基于黏菌算法優(yōu)化VMD-CNN-GRU模型的年徑流預(yù)測(cè)
2022-11-15 09:10:29徐冬梅夏王萍王文川
南水北調(diào)與水利科技 2022年3期
徐冬梅,夏王萍,王文川
(華北水利水電大學(xué)水資源學(xué)院,鄭州 450046)
中長(zhǎng)期水文預(yù)報(bào)是水資源規(guī)劃管理、防汛抗旱、水庫(kù)優(yōu)化調(diào)度的重要環(huán)節(jié),其研究一直受到眾多水文學(xué)者的廣泛關(guān)注[1]。隨著科學(xué)技術(shù)的不斷發(fā)展,許多現(xiàn)代人工智能技術(shù)方法被應(yīng)用于水文預(yù)報(bào),例如BP(back propagation)神經(jīng)網(wǎng)絡(luò)[2-3]、徑向基神經(jīng)網(wǎng)絡(luò)[4-5]、Elman神經(jīng)網(wǎng)絡(luò)[6-7]、支持向量機(jī)[8-9]、自適應(yīng)模糊推理系統(tǒng)[10-11]、長(zhǎng)短時(shí)記憶神經(jīng)網(wǎng)絡(luò)(long short-term memory,LSTM)[12-13]等。
卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)是一種前饋式神經(jīng)網(wǎng)絡(luò),能夠充分挖掘數(shù)據(jù)之間的相關(guān)性,已被應(yīng)用于物體識(shí)別[14]、故障診斷[15]、文本分類[16]等方面。門控循環(huán)單元神經(jīng)網(wǎng)絡(luò)(gated recurrent unit,GRU)是循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)衍生體系結(jié)構(gòu)中的一種典型體系結(jié)構(gòu),常用于時(shí)間序列數(shù)據(jù)預(yù)測(cè),能夠解決梯度消失的問(wèn)題,已在負(fù)荷預(yù)測(cè)[17]、氣象要素預(yù)測(cè)[18]、風(fēng)速預(yù)測(cè)[19]等領(lǐng)域得到應(yīng)用。在徑流預(yù)測(cè)方面的研究有:郭玉學(xué)等[20]利用多種遞歸神經(jīng)網(wǎng)絡(luò)對(duì)海島水庫(kù)進(jìn)行徑流預(yù)報(bào),通過(guò)對(duì)比研究發(fā)現(xiàn)具有復(fù)雜神經(jīng)元結(jié)構(gòu)的長(zhǎng)短時(shí)記憶神經(jīng)網(wǎng)絡(luò)和門控循環(huán)單元神經(jīng)網(wǎng)絡(luò)預(yù)報(bào)效果更好;李文武等[21]將相空間重構(gòu)與變分模態(tài)分解(variational mode decomposition,VMD)和深度門控網(wǎng)絡(luò)耦合,該模型對(duì)白山水庫(kù)入庫(kù)月徑流量進(jìn)行預(yù)測(cè),在測(cè)試集上擬合效果較好;包苑村等[22]提出了一種VMD-CNN-LSTM組合模型,對(duì)渭河流域的2個(gè)水文站進(jìn)行月徑流預(yù)測(cè),預(yù)測(cè)精度對(duì)比其他模型更優(yōu)且在預(yù)測(cè)峰值和谷值上優(yōu)勢(shì)更為明顯。為了提高傳統(tǒng)CNN、GRU單一模型預(yù)測(cè)精度,學(xué)者們已經(jīng)提出卷積神經(jīng)網(wǎng)絡(luò)和門控循環(huán)單元神經(jīng)網(wǎng)絡(luò)的組合模型(CNN-GRU)并應(yīng)用于多種領(lǐng)域。如:姚程文等[23]將CNN-GRU模型用于電力負(fù)荷數(shù)據(jù)預(yù)測(cè),該模型在預(yù)測(cè)精度與預(yù)測(cè)效率方面有較好的結(jié)果;黨建武等[24]將CNN-GRU模型用于股指預(yù)測(cè),有效提高了股指預(yù)測(cè)的準(zhǔn)確率;針對(duì)出菇房室內(nèi)溫濕度具有非線性等特點(diǎn),趙全明等[25]利用CNN-GRU模型預(yù)測(cè)出菇房多點(diǎn)溫濕度,相比較傳統(tǒng)的BP神經(jīng)網(wǎng)絡(luò)等CNN-GRU模型預(yù)測(cè)精度更高。
