一種基于圖嵌入模型的關聯感知真值發現
2022-11-05 07:44:48XiuSusieFang司蘇新
智能計算機與應用 2022年10期
呂 航,Xiu Susie Fang,司蘇新,王 康
(東華大學 計算機科學與技術學院,上海 201620)
0 引言
在過去的幾十年里,從搜索引擎、社交媒體平臺、眾包平臺等各種網絡渠道收集的數據量急劇增加。人們往往可以從不同的數據源收集同一實體的聲明信息,然而由于記錄錯誤、機器故障、噪音、惡意攻擊等原因,這些信息可能會相互沖突。如果不解決這些沖突,從網絡上檢索到的信息將毫無用處。為了得到可靠的信息(即真實的事實),就需要研究多源數據的聚合技術。
近些年來,許多研究提出了多源數據聚合的方法。這些方法可以分為3類:
(1)迭代法。迭代計算來源的可靠性和聲明值的可信度。
(2)基于最優化的方法。使每個聲明值與真實值之間的源加權距離最小。
(3)概率法。對源和聲明值的聯合分布進行建模,使聯合分布可能性最大化。
雖然現有方法已取得了不錯的效果,但大部分方法都忽視了實體屬性之間存在的各種關聯。研究可知,充分利用實體屬性之間的關聯能提升真值發現結果的準確性。
這里通過表1中的實例來闡述這一點。由表1看到,實體具有年齡、出生日期、居住城市和郵編等屬性。這些屬性中存在如下關聯:年齡取決于出生日期,城市和郵編具有一一對應關系。如果采用多數投票的方法,可能會在實體1的年齡屬性上得到錯誤的結果為18歲。然而,通過考慮年齡和出生日期之間的依賴關系,就可以先獲得出生日期的真值,即2004年1月1日,從而得到正確的年齡為19歲。這說明如果在本文的方法中,能夠捕捉屬性間的關系,可以獲得更準確的結果。
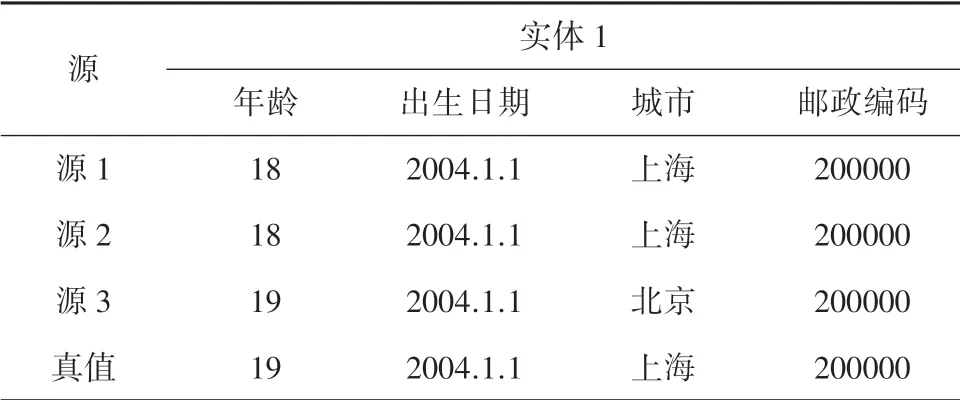
