基于改進(jìn)U-Net模型的心電波形分割
2022-11-02 07:26:38徐柏林蔡文杰楊明菲張標(biāo)
中國(guó)醫(yī)學(xué)物理學(xué)雜志 2022年10期
徐柏林,蔡文杰,楊明菲,張標(biāo)
上海理工大學(xué)健康科學(xué)與工程學(xué)院,上海 200093
前言
我國(guó)心血管疾病死亡率逐年上升,并呈現(xiàn)年輕化趨勢(shì)[1]。隨著城市化和生活方式的改變,可以預(yù)見未來(lái)患病人數(shù)不會(huì)下降,因此,對(duì)于心血管疾病的預(yù)防和檢測(cè)值得重視[2]。心電圖作為對(duì)心臟健康狀況進(jìn)行評(píng)估的重要手段,主要包括P 波、QRS 波和T 波,其中各波形都包含著重要信息,心電波形分割對(duì)于自動(dòng)診斷分析具有重要意義[3]。然而,心電信號(hào)的精確分割存在一些困難。例如,P波的振幅很小,甚至因?yàn)樵肼暩蓴_無(wú)法識(shí)別或是P波缺失;T波可能存在雙向的情況,這就導(dǎo)致很難確定T 波的起點(diǎn)和終點(diǎn)[4]。因此,亟需提出一種可以精確分割心電波形的算法。傳統(tǒng)心電波形分割算法一般先在心電信號(hào)中定位R波的位置,然后檢測(cè)QRS 波的起止點(diǎn),然后再定位P 波和T 波的起止位置。Aspuru 等[5]使用線性回歸來(lái)分割心電信號(hào),首先檢測(cè)心電圖的R 峰,然后再分離信號(hào),檢測(cè)P、Q、S和T峰值。該方法對(duì)Q點(diǎn)的檢驗(yàn)靈敏度為97.5%,對(duì)其他心電峰值的檢測(cè)靈敏度為100%;但是該方法泛化能力沒(méi)有經(jīng)受檢驗(yàn),單一的性能指標(biāo)也不能說(shuō)明算法的優(yōu)異。目前主流的用于心電波形分割的傳統(tǒng)算法是小波變換,Li等[6]使用小波變換來(lái)檢測(cè)心電信號(hào)的各波形特征點(diǎn)。借助小波變換的多尺度功能將QRS 復(fù)合波與其他波分離,QRS的識(shí)別準(zhǔn)確率在MITDB(MITBIH Arrhythmia Database)上達(dá)到99.8%。雖然很多傳統(tǒng)算法都可以用于心電波形分割研究,但大部分都是針對(duì)單獨(dú)的特征波,如QRS波,將所有心電波形進(jìn)行整體分割的研究相對(duì)較少。近年來(lái),使用深度學(xué)習(xí)的方法識(shí)別心電各波形逐漸成為研究熱點(diǎn)。Nurmaini等[7]提出使用雙向長(zhǎng)短期記憶分類器來(lái)對(duì)心電圖波形進(jìn)行分割。將心電數(shù)據(jù)按照心拍進(jìn)行切割,以P 波的起始點(diǎn)作為切割的起點(diǎn),該方法的平均敏感度達(dá)到98.82%,F(xiàn)1 分?jǐn)?shù)為98.84%;但該方法存在一個(gè)缺陷,從P 波的起始點(diǎn)開始切割,以固定心電片段作為訓(xùn)練集投入模型訓(xùn)練,勢(shì)必會(huì)導(dǎo)致模型對(duì)P波的識(shí)別準(zhǔn)確率虛高,缺乏泛化性能。
