基于YOLOv5s融合SENet的車輛目標檢測技術研究
2022-11-02 11:19:24趙璐璐王學營張美月
圖學學報 2022年5期
趙璐璐,王學營,張 翼,張美月
基于YOLOv5s融合SENet的車輛目標檢測技術研究
趙璐璐1,王學營2,張 翼1,張美月1
(1. 長安大學信息工程學院,陜西 西安 710064;2. 內蒙古自治區交通建設工程質量監測鑒定站,內蒙古 呼和浩特 010050)
針對交通監控視頻的車輛目標檢測技術在早晚高峰等交通擁堵時段,車輛遮擋嚴重且誤、漏檢率較高的問題,提出一種基于YOLOv5s網絡的改進車輛目標檢測模型。將注意力機制SE模塊分別引入YOLOv5s的Backbone主干網絡、Neck網絡層和Head輸出端,增強車輛重要特征并抑制一般特征以強化檢測網絡對車輛目標的辨識能力,并在公共數據集UA-DETRAC和自建數據集上訓練、測試。將查準率、查全率、均值平均精度作為評價指標,結果顯示3項指標相比于原始網絡均有明顯提升,適合作為注意力機制的引入位置。針對YOLOv5s網絡中正、負樣本與難易樣本不平衡的問題,網絡結合焦點損失函數Focal loss,引入2個超參數控制不平衡樣本的權重。結合注意力機制SE模塊和焦點損失函數Focal loss的改進檢測網絡整體性能提升,均值平均精度提升了2.2個百分點,有效改善了車流量大時的誤檢、漏檢指標。
車輛檢測;交通監控;注意力機制;焦點損失函數;YOLOv5模型
交通監控視頻提供的數據對緩解城市交通擁堵、提高道路通行效率以及合理分配交通資源具有重要作用。基于交通監控視頻的車輛目標檢測是后續進行車輛跟蹤、道路車流量統計的基礎。基于交通監控視頻的車輛目標檢測,對檢測的實時性要求較高[1],且易受復雜環境背景及天氣光線等干擾,尤其是城市交通擁堵路段,環境復雜、車流量,車輛互相遮擋嚴重,對車輛目標檢測提出了挑戰。
目標檢測技術是基于交通監控視頻的車輛檢測核心技術。傳統目標檢測方法,輸入一張待檢測圖片,首先采用滑動窗口的方式對圖片進行候選框提取,接著提取每個候選框中的特征信息,最后利用分類器進行識別。典型的目標檢測算法有Haar+Adaboost[2],Hog+SVM[3]和DPM[4]。傳統方法采用滑動窗口操作[5]易導致算法產生大量冗余的候選框,使得檢測速度慢、效率低、消耗資源多,而且傳統算法采用基于手工設計特征提取方法的魯棒性低、泛化效果差[6]。
LEE[7]提出的背景差分法利用當前圖像與背景之間的差距識別車輛,在背景情況復雜時,難以應對車流量大的識別場景。TSAI和LAI[8]提出的幀間差分法,其需要選定合適的時間間隔,且容易出現漏檢、錯檢問題。
隨著機器學習和GPU并行計算技術的蓬勃發展,基于學習的特征提取技術方興未艾。目前基于深度學習的目標檢測主要包括:基于區域建議的Two-Stage檢測算法和基于回歸思想的One-Stage檢測算法[9]。兩階段算法需要先生成預選框,再進行細粒度的物體檢測,檢測精度高,但效率低,其代表算法有:R-CNN[10],Fast R-CNN[11]和Faster R-CNN[12]。單階段算法不必生成預選框,直接在網絡中提取特征實現物體分類和位置的預測。相比兩階段算法,單階段算法檢測速度快,代表算法有RetinaNet[13]和YOLO[14-15]。其中,YOLO系列算法基于PyTorch框架,便于擴展到移動設備,屬于輕量級網絡。YOLOv5包括YOLOv5s,YOLOv5m,YOLOv5l和YOLOv5x 4種網絡結構,隨著網絡寬度和深度的增大,參數量依次增加。YOLOv5s是輕量級網絡的首選,便于部署到嵌入式設備。
YOLOv5系列經COCO2017測試集測試,平均準確率達72%,在GPU Nvidia Tesla V100的設備上檢測速度為每張2 ms,處于目標檢測算法中領先水平。由于單階段檢測算法未生成候選框,所以檢測速度快,但精度相比兩階段算法偏低,該系列算法在檢測精度方面仍有改進的空間。
本文在YOLOv5s的基礎上進行改進,以改善在車輛遮擋或小目標情況下檢測準確率偏低的問題。首先在Backbone主干網絡、Neck網絡層以及輸出端分別加入注意力機制SE,測試得到注意力機制的最優引入位置。其次,考慮到單階段結構存在正負樣本和難易樣本不平衡的問題,引入Focal loss函數計算目標損失和分類損失,以優化訓練過程。在公開數據集UA-DETRAC進行模型訓練和驗證,并且在自建數據集上測試算法的性能。
1 YOLOv5s模型及改進
YOLOv5s網絡采用One-Stage結構,由Input輸入端、Backbone主干網絡、Neck網絡層和Head輸出端4個部分組成,如圖1所示。Input輸入端具有Mosaic數據增強,自適應錨框計算以及自適應圖片縮放功能。Backbone主干網絡包括Focus結構,CSP結構[16]以及空間金字塔池化(spatial pyramid pooling,SPP)[17]結構,通過深度卷積操作提取圖像中的不同層次特征。Neck網絡層由特征金字塔(feature pyramid networks,FPN)和路徑聚合網絡(path aggregation network,PAN)組成。Head作為最后的檢測,在大小不同的特征圖上預測不同尺寸的目標。
1.1 YOLOv5s融合注意力機制
YOLOv5s網絡層次不斷加深,輸出端提取到的信息逐漸抽象,檢測監控視頻中遠處小目標車輛更難以實現,本文在網絡中融入注意力機制的方法有效改善了這一問題。
1.1.1 SENet網絡
SENet[18]是典型的通道注意力網絡,曾獲得ImageNet2017分類比賽冠軍。在深度學習神經網絡中,并非所有提取的特征都是重要的。SE注意力機制的作用是增強重要特征、抑制一般特征,并對卷積得到的特征圖進行包含Sequeeze,Excitation和特征重標定3步操作[19],如圖2所示。Sequeeze對卷積得到的××進行全局平均池化,得到1×1×大小的特征圖。Excitation使用一個全連接神經網絡,對Sequeeze之后的結果做一個非線性變換。特征重標定使用Excitation得到的結果作為權重,與輸入特征相乘。SE模塊具有即插即用的便利特征,已經在一些網絡中得到應用,但其融合在網絡中的哪個部分效果更好,目前還沒有完整的理論說明。

