重油加氫處理分子層次模型構建與原料適應性考察
2022-11-16 13:14:06關月明袁勝華張霖宙徐春明
石油學報(石油加工) 2022年6期
關鍵詞:模型
關 冬, 張 瑩, 張 成, 關月明, 袁勝華, 張霖宙, 徐春明
(1.中國石油大學(北京) 重質油國家重點實驗室,北京 102249;2.中國石化 大連石油化工研究院,遼寧 大連 116045)
“雙碳”背景下石油化工企業提質增效迫在眉睫,精準的石油加工過程模型將為石化行業轉型提供強大助力。石油加工過程建模伴隨著石化工業的發展,現如今,過程模型為實現石油資源最大化利用,在石化過程工藝設計、操作優化等諸多方面已經起到無可替代的作用[1]。自20世紀40年代起,石油煉制二次加工工藝蓬勃發展,50年代末期出現了最早的石油加工過程集總動力學模型,實現了石油加工過程產品收率的預測[2-3]。早期過程建模集中于集總動力學模型開發,采用集總形式可以極大簡化石油體系的復雜程度,其中具有代表性的模型如1968年Weekman[4]建立的催化裂化過程集總動力學模型,該模型對產物含量進行了預測。1969年,Qader和Hill[5]建立了減壓餾分油加氫裂化集總動力學模型,對主要產品產量和雜質脫除率進行了預測。隨后,諸多其他過程集總動力學模型相繼問世[6-8]。針對加氫過程,自Qader和Hill建立二集總減壓瓦斯油加氫裂化模型開始,加氫過程多集總以至于連續集總模型相繼被開發出來[6-7,9-12]。集總模型正向著精細化、復雜化方向發展,這是因為實際模型應用過程不再僅僅滿足加氫產品收率的預測,產品性質的預測顯得更為關鍵。由此,研究者在建模過程中納入越來越多分子層面信息,以期提高模型的精度,石油加工過程分子層次建模逐漸成為業內熱門的研究領域。
分子層次模型的研究始于20世紀90年代,許多分子層次建模的關鍵性技術相繼被開發[1,13-15]。Quann和Jaffe[13, 16]第一次在集總模型中引入了分子結構信息,提出了結構導向集總法(Structure-oriented lumping, SOL),合并簡化石油分子中大量分子結構,采用有限分子結構片段拼接表達石油分子,結合基團貢獻法,成功預測了油品性質,使模型的預測能力大為提升。Jaffe等[17]將該方法用于渣油分子組成與反應動力學建模。利用SOL法,Tian等[18-26]開發了延遲焦化、蒸汽裂解工藝等分子層次模型。SOL法在分子層次石油加工建模上擁有廣泛的應用[27-32]。與此同時,Klein課題組[14,33-37]采用更為細致的鍵電矩陣法描述和表達石油分子。Broadbelt等[34-35]將該方法應用于復雜反應體系建模,建立了從分子組成到反應過程的全流程分子層次建模方法。Klein課題組[38]也開發了KME (Kinetic model editor)和KMT (Kinetic modelers toolbox)分子管理軟件包。除此之外,Peng等[15]建立了同系物矩陣(Molecular-type homologous series, MTHS)法,Aye等[39]將該法用于石油餾分組成模型構建。筆者所在課題組[40-43]也提出了結構單元耦合鍵電矩陣(Structural unit and bond-electron matrix,SU-BEM)法,在保留分子結構細節的同時提高了可操作性,同時搭建了CUP分子管理軟件平臺,基于該平臺開發了加氫處理和催化裂化分子層次反應動力學模型。文獻報道的分子層次模型實現了不同石油加工過程的原料組成、產品組成及性質預測。對于輕質石油餾分加工過程,采用氣相色譜數據準確把握原料分子組成,為分子層次模型的準確性提供了基礎保證。對于重油餾分原料組成預測目前還停留在宏觀性質反演分子組成層面,重油原料分子分布的準確預測對重油分子層次加工模型的準確性尤為關鍵。
