基于深度學習的醫療問句分類研究*
2022-11-10 06:39:54陳小強
計算機時代 2022年11期
陳小強,胡 翰
(吉安職業技術學院,江西 吉安 343000)
0 引言
醫療資源不均衡,會導致醫患關系日益緊張,如何讓偏遠山區人民享受一線城市醫療資源已成為目前十分緊迫的問題。智能問診系統的出現,為解決此類問題提供了途徑,它可以整合醫療資源,為患者提供遠程/便捷的人機交互模式[1]。在人機交互模式下,問句分類是智能問答系統的一個關鍵部分,分類的準確性決定患者能否獲得最佳答案。文本分類做為機器學習非常重要的研究領域,已經在智能問答、情感分析[2]等方面有非常成熟的應用,然而與文本分類不同的是,問句分類[3]具有關鍵詞少、書寫不規范等特點,特別是對于醫療問句而言,患者提出的問句常常不夠專業,因此,在采用特征向量空間表征問句時,易出現數據稀疏、維數過大等難題。此外,大量的真實語料庫在特征向量構造時會引入噪聲數據。針對以上難題,本文提出基于維基百科和深度學習相結合的詞向量特征擴展模型,該模型利用中文維基百科語義結構和Word2vec構造特征詞向量,從而提高醫療問句分類準確性。
1 相關工作
雖然中文問句大部分比較短小,只包含幾個關鍵詞,但是問句中蘊含著豐富的語義關系,它的結構復雜,形式多樣,給研究者帶來不少難題。目前大部分研究集中在分類模型準確性、性能提升等工作,并且取得不錯的進展,近幾年,眾多學者開始著手研究問句關鍵詞提取,本文結合醫療問句自身特點,重點研究問句關鍵詞特征擴展,構建更準確的特征向量空間。
1.1 傳統的關鍵詞特征擴展
傳統關鍵詞特征擴展研究主要分為基于外部知識庫和基于內部語義結構方法。Yang等[4]提出通過借助外部知識庫,比如WordNet、HowNet 對短文本進行擴展,范云杰等[5]等[等提出基于中文維基百科擴展短文本。然而基于外部知識庫的關鍵詞特征擴展效果取決于知識庫的全面性、準確性,并且無法反應中文問句內部語義特征,所以特征擴展效果并不好。
后來有研究者提出基于內部語義結構特征擴展方法,葉雪梅等[6]提出基于改進的TF-IDF 關鍵詞特征擴展方法,胡江勇等[7]提出基于LDA 主題詞擴展特征向量模型。但是基于內部語義結構特征方法需要專門語料庫訓練、訓練速度慢,并且引入擴展構造主題詞使得向量維度較大且改變原本語義信息,導致分類效果一般。
1.2 基于深度學習的詞向量構建
為解決文本分類中關鍵詞矩陣稀疏的特點,有研究者提出了詞向量概念,通過文本語料訓練,將文本關鍵詞轉換成多維特征向量。2006年Hinton 等[8]率先提出深度學習概念,它是一種非監督的逐層訓練模型。深度學習模型不僅考慮了詞語出現的頻率,而且還考慮問句上下文語義關系,因此相比傳統的方法訓練結果更準確。目前主要有三種深度學習獲取特征詞向量的方法:①Bengio 等[9]在JMLR 上發表的三層深度學習模型,②Hinton 等[10]提出的訓練語言模型和詞向量,③Mikolov[11]團隊提出的Word2vec。通過Word2vec工具訓練得到關鍵詞向量后,結合卷積神經網絡模型TextCNN、快速文本分類模型FastText、長短期記憶網絡(LSTM)、注意力機制(Attention)可得到較好的分類效果。在深度學習基礎上,唐曉波等[12]提出先通過TF-IDF 和LDA 提取關鍵詞,再使用Word2vec擴展詞向量模型,雖然Word2vec 構造詞向量會考慮上下文語義關系,但是Word2vec生成的詞和向量一一對應,無法解決一詞多義現象,并且對于問句中新詞、網絡流行詞等頻率較低的詞效果較差,導致部分問句分類失真。