圖1 YOLOv5s網絡結構

圖2 SENet網絡結構
1.1.2 3種融合方法
針對YOLOv5s,本文設計了3種不同位置的融合方法。將SE模塊分別融合Backbone,Neck和Head 3個模塊,未考慮Input的原因是因其只對圖像進行預處理,并沒有特征提取的作用。由此產生3個網絡模型,本文分別將其記為YOLOv5s_A,YOLOv5s_B和YOLOv5s_C。
將SE模塊融合在Backbone主干網絡形成YOLOv5s_A。Backbone的主要作用是通過一個比較深的卷積網絡提取圖像中的深度特征,隨著網絡層數的加深,特征圖寬度越來越小,深度越來越深,可以使用SE模塊對不同位置的特征圖進行通道注意力重構,BottleneckCSP結構聚合不同層次特征,因此將SE放在BottleneckCSP之后,如圖3所示。

圖3 Backbone主干網絡融合SE模塊
將SE模塊融合Neck中形成YOLOv5s_B。Neck中的PAN和FPN結構可以自上而下地傳遞語義信息,自下而上地傳遞定位信息,通過4個Concat操作將深層與淺層信息進行融合,因此將SE模塊放在Concat之后,對融合的特征圖進行通道注意力重構,如圖4所示。
將SE模塊與網絡最后的Head融合,形成YOLOv5s_C。YOLOv5s通過3個尺度大小不同的特征圖預測目標,在小特征圖上預測大目標,大特征圖上預測小目標,考慮在預測之前,對每個特征圖進行注意力重構,如圖5所示。

圖4 Neck層融合SE模塊

圖5 Head輸出端融合SE模塊
1.2 引入Focal loss函數
1.2.1 正負樣本不平衡問題
YOLOv5s的損失包含目標損失、分類損失和邊界框回歸損失。YOLOv5s使用BCE With Logits作為目標損失函數和分類損失函數,即

