基于卷積自動編碼器視頻背景圖像提取方法研究*
2022-11-09 02:35:04蔣朝平蔡衛峰
計算機與數字工程 2022年9期
關鍵詞:背景
蔣朝平 蔡衛峰
(南京理工大學自動化學院 南京 210094)
1 引言
近年來,深度學習在計算機視覺領域取得了突破性進展,特別是深度無監督學習已成為圖像識別領域重要的研究方向[6~7]。相比于傳統方法手動提取特征,卷積網絡可以自動提取特征,并具有較好的泛化能力。本文提出了一種有效的視頻背景圖像提取算法,該算法采用卷積自動編碼器自動提取輸入圖像的特征,將圖像的前景當作噪聲處理,通過重建圖像獲得視頻的背景信息。
2 卷積自動編碼器及背景提取算法
2.1 卷積自動編碼器
卷積自編碼器[8]使用卷積層代替了傳統自編碼器的全連接層,結合了傳統自編碼器的無監督學習方式和卷積神經網絡的卷積和池化操作。卷積自動編碼器包含編碼器和解碼器,編碼器對輸入數據進行卷積和下采樣,找出數據中的局部特征,并采用權值共享減少參數計算量,解碼器進行逆向還原,常規卷積自動編碼器具有卷積層、下采樣層、上采樣層、反卷積層,示意圖如圖1所示。

圖1 卷積自編碼網絡示意圖
2.2 背景提取算法
2.2.1 卷積自動編碼器背景圖像提取模型
Pathak等[9]提出一種卷積編碼器修補網絡,可根據周圍環境生成缺失圖像的內容,在卷積自編碼器中,丟失的圖像被視為噪聲,受此啟發,本文采用編解碼網絡將輸入圖像的前景視為噪聲,編碼器將輸入圖像表示為潛在的特征向量(潛在特征向量會從輸入圖像中提取最有用的信息),再使用解碼器從表示的特征向量中恢復背景圖像,從而重構背景圖像。