綜上所述,本文綜合維基百科和深度學習的優點,在保留中文問句語義信息的前提下,引入Word2vec和維基百科相結合的詞向量構造方法,既能最大限度地保留原始問句語義,又能提高中文問句分類效果。
2 基于維基百科和深度學習詞向量特征擴展模型
2.1 總體框架
⑴輸入層。導入醫療問句原始數據集medical.txt。
⑵預處理層。數據清洗,引入jieba 分詞工具對原始數據集分詞得到數據集train.txt。
⑶ 詞向量構造層。首先采用Word2vec 工具CBOW 和Skip-gram 模型分別構造醫療問句關鍵詞向量vector.txt(對于醫療問句關鍵詞詞頻低于5 次即舍棄)。然后對train.txt 問句中關鍵詞進行判斷,如果在vector.txt 中,則直接獲取關鍵詞向量,否則,利用維基百科ESA 算法構建擴展關鍵詞向量。最后將擴展關鍵詞向量合并構成medical_vector.txt。
⑷ 分類輸出層。采用TextCNN 對問句分類,總體框架如圖1所示。
2.2 詞向量構建模型
2.2.1 基于CBOW模型構造詞向量
CBOW語言模型是根據詞語上下文的聯合概率來判斷,比如,字符串S 包含一連串詞語單詞w1,w2,…wT組成,求字符串S是自然語言的概率,公式如下:
其中,Contexti表示該單詞的上下文,即它的前后c 個單詞。p(wi|Contexti)表示前后c個單詞出現的情況下,再出現該單詞的概率。例如,問句S=“小孩咳嗽應該怎么治療?”,對問句S分詞后為“小孩/咳嗽/應該/怎么/治療”得到6個單詞,如圖2所示。
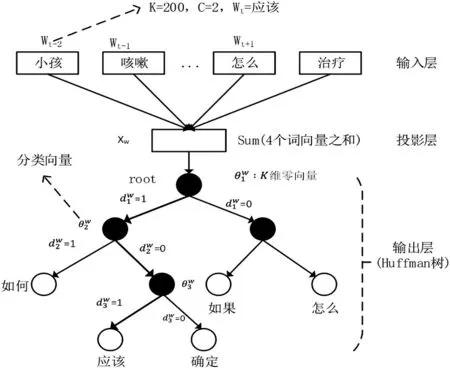
圖2 基于CBOW模型構造詞向量
除了上述的CBOW 語言模型外,Word2vec 還有Skip-gram語言模型,Skip-gram模型和CBOW模型不同的是,已知當前詞w,需要推測出它的上下文。
2.2.2 基于中文維基語義相似度詞向量構建
維基百科相似度算法ESA 主要是將文本關鍵詞映射到維基百科概念中,采用向量矩陣表示文本向量,TF-IDF表示文本向量的權重,通過余弦相似度來計算文本之間的相關度。以下是ESA算法實現過程。
Step1:對維基百科所有頁面分詞預處理,統計各個詞語wi在某個維基概念頁面的TF-IDF值為kj。
Step2:建立詞語wi和維基百科概念cj倒排索引,用kj表示它們之間的權重。詞語wi有多個維基百科概念cj,按照TF-IDF的值即kj大小排序。
Step3:對目標文檔分詞預處理,分別用詞語集合Ta={wi}、Tb={wi}表示,詞語wi的TF-IDF 值用向量{vi}表示,vi表示wi的權重。
Step4:文本Ta中詞語wi通過倒排索引,映射到維基百科概念cj,因為一個詞語wi有多個維基百科概念cj,所以對它們求和得到cj的權重,文本Ta 用向量空間{qj,q2,q3,q4,…,qn}表示,n 表示維基百科概念數目,同理求得Tb。
Step5:用余弦值求兩文本向量的相關度Red(Ta,Tb)。
Step6:最后根據相關度大小獲得詞語K 維擴展向量空間。
ESA 算法有效地利用了維基百科巨大的概念庫,基本上可以處所有的詞語,相比于知網的詞典計算,它覆蓋面更廣,而且對于網絡新詞、專有名詞處理也有較好的效果。但是ESA 也有自己的缺點,ESA 只是簡單的概念映射,容易引入噪聲數據。此外,ESA 需要考慮維基百科頁面所有數據,預處理階段花費更多時間和資源,表示文本向量時包括所有的維基百科概念,計算量過大。