針對(duì)多數(shù)CNN-GRU混合神經(jīng)網(wǎng)絡(luò)超參數(shù)的設(shè)置方法存在精度和效率偏低的問(wèn)題,本文在引入CNN-GRU組合模型進(jìn)行年徑流預(yù)測(cè)工作中,采用黏菌優(yōu)化算法(slime mould algorithm,SMA)來(lái)確定關(guān)鍵參數(shù),提出基于SMA優(yōu)化的VMD-CNN-GRU組合模型對(duì)蘭西水文站年徑流進(jìn)行預(yù)測(cè),并構(gòu)建CEEMDAN (complete ensemble empirical mode decomposition with adaptive noise)-CNN-GRU、VMD-CNN-LSTM、VMD-GRU、VMD-LSTM、VMD-PSO (particle swarm optimization)-CNN-GRU、SMA-CNN-GRU和CNN-GRU作為對(duì)比模型,以驗(yàn)證本文提出模型的有效性。
1 研究方法
1.1 變分模態(tài)分解算法(VMD)
VMD是2014年提出的一種新的處理信號(hào)的算法[26],分解信號(hào)的同時(shí)還能夠降低輸入信號(hào)中存在的噪聲,因此在處理非線性非平穩(wěn)序列上具有一定的優(yōu)勢(shì),相較于2011年由Torres等[27]提出的自適應(yīng)噪聲完整集成經(jīng)驗(yàn)?zāi)B(tài)分解算法(CEEMDAN),VMD可以有效地分離信號(hào)。VMD是給實(shí)際輸入信號(hào)尋找一組最優(yōu)重構(gòu)的模態(tài)集合,而每個(gè)模態(tài)都被約束在一個(gè)估計(jì)的中心頻率上。當(dāng)給序列確定恰當(dāng)?shù)哪B(tài)分解個(gè)數(shù)后,VMD就可以將非線性的原始序列分解成若干個(gè)具有不同頻率并相對(duì)平穩(wěn)的子序列。詳細(xì)的VMD實(shí)現(xiàn)步驟請(qǐng)參閱文獻(xiàn)[26]。
1.2 卷積神經(jīng)網(wǎng)絡(luò)(CNN)
卷積神經(jīng)網(wǎng)絡(luò)[28]是一種獨(dú)特的深度網(wǎng)絡(luò)。輸入層、全連接層和輸出層的結(jié)構(gòu)與其他神經(jīng)網(wǎng)絡(luò)的基本相同,獨(dú)特之處在于CNN擁有池化層和卷積層的結(jié)構(gòu)。池化層能夠篩選過(guò)濾掉多余的信息,不僅減少全連接層中的參數(shù)個(gè)數(shù)防止過(guò)擬合問(wèn)題的出現(xiàn),而且縮短了訓(xùn)練的時(shí)間。卷積層中的卷積核(過(guò)濾器)可以實(shí)現(xiàn)對(duì)輸入矩陣自動(dòng)提取特征,并且卷積層的權(quán)值將在神經(jīng)元之間共享。
1.3 門控循環(huán)單元神經(jīng)網(wǎng)絡(luò)(GRU)
門控循環(huán)單元神經(jīng)網(wǎng)絡(luò)是對(duì)長(zhǎng)短時(shí)記憶神經(jīng)網(wǎng)絡(luò)[29]進(jìn)行了改進(jìn)。GRU和LSTM都是通過(guò)“門”函數(shù)來(lái)進(jìn)行計(jì)算的,不同之處在于GRU比LSTM少了一個(gè)“門”簡(jiǎn)化了模型結(jié)構(gòu)。GRU只有兩個(gè)門,即更新門和重置門。GRU與LSTM運(yùn)算效果相差不大,但由于GRU參數(shù)少故計(jì)算速度更快。GRU神經(jīng)網(wǎng)絡(luò)內(nèi)部結(jié)構(gòu)見圖1。

