[10]利用長序列遮蓋進(jìn)行預(yù)測遮蓋內(nèi)容;RoBERT[11]取消了NSP 任務(wù),并且采取隨機(jī)遮蓋策略。
該文針對BERT 預(yù)訓(xùn)練模型進(jìn)行改進(jìn),使其可以更適應(yīng)中文文本摘要任務(wù),提高了摘要效果。
1 原始BERT實(shí)現(xiàn)文本摘要
BERT(Bidirectional Encoder Representation from Transformers)[12]是由谷歌研發(fā)團(tuán)隊提出的,它以Transformer 模型為基礎(chǔ)框架,不再使用傳統(tǒng)深度學(xué)習(xí)任務(wù)中常用的RNN 和CNN,整個網(wǎng)絡(luò)結(jié)構(gòu)完全由注意力機(jī)制組成。
如果利用BERT 預(yù)訓(xùn)練模型進(jìn)行生成抽取式摘要[13-14],需要它輸出每一個句子的token。BERT預(yù)訓(xùn)練模型是作為masked-language model來訓(xùn)練的,輸出的向量是句子的token。同時,BERT 對于每一個獨(dú)立的句子有專門的segmentation embeddings,不過它只有兩種標(biāo)簽來表示抽取式摘要中的句子。調(diào)整輸入和BERT的embedding進(jìn)行抽取摘要,對于連續(xù)的句子用EA和EB進(jìn)行區(qū)分。為每一個句子編碼時,在一個句子的開頭位置放置一個[CLS]token,在句子結(jié)尾位置放置一個[SEP]token,讓模型可以利用這兩個token 來判斷句子的獨(dú)立性,BERT中的三種Embedding如圖1所示。
在下游任務(wù)中,不再選擇簡單的sigmod 分類器,而是采用多層的Transformer 層來代替,從BERT 預(yù)訓(xùn)練模型的輸出中提取側(cè)重于文本摘要任務(wù)的文檔級特征:
式中,h0=PosEmb(T),T是BERT 輸出的句子向量,PosEmb 是將Positional Embedding 加入T的函數(shù);LN是Layer Normalization 處理[15];MHAtt是multi-head attention 處理;上標(biāo)l表示堆疊層數(shù)。最終的輸出層仍可以看作是一個sigmod 分類器:
式中,是句子i從l層Transformer 中輸出 的向量。在實(shí)驗(yàn)中,分別設(shè)置Transformer 層數(shù)l=1,2,3,最后發(fā)現(xiàn)2 層Transformer 表現(xiàn)最佳。
2 改進(jìn)模型適應(yīng)中文文本摘要
2.1 文本預(yù)處理