分子層次模型建立的關鍵在于準確把握石油體系的分子組成,對于重油體系,需要準確把握其特征分子結構。早期由于缺乏重油詳細的分子組成表征手段,分子層次模型的分子分布準確性沒有辦法得到有效驗證。近年來,重油分子層次表征技術突飛猛進,來自埃克森美孚公司的Qian等[44-45]通過高分辨質譜第一次實現了重油分子層次表征,在石油體系分子水平表征領域具有里程碑意義。為了能夠直接得到重油中的分子結構,Zhang等[46-48]將原子力顯微鏡技術引入重油分子結構解析領域,第一次觀察到重油中的分子結構,為基于質譜數據推斷重油分子結構提供了有力支撐。隨著高分辨質譜的發展,結合不同電離技術與預處理技術的重油分子表征方法不斷被開發出來,如采用甲基化+電噴霧電離源檢測石油中含硫化合物等[49-51]。因此,筆者所在課題組前期開發重油加氫處理分子層次模型時,采用高分辨質譜數據作為驗證原料與產物組成模型雜原子分子分布的手段,使模型更加細致,且準確地描述雜原子化合物在重油加氫處理過程的轉化規律,使模型在不同反應條件下產物性質預測能力大為提升[52-55]。然而,分子層次模型相比于集總模型的一大優勢在于原料適應性強,理論上將分子層次模型遷移到其他重油原料時,模型依然可以準確預測產物的分子組成與性質。
相較于以往分子層次重油加工模型,在重油原料分子組成模型構建過程中參照了高分辨質譜數據,以保證重油組成模型分子分布的準確性,反應模型構建過程中參照了高分辨質譜提示的雜原子反應規律,以保證反應模型的準確性。與此同時,在前期開發的重油加氫處理過程模型的基礎上,提出了分子層次模型的遷移方法,將模型應用于全新的重油原料,以考察分子層次模型的預測能力與原料適應性。
1 分子層次模型構建
分子層次模型以分子作為最小構筑單元,相比于集總模型具有更強外推/預測能力。石油加工過程分子層次模型中往往不止包含單一反應器,更為常見的是多反應器串聯或反應器-分餾塔串聯模型,如催化加氫、催化裂化等單元過程。與集總模型相比,分子層次模型在銜接前后反應裝置/分餾裝置模型時避免了原料集總的再次劃分,適用于多裝置聯合建模,更具發展前景。一般來說,分子層次模型開發包括7個步驟: (1)原料分子組成表征;(2)原料分子數字化;(3)原料組成模型構建;(4)分子反應網絡構建;(5)反應動力學模型構建;(6)反應器模型構建;(7)模型組合與優化,如圖1所示。由圖1可知,步驟(1)~(3)是原料分子組成模型構建部分,步驟(4)~(7)是反應過程模型構建部分。基于筆者所在課題組開發的石油加工分子管理平臺可高效完成上述模型搭建工作,該平臺的基礎架構采用SU-BEM框架,SU-BEM框架提供分子的數字化轉化方法,反應的數字化表達及分子物理化學性質計算方法,為油品組成模型構建及反應模型開發提供基礎[4,41]。

