基于YOLOv5的工廠化養殖蝦目標檢測方法研究
2022-11-11 04:53:02陳子文李卓璐楊志鵬何佳琦曹立杰蔡克衛王其華
海洋漁業 2022年5期
陳子文,李卓璐,楊志鵬,何佳琦,曹立杰,3,蔡克衛,3,王其華
(1.大連海洋大學機械與動力工程學院,遼寧大連 116023;2.大連海洋大學信息工程學院,遼寧大連 116023;3.遼寧省海洋信息技術重點實驗室,遼寧大連 116023;4.濟寧醫學院醫學信息工程學院,山東日照 276800)
蝦的工廠化養殖系統開發起源于20世紀90年代,國外主流工廠化養殖系統有美國德克薩斯海洋科學研究所研發的跑道式養蝦系統[1]。我國工廠化養殖發展尚處于初級階段,自動化程度低,亟需開發相關智能化系統[2]。目前,蝦的工廠化養殖仍采用人工投喂方式,餌料投喂量需根據池內蝦群密度確定[3]。傳統養殖蝦計數一般采用人工隨機采樣方式進行,勞動強度大,效率低,且易對蝦的生長和循環水系統的凈化負荷造成影響。
基于計算機視覺的養殖蝦計數方法具有全程無接觸、計數速度快等優勢,可有效解決人工計數耗時耗力且對蝦有一定損傷等問題。目前,計算機視覺技術在水產養殖中已經得到了較為廣泛的應用。郭顯久等[4]根據海洋微藻顯微圖像的特點,提出使用小波去噪、最大類間方差法等圖像處理技術自動統計海洋微藻數量的方法;王文靜等[5]對魚苗圖像進行閾值分割和目標提取后計算出每幀圖像中的魚苗數量。楊眉等[6]用canny算子提取扇貝邊界像素,并使用BP算法對扇貝圖像進行識別分類。王碩等[7]提出一種基于曲線演化的圖像處理方法,實現對大菱鲆(Scophthalmusmaximus)魚苗準確計數。
上述傳統計算機視覺方法均在水產領域取得很好的應用,但仍存在計數誤差較大、對重疊個體和差異較大個體計數不準確等缺點。隨著深度卷積神經網絡的迅速發展,基于深度學習的目標檢測已經超越傳統方法,成為當前目標檢測的主流方法,并已被廣泛應用于不同領域。基于深度學習的目標檢測算法框架主要有R-CNN(region-convolutional neural networks)系列[8-10]、SSD(single shotmulti box detector)[11-12]和YOLO系列(you only look once)[13-16]等。