基于兩層次低秩分解的無監督織物疵點檢測方法
2022-11-11 03:28:36鄧智超鄧開連劉肖燕
東華大學學報(自然科學版) 2022年5期
鄧智超, 鄧開連, 張 磊, 劉肖燕, 燕 帥
(東華大學 信息科學與技術學院, 上海 201620)
織物疵點檢測是紡織品質量控制過程中的關鍵環節之一。目前,大多數織物檢驗方法采用高成本的人工檢測,需要大量人工標注信息。因此,探索一種泛化性好、疵點定位精度高和疵點類別分辨能力強的無監督織物疵點檢測方法,具有重要的學術價值和應用價值。
近年來,針對織物疵點的檢測算法主要包含4種方法。一是基于統計的方法,主要包括直方圖統計[1]、共生矩陣[2]、顯著圖重構[3]等。雖然這類方法計算量小, 但是對環境條件敏感, 錯檢、漏檢率較高。二是基于頻譜的方法,主要包括傅里葉變換[4]、小波變換[5]、Gabor 濾波器[6-7]等。基于傅里葉變換的方法無法定位疵點位置,而小波變換和Gabor 變換的計算成本高, 難以用于生產過程中的實時檢測。三是基于模型的方法,主要包括高斯混合模型[8-9]、馬爾科夫隨機場模型[10]等。基于模型的方法穩健性較差,實際應用的效果不佳, 近幾年對其研究較少。四是基于機器學習[11-12]的方法,常見的有自動編碼器[13-14]、卷積神經網[15-17]、對抗網絡[18-19]等。由于不同面料的紋理背景、環境光線強弱和干擾噪聲的影響,面料疵點背景會有很大的差異,這使得基于機器學習的方法難以提取缺陷特征,因此實際操作中為保證檢測精度,針對不同面料需花費巨大成本訓練專有檢測模型。由于面料疵點種類繁多、形態多樣,監督學習在多形態疵點下,人工標注數據費時費力,難以對缺陷特征進行充分學習,尤其在實際操作中,未知的、新的疵點不斷出現,監督學習很難實現高精度的檢測。
綜合以上分析可知,現有基于機器學習的檢測方法很難利用大量無標注信息,且對不同紋理的適應性不強,致使檢測效果不明顯。針對織物組織紋理結構復雜、花型繁多、材質多樣的特點以及生產過程中環境的影響,如何提高無監督檢測模型的泛化能力、疵點定位精度和疵點類別分辨能力仍然是研究的熱點。