C—Carbon; H—Hydrogen; S—Sulfur; N—Nitrogen; O—Oxygen; CCR—Conradson carbon residue; SU—Structural unit;A6, N3, IH, NS, A4, AN—Chemical structures of structural units; R1—Reactor 1; R2—Reactor 2; R3—Reactor 3; R4—Reactor 4;k1—k9—Reaction rate constants圖1 分子層次模型開發流程示意圖Fig.1 Schematic diagram for the development process of molecular-level model
1.1 原料組成模型構建
原料組成模型構建對于開發重油加工過程分子層次模型尤為關鍵。對于重油,分子組成重構技術是獲取其定量分子組成的唯一方法。分子重構技術是指由油品的宏觀性質出發,尋找符合油品性質的代表性分子集的方法,由分子重構技術得到的油品分子組成被稱為分子組成模型。石油餾分分子組成模型主要包含2部分關鍵信息,足夠代表性的分子集和對應分子含量。分子含量是在分子集的基礎上優化得到的,優化目標往往是使組成模型的宏觀物性與實驗數據一致。組成模型優化過程往往不能直接優化每個分子的含量,這會造成優化參數過多而導致優化效率下降,值得慶幸的是石油體系中分子的含量分布往往符合一定的分布規律,這樣的分布規律又可以通過概率密度函數(Probability density function, PDF)描述。因此,通過優化概率密度函數參數的方式間接得到分子含量在提高優化效率的同時能夠很好地約束體系中分子分布,前期研究結果也證明了該方法的有效性[41,55]。
基于SU-BEM框架,通過優化PDF參數可以準確且高效地獲取原料組成模型。圖2給出了原料組成模型構建的具體流程,首先需要給定原料組成模型的分子集和PDF組合方式,分子集的獲取采用定義核心分子并延長其側鏈碳數完成,分子管理軟件平臺也具備了基于核心分子的分子集自動構建技術,PDF組合形式則可根據實驗數據靈活設置。拿到分子集后可對應獲得分子物性庫,通過給定分子含量初始值即可獲得油品宏觀物性,計算宏觀物性與實驗數據間的誤差,當誤差過大時,通過調整PDF參數間接調整分子含量,重新計算宏觀物性,直至原料組成模型中宏觀物性與實驗數據間的誤差達到允許值后輸出,原料組成模型構建完成。原料組成模型為分子層次模型構建提供了基礎數據。
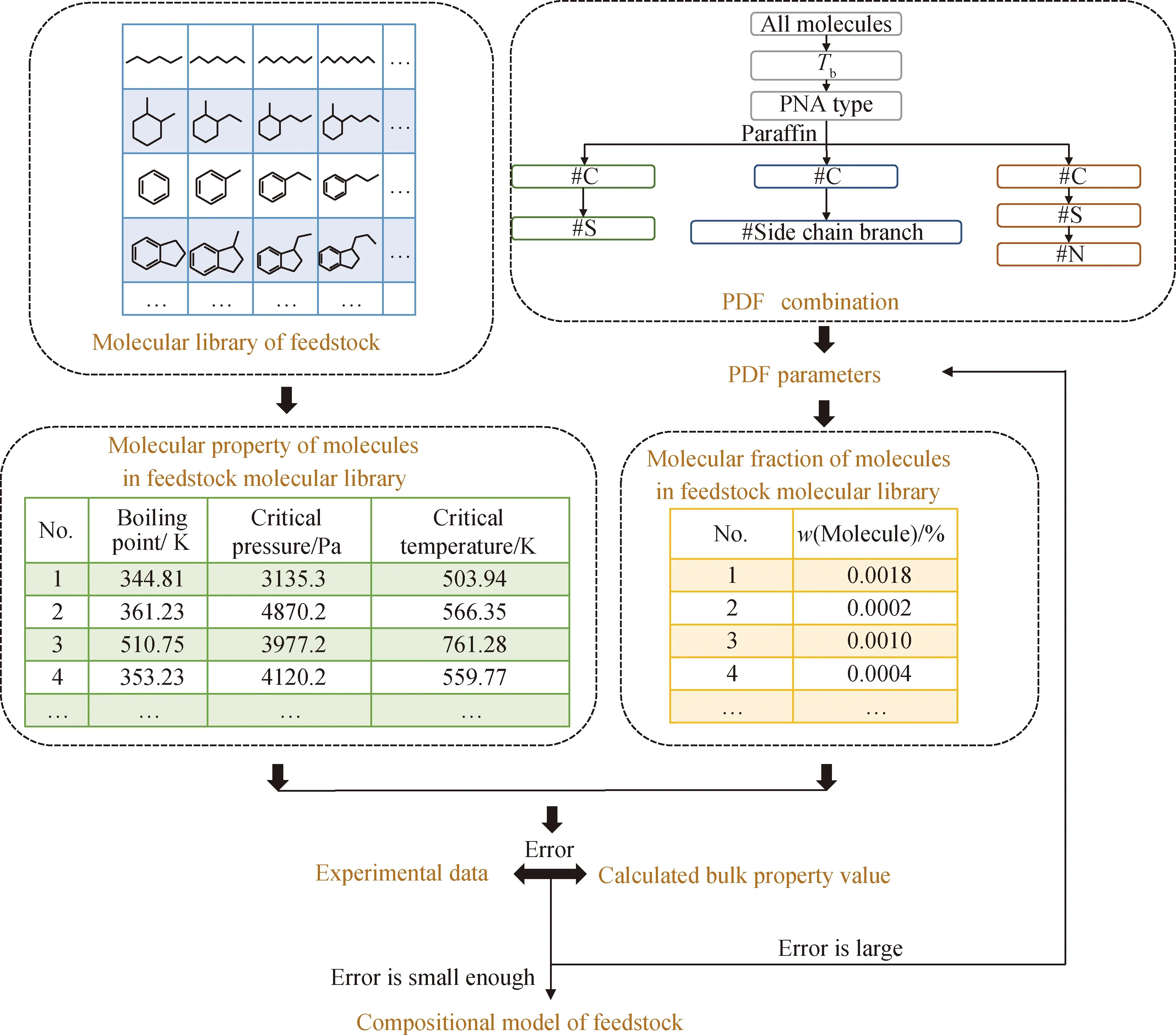
PDF—Probability density function; Tb—Boiling temperature圖2 原料組成模型構建流程示意圖Fig.2 Schematic diagram for the construction process of feedstock compositional model
1.2 反應過程模型構建
復雜體系的反應過程模型構建需要耦合體系的反應動力學模型,基于反應器內物料流動與相態的傳質模型及傳熱模型,構建難度較大。分子層次的復雜體系反應過程建模更是極具挑戰。對于輕質石油餾分尚可構建其機理層面分子層次反應動力學模型,如蒸汽裂解過程,而重油加工過程由于原料組成的復雜性,只能從反應路徑層面完成分子層次反應動力學建模。