表1 實體的信息表Tab.1 Entity information table
考慮實體屬性相關性的真值發現研究仍處于起步階段,僅有的一些方法對實體屬性關系的捕捉還不全面,比如現有的研究集中于屬性的幾種特定關系,如時間關系、空間關系或常識,或將屬性之間的關系采用數據間約束來表示。本文提出的異構網絡模型不僅捕捉了數據源間的相似關系、數據源對聲明值的偏好選擇關系,還考慮了實體屬性的一般化關系來推斷實體屬性的真實值。接下來將基于2個真實世界數據集的實驗結果證明了本文的算法優于現有方法。
1 圖嵌入模型
1.1 問題定義
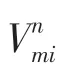
1.2 異構網絡
本節將創建4個網絡,這4個網絡一起構建了一個大型的異構網絡,如圖1所示,用于處理存在實體屬性關聯的真值發現問題。
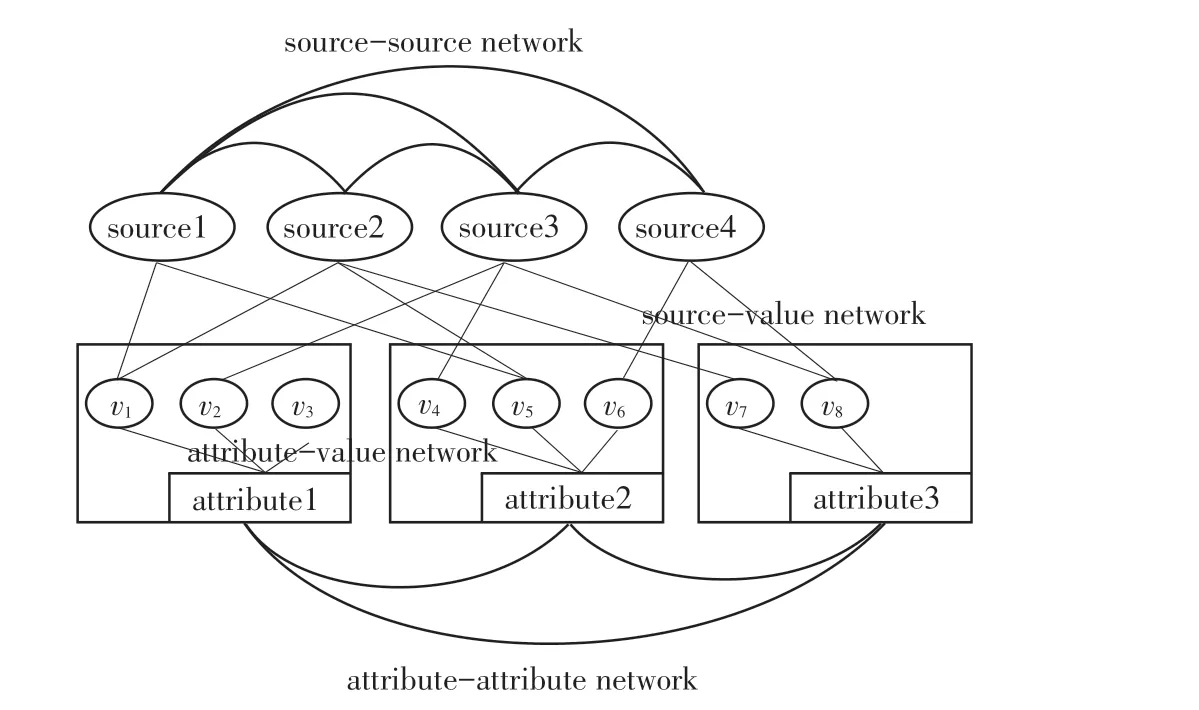
圖1 異構網絡Fig.1 Heterogeneous network
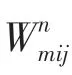
通過定義源與屬性值之間的網絡,能夠對源聲明一個屬性值的過程建模,這種建模可以將源的可靠性體現在其對聲明值的偏好選擇上。
源與源之間的網絡定義為G=(∪,E),這里是源的集合,E是源與源之間的邊,邊上定義了2種不同權重。第一種W為源S和源S對給定的同一實體的同一屬性做出相同的聲明值的數量,第二種D為這2個源對給定的同一實體的同一屬性做出不同的聲明值數量。
通過定義源與源之間的網絡,能夠挖掘源與源之間的相似性。如果相同聲明值權重W越大于不同聲明值權重D,則說明2個源越相似。同時結合源-屬性值網絡中捕捉的關系,源之間的關系表明了源提供可信聲明的偏好。