圖1 GRU網(wǎng)絡(luò)基本結(jié)構(gòu)Fig.1 Basic structure of GRU
GRU的前向計(jì)算公式為
更新門:zt=σ(Wz·[ht-1,xt])
(1)
重置門:rt=σ(Wr·[ht-1,xt])
(2)
(3)
(4)
yt=σ(Wo·ht)
(5)

1.4 黏菌算法(SMA)
黏菌優(yōu)化算法由Li等[30]于2020年提出,根據(jù)黏菌多頭絨泡菌在尋找食物過(guò)程中發(fā)生的一系列動(dòng)作和身體上的變化來(lái)建立數(shù)學(xué)模型。文獻(xiàn)[28]證明了該算法在實(shí)際問(wèn)題中能夠快速收斂并找到最優(yōu)值。詳細(xì)的數(shù)學(xué)模型如下。
階段1:接近食物。黏菌可以通過(guò)空氣中的氣味來(lái)尋找食物,具體用公式表示為
(6)

p=tanh|S(i)-DF|,i=1,2,…,n
(7)
式中:S(i)為每個(gè)黏菌的適應(yīng)度;DF為迭代過(guò)程中最佳適應(yīng)度。
(8)
(9)
SmellIndex=sort(S)
(10)
式中:Condition表示適應(yīng)度值排在種群數(shù)前1/2的個(gè)體;r為在[0,1]上的隨機(jī)數(shù);maxt為最大迭代次數(shù);bF(bestFitness)和wF(westFitness)為當(dāng)前迭代中的最優(yōu)和最差適應(yīng)度值;SmellIndex為排序后的適應(yīng)度值序列。
階段2:包圍食物。搜索食物時(shí),黏菌體內(nèi)會(huì)受食物濃度的影響產(chǎn)生一種信號(hào)。黏菌靜脈接觸的食物濃度越高,體內(nèi)產(chǎn)生的波越強(qiáng),細(xì)胞質(zhì)流動(dòng)越快,靜脈變得越粗。當(dāng)食物濃度較高時(shí),該區(qū)域附近的權(quán)重較大;當(dāng)食物濃度較低時(shí),該區(qū)域的權(quán)重會(huì)降低。更新黏菌位置的計(jì)算公式為
(11)
式中:LB和UB分別為搜索范圍的上下邊界值;rand和r為[0,1]中的隨機(jī)數(shù)。
SMA算法進(jìn)行參數(shù)尋優(yōu)的步驟如下。
步驟1:初始化SMA參數(shù)。設(shè)置種群規(guī)模n、最大迭代次數(shù)M、優(yōu)化參數(shù)的個(gè)數(shù)及其范圍,令當(dāng)前的迭代次數(shù)t=1。初始化個(gè)體,隨機(jī)生成n個(gè)黏菌個(gè)體的初始化位置。
步驟2:選用均方誤差作為優(yōu)化目標(biāo)函數(shù)。將每個(gè)黏菌個(gè)體位置向量依次作為CNN-GRU模型的前提參數(shù),根據(jù)均方誤差的公式分別計(jì)算出各自對(duì)應(yīng)的適應(yīng)度值,然后對(duì)適應(yīng)度值進(jìn)行排序,選出最優(yōu)和最差適應(yīng)度值。

步驟4:令t=t+1。判斷t是否小于最大迭代次數(shù)M,若是則重復(fù)步驟2和步驟3,反之則輸出最優(yōu)個(gè)體,即算法的最優(yōu)解,算法結(jié)束。
1.5 組合模型構(gòu)建
基于SMA優(yōu)化的VMD-CNN-GRU模型的構(gòu)建流程圖見圖2,具體的預(yù)測(cè)步驟總結(jié)如下。