其中,為經過Sigmoid激活函數輸出的概率;為真實的樣本標簽,取值為0或1。
圖像中包含車輛的部分為正樣本,其余部分為負樣本。對于正樣本,輸出概率越大則損失越小;對于負樣本,輸出概率越小損失越小。對于One-Stage目標檢測算法,正、負樣本不均衡的問題較為突出,在交通道路圖中背景的占比明顯大于車輛的占比,損失函數得出的損失值絕大部分是負樣本背景損失,并且大部分負樣本背景是簡單易分的,對于模型的收斂幾乎沒有作用。因此,本文引入焦點損失函數Focal loss,使用參數平衡正、負樣本對損失的影響,將樣本分為難分和易分樣本,降低易分樣本對總損失的權重。
1.2.2 Focal loss函數
對于正、負樣本權重的控制,需要降低大量負樣本對損失的影響,利用平衡因子

因子在樣本標簽不同時,提供不同的權重,例如BCE With Logits損失

通過改變的大小控制正、負樣本在損失的占比:在[0.50,1]區間,能夠增加正樣本損失的占比,降低負樣本損失的占比。在[0.25,0.75]范圍,能夠取得較好的AP值。LIN等[20]分別取值為0.25,0.50和0.75,因0.25不在[0.50,1]范圍內容,將其舍棄并用后2個值進行實驗。
是為了控制正、負樣本對損失的貢獻,但不影響易分、難分樣本的損失,因此使用調制因子(1-)和控制難分樣本和易分樣本的權重,即

其中,取值范圍[0,5],通過控制調制因子的大小,以控制難分、易分樣本損失權重的大小。當=0,式(4)是標準二分類交叉熵損失函數;當0<≤5,可以實現降低易分類樣本對損失的貢獻,使得模型更加專注于難分類樣本。
將平衡因子和調制因子(1-)和結合得到最終的Focal loss,即

其中,平衡因子可以平衡One-Stage檢測模型中正、負樣本不均衡的問題;調制因子(1-)和控制難易樣本差異對損失的影響。
2 機器學習實驗結果及分析
2.1 實驗準備
(1) 實驗平臺。網絡訓練平臺采用騰訊云服務器,規格為Tesla V100-NVLINK-32G GPU,40 G RAM。模型框架采用Python 3.8,PyTorch 1.9,CUDA 10.2。
(2) 數據集。UA-DETRAC[21]是美國奧爾巴尼大學車輛目標檢測和跟蹤的數據集,采集于北京和天津24個不同的地點,包括100個具有挑戰性的視頻,超過14萬幀視頻圖像和8 250輛人工標記的汽車目標,共計121萬標記過的目標檢測框。由于數據中包含夜晚、晴天、陰雨天等不同天氣場景,以及城市公路、道路交叉口等豐富的交通場景并且拍攝角度接近于監控探頭。馬蕓婷和喬鵬[22-23]及本實驗均選用該數據集。為避免相鄰幀之間圖像變化過小,每10幀選取一幀的方式,得到14 000張視頻圖像。從中選取1萬幀車流量較大的圖像作為本文的實驗數據集。
(3) 數據標注。為驗證本文算法的泛化性能,模擬監控視頻采集于西安市南二環文藝路天橋,采集場景包括傍晚、陰雨天以及光照較強的晴天總量1 500張,部分數據如圖6所示。

圖6 數據實例((a) UA-DETRAC;(b)自建數據)
自建數據集采用LabelImg標注工具進行人工標注,生成的Txt標簽格式如圖7所示。

圖7 Txt 數據標簽文件
標簽文件中每行為一個車輛信息,依次表示車輛類別,車輛中心坐標,,以及標注車輛矩形框的寬度和高度。車輛類別car,bus和van分別對應數字0,1和2。坐標均被歸一化,將車輛中心坐標和寬度除以圖像寬度,車輛中心坐標和高度除以圖像高度。
本實驗采用查準率Precision、查全率Recall、均值平均精度mAP作為評價指標,即