針對(duì)以上算法的不足,本研究提出的基于U-Net模型改進(jìn)的算法不僅可以檢出心電整體波形的起止點(diǎn),且檢測(cè)效果更好;在跨數(shù)據(jù)庫(kù)實(shí)驗(yàn)中也表現(xiàn)較好的泛化性能。
1 方法
1.1 數(shù)據(jù)集
本研究選取心電公開數(shù)據(jù)集Lobachevsky University Database(LUDB),這是一個(gè)常用于心電波形分割的開放數(shù)據(jù)庫(kù)[8]。其包含200 份來(lái)自不同受試者12 導(dǎo)聯(lián)心電圖記錄,每條記錄的采樣頻率為500 Hz,采樣時(shí)長(zhǎng)10 s;該數(shù)據(jù)庫(kù)的P 波、QRS 波和T波的邊界和峰值都由專家手工標(biāo)注。使用QTDB(QT Database)來(lái)驗(yàn)證本文算法的泛化能力[9]。其包括105 條兩導(dǎo)聯(lián)心電圖記錄,采樣頻率為250 Hz,采樣時(shí)長(zhǎng)15 min;該數(shù)據(jù)庫(kù)的每條記錄的P 波、QRS 波和T 波起止位置和峰值同樣由專家標(biāo)注。本研究選取了其中部分記錄作為算法驗(yàn)證數(shù)據(jù)。
1.2 預(yù)處理
LUDB 中的專家標(biāo)記從第二或第三個(gè)心拍開始到倒數(shù)第二個(gè)心拍結(jié)束。如圖1所示,紅色為無(wú)波,黃色為QRS波,綠色為P波,藍(lán)色為T波。
針對(duì)LUDB的特點(diǎn),本研究在構(gòu)建數(shù)據(jù)集時(shí)截取了從第3 秒(第1 000 個(gè)采樣點(diǎn))開始到第8 秒(第4 000 個(gè)采樣點(diǎn))為止的心電片段,共3 000 個(gè)采樣點(diǎn)。這樣截取可以保證選取的信號(hào)均有專家標(biāo)記。將LUDB的200份12導(dǎo)聯(lián)分別當(dāng)作獨(dú)立的記錄來(lái)處理,得到2 400 條記錄。然而,在根據(jù)標(biāo)注構(gòu)建數(shù)據(jù)集過(guò)程中發(fā)現(xiàn),LUDB 有30 條記錄存在漏標(biāo)情況,舍棄這些記錄,最后得到2 370條記錄的數(shù)據(jù)集。
針對(duì)QTDB的處理,首先對(duì)記錄重采樣到500 Hz。考慮到該數(shù)據(jù)庫(kù)中有大量記錄缺乏專家標(biāo)注,本研究選取幾條完整標(biāo)記的記錄,每3000個(gè)采樣點(diǎn)作為一條心電片段,共得到800條數(shù)據(jù)作為驗(yàn)證集。
原始心電信號(hào)中含有大量噪聲信號(hào),如肌電噪聲、基線漂移、工頻干擾等,噪聲信號(hào)的存在影響了模型的性能[10]。本研究采用小波變換去除噪聲干擾,在LUDB 和QTDB 上使用db3 的小波基對(duì)心電信號(hào)做8 尺度分解[11]。圖2為原始波形和去噪后的波形。
