基于BERT模型的指令集多標(biāo)簽分類研究
2022-11-05 07:45:12王淳睿何先波
智能計(jì)算機(jī)與應(yīng)用 2022年10期
王淳睿,何先波,易 洋
(1 西華師范大學(xué) 電子信息工程學(xué)院,四川 南充 637009;2 西華師范大學(xué) 計(jì)算機(jī)學(xué)院,四川 南充 637009)
0 引言
研究可知,編譯器作為芯片生態(tài)系統(tǒng)中的重要一環(huán),對(duì)自主操作系統(tǒng)的研發(fā)起著非常關(guān)鍵的基礎(chǔ)性作用。2021年4月,龍芯推出Loong Arch國(guó)產(chǎn)自主指令集(Instruction Set Architecture,ISA),一方面折射出國(guó)內(nèi)芯片生態(tài)系統(tǒng)的發(fā)展?jié)摿Γ瑫r(shí)也展示出了國(guó)內(nèi)芯片生態(tài)系統(tǒng)的應(yīng)用前景。然而面對(duì)全新的ISA、例如Loong Arch,構(gòu)建出支持Loong Arch架構(gòu)的編譯器后端需要耗費(fèi)大量人力以及時(shí)間。本文參考低級(jí)虛擬機(jī)(Low Level Visual Machine,LLVM)中指令描述的代碼,將指令劃分為13類,并以此為分類原則訓(xùn)練基于BERT的多標(biāo)簽分類模型。該模型對(duì)Mips、ARM指令集架構(gòu)手冊(cè)中指令的分類有著不錯(cuò)的表現(xiàn),根據(jù)指令分類完成的類別可減少開發(fā)人員對(duì)編譯器后端指令定義相關(guān)部分所花費(fèi)的時(shí)間,從而有效提升編譯器構(gòu)建效率。
1 相關(guān)理論及方法
1.1 BERT訓(xùn)練模型
BERT(Bidirectional Encoder Representation from Transformers)是一種為不同自然語(yǔ)言處理任務(wù)提供支持的預(yù)訓(xùn)練語(yǔ)言表示模型。該模型基于2017年谷歌公司發(fā)布的Transformer架構(gòu),由Transformer的雙向編碼器構(gòu)成。