本文采用的編碼器具有兩個卷積層,每層卷積層又采用最大池化方式降低維度,最后采用全連接層生成20維向量來表示原輸入圖像,解碼器具有一個全連接層和兩個反卷積層,重構出和原圖像同尺寸的背景圖像,其網絡結構如圖2所示。本文在編碼器和解碼器的每一層最后都添加了非線性激活函數,非線性函數可以提取比PCA等常用線性變換更有用的特征,使模型具有更強的學習能力,編碼器的卷積層使用relu(x)激活函數,解碼器的第一層采用relu(x)激活函數,第二層采用sigmoid(x)激活函數,激活函數的圖形和公式如圖3所示。
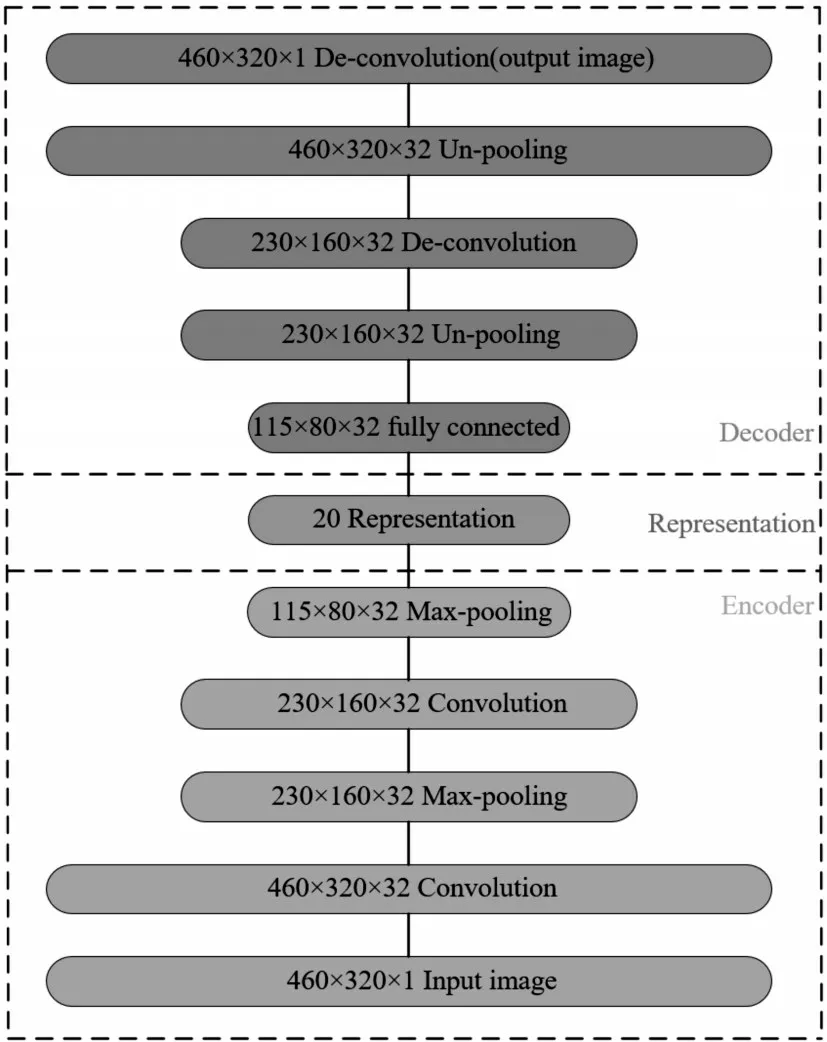
圖2 卷積自編碼網絡結構圖
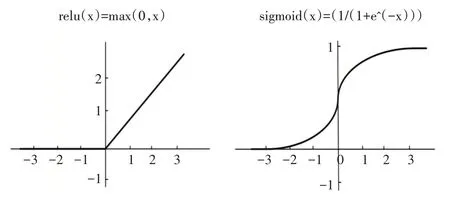
圖3 本文使用的激活函數
2.2.2 模型參數
本文采用的輸入圖像為單通道灰度圖,大小為460*320,共有250張圖像參與訓練和5張圖像參與測試。編碼部分的卷積層包含32個卷積核,步長為1,填充方式為SAME,共產生32張映射圖,池化層采用最大池化,步長為2,保留圖像最有意義的特征,全連接層將圖像編碼成20維向量;解碼部分采用Un-pooling(反池化)[10]擴充特征圖,該方法基于tf.nn.conv2d_transpose()函數,使用s×s的內核替換特征圖中s×s的左上角的元素,其余值置為0,相比于上采樣方法,該方法使用了Max-pooling的位置信息,避免將內容直接復制來擴充特征圖,實現方式如圖4所示(考慮到Max-pooling采用的核為2×2,故Un-pooling的核大小也為2×2)。反卷積采用5×5的卷積核,步長為1,填充方式SAME。