提出基于兩層次低秩分解的無監督織物疵點檢測方法:首先,利用噪聲、背景底紋、疵點信息的低秩和稀疏特性,建立兩層次低秩分解模型,通過交替方向乘子法對模型求解,實現疵點和背景噪聲的分離,提高算法對不同紋理織物、光線強弱和面料歪斜的適應性;其次,利用檢測框鄰域圖像隸屬度的相似性與層次聚類的遞進性,通過設計深度聚類網絡的聯合訓練方式,提高疵點定位精度,極大地緩解因數據復雜導致深度聚類網絡訓練難以擬合的問題。
1 無監督織物疵點檢測方法
針對疵點數據背景復雜、干擾噪聲多的問題,提出了基于兩層次低秩分解的無監督織物疵點檢測方法,該方法流程如圖1所示。
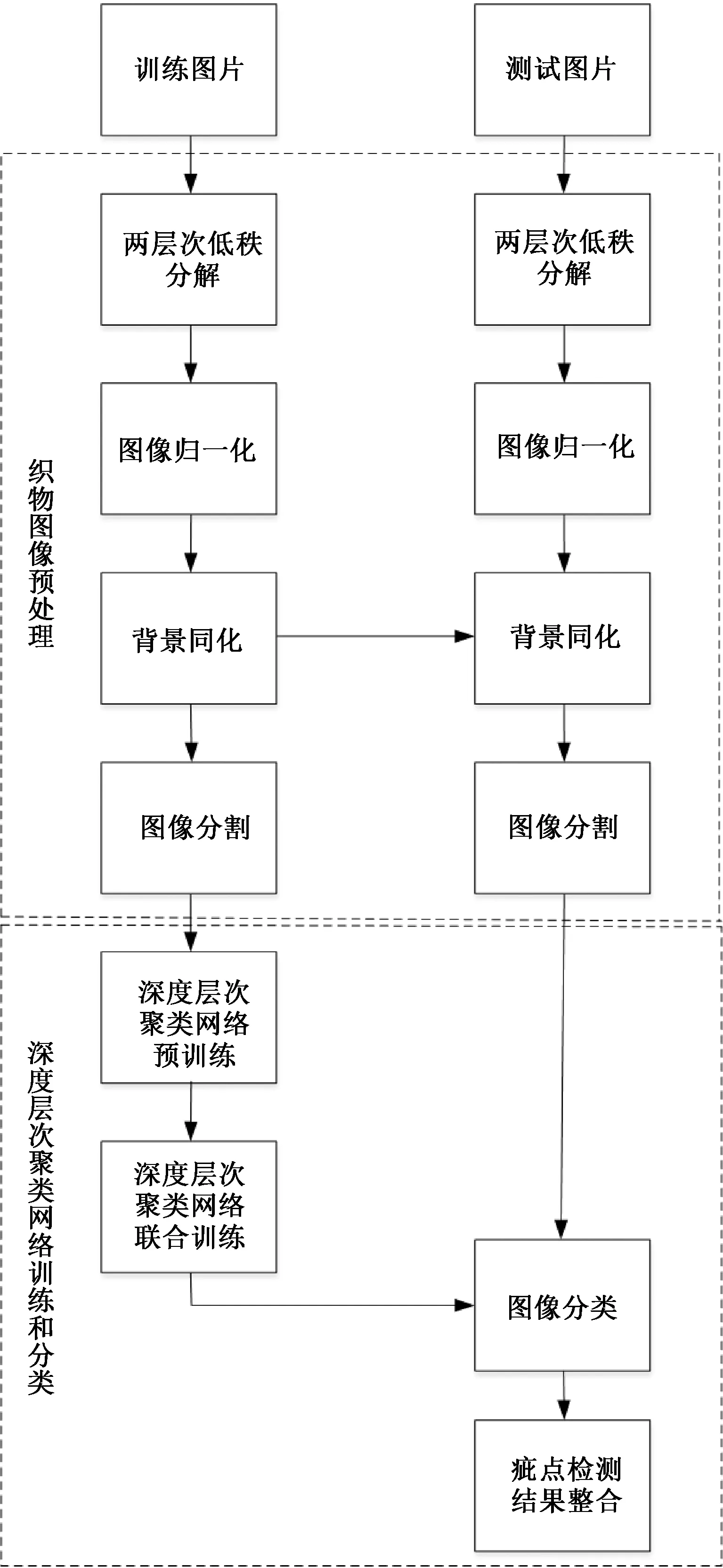
圖1 基于兩層次低秩分解的無監督織物疵點檢測方法流程圖
由圖1可知,無監督織物疵點檢測分為圖像預處理和深度層次聚類網絡兩部分。圖像預處理部分:首先,利用背景底紋復雜性和疵點信息的低秩、稀疏特性,進行兩層次低秩稀疏陣分解,將面料的疵點信息與背景和噪聲分離,減輕外界的影響。其次,調整訓練,集中每張圖像各通道的像素范圍至該通道像素極限范圍,以進行圖像歸一化。再次,統計訓練集中所有圖像各通道的像素均值,并調整訓練集所有圖像各通道的像素均值為對應通道統計均值,實現訓練集圖像的背景同化,提高檢測模型的泛化能力。最后,將處理后尺寸為M×N的圖像分割成(M-m-1)×(N-n-1)個尺寸為m×n的小圖像,并送入深度層次聚類網絡訓練。深度層次聚類網絡部分:首先,通過對編碼器進行預訓練,初始化編碼器。其次,利用疵點鄰域圖像的隸屬度具有相似性的特點,對網絡層次聚類進行聯合訓練,緩解數據復雜導致網絡難以擬合的問題,提高疵點定位精度和類別辨識的準確率。最后,通過合并相同類別且重合的疵點檢測小框,根據所包含疵點檢測小框的數量,對重合度過高的疵點大框進行非極大抑制,完成疵點的無監督目標檢測。
1.1 織物圖像預處理
1.1.1 兩層次低秩分解