圖2 預(yù)測(cè)模型構(gòu)建Fig.2 Prediction model construction
采用VMD方法對(duì)原始的徑流序列進(jìn)行分解后得到若干子序列。
建立SMA-CNN-GRU模型。設(shè)置黏菌算法中的參數(shù),再利用黏菌算法對(duì)CNN-GRU模型的卷積層層數(shù)N、GRU層神經(jīng)元個(gè)數(shù)H、訓(xùn)練次數(shù)E和學(xué)習(xí)率η進(jìn)行參數(shù)尋優(yōu)。具體步驟見1.4節(jié)。
根據(jù)建立的SMA-CNN-GRU模型對(duì)預(yù)處理后的每個(gè)分量進(jìn)行擬合得到預(yù)測(cè)值。
將所有預(yù)測(cè)后的子序列進(jìn)行進(jìn)一步累積得到最終結(jié)果。
1.6 模型驗(yàn)證
采用均方根誤差(ERMS)、平均絕對(duì)誤差(EMA)、平均絕對(duì)百分誤差(EMAP)對(duì)模型進(jìn)行評(píng)價(jià)。ERMS、EMA、EMAP的計(jì)算公式為
(12)
(13)
(14)

2 實(shí)例應(yīng)用
蘭西站是呼蘭河下游的一個(gè)水文站,斷面以上集水面為27 736 km2,距河源464 km。呼蘭河是松花江左岸一級(jí)支流,全長(zhǎng)515 km,集水面積為36 631 km2。以蘭西水文站1959—2014年的年徑流資料為研究對(duì)象,取1959—2002年年徑流數(shù)據(jù)為訓(xùn)練集,2003—2014年年徑流數(shù)據(jù)為測(cè)試集。1959—2014年蘭西水文站年徑流序列見圖3。

圖3 蘭西水文站年徑流序列Fig.3 Annual runoff series of Lanxi hydrological station
2.1 VMD分解時(shí)序數(shù)據(jù)
VMD分解徑流序列的關(guān)鍵是提前設(shè)置合適的模態(tài)個(gè)數(shù)K,不同分解個(gè)數(shù)會(huì)影響分解的結(jié)果,進(jìn)而影響最終的預(yù)測(cè)結(jié)果。K值偏高可能導(dǎo)致模態(tài)混合或純?cè)肼暷B(tài),K值偏低可能導(dǎo)致模態(tài)的重復(fù)。通過(guò)比較各分量中心頻率的方法來(lái)確定最終的模態(tài)個(gè)數(shù)K[31]。當(dāng)選擇不同的K值時(shí),對(duì)蘭西水文站年徑流序列進(jìn)行VMD分解后得到各子序列的中心頻率,見表1。從表1可以看出,在K=7時(shí),出現(xiàn)的中心頻率3 156 Hz和3 492 Hz相差不多,說(shuō)明此時(shí)可能出現(xiàn)模態(tài)混疊現(xiàn)象,所以選K=6較為合適。

表1 不同K值對(duì)應(yīng)的中心頻率Tab.1 The central frequency corresponding to various K values
圖4是分解后6個(gè)不同頻率的子序列。對(duì)比圖3原徑流序列振幅變化沒有明顯的規(guī)律,由圖4看出隨著模態(tài)分量的增加,序列振幅變化呈現(xiàn)出周期性,序列越來(lái)越穩(wěn)定,這個(gè)預(yù)處理使CNN-GRU模型可以更好地模擬數(shù)據(jù)中的特征信息并進(jìn)行預(yù)測(cè)。

圖4 蘭西水文站年徑流VMD分解圖Fig.4 VMD decomposition diagrams of annual runoff at Lanxi hydrological station
2.2 參數(shù)設(shè)置
在CNN-GRU模型中,根據(jù)一般經(jīng)驗(yàn),每層卷積核的數(shù)量為上一層的兩倍。根據(jù)黨建武等[24]的研究,再結(jié)合本文實(shí)例得到設(shè)置不同卷積層時(shí)各層對(duì)應(yīng)的卷積核個(gè)數(shù),具體數(shù)值見表2。