區(qū)別于ELMo和GPT等單向傳統(tǒng)語(yǔ)言模型,BERT利用掩碼語(yǔ)言模型(masked language model,MLM)進(jìn)行預(yù)訓(xùn)練,并且采用深層的雙向Transformer組件來構(gòu)建整個(gè)模型,最終生成能融合左右上下文信息的深層雙向語(yǔ)言表征,增加一個(gè)輸出層,可以對(duì)預(yù)訓(xùn)練的BERT模型進(jìn)行微調(diào)(Fine-Tuning),為各類執(zhí)行任務(wù)創(chuàng)建先進(jìn)的模型,無需針對(duì)特定任務(wù)的架構(gòu)做實(shí)質(zhì)性的修改。
BERT的模型架構(gòu)采用了Transformer模型的編碼部分,模型的輸入由3種嵌入層累加構(gòu)成,具體就是:詞嵌入(Token embeddings),將各個(gè)詞轉(zhuǎn)換成固定維度的向量;分段嵌入(Segment embeddings),用于 區(qū) 分 不 同 的sentence;位 置 嵌 入(Position embeddings),用于表征詞語(yǔ)位置關(guān)系。輸入的編碼如圖1所示。
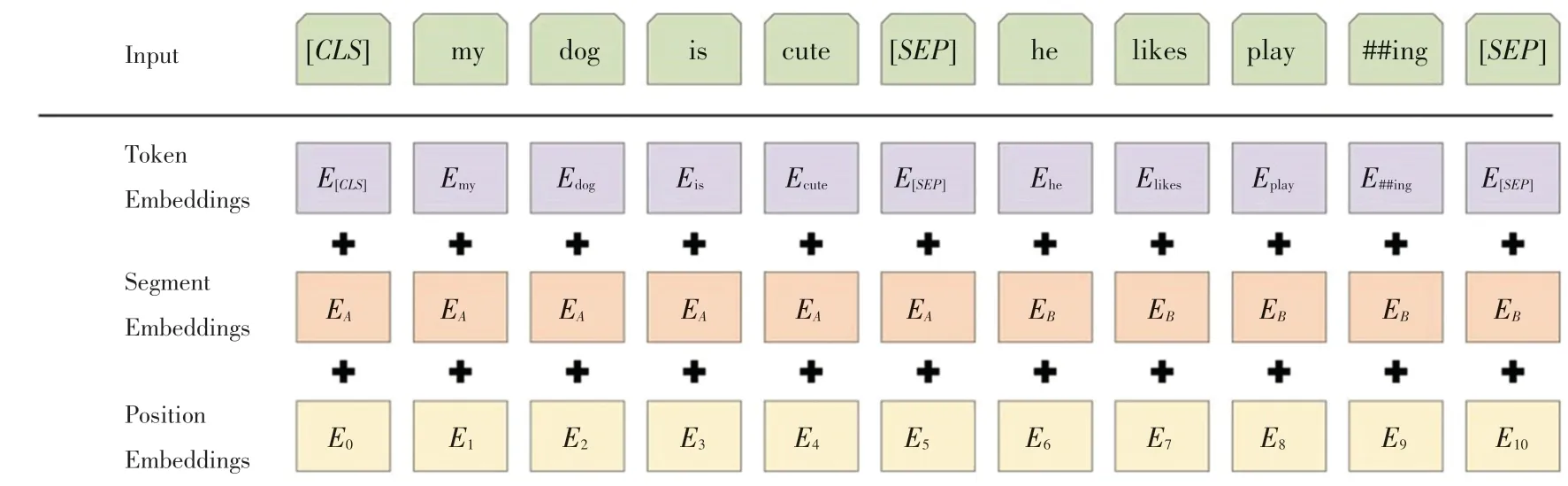
圖1 輸入編碼示例圖[4]Fig.1 Input coding example diagram[4]
BERT處理下游任務(wù)如多標(biāo)簽分類任務(wù)、采用的是微調(diào)的方式,一般而言,僅需要少量的改動(dòng),即可將BERT與下游任務(wù)融合,整體流程如圖2所示。
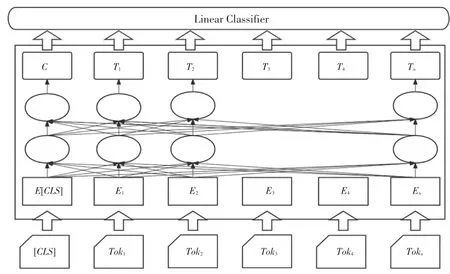
圖2 fine-tuning架構(gòu)圖Fig.2 fine-tuning architecture diagram
作為一個(gè)預(yù)訓(xùn)練模型,BERT需要應(yīng)對(duì)模型的輸入序列變長(zhǎng)問題。BERT提供了2種方法加以解決:
(1)使用分割token([])插入到每個(gè)句子中,來分開不同句子token序列。
(2)為每個(gè)token特征添加一個(gè)可學(xué)習(xí)的分割embedding來表示句子的分割點(diǎn)。
區(qū)別于ELMo和GPT等單向傳統(tǒng)語(yǔ)言模型,BERT模型的優(yōu)點(diǎn)是:
(1)采用MLM對(duì)雙向的Transformers進(jìn)行預(yù)訓(xùn)練,來生成深層的雙向語(yǔ)言特征。