目前,已有學者將其引入到農業工程領域,并取得較好效果。薛月菊等[17]使用改進的Fast R-CNN(fast regionconvolutional neural networks)針對深度圖像設計了全天候的哺乳母豬姿態的自動識別。王羽徵等[18]利用改進式VGG16網絡對水體中的單細胞藻類進行有效識別。一段式(one-stage)檢測的代表算法YOLO在目標檢測速度和算法效率上都有著不錯的表現,該算法已在農業設施智能化研究中得到廣泛應用;CAI等[19]使用改進版的YOLOv3深度神經網絡模型實現了工廠化養殖環境下的紅鰭東方鲀(Takifugu rubripes)的識別和計數。劉芳等[20]使用改進的多尺度YOLO實現了復雜環境下的番茄果實的快速識別。本文基于YOLOv5框架,采用少量高清圖像樣本,試圖實現養殖蝦的精準目標檢測與計數。
工廠化養殖環境下,蝦的游動速度較快,游動過程中的蝦體形狀和姿態存在較大的差異,需要利用高分辨率工業相機對養殖池進行抓拍,保證圖像樣本質量。然而,由于養殖環境差、樣本采集成本高、所采集圖像樣本數量有限,且高分辨率圖像直接壓縮進行訓練會導致圖像細節缺失,直接影響檢測精度。因此,針對上述問題,本文提出自適應裁片算法進行數據預處理,增強高分辨率下對蝦的細節特征的學習效果,并基于YOLOv5框架進行數據集訓練,實現養殖池內蝦精準識別與計數,以期為實現科學喂養、定量投餌提供數據基礎。
1 材料與方法
1.1 數據集
蝦的工廠化養殖圖像采用海康威視DS-2CD3T86FWDV2-15S攝像頭,2.8 mm焦距鏡頭,114.5度視角進行拍攝采集。攝像頭垂直固定于蝦養殖盤正上方進行俯視拍攝,所采集圖像為PNG格式,圖像高度為3 000 Pixl,寬度為4 000 Pixl,2 min間隔拍攝,共采集圖像181張。采集圖像樣本及其標注結果如圖1所示。

圖1 采集圖像樣例Fig.1 Example of captured images