SU-BEM框架提供了基礎的反應規則制定與反應網絡構建方法,反應動力學模型構建則需要在反應網絡的基礎上確定各反應的速率,同時需要根據反應器內物料的流動狀態確定傳質速率,進而由原料組成模型得到產物組成模型。圖3給出了反應模型的構建過程,輸入端為原料組成模型,原料分子遍歷反應規則后形成反應網絡,反應網絡中包含的分子包括原料分子及新生成的產物分子。與原料組成模型構建法類似,反應過程模型的優化目標也是獲得產物分子含量并優化各反應速率。值得注意的是,若反應過程模型中包含反應器信息,則需要根據反應物在反應器內的流動狀態確定傳質方程,將傳質系數等模型參數納入優化變量中。優化目標是使產物分子含量和性質與實驗數據達到允許誤差,當誤差較大時,需要重新優化反應過程模型參數。理論上,分子層次反應過程模型參數在后續模型應用過程中無需重新訓練。
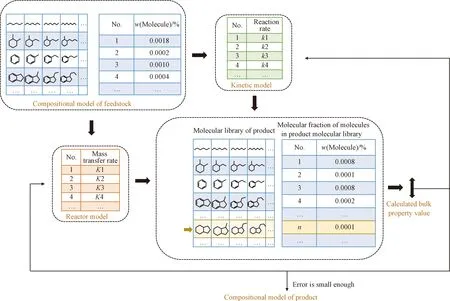
圖3 反應模型構建流程示意圖Fig.3 Schematic diagram for the construction process of reaction model
2 重油加氫處理分子層次模型構建與驗證
2.1 模型構建
為了考察分子層次模型的預測能力,基于前期工作[55]完成的重油加氫處理分子層次模型,采用全新目標重油原料,優化其分子組成模型并預測其加氫處理產物組成,以考察模型的預測能力與原料適應性。理論上,模型預測能力與模型的精細程度正相關,原料組成模型對分子分布規律及反應模型對分子轉化規律的描述越準確,模型預測能力越強。因此,前期工作在模型搭建過程中引入了傅里葉變換離子回旋共振質譜(FT-ICR MS)數據,簡稱高分辨質譜,用于原料組成模型分子分布和反應轉化規律準確性的驗證,重油加氫處理過程分子層次組成模型構建過程如圖4所示,構建過程與前期工作一致[55]。基于高分辨質譜檢測數據與目前已鑒定出的石油中的分子結構,定義了重油核心分子156個,包括正構烷烴、異構烷烴、環烷烴、芳香烴、芳香-環烷混合烴及含S、N、O的雜原子化合物,忽略含量極少的金屬卟啉類化合物,包含常見的雜原子化合物,如硫醚、噻吩、吡啶、吡咯、環烷酸及酚類化合物,經側鏈拓展后預置分子集共包含不同結構分子數為12734個。基于SU-BEM框架,采用上文所述優化方法,最終得到原料組成模型。
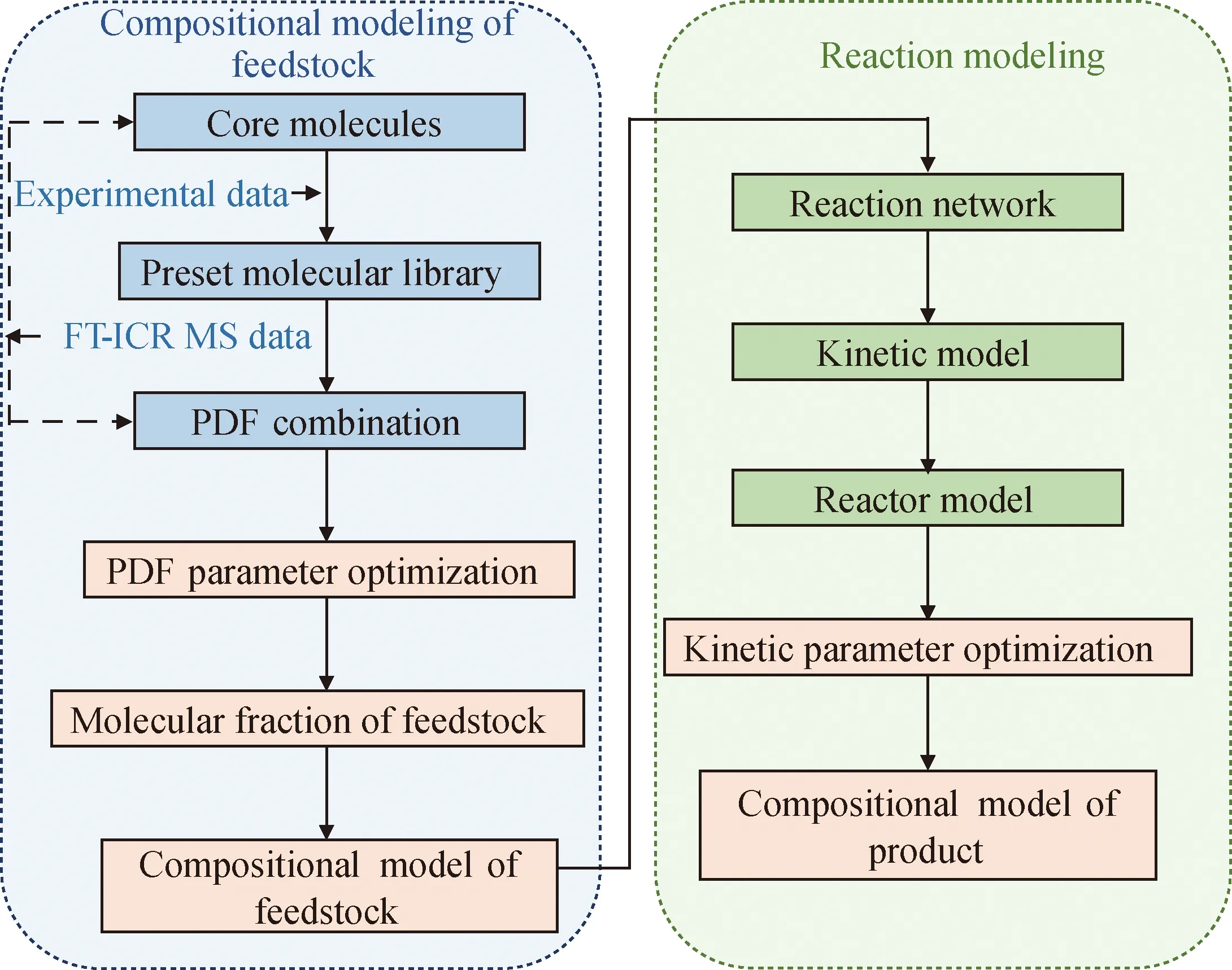
PDF—Probability density function; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry圖4 重油加氫處理過程分子層次模型構建流程圖Fig.4 Flow chart for molecular-level model construction during heavy oil hydrotreating
原料組成模型構建完成后,將其用于反應過程模型構建。反應過程模型需與實驗過程保持一致,并盡可能描述反應器內所發生的物料流動、相變及反應。圖5給出了模型所用重油加氫處理裝置示意圖,該過程采用固定床加氫處理反應器串聯模式,不同反應器內裝填不同種類催化劑,用以實現不同雜原子化合物的脫除[56-57]。以圖5所示反應流程為基礎,構建反應過程模型如圖4所示,首先以組成模型作為輸入,依據重油加氫處理過程反應機理,通過制定反應規則并遍歷反應物分子完成反應網絡構建。