(2)在訓(xùn)練后,只需要額外的輸出層進(jìn)行微調(diào),就能在多種任務(wù)中取得良好表現(xiàn),在這個(gè)過程中不需要再對(duì)BERT的結(jié)構(gòu)進(jìn)行修改。
綜合前述分析后可知,本文擬選擇BERT作為實(shí)驗(yàn)的預(yù)訓(xùn)練模型。
1.2 指令分類原則
CPU架構(gòu)是CPU產(chǎn)品制定的規(guī)范,旨在區(qū)分不同種類的CPU,目前市場(chǎng)上的CPU主要分為2類。一類是Intel、AMD為代表的復(fù)雜指令集CPU,另一類是以ARM、IBM為代表的精簡(jiǎn)指令集CPU。為了將不同品牌、不同類別架構(gòu)的指令集進(jìn)行統(tǒng)一的分類、從而提高構(gòu)建編譯器的效率,減少構(gòu)建所需要的時(shí)間,本文參考了LLVM中描述指令的代碼以及文獻(xiàn)[6]中的方法,將指令共劃分為13類,詳見表1。需要指出的是,目前國(guó)內(nèi)外多標(biāo)簽分類更多的是應(yīng)用在醫(yī)學(xué)、新聞等領(lǐng)域,應(yīng)用BERT將計(jì)算機(jī)指令進(jìn)行多標(biāo)簽分類的研究甚少,這是本文的研究亮點(diǎn)之一。
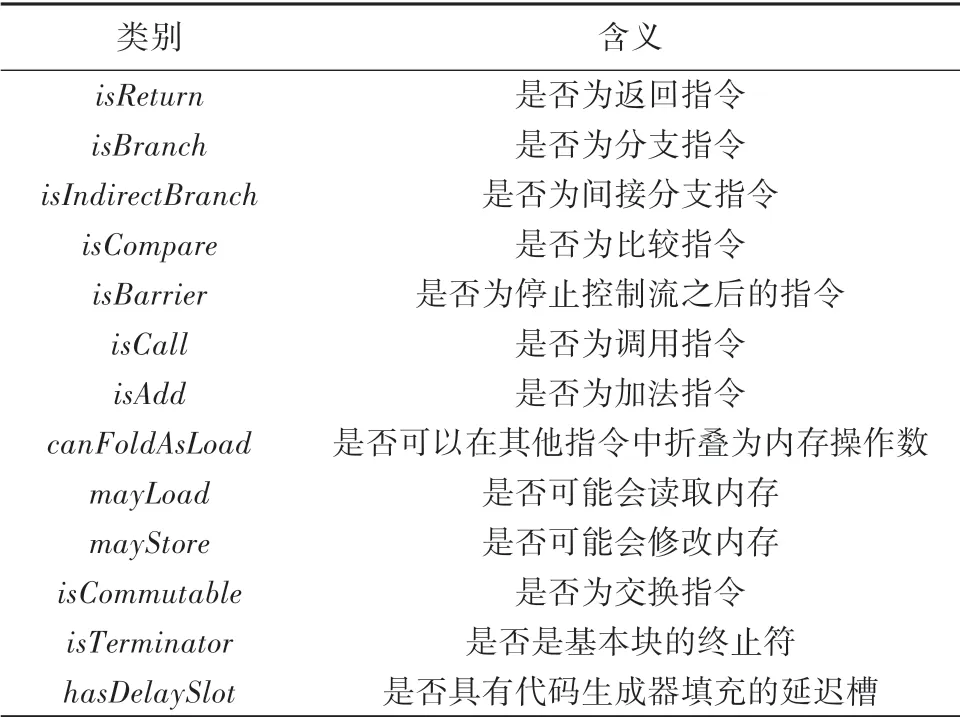
表1 指令類別劃分Tab.1 Classification of instructions
2 相關(guān)工作
2.1 數(shù)據(jù)集制作
在已經(jīng)推出的開源數(shù)據(jù)集平臺(tái)中,指令集相關(guān)的數(shù)據(jù)集甚少,故本文將從Mips32、Mips64、ARM等指令集架構(gòu)手冊(cè)中手動(dòng)提取出有關(guān)指令描述的文本,并且從LLVM的目標(biāo)平臺(tái)td文件中檢索出每條指令的類別,如圖3所示。

圖3 數(shù)據(jù)集示例圖Fig.3 Dataset example graph