表2 不同卷積層對(duì)應(yīng)的卷積核個(gè)數(shù)Tab.2 Number of convolution kernels corresponding to different convolution layers
然而對(duì)于設(shè)置卷積層層數(shù)、GRU層神經(jīng)元個(gè)數(shù)、訓(xùn)練次數(shù)、學(xué)習(xí)率的不確定性,本文提出采用黏菌優(yōu)化算法來(lái)確定CNN-GRU模型卷積層層數(shù)等關(guān)鍵參數(shù)。設(shè)置SMA算法黏菌種群規(guī)模n=10,最大迭代次數(shù)M=20;卷積層層數(shù)N、GRU層神經(jīng)元個(gè)數(shù)H、訓(xùn)練次數(shù)E、學(xué)習(xí)速率取值范圍分別為[2,5],[100,200],[400,500],[0.005,0.010]。為了確定合適的滯時(shí)來(lái)預(yù)測(cè)當(dāng)前的徑流,采用自相關(guān)函數(shù)(autocorrelation function,ACF)和偏自相關(guān)函數(shù)(partial autocorrelation function,PACF)確定CNN-GRU模型的輸入步長(zhǎng)。蘭西水文站年徑流序列的ACF圖和PACF圖見圖5。從圖5可以看出,ACF的估計(jì)值在17時(shí)達(dá)到峰值,并且在17個(gè)滯時(shí)以后其PACF的估計(jì)值均落在95%的置信帶內(nèi)。因此,時(shí)間步長(zhǎng)取17,即根據(jù)前17年的年徑流來(lái)預(yù)測(cè)下一年的年徑流。
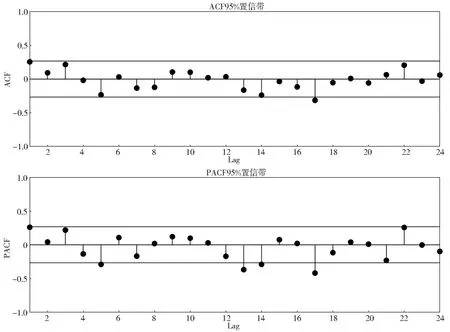
圖5 年徑流序列ACF圖和PACF圖Fig.5 ACF and PACF plots of annual runoff series
由于原始序列經(jīng)VMD分解后生成了6個(gè)子序列,針對(duì)不同序列該如何設(shè)置參數(shù)的問(wèn)題,采用兩種方案構(gòu)建VMD-SMA-CNN-GRU的預(yù)測(cè)模型。方案1(VMD-SMA-CNN-GRU1)采用對(duì)不同的序列設(shè)置不同的參數(shù),方案2(VMD-SMA-CNN-GRU2)采用對(duì)不同的序列設(shè)置統(tǒng)一的參數(shù),不同方案下SMA對(duì)各子序列參數(shù)進(jìn)行尋優(yōu)后結(jié)果見表3。除加入優(yōu)化算法的模型以外,其他6種對(duì)比模型中,卷積層層數(shù)、GRU層神經(jīng)元個(gè)數(shù)、訓(xùn)練次數(shù)、學(xué)習(xí)率分別設(shè)置為各取值范圍的中間值。因此,CNN層數(shù)為4,GRU層和LSTM層神經(jīng)元個(gè)數(shù)均為150,訓(xùn)練次數(shù)為450,學(xué)習(xí)率為0.007 5。

表3 不同方案下SMA對(duì)各子序列參數(shù)尋優(yōu)結(jié)果Tab.3 Optimization results of sub-sequence parameters by SMA under different schemes
2.3 結(jié)果分析
采用實(shí)測(cè)數(shù)據(jù)逐步分析驗(yàn)證。利用訓(xùn)練好的CNN-GRU模型先提取訓(xùn)練集中最后17年的數(shù)據(jù),以預(yù)測(cè)第一個(gè)新值,接著取第二個(gè)所預(yù)測(cè)數(shù)據(jù)前面17年的實(shí)測(cè)數(shù)據(jù)來(lái)計(jì)算當(dāng)前年的預(yù)測(cè)值,重復(fù)上述操作直至預(yù)測(cè)完驗(yàn)證期全部數(shù)據(jù)為止。選擇2003—2014年的預(yù)報(bào)結(jié)果驗(yàn)證模型預(yù)測(cè)精度,即預(yù)測(cè)到第12年結(jié)束。
為了說(shuō)明SMA優(yōu)化的VMD-CNN-GRU模型的優(yōu)勢(shì),使用CEEMDAN-CNN-GRU模型、VMD-CNN-LSTM模型、VMD-LSTM模型、VMD-GRU模型、VMD-PSO-CNN-GRU模型、SMA-CNN-GRU模型和CNN-GRU模型作為基準(zhǔn)進(jìn)行對(duì)比。各模型預(yù)測(cè)后評(píng)價(jià)標(biāo)準(zhǔn)計(jì)算結(jié)果和對(duì)比見表4和圖6。