重油加氫處理過程采用雙功能催化劑,重油分子在酸性中心主要發生裂化反應,包括烷烴裂化、環烷烴開環、芳烴脫烷基反應等,在金屬中心主要發生加氫反應,包括加氫脫硫、加氫脫氮、加氫脫氧、芳香環飽和等。由于重油體系過于龐大,筆者在制定反應規則時,忽略了部分次要反應,在反應路徑層面合并部分反應路徑以減少不必要的中間分子生成,采用的反應規則與前期工作一致,形成的反應網絡中共包含分子 17351個,反應25591個[57]。反應網絡構建完成后,還需將反應網絡轉化為反應速率表達式并與反應器傳質方程耦合。滴流床反應器內的物料呈氣-液-固三相共存狀態,加上復雜的物料組成部分,反應模型構建難度極大,因此,在保證模型精度的前提下,采用平推流模型降低模型求解難度,所用質量平衡方程如式(1)~式(5)所示。
氣相質量平衡方程如公式(1)所示。
(1)
液相質量平衡方程如公式(2)所示。
(2)
固相質量平衡方程如公式(3)所示。
(3)
將公式(3)代入公式(2)得到液相質量平衡如公式(4)所示。
(4)
基于課題組前期工作[57],加氫處理過程反應速率表達式可以采用LHHW方程表示。如方程(5)所示:
(5)
將原料組成模型與反應網絡帶入上述式(1)~式(5)中,構成常微分方程組,通過數值計算求得最終解,值得注意的是模型中包含上萬個分子,說明該常微分方程組由數萬個常微分方程組成,可見求解難度之大。最后,采用實驗分析得到的產物數據訓練并最終得到合適的反應動力學模型參數完成反應模型構建,參數訓練過程見前期工作[57]。

圖5 重油固定床加氫處理裝置示意圖Fig.5 Schematic diagram of heavy oil fixed bed hydrotreating
2.2 模型驗證
分子層次重油加氫處理過程模型構建完成后,以硫化物的分布為例,證明分子層次模型的精度,如圖6所示。由于不同組高分辨質譜數據間無法定量比較,以原料、中間產物和最終產物組成模型中各自硫化物總體質量含量為基準,統計了不同類型硫化物的質量比例變化,并與高分辨質譜數據進行比較。圖6模型計算結果顯示:原料中硫化物質量分數從大到小依次為苯并噻吩類、二苯并噻吩類、噻吩類;從重油原料到加氫后的重油產物中噻吩類和苯并噻吩類化合物質量分數逐漸下降,而二苯并噻吩類化合物質量分數略有提升,說明噻吩和苯并噻吩類化合物較為容易脫硫,而二苯并噻吩類化合物難以脫除,這與實驗規律一致,如4,6-二甲基二苯并噻吩的空間位阻作用導致其脫硫十分困難[2]。綜上表明硫化物的脫除難度與其環數正相關。分子層次重油加氫處理模型計算結果也與高分辨質譜得到的分子轉化規律一致。除此之外,由圖6可知,模型計算結果在原料與產物宏觀性質、氮化物和氧化物分子分布與轉化規律上均與實驗數據一致,證明了分子層次重油加氫處理模型的準確性。

R—Side-chain carbon number; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry圖6 模型計算結果的硫化物分子分布與FT-ICR MS數據對比Fig.6 Comparison between model calculation results for the molecular distribution of sulfides and FT-ICR MS data(a1)—(a3) Sulfur-containing species in the feedstock; (b1)—(b3) Sulfur-containing species in the intermediate products;(c1)—(c3) Sulfur-containing species in the final products