實(shí)驗(yàn)共整理MIPS架構(gòu)指令數(shù)據(jù)640條,通過隨機(jī)采樣的方式將數(shù)據(jù)按照8:1:1的比列劃分為訓(xùn)練集、驗(yàn)證集與測(cè)試集。每一個(gè)Segment長(zhǎng)度均小于512,類別包含:返回指令、條轉(zhuǎn)指令、分支指令等共13類。和僅包含消極與積極兩種類別的情感分類數(shù)據(jù)相比較,則更加清晰地展現(xiàn)了本文提出的模型的優(yōu)越性。
由于本文的實(shí)驗(yàn)訓(xùn)練數(shù)據(jù)較少,所以增加了對(duì)BERT模型的預(yù)訓(xùn)練任務(wù)。預(yù)訓(xùn)練任務(wù)的數(shù)據(jù)集來自Mips32指令手冊(cè)、ARMv8指令手冊(cè)、RISCV指令手冊(cè)等共計(jì)16本指令集手冊(cè),
本文首先使用訓(xùn)練集進(jìn)行模型的訓(xùn)練,然后在驗(yàn)證集上對(duì)模型參數(shù)進(jìn)行不斷地調(diào)整,直至找到模型的最優(yōu)參數(shù),最后在測(cè)試集上進(jìn)行測(cè)試。
2.2 文本預(yù)處理
本文運(yùn)用了文本的預(yù)處理方法,對(duì)描述指令文本中的無效信息進(jìn)行清洗,主要是對(duì)文本中的無用符號(hào)、停用詞、非文本數(shù)據(jù)等進(jìn)行處理。對(duì)預(yù)訓(xùn)練數(shù)據(jù)先將格式由PDF轉(zhuǎn)換成TXT格式,再將TXT文件進(jìn)行處理,每一行只保留一句文本,接著又將16本指令集手冊(cè)合并為一個(gè)TXT格式,再將預(yù)訓(xùn)練數(shù)據(jù)處理成MLM(Mask Language Module)任務(wù)的數(shù)據(jù),如圖4所示。
在圖4給出的整個(gè)MLM任務(wù)數(shù)據(jù)集的構(gòu)建流程中,第一階段和第二階段是根據(jù)原始語(yǔ)料來構(gòu)造MLM任務(wù)所需要的輸入和標(biāo)簽;第三階段是隨機(jī)屏蔽掉部分來構(gòu)造MLM任務(wù)的輸入,并同時(shí)進(jìn)行padding處理;第四階段則是根據(jù)第三階段處理后的結(jié)果來構(gòu)造MLM任務(wù)的標(biāo)簽值,其中[]表示padding的含義,目的是為了忽略那些不需要進(jìn)行預(yù)測(cè)的在計(jì)算損失時(shí)的損失值。
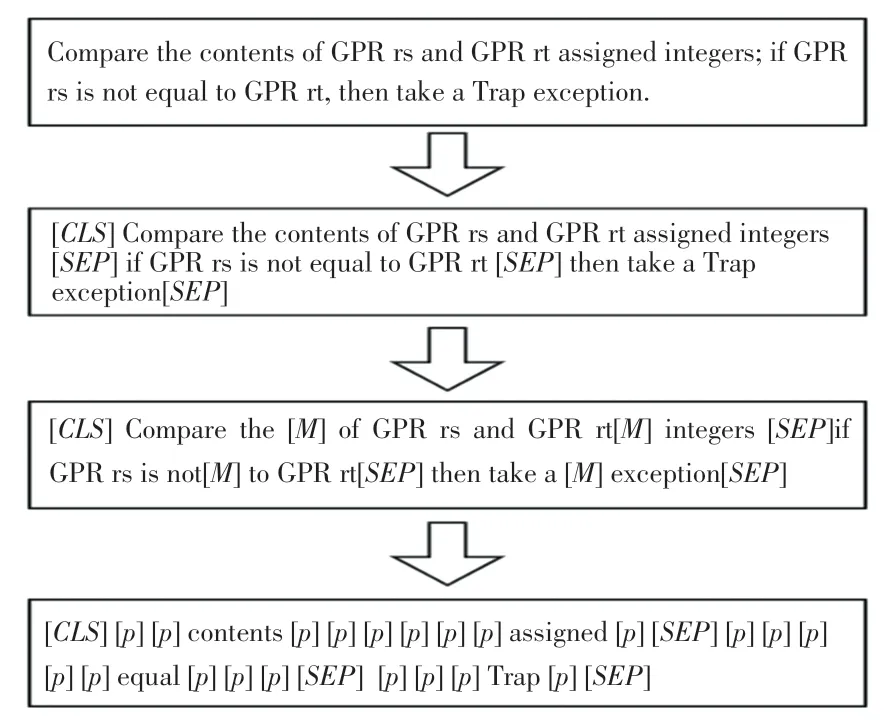