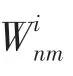
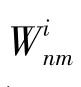
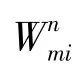
4種異構網絡中捕捉的各種連接關系為規范化真值發現建模提供了更多的證據。
1.3 網絡的嵌入
在本節中,提出將4種異構網絡嵌入到低維空間的處理方法。由于這個異構的網絡由4個子網絡組成,這里采用的是對每個子網絡進行嵌入,再嵌入整個異構網絡的方法。
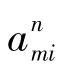
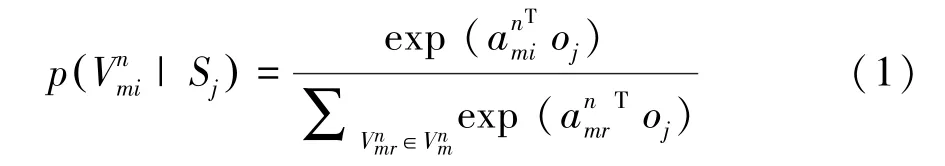
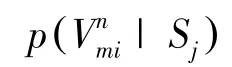
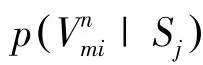
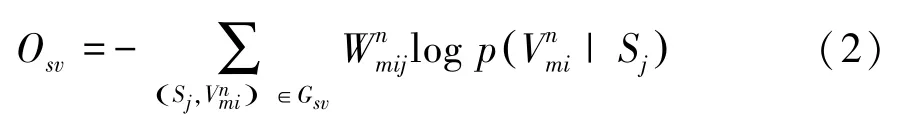
對于圖G的每一條邊,定義了源S和源S的聯合概率:
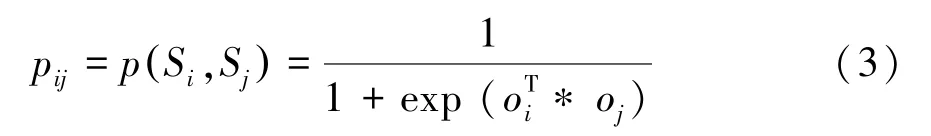
越高的條件概率p表明源S和源S具有越高的相似性。即源S和源S在同一實體屬性上做出相同聲明值的概率為p。
圖G對于每一條邊定義了2種不同的權重,在已知p的條件下,可以得到2種權重的條件概率:
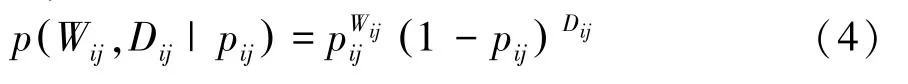
研究用分布去解決數據稀疏問題。此處需用到的數學公式為:
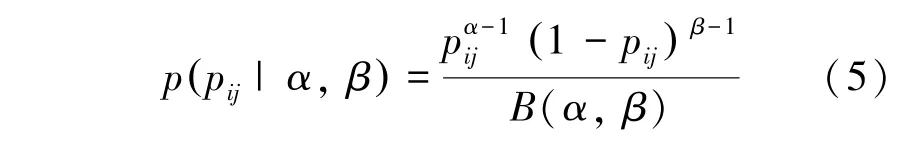
其中,是函數,,是2個超參數。
通過最大化由源-源網絡得到的概率,能使具有相似可靠性的源在嵌入空間內的距離相近。即最小化損失函數O:
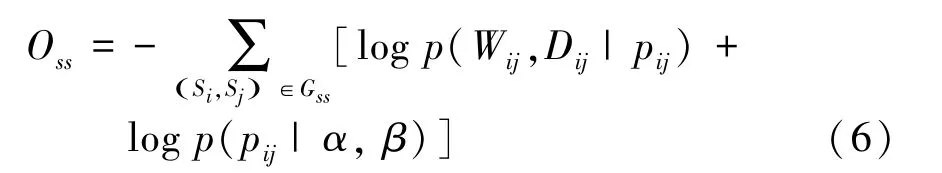
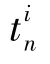
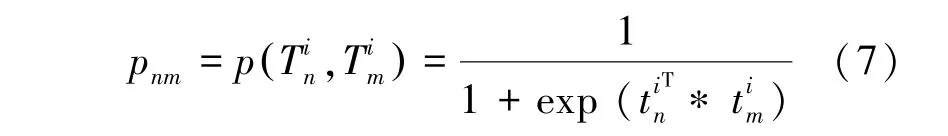
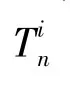
圖G對于每一條邊定義了2種不同的權重,在已知p的條件下,可以得到2種權重的條件概率為:
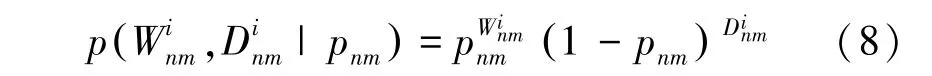
接著提出用分布去解決數據稀疏問題。推理得出的數學公式為:
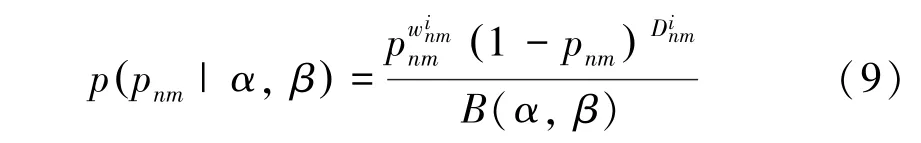
其中,是函數,,是2個超參數。
通過最大化屬性-屬性網絡得到的概率,能使具有關系的屬性在嵌入空間內的距離相近。即最小化損失函數O:
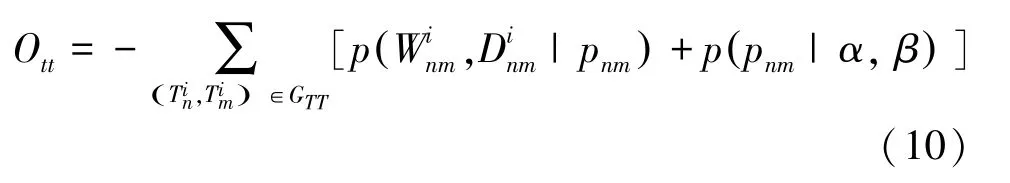
通過定義實體屬性-實體屬性值之間的網絡,能將建模的實體屬性之間的關系體現在屬性值層面上。定義圖G上的2條邊上的屬性值成對出現的概率為:

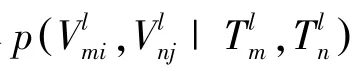
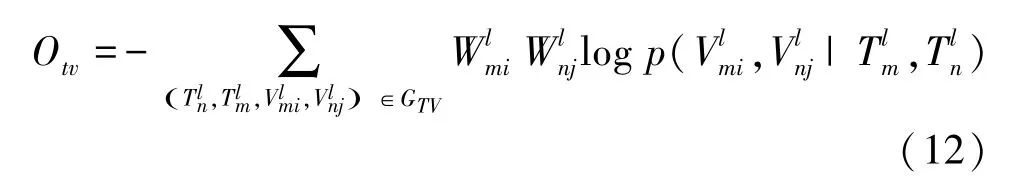
本次研究的目標是使源、實體屬性、實體屬性值的聯合概率最大化,等價于最小化損失函數O、O、O、O,即最小化O:
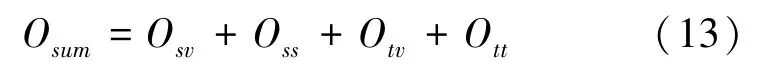
1.4 模型的學習