3 重油加氫處理分子層次模型原料適應性考察
分子層次模型相比于傳統集總模型的優勢在于原料適應性強,因此,將模型應用于不同重油原料(模型遷移),以考察模型的原料適應性。集總模型在進行模型遷移時,需要針對全新原料重新劃分集總,其后續反應動力學模型參數同樣需要重新訓練,原料適用性差。分子層次模型在模型遷移過程中,僅需優化組成模型中的分子含量,使其與新原料匹配即可,后續反應動力學參數無需重新訓練。重油加氫處理分子層次模型的模型遷移流程如圖7所示。首先需要表征重油原料1的分子組成與宏觀物性,用于重油原料1的組成模型構建,重油原料2的組成模型只需在重油原料1的組成模型基礎上優化模型參數,進而得到重油原料2的組成模型分子含量即可。組成模型構建完成后,將其輸入反應模型中,預測產物組成與性質,反應模型參數采用優化完成的重油加氫處理分子層次模型參數[57]。
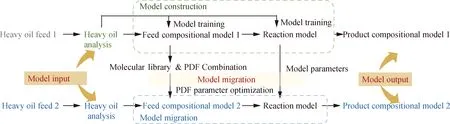
PDF—Probability density function圖7 重油加氫處理分子層次模型構建與遷移流程Fig.7 Construction and migration process of molecular-level model for heavy oil hydrotreating
3.1 原料組成模型優化結果
為了證明重油分子組成模型具有較強的原料適應性,采用圖7模型遷移方案,得到重油原料2的組成模型。對比重油加氫處理分子層次模型構建時的原料重油(重油原料1)與采用的目標重油(重油原料2)的模型構建結果,如表1所示。重油原料1與重油原料2 為來源于國內不同煉油廠的重油加氫處理原料油,2種重油原料在雜原子含量上差異較大,適用于模型的原料適應性考察。由表1可知,原料組成模型的預測值均與實驗數據保持一致,尤其是重油加氫處理過程中最為關鍵的雜原子含量與殘炭值,相比于重油原料1,重油原料2的硫含量較高,氮含量和氧含量較低,殘炭值略高,原料組成模型很好地再現了目標重油原料的特點。

表1 重油組成模型構建結果與實驗值對比Table 1 Comparison between the results of heavy oil compositional model construction and experimental data
進一步將重油原料2組成模型中雜原子分子分布結果與高分辨質譜數據對比,如圖8所示,以不同類型雜原子化合物的高分辨質譜數據為準,將雜原子化合物含量歸一化,統計了典型化合物在同種雜原子化合物中所占比例及分子分布情況。由圖8可知,重油原料2中硫化物與氮化物分子分布規律與高分辨質譜數據十分接近,如硫化物中噻吩類化合物分子分布中心位于C35左右,與高分辨數據相差無幾,分子分布峰形寬度十分接近。重油原料2組成模型計算結果顯示,其硫化物含量由大到小依次為苯并噻吩類>二苯并噻吩類>噻吩類,與圖6中重油原料1中的硫化物分布規律相同。重油原料2氮化物含量排序由大到小依次為苯并喹啉類≈喹啉類>吡啶類。重油原料2的組成模型在保證重油原料宏觀性質與實驗數據一致的前提下,很好地保證了其雜原子分子分布與高分辨質譜的一致性,證明重油原料2的組成模型具有較高準確性。