圖4 MLM任務(wù)數(shù)據(jù)集構(gòu)造流程圖Fig.4 MLM task dataset construction flowchart
2.3 實(shí)驗(yàn)環(huán)境
本文實(shí)驗(yàn)使用PyTorch深度學(xué)習(xí)架構(gòu)訓(xùn)練基于BERT的多標(biāo)簽分類模型,并配置好GPU在Ubuntu16.04系統(tǒng)上。實(shí)驗(yàn)環(huán)境配置具體見表2。

表2 環(huán)境配置Tab.2 Environmental configuration
2.4 實(shí)驗(yàn)內(nèi)容
由于本文實(shí)驗(yàn)訓(xùn)練數(shù)據(jù)的數(shù)量有限,對(duì)于目標(biāo)任務(wù)數(shù)據(jù)量少的情況下如果直接訓(xùn)練就可能無法獲得足夠多的特征,如此一來則難以較好地學(xué)習(xí)到特征和一些重要信息,所以本文使用相關(guān)領(lǐng)域的大量數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練就可以學(xué)習(xí)到本領(lǐng)域的更多的特征和信息,這樣遷移到數(shù)據(jù)量小的任務(wù)上進(jìn)行微調(diào)就可以達(dá)到更好的效果。
BERT預(yù)訓(xùn)練采用了2個(gè)訓(xùn)練任務(wù),上文提到的Masked LM任務(wù)用來捕捉單詞級(jí)的特征,Next Sentence Prediction任務(wù)用來捕捉句子級(jí)的特征。本文隨機(jī)屏蔽掉語(yǔ)料中15%的,然后去預(yù)測(cè)被屏蔽掉的,將masked token位置的隱藏層向量輸出即可得到預(yù)測(cè)結(jié)果。
本文首先在預(yù)訓(xùn)練數(shù)據(jù)集上對(duì)BERT進(jìn)行預(yù)訓(xùn)練,下游任務(wù)在訓(xùn)練時(shí)會(huì)將已經(jīng)訓(xùn)練好的模型參數(shù)加載到網(wǎng)絡(luò)中,然后使用Mips32數(shù)據(jù)集進(jìn)行下游任務(wù)訓(xùn)練,最后找出在測(cè)試集上最優(yōu)模型在其他架構(gòu)數(shù)據(jù)集上進(jìn)行測(cè)試,本實(shí)驗(yàn)詳細(xì)的模型參數(shù)見表3。