一種直觀的解法:可以同時使用所有子網絡來學習并更新各種嵌入的表示。即公式(13)的優化,也就是通過合并所有子網絡的邊,并對邊抽樣,抽樣的概率與其在網絡中的權重成正比,再根據抽樣的邊對參數的嵌入表示進行更新。但由于不同子網絡的權重是不可比的,因此迭代采樣每個子網絡的邊,基于偏導對每個子網絡的嵌入表示進行更新。
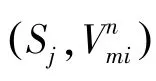
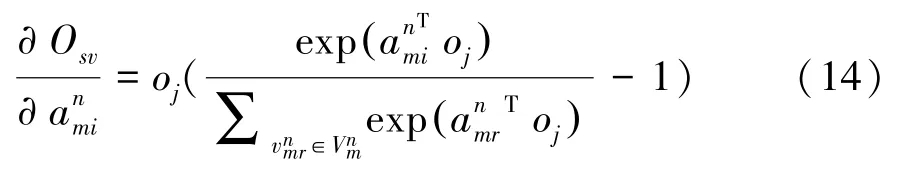
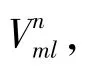
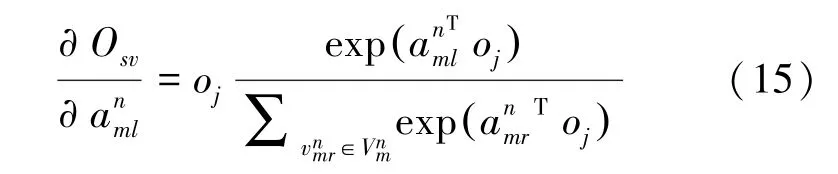
緊接著,計算O關于源S的偏導:
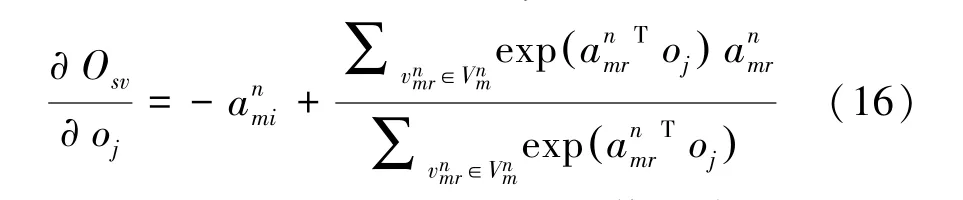
通過式(14)~(16)對源,屬性值的嵌入表示的更新,能使可靠的源和可信度較高的屬性值在嵌入空間距離相近。
對于源-源網絡,同樣計算源S關于O的偏導:
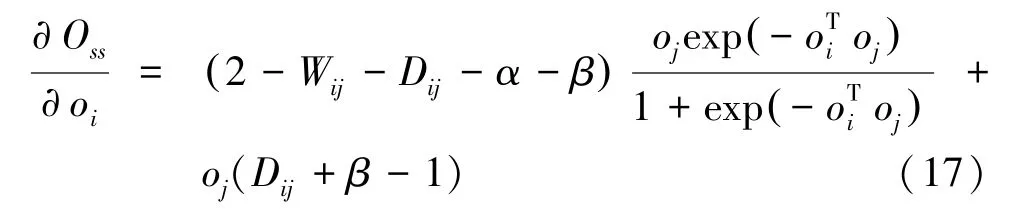
通過對源的嵌入表示的更新,能使具有相似可靠性的源在嵌入空間相近。
對于實體屬性-實體屬性網絡,同樣計算實體屬性T關于O的偏導:
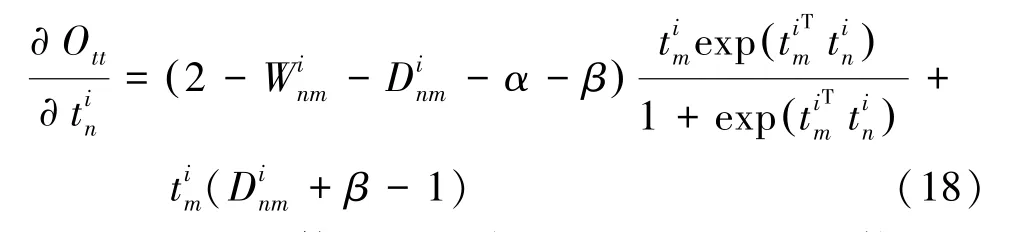
通過對實體屬性的嵌入表示的更新,能使具有關聯的實體屬性在嵌入空間相近。
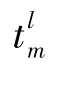
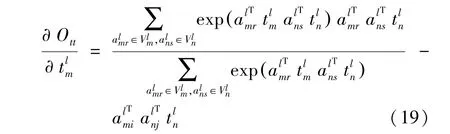
計算O關于t的偏導:
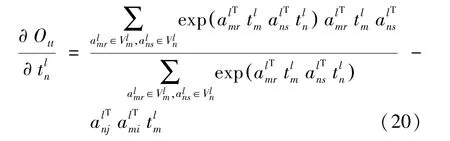
計算O關于a的偏導:
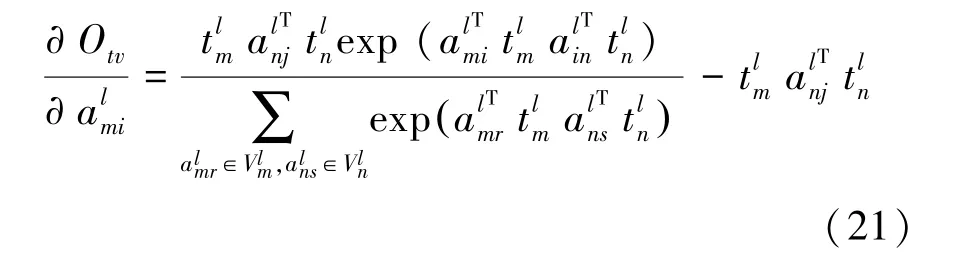
計算O關于an的偏導:
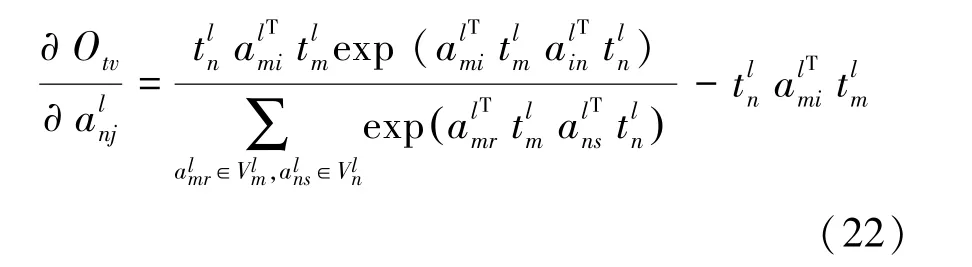
通過式(19)~(22)對實體屬性、屬性值的嵌入表示更新讓滿足實體屬性之間關聯的屬性值在嵌入空間靠近實體屬性。
綜上所述,就可使用隨機梯度下降(SGD)方法去更新實體屬性、源、屬性的嵌入表示。
1.5 真值的推斷
在模型學習中,得到了屬性值嵌入、源嵌入和屬性嵌入,同時對于各種嵌入的優化讓真值嵌入和真實屬性值嵌入在嵌入空間中接近。因此通過計算集合V中每個屬性值和真值之間的相似性,相似性最高的屬性值即為屬性的真實值。
但是由于本文算法是無監督的,并沒有真值的嵌入。為了構造真值嵌入,文中采用對所有屬性多數投票來找到真實值,對得到的真實值的集合按照真實值的可信度進行排序,從排序的真實值集合選取前個真實值并取其平均值作為真值的嵌入。
2 實驗
研究采用Python(3.6)實現了所有的基線方法和本文提出的模型(GETD),所有的實驗都是在Intel Core i5-7200U CPU@2.50 GHz的電腦上運行的。
2.1 數據集
(1)Restaurant:該數據集包括來自5個源提供的信息。每個餐廳是一個實體,每個實體有5個分類屬性:餐廳名稱、建筑編號、街道名稱、郵政編碼和電話號碼。
(2)Weather:該數據集包含9個來源提供的信息,每個城市是一個實體,每個實體具有30個分類屬性,即一個月內的天氣情況。
真實數據集的統計結果見表2。
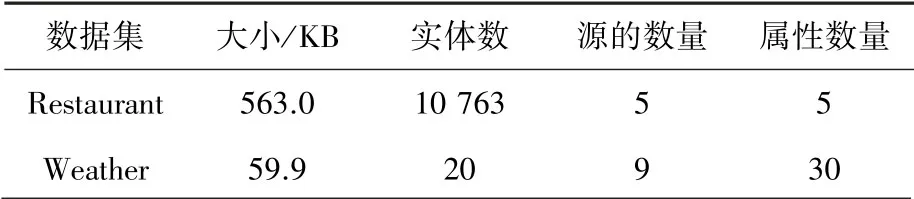
表2 真實數據集的統計Tab.2 The statistics of real-world datasets
2.2 評價指標
錯誤率():推斷的實體屬性真實值與中不同的數量占的百分比,越小的錯誤率表明實驗結果越好。