1.3 數(shù)據(jù)增強(qiáng)
LUDB 共有2 370 條記錄,為了增加數(shù)據(jù)的多樣性,提升模型的魯棒性以及泛化能力,本研究對(duì)數(shù)據(jù)集進(jìn)行數(shù)據(jù)增強(qiáng)[12]。首先,針對(duì)每條記錄的3 000 個(gè)采樣點(diǎn),在前600 個(gè)點(diǎn)中隨機(jī)選擇起點(diǎn),投入模型訓(xùn)練的記錄長(zhǎng)度為2 400,這樣在一定程度上可以保證數(shù)據(jù)的多樣性。其次,本研究構(gòu)建了一個(gè)數(shù)據(jù)生成器,在訓(xùn)練過(guò)程中對(duì)心電記錄做隨機(jī)增大或縮放,添加基線漂移和進(jìn)行平移操作[13]。其數(shù)學(xué)表達(dá)式定義如下:
式中第一步對(duì)數(shù)據(jù)進(jìn)行隨機(jī)放縮操作,α取值為[8,13);第二步將放縮后的數(shù)據(jù)添加基線漂移,β、γ、δ的取值范圍是[0,30)、[400,900)、[0,10);最后做平移操作,ε取值[-20,21)。對(duì)于每一條投入模型訓(xùn)練的記錄,都采用這3個(gè)步驟和隨機(jī)選擇起點(diǎn)來(lái)豐富數(shù)據(jù)的多樣性,增強(qiáng)模型的魯棒性。
1.4 模型
本研究提出的模型是基于U-Net 模型進(jìn)行改進(jìn)的。U-Net 框架起源于全卷積網(wǎng)絡(luò),常用于醫(yī)學(xué)圖像分割[14]。該模型是一個(gè)經(jīng)典的編碼-解碼器結(jié)構(gòu),左邊部分用來(lái)特征提取,右邊部分進(jìn)行上采樣和特征融合。本研究以U-Net為基礎(chǔ),針對(duì)一維的心電數(shù)據(jù)對(duì)模型進(jìn)行改進(jìn),模型圖如圖3所示。
原有的U-Net 模型左邊部分的單通道下采樣結(jié)構(gòu)換成了3通道,并將普通卷積改成了空洞卷積。因?yàn)樾碾娦盘?hào)是一種基于幅度的低頻數(shù)據(jù),使用小的感受野很難包含心電信號(hào)幅度較大范圍的變化[15];另外心拍本身是一段短時(shí)一維信號(hào),不能過(guò)分關(guān)注整體而忽視局部信息。本研究提出的模型左側(cè)部分的3 個(gè)通道均會(huì)對(duì)輸入信號(hào)進(jìn)行卷積、批量標(biāo)準(zhǔn)化(BN)及激活(ReLU)操作[16];在模型中使用空洞卷積代替普通卷積,空洞卷積進(jìn)行卷積操作時(shí)會(huì)跳過(guò)一些像素點(diǎn)進(jìn)行卷積,在使用相同大小的卷積核情況下,可以獲得更大的感受野;同時(shí),給各個(gè)通道設(shè)計(jì)不同的空洞率,輸出神經(jīng)元能獲得不同的感受野[17]。各通道空洞模塊結(jié)構(gòu)參數(shù)如表1所示。這種多通道加空洞卷積的設(shè)計(jì)更適合提取類似心電信號(hào)的一維數(shù)據(jù)的特征信息。