其中,,和分別為正確檢測出的車輛數目,錯誤檢出的車輛數目以及未被正確檢出的車輛數目。為單類別平均精度;為各類別的平均值,用于對所有目標類別檢測的效果取平均值,可以代表檢測性能[24]。
2.2 SE模塊融合對比實驗
本文將UA-DETRAC數據按照9:1的比例隨機劃分為訓練集和測試集,將自行采集并標注的圖像作為測試集。實驗均不采用預訓練模型,訓練過程使用相同的參數配置,輸入圖像大小為640×640,優化器為SGD,初始學習率設為0.01,動量設為0.937,衰1減系數為0.000 5。測試集上的實驗結果見表1。
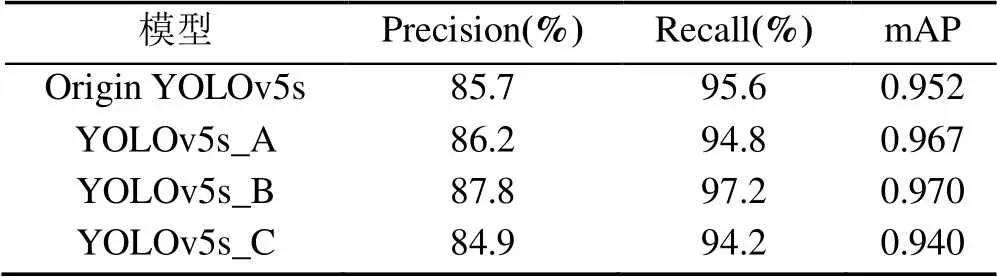
表1 融合SE的結果對比
并非所有融合SE的網絡均能提升檢測效果。YOLOv5s_A相較于原始YOLOv5s網絡查準率Precision和均值平均精度mAP有所提高,但召回率Recall卻有明顯下降,圖像中車輛被檢測到的情況較差。YOLOv5s_B對于原始網絡在3個評價指標上均有提升,均值平均精度mAP也是4個網絡中最高的,達到0.970。YOLOv5s_C在3個評價指標中全面落后原始網絡。
分析表1可知,注意力機制并不是在網絡中的任何位置均有作用,在Backbone中,網絡提取的特征還不夠充分,因此只有Precision和mAP兩項指標提高;在Neck中,網絡對深層和淺層的特征圖進行融合,在此基礎上對特征圖進行注意力融合,對不同的通道特征的重要性重新標定,因此取得了最好地檢測結果;Head中是在不同特征圖預測目標之前進行SE融合,但此處的特征圖已損失了很多低層的語義信息,SE模塊難以從這種高度融合的特征圖中區分出重要的特征通道,因此所有的指標均有下降,是4個網絡中效果最差的一個。基于以上分析本文將YOLOv5s_B作為車輛檢測的基礎模型。
2.3 Focal loss實驗
由式(5)可以看出,Focal loss主要通過2個超參數和控制正、負樣本和難、易樣本對損失的貢獻,為了更好地融合Focal loss函數與YOLOv5s網絡適應車輛檢測任務的需求,確定一組最優的和值成為進一步研究的內容。
實驗中網絡使用未融合SE模塊的YOLOv5s,損失函數采用Focal loss函數,其他各種參數均與2.2節對比實驗保持一致。選擇幾組不同的與進行對比實驗,即取0.50和0.75,取值[1,5]范圍的整數,遵循控制變量法的原則,各參照組僅有和的取值不同,測試結果見表2。

表2 不同參數組合的結果對比
從表2可知,并非所有超參數和的組合能對結果產生好的影響。在實驗中,當=0.50,=3時,網絡在測試集上取得了最好的檢測結果,3項評價指標均高于其他組合,并且高于原始YOLOv5s的結果,證明了改進損失函數的有效性。
2.4 綜合實驗結果可視化
對原始YOLOv5s同時進行SE模塊融合和Focal loss損失函數改進,在UA-DETRAC訓練集上進行訓練并在本文自建測試集上進行測試。實驗結果見表3。可以看出,同時引進SE和Focal loss之后,網絡的檢測結果有了進一步提升,mAP達到最高0.974,相較原始YOLOv5s提升了2.2個百分點。