針對模型檢測精度因面料背景的差異性而有所降低的問題,利用背景、噪聲、疵點的低秩和稀疏特性,建立了如式(1)所示的兩層次低秩分解模型。第一層次從原始圖像中分解出背景矩陣L1和疵點與噪聲的混合矩陣S1;第二層次從疵點與噪聲的混合矩陣中分解出疵點矩陣L2和噪聲矩陣S2。通過交替方向乘子算法,對兩層次低秩分解模型求取最優解,從而實現疵點與噪聲和背景的分離。
(1)
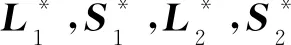
求解式(1)屬于NP-hard問題,難以獲得全局最優解,因此將其轉換為凸優化問題的求解:
λ1‖S1‖1+‖L2‖*+λ2‖S2‖1)
(2)
式中:‖‖*表示核范數;‖‖1表示1范數。
(3)
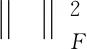
最后利用交替方向乘子算法[20]進行兩層次的迭代求解:
(4)
(5)
(6)
(7)
Y1k+1=Y1k+μ1(F-S1k-L1k)
(8)
Y2k+1=Y2k+μ2(S2k-S2k-L2k)
(9)
式中:k為迭代輪次。
1.1.2 圖像歸一化
將低秩稀疏陣分解后的圖像歸一化到0~255級灰度。
(10)
式中:Di為歸一化后的疵點i通道的像素矩陣;L2i為低秩稀疏陣分解后的圖像L2的第i通道像素矩陣。
1.1.3 背景同化
針對圖像經過歸一化后背景不一致的問題,統計所有圖像各通道的像素均值,并調整所有圖像各通道的像素均值為各通道統計均值。
(11)
式中:nimg為數據集中的圖像數量;M×N為圖像尺寸;A為所有元素為1的矩陣;Dijk為第k張圖像第i個通道的第j個像素值。
1.2 深度層次聚類網絡
1.2.1 深度層次聚類網絡的結構
針對監督學習在多形態疵點下難以實現高精度檢測的缺點,本文設計了深度層次聚類網絡,整個網絡由卷積編碼器、嵌入層和聚類層3部分組成。深度層次聚類網絡結構如圖2所示。
由圖2可知,其中聚類層使用K-means作為聚類算法,其將相同類別并且重合的疵點檢測小框合并成疵點檢測大框,并對重合度過高的疵點大框以所包含疵點檢測小框的數量進行非極大抑制。深度層次聚類網絡參數如表1所示。
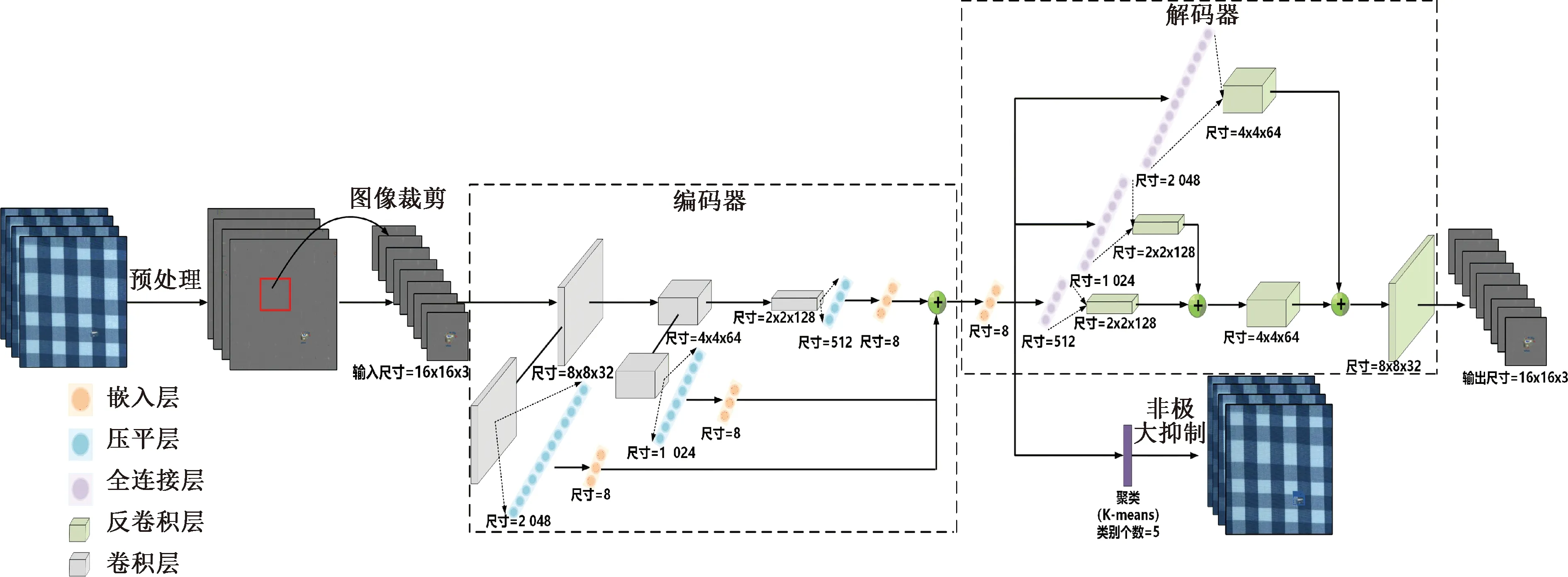