本文數據集采用“LabelImg”標注工具進行人工標注,標注信息存儲至txt標簽文件,每個標簽文件與圖像文件一一對應,其中每行存放一個目標信息,信息依次為:目標類別、檢測框中心點X、Y軸坐標以及目標寬度、高度。
1.2 YOLOv5
本文基于YOLOv5目標檢測框架(圖2)進行養殖蝦圖像分析并計數研究,該檢測框架首先將圖像劃分成S×S個網格,然后判斷目標檢測框中心點是否處于某一網格內,再預測目標的坐標位置和目標置信度,最終實現多目標檢測,在檢測速度及準確率上相對前代算法有很大提升。
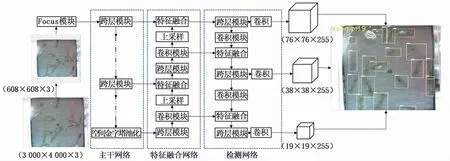
圖2 YOLOv5網絡結構Fig.2 Structure of YOLOv5
1.3 評價指標
本文采用平均精度均值(mean average precision,mAP)、準 確 率(precision)、召 回 率(recall)作為訓練模型性能的評價指標。對于分類問題,可以根據真實的類別情況與模型預測的類別情況的組合將樣例劃分為真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)、假反例(false negative,FN)4種情況,分類結果混淆矩陣如表1所示。
準確率和召回率是一對矛盾的度量標準,準確率越高,召回率一般會偏低,反之亦然,由表1可得準確率P與召回率R計算公式為:

表1 分類結果混淆矩陣Tab.1 Classification results of confusion matrix

平均精度(AP)是衡量模型檢測效果的常用標準,AP是召回率取值0到1時準確率的平均值,綜合考慮了準確率和召回率,能夠很好的衡量目標檢測效果。mAP為所有類別的檢測精度的平均值,是衡量模型預測目標的位置以及類別的度量標準,mAP的計算公式為:
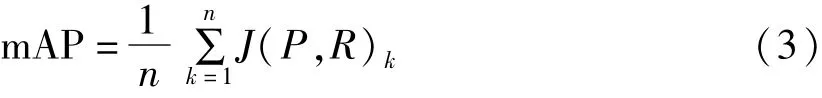
式(3)中,J(P,R)k為平均精度函數,計算方式為類別為編號k時的準確率P與召回率R構成的P-R曲線下方面積。
2 算法框架
2.1 算法整體框架