圖4 Un-pooling
2.2.3 SSIM損失函數
可見,在淹水期間,各處理水稻株高的生長速率與對照相比,淹水天數增多,株高增高越快。分蘗期淹水處理之后,各處理水稻株高和節間的生長速率與對照相比,淹水天數增多,增長速率減慢,最終表現為成熟期水稻的株高和節間變得越矮越短。一方面原因是適度淹水條件影響下促進了水稻的抗逆反應,水稻通過伸長水面上的莖葉等途徑獲取氧;另一方面原因是淹水促進了“乙烯”的產生,間接促進根、干和葉的生長,以及提高節間細胞分裂,以往的研究中亦有類似結論的報道[9-10]。但當淹水深度和淹水時間不斷增加,逐漸超過水稻的耐受限度時,其后期生長能力下降致使成熟期水稻株高的降低。
損失函數用于計算網絡的輸入圖像和網絡的重構圖像之間的相似性。Zhao等[11]通過圖像超分辨率、聯合去噪等實驗得出結論:L2損失函數由于基于像素比較差異,沒有考慮人類視覺感知,也未考慮人的審美觀,峰值信噪比指標高,并不代表圖像質量好,故本文未采用L2損失函數優化自動編碼器。Zhou等[12]提出結構相似性指數用來評估兩幅圖像之間的誤差,該損失函數考慮了亮度、對比度和結構行指標,即考慮了人類的視覺感知,本文采用SSIM損失函數進行優化,從而減小輸入圖像和重構圖像的誤差。
首先假設亮度未離散信號,則平均亮度如式(1)中μx所示,亮度比較函數l(x,y)是μx和μy的函數,如式(2)所示。
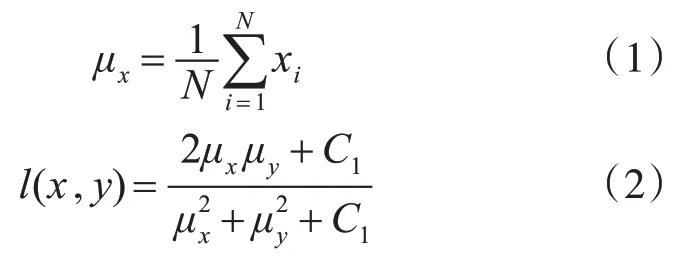
其中,C1=(k1L)2,是用來維持穩定的常數。離散信號對比度估計可表示為式(3),對比度比較函數c(x,y)是σx和σy比較的結果,如式(4)所示。
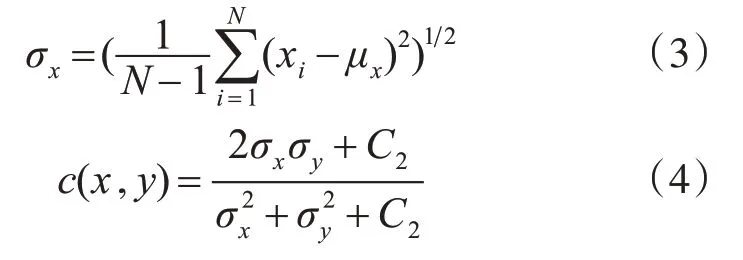
其中,C2=(k2L)2,是用來維持穩定的常數,σx2是x的方差,是y的方差,再將信號除以標準差,使得比較的兩個信號具有單位標準差,即歸一化信號,如式(5)所示:
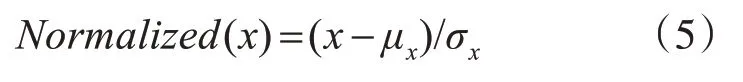
s(x,y)是基于歸一化信號得到的兩張圖像間的結構比較函數,如式(6)所示。