圖2 深度聚類網絡結構圖

表1 深度層次聚類網絡參數
1.2.2 深度層次聚類網絡的預訓練
對編碼器進行預訓練,從而初始化網絡參數。其損失函數LAE為
(12)
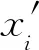
1.2.3 深度層次聚類網絡的聚類損失函數
利用DEC(deep embedded clustering)[21]中定義聚類損失的思想和檢測框鄰域的相似性的特點,定義軟標簽分布和目標分布之間的KL(Kullback-Leibler)散度為聚類損失。
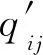
(13)
根據每張圖像的鄰域圖像的隸屬度對原隸屬度進行修正,如式(14)~(16)所示。
(14)
dk=max(|x-s|,|y-t|)
(15)
(16)
式中:hij為未進行歸一化的qij;Nnb為所用的鄰域點的個數;dk為像素點之間的棋盤距離;qij為zi到第j類的基于鄰域的隸屬度。
(2)目標分布。保證聚類目標能使數據分布更加接近聚類中心,因此定義聚類目標分布pij,如式(17)所示。
(17)
式中:pij為zi到第j類的目標隸屬度。
(3)聚類損失函數。聚類損失值計算如式(18)所示。
(18)
式中:Lc為聚類損失值。
1.2.4 深度層次聚類網絡的聯合訓練
為保證聚類訓練過程中嵌入層提取的低維數據特征能夠表示原圖像而不畸變,借助DCEC(deep convolutional embedded clustering)[22]的訓練思想,通過同時降低LAE和Lc對深度層次聚類網絡進行聯合訓練,因此聯合訓練損失函數如式(19)所示。
Ljoint=Lc+αLAE
(19)
由于面料疵點種類繁多的特點,直接對深度層次聚類網絡進行聯合訓練可能無法擬合,因此聯合訓練中使用了類似層次聚類的方式進行訓練,訓練的流程如圖3所示。
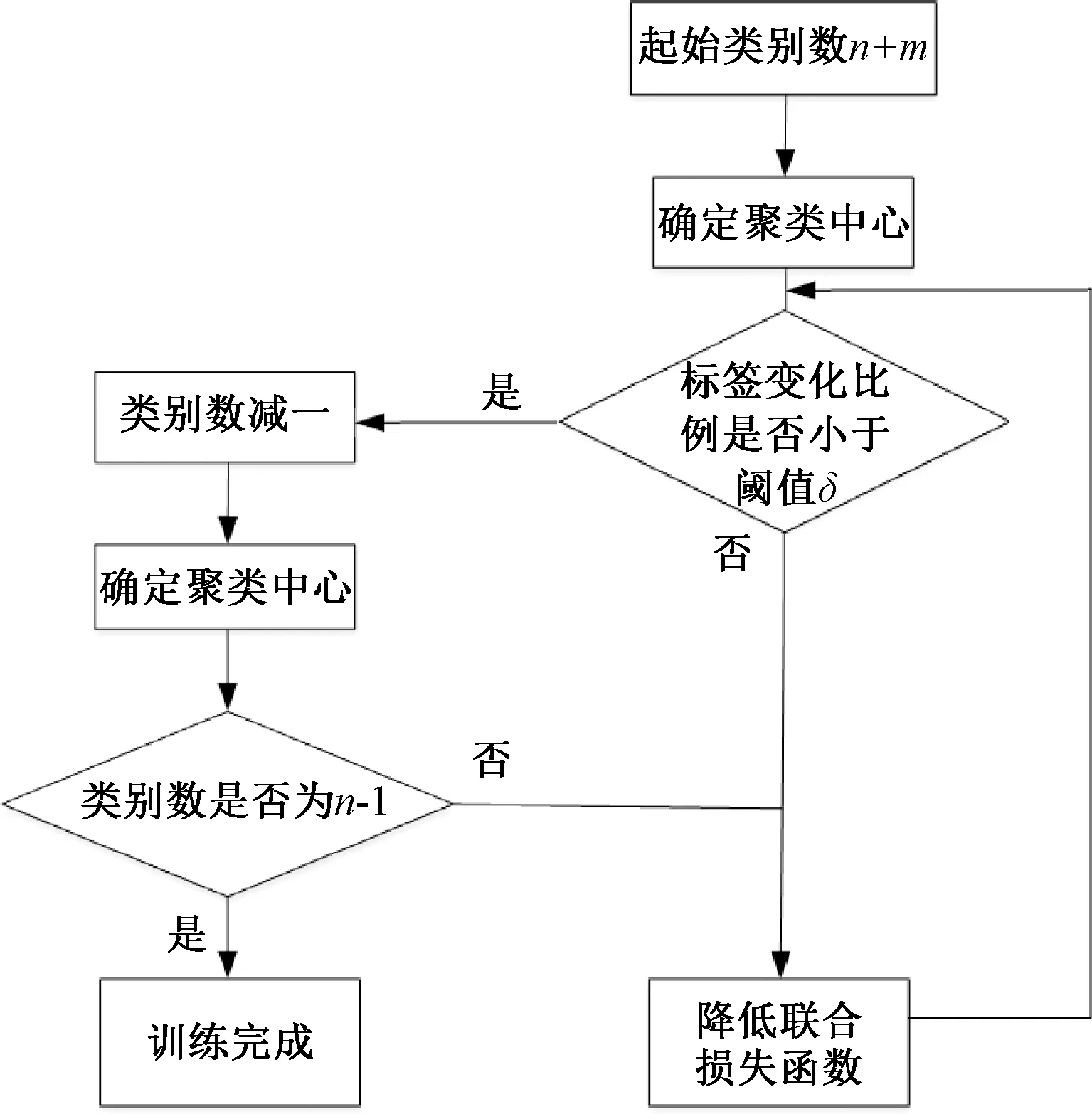
圖3 聯合訓練的流程圖