而采用深度學習Word2vec 工具對問句進行詞向量訓練,不僅速度快,而且效率高,但是對于一些同義詞、網絡流行詞的處理效果不太好。因此本文采用中文維基百科與深度學習相結合的詞向量特征擴展模型,既能保持醫療問句詞向量的語義結構,又能構造網絡流行詞、同義詞特征向量空間。
3 實驗結果分析
3.1 實驗數據集
本文對中文醫療問句進行分類,其中訓練語料有兩大來源,一是通過網絡爬蟲從好大夫網站(https://www.haodf.com/)爬取63992 條醫療問句。二是從中文維基百科知識庫抽取醫療關鍵詞信息。
3.2 實驗環境
實驗運行環境為Windows 10,內存配置16GB,CPU 配置Intel i7 9700,編譯環境為Anconda3,編程語言Python 3.9,深度學習框架TensorFlow 1.14,分詞器采用jieba,使用Gensim包構建Word2vec詞向量。
3.3 實驗設計
3.3.1 數據預處理
從“好大夫”網獲取的醫療問句數據,我們對其做以下預處理操作:
⑴數據清洗,清除原始醫療問句中錯誤數據、無效數據、重復數據;
⑵將醫療問句數據分成包括內科、外科、兒科、耳鼻喉科、眼科、婦科、男科、皮膚科、中醫科、傳染病科10大類;
⑶使用jieba 分詞器進行分詞,結合中文維基百科提高醫學類專有名詞提高分詞準確率;
⑷將預處理的醫療問句數據集分成10 份,按照8:1:1的比例確定訓練集、測試集、驗證集三大類。
3.3.2 構建詞向量
本文采用Gensim 包構建Word2vec 詞向量,詞向量維度設置300,訓練窗口大小默認設置5,訓練算法模型為CBOW和Skip-gram。采用準確率(P)、召回率(R)、均衡參數(F)對實驗結果評價,相關公式如下:

3.4 實驗結果分析
本實驗對醫療問句分類采用TextCNN 模型,分別對傳統的詞袋模型(BOW),CBOW 直接訓練詞向量模型(CBOW)、Skip-gram 直接訓練詞向量模型(SG)、CBOW+維基百科模型(WCBOW)、Skip-gram+維基百科模型(WSG)進行比較,這五種不同方法的分類效果對比如表1所示。
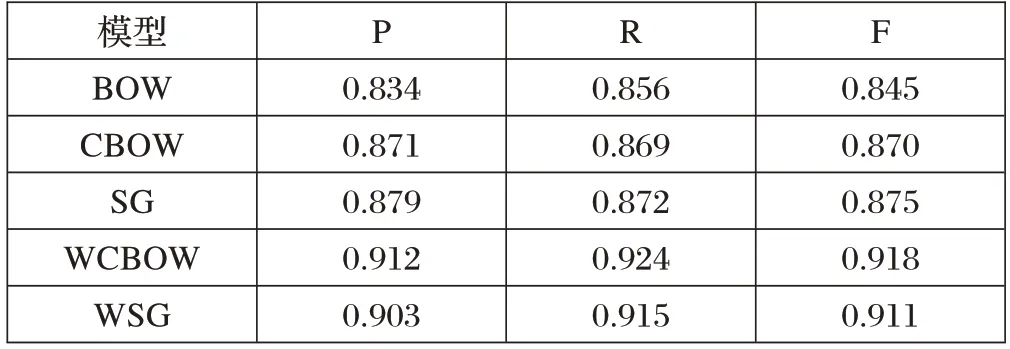
表1 不同模型分類效果對比
由表1可知,CBOW+維基百科模型(WCBOW)分類效果最佳,P值、R 值、F值均為最高,達到0.912、0.924、0.918,相對于傳統的SG 方法分別提升了3.6%、5.9%、4.9%。由此可見,基于CBOW+維基百科(WCBOW)模型相比BOW、CBOW、SG、WSG有效可行。
4 結束語
由于醫療問句關鍵詞較少、向量稀疏,對其分類存在困難,因此本文提出了基于深度維基學習的詞向量擴展模型。核心思想是通過CBOW 方法對問句關鍵詞訓練生成詞向量,對稀有特征詞采用維基百科語義結構生成詞向量,合并后構成問句關鍵詞特征向量空間,實驗表明本文方法由于傳統的Skip-gram、CBOW、BOW模型。
本文方法提升了醫療問句分類效果,改善了智能問診系統的效率,同時,也為其他短文分類提供依據。但本文中基于維基百科和深度學習詞向量構造方法也存在一定局限,它忽略了問句關鍵詞前后之間的語義關系,后續研究可嘗試從卷積神經網絡擴展關鍵詞向量。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