本文檢測算法框圖如圖3所示。原始高清圖像經過自適應裁切與標簽映射后生成裁切圖像數據集,并與原始圖像混合作為總數據集,按照訓練集70%與驗證集30%的比例劃分并輸入檢測網絡進行訓練,獲得模型后,對養殖蝦圖像進行分析,實現目標檢測與計數。
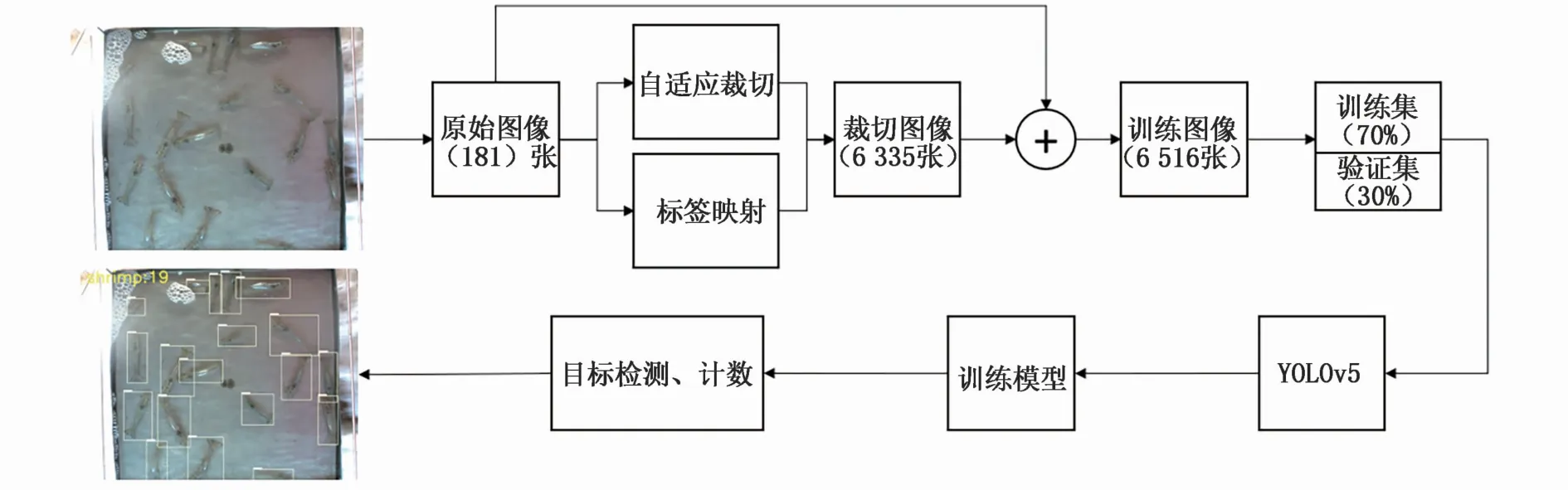
圖3 養殖蝦目標檢測算法框圖Fig.3 Block diagram of shrim p object detection algorithm
2.2 自適應圖片裁切算法
2.2.1 圖像裁切
為解決直接壓縮高清圖像導致細節丟失以及只有少量圖像樣本問題,本文設計提出一種根據網絡輸入圖像尺寸自適應調節的高分辨率圖像裁切算法,算法流程如圖4所示。該算法根據原圖尺寸與網絡預處理輸入圖尺寸計算出裁切數量與裁切窗口滑動步長,計算公式為:
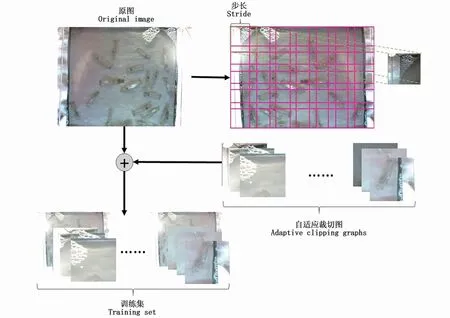
圖4 自適應圖片裁切算法流程Fig.4 Adaptive image clipping algorithm flow

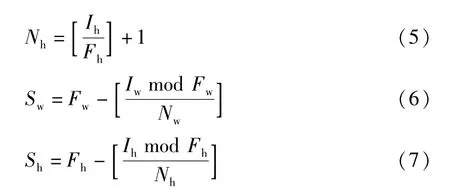
式(4)~式(7)中,Nw代表水平方向最終生成的裁切框的數量,Nh代表豎直方向最終生成的裁切框的數量,Iw代表原圖的寬度,Ih代表原圖的高度,Fw代表網絡預處理后輸入圖的寬度,Fh代表網絡預處理后輸入圖的高度,Sw為裁切框沿橫向滑動的步長,Sh為裁切框沿縱向滑動的步長。
裁切所得圖像與原圖共同組成了檢測模型數據集。本研究中原始圖像分辨率為3 000×4 000,網絡預處理輸入圖像尺寸為640×640,因此水平方向裁切框的數量為7,豎直方向裁切框數量為5,裁切框沿橫向滑動的步長為602,裁切框沿縱向滑動的步長為552。原始圖像數量為181,經過算法處理后,最終得到的圖像樣本量為6 516張。
2.2.2 標簽映射
由于算法需要對圖像進行裁切生成單獨的圖像,所以需要對標簽文件內的坐標信息進行重新計算,在裁切圖像的同時計算裁切后新圖像的坐標信息,將原圖的坐標映射到新生成的裁切圖中。標簽映射算法流程見算法1:

算法1標簽映射Labelmapping輸入:原圖目標框(x1,y1,x2,y2),滑動窗口坐標(x3,y3,x4,y4)輸出:裁切圖目標框(xtop,ytop,xbot,ybot)1:function Labelmapping(x1,y1,x2,y2,x3,y3,x4,y4)2: if IoU([x1,y1,x2,y2],[x3,y3,x4,y4])>0 then 3: xtop=max(x1,x3)4: xbot=min(x2,x4)5: ytop=max(y1,y3)6: ybot=min(y2,y4)7: return xtop,ytop,xbot,ybot
其中,原圖目標框為其左上角坐標(x1,y1)及右下角坐標(x2,y2),當前滑動裁切窗口坐標為其左上角坐標(x3,y3)與右下角坐標(x4,y4)。IoU函數用于計算兩個矩形框的交集與并集的比值,計算公式為為原圖目標框面積,B為滑動裁切窗口面積。max(x,y)為最大值函數,返回x、y中的最大值,min(x,y)為最小值函數,返回x,y中的最小值。經過計算獲得裁切圖目標檢測框的標注映射坐標分別為左上角坐標(xtop,ytop)及右下角坐標(xbot,ybot)。
3 結果與分析
3.1 模型訓練
為獲得更快的收斂速度,減少訓練時間成本,本文基于YOLOv5框架下YOLOv5s預訓練權重進行遷移學習。其中,硬件平臺參數中央處理器為Intel i7 7700k,圖形計算卡為Nvidia GeForce GTX 1070 Ti,批量數為16,訓練100輪,共迭代28 507次。
經過訓練之后,得到目標檢測模型,模型識別效果如圖5所示。訓練過程誤差函數以及mAP曲線如圖6曲線所示。

圖5 檢測效果展示Fig.5 Detection effect display
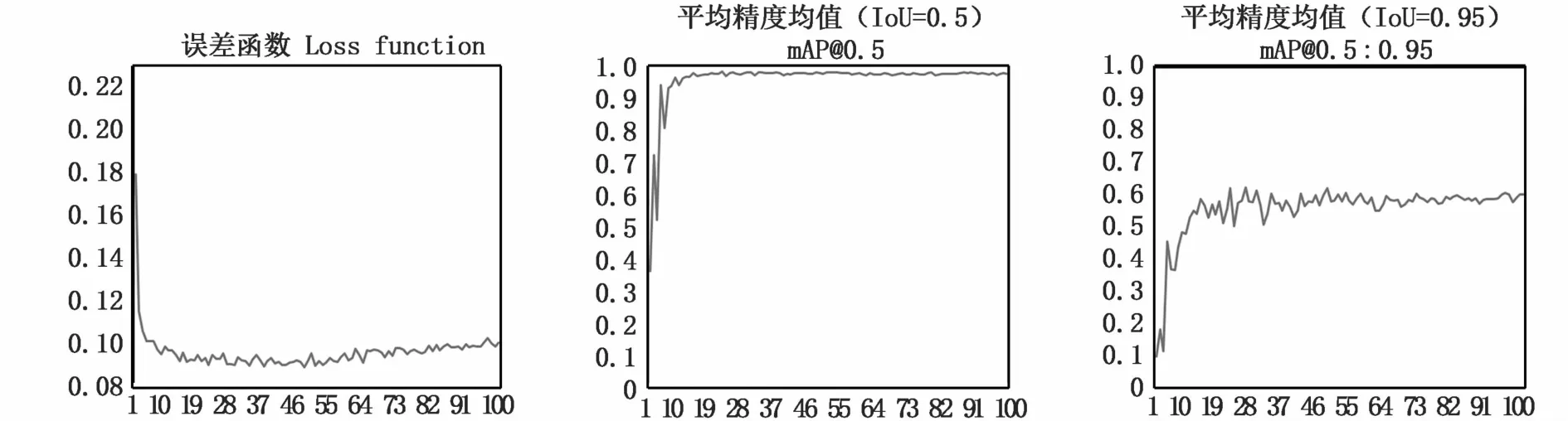
圖6 模型訓練參數Fig.6 Model training parameters
3.2 對比實驗
本文將原始圖像與自適應裁切算法生成的圖像混合作為模型訓練數據集,訓練所得模型記為模型1。為證明本文提出自適應裁切算法的有效性,本文設計了另兩組對比實驗,分別使用原始圖像作為訓練集,訓練所得模型2。以及僅使用自適應裁切算法生成的圖像作為訓練集,訓練所得模型3。