由圖3可知,聚類類別會從高于最終類別數的n+m降低到最終的類別數n。初始聚類類別數為n+m,確定聚類中心,然后降低聯合訓練損失值,當達到類別降低的條件時,即標簽變化的比例小于設定的閾值δ時,將類別數減一,再次確定聚類中心。以此類推直到最終降低到n個種類且達到類別降低條件,此時,深度層次聚類網絡的訓練完成。
2 研究結果與分析
試驗平臺軟件部分使用Python 3.6和Tensorflow 2.0搭建深度學習模型,在GPU為NVIDIA TESLA T4的服務器上完成檢測模型的訓練與測試。
試驗分為兩個部分:(1)通過層次聚類網絡的聚類能力試驗,檢驗層次聚類網絡的聚類能力;(2)通過模型進行織物疵點檢測試驗,檢驗兩層次低秩分解和深度層次聚類網絡對于面料疵點測檢的有效性和算法泛化性。
2.1 聚類能力對比試驗
2.1.1 數據集
層次聚類網絡的聚類能力試驗在4個數據集上進行評估。
MNIST-full:MNIST數據集是由總計70 000個28像素×28像素的手寫數字組成。
USPS:USPS數據集包含9 298幅16像素×16像素的灰度手寫數字圖像。
Fashion-MNIST:Fashion-MNIST數據集包含了10個類別的70 000張28像素×28像素的時尚產品圖像。
COIL-20 :COIL-20 數據集包含了20個類別的1 440張128像素×128像素物體圖像。
2.1.2 試驗結果
將本文深度聚類網絡與文獻[21-25]深度聚類網絡算法(K-means、DEC、DCEC、MDEC(multi-view deep embedded clustering)、DMJC(deep multi-view joint clustering)、VAED(variational autoencoder with distance))進行對比,測試深度聚類網絡的聚類精度,選用準確率Aclustering和歸一化互信息NNMI[26]作為網絡聚類能力的評價指標,其計算分別如式(20)和(21)所示。
(20)
式中:ms為樣本個數;li為真實標簽;ci為聚類預測標簽。真實標簽與聚類預測標簽的對應關系通過匈牙利算法計算獲得。