表3 模型參數(shù)設(shè)置表Tab.3 Model parameters setting table
2.5 評(píng)價(jià)指標(biāo)
本文使用值作為評(píng)價(jià)本多標(biāo)簽分類實(shí)驗(yàn)的指標(biāo),值用于權(quán)衡和,可定義為精確率和召回率的調(diào)和平均數(shù)。本次研究中推導(dǎo)得出的各數(shù)學(xué)定義的公式表述分別如下。
(1)精確率。這里用到的數(shù)學(xué)公式可寫為:
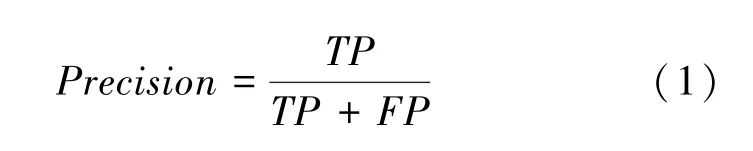
(2)召回率。這里用到的數(shù)學(xué)公式可寫為:
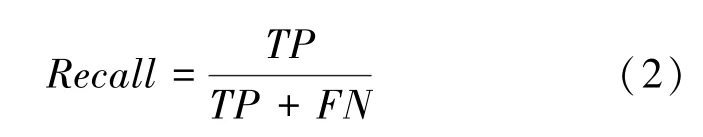
(3)準(zhǔn)確率。這里用到的數(shù)學(xué)公式可寫為:
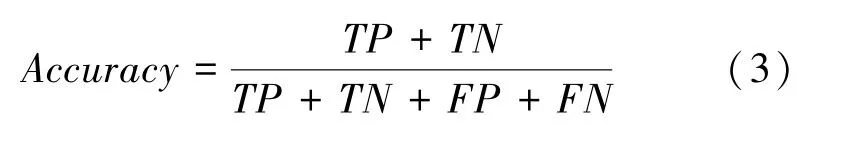
(4)值。這里用到的數(shù)學(xué)公式可寫為:
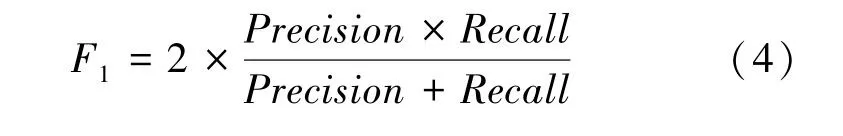
其中,(True Positive)表示預(yù)測(cè)為正,實(shí)際為正;(False Positive)表示預(yù)測(cè)為正,實(shí)際為負(fù);(True Negative)表示預(yù)測(cè)為負(fù),實(shí)際為負(fù);(False Negative)表示預(yù)測(cè)為負(fù),實(shí)際為負(fù)。通過統(tǒng)計(jì)、、、等數(shù)據(jù)可以計(jì)算出精確率和召回率[10]。
3 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)結(jié)果見表4。由表4可見,本文提出的多標(biāo)簽分類模型經(jīng)過在Mips32訓(xùn)練集上訓(xùn)練,準(zhǔn)確率達(dá)到了96.4%,值達(dá)到92.5%。分析后發(fā)現(xiàn),BERT語(yǔ)言模型經(jīng)過訓(xùn)練,在Mips32架構(gòu)指令集上有著不錯(cuò)的表現(xiàn)。再將訓(xùn)練后的模型使用Mips64和ARMv8架構(gòu)指令集數(shù)據(jù)進(jìn)行測(cè)試,準(zhǔn)確率分別達(dá)到了94.7%和86.1%,值則分別達(dá)到了90.9%與27.9%。