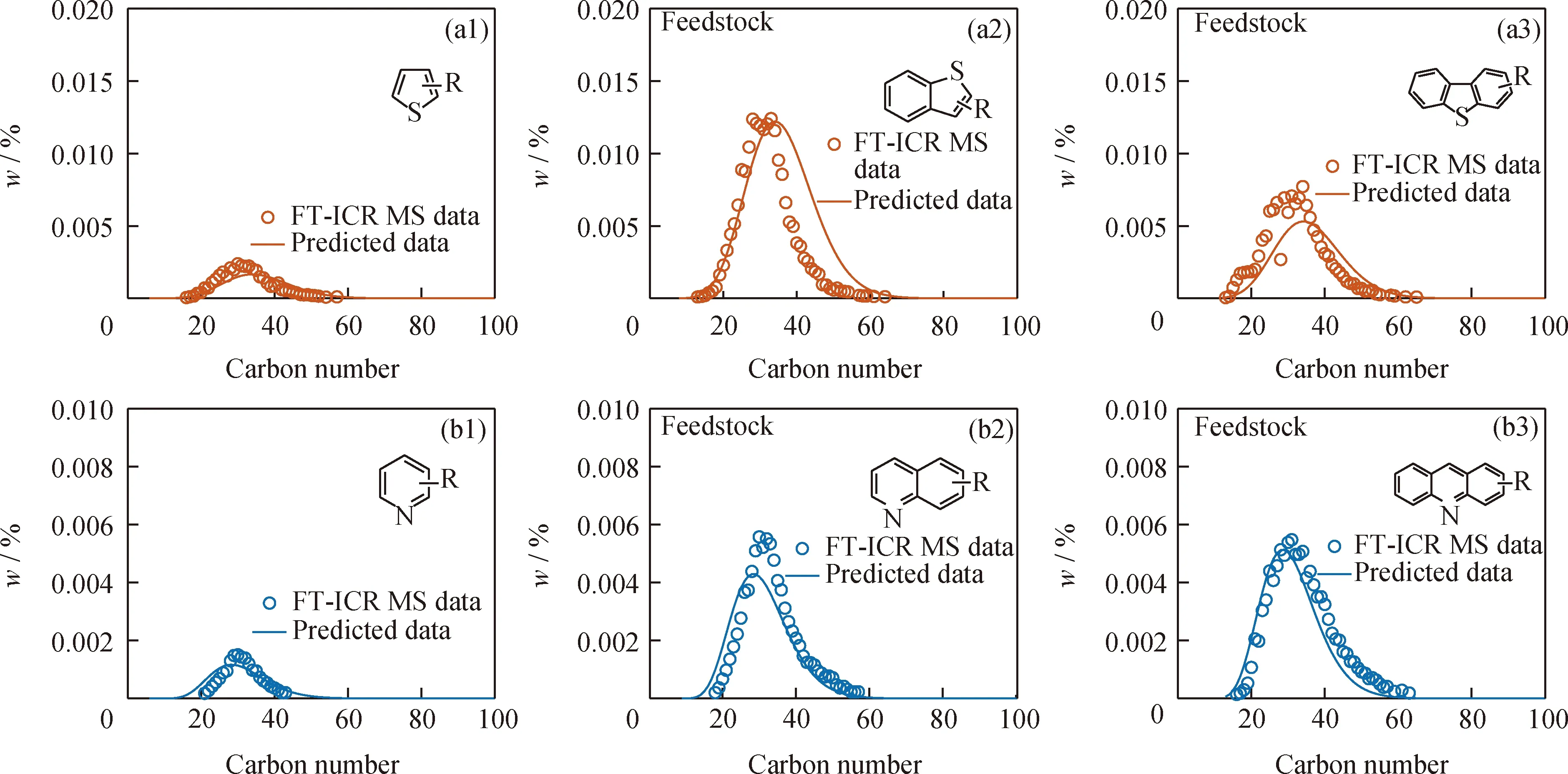
R—Side-chain carbon number; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry圖8 重油原料2組成模型分子分布與FT-ICR MS數據對比Fig.8 Comparison between the molecular distribution of compositional model for heavy oil feed 2 and FT-ICR MS data(a1)—(a3) Sulfur-containing species; (b1)—(b3) Nitrogen-containing species
3.2 反應模型預測結果
將重油原料2的組成模型輸入反應模型中,求解產物組成與性質。重油加氫處理實驗條件為:反應器入口溫度386 ℃,反應壓力17 MPa,氫/油體積比680 m3/m3,液時空速為0.2 h-1。設置完成重油加氫處理分子層次模型的實驗條件后,運行模型并得到產物性質,結果如圖9所示。由圖9可知,不同反應器出口產物模型中的關鍵參數如硫含量、氮含量與殘炭值(Conradson carbon residue, CCR)的預測結果與實驗值較為吻合,說明重油加氫處理分子層次模型很好地描述了重油加氫過程中硫、氮元素及CCR值的脫除效果。
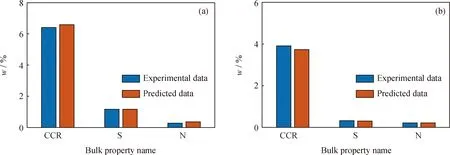
S—Sulfur; N—Nitrogen; CCR—Conradson carbon residue圖9 各反應器出口產物S、N元素含量和CCR預測值與實驗值對比Fig.9 Comparison between S and N element content and CCR predicted value of the productat the outlet of each reactor and the experimental data(a) Intermediate product; (b) Final product
為了證明重油加氫處理分子層次模型很好地描述了重油原料2加氫處理過程分子轉化規律,進一步比較各反應器出口反應產物的雜原子化合物的分布與高分辨質譜數據,如圖10所示。圖10中分別統計了重油原料2加氫處理后典型硫化物及氮化物在中間產物和最終產物中分子分布情況。由圖10可知:與原料相比,產物的硫化物中噻吩類及苯并噻吩類化合物比例隨反應的進行逐步下降,二苯并噻吩類化合物含量略有提升,說明二苯并噻吩類化合物難以脫除;產物中的典型氮化物,如吡啶類、喹啉類和苯并喹啉類化合物比例與原料保持一致,說明氮化物的反應規律與硫化物不同,其脫除難度與環數無關;重油加氫處理分子層次模型的計算結果與高分辨質譜數據吻合,與重油原料1的加氫處理產物組成模型結果一致(見圖6),重油原料2的加氫處理產物組成模型結果同樣展現了與實驗數據的一致性。以上結果表明,構建的重油加氫分子層次模型具有一定的原料適應性,可以直接用于不同原料的組成及產物性質與分子分布預測。