2.3 對比算法
(1)Majority Voting:該方法認為在所有源中出現次數最多的聲明值為真值。
(2)TruthFinder:通過給定源的可靠性,去推斷真值,再根據真值去推斷源的可靠性,迭代更新源的可靠性和真值至收斂。
(3)CRH:將真值發現視為一個最優化問題,采取兩步迭代更新,一步更新源權重,一步更新值的可信度。
(4)CATD:采用最優化的方法解決真值發現問題,將源的權重采用置信區間的方式建模,以解決數據稀疏問題。
(5)CASE:通過使用一種嵌入方法,解決真值發現問題,但不考慮屬性之間的關系。
(6)CTD:將真值發現視為一個最優化問題,同時使用數據庫約束來捕捉屬性關聯的方法。
2.4 實驗設置
為了確保公平的對比,研究運行了一系列的實驗來為每個基線方法設定最優的參數。對于本文的方法,設置嵌入維度為12。對于SGD方法,設置學習率為0.1。設置函數中和為1.1。對于真值的推斷步驟中值設為3%。
2.5 實驗結果
在表3和表4中列出了不同真值發現算法在Restaurant數據集和Weather數據集上實驗3次的運行結果及平均的錯誤率。從實驗結果中,可以看到本文提出的GETD方法在2個真實世界數據集上都優于其他方法,這是因為這些基線方法大多都沒有考慮屬性之間的關系,只是單純地考慮數據源的可靠性或相似性,并不能捕捉屬性之間的關系,導致實驗精度不夠。CTD算法雖然考慮了屬性之間的關系,但是算法的reduction部分并未考慮迭代,導致了精度的丟失。本文提出的GETD模型在考慮源的可靠性與源的相似性的基礎上,全面捕捉了一般化的屬性關系,能夠更加精準地挖掘底層數據之間的關聯。
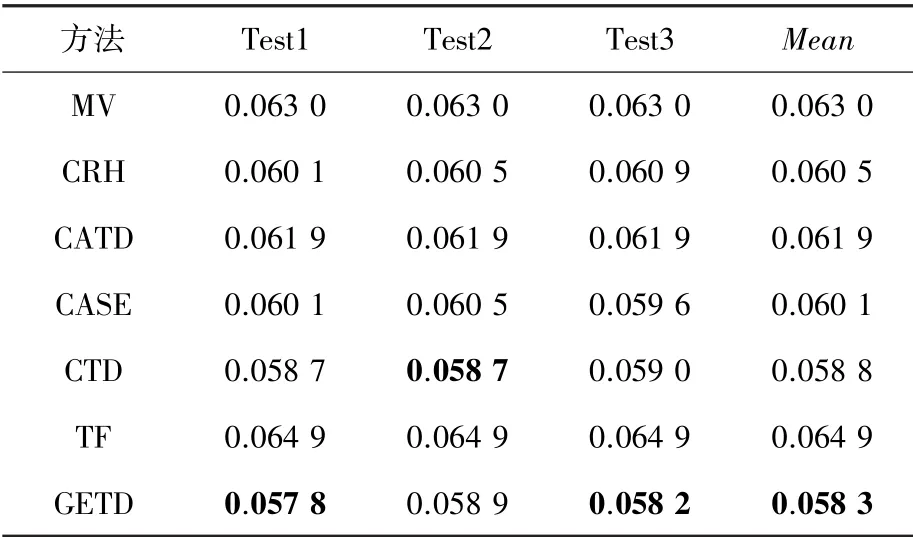