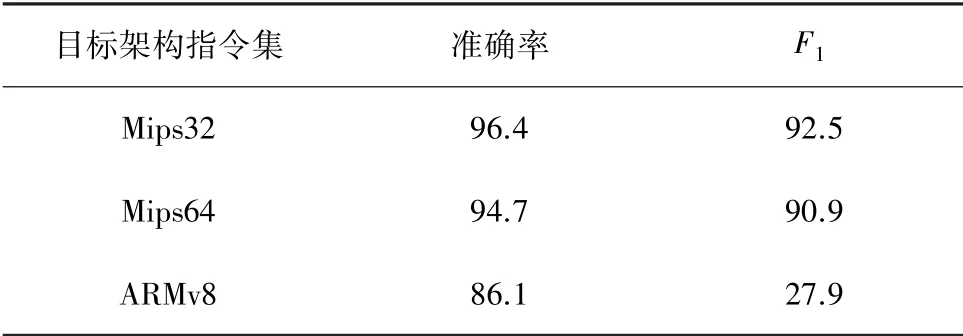
表4 實(shí)驗(yàn)結(jié)果Tab.4 Experimental results %
實(shí)驗(yàn)結(jié)果的柱狀表示見圖5。由圖5可以看到,模型在Mips32指令數(shù)據(jù)集上的準(zhǔn)確率與Mips64指令數(shù)據(jù)集上的準(zhǔn)確率相近,并且高于ARMv8指令數(shù)據(jù)集上的準(zhǔn)確率,一定程度上也表明了本文提出的分類方法在同種架構(gòu)中有著不錯(cuò)的分類表現(xiàn),在2種不同架構(gòu)的指令集上分類能力要低于同種架構(gòu)指令集。
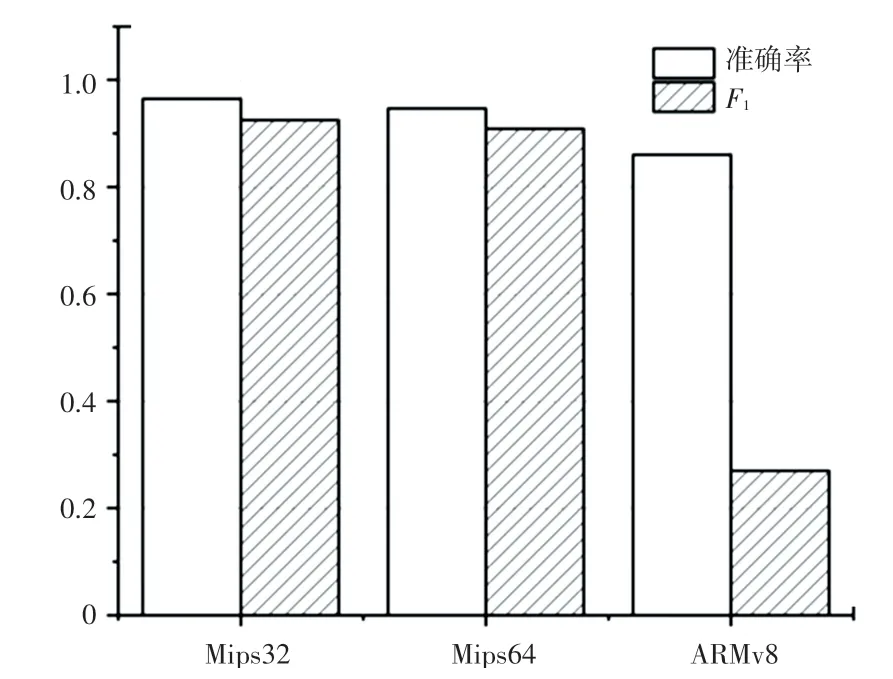
圖5 實(shí)驗(yàn)結(jié)果柱狀圖Fig.5 Histogram of experimental results
4 結(jié)束語(yǔ)
本文根據(jù)LLVM編譯器架構(gòu)中對(duì)指令描述的代碼對(duì)指令進(jìn)行分類,從Mips32架構(gòu)指令集手冊(cè)中提取出指令的描述文本,并根據(jù)上述分類原則對(duì)文本數(shù)據(jù)進(jìn)行手工標(biāo)注,最后實(shí)現(xiàn)了對(duì)BERT模型的預(yù)訓(xùn)練和s下游多標(biāo)簽分類任務(wù)的訓(xùn)練。經(jīng)過對(duì)Mips64與ARMv8架構(gòu)指令集的分類測(cè)試結(jié)果表明了本文提出基于BERT模型的指令集多標(biāo)簽分類研究方法在指令多標(biāo)簽分類任務(wù)中的有效性。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
測(cè)控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測(cè)試(2018年18期)2018-11-14 02:30:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