3.2.1 模型參數分析
本文采用均值平均精度mAP、召回率、準確率作為評價指標,對3個模型訓練效果進行評價,最終訓練參數如表2所示。

表2 模型預測參數對比Tab.2 Comparison of prediction parameters of 3 models
經過100輪的訓練之后,最終分別得到對應訓練集1、訓練集2、訓練集3的3個模型——模型1、模型2、模型3。訓練過程損失函數變化曲線如圖7所示。結果顯示,模型1可以很快收斂,并在第10輪訓練的時候基本趨于穩定,模型2在訓練開始階段有較大的波動,并且在第28輪訓練之后基本趨于穩定,模型3則波動范圍較大,不易收斂。
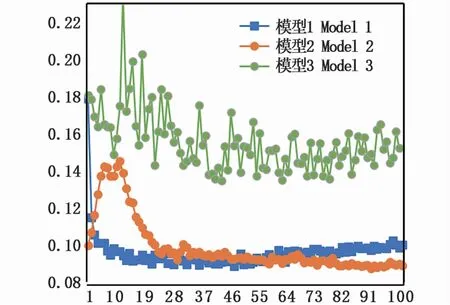
圖7 誤差函數對比Fig.7 Loss function comparison
圖8為3個模型的平均精度均值(IoU=0.5)與平均精度均值(IoU=0.95)的折線圖。由圖8中可以看到,模型1的平均精度均值(IoU=0.5)在第10輪訓練時已經基本達到穩定,最大值為97.5%,而模型2的平均精度均值(IoU=0.5)在第80輪訓練才基本到達穩定,最大值為96.4%。模型3僅為85.2%。
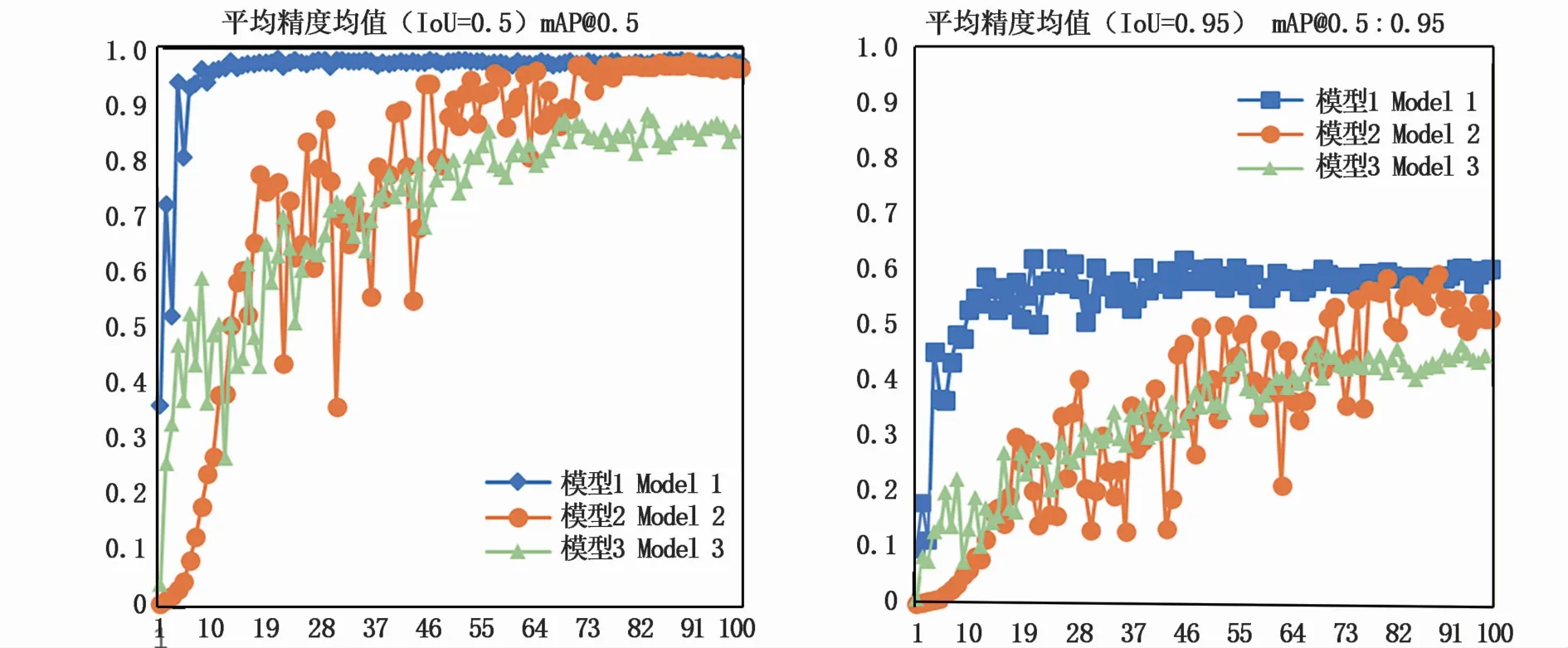
圖8 平均精度均值對比Fig.8 m AP comparison
平均精度均值(IoU=0.95)能更好的衡量一個模型的實際檢測性能,模型1的平均精度均值(IoU=0.95)的最大值為62.36%,模型2最大值為59.5%,而模型3只有46.7%。表明模型1在輸出的預測框與真實的目標框有著很高的交并比,預測效果與真實值很接近。
準確率為對目標預測值與真實值的比值,是1個目標檢測網絡對目標識別準確性的評價標準。3個模型的準確率如圖9-a所示,由曲線可見,得益于訓練集圖片自適應裁切算法,模型1僅僅訓練了20輪就達到92.55%。模型3僅使用自適應裁切算法裁切后的圖片進行訓練,缺乏對整體特征的學習,最高準確率為89.02%。模型2僅使用高分辨率原圖進行訓練,壓縮后無法學習到細節特征,最高準確率為85.43%。