在對原始文本進(jìn)行預(yù)處理的過程中,利用中文分詞語料庫對原始的文本進(jìn)行分詞分句處理。將切分出的中文詞語作為一個token 輸入或者進(jìn)行Mask,分詞與輸入對比如表1 所示。

表1 分詞與輸入對比
2.2 改變Mask策略
Mask Language Model(MLM)是BERT 的預(yù)訓(xùn)練任務(wù)之一,可以理解完形填空任務(wù)。在原始BERT中,隨機(jī)Mask 其中15%的詞(在一個滑動窗口里取一個詞,10%~15%的比例都可以)如圖2 所示,用其上下文來做預(yù)測。
改進(jìn)的BERT 中,不再對15%的token 采取隨機(jī)Mask,而是選擇遮蓋連續(xù)的token 以達(dá)到遮蓋序列的效果。如圖3 所示,遮蓋序列的長度k則是變化的,k的范圍在切分出一句話的10%~50%。其中,當(dāng)k=10%時可以把模型看作原始BERT 中的MLM,而文本摘要任務(wù)需要模型同時考慮語義與前后詞句之間的關(guān)系,所以遮蓋長度不能超過50%。同時,不同長度的k在整個訓(xùn)練過程中是同時存在的,它們占整個訓(xùn)練次數(shù)的比例不同。
在每次迭代時,都選擇一次k的長度,其中,k的長度更傾向于選擇短距離,整個訓(xùn)練k的分布近乎幾何分布,k的比例與分布如圖4 所示。
在訓(xùn)練過程中,這部分被Mask 的詞,80%的時間采用[mask]進(jìn)行表示,10%的時間采用另一個隨機(jī)的詞代替,10%的時間保持原詞不變。但是,這種遮蓋不再是單個token 的,而是整個序列級別的,被遮蓋序列中每一個token 都用[mask]代替。
3 實(shí)驗(yàn)
3.1 實(shí)驗(yàn)細(xì)節(jié)
實(shí)驗(yàn)選擇使用python3.6,pytorch1.8,CUDA11.1,bert_base_chinese 版本的BERT。在訓(xùn)練過程中,前10 000 步設(shè)置學(xué)習(xí)率如式(4)所示,對模型進(jìn)行預(yù)熱以加快擬合速度[16]。
整個模型在一塊RTX3070 顯卡上訓(xùn)練,每次訓(xùn)練100 000 步,每隔1 000 步在驗(yàn)證集上設(shè)置一個模型檢查點(diǎn)進(jìn)行保存和評估。根據(jù)驗(yàn)證集上的評估損失選擇前三個檢查點(diǎn),并反饋測試集上的平均結(jié)果。
3.2 數(shù)據(jù)集
該文選取的數(shù)據(jù)集是LCSTS。數(shù)據(jù)集主要分為三部分,如表2 所示。
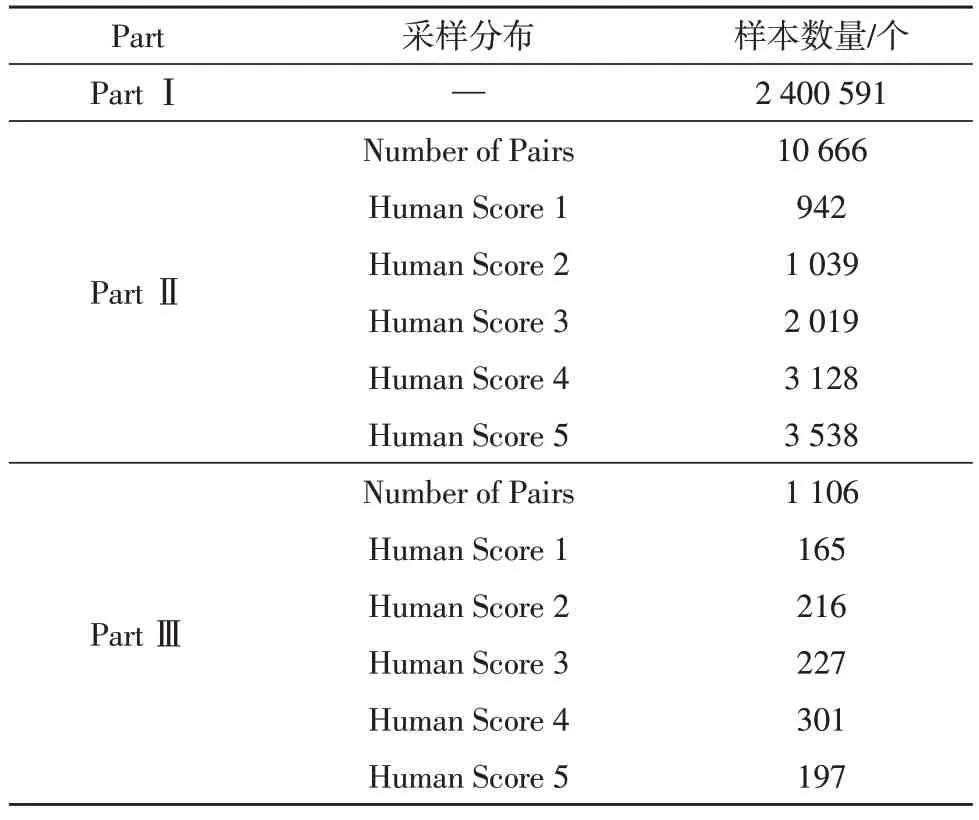
表2 數(shù)據(jù)集分布