表3 基于Restaurant數據集的對比結果Tab.3 Comparison results based on Restaurant dataset
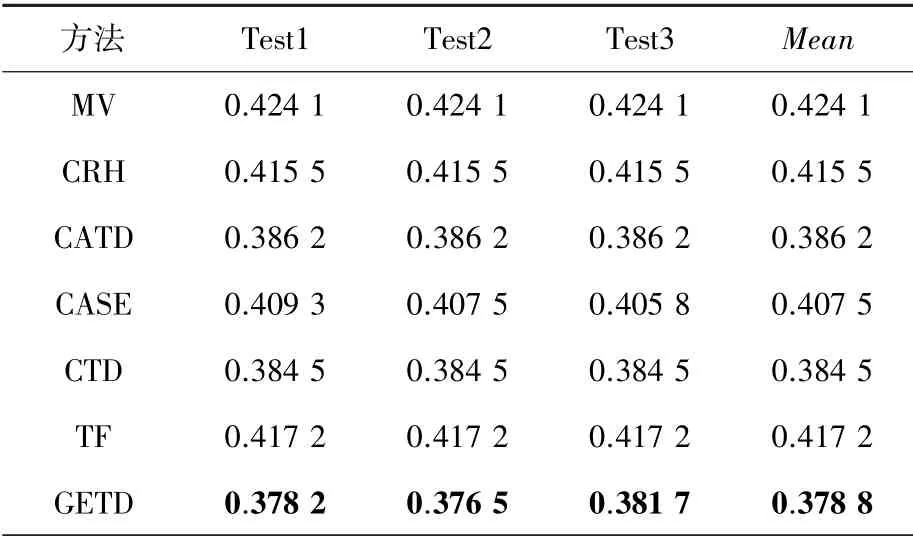
表4 基于Weather數據集的對比結果Tab.4 Comparison results based on Weather dataset
2.6 不同L值對實驗結果的影響
通過在Restaurant數據集上采用不同值,研究該參數對實驗結果準確性的影響。在這個實驗中采用實驗效果最好的CTD作為對比算法。實驗結果如圖2所示,當值低于2%時,GETD的錯誤率較高,效果不如CTD,但當值較大時,本文的方法始終優于CTD算法。根據實驗結果,文中將設置3%。
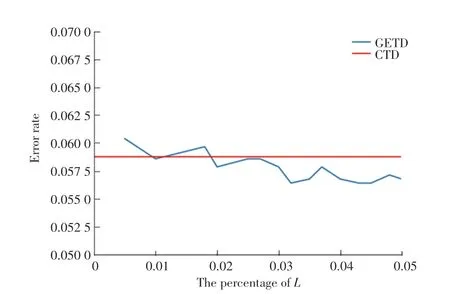
圖2 Restaurant數據集上不同L值對錯誤率的影響Fig.2 Influence of different L on error rate in Restaurant dataset
3 結束語
本文采用基于異構網絡的圖嵌入方法解決了存在屬性關聯的真值發現問題。提出的模型構建了4個異構網絡,包括源-屬性值、源-源、實體屬性-實體屬性和實體屬性-實體屬性值網絡。同時,通過源-屬性值網絡捕捉源可靠性與屬性值可信度的關系、源-源網絡捕捉源之間的相似性關系、實體屬性-實體屬性網絡捕捉屬性之間的關系,實體屬性-實體屬性值網絡將建模的實體屬性之間的關系體現在屬性值層面上,對每個子網絡采取隨機梯度下降的方法來更新嵌入表示,最后根據嵌入表示來推斷真值。在2個真實世界數據集上的實驗證明了該模型的有效性。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