(21)
式中:MMI(l,c)為l與c的互信息;l為真實標簽的集合;c為聚類預測標簽的集合;H為熵。
由聚類算法的對比試驗結果(見表2)可知,相較于改進之前的DEC和DCEC網絡,本文算法有了明顯的進步,并且在大部分數據集上的聚類能力優于現有算法。
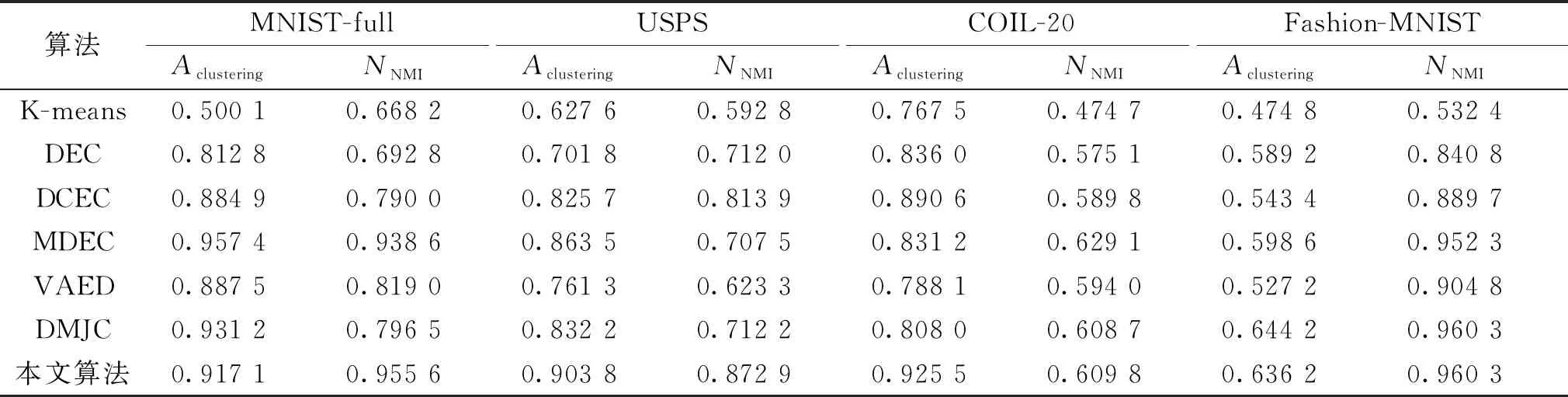
表2 聚類算法準確率與歸一化互信息對比
2.2 疵點檢測對比試驗
2.2.1 數據集
織物疵點檢測試驗選用上海嘉麟杰的典型格紋面料和典型針織棉麻面料以及TILDA中的星紋面料和點紋面料作為試驗樣本,自行設計搭建面料疵點檢測設備。面料疵點試驗平臺硬件參數如表3所示。

表3 面料疵點試驗平臺硬件參數
樣本疵點類型為生產中經常出現的缺經、缺緯、漬類和破洞等4類。格紋面料數據一共包括623張512像素×512像素的圖像,其中缺經143張、缺緯134張、漬類87張、破洞159張、正常100張。針織棉麻面料數據集一共包括465張512像素×512像素的圖像,其中缺經96張、缺緯104張、漬類109張、破洞106張、正常50張。TILDA中的星紋面料共包括25張疵點圖像和25張正常圖像。TILDA中的點紋面料共包括110張正常圖像和120張疵點圖像。
2.2.2 試驗結果
利用格紋面料訓練的模型對4種面料進行檢測,將本文算法與其他無監督算法(DEC、DCEC、MDEC、DMJC、VAED)和監督算法[27-29](Faster R-CNN、Yolov3、SSD)進行檢測精度對比,分析兩層次低秩分解(TLRD)和深度層次聚類網絡對織物疵點檢測精度的影響。試驗以檢測模型的精度為評價指標,精度計算如式(22)所示。
(22)
式中:TP為真正例;FN為假反例;FP為假正例;TN為真反例;Adetection為檢測模型的精度。
疵點檢測精度試驗結果對比如表4所示。

表4 不同算法對不同面料疵點的檢測精度試驗結果對比