每個(gè)通道的每一層經(jīng)過(guò)上述操作后,將結(jié)果按照通道維度進(jìn)行拼接,該結(jié)果用于與右側(cè)部分上采樣結(jié)果特征融合。為了將3 個(gè)通道所提取的特征信息整合到一起,本研究使用注意力機(jī)制(SENet)對(duì)特征重要性進(jìn)行調(diào)整,即通過(guò)學(xué)習(xí)的方式自動(dòng)獲取每個(gè)特征通道的重要程度,按照這個(gè)重要程度去提升有用的特征權(quán)重并抑制作用不大的特征權(quán)重,對(duì)整個(gè)網(wǎng)絡(luò)進(jìn)行重新調(diào)整[18]。
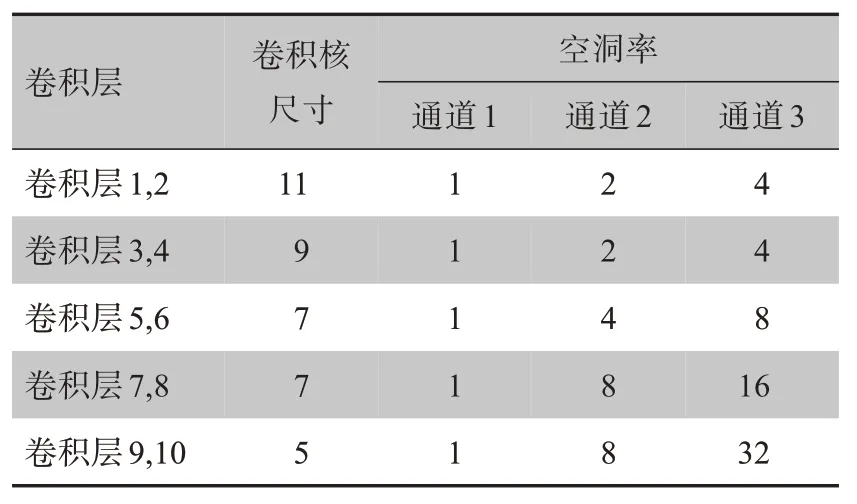
表1 空洞模塊結(jié)構(gòu)參數(shù)Table 1 Structural parameters of dilated convolution
輸入長(zhǎng)度為2 400 個(gè)采樣點(diǎn)的預(yù)處理心電信號(hào),左邊部分的多個(gè)通道的編碼器進(jìn)行特征提取工作,每次經(jīng)過(guò)池化層尺度減半。右邊解碼器部分使用上采樣的方法恢復(fù)尺寸,然后將左邊部分的多通道合并結(jié)果與上采樣特征進(jìn)行特征融合。最后,模型得到的輸出結(jié)果為2 400×4,蘊(yùn)含著屬于P波、QRS波、T波的像素級(jí)分割信息,使用Softmax 激活函數(shù)可以得到每個(gè)波形的預(yù)測(cè)結(jié)果[19]。
2 實(shí)驗(yàn)結(jié)果
2.1 實(shí)驗(yàn)配置與性能指標(biāo)
模型訓(xùn)練使用的優(yōu)化器是Adagrad,損失函數(shù)為交叉熵?fù)p失函數(shù),初始學(xué)習(xí)率設(shè)置為0.015,學(xué)習(xí)率衰減率為0.001,隨著模型訓(xùn)練,學(xué)習(xí)率可以動(dòng)態(tài)地變化[20]。Batchsize 為256,模型訓(xùn)練次數(shù)設(shè)置為300 個(gè)epoch。本研究采用pycharm 作為開發(fā)環(huán)境和pytorch框架[21]。在Ubuntu 環(huán)境上進(jìn)行訓(xùn)練,顯卡為GA106[GeForce RTX 3060 Lite Hash Rate]12 G。圖4顯示了模型在訓(xùn)練階段的損失曲線。
根據(jù)醫(yī)療器械協(xié)會(huì)(Association for Medical Instrumentation)規(guī)定,當(dāng)算法得到的起始點(diǎn)和終止點(diǎn)與專家標(biāo)記的絕對(duì)值不超過(guò)150 ms,則可以判定預(yù)測(cè)是正確的[22]。由此,可以定義一些性能指標(biāo)來(lái)對(duì)算法的質(zhì)量進(jìn)行評(píng)定。