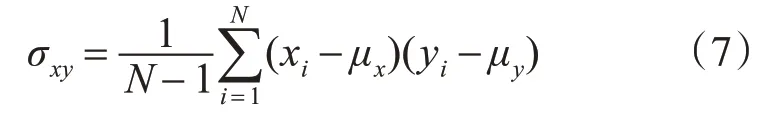
將三部分合起來,可表示出整體的相似性度量,如式(8)所示。

將亮度比較函數l(x,y)、對比度比較函數c(x,y)、結構性比較函數s(x,y)和組合函數f(·)代入式(8)可得SSIM函數的表達式,如式(9)所示。
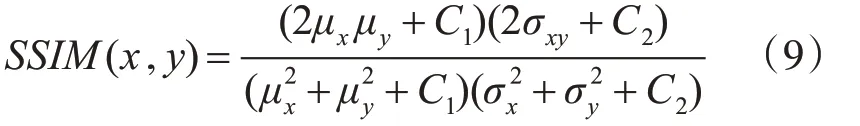
結構相似性的范圍為0~1,當兩張圖像完全相同時,SSIM的值為1。結構相似性指數從圖像組成的角度將結構信息定義為獨立于亮度、對比度并反映結構的屬性,作為本文自動編碼器的損失函數,可構建精準的背景圖像。
2.3 算法總結
本文采取卷積自動編碼器提取視頻背景圖像,將某一監控視頻場景的250幀單通道圖像輸入卷積網絡,卷積網絡將輸入圖像降維至20維向量表示,將前景圖像視作噪聲,再通過解碼重構,選用SSIM損失函數,降低重構損失,提取視頻背景圖像。
3 實驗結果與分析
3.1 實驗平臺及數據集
基于卷積自動編碼器的實驗環境包括硬件設備和軟件配置兩部分,測試所用硬件配置為Intel Core i7-8700 CPU,GPU為NVIDIA GeForce GTX 1060(顯存為6G),內存為16GB。文章的軟件環境為Window10 64bit,CUDA Toolkit 9.0,OpenCV 3.4,Python 3.6與Tensorflow 1.12.0。
本次實驗采用數據集為UCSD數據集[13]和Avenue數據集[14]。UCSD數據集通過固定在學校某位置的攝像機拍攝人行道獲得,數據記錄了不同場景人群的運動模式,包含行人、卡車、滑板、自行車、碾壓草坪等。從每個場景記錄的視頻大約為200幀,UCSDPed1數據集拍攝了行人走向和遠離攝像機的運動場景,UCSDPed2數據集拍攝了行人平行與攝像機運動的場景。在Avenue數據集中,每段視頻的時長在一分鐘到兩分鐘之間,包括人在樓梯和地鐵入口之間行走、奔跑、閑逛等場景。
3.2 數據預處理
UCSD異常數據集(包含Ped1和Ped2兩個場景),采用.tif格式圖像序列記錄每個場景,需要將.tif格式轉換為.jpg格式,Avenue數據集使用.avi格式的視頻文件存儲每個拍攝場景,需要從原視頻中提取每一幀轉換成.jpg格式,再將所有的圖像調整為460×320大小并轉換為灰度圖像以降低維數。
3.3 模型訓練結果
本文從Ped1、Ped2和Avenue數據集中隨機挑選250張圖像作為訓練集,另準備5張圖像作為測試集。圖5為Avenue的實驗結果,其中圖5(a)為訓練集圖像,圖5(b)為選擇的測試圖像,圖5(c)是灰度處理后的測試圖像,圖5(d)為重構的背景圖像。圖6和圖7分別為Ped1和Ped2的實驗結果,圖像排列方式同圖5(訓練時間為34min)。

圖5 Avenue數據集實驗結果

圖6 Ped1數據集實驗結果

圖7 Ped2數據集實驗結果
圖8(a)、圖8(b)、圖8(c)分別為Avenue數據集、Ped1數據集、Ped2數據集訓練的損失值。對于不同場景,訓練損失下降速度略有不同,但一般訓練5次左右,即可達到穩定值,表明對于不同視頻場景,模型穩定性較好。
圖8 三種數據集訓練損失
3.4 背景提取結果對比
3.4.1 基于不同損失函數
本文將SSIM損失函數和MSE損失函數分別進行實驗,實驗結果如圖9所示,圖9(a)兩張背景提取圖像結果相差不大,但圖9(b)與圖9(c)結果對比發現,基于MSE損失函數提取的結果存在重影、前景遺留的現象,基于SSIM損失函數提取結果則無前景遺留和重影的問題。

圖9 基于不同損失函數結果對比
3.4.2基于不同提取方法
本文將基于卷積自動編碼器背景提取方法與基于SVD背景提取方法[15]對比,實驗結果如圖10所示。圖10(a)對比可以發現,基于SVD方法背景提取存在模糊現象,圖10(b)與圖10(c)對比發現基于SVD方法提取的背景存在前景對象的殘影,精度不夠高,本文方法提取的背景更為清晰。

圖10 基于不同提取方式結果對比
4 結語
本文結合深度學習的優勢,使用卷積自動編碼器提取固定場景的監控視頻背景圖像,相比于傳統方式提取背景,卷積自動編碼器具有更強的泛化能力,對于不同場景,提取的背景無殘影、重影、模糊等問題,但是采用深度學習的方式提取視頻背景圖像需要較高的硬件成本,需要一定的訓練時間,從實驗結果看,采用灰度圖像進行和低分辨率圖像可大大較少訓練時間,滿足日常監控視頻背景圖像提取的需求。
猜你喜歡
教學考試(高考化學)(2022年5期)2022-11-19 14:15:16
汽車工程師(2021年12期)2022-01-17 02:29:54
當代陜西(2020年14期)2021-01-08 09:30:42
奧秘(創新大賽)(2020年7期)2020-07-27 08:26:32
活力(2019年21期)2019-04-01 12:18:06
中國自行車(2018年10期)2018-11-30 02:09:04
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
紡織服裝流行趨勢展望(2016年1期)2016-05-04 03:45:20
語文知識(2015年11期)2015-02-28 22:01:59
中國衛生(2014年10期)2014-11-12 13:10:16