由表4可知,兩層次低秩分解的無監督織物疵點檢測方法在格紋數據上訓練的模型,不僅格紋織物疵點的檢測精度能達到81.5%,而且平紋、點紋和星紋織物疵點的檢測精度也能分別達到86.1%、91.7%和95.2%。兩層次低秩分解模型(TLRD)與單層次低秩分解模型(LRD)相比,對于現有無監督算法,TLRD大都能有效提高其疵點檢測精度,提高檢測模型的泛化能力。與無監督算法DEC、DCEC、MDEC、VAED、DMJC相比,基于鄰域的深度層次聚類網絡算法能更準確地對織物疵點進行檢測,而且模型具有更好的泛化能力。與監督學習算法SSD、Faster-RCNN、Yolov3相比,本文算法對于格紋面料的檢測精度高于SSD,但由于沒有使用標簽數據,低于Faster-RCNN、Yolov3的檢測精度,而對于其他3種面料的檢測精度都高于監督算法,因此本算法具有更好的模型泛化能力。
2.3 面料疵點檢測結果
將4種不同面料的疵點圖像輸入檢測模型,得到疵點定位與分類的檢測結果。針織格紋面料、機織棉麻平紋面料、星紋面料、點紋面料的疵點檢測結果分別如圖4~7所示。檢測結果包括疵點種類和邊界框,每種顏色的疵點邊界框對應不同種類的疵點。檢測結果表明,檢測圖像經過兩層次低秩分解等預處理后,能夠將不同面料的不同紋理背景轉化為相同背景,以突出疵點的位置。因此,本算法不僅能夠對已訓練過的格紋面料進行精準的疵點分類與定位,而且對于未訓練的平紋、星紋、點紋面料,也能進行精準的疵點分類與定位。在實際面料疵點檢測中,能夠極大地減少標記成本和訓練不同面料疵點檢測的專有模型的成本。

圖4 格紋面料疵點檢測

圖5 平紋面料疵點檢測


圖6 星紋面料疵點檢測

圖7 點紋面料疵點檢測
3 結 語
本文提出一種基于兩層次低秩分解的無監督織物疵點檢測方法,實現了對針織格紋面料的4類疵點的有效檢測,檢測精度為81.5%。同時在使用相同的模型下對平紋、點紋和星紋面料疵點檢測的精度也能分別達到86.1%、91.7%和95.2%,有利于解決當前面料疵點檢測算法泛化性差、難以適應面料種類動態變化的生產實際問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