表4 各模型評(píng)價(jià)標(biāo)準(zhǔn)計(jì)算結(jié)果Tab.4 Calculation results of each model evaluation standard

圖6 各模型預(yù)測(cè)值與原序列對(duì)比Fig.6 Comparison between the predicted values of each model and the original sequence
從圖6(a)可以看出優(yōu)化后的VMD-CNN-GRU模型擬合效果均很好,相比較之下VMD-PSO-CNN-GRU模型的效果略差,從局部放大圖中可以明顯看出1988年和2013年VMD-SMA-CNN-GRU1預(yù)測(cè)結(jié)果比其他2個(gè)模型更精確。從圖6(b)可以看出:VMD-SMA-CNN-GRU2模型擬合的效果最好,尤其在預(yù)測(cè)峰值的情況下;CEEMDAN-CNN-GRU模型擬合效果最差,只有曲線的大概趨勢(shì)與原序列相同而具體數(shù)值與實(shí)際值相差較大。在訓(xùn)練期,除CEEMDAN-CNN-GRU模型以外,其他模型均達(dá)到較好的擬合效果,但通過(guò)局部放大1994年的預(yù)測(cè)結(jié)果后可以發(fā)現(xiàn)各模型之間還存在一定的差異,VMD-SMA-CNN-GRU2模型預(yù)測(cè)精度更高。從驗(yàn)證期中可以看出,VMD-SMA-CNN-GRU2和VMD-CNN-LSTM模型擬合程度優(yōu)于VMD-GRU和VMD-LSTM模型。
由表4可以得出如下結(jié)果。
經(jīng)SMA優(yōu)化的VMD-CNN-GRU組合模型預(yù)測(cè)精度最高。對(duì)比2種不同方案下VMD-SMA-CNN-GRU的預(yù)測(cè)結(jié)果可知各子序列設(shè)置不同參數(shù)時(shí)可以提高預(yù)測(cè)精度。VMD-SMA-CNN-GRU1與VMD-PSO-CNN-GRU模型相比,ERMS、EMA分別減少了31.18 %、26.33 %,說(shuō)明粒子群優(yōu)化算法[32](PSO)容易陷入局部最優(yōu)無(wú)法找到最優(yōu)解,而SMA算法能避免這一問(wèn)題并有效的尋找優(yōu)化參數(shù)。
VMD-SMA-CNN-GRU2模型與SMA-CNN-GRU模型相比,ERMS、EMA和EMAP分別減少了80.13%、 82.72%和 84.84%,可以看出分解技術(shù)和優(yōu)化算法均能提高模型的預(yù)測(cè)精度,但通過(guò)比較發(fā)現(xiàn)分解技術(shù)的提高程度更大。
VMD-SMA-CNN-GRU2模型與CEEMDAN-CNN-GRU模型相比,ERMS、EMA和EMAP分別減少了79.81%、78.66%和80.68%;與CNN-GRU模型相比,ERMS、EMA和EMAP分別減少了85.21%、87.17%和 86.99%。VMD-SMA-CNN-GRU2模型預(yù)測(cè)精度明顯高于CEEMDAN-CNN-GRU模型和CNN-GRU模型,說(shuō)明了VMD分解效果優(yōu)于CEEMDAN。
VMD-GRU模型和VMD-LSTM模型相比預(yù)測(cè)精度相差不大,但是VMD-GRU模型與VMD-LSTM模型訓(xùn)練時(shí)間分別為38.55 s和57.03 s,相比訓(xùn)練時(shí)間縮短了32.40%,通過(guò)對(duì)比兩者模型的訓(xùn)練時(shí)間可以發(fā)現(xiàn)GRU模型效率更高。GRU比LSTM訓(xùn)練時(shí)間短的原因是GRU模型只有兩個(gè)門,模型結(jié)構(gòu)簡(jiǎn)單,構(gòu)建龐大的網(wǎng)絡(luò)時(shí)更加有效。