表3 原始網絡和改進后網絡的結果對比
圖8為自建數據集對部分晴朗白天、陰雨天和夜晚檢測結果的可視化。可以看到,原始網絡對一些路段的目標和密集車輛出現了漏、誤檢現象,而本文改進網絡檢測出了這些目標。白天組中標記1處,車輛密集,原始網絡出現了漏檢現象,將多輛車識別為一輛;在標記2處,將一個車輛目標識別為了2輛。本文改進的網絡模型解決了這樣的問題,沒有出現漏、誤檢。陰雨天和夜晚監控圖像受天氣和光線影響,增加了檢測的難度,原始網絡和改進網絡檢測性能均受到影響。但圖中對比顯示,改進網絡對遠處以及遮擋車輛的誤、漏檢率總體更低,具有明顯優勢。

圖8 原始網絡和改進網絡的結果對比((a)原始網絡;(b)改進網絡)
3 結束語
本文使用改進的YOLOv5s網絡檢測交通監控中的車輛目標。針對檢測中出現的誤、漏檢問題,提出將注意力模塊SE引入YOLOv5s,為判斷SE位置不同對檢測結果造成的影響,在網絡的3個不同位置Backbone,Neck和Head分別引入并進行對比實驗;使用焦點損失Focal loss替代原始的損失函數,改善網絡的正、負樣本和難、易樣本不平衡的問題,設置不同的參數并根據實驗結果選擇最合適的組合。分別在UA-DETRAC和自建數據集上訓練、測試。實驗結果表明,本文改進方法相比原始YOLOv5s在評價指標mAP上提高2.2%,根據可視化結果,本文方法可以有效降低漏、誤檢率。目前監控探頭往往是算力較低的邊緣設備,因此,在低算力設備上部署車輛檢測模型并達到實時檢測的要求是下一步的研究重點。
[1] 蔣镕圻, 彭月平, 謝文宣, 等. 嵌入scSE模塊的改進YOLOv4小目標檢測算法[J]. 圖學學報, 2021, 42(4): 546-555.
JIANG R Q, PENG Y P, XIE W X, et al. Improved YOLOv4 small target detection algorithm with embedded scSE module[J]. Journal of Graphics, 2021, 42(4): 546-555 (in Chinese).
[2] TIAN D X, ZHANG C, DUAN X T, et al. The cooperative vehicle infrastructure system based on machine vision[C]//The 6th ACM Symposium on Devel Opment and Analysis of Intelligent Vehicular Networks and Applications. New York: ACM Press, 2017: 85-89.
[3] DRO?D? M, KRYJAK T. FPGA implementation of multi-scale face detection using HOG features and SVM classifier[J]. Image Processing & Communications, 2016, 21(3): 27-44.
[4] FELZENSZWALB P F, GIRSHICK R B, MCALLESTER D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[5] ZHU H G. An efficient lane line detection method based on computer vision[J]. Journal of Physics: Conference Series, 2021, 1802(3): 032006-032014.
[6] 李妮妮, 王夏黎, 付陽陽, 等. 一種優化YOLO模型的交通警察目標檢測方法[J]. 圖學學報, 2022, 43(2): 296-305.
LI N N, WANG X L, FU Y Y, et al. A traffic police object detection method based on optimized YOLO model[J]. Journal of Graphics, 2022, 43(2): 296-305 (in Chinese).
[7] LEE D S. Effective Gaussian mixture learning for video background subtraction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5): 827-832.
[8] TSAI D M, LAI S C. Independent component analysis-based background subtraction for indoor surveillance[J]. IEEE Transactions on Image Processing, 2009, 18(1): 158-167.
[9] 楊亞峰, 蘇維均, 秦勇, 等. 基于語義標簽的高鐵接觸網圖像目標檢測研究[J]. 計算機仿真, 2020, 37(11): 146-149, 188.
YANG Y F, SU W J, QIN Y, et al. Research on object detection method of high-speed railway catenary image based on semantic label[J]. Computer Simulation, 2020, 37(11): 146-149, 188 (in Chinese).
[10] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 580-587.
[11] GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 1440-1448.
[12] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[13] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327.
[14] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2022-01-20]. https://arxiv.org/abs/1804. 02767?context=cs.CV.
[15] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2022-02-05]. https://arxiv.org/abs/2004.10934.
[16] WANG C Y, MARK LIAO H Y, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]///The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Washington New York: IEEE Press, 2020: 390-391.
[17] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[18] HU J, SHEN L, ALBANIE S, et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 42(8): 2011-2023.
[19] 譚芳喜, 肖世德, 周亮君, 等. 基于改進YOLOv3算法在道路目標檢測中的應用[J]. 計算機技術與發展, 2021, 31(8): 118-123.
TAN F X, XIAO S D, ZHOU L J, et al. Application in road target detection based on improved YOLOV3 algorithm[J]. Computer Technology and Development, 2021, 31(8): 118-123 (in Chinese).
[20] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327.
[21] WEN L, DU D, CAI Z, et al. UA-DETRAC: a new benchmark and protocol for multi-object detection and tracking[J]. Computer Vision and Image Understanding, 2020, 193(C): 102907-102926.