本實(shí)驗(yàn)采用敏感度(SE)、陽(yáng)性預(yù)測(cè)率(PPV)、F1分?jǐn)?shù)作為性能指標(biāo)。SE可以表達(dá)算法預(yù)測(cè)特征點(diǎn)的能力,PPV 表示檢測(cè)出的特征點(diǎn)是正確的比例,F(xiàn)1 分?jǐn)?shù)是二者的綜合指標(biāo)[23]。性能指標(biāo)各公式如下:
其中,TP 代表提出的算法預(yù)測(cè)的特征點(diǎn)與專家標(biāo)記點(diǎn)的誤差的絕對(duì)值不超過(guò)150 ms;FP 代表算法預(yù)測(cè)特征點(diǎn)周圍150 ms 沒(méi)有專家標(biāo)記的點(diǎn);FN 表示在專家標(biāo)記點(diǎn)150 ms 范圍內(nèi)無(wú)法找到算法預(yù)測(cè)的特征點(diǎn)。
2.2 結(jié)果與討論
對(duì)于U-Net模型的改進(jìn)方向,本研究采取對(duì)原模型加入空洞卷積模塊、增加SENet模塊以及改變通道個(gè)數(shù)等方式,分別對(duì)每一種改進(jìn)方向都進(jìn)行訓(xùn)練和5折交叉驗(yàn)證。各個(gè)模型在測(cè)試集上的表現(xiàn)如表2所示。提出的算法在測(cè)試集上的分割結(jié)果如圖5所示。
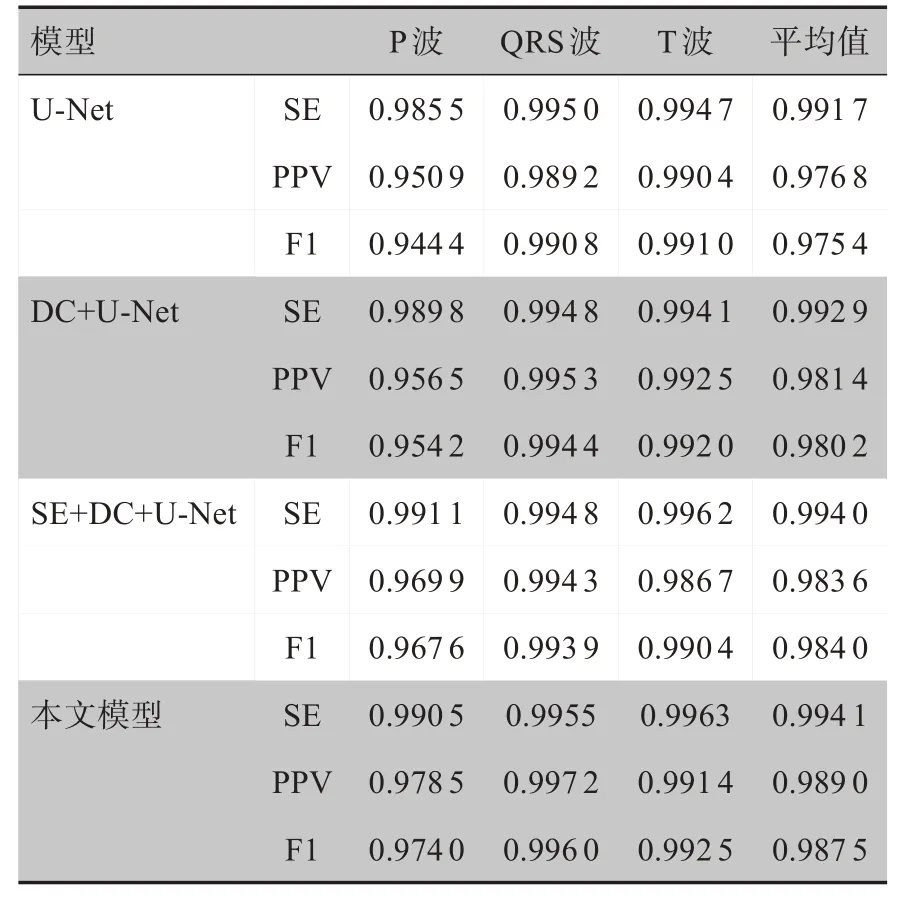
表2 不同模型的心電分割結(jié)果(LUDB)Table 2 ECG segmentation results of different models(LUDB)
DC+U-Net(Dilated Convolution,U-Net)模型 是在原U-Net 模型的基礎(chǔ)上將單通道下采樣改為3 通道下采樣,普通卷積模塊變成空洞卷積模塊,但未加入SENet。DC+U-Net 模型平均性能在PPV 和F1 上相對(duì)于U-Net模型有大約0.5%的提升,在P波和QRS波的分割上性能明顯更加優(yōu)秀,T 波效果與U-Net 相差不大。SE+DC+U-Net(SENet,Dilated Convolution,U-Net)與DC+U-Net區(qū)別在于將3通道下采樣改成了兩個(gè)通道,加入了SENet 模塊;平均性能相比于DC+U-Net 模型提升了大約0.3%。本研究提出的模型通道數(shù)為3,加入了空洞卷積和SENet 模塊,在P 波、QRS 波、T 波的分割上性能都優(yōu)于其他模型,平均性能對(duì)于U-Net模型大約提升了1.2%。
因?yàn)長(zhǎng)UDB數(shù)據(jù)標(biāo)注問(wèn)題,本研究舍棄了部分心電信號(hào)。黃鑫[24]采用了與本文類似的做法,在第3秒和第9 秒之間隨機(jī)選擇了6 s 的心電片段構(gòu)建數(shù)據(jù)集;Sereda等[22]用中值濾波去除基線漂移后也選擇了6 s的心電信號(hào)作為數(shù)據(jù)集的一條序列;Viktor等[4]從第2秒到第4秒隨機(jī)選擇起點(diǎn),序列長(zhǎng)度是4 s。將本文方法與其他方法的研究結(jié)果進(jìn)行比較,結(jié)果如表3所示。本文算法在T波的性能上有著明顯的優(yōu)勢(shì),但是在QRS 波的檢測(cè)上不如Viktor 等[4]的方法。從平均性能來(lái)看,本文方法在敏感度、陽(yáng)性預(yù)測(cè)率上都取得了更好的表現(xiàn)。