VMD-SMA-CNN-GRU2模型與VMD-GRU模型相比,ERMS、EMA和EMAP分別減少了29.43 %、23.20%和19.95%,與VMD-LSTM模型相比ERMS、EMA和EMAP分別減少了31.33%、26.20%和26.25%。加入CNN網(wǎng)絡(luò)后模型預(yù)測(cè)精度明顯提高,這是因?yàn)镃NN模型中卷積層中的卷積核(濾波器)發(fā)揮著提取數(shù)據(jù)特征作用,通過(guò)卷積提取需要的特征然后傳遞給GRU層或者LSTM層。
綜上所述,在驗(yàn)證期各種模型對(duì)蘭西水文站年徑流預(yù)測(cè)精度存在的差異較大一些,預(yù)測(cè)效果最好的方法依次為VMD-SMA-CNN-GRU、VMD-PSO-CNN-GRU、VMD-CNN-LSTM、VMD-GRU、VMD-LSTM、CEEMDAN-CNN-GRU、SMA-CNN-GRU、CNN-GRU。年徑流序列由于受多種因素的影響極其不平穩(wěn),VMD可以自適應(yīng)處理年徑流序列,對(duì)序列進(jìn)行重構(gòu)以達(dá)到去噪的效果,CNN通過(guò)提取數(shù)據(jù)內(nèi)部的特征使得GRU后續(xù)能夠更加高效地進(jìn)行預(yù)測(cè),而SMA算法為CNN-GRU模型確定了恰當(dāng)?shù)膮?shù),因此VMD-SMA-CNN-GRU模型具有良好的適應(yīng)性和預(yù)測(cè)性能。
3 結(jié) 論
在VMD-CNN-GRU模型中,隱含層神經(jīng)元個(gè)數(shù)、訓(xùn)練次數(shù)等超參數(shù)的設(shè)置影響模型擬合效果,利用SMA算法對(duì)CNN-GRU混合神經(jīng)網(wǎng)絡(luò)中超參數(shù)進(jìn)行尋優(yōu)改善了模型的性能,避免了人工試算效率低的情況,節(jié)約了運(yùn)算時(shí)間成本同時(shí)提高了模型的預(yù)測(cè)精度。
分解技術(shù)和優(yōu)化算法均能提高模型的預(yù)測(cè)精度,并且分解技術(shù)的作用影響更大。徑流序列具有非線性和非平穩(wěn)的特點(diǎn),VMD可以將原始序列分解成較為平穩(wěn)的多個(gè)子序列,增加數(shù)據(jù)的同時(shí)能夠更好地進(jìn)行擬合。VMD與CEEMDAN相比,在分解時(shí)VMD可以自主地設(shè)置合適的模態(tài)個(gè)數(shù),能夠有效解決模態(tài)混疊的問(wèn)題,使得分解精度更高進(jìn)而預(yù)測(cè)結(jié)果更準(zhǔn)確。
VMD-CNN-GRU模型同時(shí)具有CNN網(wǎng)絡(luò)和GRU網(wǎng)絡(luò)的優(yōu)點(diǎn)。CNN網(wǎng)絡(luò)可以充分挖掘數(shù)據(jù)中的特征,GRU網(wǎng)絡(luò)適用于時(shí)間序列預(yù)測(cè),試驗(yàn)結(jié)果表明兩者的結(jié)合可以有效的預(yù)測(cè)年徑流,為中長(zhǎng)期徑流預(yù)報(bào)提供了一種新途徑。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:37
湖北經(jīng)濟(jì)學(xué)院學(xué)報(bào)·人文社科版(2015年8期)2015-12-29 05:53:07
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
航空學(xué)報(bào)(2015年4期)2015-05-07 06:43:35
上海電機(jī)學(xué)院學(xué)報(bào)(2015年4期)2015-02-28 14:30:00
計(jì)算物理(2014年2期)2014-03-11 17:01:39