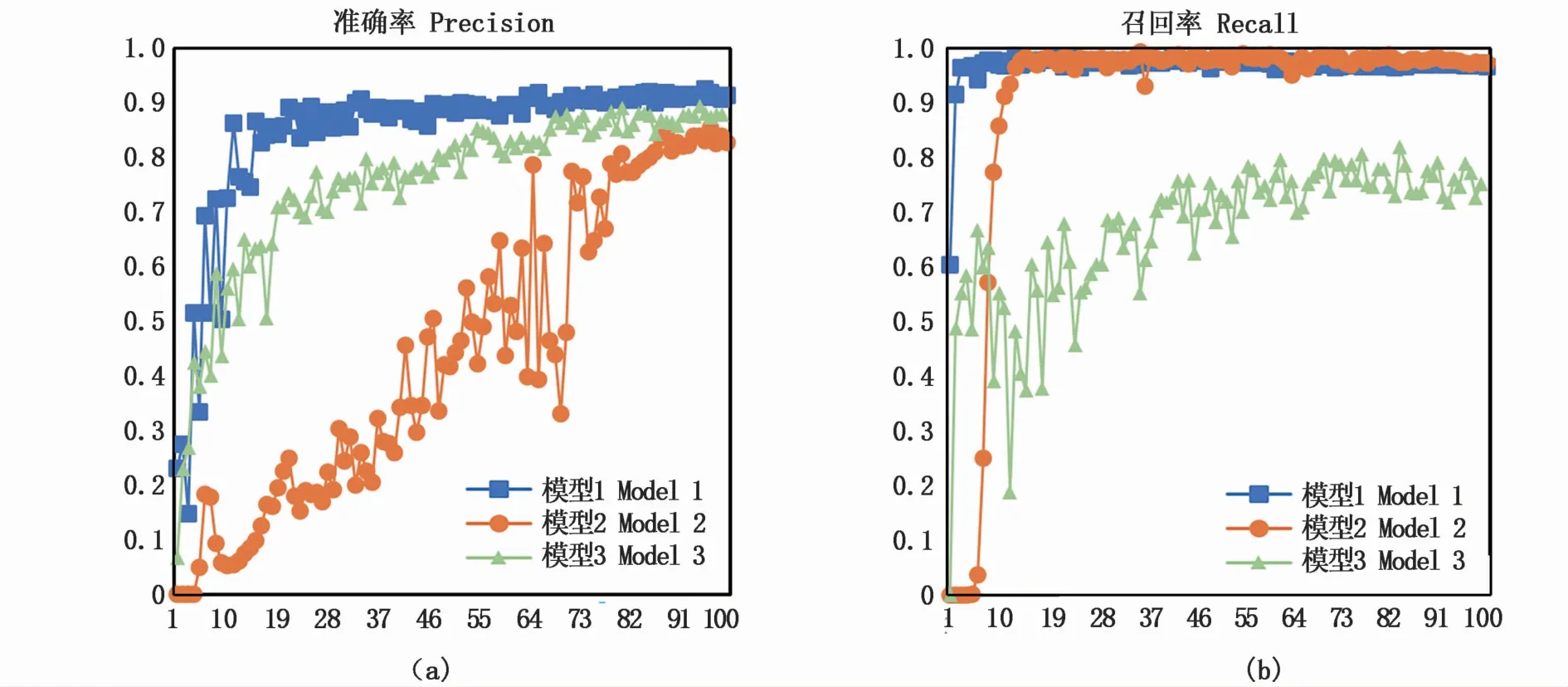
圖9 準確率與召回率對比Fig.9 Com parison of precision and recall
召回率為檢測的目標數量與所有目標數量的比值,是評價一個模型能否檢測出所有目標的衡量標準。3個模型的召回率如圖9-b所示,模型1的最大召回率為98.78%,模型2的最大召回率為98.42%,模型3的最大召回率為81.85%。由此可得,模型1在檢測目標的查全度方面優于模型2與模型3。
3.2.2 檢測效果分析
通過使用3個模型對高清圖像進行預測,挑選出6組不同干擾環境下的預測圖像進行對比。如圖10所示,(a)組中模型1的檢測與人工計數結果相同,相對于模型2,模型1成功檢測到了圖像下方有水面反光干擾的目標,而模型2與模型3均未檢測到所有的蝦;(b)組中模型1可以準確檢測到被泡沫遮擋的蝦。模型3出現了對重疊目標無法分辨的情況;(c)組中模型1檢測到了圖中被遮擋僅露出蝦尾的目標,模型2與模型3均未檢出全部目標;(d)組中模型1準確分開了1組高密度目標,并正確標記數量,而模型2與模型3出現了漏檢;(e)組中模型1同樣準確檢出了被泡沫遮擋和水面反光干擾的目標;(f)組中模型1對非正常體位的蝦進行了精確識別,而模型2與模型3因缺少此部分細節所以未能實現全部檢出。

圖10 檢測計數效果對比Fig.10 Com parison of detection and counting effect
由此可見,使用自適應裁切算法訓練的模型1無論是在蝦被遮擋,或者是被水面反光干擾、扭曲變形的情況下,均能準確的檢測出所有目標,并且能精確計數。
4 展望
本文算法僅僅在數據預處理部分進行了部分創新實驗,證明了數據預處理算法對目標檢測算法的影響。因此,如果將本文算法進行遷移到網絡檢測部分是否可行?以及如何有效減少高分辨率檢測過程中的網絡結構引起的特征損失,如何平衡分塊檢測的精度與檢測時間的關系?將是下一步的主要方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