第一部分是數(shù)據(jù)集的主要部分,用來訓(xùn)練生成摘要的模型;第二部分是從第一部分?jǐn)?shù)據(jù)中隨機(jī)采樣出來的,用來分析第一部分?jǐn)?shù)據(jù)的分布情況;第三部分作為測試集。
4 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)中,不同模型生成的摘要如表3 所示。

表3 生成的文本摘要
通過表3 可以看出,該文改進(jìn)的BERT 生成的摘要信息相比BERTsum 更加簡潔,反映的原文信息更加精準(zhǔn),更貼合人工摘要的效果。
當(dāng)然,人工評價具有一定的差異性,該文采用針對文本摘要任務(wù)專用的評價指標(biāo)Rouge,其中,Rouge_R 代表召回率,Rouge_P 代表準(zhǔn)確率,在文本摘要任務(wù)中往往希望召回率和準(zhǔn)確率都較高,但是實(shí)際情況是兩者一般呈反比例,所以主要利用F 值即Rouge_F 進(jìn)行比較。實(shí)驗(yàn)結(jié)果如表4-6 所示。
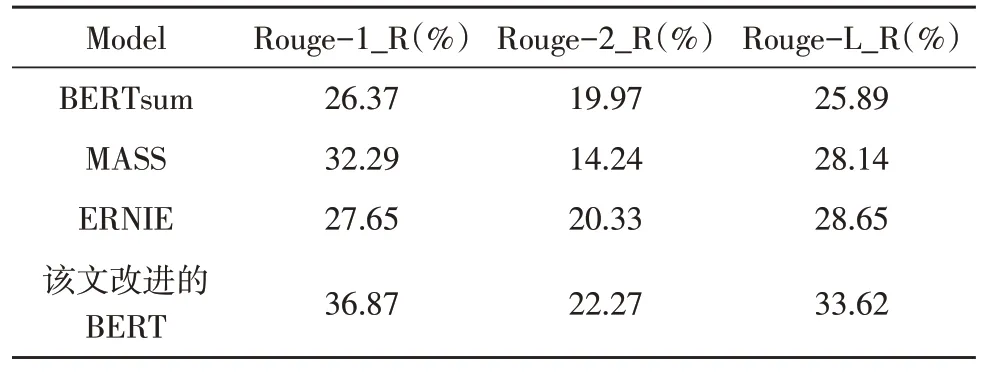
表4 四種模型的Rouge_R
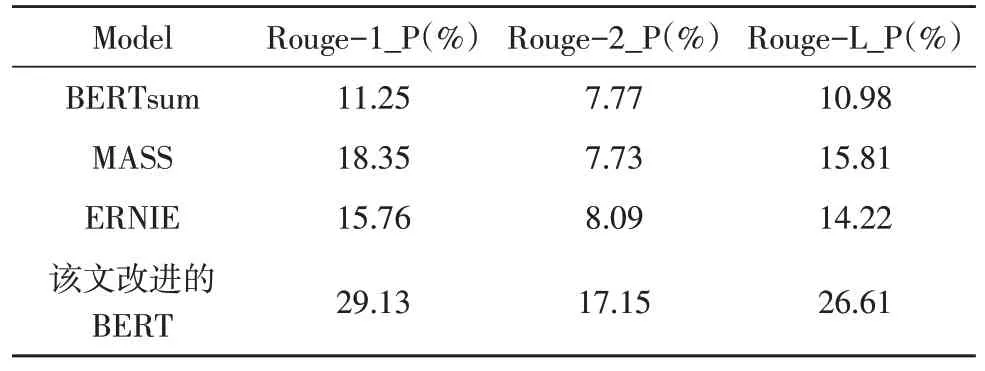
表5 四種模型的Rouge_P
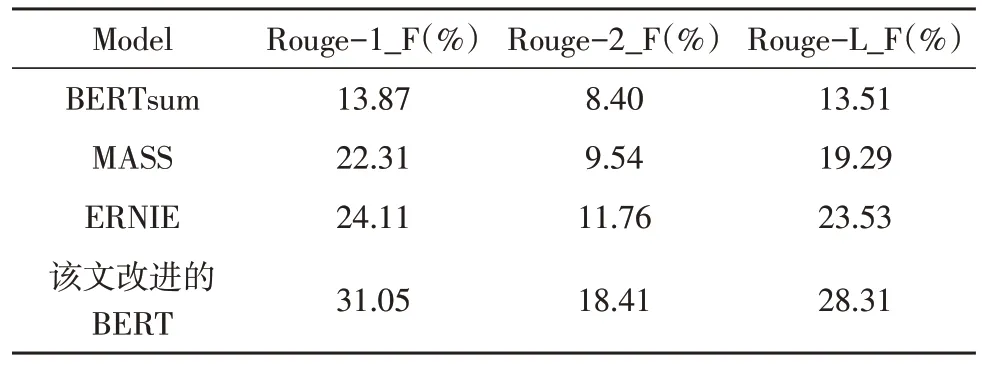
表6 四種模型的Rouge_F
實(shí)驗(yàn)中,除了對比原始BERT,還選擇采用長序列遮蓋策略的MASS 模型和針對中文數(shù)據(jù)集的ERNIE 模型進(jìn)行對比。由表中所示,改進(jìn)的BERT模型對比其他三種模型,在召回率、準(zhǔn)確率和F 值上都領(lǐng)先,其中對比原始BERT,F(xiàn) 值高出了10%~17%。
5 結(jié)論
為了在中文數(shù)據(jù)集上生成文本摘要,對原始BERTsum 進(jìn)行改進(jìn):1)在對數(shù)據(jù)預(yù)處理時,對中文文本進(jìn)行分詞處理,是一個詞語生成一個token,再進(jìn)行輸入或mask;2)在BERT 預(yù)訓(xùn)練過程中,改變mask 策略,遮蓋長度動態(tài)的長序列。實(shí)驗(yàn)結(jié)果表明,相較于BERTsum,改進(jìn)的BERT 在文本摘要任務(wù)上評價指標(biāo)Rouge-1_F 提高了17.18%,Rouge-2_F提高了10.01%,Rouge-L_F 提高了14.8%。對于BERT 模型,選擇遮蓋長序列能夠獲得比隨機(jī)遮蓋單一token 更好的預(yù)訓(xùn)練結(jié)果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