表3 與其他論文方法對(duì)比(LUDB)Table 3 Comparison with other methods(LUDB)
為了驗(yàn)證本文提出的算法的泛化能力,在處理好的QTDB 上進(jìn)行算法驗(yàn)證。表4是在LUDB 上訓(xùn)練好的算法在QTDB 上進(jìn)行驗(yàn)證的結(jié)果與其他方法的研究結(jié)果對(duì)比。同Kalya-Kulina 等[25]的方法相比可以看到本文方法在P 波段的效果不夠明顯,但在QRS 段和T 波段有明顯優(yōu)勢(shì)。Bote 等[26]采用小波分析方法對(duì)心電波形進(jìn)行分割,本文方法在QRS 波段與他們?nèi)〉玫男Ч咏窃赥波段的檢測(cè)上更勝一籌。因此,本文方法已經(jīng)接近了目前的主流水平,在跨數(shù)據(jù)庫(kù)上取得較好的表現(xiàn),具有良好的泛化能力。
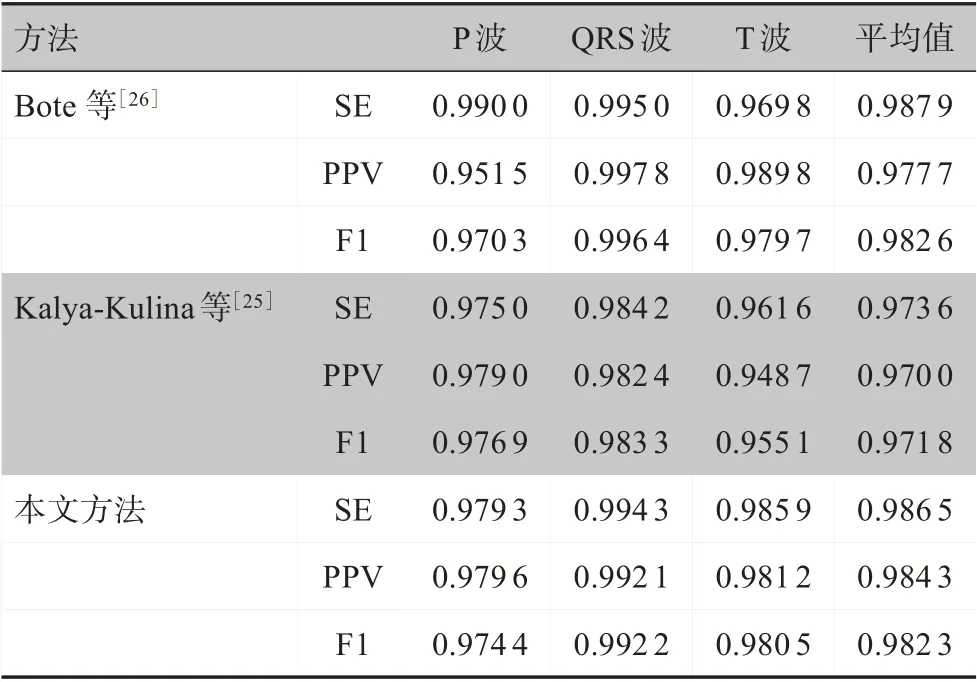
表4 QT數(shù)據(jù)庫(kù)上算法驗(yàn)證結(jié)果對(duì)比Table 4 Comparison of algorithm verification results on QT database
3 結(jié)語(yǔ)
本研究提出一種基于U-Net框架的改進(jìn)模型,用于心電波形分割。采用LUDB和QTDB構(gòu)建訓(xùn)練集,進(jìn)行5 折交叉驗(yàn)證。LUDB 用來(lái)訓(xùn)練模型并進(jìn)行測(cè)試,在QTDB上做算法驗(yàn)證。實(shí)驗(yàn)結(jié)果充分驗(yàn)證了算法的有效性和泛化能力,在LUDB 測(cè)試集上的5 折交叉驗(yàn)證結(jié)果為:平均靈敏度99.41%,平均陽(yáng)性預(yù)測(cè)率98.90%,平均F1 分?jǐn)?shù)98.75%。在QTDB 上性能可以比擬主流的方法。本研究的缺陷如下:首先對(duì)于LUDB 和QTDB 中部分漏標(biāo)的記錄,沒(méi)有充分利用數(shù)據(jù);其次,對(duì)于一些疾病類型的心電圖,例如房顫等尚無(wú)法進(jìn)行準(zhǔn)確分割。這些工作有待進(jìn)一步研究。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻(xiàn)通報(bào)(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
民用飛機(jī)設(shè)計(jì)與研究(2019年4期)2019-05-21 07:21:24
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