[22] 馬蕓婷. 基于深度特征的車輛檢測與跟蹤[D]. 蘭州: 西北師范大學, 2020.
MA Y T. Vehicle detection and tracking based on depth feature[D]. Lanzhou: Northwest Normal University, 2020 (in Chinese).
[23] 喬鵬. 基于深度學習和邊緣任務卸載的交通流量檢測研究[D]. 西安: 西安電子科技大學, 2019.
QIAO P. Research on traffic flow detection based on deep learning and edge task offloading[D]. Xi’an: Xidian University, 2019 (in Chinese).
[24] 謝富, 朱定局. 深度學習目標檢測方法綜述[J]. 計算機系統應用, 2022, 31(2): 1-12.
XIE F, ZHU D J. Survey on deep learning object detection[J]. Computer Systems and Applications, 2022, 31(2): 1-12 (in Chinese).
Vehicle target detection based on YOLOv5s fusion SENet
ZHAO Lu-lu1, WANG Xue-ying2, ZHANG Yi1, ZHANG Mei-yue1
(1. School of Information Engineering, Chang’an University, Xi’an Shaanxi 710064, China; 2. Inner Mongolia Autonomous Region Traffic Construction Engineering Quality Monitoring and Appraisal Station, Hohhot Inner Mongolia Autonomous Region 010050, China)
To address the problem that the vehicle target detection technology of traffic monitoring videos has high rates of false detection and missed detection due to serious vehicle occlusion in traffic congestion periods such as morning and evening peaks, an improved vehicle target detection model based on YOLOv5s network was proposed. The attention mechanism SE module was introduced into the Backbone network, Neck network layer, and Head output of YOLOv5s, respectively, thus enhancing the important features of the vehicle and suppressing the general features. In doing so, the recognition capability of the detection network for the vehicle target was strengthened, and training and tests were performed on the public data set UA-DETRAC and self-built data set. The results show that the three indicators were significantly enhanced compared with the original network, which was suitable for the introduction of the attention mechanism. The evaluation rate, the value, and mean average accuracy were evaluated, and the results showed that compared with the original network, the three indicators were significantly improved, suitable for the introduction of attention mechanisms. To address the imbalance between positive and negative samples and that between difficult and easy samples in YOLOv5s network, the network combined the focus loss function Focal loss and introduced two super-parameters to control the weight of unbalanced samples. Combined with the improvement of attention mechanism SE module and focus loss function, the overall performance of the detection network was improved, and the average accuracy was improved by 2.2 percentage points, which effectively improves the index of false detection and missed detection in the case of large traffic flow.
vehicle detection; traffic monitoring; attention mechanism; focus loss function; YOLOv5 model
TP 391
10.11996/JG.j.2095-302X.2022050776
A
2095-302X(2022)05-0776-07
2022-03-08;
2022-05-09
8 March,2022;
9 May,2022
2020年度陜西省交通運輸廳科研項目(20-24K,20-25X);內蒙古自治區交通運輸發展研究中心開放基金項目(2019KFJJ-003)
Scientific Research Project of Shaanxi Provincial Department of Transportation in 2020 (20-24K, 20-25X); Open Fund of Inner Mongolia Autonomous Region Transportation Development Research Center (2019KFJJ-003)
趙璐璐(1998-),女,碩士研究生。主要研究方向為基于深度學習的目標檢測。E-mail:2689797652@qq.com
ZHAO Lu-lu (1998-), master student. Her main research interest covers object detection based on deep learning. E-mail:2689797652@qq.com
王學營(1991-),男,博士研究生。主要研究領域為瀝青路面新材料及檢測。E-mail:2020124099@chd.edu.cn
WANG Xue-ying (1991-), Ph.D candidate. His main research interests cover new asphalt pavement mate rials and testing. E-mail:2020124099@chd.edu.cn
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