R—Side-chain carbon number; FI-ICR MS—Fourier transform ion cyclotron resonance mass spectrometry圖10 重油原料2加氫處理后產物組成模型分子分布與FT-ICR MS數據對比Fig.10 Comparison between the molecular distribution of product compositional model after hydrotreating ofheavy oil feed 2 and FT-ICR MS data(a1)—(a3) Sulfur-containing species in the intermediate products; (b1)—(b3) Nitrogen-containing species in the intermediate products;(c1)—(c3) Sulfur-containing species in the final products; (d1)—(d3) Nitrogen-containing species in the final products
4 結 論
介紹了分子層次模型的構建方法,并將其用于重油加氫處理分子層次模型的構建。提出了分子層次模型的模型遷移策略,考察了重油加氫處理分子層次模型的產物性質預測能力與原料適應性。結果表明,構建的重油加氫處理分子層次模型具有一定的油品性質預測能力及原料適應性。相比于集總模型,分子層次模型更加適用于煉油過程多裝置聯合優化甚至全廠優化,分子層次模型更具工業應用前景。原料分子組成模型的準確性是保證分子層次模型產物性質預測精度及原料適應性的關鍵,利用先進表征技術提升原料分子組成模型精度是分子層次模型的發展趨勢。在反應模型中有效結合反應機理、催化劑性能、物料流動狀態及物料相態變化,準確回歸動力學參數是急需解決的關鍵問題。
符號說明:
aL——氣-液傳質面積,cm-1;
aS——液-固傳質面積,cm-1;
Badsi——物質i的吸附常數;
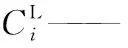
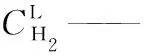
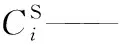
hi——物質i的亨利系數, MPa cm3/mol;
ksrij——反應j的表面反應速率常數,h-1;
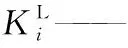
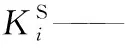
m——反應物的反應級數;
p——反應器壓力,MPa;
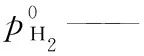
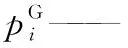
R——理想氣體常數, J/(mol·K);
rH/O——氫/油體積比,m3/m3;
ri——物質i所參與的總反應速率,mol/(cm3·h);
rij——反應j的反應速率,mol/(cm3·h);
T——反應器溫度,K;
ug——氣相平均流速,cm/s;
uL——液相平均流速,cm/s;
z——反應器長度,cm;
ηi——物質i的內擴散有效因子;
ρb——催化劑堆密度,g/cm3。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
